稀疏奖励环境中的分层强化学习①
2022-08-24欧阳名三冯舒心
欧阳名三, 冯舒心
(安徽理工大学电气与信息工程学院,安徽 淮南 232001)
0 引 言
强化学习(Reinforcement learning,RL)是一种通过与环境进行交互试错,使积累奖励最大化的机器学习方法[1],作为人工智能的重点研究领域之一在各个领域取得了突出的成就。但强化学习应用在奖励稀疏分布的环境时[2],智能体会缺乏即时的奖励反馈导致学习缓慢甚至失败,分层强化学习(Hierarchical reinforcement learning,HRL)通过在多个时间抽象上学习动作选择策略来解决问题[3]。文献[4]提出一种分层DQN算法,给强化学习引入了分层框架,有效解决了稀疏奖励问题;文献[5]在基于子目标的分层基础上结合了事后经验回放方法,实现了多层并行学习;文献[6]通过K-means聚类方法形成子目标集。在基于子目标的分层强化学习框架上,结合启发式异常检测和密度峰值聚类算法,实现了子目标集的无监督发现,可以在奖励稀疏的环境里稳定学习。
1 分层强化学习基础知识
强化学习研究的问题都建立在马尔科夫决策过程(Markov decision processes,MDP)的基础上,MDP可表示为一个五元集合(S,A,P,R,γ),分别表示状态、动作、状态转移概率方程、奖励函数和折扣系数,其中P(s^′|s,a)表示智能体在状态s时执行动作a后达到状态s’的概率。与MDP不同的是,半马尔科夫决策过程(Semi-Markov decision process,SMDP)的状态转移概率是s和τ的联合概率P(s^′,τ|s,a),即从当前状态s到下一状态s’的步数为一个随机变量τ。分层强化学习正是是基于SMDP,将复杂的学习问题在时间抽象上分解为简单的子问题,通过分别解决子问题,最终完成复杂的学习任务[7]。常见的分层强化学习方法有基于选项、基于分层抽象机、端到端以及基于子目标的学习方法。
2 DPC-HRL算法介绍
2.1 分层学习框架
将学习任务分为了两个级别的时间抽象,分为上层控制器Q1和底层控制器Q2,控制器内部使用两个独立的网络进行学习:
(a)Q1将状态st作为输入,选择一个新的子目标;
(b)Q2将状态st和选定的子目标gt作为输入,进行动作的选择和策略的更新,直到完成子目标或完成整个学习任务。
如果子目标被完成,上层控制器就会根据策略选择新的子目标,重复上述过程直到整个任务结束。
如图1所示,智能体使用由上层控制器Q1和底层控制器Q2组成的两级分层结构。在时间t,Q1接收到环境的状态s=st,根据控制器自身的策略从子目标集合G中选择一个子目标。然后,Q2选择可以到达给定子目标g的动作。Q2的目标是使积累的内部奖励值最大化,如式(1):
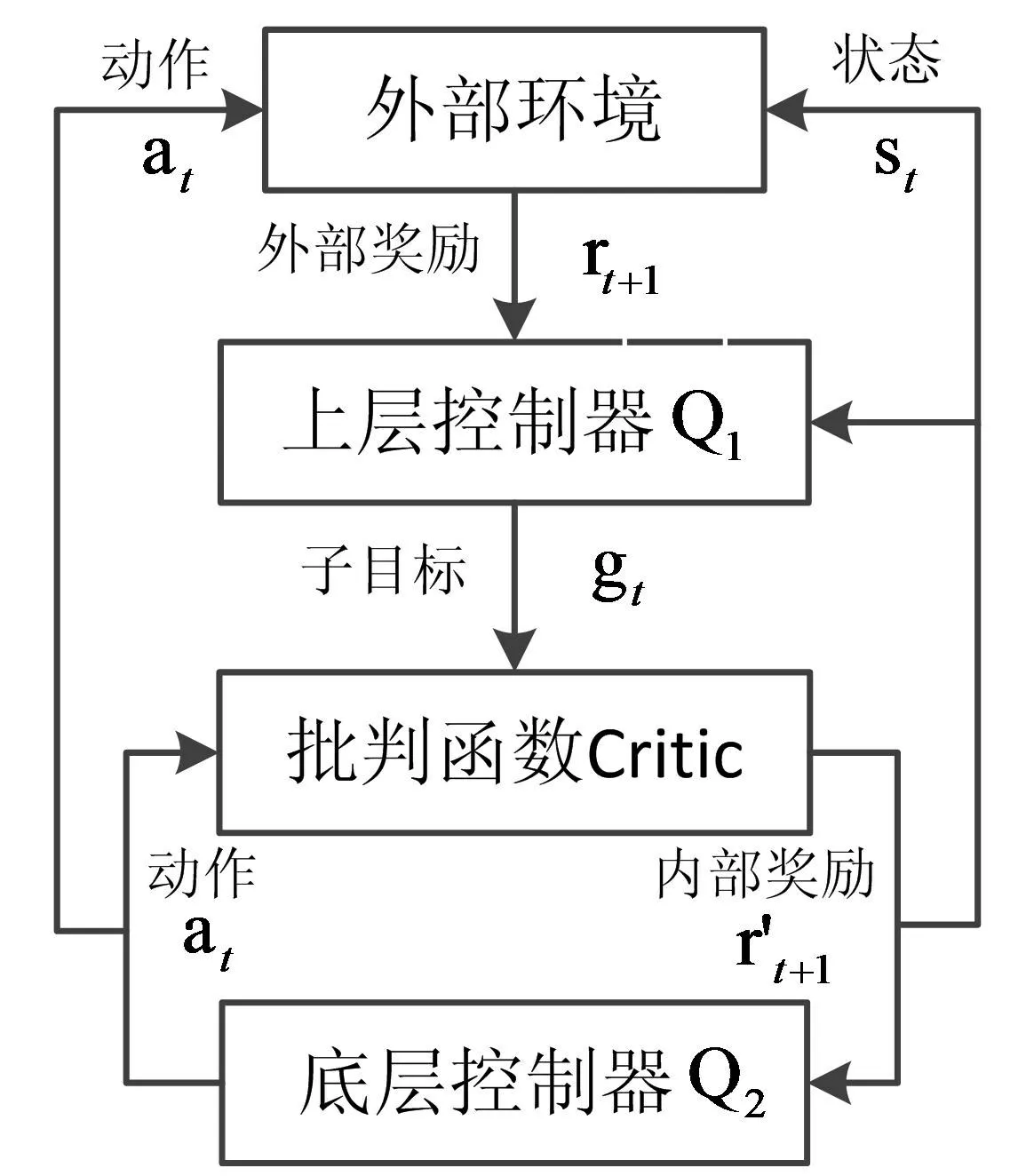
图1 分层学习框架
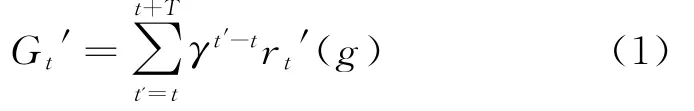
式(1)中T是到达子目标g的最大步长。同样,Q1的目标是使积累的外部奖励最大化,如式(2):

