基于Q学习的水下滑翔机路径规划方法
2022-12-01张鑫菠冀海军彭星光
张鑫菠,李 乐,冀海军,彭星光
(西北工业大学 航海学院,西安 710072)
0 引言
水下滑翔机是一种通过调节自身重心、浮力实现下潜与上浮的新型水下航行器,其凭借低成本、低功耗、长续航等特点,已经成为了一种重要的海洋观测平台。水下滑翔机路径规划是指在任务区域中规划一条满足给定目标函数(例如路径长度最短等)并满足避开障碍物等约束条件的,从起点到目标点的最优路径。路径规划主要包括环境建模方法和路径搜索算法。水下滑翔机在执行海洋环境监测和海洋安全保障等任务时,都需要进行路径规划。因此对水下滑翔机路径规划方法进行研究具有重大意义。
在水下滑翔机路径规划方面,国内外学者做了大量研究。当前水下滑翔机路径规划方法分为两类:传统路径规划方法和基于仿生学的路径规划方法[1]。传统路径规划方法如人工势场法、快速步进法和A*算法等;基于仿生学的路径规划方法如粒子群优化算法、蚁群优化算法、狼群算法和人工神经网络算法等。人工势场法[2]借鉴了物理学中势场理论的概念,将障碍物的排斥力与导航目标的引力模型结合起来,虽然简单高效,但存在目标不可达、振荡等固有缺陷。快速步进法[3]使用一阶数值近似来求解方程,具有可靠性强、易执行等优点,但是建模过于简单,未充分考虑障碍物形状和滑翔机下潜深度等约束条件。传统A*算法[4]以当前所在点为中心,对其各方向上限定范围内的点作为拓展备选点进行遍历,搜索速度快,但实时性差、运行效率低。粒子群优化算法[5]是一种基于迭代的优化方法,通过迭代的方法在搜索域中寻找最优值,参数少、收敛速度快,但是粒子间信息交互少,容易陷入局部最优。蚁群优化算法[6]是基于模拟蚁群觅食行为寻找优化路径的一种自然估算算法,具有鲁棒性、优良的分布式计算以及易于与其他算法结合等优点,但是在进行全局路径规划时收敛速度慢,易陷入局部最优。狼群算法[7]是仿生自然界狼群的捕猎行为提出的一种群体智能优化算法,不易受参数影响,简单易实现,但是也存在收敛速度慢、易陷入局部极值、稳定性差及后期局部搜索能力差等缺点。人工神经网络算法[8]是一种受生物神经网络功能的运作启发而产生的算法数学模型,容错性强、自学能力强,但存在着路径错判、计算量大、学习滞后等问题。这些方法都需要提前建立环境模型,当环境信息不能提前获得或者问题模型过于复杂时,使用这些方法往往效果不佳。针对上述不足,强化学习方法成为一种用于水下滑翔机路径规划的研究方向。
