基于改进循环生成式对抗网络的图像去雾方法
2022-12-13黄山贾俊
黄山,贾俊
(四川大学 电气工程学院,成都 610065)
0 概述
受雾霾天气的影响,电子设备采集到的图像往往存在颜色偏移、对比度低、场景模糊等问题[1],这对图像特征相关的目标识别[2]、视频监控[3]、自动驾驶[4]等领域有着重要影响。因此,图像去雾技术具有广泛的研究意义和重要的社会意义[5]。
近年来,为提高带雾图像的质量,众多学者对图像去雾技术进行了研究与分析,提出了许多去雾方法,这些去雾方法根据原理的不同主要分为三类:第一类是基于图像增强的去雾方法,第二类是基于物理模型的去雾方法,第三类是基于深度学习的去雾方法[6]。基于图像增强的去雾方法主要通过增强图像中场景的对比度、亮度以及色彩饱和度,使得图像更加清晰[7],此类方法的典型算法有直方图均衡化[8]、Retinex 算法[9]、同态滤波[10]和小波变换[11]等。文献[12]通过HSV 颜色模型与自适应直方图均衡化算法提高图像的整体对比度,重构出无雾图像。文献[13]提出一种单幅图像去雾方法,以色彩恒常理论为基础,使用增强调整因子来增强图像中的颜色信息。基于物理模型的去雾方法主要通过数学模型来模拟雾图降质的过程,再将图像逐渐清晰化,此类方法包括暗通道先验算法以及基于偏微分方程的算法[14]。文献[15]提出的暗通道先验理论通过假设先验估计出模型的未知量,再逆向地复原出无雾图像,由于该算法无须利用辅助设备或者额外信息对模型进行约束,因此后续出现了大量文献[16-18]这类以暗通道先验作为基础的改进算法。文献[19]通过变分得到图像的偏微分方程,结合大气散射模型与梯度算子得到图像之间的关系,对图像进行局部修正,还原场景的分辨率与真实色彩。随着深度学习在计算机视觉研究中取得了较为明显的进展,不少学者开展了基于深度学习的去雾研究。文献[20]将门控上下文聚合网络用于图像去雾中,在不需要套用先验知识的情况下建立了GCANet 网络获取无雾图像。文献[21]对大气退化模型进行了全新的估计,利用卷积神经网络深层结构建立了DehazeNet模型用于图像去雾,取得了较好的效果。文献[22]设计了一种多合一除雾网络AOD-Net,通过卷积神经网络从单个带雾图像直接获取到无雾图像。文献[23]在神经网络中融入了注意力机制来提取图像中的特征信息,从而获取到拥有更多有用信息的目标图像。
目前的去雾算法虽然取得了一定的去雾效果,但是依然存在一些不足:基于图像增强的去雾算法能够对图像中的环境起到突出的作用,但是去雾时容易丢失图像的细节信息;基于物理模型的去雾算法考虑了雾化降低图像质量的根本因素,但是这类方法在去雾过程中加入的先验信息难以获取,算法复杂度较高;基于深度学习的去雾算法利用神经网络的学习能力,能够实现端到端去雾,但是深度学习模型大多需要成对数据集进行训练[24],并且算法恢复出的无雾图像存在不同程度的颜色失真与信息丢失。
针对上述问题,本文提出一种基于生成式对抗网络(Generative Adversarial Network,GAN)的去雾方法。首先采用循环一致性生成式对抗网络作为模型基础,在不需要成对数据集的情况下产生无雾图像;然后使用多尺度鉴别器对判别网络进行搭建,提高网络的判别能力和图像生成能力;最后通过最小二乘和循环感知损失,加强对网络模型的约束,提高图像质量。
1 基础知识
1.1 生成式对抗网络
文献[25]提出的生成式对抗网络是一种深度生成的神经网络模型,如图1 所示,其由生成器和判别器两个功能模块组成。生成器接收随机噪声z,从真实样本中获取数据分布映射到新的数据空间,尝试生成能够欺骗判别器的虚假样本G(x)[26]。判别器的输入包括两个部分,分别是生成器生成的数据G(x)和真实数据x,判别器需要尽可能去判别输入的样本是生成器生成的样本还是真实样本,若判别输入为真实样本,则输出1,反之则为0。生成器和判别器两者不断进行对抗和优化,直到生成器生成的样本能够以假乱真,判别器判别错误的概率达到最小。
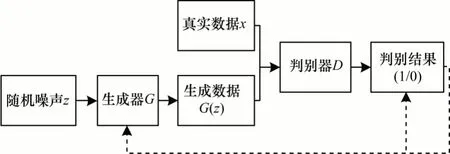
图1 生成式对抗网络结构Fig.1 Structure of generative adversarial network
GAN 的训练过程可以视为生成器和判别器互相博弈的过程,训练时会先固定生成器G,更新判别器D的参数,然后再固定判别器D,更新生成器G的参数,两个模型交替迭代,最终达到最优解。生成器和判别器之间存在的对抗关系表示如下:

在训练判别器时,为了最大程度降低判别模型D判别错误的概率,需要极大化判别模型:当判别器的输入为真实样本x时,希望D(x)能够趋近于1;当输入为虚假样本G(z)时,希望D(G(z))趋近于0,即1-D(G(z))趋近于1。而对于生成模型G则需要极小化,生成器的输入只有随机噪声z,此时希望D(G(z))能够趋近于1,即1-D(G(z))趋近于0,生成样本G(z)被判别器判别为真的概率值为1。只有当Pz=Pdata时,生成器学会真实样本Pdata的分布,判别器的准确率稳定为1/2,此时该模型得到全局最优解。
1.2 循环生成式对抗网络
文献[27]提出的循环生成式对抗网络(Cycleconsistent Adversarial Network,CycleGAN)是一种在GAN 基础上提出的无监督生成式对抗网络,通过对传统GAN 的镜像对称得到具有两个生成器和两个判别器的网络结构。得益于这种循环网络结构,CycleGAN 模型可以在不需要成对图像数据集的情况下,让两个域的图片相互转换,原理如图2 所示。其中:X和Y分别为原域X和目标域Y;G和F分别为进行X→Y映射的生成器与进行Y→X映射的生成器;DX和DY为对应的判别器。G将X域的图像转换为Y域的图像G(x),再由判别器DY判断图像为真或者假。同理,F将X域的图像转换为Y域的图像F(y),再由判别器DX判断图像为真或者假。

图2 CycleGAN 网络结构Fig.2 Network structure of CycleGAN
生成器G生成图像G(x),然后由判别器DY来判断G(x)是否为真实图像,这一过程就是一个标准的单向GAN 模型训练过程,故CycleGAN 的对抗损失函数与GAN 一致,G和DY的对抗损失函数表示如下:

同理,F和DX的对抗损失函数表示如下:

生成器G将图像x转换为G(x),再由F转换为F(G(x))后,为了尽可能地保证图像在经过两次网络之后还能保持一致,即试图使F(G(x))≈x以及G(F(y))≈y,需要计算原始图像与F(G(x))之间的损失。循环一致损失由原始图像与映射图像的L1范数计算得到,其函数表达式如下:

CycleGAN 的损失函数由以上三个部分组成,其总目标函数表示如下:

其中:LGAN为对抗损失;Lcyc为循环一致性损失;λ为循环一致性损失的权重系数。
2 本文方法
根据现有图像去雾方法和生成式对抗网络原理,结合CycleGAN 无需成对数据的特点,本文以CycleGAN 作为基础网络对模型进行改进,引入多尺度鉴别器并设计新的损失函数,解决现有图像去雾方法信息失真和去雾效果不自然等问题。
2.1 多尺度鉴别器
在生成式对抗网络中,判别器作为模型的重要网络结构,主要目标是判别出真实和虚假样本并提供反馈机制,优化生成器的性能[28]。在一般情况下,判别器将输入的图像进行分层卷积,不断地对图像进行压缩,然后获得与图像特征相对应的特征矢量,最后以一个概率值作为输出来判断图像的来源。这种传统单一的判别方法存在缺陷,即只能惩罚一定块规模的图像,然后对整张图像进行卷积,并且与生成网络配合,最后输出平均化的结果,无法反映出图像的整体结构。为更好地学习图像的局部与全局特征,本文利用多尺度鉴别器对真实图像与生成图像进行下采样,分别在多个尺度上对图像进行区分。多尺度鉴别器工作原理如图3 所示。