式(2)中τ是最后一步。用两个不同的值函数来学习上层控制器Q1和底层控制器Q2的策略。Q2估算以下Q值,如式(3):

式(3)中g是状态s是上层控制器给定的子目标,πag=P(a|s,g)是Q2到达g的策略。同样,上层控制器需要估算以下Q值,如式(4):
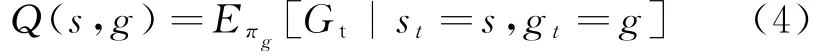
式(4)中πg是Q1选择子目标的策略。
在上层控制器Q1中,通过估计每个子目标的价值函数Q(s,g;ω)来更新策略,并选择估值最高的子目标。选择当前子目标后,底层控制器Q2以当前状态s和当前子目标g为输入,选择价值函数q(s,g,a;ω)估值最高的动作,而Q2内部的批判函数监视当前状态,将其与当前子目标进行比较,并在每个时间步长向Q2提供适当的内部奖励r’。每个过渡经验集合(s,r,a,r',s')都记录在Q2的经验记忆集D2中,以便于智能体学习。当达到子目标或达到最大时间步长时,Q1观察状态s t'=s t+T+1,并选择另一个子目标g'=g t+T+1,Q1的经验记忆集D1记录Q1的过渡经验集合(s,g,G,s t'),然后重复上述操作,直到任务结束。
值函数的参数根据最近的经验集合进行调整,为训练Q1的值函数逼近器,我们通过外部环境反馈的奖励值来最小化损失函数,如式(5)-(6):

其中y是Q1选择子目标g时的预期回报,γ是折扣系数,ω是Q1值函数逼近器参数,G是选择连续子目标之间的外部累计奖励。
底层控制器Q2通过经验记忆集D2学习值函数q(s,g,a;ω')来更新其策略π(a|s,g),并更新其值函数逼近器参数ω',以最小化损失函数,如式(7):

2.2 内在动机学习
内在动机学习是分层学习方法的核心思想,在某些延迟反馈稀疏的环境中,强化学习的智能体无法有效地探索状态空间,从而没有足够的经验集来学习如何使奖励最大化。在我们分层强化学习框架中的内部批判家可以向底层控制器Q2发送更多的常规奖励反馈,因为它是基于子目标而不是基于任务的最终目标。举例来说,当智能体到达当前子目标g和其他的状态转换时,会有+1的固有奖励。成功解决复杂的任务不仅取决于这种学习机制,还取决于如何确定一组子目标集以及上层控制器Q1学习如何从子目标集中为当前状态选择正确子目标的能力。
我们假设子目标g∈G由上层控制器Q1提供,底层控制器Q2接收状态s t和子目标g作为输入,输出动作a t。智能体会感知到下一个状态,并从批判函数那里收到一个内部的奖励信号r't+1,形式如式(8):

