基于深度主动学习的MVB网络故障诊断方法
2022-12-16杨岳毅王立德王慧珍
杨岳毅,王立德,王 冲,王慧珍,李 烨
(北京交通大学电气工程学院,北京 100044)
MVB (multiple vehicle bus)网络用于传输列车车辆各设备间的控制信息、状态信息等,在高速动车组和地铁列车上得到广泛应用[1].由于恶劣的工作环境和网络设备的不断增加,多种因素都会造成MVB网络故障,网络故障表现多样.目前,MVB网络故障仍然依赖于人工排查,查找MVB网络故障根源十分困难.因此,研究MVB网络智能故障诊断方法对于实现智能化检修,降低列车运维成本具有重要意义.
MVB网络的物理层和链路层包含最多的网络状态和故障信息,常用于网络状态监视和故障诊断.文献[2]提取峰峰值、正稳态幅值等8种MVB信号特征,采用多核支持向量机来识别多种MVB端接故障,取得了不错的诊断效果.文献[3]提出一种基于权重化支持向量机的故障诊断方法,提取MVB信号特征用于诊断端接、并联电阻、串联电阻等故障.然而,这些方法依赖于专家经验进行特征提取和选择,只适用于特定应用领域.
近年来,随着深度学习的不断发展,国内外专家学者提出了许多基于深度学习的故障诊断方法[4-7].其中,由于结构简单、效率高等优点,堆叠去噪自编码器(stacked denoising autoencoder,SDAE)被广泛应用于多种领域的故障诊断中.为得到高性能的深度学习模型,需要大量的已标记数据进行模型训练.然而,工业应用中缺乏大量带标签的数据,标记数据十分耗时且成本高昂,因此,很难有充足的带标签数据进行模型训练.为解决这些问题,一些学者提出了将深度学习算法和主动学习相结合的方法,从而在少量标记数据下得到高质量的深度学习模型,已经应用在图片分类[8-9]、文本分类[10]、系统监测[11]、故障诊断[12]等多个领域.主动学习通过采用不同采样策略来选择位于分类边界、类中心等高信息量的样本进行专家人工标记后用于模型训练,从而大大降低实际应用中的标记成本.其中,不确定性采样策略具有计算量小、效率高等优点,在实际中应用最为广泛[13].文献[14-15]均采用主动学习和堆叠自编码器结合的方法进行心电图信号分类,利用信息熵和最小边缘的方法度量样本的不确定性.文献[16]采用卷积神经网络(convolutional neural network, CNN)模型进行半导体生成过程的故障诊断,利用多种不确定性采样方法来选择信息量最大的样本进行标记.然而,不确定性采样方法只选择位于分类边缘或者低密度区域的样本,因此,可能会造成样本采样偏差,同时更容易选择到异常样本,从而无法得到高质量的深度学习模型.
本文提出一种基于不确定性和可信度相结合的高效率主动学习方法,并将其与基于SDAE的MVB故障诊断模型相结合.在模型训练过程中,基于最小边缘选择高不确定性样本进行人工标记,同时,基于信息熵选择高可信度样本并自动标记伪标签,将被标记样本用于模型训练,从而实现在减少标记样本的同时得到高质量的深度神经网络模型.在MVB网络实验平台上进行了故障模拟实验,并通过多组对比实验验证了提出方法的有效性.
1 MVB网络故障
在实际应用中,MVB网络通常采用电气中距离(electrical middle distance, EMD)传输介质,MVB信号采用曼彻斯特编码,传输速率为1.5 Mbit/s.IEC 61375协议规定了EMD发送器输出信号的一致性测试标准[17].
图1为MVB网络EMD单线常见故障示意图,MVB设备采用带隔离变压器的RS485芯片作为收发器,设备间通过无源连接器和屏蔽双绞线连接,终端设备配置120 Ω ± 10%的端接器.

