基于教育数据挖掘的学业表现影响因素研究①
2022-12-15沈林豪
沈林豪, 唐 海, 许 睿
(湖北汽车工业学院电气与信息工程学院,湖北 十堰 442002)
0 引 言
十四五以来随着高等教育的普及,毕业率和就业率等问题逐年增多,教育部提出,完善高等教育服务体系,防范低分低能风险,推动高等教育高质量发展,培养综合型高质量研究型人才。
大数据时代背景下,随着信息技术的快速发展以及人工智能和云计算等技术的大规模应用,各行各业都积累了海量的数据,这些数据往往蕴含着有价值的“知识”和“信息”。教育信息化和在线教育的发展产生了超大规模的数据,运用教育数据挖掘技术挖掘出有价值的信息并呈现给学习者和教师,从而提高学生学业表现和改善教学模式,已成为高校的现实需要[1]。高校学生学业表现是高等教育质量的重要体现,通常以综合学习成绩“优、良、中、差”分类等级的形式呈现。本研究采用教育数据挖掘技术,在学校教务管理系统、学生管理系统、学生个人信息系统等各信息系统中收集学生人口统计特征、个人特征、学习环境和学习投入四个方面的信息,构建学生学业表现预测框架,然后通过使用贝叶斯网络、决策树、支持向量机和神经网络四种算法分别建立分析模型,分析影响学业表现的因素。
1 研究现状
以往学业表现研究考虑的因素主要是围绕着课程成绩、作业成绩和考勤率等,使用相关的统计学方法或者大数据技术来预测学生的学业表现。由于课程成绩、作业成绩、考勤率等因素与学业表现具有强相关性,所得结论欠缺说服力。随着大数据与人工智能的发展,高等院校对人才培养的严要求,使用教育大数据技术为高校学生的学业表现进行评估和预测已是大势所趋。教育大数据正在通过分析高校数据,改善教学方式,提高教学质量等方式推进教育教学方式的变革。教育数据挖掘作为二十一世纪以来新创立的一门学科,已经成为教育领域分析高校学生学业表现的有力工具。
