基于改进二分K-means算法的网络异常检测技术研究
2022-12-01张雅茹
张雅茹
(连云港开放大学 继续教育学院,江苏 连云港 222000)
大数据时代,海量数据中隐藏着的大量攻击性异常行为数据对网络安全造成重大隐患,而入侵检测技术能够为数据安全提供保障[1]。针对现有网络异常行为检测技术中因数据不平衡而导致召回率低的问题,杨宏宇等人提出一种基于逆向习得推理的异常行为检测模型,实验结果表明,该模型在数据不平衡时仍具有较高的召回率和检测精度[2]。针对现有网络流量异常检测技术对网络环境动态变化适应性差的问题,蒋华团队提出一种自适应阈值的网络流量异常检测方法,研究结果表明,该检测方法对网络异常流量具有较高的检测精度[3]。在关于网络异常检测技术的研究中,较少有学者用二分K-means 算法解决正常行为特征行为模型效率低的问题,基于此,研究提出以改进后的二分K-means 算法来构建正常行为特征训练集模型,并在此基础上设计出网络异常检测算法ITCM-KNN,期望实现对网络异常行为数据的高效检测。
1 基于改进二分K-means 算法的网络异常检测算法设计
1.1 以改进二分K-means 算法构建正常行为特征模型
网络异常检测技术是根据正常的网络数据集建立模型,然后将待检测的数据与模型进行比对来判断数据是否异常,异常检测能够检测出未知的异常行为数据,甚至察觉到潜在的网络攻击行为,因此常被用于进行网络安全监测[4-5]。大数据时代下,随着网络数据不断更迭,传统异常检测方法效率低下、误报率较高,难以有效区分攻击类型和正常类型,基于此,研究提出基于改进二分K-means 算法的网络异常检测模型。首先利用二分K-means 聚类算法来对海量数据进行挖掘分析从而构建出正常网络行为模型,其次结合正常网络行为模型设计出检测算法ITCM-KNN,该模型如图1 所示。
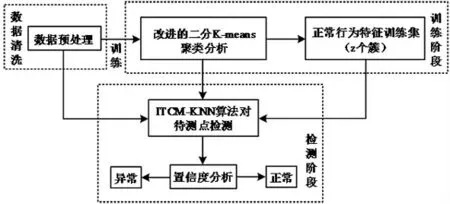
图1 基于改进二分K-means 算法的网络异常检测算法模型示意图
聚类分析是在未给定训练目标的情况下按照“簇内样本相似度最大,簇间样本差异度最大”的规则对所收集的数据对象进行分类[6-7]。K-means划分聚类算法因其简洁、高效而被广泛应用,该算法的核心是依据特定的距离函数在已知的数据集合上将数据对象反复分配至k(需要的聚类数目)个聚类中[8]。根据欧几里得距离公式计算出数据样本点和聚类中心的距离如式(1)所示:

式(1)中,m 表示待聚类的个体特征变量,Xik、Xjk分别为第i 个、第j 个样本的第k 个指标的取值。Dist(Xi,Xj)表示样本点Xi、Xj之间的距离,距离越小表明两个样本点的性质越相近。在构建正常行为特征训练集模型时,Xij、Xjk分别代表两个不同时刻的基于流量数据属性的度量值数据集合。在异常检测阶段,Xij、Xjk分别代表不同时刻所得的H(SIP)、H(InDeg)、H(DPort)、OWCD 四维结构数据属性的度量值。假定总数据集D 通过聚类得到K个簇即D=(D1,D2,D3,…,Dk),异常检测是以每个新类中各维数据的均值作为新类的中心值,新类Di的中心值Xi0如式(2)所示:
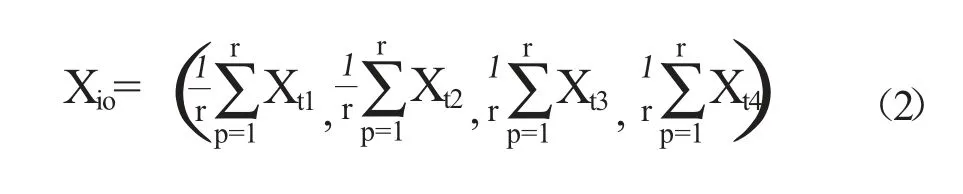
式(2)中,r 代表在某个新类中的数据个数,Xt1、Xt2、Xt3、Xt4分别表示四维结构的离散样本点。由于K-means 算法是一种用于优化非凸代价函数的贪婪下降求解算法,易陷入局部最优解,且聚类结果受制于聚类中心的初始化选择,因此研究引入二分K-means 算法解决上述问题。该算法的核心是利用K-means 算法将所有样本数据分为两个聚类,然后从两个聚类中选择样本数据数量最多的聚类,并对该聚类进行迭代划分操作直至获得K个簇类算法。K-means 算法中的畸变函数即误差平方和是聚类的评价函数,如式(3)所示:

1.2 以ITCM-KNN 算法设计网络异常检测方法
直推信度机是以随机性思想理论为基础建立的一种置信度机制,常用于衡量样本的类别归属问题[9]。K-近邻分类算法通过直接从训练集中搜寻出距待分类的样本对象最近的k 个点来对样本进行归类,但是若样本分布不平衡,待分类的样本便可能分配到非目标类中,利用TCM 的检测函数能够避免KNN 算法将待分类的样本归类于非目标类中[10]。研究结合TCM、KNN 设计出TCM-KNN算法,该算法基于现有的样本区域计算出待分类样本各点之间的空间距离,然后利用置信度外推机制得到检测函数P,并根据P 值评估样本分属于某一类中的可靠度。待分类的样本i 对于类别y 的P 值如式(4)所示:
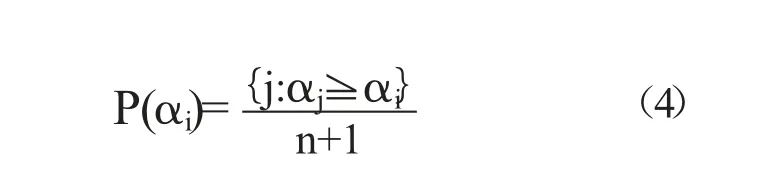
式(4)中,“#”为集合的“势”,表示有限集合所包含的元素个数,αj为集合中任一样本的奇异值,αi为待分类样本的奇异值,n 表示集合的个数。研究将TCM-KNN算法结合聚类分析构建网络异常检测算法ITCM-KNN。ITCM-KNN算法是根据聚类后的正常数据集而构建的异常检测算法,假设改进的二分k-means 算法将正常数据集合分类为f 个聚类,ITCM-KNN 算法首先需计算出待测样本相对于f 个聚类中心的欧氏距离,并将待测样本加入到距离最短的聚类中。然后选择最接近待检测样本点的聚类作为正常特征行为训练集。最后根据公式(4)得到待测样本归属于正常特征行为训练集的概率P 值,若P 值小于预定的阈值τ=0.05,则置信度为1-τ 即作为判定异常的指标。
2 网络异常检测实验结果分析
2.1 ITCM-KNN 算法的性能仿真实验分析
研究选用1999DARPA 数据集对异常检测算法进行评估,使用Wireshark 抓包工具捕捉分析网络中的数据包。对构建正常行为模型的改进二分K-means算法设置参数:聚类个数z=5;对网络异常检测算法ITCM-KNN设置最近邻目数k=8,置信度1-τ=95%,并且实验引入传统检测算法Cluster 作为基准算法与研究所提出的算法进行对照实验。为检验ITCM-KNN算法的优越性和有效性,研究在数据集上仿真算法Cluster、KNN、ITCM-KNN 对K-means 的聚类能力,以每一次迭代后的最优适应度值作为指标,如图2 所示为根据每次迭代结果所绘制的迭代收敛图。
