Residual Network with Enhanced Positional Attention and Global Prior for Clothing Parsing
2022-12-09WANGShaoyu王绍宇HUYunZHUYian朱艾安YEShaoping叶少萍QINYanxia秦彦霞SHIXiujin石秀金
WANG Shaoyu(王绍宇), HU Yun(胡 芸), ZHU Yian(朱艾安), YE Shaoping(叶少萍), QIN Yanxia(秦彦霞), SHI Xiujin(石秀金)
School of Computer Science and Technology, Donghua University, Shanghai 201620, China
Abstract: Clothing parsing, also known as clothing image segmentation, is the problem of assigning a clothing category label to each pixel in clothing images. To address the lack of positional and global prior in existing clothing parsing algorithms, this paper proposes an enhanced positional attention module (EPAM) to collect positional information in the vertical direction of each pixel, and an efficient global prior module (GPM) to aggregate contextual information from different sub-regions. The EPAM and GPM based residual network (EG-ResNet) could effectively exploit the intrinsic features of clothing images while capturing information between different scales and sub-regions. Experimental results show that the proposed EG-ResNet achieves promising performance in clothing parsing of the colorful fashion parsing dataset (CFPD) (51.12% of mean Intersection over Union(mIoU) and 92.79% of pixel-wise accuracy(PA)) compared with other state-of-the-art methods.
Key words: clothing parsing; convolutional neural network; positional attention; global prior
Introduction
Clothing parsing is a specific form of semantic segmentation, which aims to assign semantic labels of clothing items or background to each pixel in the image. These semantic labels provide high-level semantic information varying from the background to the category, position, and shape of each clothing item in an image, which makes clothing parsing crucial for many clothing-centric intelligent systems, such as clothing retrieval[1], outfit recommendation[2], and clothing match[3]. Despite the potential research and commercial value of clothing parsing in practical applications, it is still facing many problems. This is because clothing parsing as a domain-specific problem has the following characteristics. First, unlike the general semantic segmentation task, the scale of clothing items varies greatly. As shown in Fig. 1, some clothing items can have very large spatial representations,e.g., the dress in Fig.1(a), while other items can have significantly smaller representations in the image,e.g., the belt and sunglasses in Fig. 1(a). Second, some clothing items have many similarities in appearance. For example, the pants in Fig. 1(c) and the jeans in Fig. 1(d) have the similar appearance but are classified in different categories. Finally, cluttered backgrounds, complex human poses shown in Fig.1(b), self-occlusions, and variations in colors and styles all make it a challenging task.