图3 多尺度鉴别器工作原理Fig.3 Working principle of multi-scale discriminator
本文所使用的多尺度鉴别器的网络结构如图4所示(彩色效果见《计算机工程》官网HTML 版),其由两个结构完全相同的判别器组成,判别器D1和判别器D2都包括了7 个卷积层,每个卷积层的卷积核尺寸均为3×3,全连接层为1 024,左上方的图像是由生成器产生的图像,无须对该图像进行任何处理,将其直接输入到第一个判别器D1中,随后再执行2 倍下采样操作,将缩小后的图像作为判别器D2的输入。在网络模型中引入多尺度鉴别器后,网络会将原来尺寸的图像和缩小两倍尺寸的图像分别输入到两个判别器中,这两个判别器具有不同大小的感受野,当输入的图像尺寸较小时,判别器拥有较大的感受野,会更加关注图像的结构,而当输入的图像尺寸较大时则会更加关注图像的细节信息。通过这种方式可以提高判别器对样本图像细节与整体的鉴别能力,监督引导生成器生成更加真实的图像。
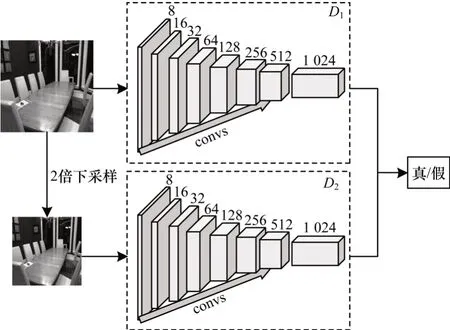
图4 多尺度鉴别器网络结构Fig.4 Network structure of multi-scale discriminator
2.2 改进的复合损失函数
2.2.1 对抗损失
原始CycleGAN 采用Sigmoid 交叉熵损失函数作为对抗损失,这就导致了无论生成器生成的图像质量如何,判别器对生成器产生的图像都只进行一次判别,无法保证除雾后图像的质量。因此,本文将原本的Sigmoid 交叉熵损失改进为最小二乘损失。以最小二乘作为对抗损失函数时,判别器在对图像进行判别之后,会将图像再次放回到决策边界[29],从而提高无雾图像的质量。生成器G与判别器DY的损失函数如下:

生成器F与判别器DX的损失函数如下:

2.2.2 循环感知损失
虽然CycleGAN 在执行图像转换任务的过程中,通过使用循环一致性损失对输入图像与循环重建的图像进行约束,除去了图像的一部分噪声,但是仍然存在部分残留,无法完全还原图像的细节信息,而VGG 网络有着较深的网络结构,相比一般鉴别器可以提取更加丰富的细节与高级特征,其视觉表现更好。因此,本文引入循环感知损失来确保图像之间的结构相似性,进一步提升生成图像的质量。循环感知损失函数表达式如下:

其中:x和y分别为带雾图像和无雾图像;φ()为特征提取器函数;||||2为L2范数。
经过上述改进之后,最终的复合损失函数如下:

其中:LGAN为改进后的对抗损失;Lcyc为循环一致性损失;Lperceptual为循环感知损失;λ1为循环一致性损失的权重系数;λ2为循环感知损失的权重系数。
3 实验结果与分析
3.1 实验数据集
本文选用D-HAZY 数据集[30]与SOTS 数据集[31]作为实验合成数据集,两者都是常用于图像去雾领域的公开数据集,其中D-HAZY 数据集作为训练集,SOTS 数据集作为测试集。为使实验数据符合本文网络训练图像的要求,首先将所有图像调整为256×256像素,然后将训练集数据分为A组与B 组,A 组中存放有雾图像,B 组中存放无雾图像。
3.2 实验设置
实验环境配置:CPU 为Intel®Celeron®N2940 @1.83 GHz,内存为16 GB,GPU 为Nvidia GeForce RTX 2080 Ti。本文深度学习的框架为Pytorch 1.10.0,解释器为Python 3.8,Cuda 版本为11.3。
实验流程参数设置如下:学习速率初始化为2×10-3;采用小批量的方式训练模型batch-size 为1;迭代次数为200 次;num_workers 为4;不对原始网络权重系数λ1进行修改,故λ1为10;权重系数λ2根据经验设置为0.5,并且在每个epoch 开始时对数据进行重新打乱。
3.3 实验结果
为验证本文方法的有效性,使用基于图像增强的Fan 算法、经典的DCP 算法,以及基于深度学习的GCANet、DehazeNet 与AOD-Net 作为对比算法,在SOTS 数据集上进行去雾效果比较,从主观评价和客观评价两个角度对实验结果进行分析。
3.3.1 主观评价
不同算法的去雾结果对比如图5 所示(彩色效果见《计算机工程》官网HTML 版),从中可以看出:经Fan算法去雾后的图像颜色发生严重偏移,纹理以及边缘信息存在大量丢失,整体去雾效果最差;基于物理模型去雾的DCP 算法效果优于Fan 算法,但是由于该算法过于依赖颜色信息,容易出现图像整体清晰度低而局部色彩饱和度偏高的情况;GCANet算法去雾能力不足,去雾后的图像出现了颜色异常;与DehazeNet算法相比,显然AOD-Net 算法去雾后的图像视觉效果更好,但是也存在部分雾气残留以及细节丢失等不足;与前面4 种方法相比,本文算法得到的去雾图像具有更明亮的颜色和更清晰的边缘与细节信息,与原始无雾图像最为接近。

