基于迁移学习的文本共情预测
2022-11-30李晨光张波赵骞陈小平王行甫
李晨光,张波,赵骞,陈小平,王行甫*
基于迁移学习的文本共情预测
李晨光1,张波2,赵骞2,陈小平1,王行甫1*
(1.中国科学技术大学 计算机科学与技术学院,合肥 230026; 2.国网安徽省电力有限公司,合肥 230022)(∗通信作者电子邮箱cg0808@mail.ustc.edu.cn)
由于缺乏足够的训练数据,文本共情预测的进展一直都较为缓慢;而与之相关的文本情感极性分类任务则存在大量有标签的训练样本。由于文本共情预测与文本情感极性分类两个任务间存在较大相关性,因此提出了一种基于迁移学习的文本共情预测方法,该方法可从情感极性分类任务中学习到可迁移的公共特征,并通过学习到的公共特征辅助文本共情预测任务。首先通过一个注意力机制对两个任务间的公私有特征进行动态加权融合;其次为了消除两个任务间的数据集领域差异,通过一种对抗学习策略来区分两个任务间的领域独有特征与领域公共特征;最后提出了一种Hinge‑loss约束策略,使共同特征对不同的目标标签具有通用性,而私有特征对不同的目标标签具有独有性。在两个基准数据集上的实验结果表明,相较于对比的迁移学习方法,所提方法的皮尔逊相关系数(PCC)和决定系数(R2)更高,均方误差(MSE)更小,充分说明了所提方法的有效性。
迁移学习;文本共情预测;文本情感极性分类;自然语言处理;深度学习
0 引言
共情(同理心)作为情感的重要组成部分,反映了人们面对他人遭遇或目睹他人境况时所产生的对应情感[1]。共情的定义较为广泛,因而存在许多不同的评测标准[2-4]。这些不同的共情评测标准均可以反映人们面对他人遭遇时所产生的情感及反馈,除此之外共情分析也与人机交互、情感分析等息息相关[5-7],因而识别文本内所蕴含的共情因素是非常必要的。
截至目前,基于文本的共情预测这一领域仍然进展缓慢,核心原因是目前所发表的基于文本的共情数据集的样本量都过小。显然,当数据量不足时,训练出的网络模型的泛化能力会比较差,且预测精度也会较低。目前公认的开源文本共情数据集[8-10]均只包含一千多条数据。与之形成对比的是,一些其余的情感分析任务拥有非常充足的训练数据。以情感极性分类任务为例,目前该任务对应非常多的开源数据集,这些数据集包含数万乃至数十万训练样本[11-13]。表1列举了一些样例,这些样例是标注者阅读完一些新闻后写下的读后感,以及这些读后感所对应的共情标签与极性标签。从该样例可以看出,共情标签与极性标签都在一定程度上反映了文本的情感属性,且两者的值都依赖于文本内所包含的情感词。这说明两个标签之间存在一定的联系,从而为在这两个任务之间进行迁移学习提供了可能性。因此,本文提出一种迁移学习方法,希望通过情感极性分类任务来辅助共情预测任务,以获得更好的共情预测结果。