国外教育数据挖掘的技术和方法研究较早,有着丰富的研究成果和案例。Garcia等[2]在2011年考虑社会人口特征和学术变量特征对学习成绩的影响,通过使用数据挖掘技术和朴素贝叶斯分类器构建了一个准确率接近60%的模型。同年Sajadin Sembiring等[3]基于支持向量机分类模型,通过使用问卷收集到的学生心理因素和数据库管理系统课程中的学生数据等作为输入变量,构建了一个成绩等级预测模型,将所有成绩分成优秀、良好、中等、一般、差,对1000名来自三个不同专业的学生成绩进行预测,正确率为61%。Ashkan Sharabiani等[4]在2014年基于贝叶斯网络框架构建学业成绩预测模型,把300名学生的年龄、性别、种族、国籍以及已修关联课程成绩作为输入,预测课程成绩。Garima Sharma与K Santosh[5]在2017年利用ID3决策树算法,根据学生以前的成绩预测学生的最终成绩,对学生学业成绩按照“低、一般、好”进行预测,正确率分别为79%、97%和67%。
国内关于教育数据挖掘的研究较晚,成果较少。黄景碧[6]在2012年设计开发了数据驱动的教育决策支持系统原型,通过各种算法从多维度分析学习者的学习兴趣,预测学习成绩,为提高学习者的学习,课程优化等提供客观性和科学性的决策。舒忠梅和屈琼裴[7]在2014年通过教育数据挖掘技术在学生个体和学校两个层面构建大学生学习成果的预测和评价模型。彭涛[8]在2015年从数据准备、数据筛选、数据预处理、数据转换、数据挖掘模型建立及结果分析等六个方面构建学生表现预测模型。