基于贝叶斯推断的产量递减综合预测新模型
2022-12-10王军磊位云生齐亚东朱汉卿雷丹凤
王军磊 位云生 齐亚东 倪 佳 于 伟 袁 贺 朱汉卿 雷丹凤
1.中国石油勘探开发研究院 2.中国石油西南油气田公司页岩气研究院 3.德克萨斯大学奥斯汀分校
0 引言
油气井生产数据分析或产量递减分析是指油气藏进入投产阶段以后,通过使用合理模型拟合历史动态数据、预测未来产量,并为早期气田产能建设和后期方案调整优化提供可靠信息的技术方法。在衰竭式油气藏开采过程中,生产井呈现缓慢的产量递减特征,根据建模原理将产量递减模型分为理论类(如生产数据分析方法,即RTA)[1-3],经验类[4-7](如各类经验递减模型)以及数据驱动类(基于机器学习、神经网络算法等建模)[8-12]3类方法。其中,理论类方法虽然具有明确的物理意义,但难以处理好物理模型的全因素假设和模型模拟效率间的矛盾;经验类方法在大量生产数据分析基础上建立经验式产量递减模型,但没有严格的渗流理论支撑、适用性差;数据驱动类方法更多的是反映数据到数据的映射关系,预测精度直接取决于训练数据的质量及算法的适宜性。需要明确的是,以上方法原则上适用于页岩、致密砂岩等不同类型的非常规油气藏/井动态数据分析。
盲目使用以上方法应分析实际生产数据会极大增加产量递减分析预测的不确定性[13-14],如何合理量化这种不确定性是关键,频率学派和贝叶斯学派是目前2种主要流派。频率学派依据最大似然估计原理,主要有3种方法:①在产量数据库基础上逐井拟合获得递减模型参数的概率分布模型,结合随机模拟获得气井产量的概率性预测[15];②对特定井的生产数据进行有放回地多次抽样以形成多数据组合,通过拟合获得产量预测的概率性分布[16];③假定模型参数概率密度,通过随机参数抽样预测产量,根据目标函数设定以筛选概率性产量预测结果[17]。贝叶斯学派则是以最大后验估计为基础,克服频率学派模拟时的随机性,Gong等[18]首次利用贝叶斯理论量化产量递减分析的不确定,Fulford等[19]以流态识别为依据,通过使用瞬时双曲模型和参数分布似然函数改进了Gong提出的方法;Paryani等[20]使用近似的复杂似然函数建立近似贝叶斯概率性方法,大幅度提高了贝叶斯模拟效率,通过多模型协同约束以降低预测不确定性;Holanda等[21]建立具有物理意义的全流态演化模型,结合随机最大似然原理更新似然函数中的协方差矩阵,有效提高了贝叶斯方法的运行效率。
