基于多智能体强化学习的分层决策优化方法
2022-12-14李天皓白春光
□张 倩 李天皓 白春光
[电子科技大学 成都 611731]
引言
决策是指决策主体选择其行为的过程,决策过程的任一环节出现偏差都有可能导致失误,决策辅助支持系统对提高决策科学性和正确性具有重要作用[1~2]。随着机器学习(Machine Learning, ML)、深度学习(Deep Learning, DL)和大数据等技术的发展和成熟,人工智能技术在辅助决策方面也表现出良好的应用前景,可通过挖掘在线医疗评论等为医疗决策提供参考,为政府智能决策提供优化方案等[3~4]。
传统的决策优化方法主要建立数值模型求最优解[5~6],方法的计算成本高,且模型泛化能力较差,尤其在长周期连续决策问题中往往效果不佳。作为一种智能决策框架,强化学习(Reinforcement Learning, RL)以马尔可夫决策过程(Markov Decision Process, MDP)为理论基础,采用“试错”的方式进行学习,在连续决策过程中寻找解决问题的最佳策略。智能体通过与环境的交互学习经验,并利用过去的经验来改善未来行动的预期结果,在探索与利用的平衡之间实现奖励的最大化,是一种适应性的学习过程。利用强化学习优化决策问题的研究在围棋、电子游戏、医疗决策、军事战略等领域都取得了显著优于人类决策的效果[7~12]。
强化学习被证实在优化重症监护临床决策、电力系统决策控制、职业道路选择推荐等方面发挥出巨大的作用[13~15]。针对自动驾驶汽车在交通中的决策问题,强化学习可以根据道路情况自主决定驾驶行为,进行车道变更的决策[16~17]。在农业方面,强化学习借助天气预报优化水稻灌溉决策,为农作物疾病的最佳治疗方案提供决策支持[18~19]。在商业领域,智能决策支持系统采用强化学习预测物流网络的变化,也可以为金融市场的股票交易策略提供支持[20~21]。在教育方面,强化学习可基于学习者的个人信息和社交资料推荐最佳的学习方式和适合的学习课程[22],以提高学习质量。在医疗领域,强化学习在支持临床疾病诊断辅助[23]和个性化用药治疗[24]方面展现出明显的优势,可为智慧医疗建设发挥作用。可见,强化学习已经被应用于社会活动的各个方面,在为决策优化提供辅助和支持方面显示出较强的应用潜力。
在社会决策过程中,决策的结果往往由多个参与者共同决定,强化学习使用多智能体建模多主体决策行为[11]。决策者可以应用多智能体强化学习(Multi-Agent Reinforcement Learning, MARL)算法辅助决策,智能体之间通过竞争与合作方式以最大化团队行动的价值,从而改善决策结果[25]。由于现实中多数决策过程的参与者之间存在明显的等级关系,本文应用具有层级关系的多智能体进行建模,即多智能体分层强化学习(Hierarchical Reinforcement Learning, HRL)[26]。作为多智能体合作强化学习的一种特殊结构,分层强化学习采用层次结构克服多智能体强化学习环境的不稳定性,具有解决稀疏奖励和延迟奖励问题的能力[27]。随着多智能体分层强化学习技术的日益成熟,HRL应用于MOOCs课程推荐、自动驾驶辅助决策、机器人控制等多方面都取得了良好的效果[16,28~30]。
