基于标注点分析字体结构与系统设计*
2022-12-10律睿慜
律睿慜,席 旭
(江南大学 人工智能与计算机学院,江苏 无锡 214122)
0 引 言
中国书法是一门古老的研究学科,是对字体书写和形式美学的研究。近年来,随着书法学习人群的增加,书法这类的艺术受到了更多的重视,也成为了计算机艺术[1]的研究内容。而利用人工智能(artificial intelligence,AI)技术创作书画艺术等研究的兴起,推动了书法与科技的结合,如机器创作书法、手写汉字识别[2,3]等应用的出现。为了更好地促进书法与技术的结合,推动其发展,有必要探索新方法研究书法艺术。其中,结构作为书法三要素之一,分析结构一直是书体研究的重点。但以往研究主要是根据对书法家及作品的经典个案分析总结书法特征;如石璐对魏晋女书法家[4]的研究,蔡显良分析王羲之对中唐书法的影响[5],高聿加对赵孟頫书法的解析[6]等。尽管能有效分析出书法特点,但对书法的量化研究不足。
针对上述问题,本文根据人文计算的理念,提出一种基于结构关键点研究楷书结构的方法,并参考机器学习领域的数据标注工具设计了一种用于字体图像标记的软件系统。利用开发的图像标注系统,通过被试者标注实验采集到不同书体的关键点位置坐标。筛选实验数据,再通过有效的标注数据计算字体结构的关键要素,以分析书体的结构特征。
1 方法与工作
1.1 结构量化方法
随着信息技术的发展,数字人文[7]这一计算机和人文学科相互交叉研究的新领域出现。借鉴其方法,本文利用专家定义标注的关键点计算分析楷书四大家书体的结构差别。关键点是定义在字体上能代表结构特征的特殊点。
本文研究的实验方法如下:
Step1 选取笔画、结构、间架等不同的研究汉字。
1)采集研究文字的对应书法图片;
2)定义并标记所有研究汉字的关键点。
Step2 开发用于字体标注的系统,在系统平台中设置好带有标注点的参考字与要标注的书法字;找到被试者标注字体获取坐标数据。
Step3 计算字体各关键点的均值坐标。通过坐标计算字体关键点之间的距离与角度等数值要素,以度量4种不同书体的结构特点。
1.2 实验文字的选取
研究书法[2~6]一般是通过具体的书法字分析书体,但汉字数量庞大,不能对所有字体都进行研究。因此,由Zipf定律,从黄自元92法的每一法中选取一个研究字,代表了常用的字体结构,且在文本中的出现频率较高。频率根据式(1)计算
C(m)=(m/n)×100%
(1)
式中C(m)即字频,其中语料规模n为20 000万字,m为文字出现次数,是在相关网站上爬取的文本信息。
1.3 书法图片的采集
利用标注关键点研究书法的另一个准备工作是书法图片的采集。本文用到的图片为颜柳欧赵4种楷书的碑文石刻等作品,来源于书法字典网,属于原书法家的字体,且图像质量较高,适合标注。但字典网中不能找到全部研究汉字的书法素材,缺失的字体图片利用楷书字体生成软件获取。
1.4 结构关键点的定义与标记
文字与图片确定后,再对不同汉字定义要标注的关键点。关键点标注在能代表字体结构要点的位置,而标注点的顺序依照汉字书写的笔画顺序。如图1为关键点的选取定义。关键点利用同心圆放置标记,同心圆中间的圆心为字体关键点位置,外部的圆环为辅助确定结构的关键点位置。再根据四色定理[8]给字体笔画用不同颜色染色,使相邻与相近笔画的同心圆颜色不同;让测试者能清晰的分辨出不同笔画并标记关键点;最后根据汉字笔顺给标记点标上序号。所有汉字关键点都按照这种方式严格设计制作。

图1 结构关键点的文字标记
这样就将对字体结构的分析转换为对结构关键点的计算以度量不同书法结构的差异。而结构关键点的选取和定义有严格的标准[9],要能代表字体结构特点;其选取规则与在笔画上的标号顺序为:起点(1),弯曲点(曲率最大处)(2),弯折点(2),相接点(2),相交点(2),特殊点(2),终点(3)。
为了判断选定的关键点能否代表结构要点,在Unity平台上对字体关键点进行线条连接。如图2为对Mac系统中Apple字体标注关键点的连接拟合,看到基本覆盖了整个字体骨架,表明定义的关键点代表了不同字体的关键结构特征。