需要指出的是,以上研究均是针对某种特定的模型,所选模型类型本身也会影响预测结果的不确定性。传统方法中仅通过对比适用条件和历史拟合效果而优选“好”模型是不科学的[22-23],适用性好、拟合效果好的模型并不代表是真正意义上的“好”模型,而是代表该模型是“好”模型的概率(可视为权重)为1,人为区分“好”模型和“差”模型相当于指定了模型概率(即好模型概率为1,差模型概率为0),大大增加产量预测的风险性。本文以6种常见经验模型为候选模型,使用“贝叶斯概率”量化双重的不确定性,即单一模型EUR预测的不确定性和多个模型选择权重的不确定性,充分发挥多种模型间相互兼容、相互制约的技术优势,有效提高单井EUR预测可信度。该方法不仅适用于经验式模型,也适用于解析模型和数值模型,具有良好的可扩展性。综合模型可以有效改进单一模型EUR预测结果的不确定性和风险性,为我国非常规油气开发提供有益借鉴。
1 产量递减模型适用性评价
产量递减模型原理是回归历史生产数据。实际应用时,根据实测数据利用各种优化算法,获得最优拟合效果(即优选最“好”模型),通过反演计算模型参数(向量)以获得确定性的预测结果。
经验式产量递减模型是建立在同一种或几种流动状态下动态分析基础上的,即每种模型对应特定的流动状态。本文给出了Arps型、幂律指数型(PLE)、扩展指数型(SEPD)、Duong型和逻辑增长型(LGM)等适用于不同流态的6种递减模型,根据量纲一致性原理将模型转化为无量纲形式,以便使用典型图版拟合法进行数据分析。相应模型数学表达式和出处见表1。

表1 常见的6种经验式产量递减模型表
以北美地区某口致密气压裂井生产数据为例进行分析[26],相应的地质工程参数为:原始地层压力为19.07 MPa,地层温度为30 ℃,储层有效厚度为4.5 m,孔隙度为8.5%,含气饱和度为80%,原始地层压力下气体黏度(μgi)为0.021 6 mPa·s、偏差因子(Zgi)为0.776 1。建立RTA解析模型拟合生产数据,拟合后的裂缝长度为12 m,地层渗透率为2.67 mD,井控地质储量(OGIP)为2 049×104m3,设定20年生产周期,EUR预测值为1 185×104m3(该值可视为EUR真实值)。使用经验式模型进行典型图版拟合分析(图1),气井先后经历双线性流+线性流+拟稳态流三个连续生产阶段。结果显示:除Duong模型外,其余模型均可获得较好的历史拟合效果,EUR预测结果 为 :EURArps=1 314×104m3、EURPLE=1 149×104m3、EURSEPD=1 016×104m3、EURLGM=1 387×104m3、EURFDC=1 572×104m3、EURDuong=2 625×104m3。
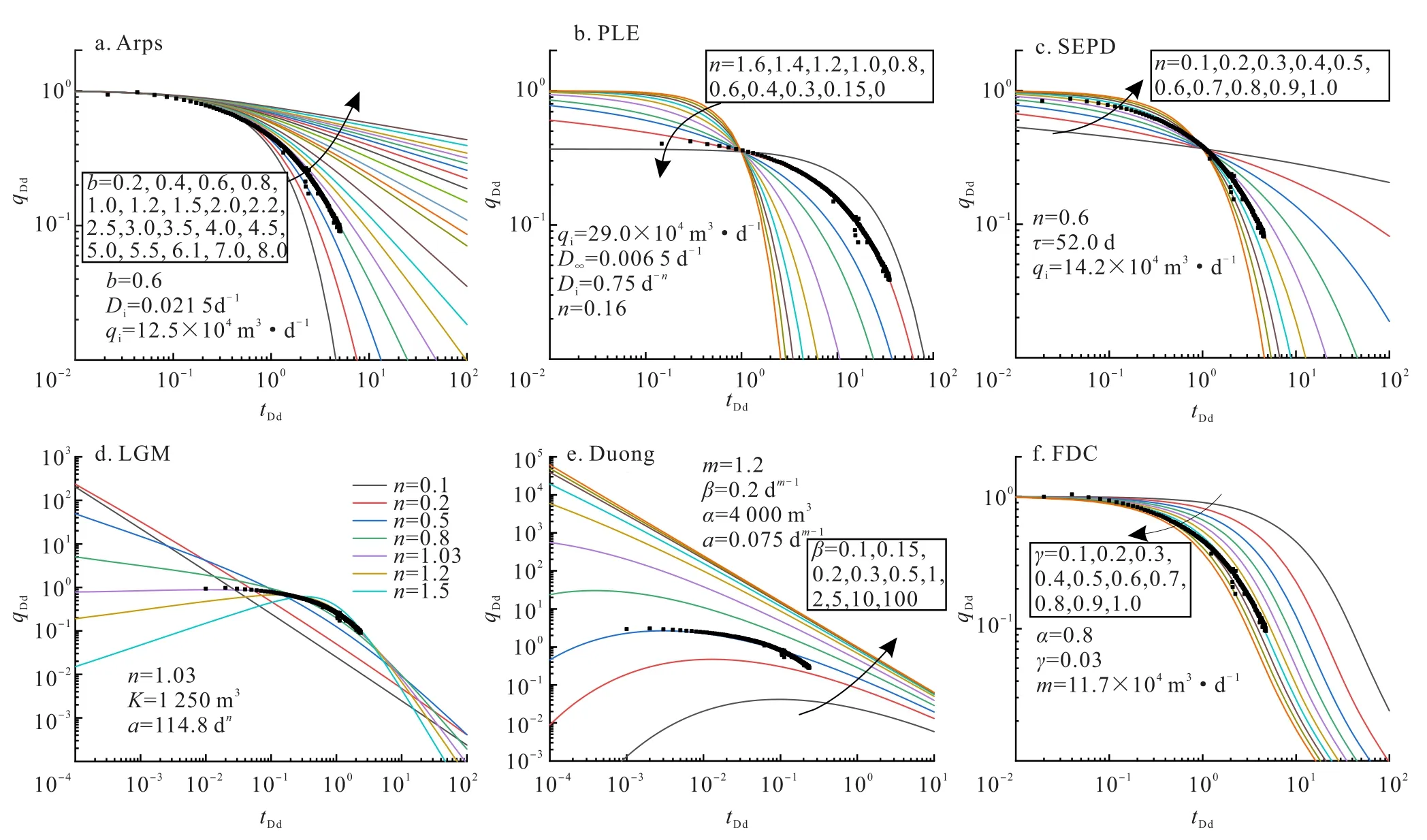
图1 产量递减模型典型图版拟合效果图
