Apriori算法在卫生标准问卷调查数据挖掘中的应用及R语言实现
2022-12-02刘拓俞铖航黄烈雨
刘拓 俞铖航 黄烈雨
问卷调查是开展卫生健康标准研究的主要方法之一。既往卫生健康标准研究中,问卷调查数据的统计分析多采用描述性统计分析,对于调查对象选择问卷中各题目选项之间的关联关系关注较少。既往研究表明,关联规则(association rules)可以从大量数据中挖掘各属性指标或指标组合之间的隐藏关联关系,从而为优化管理提供技术线索;而Apriori算法是其中最为常用的算法之一[1-5]。R语言作为一种免费的开源性数据分析工具,已有大量优秀的包(package),可以适用于多种场景和统计功能,且更加适合当前知识产权保护意识及软件正版化逐渐增强科研环境[6]。本研究拟以某次职业病诊断标准应用情况调查数据为例,归纳Apriori算法在卫生健康标准问卷调查数据中的应用方法、注意事项及R语言实现方法,为进一步完善卫生健康标准问卷调查数据挖掘方法体系提供参考。
1 资料与方法
1.1 数据来源
以课题组利用自制问卷,于2019年5—9月在全国范围开展的职业病诊断标准应用情况调查数据为例。该数据共有有效问卷92份,调查92名对象,涉及11个省、自治区的37个机构,涵盖疾控中心、职防院所、医疗卫生、用人单位等机构从事职业病诊断工作的人员。调查对象对115项职业病诊断标准的科学性、可操作性、实施效果、满足需要等4个方面进行评价,采用Likert 5级计分法,以1分为完全不符合(最差),5分为完全符合(最好)。
1.2 原理简介
1.2.1 关键规则的原理 关键规则是一种挖掘复杂事物中两个或多个变量之间频繁规律和关联特征的方法。关联规则是表达形式为X→Y,其中项集X为先决条件,即前项;项集Y为对应关联结果,即后项。项集X与项集Y均为项集I的真子集,并且X与Y无交集,项集I为事务数据库D的项集。有3个指标用于描述关联规则的关联强度,即支持度(support)、置信度(confidence)、提升度(lift),分别度量关联规则的普遍性、有效性和前项出现对后项出现的影响程度。一般以支持度>最小支持度且置信度>最小置信度为强关联规则,详见表1。

表1 关联规则统计指标计算公式表
1.2.2 Apriori算法原理 作为一种逐层搜索的迭代方法,Apriori是关联规则计算中最常用的的算法之一,其主要利用最小支持度和最小置信度2个参数进行控制,利用“任一频繁项集的所有非空子集均为频繁项集”的性质进行计算,算法流程详见图1。
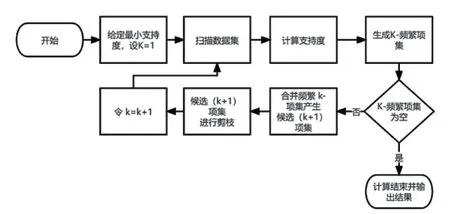
图1 Apriori算法流程图
1.3 统计学方法
将调查数据用Excel 2013整理后导入Rstudio(版本号:3.5.3),利用arules包(版本号:1.6-4)的Apriori函数进行关联规则计算,设定最小支持度和最小置信度分别为0.3和0.8,以提升度排名前10名的规则作为有效强关联规则。
2 结果
2.1 数据整理
将问卷调查数据整理成如表2的形式,其中ID问卷编号,共计92份有效问卷。为了方便Rstudio进行数据分析,设标准用S表示,S1表示编号为1号的标准,S2表示编号为2号的标准,以此类推,共计115项标准;科学性、可操作性、实施效果、满足需要分别用V1、V2、V3、V4表示;分值分别用A、B、C、D、E表示Likert得分为5、4、3、2、1分。则S1_V1表示编号为1号的标准的科学性,如其取值为S1_V1=A,则代表编号为1号的标准的科学性的Likert得分为5分。

表2 关联规则数据导入样表
2.2 程序介绍
如果所有的package都默认已经安装。如未提前安装,可直接通过菜单→Tools→Install Packages来安装,或者利用install.packages()命令来进行安装。
2.2.1 数据导入 将整理好的Excel文件命名为“import172”,地址为“E:/Ranalysis”。打开RStudio,输入library()命令调用readxl包,并导入数据。代码及其注释如下:
library(readxl)# 调用 readxl包
import172<-read_excel("E:/Ranalysis/import172.xlsx")# 导入Excel文件并命名为import172
View(import172)#查看导入的数据
trans172<-as(import172,"transactions")#将导入数据转为关联规则可以分析的形式
View(trans172)#查看转化后的数据
如转化后的数据无问题,则可以进入下一步的分析中。
2.2.2 计算关联规则 输入library()命令调用arules包,将设定最小支持度和最小置信度分别为0.3和0.8,挖掘出的关联规则命名为res172。代码及其注释如下:


2.3 结果解读
本次挖掘共产生28条强关联规则,取提升度排名前10名的强规则作为有效强关联规则。则有效强关联规则支持度、置信度和提升度的最小值分别是0.373 6、0.871 8和2.063 5,最大值分别是0.439 6、1和2.166 7,详见表3。