强化学习方法不需要提前得知环境信息,也不需要预先给定任何数据,而是通过不断与环境交互,从环境中获得累积行为奖励的方式来更新模型参数,进而寻求最优解[9],并且可以根据优化目标来设计奖励函数。这种方法自适应性强,运行效率高,能避免陷入局部最优解。因此适合于水下未知复杂环境中的滑翔机路径规划问题。
本文提出基于Q学习的水下滑翔机路径规划方法。首先,在水下滑翔机工作深度一定的条件下,对典型的几种俯仰角情况分别设计了航向动作选择集;其次,根据水下滑翔机路径最短的目标和障碍物外部约束条件,设计了奖励函数与动作选择策略,给出了Q值更新函数。最后,通过仿真实验验证了算法的有效性。
1 问题描述
传统的路径规划方法都需要提前建立环境模型,当环境信息不能提前获得或者问题模型过于复杂时,这些方法往往不能使用。目前Q学习路径规划方法多仅考虑二维水平动作变化。
综合考虑水下滑翔机的自身运动特性和滑翔过程水下环境的影响,水下滑翔机的路径规划需要满足以下约束条件。
1.1 路径总长度约束
水下滑翔机在水中能滑翔的总航程有限,规划出的从起点到终点的路径总长度不能超过水下滑翔机能滑翔的最大航程。
1.2 障碍物约束
水中环境未知复杂,会有各种岛礁、船舶等障碍物阻挡水下滑翔机的运动,规划路径要规避障碍物威胁。
1.3 滑翔参数约束
水下滑翔机在俯冲与上浮时,要满足自身运动的俯仰角、横滚角、偏航角约束以及航行深度等参数约束。
2 Q学习方法概述
Q 学习是一种典型的无模型强化学习方法,利用迭代方法直接优化一个可迭代计算的Q函数,也是一种增量式的在线学习[10-12],它迭代时采用状态-动作对的Q(S,a)函数,其中S表示状态,a表示动作。在Q学习方法中,智能体每一次学习迭代时需要考察每一个行为,确保学习过程收敛。
Q学习首先初始化Q(S,a)的值,基于当前状态St,使用动作选择策略确定下一步动作at,然后环境立刻反馈一个奖励值rt与新的状态值St+1,根据Q值更新函数更新对应状态St和动作at的值,然后基于新状态值St+1进行同样的步骤[13-15]。当新的状态值为目标状态或者满足结束条件时,完成一次循环迭代,继续从起始状态开始新的循环迭代,直到学习结束[16]。Q学习本质上就是不断地优化可迭代计算的Q(S,a)函数值,直到其收敛到最优值[17-19]。Q值更新函数如下:
(1)
其中:St是当前状态,at是当前动作,rt是在St状态下选择动作at得到的奖励值,St+1是执行动作at后的新状态,0<α<1表示学习率,0<γ<1表示衰减率。
Q学习过程包括多次迭代循环,每次迭代循环又包括多次动作a的选择与执行,动作a选择与执行步骤如下,假定当前为第t次动作选择:
1)已知当前状态St;
2)根据动作选择策略,得到并执行动作at;
3)得到奖励值rt和新状态值St+1;
4)更新Q(St,at)的值;
5)进入第t+1次动作选择。
3 Q学习水下滑翔机路径规划方法
基于Q学习的水下滑翔机路径规划方法包括Q学习要素设计与算法流程两部分。Q学习要素是实现基于Q学习水下滑翔机路径规划的基础。算法流程是实现路径规划的方法与步骤,具体内容在本节给出。
3.1 水下滑翔机Q学习要素设计
水下滑翔机Q学习要素主要由水下滑翔机状态、动作集合、奖励函数、动作选择策略、Q值表五部分组成,如图1所示。水下滑翔机根据当前状态选择要执行动作的依据是动作选择策略。具体Q学习要素的设计在下文给出。
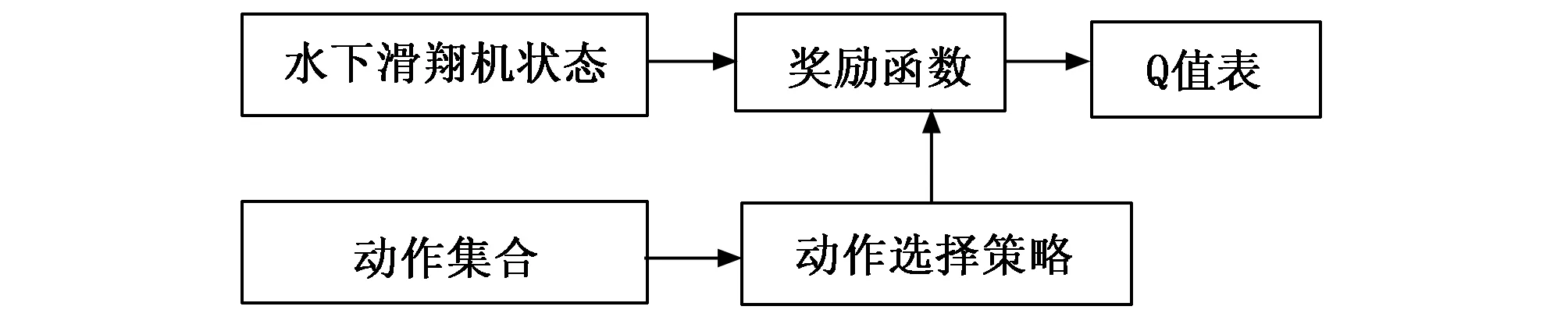
图1 Q学习要素表示
3.1.1 水下滑翔机状态表示
在解决路径规划问题中,对环境空间进行栅格化表示是一种常用的方法。本文用二维栅格表示水下任务环境的水平面。对环境空间的栅格化表示是为了在仿真实验中模拟环境对水下滑翔机动作的反馈,算法本身不需要提前建立环境模型。水下滑翔机在环境中的状态用该时刻滑翔机在栅格中的坐标点位置S(x,y)表示。
3.1.2 动作集合表示
考虑到水下滑翔机在执行一些特定任务时会提前给定俯仰角θ及深度值h,且航向角ψ的选择范围通常是几个离散角度值。因此假设给定深度值为h,对m种典型的俯仰角{θ1,θ2,…,θm}分别设计n种典型的航向动作选择集{ψ1,ψ2,…,ψn},如图2所示。这些动作的步长由公式(2)~(4)得到:

图2 动作选择集合
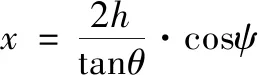
(2)
(3)
(4)
