基于模型驱动辅助MPA的SCMA多用户检测算法*
2022-12-07郭红耀
邵 凯,郭红耀
(重庆邮电大学 通信与信息工程学院,重庆 400065)
0 引 言
稀疏码分多址接入(Sparse Code Multiple Access,SCMA)由低密度签名(Low Density Signature,LDS)演进而来,是一种基于码域的非正交多址接入技术。SCMA将高维调制器和稀疏扩频器联合在一起对数据进行编码,该编码方式实现了用户数据过载发送,同时由于码字具有稀疏特性,降低了各用户相互之间的信息干扰,从而提高了系统整体容量。SCMA系统主要有两个问题亟待解决:发送端的码本优化和接收端的译码器设计。在工程应用中,高效的译码方案是SCMA能否成为5G空口技术[1]的重要标志,因此本文针对SCMA系统接收端的译码方案展开研究。
SCMA系统接收端通常采用消息传递算法(Message Passing Algorithm,MPA)进行译码[2],该方案可以有效地接近最优的最大联合后验概率(Maximum Joint a Posteriori Probability,MAP)[3]。MPA算法可利用码本的稀疏性降低算法复杂度,但是需要通过多次迭代实现对用户数据的检测,随着用户数量和调制阶数的增加,计算复杂度将随着用户数量的增加呈指数级增长。为了降低接收器的计算复杂度,研究人员常从减少参与更新的消息数量[4-9]和减少算法迭代次数[10-15]两个方面入手。
随着人工智能的发展,深度学习已成功应用于通信领域,尤其在信道均衡以及信号检测中取得了很大突破[16-17]。对于SCMA系统,文献[18]采用并行神经网络结构完成对SCMA接收端信号的学习和检测;文献[19]提出深度学习辅助的SCMA算法,其自适应地构造了将误码率(Bit Error Rate,BER)最小化的码本,并使用基于深度神经网络的编码器和解码器学习了编码方式。由以上文献所提出的SCMA系统接收端译码改进方案,相对于传统MPA算法的6次迭代,基于传统角度的改进方案都在一定程度上牺牲了BER性能,而采用深度学习的改进方案在一定程度上降低了BER,但是均在一定程度上牺牲了复杂度。为得到获取更好的通信质量,需要在低复杂度的基础之上提升BER性能,更利于在硬件上的实现,从而提升系统的整体译码性能。在深度学习中,基于模型驱动的方法[20]将具有性能保证的传统算法与神经网络的优点融合在一起,形成新的类似神经网络中的层级结构,能加速算法的收敛。因此本文基于这种利用网络模型更新算法中关键参数的思想提出基于模型驱动辅助MPA的SCMA多用户检测算法(Model-driven Assisted MPA,MD-MPA),对MPA算法每轮迭代过程中资源块节点、用户节点信息更新结束后得到的信息矩阵以及输出的概率矩阵之后添加参数,通过神经网络的反向传播算法(Adam)更新参数,最终将训练好的参数部署于MPA算法,使改进算法具有更低的计算复杂度以及更好的BER性能。
1 系统模型
1.1 SCMA系统模型
SCMA作为一种具有应用前景的稀疏码多址技术,用户数据流的lbM个编码比特映射到K维码字构建的稀疏码本,且映射后的码字具有稀疏性。由于发送数据的用户个数一般小于正交资源块的个数,因此SCMA系统可以实现多用户发送数据过载,从而提高数据的传输速率以及信息容量。SCMA系统上行链路模型如图1所示。在系统的发送端有J=6个用户在K=4个资源块上传输数据,因此过载因子可被定义为μ=J/K(通常μ≥1)。对于SCMA上行链路通信系统,SCMA的码本映射过程可以表示为f:Blb M→X,其中,M表示码本的基数大小,X表示用户码本,且码本大小|X|=M。SCMA系统中第j(j=1,2,…,J)个用户发送的二进制比特数据映射过程可被表示为xj=f(bj),xj=[x1,j,x2,j,…,xk,j]为第j个用户信息映射后的码字,bj表示第j个用户的二进制比特流数据。当所有用户信息全部映射完成后,J个用户的数据以非正交的形式叠加在K个时频资源块上进行发送。在信号发送过程中,假设所有用户的数据是同步复用的,在接收端接收到的叠加信号如式(1)所示:
(1)
式中:y表示系统接收端所有用户的信号叠加;hj表示第j个用户的信道信息;xj表示用户j的映射码字;n表示加性高斯白噪声。

