一种基于分段式路由查找的布隆过滤方案*
2022-12-12乔庐峰陈庆华邹仕祥
张 镱,丁 帅,乔庐峰,陈庆华,刘 熹,邹仕祥
(中国人民解放军陆军工程大学,江苏 南京 210001)
0 引言
下一代路由器应支持数以千万计的数据包的线速转发,并提供快速实时更新,以适应不断增长的路由表,这使得基于网际互连协议(Internet Protocol,IP)的路由查找任务面临巨大的挑战[1]。当前,IP 地址分配广泛采用无类域间路由(Classless Inter-Domain Routing,CIDR)技术。基于CIDR 提出的最长前缀匹配(Longest Prefix Matching,LPM)算法多采用Trie 树形数据结构。然而随着查找深度加大,经典Trie 树形结构的查找效率会大幅降低,因为这种一次一位的检索机制在最坏情况下需要进行的次数等于地址长度的存储访问。
为了解决上述问题,一系列基于多位Trie(Multibit Trie)的路由查找算法被提出[2-4]。这些算法的基本思想是通过构造步幅不固定的前缀子树,将路由查找分段式并行进行,检索位数由一次一位提高到一次多位,以减少存储访问次数,实现更高的查找速度。然而,这类方案的缺点在于,需要为每个阶段的访问设置一块独立内存且占用大量计算资源,这在某些资源功耗受限的场景下是很难适用的。一般来说,使用共享内存的查找方法可以避免过高的存储需求,但是查找操作只能顺序执行。此类查找方案多采用优先级搜索,当高优先阶段无匹配项时,则顺序查找次优先级的阶段。因此,不必要的查找阶段将导致算法整体耗时较长。针对类似的问题,在文献[5]中,作者利用布隆过滤的方法,在基于Hash 的路由查找方案中进行了设计验证。
本文提出了一种基于分段式路由查找的布隆过滤方案,面向资源功耗受限的星间网络,尽可能减少查找次数,提高转发速率,节省星上计算资源。该方案借鉴地面路由器架构,将布隆过滤器引入到基于多位Trie 的分段式路由查找中,通过减少对外部存储访问次数来提高查找性能。该方案在满足星上资源功耗要求的同时减少了无效查找,提高了查找命中率。此外,本文方案还将布隆过滤器位数组中的每一位与一个计数器相关联,以支持路由的实时更新。
1 布隆过滤器
布隆过滤器是一种节省空间的数据结构,用于确定集合中是否存在某些元素。它由Bloom 于1970年提出[6],是目前执行近似成员资格查询的最流行的架构之一,广泛用于加速计算和网络应用,如DNA 测序[7]、缓存[8]和网络安全[9]等。
布隆过滤器本质上是一个m位数组,用于存储集合中元素的成员信息并回答成员资格查询。初始时每个位被设置为“0”,使用k个hash 函数h1(x),h2(x),…,hk(x),在其上插入元素或检查其中的元素。为了插入元素x,将由h1(x),h2(x),…,hk(x)寻址得到的位设置为“1”。与插入相反,为了检查元素是否存在于集合中,将读取这些位置上的比特信息,并且当且仅当所有位反馈都为“1”时,才会认为该元素具有一定概率属于该集合,即成员资格查询结果返回true。
标准布隆过滤器结构如图1 所示,在过滤器上插入元素x和y,检查元素x,y,z的成员资格。
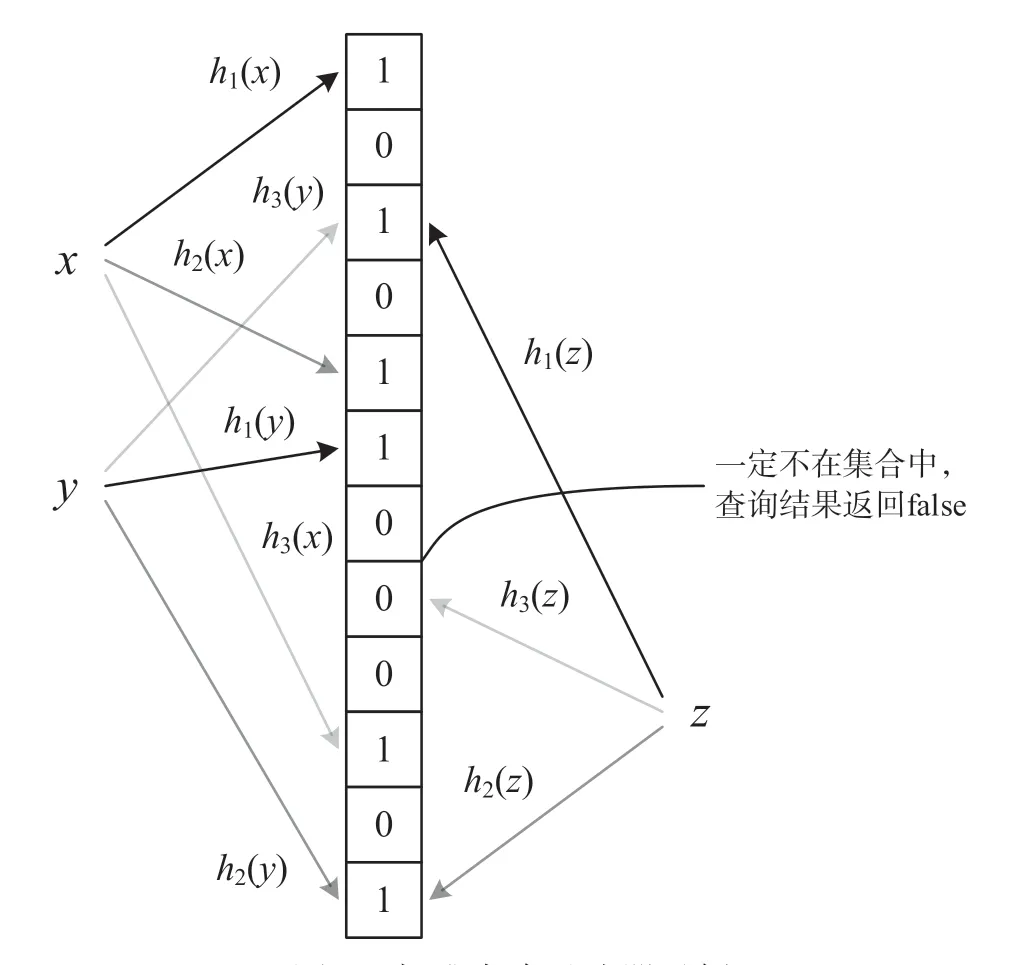
图1 标准布隆过滤器示例
对于已插入的元素,成员资格查询结果将始终返回true,即布隆过滤器没有假阴性。相反,当检查未插入的元素时,过滤器在绝大多数情况下查询结果会返回false,但也有一定概率会返回true,即出现了假阳性。对于未存储在过滤器中的元素,其hash 索引对应的k个位置上因其他元素的插入而被设置为“1”时,就会发生假阳性的情况。检查时产生这种假阳性误报的概率可近似认为是pk,其中p是m位数组中一个比特位被设置为“1”的概率,它是插入元素数量的函数。当过滤器中插入n个元素时,p可以具体表示为:
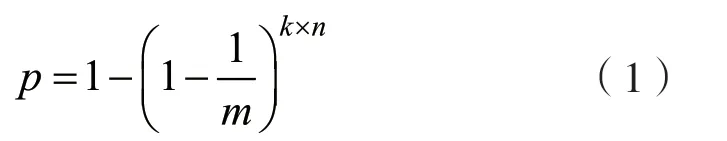
因此,假阳性误报概率f为:

若m足够大,式(2)可进一步简化为:

对于给定的过滤器大小m和插入的元素数量n,为使误报率f达到最小,k的最优值为:

此时误报率f为:

除了存在假阳性概率,标准布隆过滤器的另一主要缺点在于不支持元素的删除。由于给定位置的比特指示位可能已被多个元素设置为“1”,移除单一元素时将其清零可能会导致误报,因此无法删除元素。
2 可删除计数式布隆过滤器
一般来说,标准布隆过滤器在所要表达的集合是静态的情况下,可以达到理想的效果。相反,当所要表达的集合变动频繁,其不支持删除的弊端就会显现出来。通常来说,网络前缀的修改、插入和删除,甚至子网可用性配置的更改,都会引起大量的路由更新。对于基于布隆过滤器的路由查找方案而言,如果在路由变动时,不相应地更新布隆过滤器,势必会造成大量误报,从而影响查找匹配结果,这在路由查找中是不能接受的。
为了解决上述问题,本文提出将路由查找中使用的标准布隆过滤器扩展为可删除计数式布隆过滤器(Deletable Counting Bloom Filter,DCBF)。具体而言,将标准布隆过滤器位数组的每一位对应一个计数器以支持删除操作,计数器仅用于插入和删除,而不用于查找。图2 为插入元素A,B,C 的可删除计数式布隆过滤器示例。