Fig. 1 Some example images in dataset: (a) with large variations in size; (b) with complex human poses; (c) and (d) with similar appearance
Recently, many studies have focused on using deep convolutional neural networks to solve image segmentation problems, some of which have also been applied to the field of clothing parsing. One common approach is to use fully convolutional network (FCN)[4]and fuse additional feature branches at a later stage of the network to improve the performance of clothing parsing. For example, Tangsengetal.[5]extended the FCN architecture by proposing a side-path outfit encoder to encourage combinatorial preferences. Khuranaetal.[6]proposed a two-stream architecture that used a standard FCN network in one stream and exploited hand-crafted texture features in the second stream. The model helps to disambiguate clothing items that are similar in shape but different in texture. Besides, Martinsson and Mogren[7]integrated feature pyramid networks[8]with a backbone consisting of ResNeXt[9]architecture to highlight the importance of cues from shape and context.
The above studies exploit the characteristics of clothing items such as diverse appearance variations and complex texture information, but none of these approaches consider the positional information of clothing. We notice that the distribution of clothing categories in different positions is imbalanced. For instance, socks and shoes always appear in the lower part of the image, sunglasses always appear in the upper part, while the middle part contains various relatively large objects. To drive the convolutional neural network to consider the spatial positional information of clothing items, an enhanced positional attention module (EPAM) is introduced in the network. It extracts contextual information in the vertical direction of the clothing image and then uses this information to compute attention weights to estimate how channels should be weighted during pixel-level classification of the clothing parsing. Additionally, a global prior module (GPM) for clothing parsing is proposed, which captures different levels of details in an image at multiple scales, and it exploits global image-level priors to understand different clothing items by contextual aggregation of different regions. The experimental results show that the proposed clothing parsing method based on positional attention and global prior achieves the best performance compared with previous methods.
1 Proposed Method
1.1 EPAM: adaptive feature recalibration
When humans analyze and recognize clothing items, they have prior knowledge on the vertical position of specific objects (e.g., shoes and hats appear in the lower and upper parts, respectively). Inspired by height-driven attention networks (HANet)[10], which describes the structural prior involved in urban-scene images depending on the spatial position, we propose an EPAM in our model to get better parsing performance.
As shown in Fig. 2,Xl∈RCl×Hl×WlandXh∈RCh×Hh×Whdenote the lower-level and higher-level feature maps in the network,Cis the number of channels, andHandWare the height and width, respectively. Given the lower-level feature mapXl, the module will generate a channel-wise attention mapA′∈RCh×Hhthat matches the channel and height dimensions of the higher-level feature mapXh.
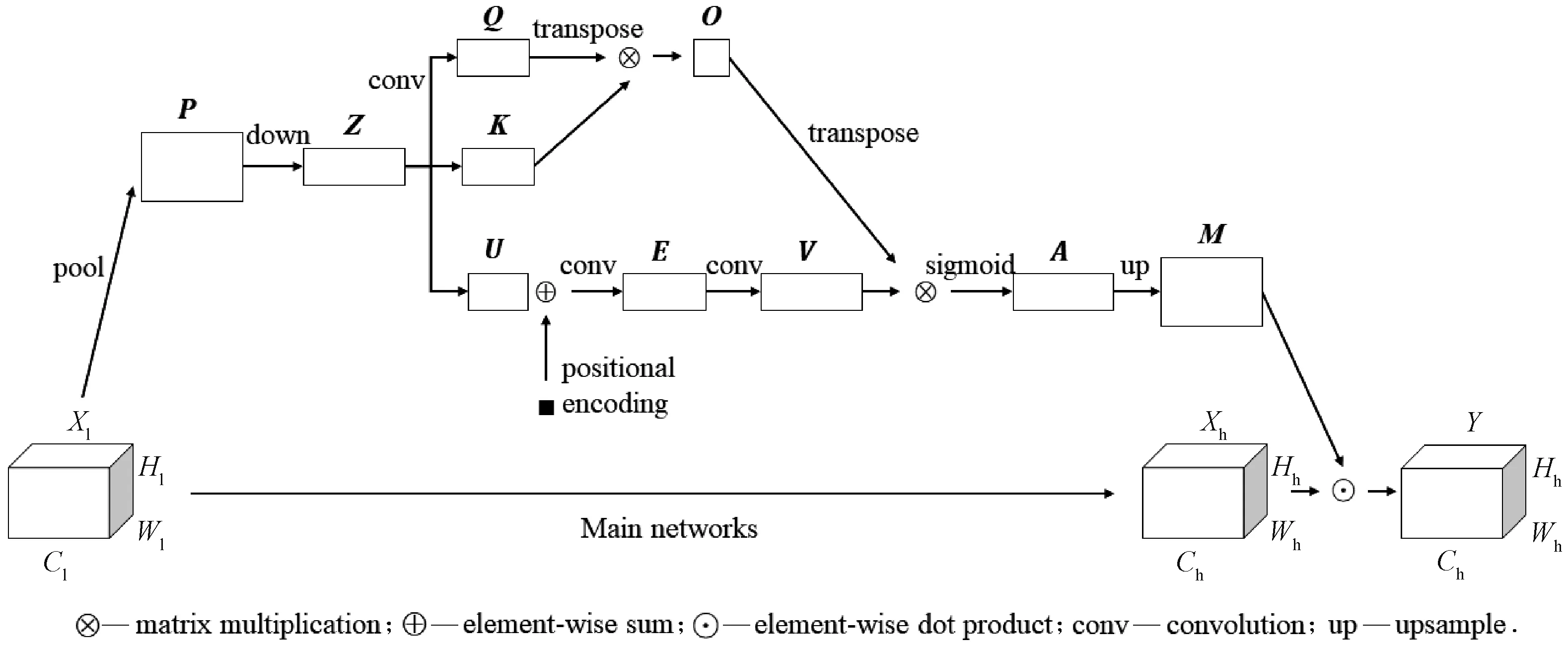
Fig. 2 Architecture of the proposed EPAM