郭芳侠和刘琦[9]在2018年基于混合式教学,从学生的平时成绩、在线学习情况、评论条数、在线学习时长、在线活跃度、班级活跃度和章节测试成绩等七个方面,利用相关性分析,探讨学习行为对学业表现的影响相关性及男女生之间的差异。赵呈领[10]在2019年基于在线学习者的学习行为,从在线时长,观看视频次数、浏览文档时长、作业完成情况和讨论次数这五个方面对学生学业表现的影响进行相关性分析。张敬和芦雪娟[11]在2020年以高等数学课程改革为例,利用相关性分析法,从学生学习时间、测试成绩、下载学科资料次数和学生参与问题的研讨次数四个主要方面来研究学习行为与学生课程成绩的相关性,结果表明,上述四个方面对学生学业表现均存在显著的影响。杨婉霞[12]在2021年分别从学生的课堂考勤率、参与讨论相关问题的次数、在线学习时长和浏览教学资料次数四个方面来研究学生在线学习行为与期末考试成绩之间的内在关联性。综上所述,国内对于学业表现的研究主要在于定性的分析与多技术的融合提高理论准确率等,借鉴国内高校学生学业表现研究经验,本研究采用教育数据挖掘技术对学生学业表现数据进行处理,从学习效果角度进行分析解读,探索学生学业表现的影响因素。
2 学业表现研究方案
学业表现实际上是一个学习成果评估问题,学生的学业表现是学生在经过一段时期的学习后对上一阶段学习成果的一个体现。
2.1 学业表现的影响因素
高校学生学业表现的影响因素是多方面的,包括外部环境和个体内在表现。为探究高校学生学业表现影响因素,把众多的影响因素进行有效地结合起来构建一个总体研究框架,使得研究设计更加科学,结论可解释。
早在二十世纪九十年代,Pace[13]就已经开始探索高校学习环境、学生学习投入程度与学生学业表现的相关性了。清华大学的史静寰和王文[14]梳理了国内外有关学业表现的主要研究成果,同时在总结清华大学学生学习表现的基础上,设计了中国大学生学情研究框架,重点关注学生在行为、认知和情感三方面的投入与表现。张劲英[15]在2017年提出从环境、学生个人、学习行为三个因素构建大学生学业成就分析框架,应用数据挖掘技术构建大学生学业表现的关系模型。