由EUR预测结果可知,该算例中除Duong模型不适用外,其余5种模型EUR结果介于1 149×104~1 572×104m3之间,包括EUR真实值(EURRTA=1 185×104m3)。其中,FDC模型结果最为乐观,SEPD模型结果最为保守,PLE模型结果最为接近,Arps和LGM模型结果近似。根据模型适用性条件分析可知:①Arps模型(图1-a)仅适用某种特定流态,当2<b<4时适用双线性流,当b=2时适用线性流,当b<1时适用拟稳态流[27],该井拟稳态生产周期相对整个周期较长,EUR预测值较合理但仍偏高;②PLE模型(图1-b)通过将递减指数b修正为关于时间的变量,适用从(双)线性到拟稳态的整个流态变化过程,该井流态较为清晰,通过拟合该模型获得最为合理的EUR预测值;③SEPD模型(图1-c)适用任意非稳态生产数据,但在后期累积产量趋近于界限值,该井较长的拟稳态生产历史使得模型低估了EUR;④LGM模型(图1-d)难以拟合整个流态过程,拟合拟稳态过程时需要更新模型参数,适用条件和预测结果与Arps模型类似;⑤Duong模型(图1-e)适用于(双)线性流数据,该井后期的拟稳态数据仍解释为线性流,因而该模型EUR预测值偏大;⑥FDC模型(图1-f)能较好拟合各种流态,包括过渡流等,该井在拟稳态阶段近似指数递减,而模型衰减速率要低于指数衰减,导致EUR预测结果较高。因此,判断某种模型是否适用于特定的流动状态,应以流态识别为依据的同时结合模型适用条件进行具体分析[13]。
总的来看,该口井经历的流态较多(即生产周期相对较长)、气井数据质量较高(生产制度稳定、数据噪音小、流态清晰),即使获得了最优历史拟合,不同模型EUR预测结果仍有较大不确定性。不确定性主要来自两个方面:①单个模型本身参数拟合的多解性;②不同模型适用条件的差异性,而且模型参数越多、模型差异越大,预测EUR的不确定性越高。如何用“概率”思维量化双重不确定性是扩展经验递减模型适用范围的关键。
2 贝叶斯推断原理
贝叶斯原理主要用以描述模型参数、实测数据和模型输出值之间的关联,其将概率看成对事件发生的信心,并且保留不确定性。将多维参数向量(θ)视为随机变量,则存在与θ相关的概率分布函数,给定任何θ取值都能得到相应的概率值。经典贝叶斯推断定理可表述为根据先验分布和可能性(似然)分布获得后验分布的过程,满足如下公式[23]:
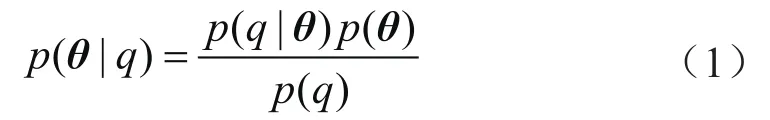
式中q表示观测数据,对应历史生产数据,如产量或压力等;θ表示模型参数向量;p(θ|q)表示给定实测数据时关于模型参数向量(θ)的后验分布概率;p(q|θ)表示似然函数;p(θ)表示关于模型参数向量(θ)的先验分布;p(q)表示边际似然函数。
对于边际似然函数,本文分为两种情况进行计算:
第一种连续型变量(即模型参数),对应的分布为概率密度函数,边际似然函数为积分形式:

第二种离散型变量(即模型类型),对应的分布为概率质量函数,边际似然函数为求和形式:
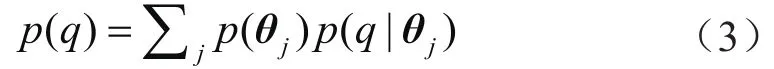