本文基于多智能体强化学习提出了分层深度Q网络(Hierarchical Deep Q-network, HDQ)模型,该模型引入两个智能体相互合作进行学习,在分层模型的基础上,引入目标分解的思想,并结合DL模型,通过神经网络对智能体进行建模,让上层智能体学习最佳的目标分解策略,并将分解的最佳目标传递给下层智能体,指导下层智能体采取行动,通过智能体之间的相互合作,实现团队整体的最终决策目标。
一、多智能体强化学习的分层决策优化
(一)强化学习
强化学习是以马尔可夫决策过程为基础的理论框架,阐述了在解决动态决策问题中智能体与环境的交互过程。强化学习可通过其5个主要要素表示成为5元组 < S,A,P,R,γ>,其中S表示状态集合,A定义智能体可采取的动作集合,P为状态转移矩阵,刻画环境状态的动态变化方式,R是智能体采取动作后获得的奖励集合, γ (0≤γ≤1)表示未来奖励对当前累计奖励的折扣率。强化学习将决策主体建模成能与环境进行动态交互和学习的智能体。在时刻 t =1,2,···,T 时,当智能体采取动作 at∈A,环境会以概率 p (st+1|st,at)∈P 从当前状态 st∈S转移到下一个状态 st+1∈S ,此时智能体获得奖励 rt∈R。RL将决策问题形式化为寻找使预期累计奖励最大化的最优策略[31],其中预期累计奖励可计算如下:

由于传统的RL模型在处理高维数据中具有局限性,DL可以与RL相结合实现更好的决策效果。深度Q网络(Deep Q Network, DQN)利用神经网络在高维空间学习中的优势,引入神经网络作为值函数逼近器,计算最大化累计奖励的最优解。DQN采用带参数的神经网络估计动作价值 Q (s,a),并基于经验回放机制进行学习,通过最小化误差损失不断逼近最优解:
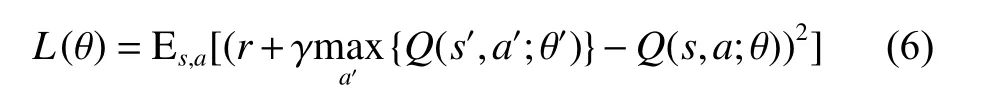
但是传统的DQN模型存在高估Q值的问题,容易跳过最优解学习到次优解,导致模型效果不佳。为了缓解这一问题,Dueling DQN[32]在DQN的基础上引入优势函数衡量动作的相对价值,优势函数计算如下:
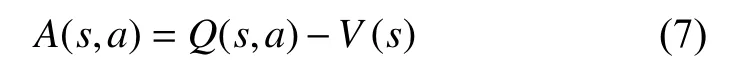
从而将智能体的目标转化为最大化:

(二)目标分解与层级决策
强化学习因其特有的马尔可夫特性而在顺序决策中具有较大优势,但在应用于长周期决策优化问题中,短期内无法衡量动作对最终目标G的影响,智能体在多数时间步内的奖励为0,从而造成奖励的稀疏性,且没有奖励引导容易使智能体陷入困境,影响智能体的学习效率。分层强化学习应用具有层级结构的智能体能够解决稀疏奖励问题,智能体通过决策引导其他智能体采取动作。