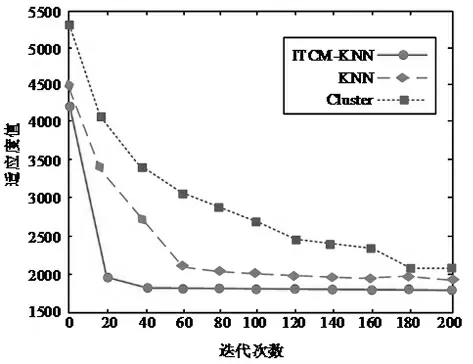
图2 不同算法在数据集上的收敛图
由图2 仿真曲线可知,相较KNN、Cluster 算法,ITCM-KNN 算法适应度曲线较为平滑且收敛速度最为迅速,在迭代次数20 次内就以较快的速度接近全局最优解,在[20,40]的迭代区间内实现最优解。由此说明,ITCM-KNN 算法对比KNN、Cluster 算法对全局和局部的搜索能力提升显著,聚类效果更优异。
2.2 ITCM-KNN 算法应用于网络异常检测的效果分析
实验以检测率、误报率作为衡量算法对网络异常进行检测的指标,如图3 所示为Cluster、KNN、ITCM-KNN 算法误报率-检测率实验关系对比图。
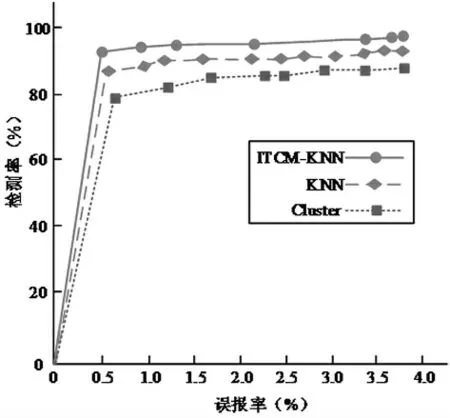
图3 算法误报率-检测率检测对比图
由图3 可知,随着检测率的提升,三种算法的误报率均相应增加,其中ITCM-KNN 算法相较KNN、Cluster 算法在较高的检测率下误报率最低且曲线走势平滑,由此说明ITCM-KNN 算法能较好平衡检测率和误报率两者指标的关系。如图4所示为三种算法在网络异常检测中检测率、误报率的具体表现。

图4 算法网络异常检测效果对比图
由图4 可知,ITCM-KNN 算法在检测率指标中相较Cluster、KNN 算法提升显著,其检测率较Cluster 算法平均提高8.37%,较KNN 算法平均提高2.78%。ITCM-KNN 算法在数据含量超过1/2 后与KNN 算法曲线拉大差距,说明ITCM-KNN 算法能够快速准确地确定聚类中心,跳出局部最优值而确定全局最优值,从而提升对数据集的检测率。从误报率指标结果图可知,ITCM-KNN 算法相较其它两种算法误报率最低,随着数据含量增大误报率下降明显,其中相较Cluster 算法误报率平均下降2.14%,较KNN 算法平均下降1.03%。
3 结论
在大数据时代,网络数据呈现出指数级增长的趋势,而在这些数据中,大量网络异常数据所代表的网络性攻击行为对网络安全造成巨大挑战,传统网络异常检测技术难以对海量数据进行有效挖掘分析。研究提出以改进二分K-means 聚类算法构建正常行为特征训练集模型,在此基础上将直推信度机制、K-近邻算法结合所建立的正常行为特征模型设计出异常检测算法ITCM-KNN,随后以仿真的形式对该算法进行了验证。实验结果表明,ITCM-KNN 算法的检测率相较Cluster 算法平均提高8.37%,误报率平均下降2.14%,检测率相较KNN 算法平均提高2.78%,误报率平均下降1.03%。由此说明研究所提出的ITCM-KNN 算法能够在保持较高检测率的同时降低误报率,改善了传统检测技术难以处理海量数据的困境。由于研究对该算法进行验证所采用的是模拟实验数据集,因此未来可将ITCM-KNN 算法应用于真实网络环境中检测,以便更有效说明该算法的适应性与可行性。