图2 可删除计数式布隆过滤器示例
添加成员资格时,需要对位数组及计数器进行修改,过滤器通过算法1 中所示的过程添加新项。

成员资格查询过程与标准布隆过滤器相同,如算法2 所示。

算法3 描述了计数式布隆过滤器的删除过程。删除成员资格时,检查给定元素hash 索引对应的计数值并减1,当且仅当计数值减为0 时,将对应的位数组值置零。

3 过滤单元的设计与实现
3.1 分段式路由查找算法
常规的分段式路由查找算法在数据结构的设计上,都尽可能避免将流行的前缀长度设为段首来节省存储,因而原则上没有固定的分段方法。
以国际协议版本4(Internet Protocol Version 4,IPv4)地址为例,从俄勒冈大学Route Views 项目[10]给出的路由表地址分析报告中可以看出,路由表地址的前缀长度分布在8 到32 之间,并且绝大多数的前缀长度集中在16 至24。图3 根据报告提供的数据给出了IPv4 前缀长度的分布情况,从中可以看出IPv4 前缀长度分布的不均匀性。
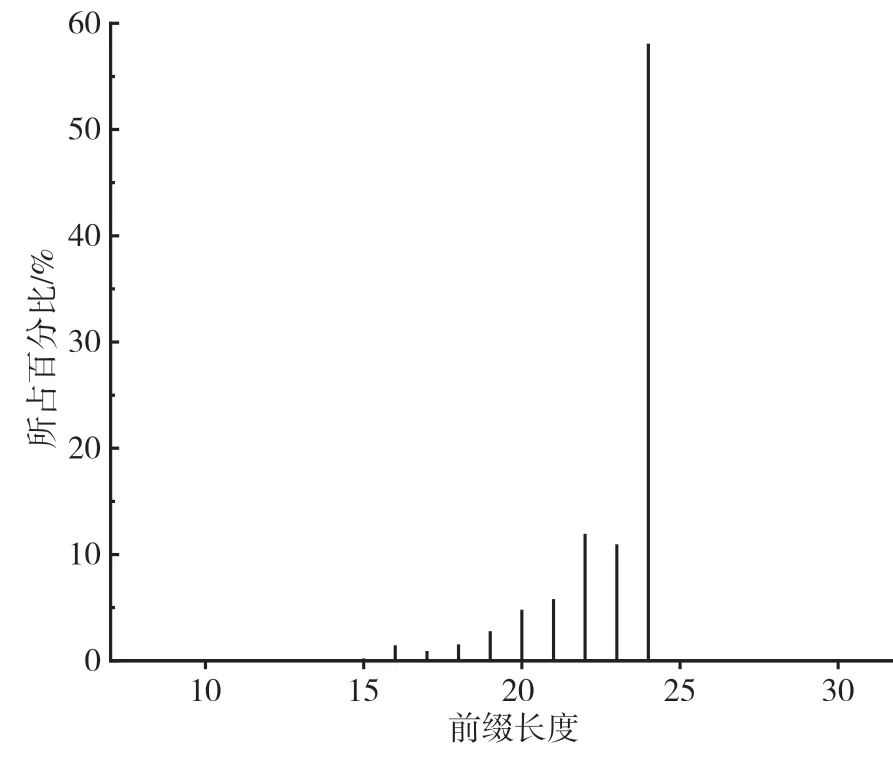
图3 IPv4 前缀分布情况
基于这种不均匀分布特性,本文设计的路由查找算法将32 位IPv4 地址划分为4 段。具体分段方案为:第1 阶段包含长度为1 到8 的前缀信息;第2 阶段包含长度为9 到16 的前缀信息;第3 阶段包含长度为17 到24 的前缀信息;第4 阶段包含长度为25 到32 的前缀信息。每一阶段基于Trie 树算法生成完整的路由前缀位图,并配置1 个维护前缀子树的过滤器,所以在本文方案中共采用了4 个改进型布隆过滤器。
路由的查找过程主要依据布隆过滤器组、位图信息表和转发信息表来完成转发操作。转发路由查找过程的流程如图4 所示,查找的具体流程如下文所述。

图4 转发路由查找流程
首先,将待匹配的IP 地址分段并行输入布隆过滤器,执行成员资格查询操作。若对应于每个阶段的布隆过滤器均返回false,说明该地址在路由转发表中无匹配项,直接以缺省路由进行转发;反之,则根据过滤单元返回结果进行优先级编码。
其次,依据最长前缀匹配的原则,检查最高优先级阶段对应的路由前缀位图,并根据输入地址遍历前缀位图。若当前位图存在匹配前缀,则输出该前缀子树对应的基地址和相应的转发表寻址信息;若当前位图匹配失败,则顺序查找前级命中的次优先级阶段;若全部阶段无位图匹配,待匹配IP 地址将以默认端口输出。
最后,根据位图寻址信息查找路由转发表,提取下一跳地址并输出。整个查找架构如图5 所示。