图1 SCMA系统模型
为方便研究SCMA系统中资源块和各个用户信息之间的关系,图2(a)给出了SCMA系统发送端低密度子载波扩频示意图,图中描述为6个用户占用4个资源块,横坐标每一行表示一个用户的稀疏码字,且一个用户占用两个资源块;纵坐标每一列表示1个资源块的稀疏扩频序列,且一个资源块携带3个用户信息。图中白色方块表示对应资源块不携带用户信息,非白色方块表示对应资源块携带用户信息。
SCMA系统接收端的复用模型可以用图2(b)和图2(c)描述。通过因子图模型可以更清楚地看到各个资源块节点FNK={f1…f4})和用户节点VNJ={v1,v2,…,v6}相互之间信息的传递关系,并且可以通过矩阵F(K,J)来简化因子图模型:当矩阵F(K,J)的第j列k行元素为1时,说明第j个用户占用了第k个资源块;当矩阵F(K,J)的第k行第j列元素为1时,则说明第k个资源块携带了用户j的信息。SCMA系统通过这种用户和资源块之间的稀疏连接,有效地实现了用户信息过载,且在很大程度上降低了用户之间的信息干扰,从而更有利于在接收端通过译码算法利用接收的信号来预测发送端各个用户发送的数据。
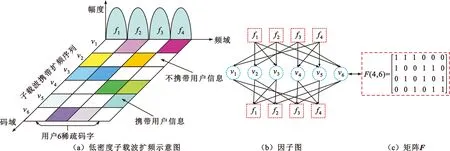
图2 低密度子载波扩频示意图以及因子图与矩阵F的对应关系
1.2 MPA算法
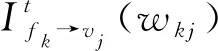
(2)

(3)
资源块节点的信息更新完成后,将所有用户节点信息进行更新,更新过程如式(4)所示:
(4)
式中:ξj表示与用户节点vj相连的资源块节点集合;ξk/{j}表示与vj且除了fk以外的资源块节点的集合。
第二步,用户节点以及资源块节点信息更新完成后计算概率值,计算过程如式(5)所示:
(5)
式中:tmax表示最大迭代次数。
第三步,通过软判决计算用户发送的比特信息,计算过程如式(6)所示:
(6)
2 多用户检测改进算法

2.1 改进MPA译码方案

(7)
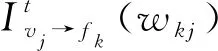
(8)
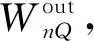
(9)
当算法迭代过程中的计算结果由上式重新计算后只需将预测值Qnj(wj)求出,不需要再进行原算法中式(6)的软判决操作,直接通过预测值的最大索引位置判断用户发送的比特数据。
2.2 训练模型与训练参数

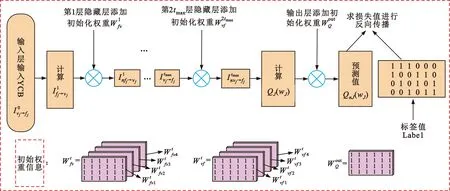
图3 MD-MPA训练参数W模型图
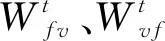
(10)
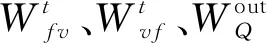
2.3 复杂度分析
MulMD-MPA=tmaxKNfM(Nf)(2Nf+1)+
tmaxJNvM(Nv-2)+2JM2,
(11)
AddMD-MPA=tmaxKNf[(Nf+1)M(Nf)-M],
(12)
EXPMD-MPA=tmaxKNfM(Nf)。
(13)
3 仿真与分析
本节对SCMA系统在接收端与不同传统算法在不同迭代次数、不同信噪比以及复杂度三个方面进行比较。为了体现实验的公平性,发送端码本设计采用华为发布的码本,控制用户个数、资源块个数相同,并且采用相同的信道条件。在对比实验中,所采用的传统方案为MPA算法[3]、串行SMPA(Serial-MPA)算法[10]、基于残差值的RMPA(Residuals-MPA)算法[11]、外部信息自适应更新的AU-MPA(Adaptive Updating-MPA)算法[14]译码方案。仿真参数设置如表1所示,信道为高斯白噪声信道。

表1 仿真参数
3.1 收敛速度
图4所描述的是MD-MPA算法和传统MPA算法、串行SMPA算法、残差值RMPA算法、外部信息自适应更新的AU-MPA算法在信噪比相同、迭代次数不同时的BER性能仿真对比结果。