其中:θ、ψ、h分别表示俯仰角、航向角、深度,x、y表示横、纵坐标,step表示步长大小。
3.1.3 奖励函数设计
Q学习的目的是得到从起始点到目标点的最大累积奖励,此奖励是环境反馈得到,直接影响到学习的速度和效果,因此设计合理高效的奖励函数非常重要。本文设计的奖励函数如下。
当到达目标点:
Reward=500
(5)
当碰撞到任何一个障碍物:
Reward=-500
(6)
当在自由区域运动时:
Reward=Ω[(xAug-xTarget)2+(yAug-yTarget)2]
(7)
式中,xAug,yAug是水下滑翔机在栅格环境中当前位置的横、纵坐标;xTarget,yTarget是目标点的横、纵坐标;Ω为缩放系数,用来调节自由区域运动时的奖励值范围,使其奖励值的绝对值远小于到达目标点或碰撞到障碍物时奖励值的绝对值,通常任务区域面积越大Ω取值越小。
3.1.4 动作选择策略
本文在ε-greedy方法基础上结合水下滑翔机运动特点,设计了一种新的动作选择策略。算法1给出了水下滑翔机Q学习动作选择策略算法流程。首先判断俯仰角θ的大小,θ的选择范围为设定的m种典型俯仰角{θ1,θ2,…,θm}。根据俯仰角大小,选择对应的n种典型的航向动作选择集{ψi1,ψi2…ψin}。然后设定一个贪婪值ε,在每次选择动作时会随机产生一个p,当p小于ε时随机选择动作值。当p大于ε时,则选择动作集合当中Q值最大者作为此次选择的动作。
算法1:
IFθ=θi,i∈(1,m)
ai={ψi1,ψi2,…ψin}
End IF
Generate p randomly, p∈(0,1)
IFp>ε
a=argmax(Q(s,ai))
Else
a=Random(ai)
End IF
3.1.5 Q值表初始化方法
在Q学习的初始学习阶段,系统对于环境状态基本一无所知[20],对动作的选择都是随机盲目的,因此使用先验知识初始化Q值表对提高Q学习算法的收敛速度非常重要。
在水下滑翔机的路径规划问题中,本文使用栅格环境中坐标点与目标点的直线距离进行Q值的初始化,即式(5)所示,距离目标点越远的点初始Q值越小。这种根据与目标点距离初始化Q值表的方法,使得水下滑翔机具有向目标点移动的趋势,减小了搜索训练的盲目性,提高了Q学习方法的学习速度。
(8)