图2 字体标注点的拟合仿真
1.5 关键点分析方法
本文提出的关键点分析字体结构有2种计算方式,一是通过关键点计算出笔画距离和角度分析结构,二是通过仿真字体骨架分析结构。如设关键点坐标为A(xm,ym),B(xn,yn),根据两点间的距离公式有
(2)
通过式(2)能得到存储字体两两关键点之间距离的对称矩阵X,如下所示
(3)
矩阵X关于对角线对称,可以将X合并成上三角矩阵分析字体笔画的长短,新矩阵U如下
(4)
同样,知道两点坐标后还可以计算字体笔画的方向角度矩阵,这样通过关键点就能计算出字体的距离、角度等数值。而利用数值就可以统计出笔画间距、字型大小、偏旁距离等几乎全部的结构特征。而对于学习者还可以参考定义的关键点学写结构。图2的拟合说明关键点代表了中文字体常见的结构要点。
2 标注系统的设计开发
数据标注是人工智能的基础工作之一,开始于斯坦福大学启动的 ImageNet 项目[10]。目前有多种用于图像标注的软件系统,但还没有专门应用标注字体图像的工具。为了方便收集标注数据,根据本文的实验方法,参考LabelImg,VOTT等标注工具的功能后,设计了一种用于书法图标注的系统。
如图3所示,系统由登录、跳转(结束)和书法字标记界面3部分组成。每个标记页面能设置要研究的书法字。而点击最后一页的按钮会进入下一轮书法字的标记测试或结束标注。标记界面有3个标注交互按钮,分别是“撤销”,“下一个”和“上一个”,有标记点的撤销、标注下个字和返回上个已标注汉字的功能。3个交互按钮能让测试者对每个书法字关键点都进行最精准的位置标记。并将以往LabelImg标注软件的矩形标记改为圆标记,记录的也是圆心坐标而不再是左上角的坐标,且数据记录格式由.xml改为.csv文件。

图3 字体图像标注软件
标记界面左边是利用软件平台自身的绘图功能制作好关键点的参考字,相当于专家标注字体。右面是要标注的书法字。参考字选用笔画粗细均匀的Apple印刷字,测试时参考字会显示一个圆标注点和对应颜色的笔顺线条指导用户在书法图上如何标注。对应书法图的下方会显示已标记的关键点和总标记点;最下方是汉字目录,也会改变颜色提示测试进度。当标注完成一个字体后,目录中的汉字由白色变成黄色表明该字体的位置点标记完成。标注的交互方式是鼠标点击,每点击一次就会产生一个标记点位置坐标并记录,然后系统根据坐标计算关于字体结构的矩阵并存储。
3 标注实验
3.1 实验设计与被试者
字体标注系统完成后,采用众包标注[11]模式。在本地找到130名数字媒体专业的大学生为标注人员,男女比例为1︰1。通过他们对系统中字体的标记收集到书体的关键标注点数据,用于度量结构,并调查分析大众对书法结构的普遍差异感受。
3.2 实验过程
实验的汉字共有90个,而每个字又有4种不同的书法字;因此实验时随机将学生分为10个小组标注字体。系统为每组平均分配约15个不同的研究字,确保每个字都最少经过16人标记。系统会自动取得标注点的位置并记录,大约0.5 h学生就能完成实验。
3.3 数据记录
系统收集到关键点的标记结果后,会将标注点坐标记录在以学生姓名与学号命名的文件夹中。先记录字体各标注点的坐标值;再根据关键点坐标值计算出关于字体结构的2个矩阵,最后存储到文本中。
4 结果与分析
4.1 数据预处理
因为每位学生单独标注,为得到小误差的结构关键点坐标数据,先对标注点进行分类。将不同学生同一字体的标注数据汇集到一个文件中,再利用系统中的线条对数据有效性进行可视化复原验证;使文件中每一个位置点都是去掉无效数据后13人以上的标注数据。最后利用Python的Pandas和Matplotlib函数库对标注的关键点坐标进行运算,取得其平均值。均值代表实验所期望获取的各字体关键点位置数据。
4.2 字体结构矩阵
学生标注时系统会根据在字体上的标注信息实时创建2个数值矩阵,分别存储着字体两两关键点之间的长度和角度信息。其中,距离矩阵根据式(2)计算,其中,m,n取值为{0,1,2…,i-1,i}。i为一个字体定义的关键点数量,i越大,矩阵的维度越高。而角度矩阵的计算也与距离矩阵类似。
如图4为系统后台计算得出的字体结构矩阵文件。矩阵最直接的作用是把字体结构数据化,将其笔画的长度和书写角度转换为数值存储到矩阵。距离矩阵是两两关键点的长度信息,可以合并成主对角线以下为0的上三角矩阵;而角度矩阵代表笔画书写的角度。2个矩阵可以用来度量字体的结构特征。如从汉字“下”的赵体和颜体距离矩阵相比,横笔画的长度类似,而竖笔画赵体更短。从角度矩阵看出柳体“土”比欧体“土”的第一笔横向笔画的倾斜角度更大。