研究教育学理论为指导结合数据挖掘技术,从人口统计特征、学习环境、个人特征和学习投入等四个方面来探讨高校学生学业表现,如图1所示。
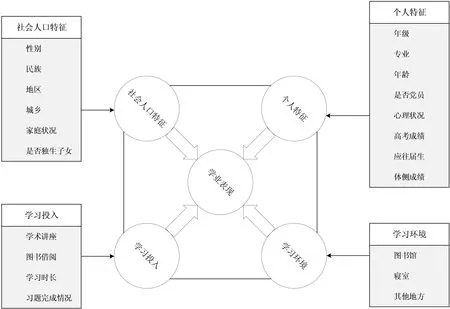
图1 高校学生学业表现影响因素
2.2 数据来源
本研究数据来源于某高校教务管理系统、学生信息系统、学生管理系统和问卷调查等。由于学生的各方面的信息来自不同的管理系统或者问卷调查,因此需要构建综合型教育数据系统,将分散的各类数据集中存储到统一的数据库中。系统分为数据层、数据预处理、数据整合层和数据应用层四个层次,总体结构如图2所示。
研究从社会人口统计特征、个人特征、学习环境和学习投入等四个方面来考虑预测目标,共采集21个变量,具体如表1所示。

表1 学业表现预测模型的变量
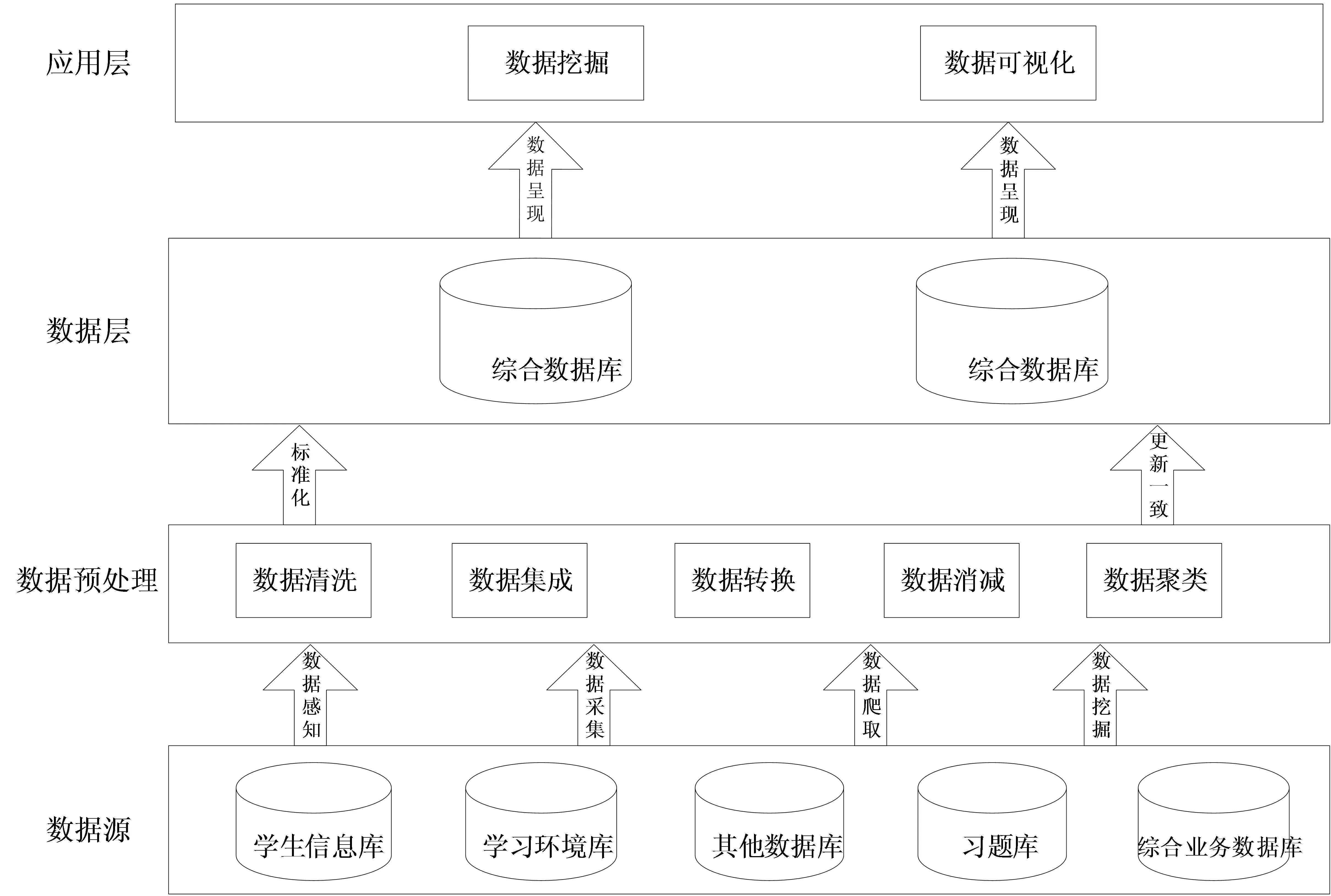
图2 综合型教育数据系统总体结构
2.3 研究工具
本研究使用SPSS Modeler作为建立学业表现研究模型的工具软件。SPSS Modeler内置多种建模算法,比如K-means聚类算法、决策树分类算法、支持向量机算法和神经网络算法等等。使用各种算法的目的就是通过对数据的建模分析出各因素的内在相关关系以及对学生学业表现的影响。SPSS Modeler在符合数据挖掘的标准协议上,以工作流的方式将数据源的选取,字段的选取,建模以及输出结果等教育过程以图形可视化的方式呈现。
3 学业表现分类模型的构建与评估