在复杂任务的解决过程中,决策周期T通常很长,需要在多个决策时间步 (t =0,1,2,···,T)依次决策,且决策的有效性和准确性在短期内无法得到验证。本文的做法是采用分解的思想对目标进行细分,化繁为简,分而治之,通过小目标的实现逐步达成最终目标。分解的思想也被用于解决复杂数据集下的机器学习和数据分析问题[33],表现出优于基线方法的良好效果。如图1所示,智能体的任务是在决策周期T内实现目标G,在目标分解方法下,智能体学习如何将整体目标G分解为各个子目标gt(t=0,1,2,···,T),并通过计算状态st(t=0,1,2,···,T)与子目标之间的距离 d is(gt,st)判断子目标是否完成,此时,智能体的动作定义为在不同的状态下选择子目标,即at:=gt。

图1 目标分解过程
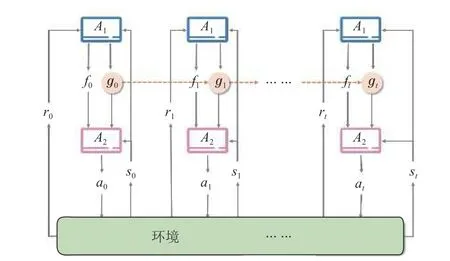
图2 模型结构
(三)目标优化
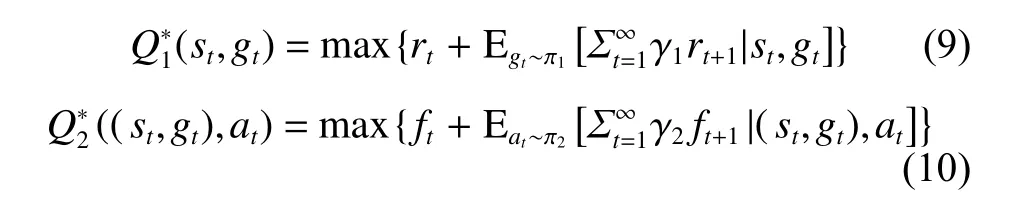
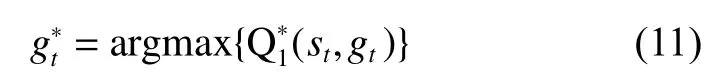
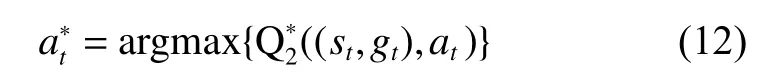
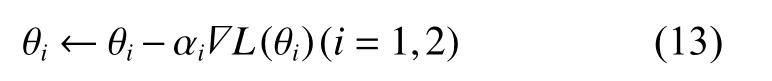
其中 αi(i=1,2)为梯度下降的步长,即神经网络的学习率,智能体和智能体交替迭代进行学习和参数更新,直至整体策略收敛。
二、实验验证分析
(一)实验背景
脓毒症是由感染引起的危及生命的器官功能障碍,是导致危重患者死亡的主要原因[34]。不同脓毒症患者对治疗措施的个体反应不同[35],反复住院率高[36]。脓毒症患者的治疗过程是一个长期的、动态的、连续的临床决策过程,对决策质量的要求高,传统的技术方法难以对其进行优化。本文提出的方法一方面可以克服强化学习延迟的奖励和复杂的状态空间容易导致策略的次优性,通过将任务分解为子目标,可以减少探索空间。另一方面,本文方法可以模拟不同等级的医生之间层级指导和合作行为,协同做出治疗决策。我们将结合目前广泛用于研究的医学数据集的MIMIC-IV提取脓毒症患者序列和特征,对患者的治疗决策过程进行优化。
(二)实验设计
1. 数据提取
本文的实验对象为MIMIC-IV数据库中符合Sepsis-3条件[37]的4 800名脓毒症患者。表1显示了原始数据集的汇总,包括存活和死亡患者的比例、平均年龄、男性比例、再入院情况和SOFA评分,其中SOFA评分是脓毒症的顺序器官衰竭评分,根据患者的呼吸系统、血液系统、肝脏系统、心血管系统、神经系统和肾脏系统等六大人体系统相关指标计算而得的分数[37],是判断脓毒症严重程度的关键指标,与患者死亡有着密切关系[38]。
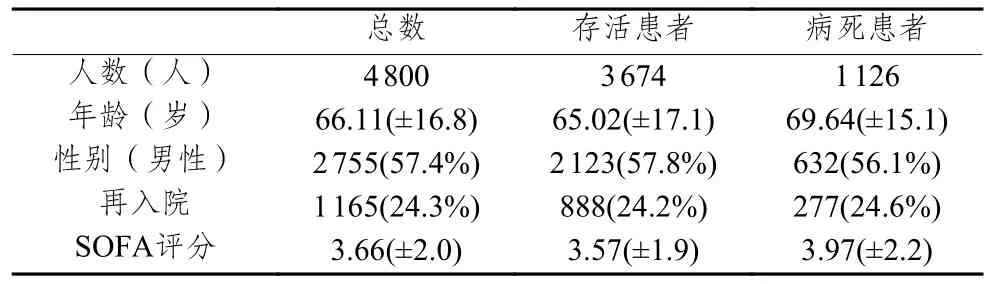
表1 患者信息表