3.2 基于Q学习的水下滑翔机路径规划方法流程
基于3.1节水下滑翔机Q学习要素设计,水下滑翔机的状态由位置坐标S(x,y)表示。给定深度值h,对典型的m种俯仰角{θ1,θ2,…,θm}分别设计n种典型的航向动作选择集{ψ1,ψ2,…,ψn},当水下滑翔机碰到障碍物时奖励函数值为-500,到达目标点时奖励函数值为500,在自由区域时奖励函数如公式(7)所示。算法1给出了动作选择策略。按照如图3所示具体流程图,实现基于Q学习的水下滑翔机路径规划。
具体步骤如下。
步骤1:给定水下滑翔机初始位置S,给定深度h,俯仰角θ=θ1,航向动作集合{ψ1,ψ2,…,ψn}
步骤2:根据Q值表初始化方法,给Q值表赋初值;
步骤3:根据动作选择策略,从俯仰角对应的动作选择集中选择动作a;
步骤4:根据3.1.3节给出的奖励函数得到立即的奖励值r和执行动作a后的新的滑翔机位置S’;
步骤5:更新对应于状态S与动作a的Q值:
Q(S,a)←(1-α)Q(S,a)+α[r+γmaxQ(S′,a)]
(9)
步骤6:判断水下滑翔机是否碰到障碍物,是则结束此轮学习,转到步骤1,否则继续进行下一步。
步骤7:判断水下滑翔机是否到达目标区域,未到达则转到步骤3 ,选择下一动作。若已到达目标区域,继续进行下一步。
步骤8:判断是否完成m种不同俯仰角设定下的路径规划,是则输出m条路径中最短路径的规划路径点。否则重新给定俯仰角,进行新一轮学习。
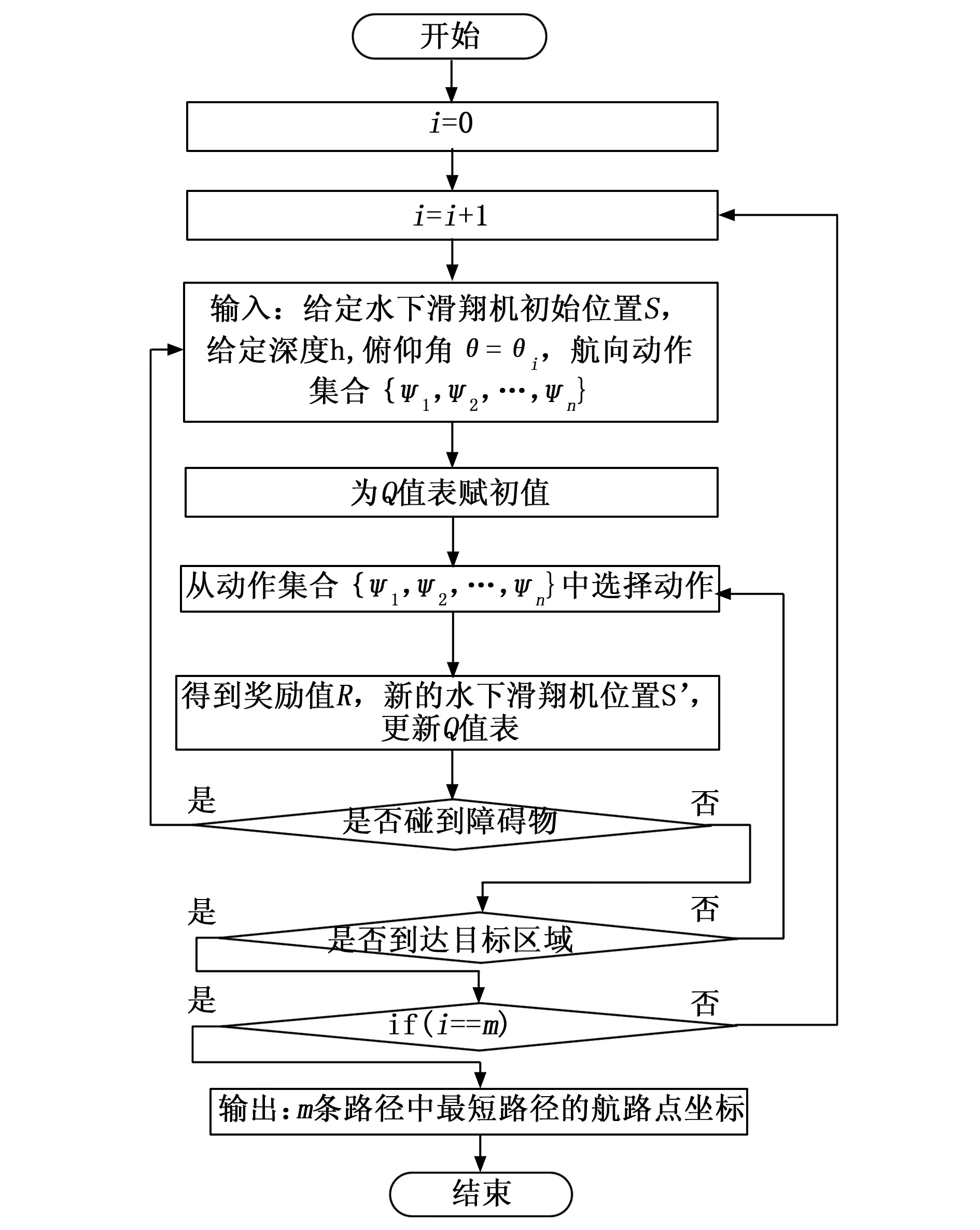
图3 基于Q学习的水下滑翔机路径规划方法流程图
4 仿真实验及结果分析
4.1 仿真实验环境
水下滑翔机路径规划区域为12 km×12 km的二维栅格区域,表示水下任务环境,设置栅格粒度大小 Ngrid = 1 km。假设水下滑翔机的单周期最小滑翔距离为0.3 km,滑翔深度为0.2 km。在圆形障碍物环境、矩形障碍物环境与复杂障碍物环境3种规划区域中进行验证。在Python中建立水下滑翔机路径规划的初始环境空间,圆形障碍物、矩形障碍物与复杂障碍物信息在下文给出。