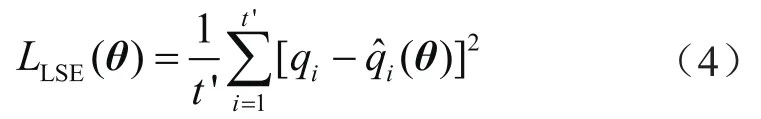
假设损失函数满足标准正态分布N(0,σ2),似然函数为:
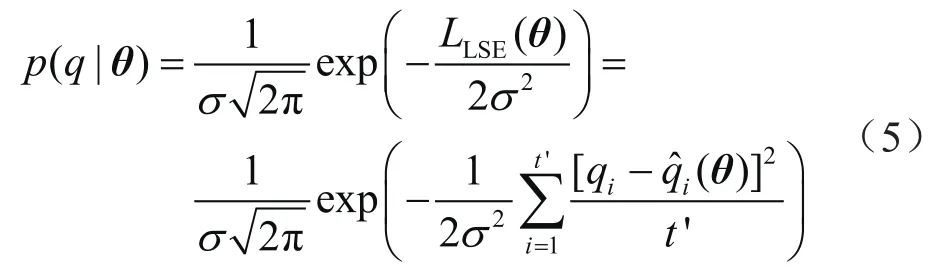
理论上先验概率分布p(θ)可以任意给定,通常假设随机变量均匀分布,而最终(稳定)的后验分布通过式(1)~(5)结合实测数据确定。
2.1 离散型变量随机模拟
将模型类型视为离散型变量,利用概率关系联合多个单一模型构建综合模型。根据贝叶斯推理,式(1)第j个模型mj为“最佳”模型的后验概率为
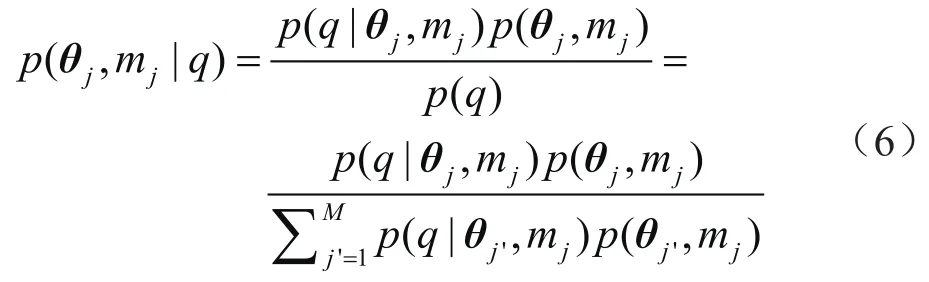
式中θj表示第j个模型的参数向量。
离散型参数的边际似然函数p(q)的积分形式可以写为离散求和形式。与连续型变量不同,式(6)可以直接计算。
根据先验分布特征,假设各个模型的先验概率分布相同,即
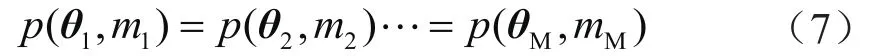
则式(6)改写为:
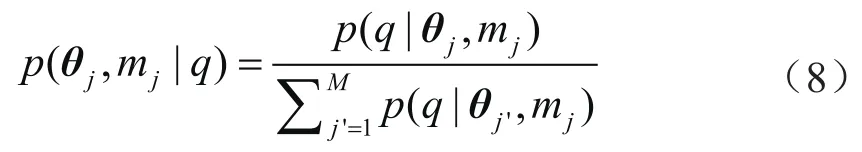
根据似然函数定义,将式(5)代入式(8),特定模型参数向量条件下的后验概率为:
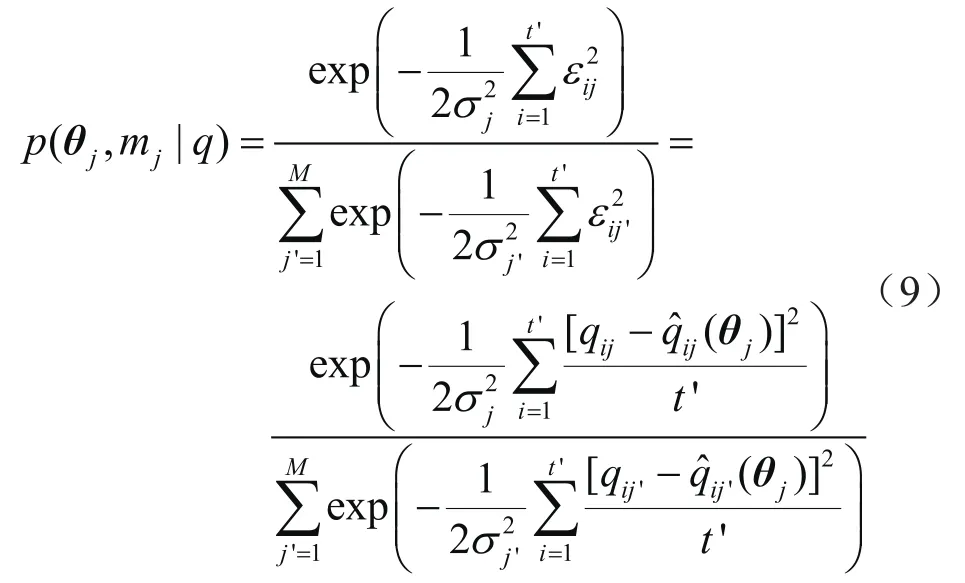
式中p(θj,mj|q)表示给定观测数据q下第j个模型参数θj的后验分布概率,可以作为第j个模型预测结果的权重;mj表示第j个模型;M表示模型总个数;εij表示第j个模型中第i组数据间的随机误差;σj表示第j个模型的数据标准差。
2.2 连续型变量随机模拟
借助马尔科夫链—蒙特卡洛(MCMC)方法,即从近似分布中获取一系列的模型参数采样点,通过校正采样点获得后验分布更好的近似后验分布。由于随机变量的后验分布是未知,需要通过从另一个概率分布中抽样获得。MH(Metropolis—Hastings)方法是实现MCMC过程的经典算法,通过建立满足细致平稳方程的转移概率矩阵,基于“拒绝采样”原则沿着马尔科夫链不断逼近平稳分布,即从任一状态出发通过不断进行状态转移最终收敛到平稳分布。
MH算法的关键是建议分布p(θ|θ*)和接受率分布(α),其中θ表示随机变量,θ*表示给定的随机变量。这里设定接受率(α),即接受θ=θ*的概率为α,不接受概率为1-α。设定接受率大于1时为1,规整化处理后满足如下公式:
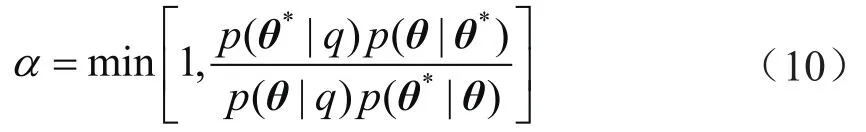
通常情况下建议分布满足对称假设,即p(θ|θ*)=p(θ*|θ),式(10)可进一步简化为 :
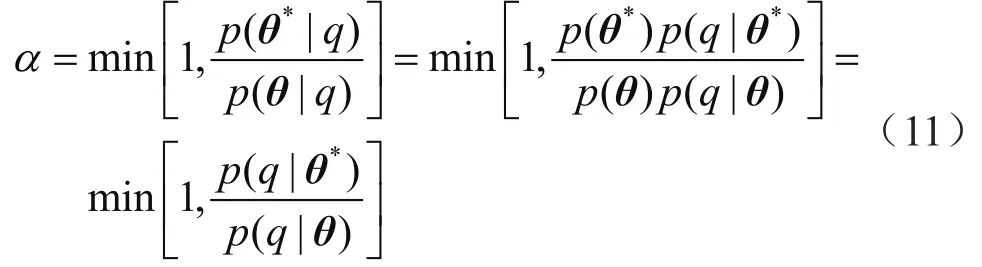