目前分类算法中使用最广泛的是决策树算法、贝叶斯网络算法、神经网络算法和支持向量机算法,因此本研究分别运用这四种算法对数据进行预测,并对预测结果进行评估。
3.1 数据采集
本研究以湖北某高校信息与工程学院开设的“离散数学”课程为例建立学生学业表现分类预测模型,通过教育数据挖掘技术将教学管理信息系统、学生管理系统、学生信息系统和图书借阅系统等各个系统中的学生信息分别挖掘出来放入到综合型教育数据框架中。然后在综合教育数据框架中采集本问所需要的,探讨影响学生学业表现的影响因素和各种因素对学业表现的影响方式。共采集了本院大二学生数据600条,约占信息与工程学院大三学生总数的90%。数据包括本研究所探讨的21个因素和学业表现情况,并在综合型教育数据框架中对原始的各类学生信息进行数据预处理。本文将学生取得的学业表现分为了四种基本类型:优秀、良好、一般、差,在建立学业表现模型时需要把学生的成绩转换为对应类别。其中85分以上记为优秀,75~85分之间记为良好,60~75分记为一般,低于60分的记为差。
3.2 模型构建
在对学生学习成果评估之前需要对学生数据进行预处理。先针对原始数据中所存在的数据缺失问题,采用权值平均法对缺失数据进行填充,以突出数据中临近数值之间的关系;其次将处理后的数据划分为训练集和测试集;最后通过比较不同模型在测试集上的性能,评估各个模型的优劣性。
将综合型教育数据框架中的学生信息Excel文件导入到SPSS Modeler中进行建模分析,在SPSS Modeler中的“分区”节点中将总数据量的85%设置成模型训练集,剩下的15%作为测试集进行实验;在“类型”节点中将四个方面的21个影响因素设置成自变量,学业表现作为预测变量进行建模研究;分别选择决策树、贝叶斯网络、支持向量机和神经网络四种建模算法对学业表现的运行结果进行探讨,总体工作流程如图3所示。
