基于改进YOLOv5 的工程着装检测算法
2022-12-12李敏芳
李敏芳
(昆明理工大学信息工程与自动化学院)
检测建筑工地上作业人员是否按要求佩戴安全帽、穿反光衣,是保障作业人员安全的重要事项之一。 2000年,国家发布了《劳动防护用品配备标准》,2017年发布了《安全生产标准“十三五”发展规划》,针对不同行业制定了防护安全标准。但这些强制标准不能保证作业人员落实安全着装,因此很多作业现场就不得不以人工监督这种原始的方式加以督促。
随着计算机视觉技术的发展,设计以目标检测算法[1]为核心的智能监管系统,可以克服人工监督效率低下和成本过高的问题。 目标检测技术是指在获得图片时自动检测图片上物体的位置和类别,可分为3个步骤:首先,对需要检测的区域进行定位;然后提取目标特征;最后将特征传给算法分类器,例如Adaboost[2]、支持向量机[3]及随机森林[4]等,对目标类别进行判断。 2012年之前,主要是利用传统目标检测方法进行这类实验和应用;之后,目标检测引入了深度学习的思想来优化传统算法,但是当前针对工程安全着装的算法基本都是在网络结构复杂的二阶算法模型上实现的, 即以牺牲一定的检测速度来提高精确度, 而且并未就图像中的小目标物体进行处理,导致一定的漏检和误检。 传统目标检测方法存在计算效率低下和准确率低的问题。
随着卷积神经网络的不断发展,目标检测技术在图片提取特征方面有了明显提高。 很多学者在神经网络的基础上提出诸如R-CNN、Fast RCNN、Faster R-CNN[5]等优秀的目标检测方法。 在工程安全方面,2017年中南大学的毕林采用深度卷积神经网络(CNN)在Caffe框架下对矿山环境中工人安全帽的佩戴情况进行检测, 在500轮训练后取得了约79%的检测精度;文献[6]用目标检测算法Faster R-CNN对安全帽佩戴情况进行检测,取得了约84%的平均精度,但网络深度大的二阶算法会导致训练速度较慢,在工程安全对于时效性非常看重的情况下,就把目光转向了基于回归的一阶算法 (如SDD、YOLO系列等) 模型。YOLOv1[7]是YOLO系列的第1个版本,把目标检测问题转换成了回归问题,也就是让它直接回归到物 体 的 类 别 概 率 和 位 置 坐 标 值。 YOLOv2[8]在YOLOv1 的基础上引入了Anchor 机制和Batch Normalization,并且使用Darknet-19替代原来的网络 结 构。 2018 年,Redmon 提 出 了YOLOv3,用Darknet-53替代了Darknet-19, 由此YOLOv3可以实现多尺度检测,并且利用逻辑回归方法替代了YOLOv2的Softmax来实现分类。 2019年,施辉采用图像金字塔(Image Pyramid),通过提取多种尺度的特征图,结合YOLOv3进行安全帽佩戴的检测。YOLOv4[9]保留了YOLOv3的头部部分,将主干网络换成了CSPDarknet-53 (Darknet-53和CSPNet的结合体),并且使用空间金字塔池化(SPP)[10]增加感受野,在YOLOv3的FPN[11]的基础上对PAN[12]使用张量连接, 以此为颈部作为参数聚合的方法。2020 年6 月10 日YOLOv5 发 布,YOLOv5 模 型 比YOLOv4小近90%,但在整体计算速度上提高了很多, 同时检测精确度却没有YOLOv4 的高,YOLOv5由输入端、主干网络、颈部和检测端4部分组成。 YOLOv5的主干网络主要由Focus结构和CSP结构组成,Focus结构是在YOLOv5中新增加的一个操作,重点是切片。 颈部位于主干网络和预测之间, 使用FPN-PAN结构、CSP2结构和PAN来聚合特征,增加特征的融合能力。
工程安全着装检测面临的挑战[13]主要是:安全帽这类小目标在图片中占比过小, 特征不明显; 卷积神经网络的多次下采样导致安全帽等小目标特征丢失问题。 在针对目标检测的小目标识别上,可以简略地考虑分为Anchor-based的改进以及Anchor-free的改进。 YOLOv5是一个Anchor-based模型,并且YOLOv5含有多层卷积神经网络, 因此就YOLOv5 的模型特征考虑:在Anchor机制上进行优化; 在整个网络结构上优化。 笔者先利用遗传算法对Anchor机制优化锚框,克服自适应Anchor机制过于依赖初始聚类中心的问题; 然后在网络结构里嵌入轻量级的注意力机制模块ECAnet[14],以提高整体模型提取重要信息特征的能力以及对安全帽等小目标的检测能力。
1 模型改进策略
Anchor机制能够产生大量密集锚框, 可以通过设计更符合安全帽等小目标、尺度和长宽比不同的锚框来覆盖尽可能多的有效感受野,在此基础上, 网络可以进行目标分类和预测框坐标回归, 并且密集锚框对网络的召回能力有一定提高,这对目标识别有很大的优势。
YOLOv5原来使用自适应锚框计算, 模型受初始设定的影响, 不一定适用于现在的数据集,因此引入遗传算法优化锚框。 YOLOv5是一个提取多尺度特征图的模型,会提取出不同深度的特征图。 对于不同深度的特征图,深层特征具有更多的语义信息和抽象信息,浅层特征保留了更多的空间信息。 因此,深层特征图缺乏目标的细粒度信息, 而浅层特征图会有语义信息不足的问题。 笔者引入ECAnet模块来高效融合不同层次的特征信息, 不仅增加浅层特征图的语义信息,也增加了深层特征图的细颗粒信息,也即总体增强了安全帽等小目标细节特征的同时保留了它们的边缘信息, 提高了整体网络的特征提取能力。改进后的YOLOv5结构如图1所示。