圆形障碍物环境中,起点与终点坐标分别为(0.5,0.5)km和(10,10)km,4个圆形障碍物半径均为0.6 km,几何中心坐标分别为(1,3)km、(5,4)km、(5.5,6.5)km、(8.5,7.5)km;矩形障碍物环境中,起点与终点坐标分别为(0.5,0.5)km和(10,9)km,3个矩形障碍物边长均为1.5 km,几何中心坐标分别为(1,3)km、(4,1)km、(5.75,5.75)km;复杂障碍物环境中,起点与终点坐标分别为(0.5,0.5)km和(9.6,8.5)km,共有6个障碍物,其中1个圆形障碍物半径为1 km,其余5个障碍物是由边长为1 km的矩形组合而成,几何中心坐标分别为(1,5)km、(2,10)km、(4,1)km、(5.5,4.5)km、(5.5,8.5)km、(9.5,3.5)km。
4.2 Q学习水下滑翔机路径规划仿真
基于Q学习的水下滑翔机路径规划方法,根据滑翔机的当前位置坐标S,在Q值表中找出对应当前位置坐标的最大Q值,进而执行此Q值所对应的动作a,然后得到一个立即的环境奖励值R与新的位置坐标S’,根据奖励值R更新对应于状态S与动作a的Q值, Q值更新的方法如3.1.3节公式(5)(6)(7)所示。仿真参数设定为:α=0.1,γ=0.9,ε=0.1,Ω=-0.000 1,学习最大次数为3 000次。
4.2.1 Q学习水下滑翔机路径规划方法验证
水下滑翔机在特定任务中的路径规划需要提前设定俯仰角,俯仰角可选范围并非连续值,而是根据水下滑翔机自身性能、任务参数以及海洋状况确定的几个典型离散数值。因此有必要对多种俯仰角下所规划路径进行比较,以保证规划的路径最短。
给定深度值h=0.2 km。设俯仰角个数m=3,取值为{θ1=20°,θ2=30°,θ3=40°}。设航向动作选择集包含动作个数n=8,动作选择集合{0,1,2,3,4,5,6,7}表示当俯仰角为时,航向角{315°,270°,225°,180°,135°,90°,45°,360°}分别对应的动作。动作选择集合{8,9,10,11,12,13,14,15}表示当俯仰角时,航向角{315°,270°,225°,180°,135°,90°,45°,360°}分别对应的动作。动作选择集合{16,17,18,19,20,21,22,23}表示当俯仰角时,航向角{315°,270°,225°,180°,135°,90°,45°,360°}分别对应的动作。针对20°、30°、40°3种典型俯仰角取值,使用3.1.2中提出的动作集合,在复杂障碍物环境下分别规划。图4为3种俯仰角设定下的路径规划结果图,在不同的俯仰角设定下,均能规划出避免碰撞的安全路径。