MH算法假设参数间相互独立导致接受率过低,这里使用AM算法增加变量间的自相关性以提高接受率,基本原理为:每次迭代过程中,在上一步协方差矩阵(Ci)基础上生成并更新建议分布[27]:
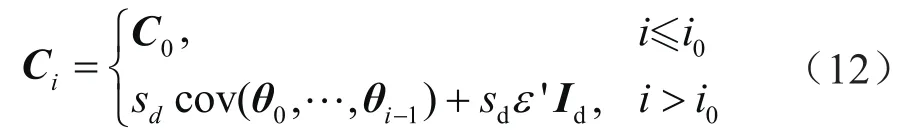
式中i0表示初始周期(更新协方差矩阵的周期);ε'表示极小值以确保协方差矩阵非奇异,一般取10-12;Id表示d维单位矩阵;sd表示取决于变量维数的换算因子,一般取sd=2.42/d;C0表示初始正定矩阵。
以一维随机变量模型为例对比MH和AM算法的采样模拟效果。假设变量目标的概率密度(PD,取值范围介于0~1)分布满足正态分布加权平均形式,对应的后验概率π为:
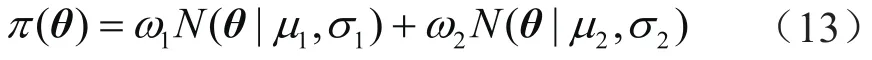
式中ω1=0.3,ω2=0.7,μ1=0,μ2=10,σ1=2,σ2=2。模拟结果如图2,可以看出AM算法接受率更高(α=0.354),而且在采样过程中随机变量的取值范围更广、更均匀,可以获得更好的目标分布。随机变量维数越高,AM算法优势越显著。
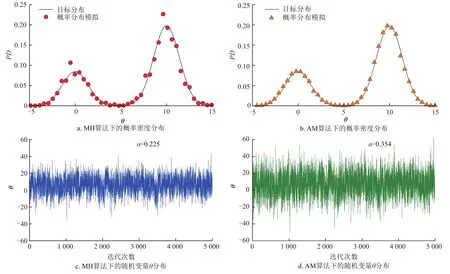
图2 MH算法与AM算法模拟结果对比图
3 综合模型产量递减不确定性分析
3.1 单一模型分析
量化单一模型拟合结果的不确定性分为3个步骤:①根据最小二乘法原理,即实测数据与模型预测值间的损失函数最小,获得确定性“最优”模型参数θ0;②求解损失函数最小时对应的近似参数向量()及对应的协方差矩阵;③以最优拟合参数(θ0)及协方差矩阵为多维高斯概率模型的初始值代入式(12),并根据建议概率分布N(θi,Ci)抽样参数向量θ*,进而调用MCMC模拟拟合或预测结果的不确定性。
以FDC模型为例说明单一模型预测的不确定性。迭代次数设定为10 000次、每100次更新协方差矩阵(i0=100)。为了提高模拟效率,将产量递减模型处理为关于最高产量和时间的形式(即三维参数向量降维为二维):
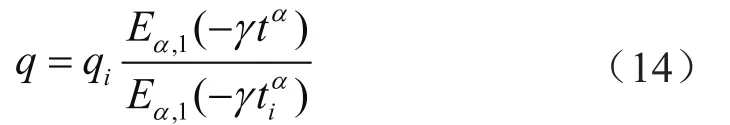
式中qi表示产量最高值(qi=11.74×104m3/d);ti表示产量最高值对应的时间(ti=1 d);Eα,1( ) 表示Mittag-Leffler函数;α、γ表示待拟合无量纲参数。
根据Mittag-Leffler函数的性质[25],可以获得最优模型参数向量{θ0=[α0,γ0]}对应的雅克比行列式:
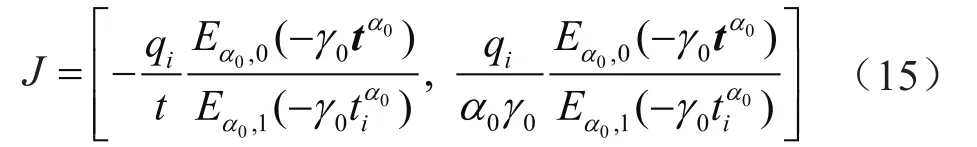
式中J表示雅克比行列式;t表示时间序列向量,d;α0、γ0表示最优拟合参数。