表1 共情/极性数据样例
但是,在共情预测与情感极性分类这两个任务间进行迁移学习存在两个困难。第一个困难是两个任务之间的领域差异,即数据集分布差异。共情数据集与情感极性数据集的采样空间与文本风格可能截然不同。举例而言,共情数据集[8]主要来源于对各类新闻的读后感,而情感极性数据集[11]主要来源于电影评论领域。这是两个截然不同的领域,因而对应不同的样本空间。第二个困难是两个任务的预测标签并不相同。从表1可以看出,极性更多是判断一段文本是开心的还是悲伤的,而共情则要更加复杂,它更多是考察共情的情感强度,而无需考虑共情的情感是正向还是负向的。
数据集领域方面的差异与标签不同所带来的差异给两个任务之间的迁移学习带来了干扰。因此,本文提出一种新颖的共情预测方法,可以从情感极性分类任务中学习到可迁移的公共特征,且避免领域和标签差异所带来的干扰。该方法主要包括三部分:首先,利用注意力模块依据公私有特征对对两个任务间的公私有特征进行动态加权;其次,通过一个领域分类器分辨所有特征的来源领域,从而使公共特征对不同领域的数据集领域具有普适性,而私有特征对不同领域的数据集领域具有独有性,利用对抗学习模块消除领域差异;最后,为减少标签差异,设计一种Hinge‑loss约束策略使公共特征提取器更多地提取对标签预测有益的特征,而对标签预测没有助益的特征都由另一任务的私有特征提取器提取。
为了验证本文方法的有效性,在两个共情数据集[8-9]和两个情感极性分类数据集[12,14]上进行实验,即通过这两个情感极性分类数据集来辅助两个共情数据集。实验结果表明,本文方法在引入情感极性分类任务后大大提高了共情预测的准确度。本文方法可以同时降低数据集领域不同与预测标签不同所带来的干扰,从而可以在两个标签不同且领域不同的任务间进行迁移学习,具有较强的可拓展性。
1 相关工作
1.1 文本共情预测
虽然文本共情预测对于人机交互、情感分析非常重要,但是该领域目前的相关工作还比较少。例如,Xiao等[15]提出一种N‑gram模型对医学与心理学领域中的数据样例进行了共情与非共情的分类;Khanpour等[16]提出一种基于卷积神经网络的模型来识别在线健康论坛内的共情信息;Zhou等[17]分析了各种领域的共情样例,例如新闻报刊、校园欺凌、心理治疗等。以上这些工作均在部分领域对共情进行了分析与讨论,但所使用的数据集并未开源,因此在这些工作的基础上尝试进一步的探索非常困难。
