基于频率分解Transformer的时间序列长时预测模型
2022-12-11付恩张益农杨帆王疏影
付恩,张益农*,杨帆,王疏影
(1.北京联合大学 北京市信息服务工程重点实验室,北京 100101;2.清华大学自动化系,北京 100084;3.北京联合大学 城市轨道交通与物流学院,北京 100101)
0 引言
时间序列预测在多种领域内均有重要意义,如工业监控[1]、能源分析[2]等,随着近些年深度学习方法的成功,时间序列预测的研究也进入了新的阶段。
目前对于时间序列预测算法的研究可以大致分为基于时域的方法与基于频域的方法。
基于时域的方法研究成果最为丰富。循环神经网络(RNN)[3]由于其结构上的时序性,天然适合处理时序数据。例如,有研究者将LSTM[8]与传统遗传算法相结合来预测时间序列[9]。为了解决RNN结构所带来的梯度问题以及长距离依赖问题,注意力机制经常与RNN结构共同使用。基于双阶段注意力机制的RNN模型(DA-RNN)[10]是经典的时序预测模型,它使用两层RNN与注意力相结合的结构进行短期时间序列预测。自注意力机制在多种任务中均具有优越性,有研究利用LSTM改进标准自注意力机制,用于提升多变量序列的短期预测性能[11]。最新的方法中基于Transformer[4]的深度学习架构在长期预测问题中取得了很好的效果,如:Informer[6]基于KL散度优化了自注意力机制的复杂度,提出了稀疏自注意力机制,并在长期预测问题上获得了更好的性能。Autoforme[5]基于随机过程自相关理论提出了自相关机制用以取代自注意力机制,在多组数据集上取得了目前最佳的长期预测效果。
基于频域的预测方法主要利用离散傅里叶变换(DFT)将时间序列转换至频域进行分析,在信号处理中是十分有效的方法。如StemGNN[7]结合图神经网络对多序列进行建模,通过卷积对序列的频域特征进行提取,并结合序列分解结构逐层学习序列的变化模式,取得了更好的中长期预测效果。
总的来说,目前基于时域的方法相较于基于频域的方法研究成果更多,但最新的一些研究也表明了频域方法的潜力,基于频域的预测方法同样具有很强的研究价值。
但上述的两类方法均存在不同的问题:
1)基于时域的方法容易受到噪声的影响而难以对序列的宏观特征进行建模,如序列的周期,而宏观特征对于长期预测的准确性至关重要。
2)目前基于频域的方法没有考虑不同频率分量的重要性,不同频率分量对预测结果的影响不同,长期预测受到低频分量的影响更大,目前缺乏用于长期预测的、具有针对性的频域模型。
为了解决上述的问题,本文从频域的角度提出了一种基于Transformer[4]的频率建模方法,针对不同的频率分量分别进行处理,本文的主要贡献如下:
1)提出一种频率分解多头自注意力模块,用来对不同频段的频率分量针对性地进行建模,是自注意力机制在频域处理中的新方法。
2)本文将Tranformer[4]结构作为特征提取框架,基于频率分解多头自注意力模块,设计了频率分解Transformer(FD-Transformer)模型。通过实验与目前最新的研究成果进行了对比,本文的方法在3个真实数据集的多个指标上取得了最佳性能。
1 模型架构
本节将介绍所提出的FD-Transformer的输入、预处理、频率分解多头自注意力模块以及模型总体架构。
1.1 问题定义
给定输入序列Xt∈Rn×t,由n条长度为t的序列构成。定义Yl∈Rk×l为输出序列,其中1≤k≤n,由k条长度为l的变量构成,Yl为Xt的预测值,数学形式如下:
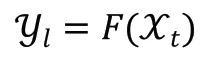
其中F(*)为映射函数,即模型的学习目标。
1.2 预处理
为了获取输入序列的频域特征,首先需要使用离散傅里叶变换(DFT)对输入序列进行预处理。
编码器输入:如图所示,xt为n条输入序列的时域表示,时间长度为t,wt为输入序列的频域表示,由组频率分量构成。由于傅里叶变换结果的对称性,在此处只取单边频谱作为编码器的输入。wt中的虚部与实部会被堆叠在最后一维作为整体传入模型。具体的维度变化如图1。
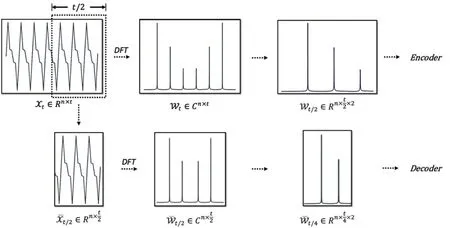