获得的参数向量最优解(α=0.836 1,γ=0.031 0)与手动图版拟合结果基本一致(图1-f),二维参数向量的接受率为36.57%,满足接受率的要求。模型参数向量的后验概率分布如图3,参数分布较为集中(α和γ分布区间分别介于0.72~0.95和0.015~0.061),参数间的Pearson's r(皮尔逊相关系数)为-0.962 3,近似反向线性相关。
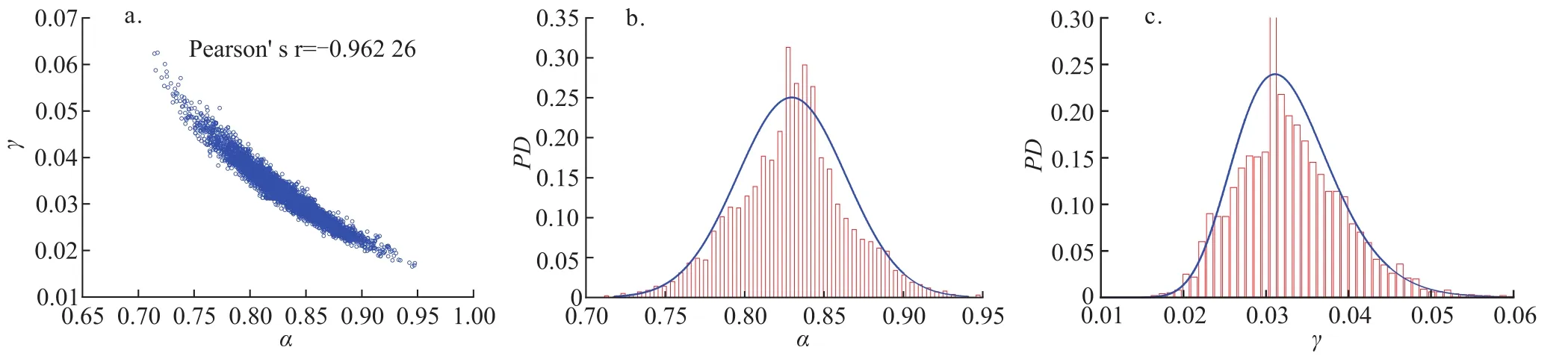
图3 递减模型参数的后验概率分布及双参数间关联度图
根据模型参数后验分布,对每种参数组合下的模型进行产量拟合及EUR预测,不确定性模拟结果如图4所示,其中图4-a为日产气量(q),图4-b为累积产气量(Gp),图4-c为EUR概率密度分布(PD)及累积分布(CD)。该井EUR预测区间介于1 462×104~2 133×104m3(最低值—最高值),80%EUR置信域(P10~P90)区间介于1 537×104~1 893×104m3,EURP50=1 629×104m3。图版最优拟合解(EURFDC=1 572×104m3)位于80%置信域内,近似于P50值,说明确定性图版拟合法和不确定性法的评价结果具有较高相融性。但FDC模型80%置信域并不包括EUR真实值(1 185×104m3),说明选择该模型预测EUR的可信度较低(即风险性较高)。

图4 递减模型不确定产量拟合及EUR预测结果图
3.2 综合模型分析
在单一模型不确定性分析基础上,根据贝叶斯推断原理和MCMC采样,建立基于贝叶斯概率的不确定性产量递减分析综合模型,以降低单一模型预测的风险性。建模流程如图5所示(其中白色框架为MCMC-AM采样内容,黄色框架为贝叶斯推断原理内容),每次迭代(i=1~N)时计算每种模型(j=1~M)的后验(贝叶斯)概率值p(θji,mj|q)记为Pji;以观测数据(q)为约束,基于模型mj使用参数向量(θji)计算得EUR值记为fji,分布如表2所示。
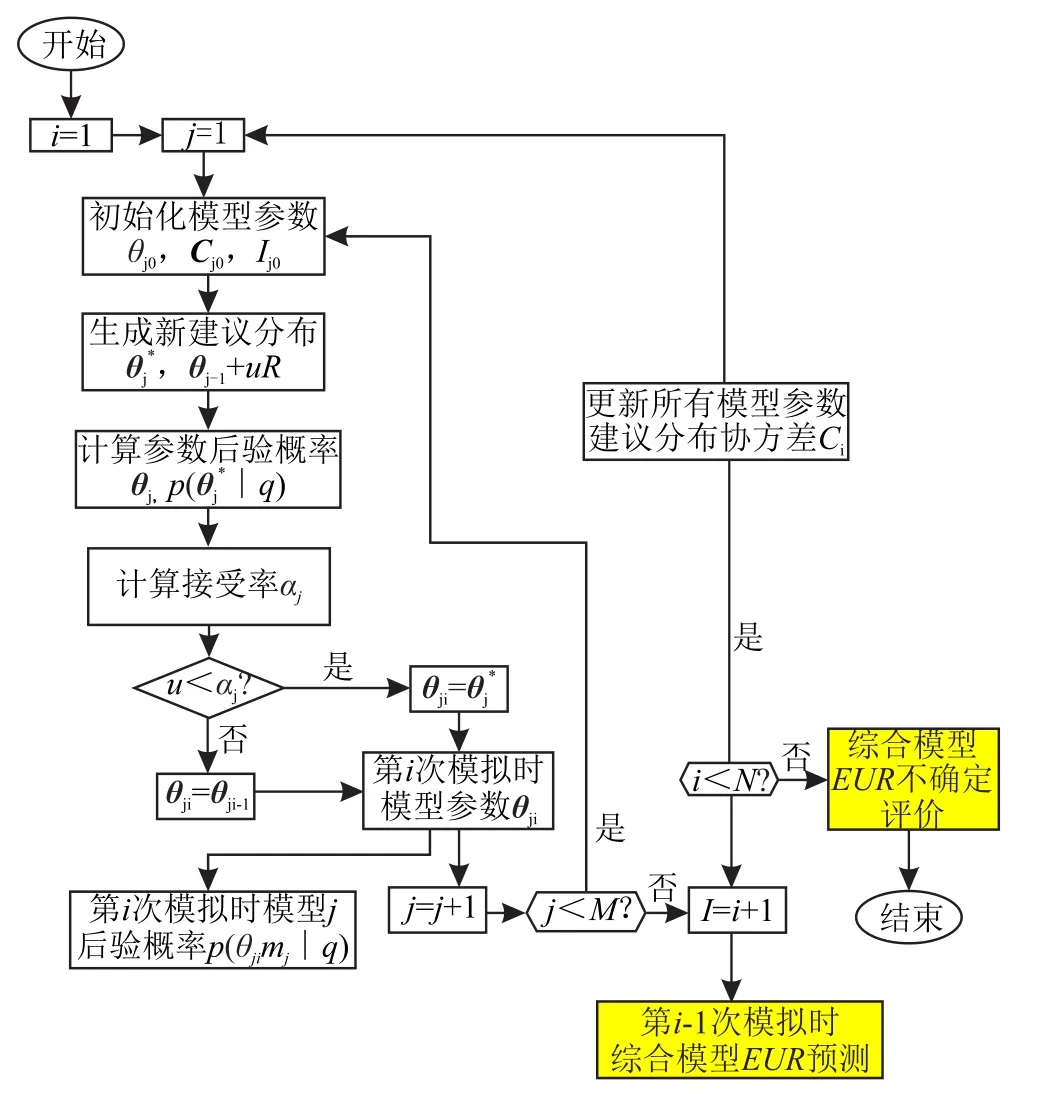
图5 综合模型建模工作流程图
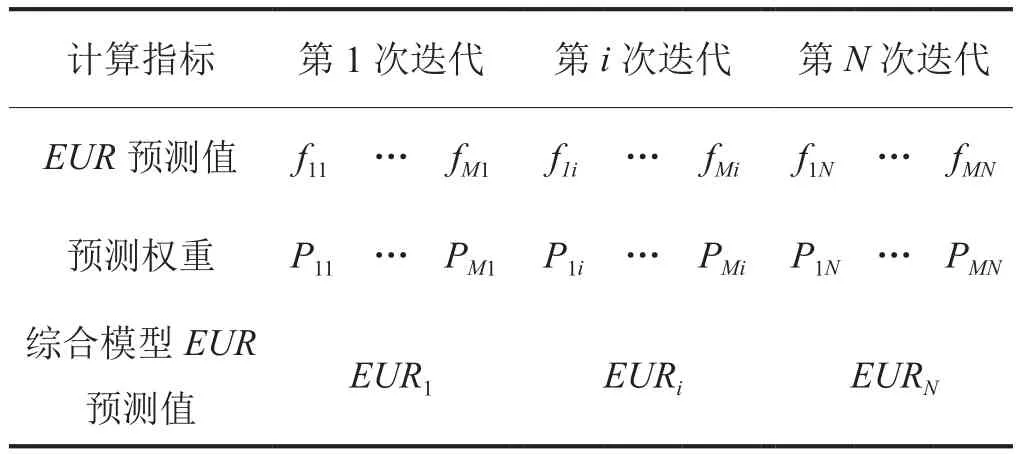
表2 迭代过程中不同模型的权重值分布表
相应地,第i次迭代时综合模型的EURi预测值为:

式中Pji表示第i次迭代时第j个模型的后验概率值;fji表示基于第i次迭代时第j个模型计算的EUR值;M表示模型个数。
对于给定观测数据(q),相对于其他模型,第j个模型是“优选”模型的相对可信度(即优选模型概率):

式中mj表示第j个模型;N表示迭代次数;p(q) 表示在迭代过程中独立样本,即p(q)=1/N。
以算例数据为例说明工作流程,分两种情况:
第一种情况:分别对其余4种模型进行不确定性评价(Duong模型除外)。各模型参数向量的后验概率分布如图6所示,Arps模型(图6-a)参数分布范围最大、接受率最低(30.26%);而PLE模型(图6-b)参数分布范围最小、接受率最高(36.35%),其余两种模型介于两者之间。