图4 收敛速度对比
实验分别在8 dB和14 dB信噪比下进行仿真,从图中可以看出,各算法的误码率随着信噪比的增加而降低,同时在信噪比相同的情况下,MPA算法需要6次迭代数据收敛,串行SMPA算法、残差值RMPA算法、外部信息自适应更新的AU-MPA算法需要3次迭代数据收敛,本文提出的MD-MPA算法需要4次迭代数据收敛,且第3次迭代时误码率已低于串行SMPA算法、残差值RMPA算法、外部信息自适应更新的AU-MPA算法。并且可以从图中看出,MD-MPA算法相较于MPA算法,在算法收敛之前,随迭代次数的增加误码率逐渐降低,不仅可以通过少于MPA两次迭代使数据收敛,同时精度上也得到了提升。这是由于MD-MPA算法添加由模型训练更新的权重值Wnew后,可以获得更佳的迭代效果,从而使得MD-MPA算法的译码性能得到提升。MD-MPA算法相较于串行SMPA算法、残差值RMPA算法和外部信息自适应更新的AU-MPA算法虽然数据收敛迭代次数要多1次,但是在BER性能上要优于串行SMPA算法、残差值RMPA算法和外部信息自适应更新的AU-MPA算法。从仿真结果可知,MD-MPA算法的计算复杂度要低于MPA算法,BER性能要优于SMPA算法以及残差值RMPA算法和外部信息自适应更新的AU-MPA算法。
3.2 BER分析
图5描述的是MD-MPA算法和传统MPA算法、串行SMPA算法、残差值RMPA算法、外部信息自适应更新的AU-MPA算法在分别在不同信噪比下BER性能仿真对比结果。
图5 误码率性能对比
从图中可以看出,当MD-MPA算法和传统MPA算法、串行SMPA算法、外部信息自适应更新的AU-MPA算法以及残差值RMPA算法的迭代次数均为3次时,MPA算法和MD-MPA算法的数据均没有收敛,且MPA算法的BER最高。虽然MD-MPA算法在3次迭代后的数据同样没有收敛,但此时MD-MPA算法的BER已经低于MPA算法,基本和串行SMPA算法、外部信息自适应更新的AU-MPA算法以及残差值RMPA算法的BER相同。MD-MPA和MPA算法分别在迭代4次、6次后数据收敛。从图中可以看出,MD-MPA算法收敛后,尤其是随着信噪比的增加,MD-MPA的BER明显低于MPA算法、串行SMPA算法、残差值RMPA算法、外部信息自适应更新的AU-MPA算法。
3.3 复杂度对比
图6描述的是MD-MPA算法和传统MPA算法、串行SMPA算法、残差值RMPA算法、外部信息自适应更新的AU-MPA算法在数据均收敛后的各个算法所需要乘法计算次数、加法计算次数、指数计算复杂度分析对比结果。

图6 复杂度对比
通过图6的统计结果可知,MD-MPA相较于MPA算法减少了29.76%的乘法运算、33.33%的加法运算、33.33%的指数运算。串行SMPA算法、外部信息自适应更新的AU-SCMA算法以及残差值RMPA算法的计算量近似相同,MD-MPA算法相较于串行SMPA算法、外部信息自适应更新的AU-SCMA算法以及残差值RMPA算法增加了40.47%乘法运算、33.33%的加法运算以及33.33%的指数运算。结合图4可知,MD-MPA算法不仅计算量低于MPA算法,且BER低于MPA算法。虽然MD-MPA算法计算量大于串行SMPA算法、外部信息自适应更新的AU-MPA算法以及残差值RMPA算法,但是其BER性能要优于它们。通过对仿真结果的分析可知MD-MPA算法的综合译码性能优于MPA算法、串行SCMA算法、外部信息自适应更新的AU-MPA算法以及残差值RMPA算法。
4 结束语
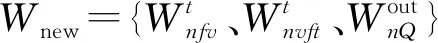
本文方案只研究了在加性高斯白噪声信道下的性能仿真实验,而实际的通信信道更为复杂,后续研究将针对复杂信道条件展开深入研究,同时SCMA系统存在峰均功率比(Peak to Average Power Ratio,PAPR)过高等问题,如何降低该系统的PAPR同时不会造成过高的线性失真也将是后续研究工作的重点 。