图1 改进后的YOLOv5模型结构
1.1 基于遗传算法对自适应锚框的优化
Anchor机制最初是在Faster R-CNN 中提出的,目标是处理图像尺寸和长宽比的大规模变化问题,规划规范的预测框型号以减少冗杂的计算量。
YOLOv5模型中是自适应锚框算法, 加入遗传算法进行优化,利用预设锚框对预测框计算宽长比, 取宽长比最小值和9个锚框中最大的比例值, 原本的k-means算法是利用欧式距离作为度量, 本研究采用交并比(Intersection over Union,IoU)替代欧式距离计算聚类。 遗传算法的流程如图2所示,将最大可能召回率(best possible recall)作为指标, 首先利用默认的锚框计算出宽高,并对比真实框的宽高差距计算交并比,利用k-means算法不断更新锚框大小, 最终得到最佳的9个锚框值;然后计算最大可能召回率,如果最大可能召回率大于0.98就直接输出, 如果小于0.98则进入遗传算法。
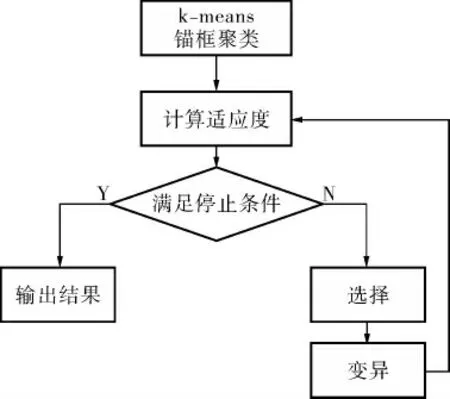
图2 遗传算法流程
遗传算法主要是对参数的编码进行操作,不影响参数本身,从族群出发,不是只关注在特定点上,因此可以防止过程收敛在局部最优,它的规则是由概率决定,而非一个确定的答案。 本研究选择遗传算法的过程只经过了选择和变异的过程。 具体操作过程:首先对根据聚类选出来的n个点进行随机突变,利用适应度函数(mAP@.5和mAP@.5:.95的比例为1∶9) 选出突变后最佳的锚框值,计算最大可能召回率,如果大于0.98则直接输出,如果小于0.98就进入下一次迭代。
1.2 基于注意力机制优化网络结构
为了让模型获得关于需要注意的目标的更详细的信息,并抑制来自不同通道的其他无用信息,考虑利用注意力机制。 在之前的注意力机制的研究中,大多现有方法都致力于开发更复杂的注意力模块,以获得更好的性能,这不可避免地增加了模型的复杂性。 为了能够保留YOLOv5轻量级的优势,本研究引入一个高效信道注意ECA模块(ECAnet),该模块只涉及少量参数,同时带来明显的性能增益。
ECAnet是 在SEnet[15]的 基础 上 进行 优 化 后 的版本。 SEnet是注意力机制的经典算法,在给定输入特征之后,SEnet为每个通道采用全局平均池化(GAP),之后利用非线性的全连接层(FC)和Sigmoid函数来获取通道的权重。 其中,全连接层是为了获得非线性的跨通道交互,与降维和控制复杂度有关。 研究发现,降维会对预测带来负面影响, 并且对通道间的关系也没有较明显的作用,因此不同于SEnet,ECAnet去掉了SEnet中使用的两个为了获取跨通道权值、降维的FC层。如图3所示,ECAnet在不降低维度的情况下进行了全局平均池化, 利用当前通道和它的k个相邻通道来进行本地跨通道交互。 具体操作:特征图输入在进入全局平均池化的聚合特性后,ECAnet用一维卷积替代SEnet中的FC层快速生成通道权值,其中k为卷积核大小,作为参数进行通道间的交互。
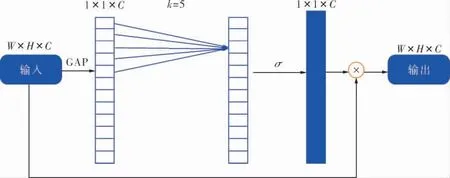
图3 ECAnet模块结构
ECAnet使用一个矩阵Wk来学习通道注意力,Wk的计算式为:

可以看出Wk涉及k×c个参数。
权值ωi的计算式为:
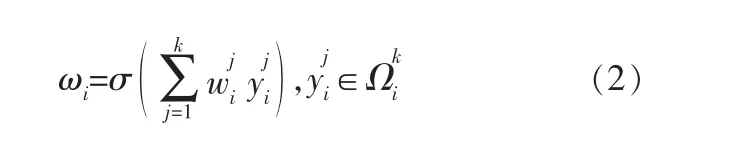
其中,yi的权值只考虑yi和它的k个邻居通道直接的交互;σ为Sigmoid函数;Ω为y的集合。
假设所有通道共享相同的学习参数,那么就简化了式(2),得到:

上述过程可以简略地利用一个大小为k的卷积核一维卷积实现:

其中,C1D是一维卷积。
式(4)由ECAnet调用,它只涉及k个参数。k值可通过通道维度量C的函数自适应地确定, 计算式为:

其中,|·|odd指选择最近的奇数;γ的值取2,b取1。
卷积神经网络对小目标特征提取过程中的特征不断降维缩小会导致小目标的信息损失,选择在卷积网络这边嵌入ECAnet以增强小目标信息,通过网络结构“Conv+BN+ECAnet+LeakyRe-LU”在网络学习中捕获不同通道的权重参数,更多地保留小目标的细节信息,强化重要信息并抑制非重要信息。 具体结构如图4所示。
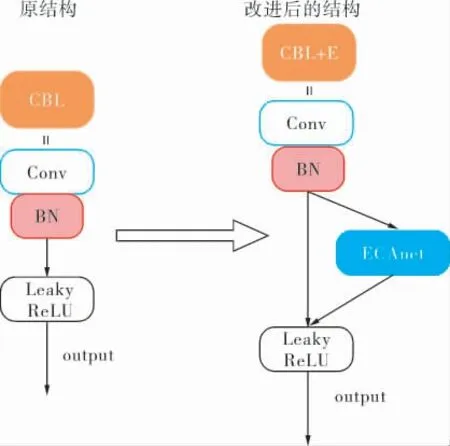
图4 ECAnet嵌入位置
2 实验与分析
2.1 实验
2.1.1 数据集
本研究涉及的数据集包括:coco2017公开数据集和私有数据集。 其中包括了不同人体朝向(正面、背面、侧面、上半身)在不同场景(室内、室外)及不同密度(单人、多人)等情况,并划分出3 004张训练集和400张验证集。
2.1.2 环境配置
Windows 10操作系统,Pytorch框架Python语言完成模型的训练。 测试设备CPU型号11th Gen Intel(R)Core(TM)i5-11400@2.60 GHz,GPU 型 号NVIDIA GeForce RTX 3060,内存16 G,软件环境CUDA 11.4,CUDNN 7.6,Python3.8。
2.1.3 性能指标
精确率P是计算预测正确的比率,召回率R是正确找到目标的比率。
本研究引入精确率和召回率作为衡量是否准确找到目标物体的基础,计算式为:

其中,TP指将正样本预测为正,FP指将负样本预测为正,FN指将负样本预测为负。
平均精确度AP(AveragePrecision)的计算式为:

AP是由R作为横坐标和P作为纵坐标的积分,即PR曲线下方的面积,它的取值范围在0~1。
mAP(mean Average Precision)表示每个类AP的平均值,用作多类标签预测的指标,计算式为:

其中,QR指的是分类的数量。
IoU的计算如图5所示,可以看出IoU是预测框与真实框之间的交集与并集的一个比值,这个值的大小可以反映检测效果。
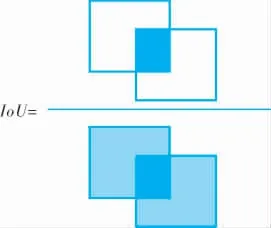
图5 IoU计算示意图
mAP@.5的含义是当IoU为0.5时的mAP值;mAP@.5:.95指的是在不同IoU (从0.50到0.95,步长0.05)上mAP的平均值。
2.2 实验步骤
本研究首先将数据集转换成YOLOv5可以处理的格式。
为了设计出更优化的YOLOv5模型, 笔者对YOLOv5 构建的不同深度和宽度的模型(YOLOv5s、YOLOv5m、YOLOv5l和YOLOv5x)进行了实验和对比。 通过实验选择出最适合的基准模型,然后针对基准模型进行优化和改进。
本研究在YOLOv5常用的4种模型上的超参初始设置:迭代次数1 000代;初始学习率0.01;余弦退火值0.2;动量(momentum)0.937;batchsize为4。
为了让模型提前熟悉一下数据集,如果使用较大的学习率会导致整个模型振荡, 选择warmup预热会比较快地使模型稳定,因此这里设置的是3代小学习率warm-up训练。
2.2.1 4种模型对比实验
图6是目标物体的位置和大小分布。 从图6a中可以看出目标物体的分布比较均匀, 说明所选数据集在目标物体的位置信息上具有泛化性。 图6b是目标物在整个图像中所占宽高比, 可以看出数据集中的目标物体在图像上的占比大部分偏小。
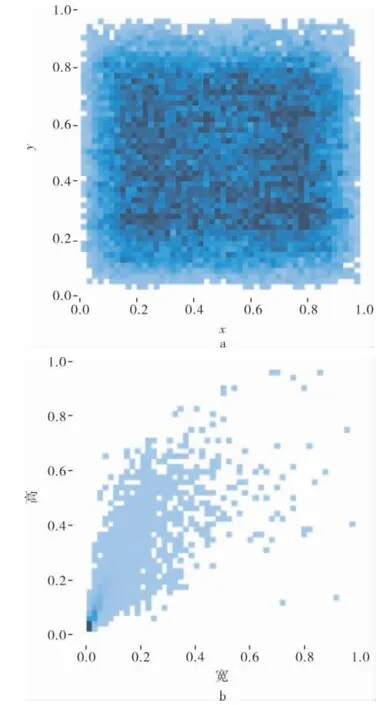
图6 目标物体的位置和大小分布
小目标的定义即指图片上占比过小或像素点稀疏的目标物,因此此数据集属于小目标检测范畴。
当一个模型拥有越复杂的网络结构,可能会获得更高的检测精确度, 但其相对参数也越多,训练所需时间也越长。 模型如果过于复杂,未必能在小目标样本上得到最优结果,而且复杂模型的权重相对较高,计算量也更大。
笔者先针对YOLOv5s、YOLOv5m、YOLOv5l和YOLOv5x对本数据集进行训练。 不同模型的各项指标见表1, 其中深度指网络的深度也就是通道的系数, 在后面计算时需将通道数乘以该系数;宽度是指网络的宽度, 也就是BottleneckCSP模块的层缩放系数,需将每一层的卷积核数量乘以该系数。 随着模型复杂度加深,模型参数也越来越多,GFLOPS(每秒千兆浮点运算次数)也越高,对于GPU的内存需求也就越大。