Buechel等[8]在2018年提出了首个开源的共情标注数据集,这些数据来源于用户对一些新闻的读后感,而且每位用户还对其写下的读后感进行了共情标签的标注,标注标准为EC‑PD标准[2],从而每份读后感都对应一个标签值,标签值的取值范围为从1~7。而Zhou等[9]则同样开源了一份共情数据集,这份数据集内的每条数据也对应一个标签值,标签值的取值范围为从1~5。目前的主要问题是这两个数据集都只包含1 000条左右的样本,数据量非常小,因此难以训练出泛化能力强的神经网络。而情感极性分类任务则包含大量的数据样本,如文献[11-13]中介绍的这些数据集往往包含数万条情感极性分类数据,并且此这些数据与共情预测任务之间存在较强的相关性。
1.2 迁移学习
从迁移学习的相关综述论文[18-19]可知,目前迁移学习方法主要分为两种,分别是:同质迁移学习与异质迁移学习。其中:同质迁移学习方法[20-21]主要针对同一特征分布空间的情况;而异质迁移学习习方法主要针对源领域与目标领域的特征分布空间不同的任务。由于源领域与目标领域的特征空间分布往往不一致,因此近年来自然语言处理领域的相关工作主要集中于异质的迁移学习。
异质迁移学习可进一步地分为有监督异质迁移学习与无监督异质迁移学习。其中后者虽然有大量的相关工作[13,22],但由于本文所涉及的共情领域是有标签的,因此这些方法难以应用到本任务中。而针对有监督异质迁移学习而言,虽然目前也存在一些相关工作[23-24],但这些任务往往只考虑了数据集领域间的差异,忽略了标签带来的差异。若忽略共情标签与极性标签的差异,必定会对共情预测任务带来不利的影响。因此要在文本共情预测任务与文本情感分类任务间进行迁移学习,需要同时考虑数据集领域差异与标签空间差异。
2 本文方法
2.1 问题定义
2.2 模型框架
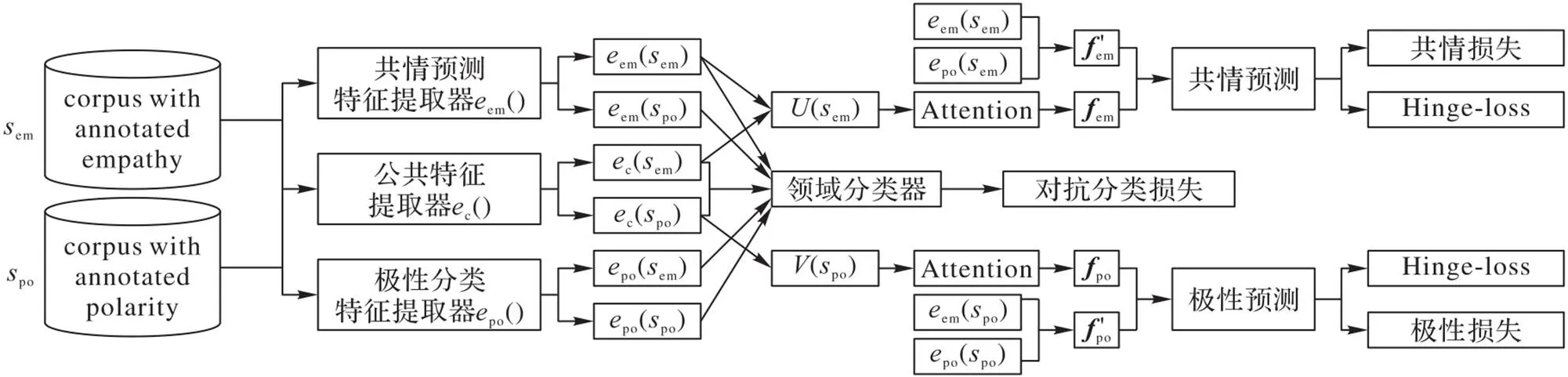
图1 本文方法的模型框架
在后续的网络架构中,由于公私有特征对共情预测的贡献可能不一致,因此首先通过一个注意力模型(Attention)对公私有特征进行加权,通过动态加权的方式将公私有特征融合为最终的特征表达,并进行对应标签的预测。与此同时,针对共情预测与极性分类这两个任务间数据集领域差异与标签评测差异所带来的干扰,模型通过对抗分类损失来降低数据集领域差异所带来的干扰,并通过设计Hinge‑loss的方式来降低不同标签所带来的干扰,从而使特征编码器所学习到的可迁移特征能适用于不同的领域和标签,进一步地解缠中所得到的两个任务之间的公私有特征。
2.2.1基于Attetion架构的公私有特征动态融合
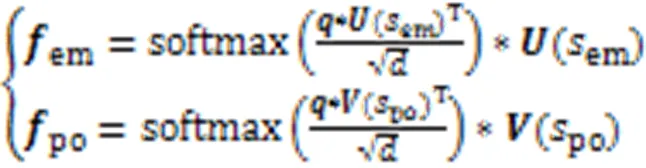