图5 不同算法的去雾结果Fig.5 Defogging results of different algorithms
3.3.2 客观评价
通常来说,人眼的视觉特性会导致人眼对不同图像同一区域的感知结果易受邻近图像的影响,不同个体评价图像时也会受到个体主观意识的影响,因此,评价图像质量不能仅靠主观评估,对图像质量进行量化尤为重要。本文采用峰值信噪比(Peak Signal to Noise Ratio,PSNR)[32]和结构相似性指数(Structure Similarity Index,SSIM)[33]作为结果图像的评估指标。
PSNR 用于对图像像素点间的误差进行衡量,计算公式如式(10)所示,其中MMSE为图像之间的均方误差,MMAX1为图像最大像素值。PSNR 值越大,图像受噪声影响越小,图像质量越好。

SSIM 用于对图像之间的相似度进行度量,计算公式如式(11)所示,其中L为图像的亮度比较,C为图像的对比度比较,S为图像的结构比较。SSIM 值越大,代表图像保留了越多细节信息。

不同算法去雾后的PSNR 与SSIM 平均值如表1所示。从中可以看出:Fan 算法与GCANet 的PSNR和SSIM 值都较低;DCP 算法的PSNR 与SSIM值略高于DehazeNet 算法,具有更好的图像重建能力;AOD-Net 算法的PSNR 值虽然高于其他算法,但是SSIM 值反而降低了;相比之下,经过本文算法去雾后的图像SSIM 和PSNR 值都高于对比算法,其中PSNR 值与对比算法中的最佳值相比提高了7.1%,SSIM 值提高了4.3%。由此可见,本文算法能够更好地保留图像的场景结构和细节信息,结果图像与原始无雾图像的像素级差异更小,能够获得更好的去雾效果。

表1 不同算法的客观指标Table 1 Objective index of different algorithms
3.4 消融实验
为进一步证明本文算法引入的多尺度鉴别器和复合损失函数的有效性,本文对算法进行剥离,增加了有无改进部分的对比实验。实验的对比模型主要包括原始循环生成式对抗网络模型Model-1、仅增加多尺度鉴别器的网络模型Model-2 以及仅采用改进复合损失函数的网络模型Model-3,并分别对拆解的模型进行测试。
图6 为消融实验结果(彩色效果见《计算机工程》官网HTML 版)。从中可以看出:不进行任何修改的原始CycleGAN 网络能够在一定程度上去除雾霾,但是将去雾后的图像与原始无雾图像相比较后不难发现:原始CycleGAN 网络处理后的图像颜色发生了扭曲,细节恢复能力不足,亮度过渡区域也较为生硬,去雾效果不自然;引入多尺度鉴别器的网络模型与采用改进复合损失函数的模型生成的图像均比原始网络更好,生成的图像更加接近原始无雾图像,视觉上更加自然。

图6 消融实验结果Fig.6 Results of ablation experiment
上述各个模型去雾后的图像质量指标如表2所示,可以直观地从表中看出,经改进部分的模型去雾后图像的PSNR 值和SSIM 值均比未改进的原始模型高,其中,Model-2 的PSNR值比Model-1 提高 了18.8%,Model-3 的SSIM值比Model-1 提高了9.1%。

表2 消融实验结果的客观指标Table 2 Objective index of ablation experimental results
多尺度鉴别器能够通过不同大小的感受野获取到更多的图像特征信息,加上判别器和生成器相互配合,在提高判别网络能力的同时也会优化生成网络,从图6 和表2 可以看出,与原始网络相比,引入多尺度鉴别器的网络模型生成的图像无论是视觉感观还是客观指标均优于原始网络,能够更好地保留图像的细节信息,改善亮度转换区域过渡不自然的问题,生成的图像更加贴近原始无雾图像。改进的复合损失函数能够利用多个隐藏层作为特征提取器来提取特征,并且按照样本和决策边界的距离对样本图像做出惩罚,从而提高图像的质量,从实验结果中可以看出,采用改进复合损失函数的网络恢复后的图像信息丢失更少,能够较好地改善图像细节信息缺失和颜色失真的问题,去雾效果比原始网络更好。由此可见,本文对于CycleGAN 的改进能够促进网络优化,对图像去雾起到有利的作用。
4 结束语
本文设计一种基于改进CycleGAN 的图像去雾方法。以CycleGAN 作为基础网络模型,采用多尺度鉴别器代替单个鉴别器提高生成图像的质量,使得生成的图像更接近真实无雾图像,同时引入最小二乘和循环感知损失对映射空间进行约束,改善去雾图像颜色扭曲和细节丢失等问题。实验结果表明,相比传统去雾方法,本文方法在图像去雾方面效果更优,并且具有更好的视觉效果。后续将对模型做进一步优化,提高其在低照度情况下的去雾性能。