图1 预处理过程
解码器输入:由于时间序列的时间动态性,越靠近预测点的时间段越具有参考性,此处将输入序列的后一半提取,进行相似操作表示xt的后一半时域序列,为的频域表示,由t/2组频率分量构成,与编码器相同,取单边频谱作为解码器输入。
设有t长度的n条序列同时作为输入,即xt为(n,t)的实矩阵,经过离散傅里叶变换之后得到的wt为(n,t)的复矩阵,为了使得该矩阵便于运算,将其实部与虚部分别提取并堆叠,再取其单边频谱,最终的wt/2的维度为(n,t/2,2),其中最后一维的2代表复矩阵的实部与虚部,同理可得
经过上述预处理,得到了wt/2和分别作为编码器与解码器的输入。
1.3 频率分解多头自注意力模块
时间序列的不同频率分量中的低频部分构成了序列的趋势信息,而中高频部分包含了噪声以及细节信息。针对这一特点,设计了频率分解多头自注意力模块。受到标准多头自注意力机制的启发,频率分解多头自注意力机制通过多个头分别处理不同频率段的特征,与多头自注意力机制不同的是,频率分解多头自注意力机制的目的是寻找不同频率分量之间的依赖关系。模块的整体结构如图2所示。

图2 频率分解多头自注意力
其中,w为输入的频域特征,形状为(d,w,2),其中d为特征维度,w为频率维度,2为频率的虚部与实部,将w由低频到高频分为多个区间,每个区间长度逐级递增。可以保证低计算量的前提下使低频部分特征干扰项更少。每个频率区间分别输入到独立的自注意力层形成多头结构。其中Conv是贯穿全模块的线性映射层,由堆叠的二维卷积构成,为了降低模型计算量,第一个卷积层采用深度可分离卷积,卷积核宽度随着频率区间的增大而增大,其中表示频率区间下标,第二个卷积层为标准卷积,使用Leaky RELU作为激活函数。各个频率区间的处理结果通过连接(Concat)操作拼接在一起,拼接后的形状保持为(d,w,2)。最后使用Conv模块对输出做整体映射。
1.4 模型整体架构
基于上述的预处理方法和频率分解多头自注意力机制,本小节将介绍模型的整体结构,如图3所示。

图3 模型整体结构
Conv层作为基本映射单元贯穿整个模型。由于频率特征不同频率分量的振幅差异大,导致频率特征内部方差较大,不利于模型收敛,因此使用LayerNorm对频率特征归一化消除过大方差对模型训练的影响。最终,解码器的输出特征经过Conv层后做反傅里叶变换,得到最终的预测结果。
图3中,Conv层结构与图4中的结构相同,用于处理频率特征,并保持频率特征长度不变。编码器与解码器在输入前分别存在Conv与Conv &Linear输入层,Conv层将输入的变量维度扩展至指定的高维空间。例如,模型维度为m,输入wt/2经过Conv层后转变为解码器输入前的线性层将输入的频率特征长度扩展至所需的预测长度,实现一次前向传播得到整个预测序列。例如,预测长度为l,则解码器输入经过Conv+Linear层后转变为
2 实验
本节通过实验验证所提出的FD-Transformer的有效性。
2.1 数据集与模型衡量指标
1)Electricity数据集,该数据集包含2012年至2014年321个客户的每小时用电量。
2)Weather数据集,该数据集包含21个气象指标,每十分钟记录一次。
3)Traffic数据集来自美国加利福尼亚交通部,利用位于旧金湾区高速公路上的传感器记录了每小时的道路占用率。
我们使用均方误差(MSE)、平均绝对误差(MAE)以及皮尔逊相关系数(CORR)来衡量模型的性能,其表达式如下:
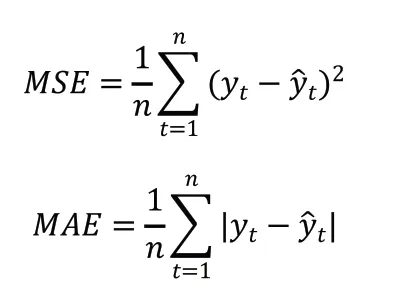
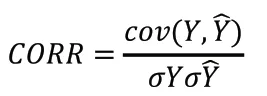
其中,Y为真实值序列,为预测序列,cov为协方差,σ为标准差。目前的长时序列预测研究中通常只关注MSE与MAE,但这是不够全面的。MSE与MAE容易受到序列高频部分的影响,因此我们通过皮尔逊相关系数(CORR)重点衡量低频趋势的预测能力,再综合MSE与MAE,可以更加客观的反映出模型性能的优劣。MSE与MAE越小代表模型性能越好,CORR越接近1代表模型性能越好。