随后,本文提取了患者住院前4小时到住院后72小时的特征,如性别、年龄、体重、SOFA评分、心率、血压、呼吸频率、血氧饱和度、体温、血红蛋白、钾含量、钠含量、凝血酶原时间和血小板数量等在内的45个特征。然后,对每个特征进行一次4小时窗口汇总,使用均值插值方法处理其中的缺失值。其次,使用最大最小归一化方法消除特征之间的量纲,以确保数值在[0,1]区间内。最后,得到了包括45个特征的91 200条可用数据记录,每个患者对应19个历史治疗轨迹。
2. 实验变量与参数选择
(1)状态
状态空间由动态变量和静态变量组成[11]。静态变量包括性别、年龄、体重等信息,动态变量包括患者的生命体征、实验室检查指标和尿液量等数据。由于变量过多容易造成模型的过拟合,影响模型的效果。同时,过多的状态变量容易导致强化学习中的转移矩阵过于稀疏,导致状态转移困难。因此,为了降低数据特征的维数,本文采用了K-means算法对状态进行聚类,以达到降维的目的,避免转移矩阵的稀疏性。经过聚类处理后,得到了700个不同的状态类别来表示患者的身体状态[39]。
(2)子目标
SOFA评分是衡量脓毒症患者的关键指标,与患者的死亡率密切相关,对于治疗决策的结果有着较大影响。上层智能体学习子目标的分解策略,其动作空间定义为患者的SOFA评分。因此,本文根据数据集中患者的SOFA评分的取值范围对上层智能体的动作进行离散化处理,将其动作空间定义为一维向量,元素取值为[0,18]区间内的整数。因此,在每一个决策的时间步中,上层智能体根据患者状态选择最佳的目标SOFA评分,并将其传递给下层智能体作为子目标。
(3)动作
临床实践中,医生普遍采用血管升压药和静脉输液治疗脓毒症患者。下层智能体在不同的时间步根据状态和子目标选择最优的动作,以学习实现目标的用药策略。动作空间定义为两种药物组成的二维矩阵,分别由血管升压药的最大剂量和静脉注射的总剂量组成,其中血管升压药包括血管升压素、多巴胺、肾上腺素和去甲肾上腺素,静脉注射液包含晶体、胶体和血液制品以及静脉注射抗生素等。药物剂量通过四分位数进行离散化,没有使用药物的患者对应剂量为0。
(4)奖励

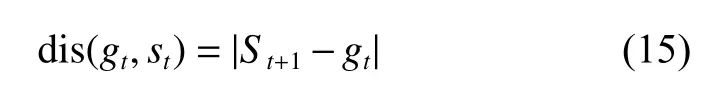
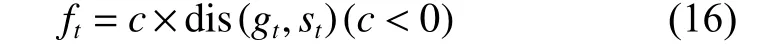
(三)实验结果分析
实验环境基于Python 3.6和TensorFlow 1.15,两个智能体均由神经网络进行建模,网络的学习率α设置为0.01。算法基于强化学习建模,强化学习模型的奖励衰减折扣γ设置为0.9,下层智能体的目标阈值η设置为2,模型基于以上参数进行训练。
根据实验设计,本文对照临床医生的用药决策、无层次结构的单智能体Dueling DQN以及DQN作为基准模型,基准模型的所有参数设置和训练迭代次数均相同。通过与基准模型进行对比,评估HDQ模型在决策优化问题中的效果。