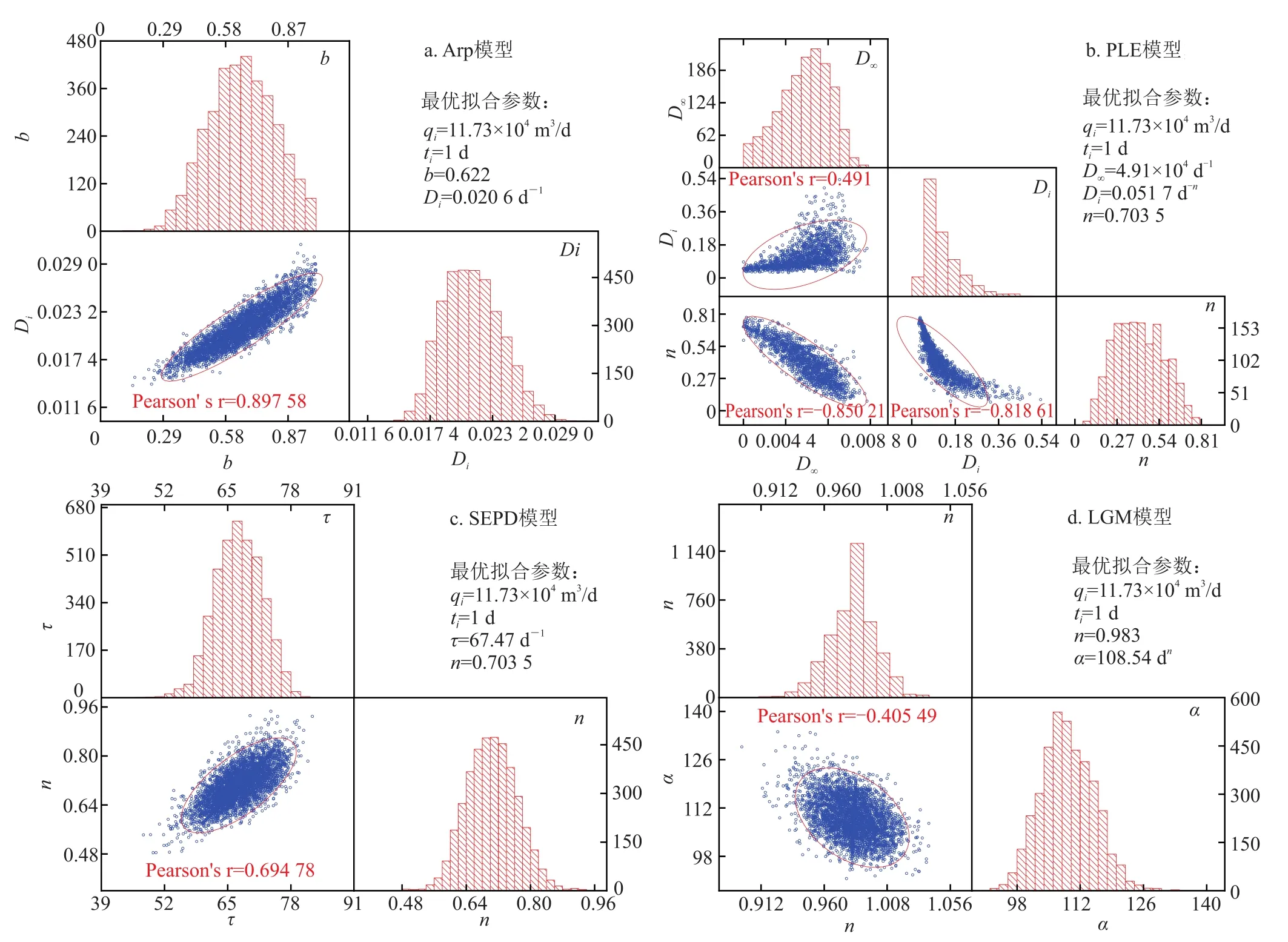
图6 不同模型间模型参数向量后验概率分布图
图7-a~b为Arps和PLE两种模型产量递减的80%置信域区间(P10~P90),PLE模型具有比Arps模型更小的产量递减置信域区间,这与模型参数的分布范围集中程度相关;图7-c为不同模型预测EUR的累积概率分布,其中Arps模型分布区间最大,PLE模型分布范围最小,进一步验证了产量递减置信域区间范围。
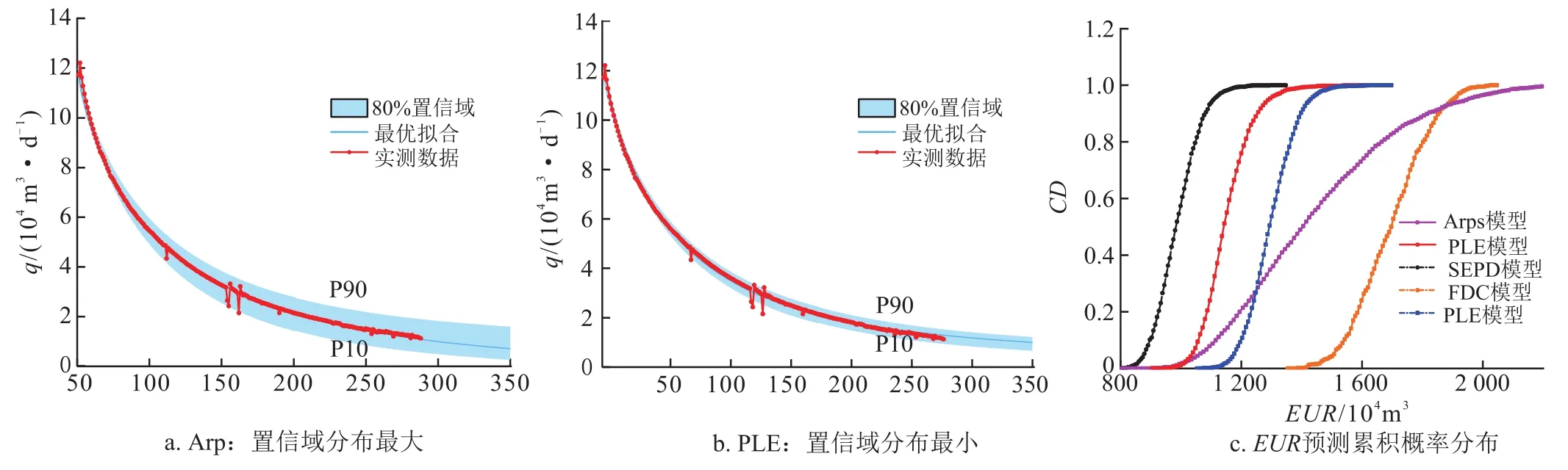
图7 Arps模型与PLE模型80%置信域的产量递减区间图
第二种情况:评价综合模型EUR预测结果的不确定性。由于每种模型接受率不同导致对应的预测EUR值个数不同,假设EUR样本数据独立同分布,采用自助法(bootstrap)进行有放回抽样[16],每种模型获得相同数量的EUR样本值(表2)。使用式(17)计算各模型的相对可信度,Arps、PLE、SEPD、LGM和FDC模型依次为13.2%、37.6%、15.9%、21.7%和11.6%。其中,PLE模型相对可信度最高,原因在于该模型能够很好地拟合连续的双线性+线性+拟稳态三个流态数据,模型参数约束性较好(即未知参数与流态数量相匹配),预测结果更接近真实值。
图8对比了不同单一模型和综合模型EUR不确定性评价结果。在单一模型中,FDC模型80%EUR置信域均高于EUR真实值,SEPD模型80%EUR置信域均低于EUR真实值,其余模型80%EUR置信域包括了EUR真实值。此外,Arps模型EUR预测的不确定性最大(标准差为269.11,对应80%置信域区间最大),PLE模型EUR预测的不确定性最小(标准差为147.56,对应80%置信域区间最小),PLE模型EUR预测的可靠性最强,EUR真实值位于50%EUR置信域(P25~P75)、对应的EUR的P50值(即中位线)与真实值最接近,这与图7-b预测结果以及模型相对可信度(PLE为37.6%)解释相一致。相对于特定单一模型,综合模型的80%EUR置信域范围介于各单一模型置信域范围之间,抵消了单一模型高估/低估预测的风险,而且EUR真实值位于20%置信域内(P40~P60),相对于PLE模型更为接近。原因为:①PLE模型残差的方差值最小[据式(5)、(9),PLE 模型对应的p(θj,mj|q)值最大],导致EURPLE预测值所占权重最大,FDC模型则情况相反;②综合模型同时考虑了其他模型的概率影响,避免了只选择特定模型所带来的“人为”风险。
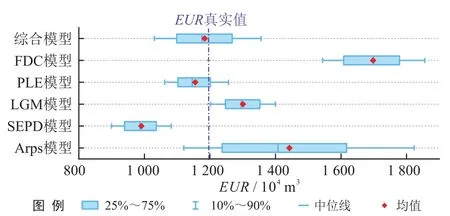