图5 引入布隆过滤器的分段式路由查找架构
3.2 过滤单元的参数设计
在上一小节中,本文提出为分段式路由查找的每一阶段配置一个本地计数式布隆过滤器,来维护该级别生成的子树。对于过滤单元而言,计数器的内存分配如何做到合理且适用是至关重要的。根据第2 节的描述,已经计算得到了布隆过滤器误报率的相关公式,现在在此基础上展开如下推导。
首先,计数器i被增加j次的概率为:

式中:ci为计数器i的计数值;n为插入元素数量;k为hash 函数数目;m为计数器个数,即对应原先位数组的大小。
因此,计数器的值大于或等于j的概率可以限定为:
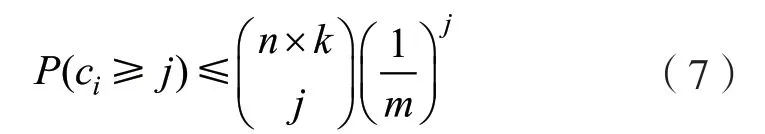
依据Stirling 公式,则可进一步得到:

最后,根据hash 函数数目的最优值公式(4),假设k小于kopt,就可以得到如下结论:
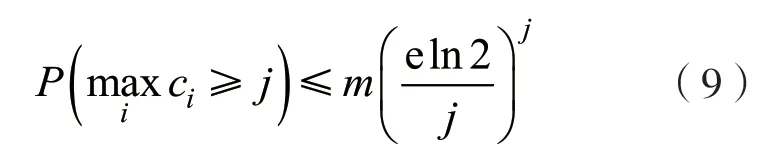
在实际运用中,对于hash 函数数目k,通常选择一个低于最优值的整数值来减少计算开销;对于最大计数值j,取4,8,16 等对应计数位数的整数值代入式(9)得到以下示例值:
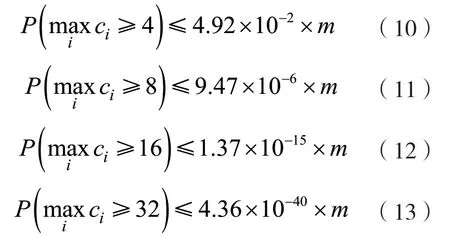
具体而言,如果为每个计数器分配3 位,则当计数值达到8 时就会溢出,其概率如式(11)所示,此时溢出概率很小;同理,如果每个计数器允许分配4 位,则实际值溢出(即计数值达到16)的概率如式(12)所示,这个数值已经足够小,能够满足绝大部分应用需求。
综上所述,并结合路由前缀的不均匀分布特性,过滤单元的具体参数设置如表1 所示,其中前缀子树的相关数据基于路由表地址分析报告[10]给出。

表1 过滤单元参数设置
4 仿真分析
本文使用Vivado2019.2 和Modelsim10.6d 软件对过滤单元进行设计实现与仿真测试,FPGA 芯片选择Xilinx 的Virtex-7 xc7vx690tffg。图6、图7 和图8 给出了过滤单元关键算法的仿真波形。
添加前缀子树的成员资格时,过滤单元对子树索引的读取和相应计数器操作的过程如图6 所示。其中1 处上半部分表示完成对第1 阶段子树索引128.0.0.0(32’h8000000)寻址的位数组值的写入,下半部分对应其计数值的变化。图6 中其余2、3、4 处同理。

图6 DCBF 插入算法仿真结果
在完成对4 个阶段子树索引128.0.0.0、128.128.0.0、128.128.128.0 和128.128.128.128 的添加之后,对4 组IP 地址128.0.0.0、128.128.0.0、128.128.128.0 和128.128.128.128 进行测试,结果分别如图7 中5、6、7、8 处所示。以匹配第1 阶段和第2 阶段子树索引的IP 地址128.128.0.0(32’h80800000)为例,其过滤结果为0011,即输出的4 位结果由高到低与命中的4 个阶段一一对应。

图7 DCBF 查询算法仿真结果1
过滤单元收到删除请求后读取待删除的子树索引,删除第1 阶段子树索引128.0.0.0 和第3 阶段子树索引128.128.128.0 的成员资格,如图8 中9 和10 处所示。索引删除完成之后,重复上述4 组IP地址的资格查询操作,结果分别如图9 中11、12、13、14 处所示。

图8 DCBF 删除算法仿真结果

图9 DCBF 查询算法仿真结果2
5 结语
本文针对资源功耗受限的卫星网络应用场景,给出了一种能够在较少资源消耗下提高分段式路由查找速率的解决方案。该方案通过布隆过滤算法来缩小查找阶段范围,减少路由查找过程中外部存储的访问次数。同时,将标准布隆过滤器扩展为可删除计数式布隆过滤器,用于支持路由的实时更新。理论分析和仿真结果都表明,该方案具有有效性。
