基于迁移学习和边缘计算的农作物病害识别*
2022-12-12谢湘慧谢晓春章倩丽喻玲娟
谢湘慧,谢晓春,†,章倩丽,喻玲娟
(1.赣南师范大学 物理与电子信息学院;2.江西理工大学 信息工程学院,江西 赣州 341000)
1 引言
在大部分发展中国家,农作物生产基本上是小农生产,因为农作物病害导致农产品质量、产量减少50%是非常常见的.为减少病害对农作物的损害,广大小农产品生产者想出各种办法,例如通过人工观察和使用强力的化学农药.然而人工观察效率低,且有主观意识导致判断失误,而使用强力的化学农药则会导致水土污染严重,农产品品质下降等诸多问题.近年来,随着计算机视觉和深度学习的发展,现有的神经网络模型已经成功运用于农业领域.在农业病害分类上,Yong Wei等人[1]通过建立BP神经网络模型对采集到的100多张黄瓜叶片样本图像进行训练,识别准确率可达到80%.Lei Chen等人[2]构建一个农业病害图像数据集.并通过该数据集研究不同类型的迁移学习的农业病害识别方法,该方法与Alexnet和Vgg模型进行对比准确率提高了1%~9%,总体的准确率在94%以上.Lu, Y等人[3]提出一种基于深度卷积神经网络的水稻病害识别方法,在交叉验证策略下模型的准确率达到95.48%.Srdjan, S等人[4]开发一个深度学习模型将植物病害树叶与周围的环境区分开来,在开发的模型上可识别13种植物病害,结果显示平均分类精度达到了96.3%.李淼、王敬贤等人[5]利用改进的AlexNet和VGG模型使用迁移学习获得了较高准确率.
本文重点研究Squeezenet[6]、Efficientnet-B0[7]2种深度学习模型网络,在植物病害数据集上取得了较好的分类结果,某些病害达到了100%的准确率.深度学习运用到植物病害还面临了一些挑战,具体表现在以下几点:
为使实验条件降低和缩短训练时的收敛时间,提高识别精度,本文实现了一种基于Efficientnet-B0、Sequeenet深度模型的迁移学习和模型微调的学习方法,利用Sequeenet模型的网络中堆叠的Fire module 的卷积来减少参数数量的目的,再利用混合训练[8]的训练方式加快训练提高训练精度.最终得到的模型参数文件10.1 M,分类精度为96.85%.
2 研究方法
2.1 轻量级模型Squeezenet
国内外研究深度学习的相关论文中都曾提出模块化设计,比如Alexnet模型[9]中的卷积层与Relu激活函数和池化层模块化,Capsule Neural Networks模型[10]中使用的胶囊表征,以及Efficientnet-B0模型都是使用模块化设计的理念来构建的模型.其中Squeezenet模型的核心模块为Fire模块,如图1.在fire模块中,使用Relu函数连接Squeeze和Expand这两部分.

图1 Fire moudle结构图
Squeezenet模型压缩运用3个策略:第1,将3*3的卷积替换成1*1的卷积.其中Squeeze部分中使用的是1*1的卷积核用来压缩通道数与3*3的卷积对比减少了9倍的参数数量;第2,减少3*3卷积的通道数,即Expand中使用2个通道分别为1*1与3*3的卷积核,使用Concat层来连接这2个卷积核合并得到通道数为(e1+e3),与原有的通道数相比较减少通道数;第3,将降采样后置,即将降采样的往分类层移动.实现在不影响模型的性能的情况下,尽量减少参数的数量,为模型在边缘计算的部署提供了可能.
Squeezenet模型结构如图2所示,一共包含10层网络.第1层卷积层,使用一个7*7的卷积核,缩小输入图像,针对224*224的输入图像得到输出图像为111*111*96,第2层到第9层为Fire模块,每经过一个Fire模块通道数就会少量的增加.为了尽可能的减少模型训练时产生的参数量,在Conv1、Fire4、Fire8加入Max-pooling,缩小上一层输出特征的尺寸.且在Fire9模块后添加了Dropout,减少了中间特征数量即减少冗余数据,增加了每层数据特征的稀疏性,预防模型出现过拟合现象.最后一层卷积层,为每一个像素预测分类中38类的得分,最后通过Softmax输出结果.

图2 squeezenet模型结构
2.2 Efficientnet-B0模型
与单一放大模型的某种维度系数从而提高分类精度相比,Efficientnet-B0网络利用一种新的缩放方法混合缩放:利用复合系数来统一缩放模型的维度复合系数,包含神经网络深度、宽度、分辨率等.如resnet50~resnet152是通过加深网络的深度来提高分类精度.Efficientnet-B0的网络结构如图3.