2.2 实验结果与分析
2.2.1 基线模型
我们选择3个基于时域的模型与1个基于频域的模型作为基线模型。
Autoformer:目前的最佳长序列预测模型,Autoformer基于Transformer结构额外引入了改进的序列级自相关机制,其在多个数据集上均取得了最佳的长期预测效果。
Informer:基于KL散度设计了稀疏自注意力机制,大幅度减少了标准自注意力机制的计算量,在时间复杂度上达到了(nlogn),并且可以一次性生成多步序列预测结果。
StemGNN:基于图神经网络(GNN)对多变量序列进行建模,并在频域中捕捉序列特征。
实验中Autoformer、Informer与StemGNN均使用作者默认配置。
LSTM:LSTM为编解码器结构,编码器、解码器各2层,模型隐层维度为256,每层使用20%的dropout避免过拟合。
2.2.2 实验结果
本文跟随Autoformer的实验设置,给定输入序列长度为96,预测长度分为96、192、336和720。本文模型的编码器与解码器层数为2,频率从低频到高频依次划分为4组,分别为[0,6%]、[6%,20%]、[20%,50%]、[50%,100%],模型训练迭代次数为10次,batch大小为32,模型隐层维度为512,初始学习率为5×10-4,每2次迭代将学习率减小1/2。
模型的预测性能对比如表1所示。我们的模型在3个数据集的相关系数(CORR)指标上均取得了最优结果,即本文的模型拥有更稳定的长期预测性能。通过注意力机制本身的稀疏性,模型可以从高频分量中提取到更加本质的高频特征,所以对于MSE与MAE,模型也取得了大部分的最优性能。在结果中只有LSTM是迭代生成预测的模型,随着预测长度的增加,误差累积导致的预测性能下降最为明显。Autoformer在更加反映低频趋势的CORR指标上表现一般。

表1 多变量序列预测结果对比
所有模型的输入长度为96,每个数据集的预测长度分为96、192、336和720共4组。
2.3 超参数敏感性分析
本节对频率分解注意力机制中最重要的超参数频率划分区间与对模型的影响进行实验验证。
频率划分区间选取不同的划分策略如表2所示。

表2 用于实验的频率划分策略
表2中的区间*代表不同的区间号,每个区间对应本文注意力层中的一个“头”。区间含义[0,2%]代表频率段的前2%的划分为一组,[50%,100%]代表频率段的后50%划分为一组。策略1到策略4的低频部分逐渐增大。实验输入序列长度96,预测长度336,其余超参数设置与4.2.2节相同。4组划分策略实验结果如表3示所示。
由于序列低频分量对中长期预测的重要性,更细粒度的低频划分区间有助于帮助模型获取更详细的低频特征。但过细的粒度会强迫模型使用更多的低频特征,限制模型的灵活性,因此,并非粒度越细越好,从表3中可以看到,策略2的划分方式最佳。此外,模型稳定性较好,以最优指标为基准,MSE、MAE和CORR指标波动幅度分别为:在Electricity数据集上为2.6%,2.5%,3.1%,Weather数据集上度为12.5%,4.2%,16.8%,Traffic数据集上为6.3%,8.5%,2%。
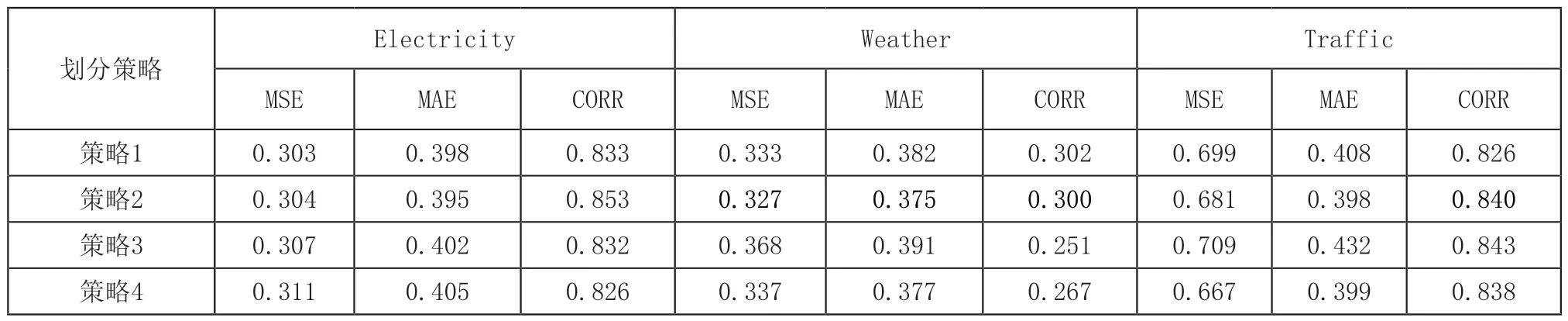
表3 不同频率划分策略的效果差异
3 结语
本文提出了一种频率分解自注意力机制,通过自注意力机制提取用于中长期预测的频率特征。由于频域本身描述了序列宏观的特征模式,相比于时域,频域分析对于中长期序列预测更有优势,通过针对高频低频别分建模可以有效区分序列中的趋势与噪声。基于频率分解自注意力机制本文提出了一种改进的Transformer架构用于处理频域特征,主要通过特殊设置的二维卷积模块替代线性变换层保证频率特征维度正确同时拥有更少的参数量。通过编码器、解码器结构协助模型进一步学习序列的变化模式。在Traffic、Weather和Electricity共3组公开数据集上与目前最新的研究成果Autoformer在内的共4个基线模型进行了对比,本文提出的方法在多组指标上提升明显,验证了本文模型在中长期序列预测问题中的有效性。