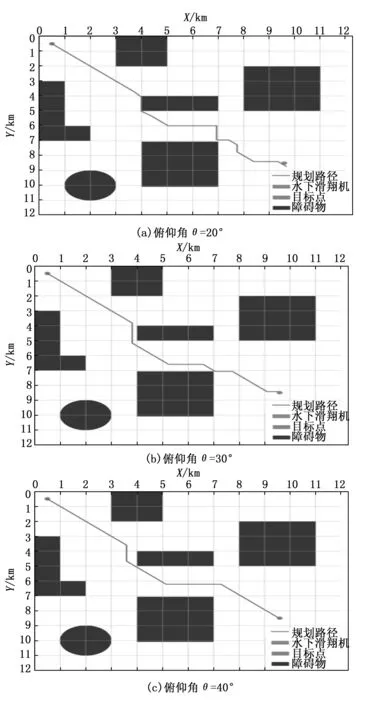
图4 不同俯仰角设定下的路径规划结果
图5为3种俯仰角设定下,每一轮学习所规划出的从起点到目标点的路径长度变化。在俯仰角θ=20°的路径规划中,经过400轮学习可以寻得最短路径,路径长度为14.282 km。在俯仰角θ=30°的路径规划中,经过700轮学习可以寻得最短路径,路径长度为15.218 km。在俯仰角θ=40°的路径规划中,经过2 300轮学习可以寻得最短路径,路径长度为15.241 km。由于基于Q学习的水下滑翔机路径规划方法依靠不断探索学习来寻求最优解,因此在寻找最短路径后会继续学习,在图5中体现为最短路径与非最短路径接替出现,形成震荡。
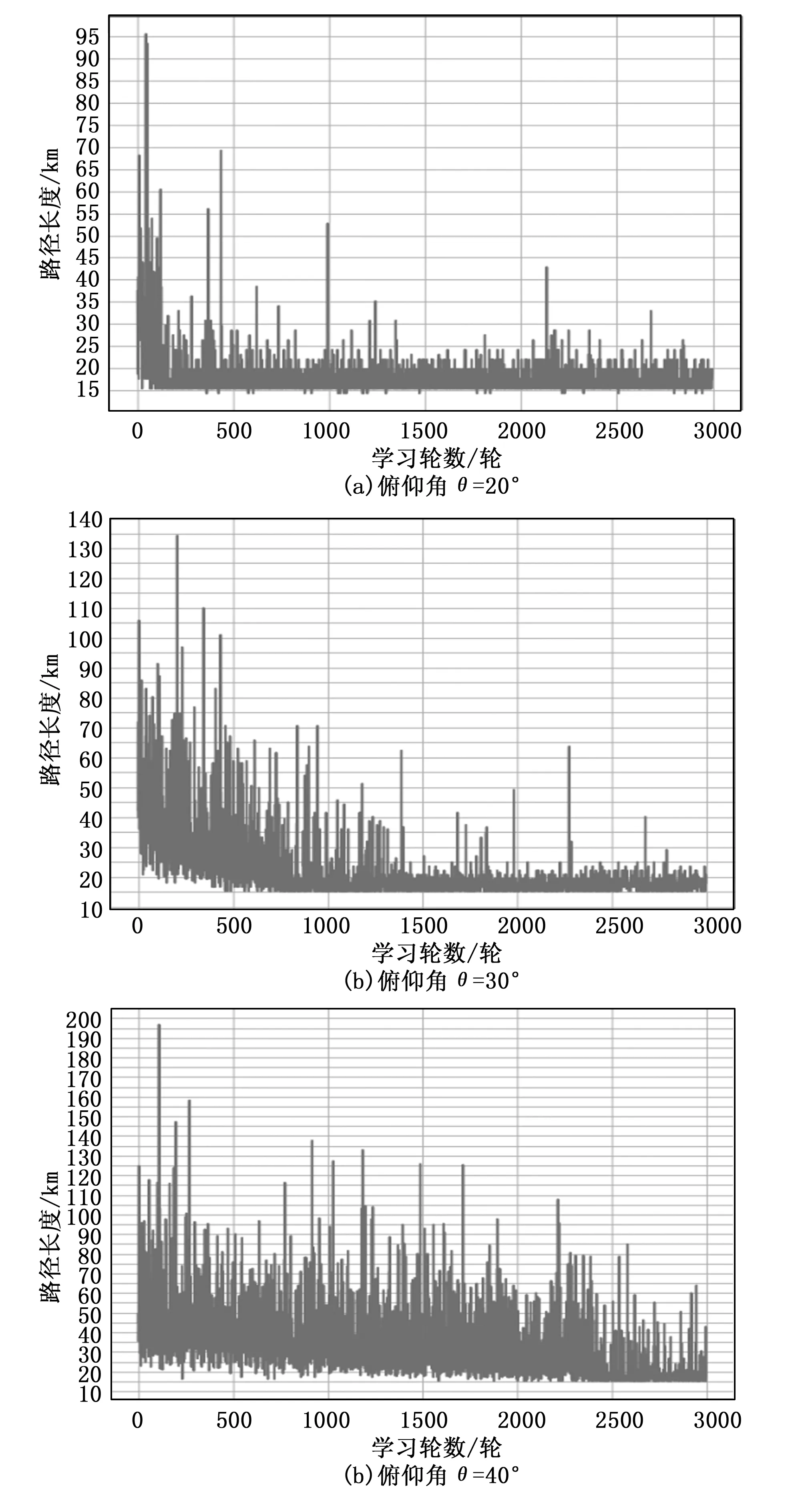
图5 不同俯仰角设定下的路径长度变化
表1记录了3种俯仰角设定下,最终规划路径的路径点个数、最短路径长度、与理论最短距离之差。理论最短距离指起点与目标点之间的直线距离。由表中数据知,在复杂障碍物环境中,设定俯仰角θ为20°时,相较于30°、40°,可以规划出长度最短、与理论最短距离差最小的路径。此时路径长度14.282 km、与理论最短距离差为2.165 km。
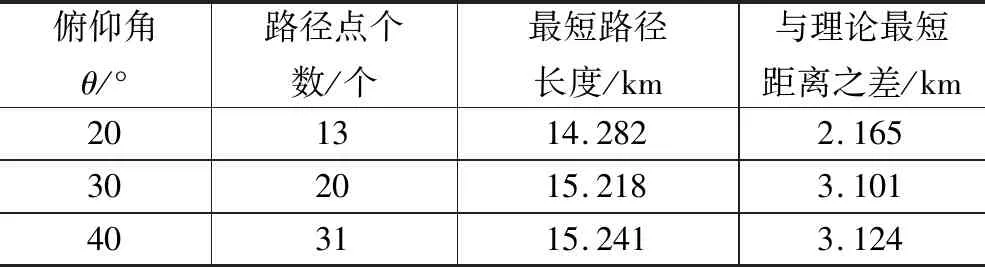
表1 不同俯仰角设定下的路径规划结果
4.2.2 不同障碍物环境下的路径规划
由于水下环境复杂多样,针对圆形障碍物与矩形障碍物环境分别给出了3种不同场景,验证基于Q学习的水下滑翔机路径规划方法的完备性。图6是水下滑翔机在圆形障碍物初始环境中的路径规划仿真,图6中a)、b)、c)分别表示圆形动态障碍物几何中心在(5,4)km、(3,3)km,(7.5,6.5)km三个不同位置时的规划结果。图7是矩形障碍物初始环境中的路径规划仿真,图7中a)、b)、c)分别表示矩形动态障碍物几何中心在(5.75,5.75)km、(8.55,6.75)km,(8.55,5.75)km三个不同位置时的规划结果。

图6 圆形障碍物环境下路径规划结果