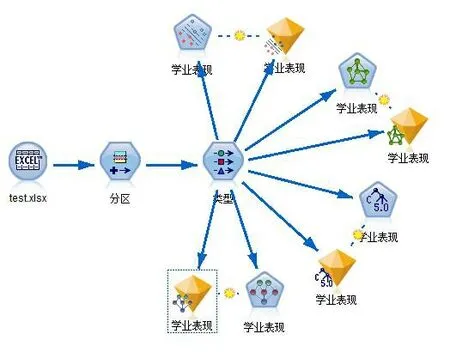
图3 总体工作流程图
不同的方法对学业表现进行建模研究,研究结果所呈现的方式各不相同,其中决策树C5.0算法的运行结果以树状图的方式呈现,其中最左端的节点代表着预测变量学业表现,决策树算法将影响学业表现的因素分成4层,共9个节点。决策树C5.0算法的运行结果如图4所示。
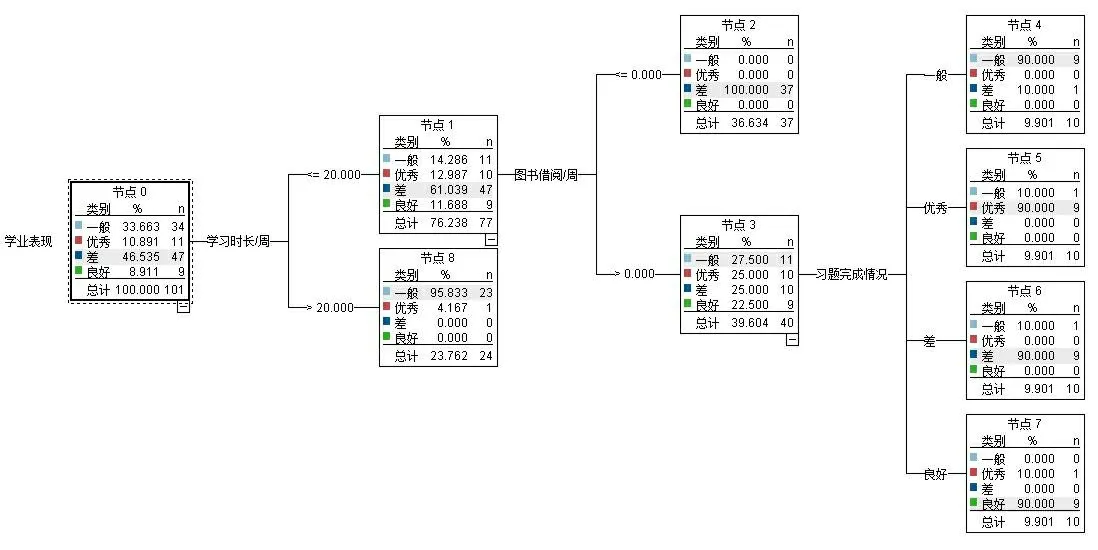
图4 决策树C5.0算法运行结果
运用决策树算法探索对学业表现影响最大的三个因素,结果如图5所示。
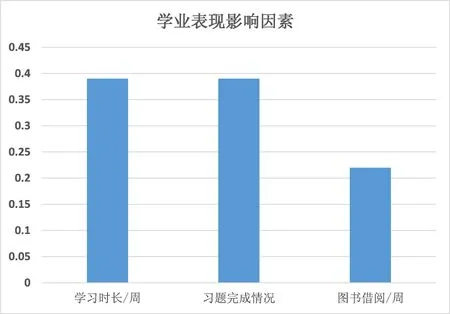
图5 决策树运行结果
通过决策树模型对所有影响因素的分析可知,对学业表现影响最大的两个因素是每周学习时长和习题完成情况,影响大小为0.39,从正面体现了每周学习时长和习题完成情况直接影响学生学业表现。其中对学业表现影响最小因素是图书借阅/周,影响大小为0.22,这说明学生每周图书借阅次数对学业表现的影响一般。高等教育的重点在于学生本身自学的时长。
在贝叶斯网络模型中学业表现与影响因素之间是以有向无环图的方式展现,最左端节点为目标节点学业表现,其他节点依据对学业表现的影响大小进行分层排列,根据各因素之间的内在关系,其他因素节点之间以有向边连接,每一条边都代表着该因素对上一个因素节点的影响概率,从左往右相乘所得概率值为最右端的因素节点对学业表现的影响概率大小。贝叶斯网络算法的运行过程如图6所示。
通过贝叶斯网络预测模型研究性别对学业表现的影响,结果如图7所示,体现出性别与学生学业表现有着明显的联系,特别是在学业表现“一般”的人群中性别的差异表现得尤为明显。学业表现“一般”的学生中女生所占比例为71%,说明女生对于外界各种干扰因素有较强的自控力,更适应目前中国高校教学方式。