图1 EMD单线连接常见故障类型Fig.1 Typical fault modes of EMD single-line connection
根据传输线理论,传输线反射系数ΓL为反射波电压与入射波电压之比,其在电缆终端处为

式中:ZL为终端电阻;Z0为电缆特性阻抗.
当阻抗匹配时,终端反射系数ΓL= 0,无反射波;当负载断路或短路时,发生全反射.当0 <ΓL<1时,发生部分反射.阻抗不匹配会引起信号反射,从而造成MVB信号畸变.
电缆安装不当和弯折、连接器老化和虚接等多种原因都会造成电缆特性阻抗Z0发生变化,导致反射系数ΓL发生变化.电缆回波损耗为

在阻抗匹配时回波损耗最大,而阻抗不匹配越严重会导致回波损耗数值越小,电缆信号反射越严重,MVB信号的信噪比越低,误码率增大.
电缆衰减可以表示为

阻抗匹配时电缆衰减最小,超过极限值将导致严重的信号损耗,造成丢包率和误码率上升.
如表1所示为MVB网络常见故障,多种网络故障都会影响MVB信号物理波形质量.因此,采集MVB信号物理波形可以用于对电缆性能退化、连接器老化等网络早期故障的诊断.

表1 MVB网络常见故障Tab.1 Typical faults of MVB network
根据IEC 61375协议规定,MVB主帧的帧头为9位固定格式和长度的起始分界符,在整个MVB网络通信过程中不发生变化.因此,本文将采集到的MVB网络主帧的起始分界符对应的物理波形数据作为故障诊断模型的输入.
2 故障诊断方法
2.1 堆叠去噪自编码器
经典自编码器是一种3层对称神经网络,由编码器和解码器组成,通过最小化重构误差来实现特征学习.相比于经典自编码器,去噪自编码DAE(denoising autoencoder)通过在训练阶段中对输入样本加入随机噪声来获得更好的鲁棒性.训练完成后的DAE能够有效进行特征提取,并且能够消除输入噪声的影响.SDAE由多个上下连接的DAE组成的深度网络结构,通过将上一层DAE的隐含层输出作为下一层DAE的输入来得到更好的特征表示.采用SDAE进行故障诊断时,训练过程包括无监督特征学习和有监督全局微调.
假设输入数据X= {x(1),x(2),…,x(i),…,x(N)},x(i)∈RS,i= 1, 2,…,N,N为样本数量,S为样本的特征维度.如图2(a)所示,在无监督特征学习阶段,第m个DAE隐含层输出为
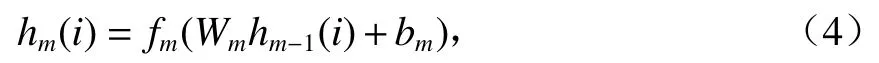
式中:fm(•)为第m个DAE隐含层激活函数;Wm和bm分别为第m个DAE编码器的权重和偏置;hm−1(i)为第m-1个DAE的隐含层输出.
第m个DAE重构输出为

则第m个DAE重构误差为

式中:θm= {Wm,bm,,}.
采用批量梯度下降对SDAE进行分层预训练,直到所有的DAE都训练完成.
如图2(b)所示,在有监督全局微调阶段,构建一个深度神经网络(deep neural network,DNN),在其最后一层增加一个softmax层,Wc和bc分别表示softmax层的权重和偏置.DNN模型的softmax层参数随机初始化,其他层初始化参数采用训练好的SDAE模型参数.利用训练集(X1,Y1),通过最小化损失函数来优化模型参数,损失函数定义为

图2 SDAE模型训练过程Fig.2 Training process of SDAE model

式中:n为每轮训练样本数;I(•)为指示函数;y(i)为样本x(i)的预测标签;K为故障类型数;p(x(i))为样本x(i)的模型概率输出;γ为损失函数权重.
2.2 主动学习
主动学习的目的是通过采用不同采样策略,从未标记数据中选择信息量最大的数据进行专家标记后用于模型训练,从而以最小标记成本得到高质量分类模型.基于不确定性的采样策略具有使用简便、计算量小等优点,因此应用最为广泛.假设存在带标签数据集DL和未标记数据集DU,不确定性采样利用softmax分类器输出不同类概率用于样本不确定性度量,度量准则包括:
1)信息熵(entropy, EN).利用全部类概率进行不确定性度量,值越大表明模型分类此样本的不确定性越大,第i个样本分类信息熵计算公式为
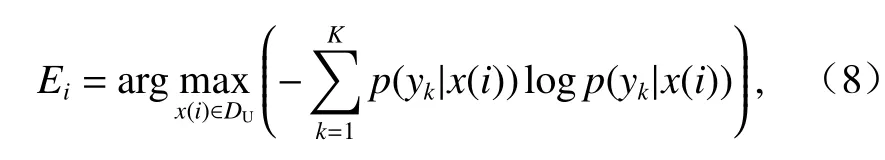
式中:yk为第k个故障类型的标签;p(yk|x(i))为样本x(i)在第k个标签的条件概率.
2)最小边缘(smallest margin, SM).将样本的最大后验概率和第二大后验概率的差定义为边缘,样本的分类边缘越小表明模型分类此样本时具有越高不确定性,第i个样本分类边缘计算公式为

式中:y∗1和y∗2分别为由模型输出得到的最大和第二大类标签.
3)最小可信度(least confident, LC).模型输出的样本最大类概率定义为样本分类可信度,样本的低分类可信度表明模型分类此样本具有高不确定性.