图3 Efficientnet-B0网络结构
Efficientnet-B0网络结构主要由16个MBConv模块、2个卷积层和全局平均层以及全连接层构成.其中MBConv(mobile inverted bottleneck convolution)模块类似MobileNetV2由深度可分离卷积和注意力模块构成.可分离卷积的操作如下:将每一个通道先进行各自的卷积操作,在得到的新通道后进行标准的1*1跨通道卷积操作.假设输入的通道数为3,要求输出的通道数为96,有2种做法:其一,直接使用3*3*96的卷积核,参数量(3*3*3+1)*96=2 688;其二,进行可分离卷积操作,分两步进行得到的参数量为3*3*3*3+3+3*1*1*96+96=468,将参数量降低了8.5倍且提高了模型的特征的提取质量.注意力模块方法为:将上一层的输出分为2条路线,第1条路线直接通过,第2条路线利用squeeze的将特征进行压缩,得到特征权重,并将权重加权到第1条路上,给特征的权重分配.MBConv模块结构如图4.
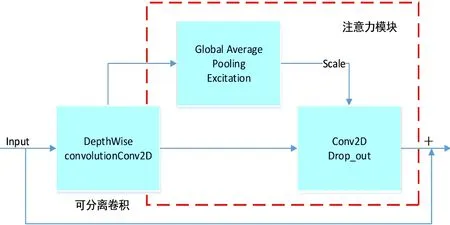
图4 MBConv结构图
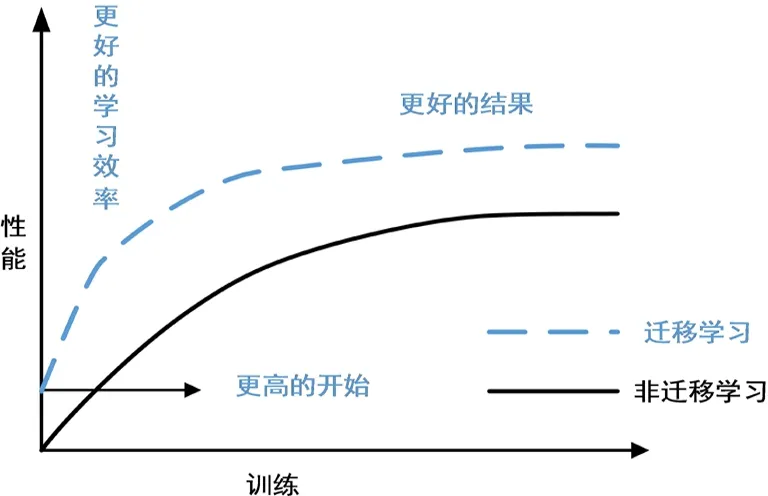
图5 迁移学习性能对比
实验结果证明,利用轻量级模型Squeezenet与Efficientnet可以有效的减少训练的参数.其中squeezenet为10.1 M,Efficientnet为32.8 M.
3 迁移学习
在众多的迁移学习案例中,大都通过使用源域与目标域中特征,任务以及模型的相似性,迁移到对目标域的学习上.与传统的深度学习相比,迁移学习具备以下优点:①减少对低维特征的学习时间;②提高学习效率加快收敛速度;③有着更高的准确率.
深度学习模型的迁移学习有3种,其中Fine-tune[11]是最简单快捷的方法.Fine-tune通过修改预训练模型结构,以及选择性的载入预训练模型的权重来达到快速训练模型的效果.本文利用公开的大型数据集Imagenet训练Squeezenet网络得到预训练模型,再利用Fine-tune的方法对预训练模型进行修改.源域为Imagenet目标域为PlantVillage,针对源域的一些形状特征、纹理特征进行先验学习,减少对目标域中对低维特征的学习,进而加快学习速率.
运用Fine-tune训练squeezenet1_0模型流程如图6.数据增强包含图像的裁剪,水平旋转以及垂直旋转等.预处理是将图片转换成Tensor格式,为pytorch的数据处理做准备.微调的过程是将Last-linear进行修改,以及加入Global avgpool[12]层.训练的超参数如表1所示.