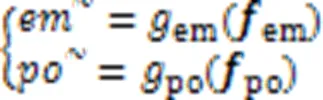
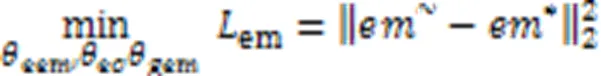
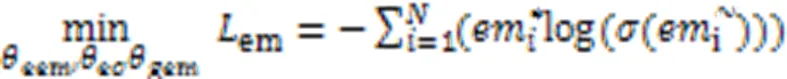
极性分类的训练损失如式(5)所示:
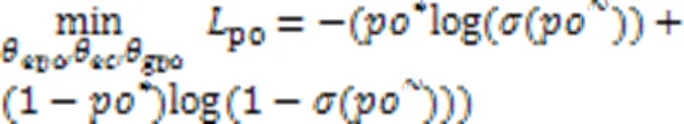
2.2.2基于对抗损失来消除数据集领域差异
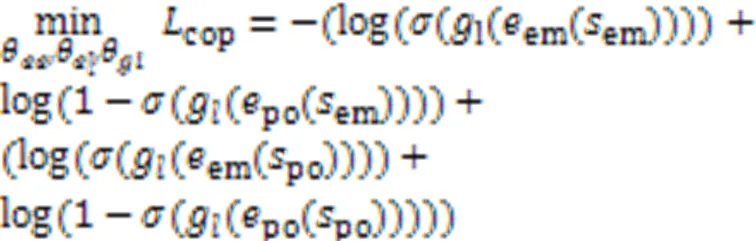
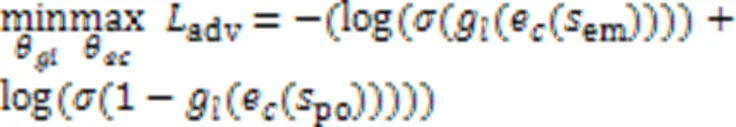
2.2.3基于Hinge‑loss来消除标签差异
为消除共情任务与极性任务两者间的标签差异,本文提出了一种标签训练策略。具体而言,以共情预测为例,有些可迁移特征对共情预测是有用的,而有些特征是没有用的。这些有用的特征应该主要通过公共特征编码器进行提取,而无效的特征由另外一个任务的私有特征提取器提取,这是因为在测试阶段另外一个任务的私有特征提取器是不使用的,从而可以舍弃这些无效特征。因此,本文方法通过Hinge‑loss这一模块来尽可能扩大公共特征器和共情私有特征提取器所对应的实验结果与极性私有特征提取器和共情私有特征提取器所对应的实验结果之间的差值。
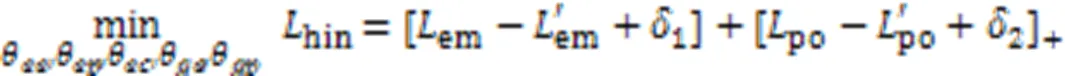
其中:1和2为实验中的两个超参数,实验中两者取值分别0.4与0.5。
2.2.4总体损失函数
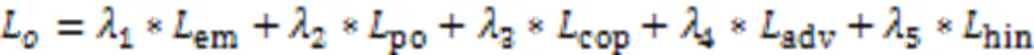
3 实验与结果分析
3.1 实验条件
本文在两个共情分析数据集进行了实验验证,它们分别来自文献[8-9]。辅助这两个共情数据集的情感极性分类数据集分别为SemEval 2017 task(以下简称SemEval)[12]与IMDB reviews[14](以下简称IMDB)。对于极性数据集而言,仅保留其中正向样本与负向样本。
由Buechel等[8]提出的共情数据集(以下简称Buechel)共包括1 860条标注数据集,主要来源于标注人员对于各类新闻的读后感;其中每条数据样例都包括两个共情标签,分别是EC和PD,这两个标签值的取值范围是1~7。由Zhou等[9]提出的共情数据集(以下简称Zhou)则包括1 000条标注数据,这些数据来源于Reddit论坛,主要内容为用户在该论坛上的发帖及对应帖子的回复;其中每条数据样例都被打上了一个共情标签,标签值的范围为1~5。极性分类数据集SemEval主要包括用户在Twitter上发布的各类推文,包含7 061条正向样本与3 240条负向样本;IMDB则主要是用户对各种类别电影的观后感及评论,包括25 000条正向样本与25 000条负向样本。