LC度量准则只关注分类器输出的最大分类概率,不宜用于解决多分类问题,而EN度量准则易于受到小分类概率的影响,因此,本文选择SM作为样本不确定性度量的准则.然而,不确定性采样方法只关注在低密度区域或分类边界的样本,从而造成采样偏差问题,同时噪声样本更容易被选择.因此,本文提出的高效主动学习方法在每次查询时不仅通过SM方法选择高不确定性样本并进行人工标记,同时采用信息熵度量样本分类可信度,选择分类输出概率的信息熵小于阈值λ的样本,并将输出的预测类标签j自动作为样本的伪标签,伪标签yp(i)可以定义为

在模型训练开始阶段,由于模型分类能力不强,阈值λ需要设置为一个较大的值,保证能选择到高可信度样本.随着训练的进行,模型分类能力提高,阈值λ应相应减小,避免错误地自动标记.本文中,阈值λ可以定义为

式中:λ0为初始值;r为查询次数;a为衰减率.
2.3 MVB网络故障诊断步骤
本文提出的深度主动学习方法是为在少量标记样本下得到高诊断精度的故障诊断模型,其整体架构如图3所.假设在开始阶段所有数据均未标记,带标签的初始训练数据集DL(0)为空,故障诊断方法总共分以下几个步骤:

图3 深度主动学习方法架构Fig.3 Framework of deep active learning method
步骤1SDAE预训练.SDAE模型利用所有的初始未标记数据集DU(0)进行无监督特征学习;
步骤2主动学习初始化.构建DNN分类器模型,利用训练好的SDAE模型参数进行初始化.随机从未标记数据集DU(0)中选取N0个初始样本组成初始选择样本集DS(0)并进行人工标记,得到初始标记训练数据DL(1),输入DNN模型进行初始模型训练,并更新未标记数据集DU(1) =DU(0) −DS(0)和训练数据集DL(1) =DL(0);
步骤3基于主动学习的全局微调.对未标记数据集输入DNN模型,根据式(8)、(9)、(11)和式(12)分别进行不确定性度量和可信度度量,选择Nr个样本组成第r轮选择数据集DS(r),其中,选择的高不确定性样本进行人工标记,而选择的高可信度样本自动添加伪标签,从而得到第r轮的标记训练集DL(r),然后对模型进行再训练.同时,更新未标记数据集DU(r+ 1) =DU(r) −DS(r)和训练数据集DL(r +1) =DL(r) +DL(r),并根据式(12)动态调整阈值λ的大小;
步骤4重复步骤3,直到达到最大查询次数rmax或未标记数据集为空,从而得到训练好的模型.
步骤5将测试样本输入到训练好的故障诊断模型,得到MVB网络故障诊断结果.
3 实验验证
3.1 实验设置
如图4所示,在实验室环境下搭建MVB网络实验平台.通过在原有MVB网络中增加一个网络健康诊断装置来采集MVB信号物理波形.离线状态下,将采集到的MVB信号物理波形传输到上位机,用于训练故障诊断模型.最后,将训练好的故障诊断模型进行在线部署.采用自研的MVB故障注入板卡进行故障模拟实验,通过可编程阵列逻辑(field programmable gate array, FPGA)控制继电器和模拟开关注入不同故障.