图6 贝叶斯网络算法运行过程
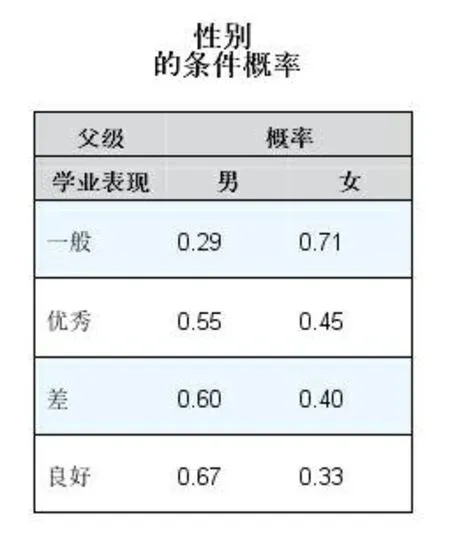
图7 性别对学业表现的影响
神经网络主要是通过分析多因素的联合作用对学业表现的影响来建立模型。采用神经网络算法进行学业表现预测运行过程如图8所示,最右端为目标变量学业表现,最左端为学业表现影响因素,学业表现预测模型总共分为三层,其中隐含层包含6个神经元。
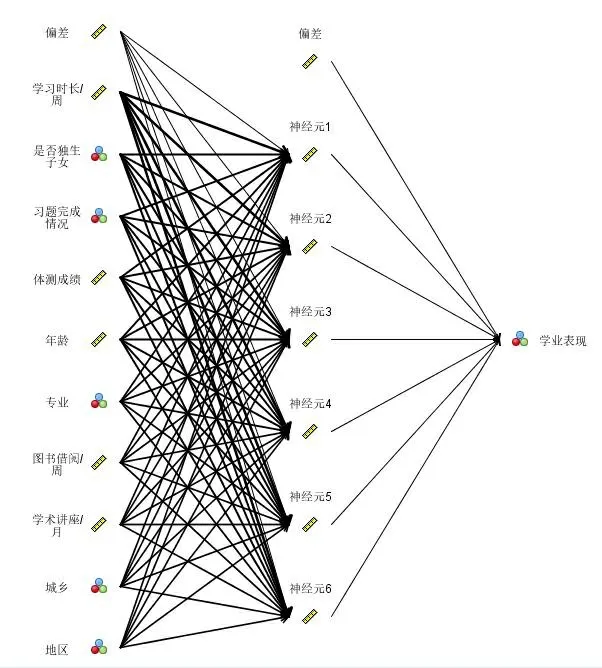
图8 神经网络算法运行过程
基于神经网络算法对各影响因素进行分析结果如图9所示。其中对于影响因子小于0.05以下的忽略不计,通过神经网络算法对影响学业表现的因素分析可知,对学业表现影响最大的三个影响分别是每周学习时长、是否独生子女和习题完成情况。
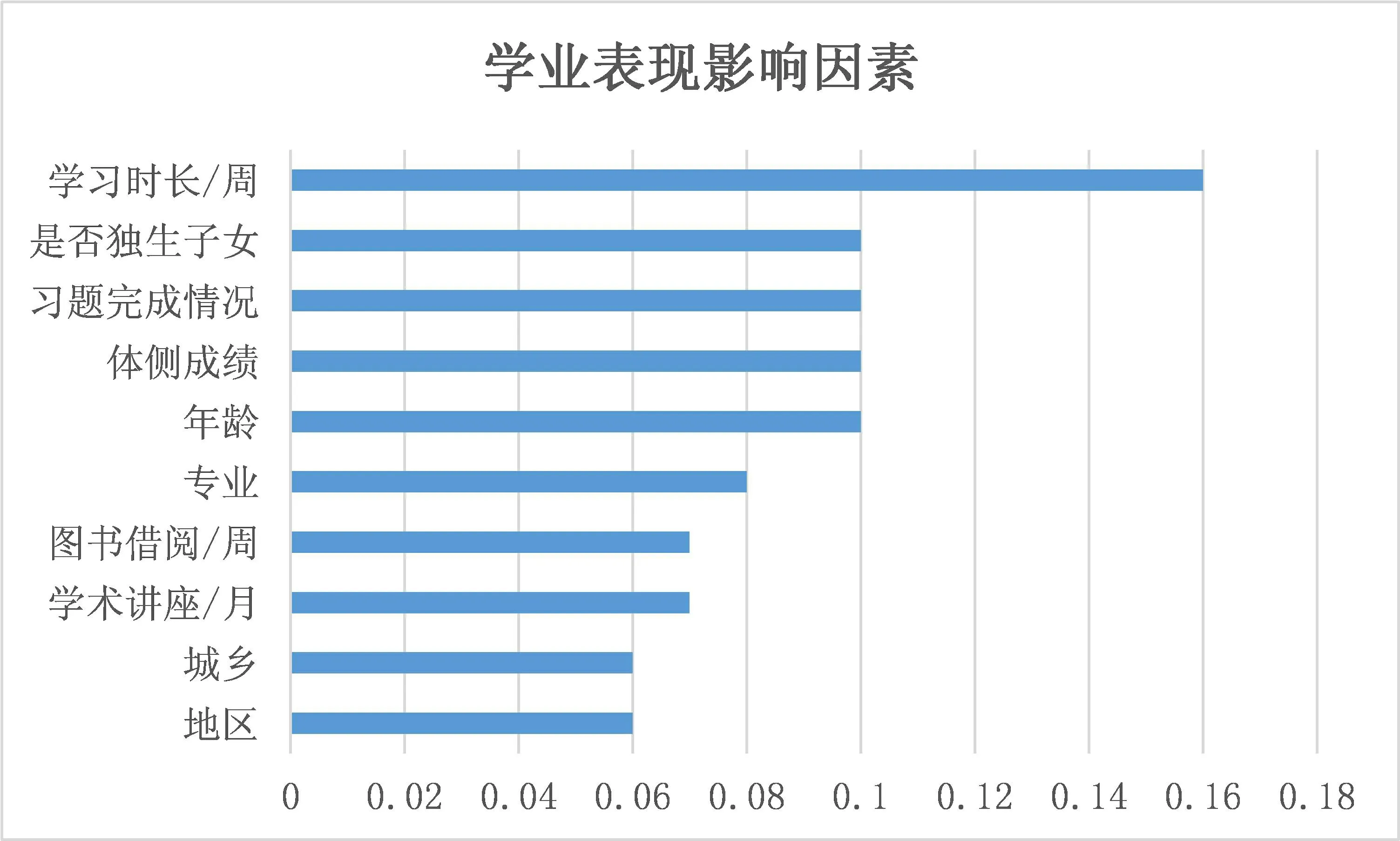
图9 基于神经网络的影响因素重要性分析
基于神经网络的学业表现的分类准确率如图10所示。其中神经网络在学业表现“一般”和良好的人群分类上面准确率达到100%,在表现“优秀”人群上预测率最低60%,总体准确率为91.7%。
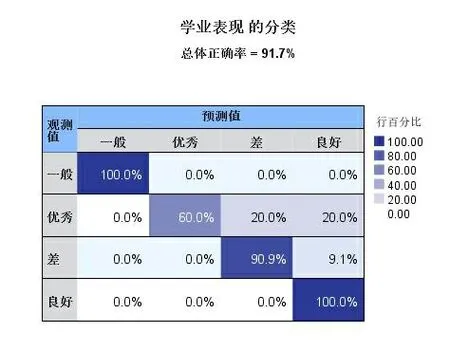
图10 基于神经网络的学业表现准确率
运用支持向量机模型对影响学业表现的因素进行分析,同样对于影响因素小于0.05以下的影响因子忽略不计,对学业表现影响最大的十个因素如图11所示,其中对学业表现影响最大的三个因素为习题完成情况,性别和家庭状况。
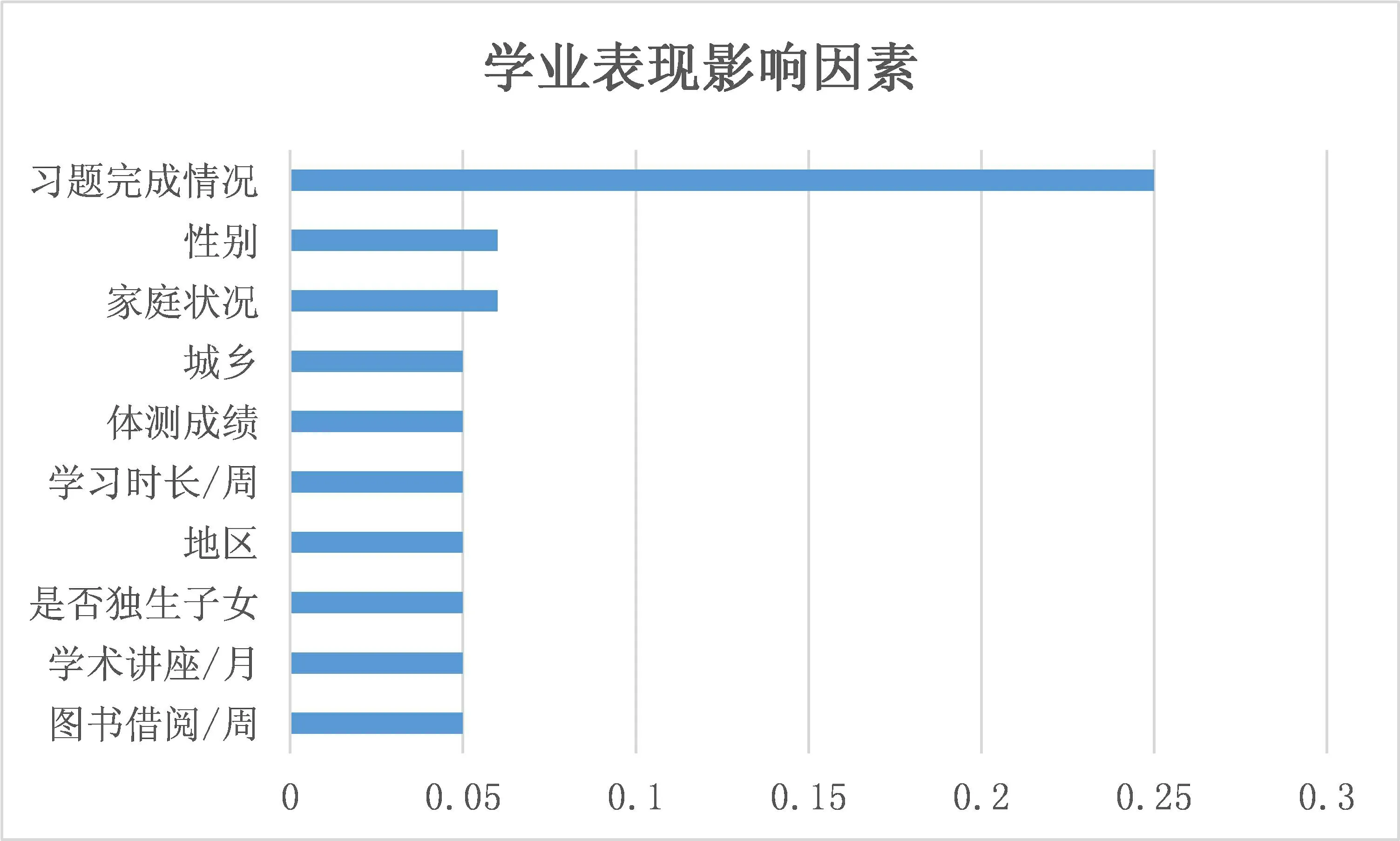