图6 Fine-tune流程图

表1 迁移学习超参数设置
同理在对Efficientnet-B0模型Fine-tune训练中,修改最后一层的参数以及加入dropout层也取得了较好的结果.
4 实验结果
实验在ubuntu服务器上训练,使用GeForce RTX 2080Ti GPU进行加速训练.所有的实验由pytorch框架实现,实验数据利用大型的公开数据集Imagenet以及PlantVillage数据集.在边缘计算器jetson nano上部署模型使用fps、召回率、准确率以及F1分数来作为模型性能的指标.本实验使用不同比例的数据验证模型的识别性能,结果表明,模型具备一定的可靠性.
PlantVillage数据集由14种植物共 54309 张健康和不健康的叶片图像组成,26种常见植物疾病每个类别最少的叶片张数为Potato___healthy只有152张,最多的为Orange___Haunglongbing共5 507张.
图7是采用迁移学习和未采用迁移学习进行squeezenet1_0模型训练的准确率及损失对比曲线,结果表明在源域与目标域中纹理特征有相关性时,使用迁移学习可以获得更高的开始、更快的收敛速度和更高的准确率.训练模型趋于收敛,最终准确率稳定在96.85%(即图中蓝色曲线),取得了较好的分类结果.准确性是评估分类模型的一个不可靠的性能指标,因为当数据集中不同类别的样本数量分布不均匀时,会产生误导性的结果.即难分类的类别会被容易分类的类别所改进.混淆矩阵[13]是分类模型对每个分类类别的准确程度.训练结果最优的混淆矩阵图如图8显示,Raspberry-healthy、Strawberry-leaf-scorch和Cherry-healthy病害识别的准确率为100%,在分类上不干扰其他类型的叶部病害.而Apple-cedar-rust、Grape-black-rot和Corn-spotgray-leaf-spot准确率较低,会降低分类模型的准确率.

图7 准确率及损失对比曲线

图8 混淆矩阵
图8中,0至37分别为PlantVillage数据集中的38种检测分类标签,分别对应Corn-northern-leaf-blight、Corn-healthy、Potato-early-blight、Blueberry-healthy、Corn-common-rust、Cherry-powdery-mildew、Grape-black-rot、Tomato-healthy、Squash-powdery-mildew、Potato-healthy、Strawberry-healthy、Grape-esca、Raspberry-healthy、Apple-black-rot、Tomato-target-spot、Apple-healthy、Corn-spotgray-leaf-spot、Orange-huanglongbing、Tomato-early-blight、Soybean-healthy、Grape-healthy、Apple-scad、Grape-leaf-blight、Tomato-late-blight、Tomato-spider-mites、Tomato-bacterial-spot、Apple-cedar-rust、Peach-bacterial-spot、Tomato-yellow-leaf-curl-virus、Tomato-leaf-mold、Pepper-bell-bacterial-spot、Peach-healthy、Strawberry-leaf-scorch、Pepper-bell-healthy、Potato-late-blight、Tomato-septoria-leaf-spot、Tomato-mosaic-virus、Cherry-healthy.
表2显示如式(1)所示某个类i的预测准确率:

表2 部分类别的准确率,召回率,F1分数

表2 各个CNN模型在jetson nano的Fps比较

(1)
同理某个类别的召回率如式(2)所示:

(2)
单一类别的F1分数利用上面计算出的单个类别准确率和召回率,见式(3):

(3)
再将各个类别的和加起来计算平均准确率以及平均召回率和F1分数.经计算平均分类精度为96.85%,平均召回率为96.73%,平均F1分数为96.79%.
不同模型的模型大小比较以及在jetson nano上Fps的比较见表2.在表格中可以直观的观察到,CNN模型越大,CNN拥有的参数越多.由于VGG16[14]、AlexNet模型使用全连接层作为最后的结构导致训练模型参数量增多,导致训练模型大小分别为1.1G、489.4M.其中训练出的Vgg16模型由于参数量过大无法在jetson nano上部署运行.相反的,Squeezenet1_0采用模块化设计以及采用了Global avgpool可以使得缩短训练时间和参数记忆要求,提高模型的泛化能力.最后训练出的模型的参数降低到10.1M,为模型部署在移动端做好准备.
5 结论
本文利用轻量级模型Squeezenet1_0用于边缘计算器jetson nano针对不同植物叶片病害的识别和分类.基于Squeezenet1_0的轻量级模型,利用迁移学习的方法来对植物树叶病害的识别和分类,提高模型在植物叶部病害数据集上的分类精度.与从头训练对比提高了5%的识别精度.此外,利用混合训练的训练方法增高训练精度.该方法在植物叶部病害测试集上取得了96.85%的平均分类准确率.与其他一些CNN方法相比,它在模型大小上有明显的优势,对识别不同植物叶片的不同病害表现出良好的鲁棒性.在模型部署到jetson nano上可以做到存储空间小,实时性好等优点.在后续的发展上加大数据集的收集,利用迁移学习以及CNN神经网络开发一个基于网页以及线下APP的病害识别系统,应用于实际的农作物生产.