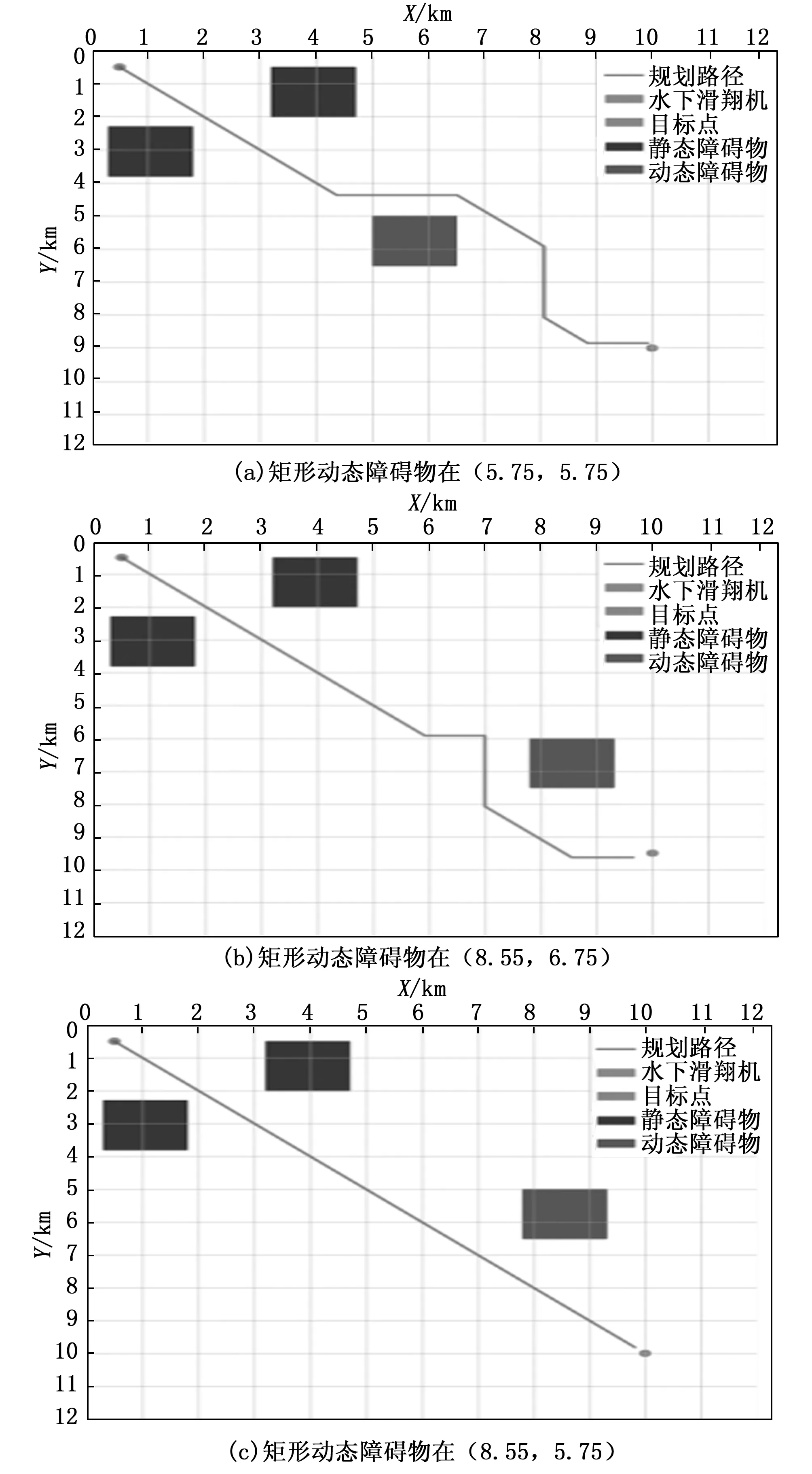
图7 矩形障碍物环境下路径规划结果
表2与表3记录了圆形与矩形两种障碍物环境中,不同位置动态障碍物下的规划路径的路径点个数、最短路径长度、与理论最短距离之差。理论最短距离指起点与目标点之间的直线距离。
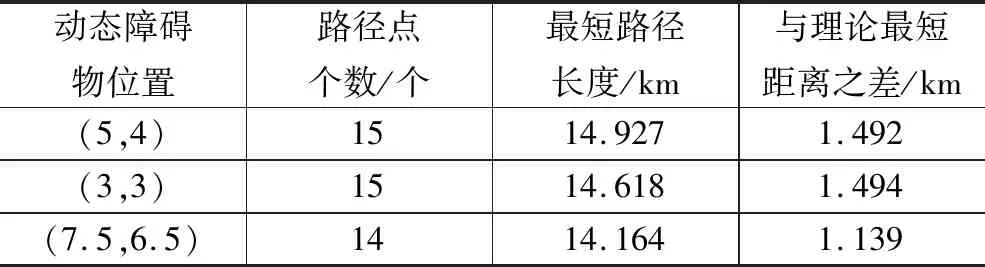
表2 圆形障碍物环境路径规划结果

表3 矩形障碍物环境路径规划结果
由表2数据知,在圆形障碍物环境中,当动态障碍物位置在(5,4)km时,规划最短路径长度为14.927 km,与理论最短距离差为1.492 km;当动态障碍物位置在(3,3)km时,规划最短路径长度为14.618 km,与理论最短距离差为1.494 km;当动态障碍物位置在(7.5,6.5)km时,规划最短路径长度为14.164 km,与理论最短距离差为1.139 km。在圆形障碍物环境中,以上3种情景中,当动态障碍物位置在(7.5,6.5)km时所规划出的路径长度与理论最短距离差最小。
由表3数据知,在矩形障碍物环境中,当动态障碍物位置在(5.75,5.75)km时,规划最短路径长度为14.143 km,与理论最短距离差为1.395 km;当动态障碍物位置在(8.55,6.75)km时,规划最短路径长度为13.118 km,与理论最短距离差为0.381 km;当动态障碍物位置在(8.55,5.75)km时,规划最短路径长度为13.172 km,与理论最短距离差为0.263 km。在矩形障碍物环境中,以上3种情景中,当动态障碍物位置在(8.55,5.75)km时所规划出的路径长度与理论最短距离差最小。
仿真实验数据表明: 基于Q学习的水下滑翔机路径规划方法能有效解决滑翔机在不同环境下路径规划问题且效率较高。能够在多个俯仰选择下规划出最优路径,路径长度与理论最短路径长度差距较小。当环境发生变化时,依然能得到最优路径。
5 结束语
本文提出基于Q学习的水下滑翔机路径规划方法,不需要提前得知环境信息,而是通过环境反馈的奖励值,使水下滑翔机学习对障碍物的有效规避,得到较短路径。仿真实验数据表明,本文提出的方法能满足水下滑翔机在复杂环境中的路径规划任务需求,并且在不同的环境条件下能够进行迁移,具有良好的通用性。