O=QTK.
(1)

A=σ(V′OT),
(2)
whereσis a sigmoid function.

(3)
Through this series of steps, the spatial relationship in the vertical direction of any two pixels is modeled. The network can scale the activation of channels according to the vertical position of the pixels to obtain better parsing results.
1.2 GPM: multi-scale contextual parsing
Clothing items contain objects of arbitrary size. Several small-size items, like the belt and sunglass, are hard to find, but they are as important as items in other categories. Conversely, big objects may exceed the receptive field of the network and lead to discontinuous predictions. In order to deal with objects of different scales and take into account contextual information, a GPM for clothing parsing is proposed, as shown in Fig. 3.

Fig. 3 Architecture of the proposed GPM
The GPM includes five branches {bk,k= 1, 2, …, 5}.Starting from the second branch, an adaptive average pooling is first used in each branch to reduce the spatial size of the feature maps to 2k-3. This is followed by a 1×1 convolution layer that reduces the channel size to 512. Whenk> 2, we use pyramidal convolution[13]withk-2 layers, which contains different levels of kernels of different sizes and depths, thus being able to parse the input at multiple scales. Then a 1 × 1 convolutional layer is applied to fuse the information from different scales. The feature maps of the last four branches are upsampled to the initial size before pooling and concatenated with the original feature map of the first branch. Finally, a 3 × 3 convolutional layer is used to merge the captured all levels of contextual information. Thus, the convolution kernel can cover different ranges of the input image.
2 Experiments
2.1 Dataset and metrics
We evaluated our clothing parsing method on the colorful fashion parsing dataset (CFPD)[14]. The dataset consists of 2 682 images annotated with superpixel-level, each of which has different backgrounds, poses, clothing categories,etc. The images were randomly divided into training set, validation set, and test set in the ratio of 78%, 2%, and 20%, respectively. It contains 23 clothing category labels, including a background class.
Figure 4 presents the class distribution of the dataset on the vertical position (excluding background and skin). Figure 4(a) shows the average number of pixels assigned to each class in a single image. Figure 4(b) shows the class distribution of each part of the image that is divided into three horizontal sections. They-axis is on a log scale. By comparing Figs. 4(a) and 4(b), it can be observed that the class distribution has a significant dependence on the vertical position. That is, the upper part of the image is mainly composed of hair and face, while the middle part contains a variety of relatively big objects. In the lower part, shoes are the main objects. Therefore, being able to identify the spatial position of a given arbitrary pixel in an image would be helpful for pixel-level classification in clothing parsing.
We used pixel-wise accuracy (PA) and mean Intersection over Union (mIoU) for quantitative performance evaluations. The cross-entropy loss function was used in the training process.
2.2 Implementation details
The EPAM and GPM based residual network[15](EG-ResNet) was implemented in PyTorch, and the overall framework of the network is shown in Fig. 5. For a given input image, the pretrained residual network (ResNet) model was first used to extract the feature map. In order to further enlarge the receptive field, we removed the last two downsampling layers and used dilated convolutions[16]in the subsequent convolution layers, and the final feature map size was 1/8 of the input image. On top of the map, we used GPM to parse it to obtain different levels of contextual information. It was followed by an upsample layer and a convolution layer to restore the feature map to the initial input image size and generate the final prediction map. EPAM was added to the network after the fourth stage because the higher-level features are more correlated with the vertical position. Then, the computed attention map was element-wise multiplied with the feature map obtained in the fifth stage.