图4 结构信息矩阵
矩阵的意义是首次采用数值表示与分析结构。如2个书法字的距离矩阵差值,对应到结构上就是不同书法笔画写法偏短或偏长,准确存储并显示了每个字体笔画的长度和角度信息。标注系统为字体创建的距离与角度矩阵为结构特征的初步分析结果。
4.3 结构特征统计(任务1)
4.3.1Z值统计分析字型
仅靠字体矩阵难以直观统计字体更多的结构特点,而且矩阵存储的字体数据为相对量而非绝对量。为了对结构做更准确分析,需利用特殊关键点度量结构。从关键点中找到能度量字型“胖”或“瘦”的特征点,特征点代表了字体结构的高度和宽度。根据本文关键点定义方法,可以找出代表字体宽高的特征点。设X,Y,Z三个量,Y为字体高度,X为宽度,则
(5)
式中Z为字体形态值,可知值域为Z∈(0,+∞),这样设定可以用来衡量字型的“胖”和“瘦”。如Z为b时代表字体结构方正,为c时偏“瘦”,为a时偏“胖”。表1就是利用Z值度量字体的结果。

表1 颜体和柳体部分字的Z值
限于篇幅表1只列出了部分文字,结果显示柳体字相比颜体Y/X的值更大,说明柳体字型更偏瘦,而颜体字型更丰肥,这也体现了“颜筋柳骨”的特征。
4.3.2 笔画角度分析字体倾斜度
结构中正度、笔画倾斜度等结构特征,利用距离难以度量,需要引入数学角度统计分析。将单个笔画看成直线或曲线,利用标注点计算斜率的公式为
(6)
式中 (x1,y1),(x2,y2)为字体上2个关键点的坐标,k为笔画的斜率,由k计算出竖、横、撇等笔画的角度a,然后通过角度度量字结构的端庄与倾斜。如表2是两种书体部分汉字笔画的斜率和角度对比。主要统计对应的横向笔画,因为斜率为正,利于分析。
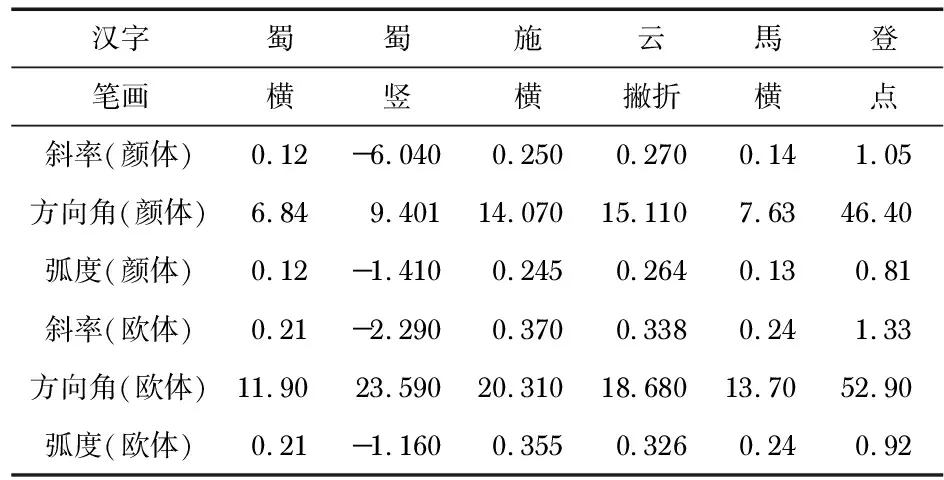
表2 颜体和欧体字部分笔画的斜率与角度
由表2结果看出,欧体笔画比颜体倾斜程度普遍更高。下文将利用Z值与角度统计其他字体的结构。
4.4 结构特征统计(任务2)
将数据结合参数样条曲线[12]仿真分析书体结构的保存或损失程度。在标注系统中利用Bezier曲线能将位置点数据可视化以研究书法结构。曲线由Pierre Bezier提出,对于给定的点P0,P1,…,Pn,有