控制器的值函数逼近器用多层神经网络实现,如图2所示。底层控制器网络q(s,g,a;ω')将状态s和子目标g作为输入,状态s以笛卡尔坐标的形式输入进网络,坐标的两个维度都有单独的输入池,子目标g最初是从发现的子目标集中随机选择,这是智能体早期随机学习期间无监督发现子目标的结果。Q1值函数接收当前状态s的Onehot(一位有效)编码,该编码通过将当前状态转换为相应子目标的索引来计算,值函数输出的是最佳子目标的One-hot编码。底层控制器接收由子目标门控的当前状态变量(笛卡尔坐标)的高斯模糊表示,并使用Winners-take-all(赢者通吃)机制在隐藏层上产生稀疏联合编码,然后映射到值函数的动作输出上。值函数训练网络设置为16层,超参数迭代次数为100次,学习率为0.001。

图2 控制器值函数训练网络
2.3 子目标无监督发现
为上层控制器选择合适的子目标集是分层学习框架的关键,子目标的特点为处于一种有奖励的状态或者是过渡到更接近奖励状态的一组状态。路径导航环境里,钥匙和锁就是一种奖励状态,而房间之间的门道可以看做是过渡状态。基于智能体初期探索的经验集合应用启发式异常检测方法发现奖励异常值,即子目标集,并结合密度峰值方法实现子目标集的聚类。
启发式异常检测方法是一种半监督的识别检测方法,将正常的数据建立一个高斯概率模型,可以随着新数据加入调整模型以提高拟合度,在模型中会定义一个边界,落在边界外的数据点标记为异常。该无需异常数据进行训练,可应用在陌生或异常数据难以获取的环境中。
密度峰值聚类(Desity Peaks Clustering,DPC)算法是一种不基于密度的聚类算法,无需迭代即可完成数据的聚类。DPC算法的思想是:在数据集合中,聚类中心的局部密度较高,且高局部密度点之间的距离较远。局部密度ρi和高局部密度点距离δi的定义如式(9)-(11):
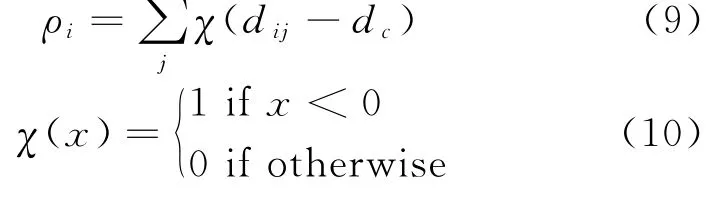
式(9),(10)中dc为截断距离,i的距离小于dc的数据的个数即为数据点i的局部密度。

在智能体进行探索的时期,启发式异常检测会建立高斯模型检测出环境的奖励状态和过渡状态,然后DPC算法根据数据点的局部密度和高局部密度点距离,绘制关系散点图,选取聚类中心并分配剩余数据点。
3 仿真实验与分析
选择一个带钥匙和锁的四房间环境进行路径导航模拟实验,该任务需要智能体先取得钥匙再到达锁,锁和钥匙会在每次任务开始时随机刷新位置,环境具有时空的层次结构和奖励稀疏延时反馈的特点,具体场景如图3所示。

图3 仿真实验环境
在每次任务开始时,智能体A会在任意房间的任意位置初始化,该智能体具有东南西北四个可移动的方向。将奖励值设置为到达钥匙时r=+10,携带钥匙到达锁时r=+40,撞到房间边界r=-2。在任务初期允许智能体探索100次的房间环境,每次任务在达到200的时间步长或者完成任务后结束。从两个方面分别对提出的DPC-HRL算法与Kmeans-HRL算 法、SARSA-RL算 法进行评价:一是任务的平均回报;二是任务的平均成功率。算法的参数设置为:学习率α=0.001,折扣系数γ=0.99,探索率□=0.2,最大步长为100000。仿真实验结果如图4和图5所示。

图4 任务的平均回报

图5 任务的平均成功率
从图4中可以看到,由于稀疏奖励问题,常规的RL算法会困在钥匙区域,尽管设置了较高的探索率,但智能体并没有动机去探索其他区域以到达锁的位置,所以只能得到钥匙的奖励回报,而DPC-HRL和Kmeans-HRL的分层学习结构都能在内部生成常规的奖励反馈可以得到最高的奖励回报。图5的任务平均成功率显示了DPC-HRL和Kmeans-HRL都能有效的解决稀疏奖励问题,完成路径导航的任务,且与Kmeans-HRL算法相比,提出的DPC-HRL算法可更快快收敛,但在初期的学习效率较低。
4 结 语
基于分层学习框架将控制器分为两层进行学习,控制器通过神经网络结构来训练价值函数,底层控制器可以有效接收到上层控制器的子目标和内部奖励,不会因奖励稀疏无法学习。启发式异常检测方法可以检测到环境中的奖励状态和过渡状态,结合密度峰值聚类算法,能快速完成子目标的无监督发现。仿真实验结果表明,该方法可以有效解决稀疏奖励问题,具有较高的稳定性和较快的收敛速度。尚未考虑到复杂任务的学习层数问题及异常值密集问题,今后将进一步研究改进。