图11 基于支持向量机的影响因素重要性
运用上述四个算法,对学业表现的21个因素进行影响程度计算,结果如表2所示:

表2 四个模型分析影响因素
3.3 模型评估
由于本研究的学生数据量不大,为提高模型的预测精度,采用10折交叉验证方法对各模型进行训练和预测,将10次实验结果的平均值作为模型评估指标相应的值,并且10折交叉验证法可以避免由于数据集划分不合理而导致模型在训练集上过拟合。准确率是指被分类模型正确预测的百分率。召回率指真实值被正确识别的百分率,F1值是为了同时兼顾准确率和召回率的,F1值越高,则分类模型越有效。以上四种算法的准确率、召回率和F1值如表3所示。
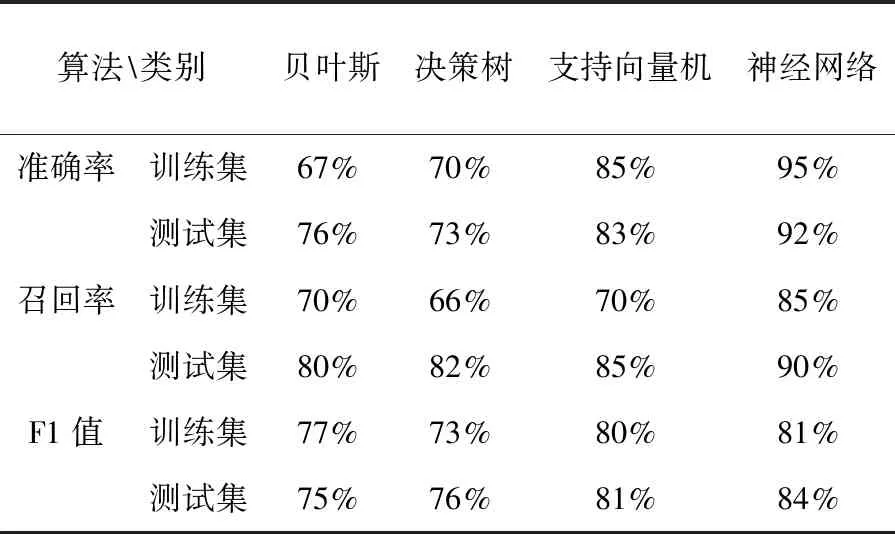
表3 四种模型的准确率、召回率和F1值
在四种算法构造的模型中,支持向量机和神经网络算法的学业表现预测准确率最高,类似研究可考虑运用这两种算法搭建模型。
4 结 论
运用数据挖掘技术预测学生学业表现。考虑到影响学业表现的因素较多,提出了综合教育数据框架,采用四种分类算法对各种影响因素进行分析,得出以下结论:
1.高校学生学业表现主要受人口统计信息、学习环境、个人特征和学习投入四方面因素影响。在学习环境方面,在图书馆学习的学业表现要明显优于其他地方的学习环境。在个人特征方面,是否是学生党员、心理状况等都对学业表现产生了直接或间接的影响。在学习投入方面,每周学习时长和习题完成情况对学生的学业表现影响较大。
2.研究发现在影响学生学业表现的四个方面中,学习投入是最重要的。四个模型的运算结果显示,学生在学习投入方面越多,学业表现越优秀。
最后,本研究的实验数据来源于一所地方高校,本结论对全国其他高校是否具有普适性,有待进一步的研究。