(7)
利用式(7)结合关键数据就能仿真出字体形态,且去除了字体的笔法等要素,只保留结构进行分析。
如图5从左到右依次是颜、柳、欧、赵字体,与对应的字体曲线仿真图对比后,可以看到,赵体的关键点难以覆盖住连笔笔画;其结构偏离了正楷字,而带有行书风格的特征。仿真字体后的笔画缺失显示赵体的书写更随意,学生也不会将连笔当作笔画的终点或起点。在系统中对所有字体仿真并与原图对比后,统计出各书体带有粘连笔画的文字数量为:颜体:1,柳体:1,欧体:3,赵体:24。表明:赵体的连笔字远超其他字体,也就是有连贯的结构特征。了解这个特征很重要,如知道了关于楷书的笔画爬取算法就不适用于赵体字。因为粘连笔画较多,要采用新的提取算法才能准确分离赵楷的笔画。

图5 书法字和曲线字体的对比
4.5 结构特征统计(任务3)
表3利用前文方法统计分析结构的结果。表中Z值是全部研究汉字的总和,横向总斜率是随机从每个研究字体抽样相同的共150个横向笔画计算得出。
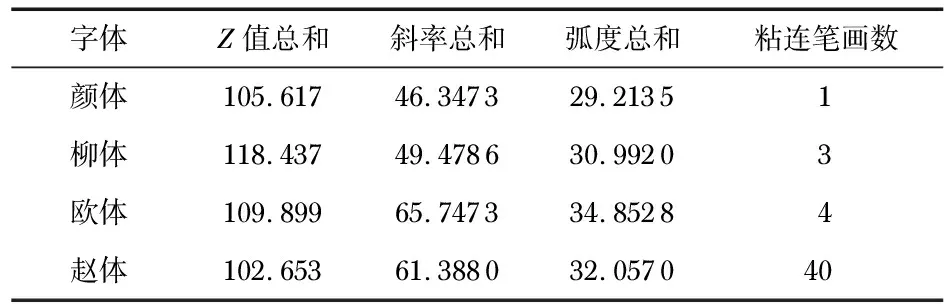
表3 字体结构特征的统计结果
从Z值中看出字形“胖瘦”程度为:赵体>颜体>欧体>柳体。从笔画斜率和角度统计看出结构中正程度为:颜体>柳体>赵体>欧体。而字体粘连笔画的数量多少为:赵体>欧体>柳体>颜体。
上述为总体上的结果。表3除粘连笔画外,其他统计量差别不是很大。如从Z值看,柳体字形只是总体上比赵体细长,计算时发现个别赵体字比柳体字的Z值更大,斜率也类似。这表明:书法结构的普遍特征在单个字上或许不存在,显示了每个字体的特殊性。
5 结束语
本文提出了一种利用标注字体关键点研究结构的方法,并通过众包标注获取的数据对颜柳赵等书体结构进行计算度量。统计结果表明,关键点分析能发现更准确的结构差异,以后可以优化该方法应用到隶行书的研究中。设计的标注工具在书法图像集标注、结构研究等方面也有应用前景。未来将尝试将卷积神经网络等技术融入到系统中,以提高结构分析的效率。