图8 不同模型间的EUR预测结果置信域分布范围图
按照以上分析方法及流程,选取川南地区25口页岩气井生产数据进行分析,生产历史从14个月到58个月不等,井间经历的流态差异性较大。井间各个模型成为“好”模型的优选概率模拟结果如图9,其中为优选模型的SEPD涉及井数为10口、PLE模型为7口、LGM模型为4口、PDC模型为3口、Duong模型为1口、Arps模型为0口,原因在于目前生产周期内气井均处于非稳态生产阶段,Arps模型的适用条件均弱于其他模型。同时可以得到没有一种模型适用于所有井,当模型间相对可信度值较为接近时,实际应用时需要参考综合模型EUR预测结果;当某种特定模型相对可信度远高于其他模型时(如14#、18#、22#井),说明该模型成为优选模型的概率高,在综合模型EUR预测结果基础上可重点参考该模型。
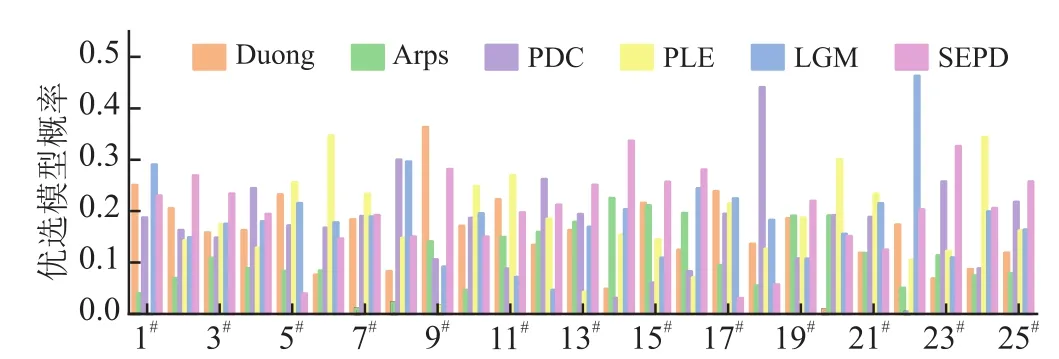
图9 25口页岩气井不同模型优选模型概率图
图10-a给出了使用单一及综合模型的25口井EUR预测中值,可以得到井间不同模型EUR预测值差异性较大,主要原因在于井间的流态演化不同、数据质量不同,也证实了选择单一优选模型时的不确定性。图10-b给出了25口井的综合模型不确定性EUR预测结果,所有井的均值都位于50%的EUR置信域内,在集合了各个模型优势基础之上有效降低了使用单一优选模型所带来的风险,对于EUR置信域范围较小的井(如1#、11#),对应的生产历史较长、流态特征清晰且个数较多、拟合效果好,各模型EUR置信域近似,这种井EUR预测结果可靠性强;对于EUR置信域范围较大的井(如3#、6#),其数据质量噪音较大、拟合效果差,各模型EUR置信域差异较大,这种井EUR预测结果可靠性较差。

图10 25口页岩气井单一模型及综合模型EUR预测结果
由此可见,综合模型EUR预测值的置信域具有合理分布区间,同时能够保证EUR真实值位于更小的置信域内(即获得EUR真实值的概率更高),降低了使用单一优选模型带来的风险。
4 结论
1)经验产量递减模型仅适用特定的某个或多个流动状态,超出条件即使获得较好的拟合效果也会导致不可靠的EUR预测结果;受制于模型参数、模型选择,EUR预测值具有不确定性,动态数据相对生产周期越短、模型参数越多、模型适用性越差,不确定性越高。
2)使用马尔科夫链—蒙特卡洛算法可以获得各个单一模型参数的后验概率分布及EUR不确定性预测区间,但模型预测的EUR置信域可能不包括EUR真实值,这取决于是否选定合适的模型。
3)以各单一模型参数的贝叶斯后验概率值为权重,加权平均获得的综合模型不确定性EUR预测置信域分布区间更为合理,提高了获得EUR真实值的概率,生产数据质量越差、优选模型越困难,使用单一模型预测EUR的不确定性和风险性越高,对应的综合模型法优势越明显。