表3 卫生健康标准问卷调查数据关联规则表(按提升度排序)
通过关联规则挖掘可知,有效强关联规则的均涉及编号为91号的标准(以下简称S91标准),其在科学性、可操作性、实施效果、满足需要4个维度上得分为5分(即S91_V1=A、S91_V2=A、S91_V3=A和S91_V4=A)之间出现较为频繁,提示S91标准综合可能评价较高。频数统计发现,分别有54、51、51、50名调查对象对S91标准的科学性、可操作性、实施效果、满足需要4个维度(即S91_V1、S91_V2、S91_V3和S91_V4)进行打分,分别占调查对象总数的58.7%、55.43%、55.43%、54.35%。其中有45、42、42、38名调查对象对科学性、可操作性、实施效果、满足需要4个维度给出了5分,即S91_V1=A、S91_V2=A、S91_V3=A、S91_V4=A分别有45、42、42、38名,占对S91标准打分调查对象的83.33%、82.35%、82.35%、76.00%。综上基于Apriori算法的关联规则挖掘的结果与频数统计结果基本相符。
2.4 数据可视化
输入library()命令调用arulesViz包及其依赖的grid包。如挖掘出的关联规则过多,不宜直接绘制散点图,可以采用随机抽样的方式抽取一部分数据绘制散点图,散点图以支持度和置信度为横轴和纵轴,以提升度为三点颜色,颜色越深提升度越高,详见图2。代码及其注释如下。
library(grid)#调用arulesViz包依赖的grid包
library(arulesViz)# 调用 arulesViz包
set.seed(123)#设置随机抽样的种子
res172_smpl<-sample(res172,size=10,replace=FALSE)# 在产生的关联规则中进行抽样,抽样的样本量为10,抽样后产生的数据集为res172_smpl
plot(res172_smpl,measure=c("support","confidence"),shading="lift")#绘制关联规则的散点图
2.5 关联规则交互探索
除了直接运行代码进行关联规则的数据挖掘之外,还可以利用shinythemes包进行交互式关联规则挖掘。在交互界面,可以通过鼠标拖动,设定最小支持度、置信度、提升度和规则长度等参数,实现自动挖掘关联规则。代码及其注释如下。
library(shinythemes)# 调用 shinythemes包
ruleExplorer(res172)#启动交互界面
3 讨论
3.1 关键规则中Apriori算法可为卫生标准问卷调查提供新的分析思路
调查问卷在卫生健康标准领域其多用于标准需求调研、实施效果评估等,具有应用范围广、编制灵活、操作简单的优点,调查数据结果多为以二维表的形式呈现离散型数据。既往卫生健康标准研究多数据研究中,多将问卷调查数据中不同的题目之间视为成相互独立的指标,统计方法以描述性统计分析为主,多采用概貌分析策略和差异性分析策略,前者主要是统计调查对象选择问卷中各题目选项的频数或频率,以获取调查数据的概貌特征;后者主要是根据调查对象的不同特征(如专业背景、地域分布、行业来源)等进行分组并构建交叉表,利用卡方检验等统计方法分析某一指标不同分组之间的分布差异是否具有统计学意义。概貌分析策略和差异性分析策略忽略了不同题目的之间关联信息,可能存在对数据分析不充分的问题。随着我国社会经济快速发展,标准在社会管理事务中发挥的作用越来越大,也越来越受到社会各界的重视[7],Apriori算法作为关联规则最为经典的算法,可以有效从卫生健康标准相关调查问卷数据中挖掘各项目之间隐藏的关联知识,提炼具有潜在价值的特定信息,为完善标准体系提供技术线索。
3.2 关键规则中Apriori算法耗时较长,影响其在大规模问卷调查数据挖掘中的应用
Apriori算法作为关联规则最经典算法,其存在着两个主要缺陷,其一运算过程中会产生大量候选项集,其二是需要多次遍历扫描数据库,两个缺陷会影响算法效率,导致算法适应面偏窄[8]。特别是对于数据量较大的问卷调查数据,运算时间可能较长,甚至出现内存不足导致运算中断的情况。针对Apriori算法的缺陷,既往学者进一步开发了FP-growth算法、Relim算法和DHP算法用于提高算法效率。FP-growth算法通过构造频繁模式树(FP-tree)以避免反复扫描数据库,提高算法效率;Relim算法是对FP-growth算法进一步改进,其摒弃了构建构建频繁模式树的方法,而是通过构造一个事务链表组来获取挖掘结果;DHP算法主要通过哈希技术缩小候选项集的数量来提高算法效率[1]。
3.3 卫生健康标准管理人员亟需重视数据挖掘对标准工作的辅助作用
随着网络在线调查技术的普及,开展标准相关调查成本越来越低,相关调查数据也在快速积累中[9-14]。卫生健康标准管理人员如何充分运用关联规则等数据挖掘技术,从问卷调查数据中提取关联知识,提供标准管理线索,实现标准管理从经验驱动到数据驱动的跃迁,成为亟待解决的问题。关联规则等数据挖掘属于信息学、统计学和卫生健康标准专业知识的多领域交叉学科,而在既往卫生健康标准研究中,应用关联规则等数据挖掘技术的研究相对较少。建议在未来可以着重培养具备多领域复合型标准研究团队,充分发挥信息学、统计学和标准相关专业领域的优势,为快速挖掘获取有用的信息,提取管理线索打下坚实基础。
3.4 关联规则数据挖掘的局限性
关联规则数据挖掘结果受到其参数设定的影响较大,参数设置过高或过低均会对结果产生不良影响,且关联规则得出的规则是否具有指导实践意义,需要经过专业判断和管理实践证实,而不能单纯只看数据挖掘结果。
本研究归纳了Apriori算法在卫生标准问卷调查数据挖掘中的应用方法、注意事项及R语言实现方法,其挖掘的关联信息可以为完善标准管理提供技术线索,但是也存在算法效率偏低,不适用于数据量较大的问卷调查数据。