图4 MVB网络实验平台Fig.4 MVB experimental platform
实验室环境下模拟的MVB网络状态包括:正常状态(Normal)、断路故障(Fault 1)、短路故障(Fault 2)、终端电阻缺失(Fault 3)、MVB收发器电路电气特性变化(Fault 4)、连接器老化(Fault 5)、电缆性能退化(Fault 6)等7种.为了模拟实际中存在的类不平衡问题,采集5000个正常样本和每个故障类型下1000个样本,选取主设备起止分节符的600个采样点作为模型输入,从而得到的MVB网络状态数据集大小为11 000 × 600.对MVB网络状态数据集进行随机划分,70%的数据用于模型训练,其余数据用于模型测试.
采用Keras深度学习架构搭建模型,SDAE模型有3个隐含层,隐含层神经元个数分别为50、200和400,输入层和输出层神经元个数均与MVB信号采样点个数相同.因此,DNN模型输出层神经元数与故障类别数相同,其他层神经元数与SDAE模型相同.模型训练采用Adam优化器,学习率为0.01.初始阈值λ0为0.01,衰减率a= 0.0002,初始样本数N0为1个,每次查询的样本数N= 100个.为评估故障诊断方法的性能,选择分类准确率、诊断错误率和检测错误率3种评价指标[18].分类准确率为分类正确的样本数与总样本数的比率;诊断错误率为错误地分类为其他故障类型的故障样本数与总故障样本数的比率;检测错误率是故障样本被错误分类为正确样本的数量与总故障样本数的比率.
3.2 实验结果分析
为验证提出方法的有效性,本文选择EN、LC两种方法分别与高可信度评估方法相结合,分别表示为HEAL_EN、HEAL_LC.AL_ALL表示未采用主动学习策略,将所有数据进行人工标记后用于模型训练.AL_RAND表示不采用主动学习策略,随机选取样本进行人工标记.如图5所示,所有基于主动学习方法的表现均明显优于AL_RAND,这说明采用主动学习方法能够在少标记样本的情况快速提升模型性能.为了达到90%分类准确率以上,本文方法只需经过5次查询,共需标记600个训练数据,约占总未标记样本集的7.79%,而AL_RAND方法需要27次查询,共需标记2800个训练数据,约占总未标记样本集的36.36%.同时,本文方法的表现要略优于HEAL_EN和HEAL_LC两种方法,这是因为SM采样策略更适用于解决多分类问题.

图5 不确定性和可信度相结合的主动学习方法的对比实验结果Fig.5 Comparison results of active learning methods based on uncertainty and credibility
为进一步验证本文方法的优越性,将本文方法与文献[14]提出的基于SM和基于EN的主动学习方法进行对比实验.图6中AL_SM和AL_EN分别表示采用最小边缘采样策略和信息熵采样策略.由图6和可知,本文方法表现优于AL_SM和AL_EN方法,在少标记样本的情况能够更明显提升模型性能.表2为不同已标记样本数下的对比实验结果,在相同数量的已标记训练样本下,本文方法的准确率均高于AL_RAND方法的准确率,同样也高于文献[14]提出的两种方法.这是因为SM方法能够有效选择分类边界处的样本点来加速模型训练,而且通过选择高可信度的样本避免出现采样偏差.同时,HEAL_EN方法的表现也优于AL_EN方法,进一步说明本文提出方法结合能够提升主动学习方法的性能,提高模型的训练效率.

表2 不同已标记训练样本数下的分类准确率Tab.2 Classification accuracy under different numbers of labeled samples%
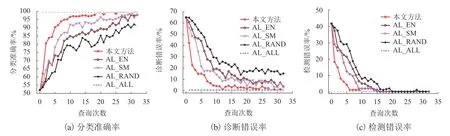
图6 与基于不确定性的主动学习方法的对比实验结果Fig.6 Comparison results with different active learning methods based on uncertainty estimation
为展示本文提出方法的工作过程,每次查询时带标签训练集中不同类别样本占比如图7所示.如图7(a)可知:每次查询时随机采样方法并不会改变样本类分布,正常状态样本占比并没有变化,训练样本处于类不平衡状态,从而影响模型训练质量.如图7(b)可知:采用本文方法后,每次查询时样本类分布是在动态变化的,正常状态样本比例下降,样本类分布相对更加均衡,能够得到更好的模型训练效果.

图7 查询过程中带标签训练样本的类别分布Fig.7 Class distributions of labeled training samples in query process
4 结 论
本文提出了一种基于主动深度学习的MVB网络故障诊断方法,采用SDAE模型从MVB信号物理波形中自动提取高可分性的故障特征.同时,提出一种高效主动学习方法,选取人工标记的高不确定性样本和自动伪标记的高可信度样本用于深度神经网络训练,从而在少标记训练样本下得到高质量的诊断模型.与其他方法相比,本文提出的方法具有更高的模型训练效率,在相同带标签的训练样本下能够得到更好表现的故障诊断模型.在MVB网络实验平台上模拟多种网络故障,并进行了多组对比实验,实验结果验证了方法的有效性.未来重点探讨本文方法在更多应用场景下的适用性,同时研究多种采样策略组合方法.