表1 4种模型指标参数
4种模型训练过程的对比如图7所示,可以看出,模型的性能表现跟其结构的复杂程度是成正比的,损失值越小,说明错漏检测的情况越少,在理想状态下,希望这个值越接近0越好。由图7a可以看出, 模型损失随着训练的进行逐渐下降,在训练了500代后基本稳定接近10%, 最终达到10%以下。 由图7b可以看出,mAP@.5的值在训练了200代之后逐渐稳定,最终接近90%。还可以看出,4个模型的最终精确度非常接近。在实际应用过程中,除了要考虑模型效果,还应该考虑硬件是否比较容易达到, 这样才能推广并降低成本。YOLOv5x模型对于CPU内存的需求将近YOLOv5s的3倍多,可见,模型越复杂,对计算机的性能要求也越高。

图7 4种模型训练过程对比
将4个模型在测试集上得到的数据和训练集上训练的数据结合,得到表2(表中“检测速度”指检测一次所花费的时间),可以看出,模型越复杂,能够获得的精确度也越高, 但是付出的时间代价也越大。 在精确度相差不大的情况下,YOLOv5x所需的检测时间是YOLOv5s的3倍多,YOLOv5x所花费的检测时间以及训练时长都远多于YOLOv5s。在实际生产过程中, 目标检测对于实时性要求很高,越快速地检测出目标物体越好。 因此,在精确度相差不大的情况下, 选择YOLOv5s作为工程应用的最佳检测模型比较符合实际。