在强化学习中,Q值的大小用于衡量模型所选动作的价值高低,图3显示了本文的HDQ模型与Dueling DQN和DQN两个基准模型在训练过程中的Q值比较情况,其中横轴表示模型训练的迭代次数,纵轴表示模型的Q值大小。在模型迭代训练10 000轮后,三个模型的都达到了收敛,学习到了有效的稳定策略。根据图3可见,在训练前期,模型都倾向于选择具有较高Q值的动作。随着训练过程的进行,模型学习调整动作的选择,导致Q值不断减小并最终收敛。同时,根据Q值比较结果也可以发现,Dueling DQN模型的效果优于传统的DQN算法,但与本文的HDQ模型相比还有一定的差距。与基准模型相比,本文的HDQ模型在动作的选择上具有明显优势,在收敛条件下,Q值显著高于基准模型。
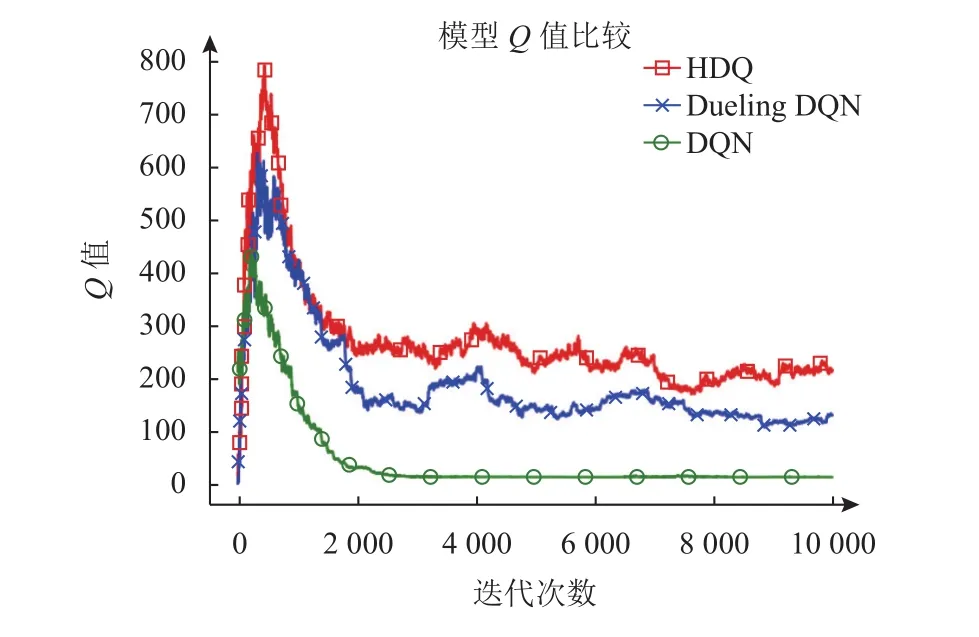
图3 不同模型Q值比较
死亡率是衡量医疗用药决策策略有效性的重要指标,对患者的治疗结果有着决定性作用,表2列出了不同策略下患者住院死亡率的比较。整体而言,临床医师治疗策略下的患者死亡率是最高的,高达23.5%。对于无分层结构的模型来说,不论是Dueling DQN还是DQN算法,都能够在临床医师的基础上通过优化决策策略,达到降低患者死亡率的目标,但改进后的Dueling DQN算法在策略优化方面的效果会比DQN更加显著。

表2 模型死亡率
显然,本文提出的HDQ模型在降低患者死亡率方面比临床医师和无分层结构的模型更有优势。虽然其他算法也可以通过推荐药物剂量达到降低患者死亡率的目的,但通过HDQ模型学习的用药策略的死亡率是最低的,比DQN算法低4.5%,比没有层次结构的Dueling DQN结构低3.4%,相比于临床医生的死亡率降低了10.3%。
由此可见,HDQ模型在临床决策优化方面具有显著的优势,这也证明临床医师的决策还有较大的优化空间,无论是本文的分层模型,还是现有的非分层模型,都能实现临床医师策略的优化。
三、结论
针对社会中面临的长期决策优化问题,本文提出了一种基于多智能体强化学习的分层决策优化(HDQ)算法,以目标分解和层级合作的方式实现长周期顺序决策优化。在所提的HDQ算法模型中,具有层级关系的多智能体基于强化学习理论相互合作,上层智能体学习最佳的目标分解,下层智能体学习在子目标指导与约束下完成目标的行动策略,从而共同构建团队任务的最佳策略、实现决策优化。为了检验该模型的决策效率,本文提取MIMIC-IV数据集对脓毒症患者的临床诊疗决策问题进行了分析验证,发现该算法既能避免强化学习延迟奖励和复杂状态空间导致的策略次优性,还能模拟出不同等级医生之间的层级指导和合作行为,进而协同做出优于人类临床医师的治疗决策。
与传统的智能决策算法相比,HDQ算法具有明显的优越性,弥补了传统决策方法模型泛化能力较差、长周期连续决策效率低下的不足,适用于具有连续决策过程的策略优化问题。尽管如此,本文的决策方法在实际运用过程中仍可能存在一定局限性;这是由于该方法作为一种独立学习的方式,采用两个智能体交替学习和更新,下层智能体完成目标的行动策略将高度依赖于上层智能体对子目标分解的合理性。因此,未来可进一步探索消除上层智能体学习训练结果对模型性能产生负面影响的方法,并针对模糊环境下多层次、多目标的决策问题开展研究。