Fig. 4 Pixel-wise class distributions on average number of pixels assigned to each class in (a) single image; (b) each of upper, middle and lower parts

Fig. 5 Architecture of the proposed clothing parsing method
We used Adam algorithm for optimization with a batch size of 4 and an initial learning rate of 0.000 02. During the training process, the learning rate was decayed according to the polynomial learning rate policy with power 0.9. In the training phase, we randomly cropped patches with 400 pixels×400 pixels as the input to the network and employed data augmentation to avoid overfitting, including random scaling in the range of [0.5, 2.0], random rotation in the range of [-10°, 10°], random horizontal flipping and random cropping. In the inference phase, a sliding window strategy with a stride of 64 pixels×64 pixels was used to get the final parsing results.
2.3 Clothing parsing results and discussion
2.3.1Ablationstudy
In order to verify the effectiveness of each component of our method, we conducted experiments with several settings, including using GPM or EPAM. The baseline applies a 3 × 3 convolutional layer as a head on the output feature maps provided by the backbone.
As shown in Table 1, each part of the proposed method is very helpful for our final results and represents a significant improvement compared with the baseline. By using GPM, we achieved a 2.85% improvement in mIoU over the baseline method. By incorporating the spatial positional prior, the performance of the baseline improved from 47.12% to 47.69% of mIoU. This indicates that the positional information has an important impact on the performance of clothing parsing and is an effective way to improve the parsing accuracy.

Table 1 Ablation experiments of the proposed method on test set
2.3.2Comparisonwithpreviousmethods
To verify the advantages of our EG-ResNet, we compared its performance with four models: classical FCN-8s, pyramid scene parseing network(PSPNet)[17], DeepLabv3[18], and CCNet. Table 2 shows the quantitative comparison of these methods. It can be found that compared with FCN-8s, all other models improved the parsing performance by a large margin, demonstrating the advantage of considering contextual information under the clothing parsing task. The CCNet achieves better performance by capturing full image dependencies to integrate contextual information. In contrast, our EG-ResNet exploited the intrinsic features of the clothing images and used a combination of positional prior and global prior to achieve 51.12% of mIoU and 92.79% of PA.
More visual results on the test set are shown in Fig. 6. The figure shows the input images, the manual annotations, the outputs of FCN-8s, PSPNet, DeepLabv3, CCNet and the proposed EG-ResNet from left to right, respectively. For some small objects such as the bag, the proposed method can give satisfactory results. This method can also successfully parse some big objects such as dress. Furthermore, our method can handle edges and details and even show some better visual results than manual annotation. For example, the last example in Fig. 6 shows the incorrect annotation, while our method gives accurate parsing results.

Fig. 6 Visualization of the parsing results
3 Conclusions
In this paper, we proposed a novel method based on positional attention and global prior for clothing parsing. Specifically, considering that the distribution of clothing categories is highly dependent on vertical position, we incorporated the positional information of clothing items into our clothing parsing method. An EPAM was proposed to collect contextual information in the vertical direction of each pixel and enhance the spatial modeling capability of the network. Moreover, we noticed that the clothing items are partially occluded and display different scales. A GPM was proposed to process different levels of contextual information and improve the ability of the model to extract multi-scale features. As demonstrated by experiments on the CFPD dataset, our EG-ResNet produced more accurate and reasonable parsing results than other methods. In the future, we plan to explore the innovation of the parsing pipeline and consider the impact of more prior information on clothing parsing.
杂志排行

Journal of Donghua University(English Edition)的其它文章
- Evaluation of Tactile Comfort of Underwear Fabrics
- Classification of Young Females’ Body Shape in Jiaodong Area Based on 3D Morphological Characteristics
- Property of Polyimide/Flame-Retardant Viscose Blended Fabrics
- Electromagnetic Transmission Characteristics of Y-Shaped and Y-Ring-Shaped Frequency Selective Fabrics
- Adaptive Neural Network Control for Euler-Lagrangian Systems with Uncertainties
- Adaptive Single Piecewise Interpolation Reproducing Kernel Method for Solving Fractional Partial Differential Equation