表2 4种模型在测试集上的性能对比
2.2.2 改进后的模型和YOLOv5s模型的对比实验
图8是优化前、 后模型的训练过程对比,“YOLOv5s+ECA” 为YOLOv5s 经 由 遗 传 算 法 和ECAnet优化后的模型。 由图8a可以看出,总的损失在前100代左右是急速下降的, 之后拟合状态良好,逐渐趋于缓和,优化后的模型在总的损失值上的表现比基准模型更加优秀,更接近于0。 由图8b可以看出,平均精确度随着训练迭代次数的加大而增加, 在100代左右就达到了比较好的拟合状态,后面逐渐趋于稳定,平均精确度在训练到200代时已经能够达到比较高的精确率, 接近90.00%。
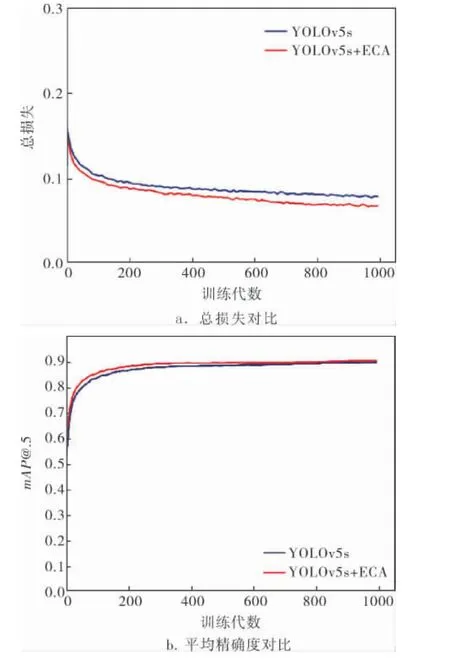
图8 改进后的模型和YOLOv5s模型的对比
在对比了训练模型之后,为了验证优化模型的效果是否到达预期,将优化后的模型和基准模型在测试集上进行实验,结果见表3,可以看出,改进后的模型在原来的基础上召回率提高了3.82%,mAP@.5提高了0.73%,mAP@.5:.95提高了1.00%。 也就是说在检测速度差不多的情况下,引入ECAnet和遗传算法提高了整体检测精度。
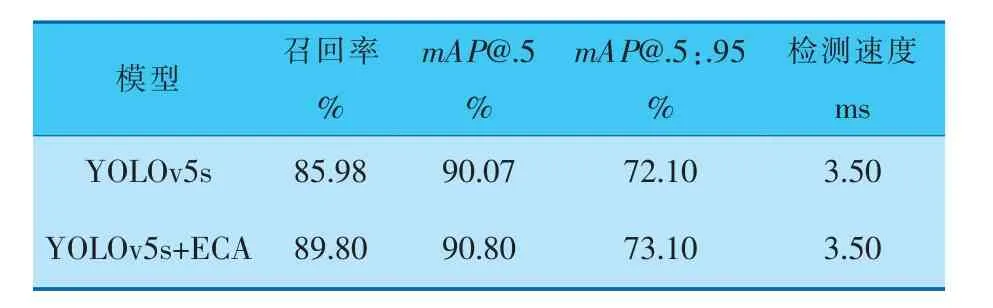
表3 改进后模型与YOLOv5s模型在测试集上的性能对比
图9为改进后的模型和基准模型的检测效果对比, 可以明显看出优化后的模型相较于原模型在精确度上有一定的提高。 YOLOv5s模型能够准确地检测出大尺度目标, 但是在检测被遮挡的小尺度目标时出现了错漏; 改进后的模型对小尺度目标的检测效果更好,错漏情况更少。证明改进模型在复杂场景下,相较于YOLOv5s模型,对于小尺度目标具有更高的检测精度、定位精度和鲁棒性。


图9 改进前、后模型的检测效果对比
3 结束语
为了适应小尺度目标的特征, 对YOLOv5s的Anchor机制利用IoU替代欧式距离作为k-means算法的度量,然后进行遗传算法的流程优化,增强模型的收敛效果。 为了削减卷积神经网路在特征提取过程中对安全帽等小目标特征的丢失现象,笔者在骨干网络中嵌入ECAnet,利用ECAnet对不同通道进行加权以更好地专注在重要通道上的特点,可以提高整个模型的特征提取能力,减少整个模型的计算量。与原YOLOv5s模型相比,优化后的模型召回率增加了3.82%,mAP@.5增加了0.73%,mAP@.5:.95增加了1.00%。 相关实验也证明改进模型在各种常见建筑作业下,对于不同姿势和服装颜色都能够做出准确的识别,证实了模型的普适性和鲁棒性。
在接下来的研究工作中,会继续针对小目标特征进行模型改进, 并在不同数据集上进行实验,以期得到性能更好、应用更广泛的模型。