实验参数部分,编码器部分采用了两种不同模型,分别是双向长短记忆(Bi‑directional Long Short‑Term Memory, Bi‑LSTM)网络[25]与双向Transformer表征预训练模型(Bidirectional Encoder Representation from Transformers, BERT)[26]。当Bi‑LSTM作为编码器时,其前向LSTM与后向LSTM的隐层维度均被设置为200。为了保持一致,本文采用了同文献[8]中相同的词向量词典对输入文本进行词向量的转换;而当BERT作为编码器时,直接采用BERT中的bert‑base‑uncased模型作为基准编码模型。Bi‑LSTM作为编码器时,学习率设置为0.001,而BERT作为编码器时,学习率设置为0.000 02,衰减系数统一设置为0.95,Dropout率设置为0.3,训练的batch大小为16,正则化方法为L2正则化。训练过程中,极性数据集中的样本同共情数据集内的样本进行组合,以成对的形式输入到网络架构内。实验框架为Pytorch,优化器采用Adam[27]。
3.2 消融实验
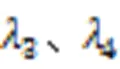
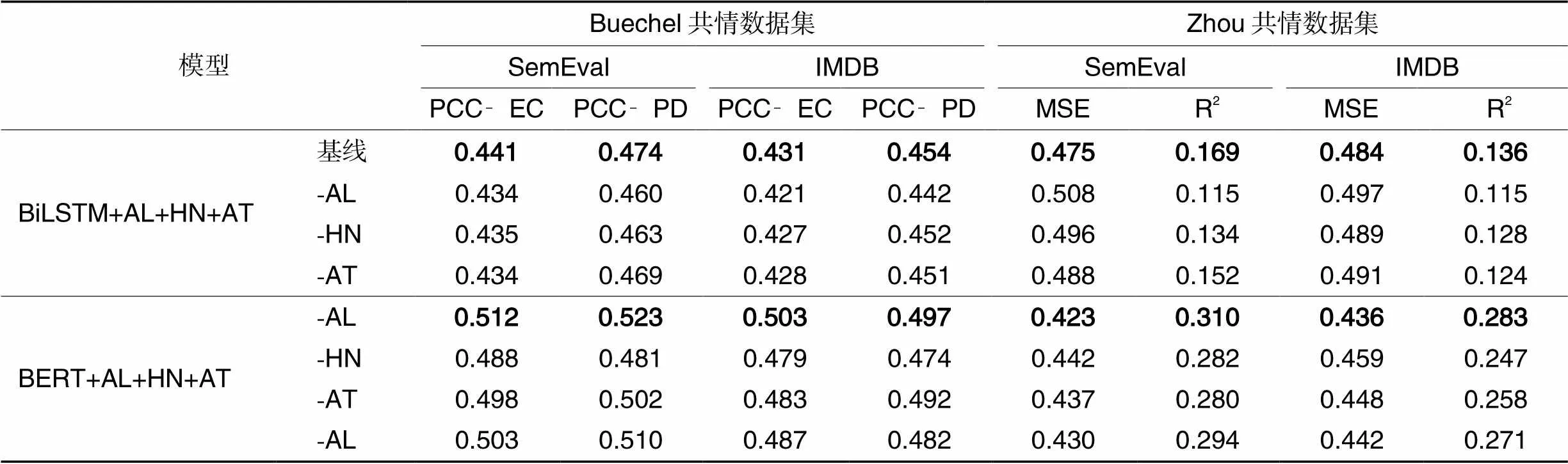
表2 两个共情数据集上的消融实验结果
从表2的实验结果中可得出以下三点结论:
首先,从实验结果中可以看出,AL对共情预测取得了最明显的辅助作用,即AL模块的贡献最高。造成这一结果的原因是共情与极性这两个标签都具备一定的情感属性,因此两者间的标签差异较小;但与此同时,其数据集领域差异要明显更大,例如Buechel共情数据集主要来自Twitter上的用户推文,而IMDB极性分类数据集则主要来自用户电影评论,这两个数据集领域之间的分布差异非常大。因此,对于共情预测与极性分类这两个任务而言,其数据集领域差异要大于标签差异。三个模块中,AL模块的主要作用便是缩小数据集领域差异,其余两个模块对于缩小数据集领域的差异的功效远小于AL模块。因此,AL模块可以最大限度地缩小两个任务之间的差异,进而取得更好的实验结果。
其次,对于BiLSTM与BERT这两种编码器而言,当BERT作为编码器时,实验结果要更优。针对这一现象,推测原因主要是Bi‑LSTM作为编码器时模型是随机初始化的,而当BERT模型作为编码器时,本文直接使用了预训练模型bert‑base‑uncased作为编码器。预训练模型bert‑base‑uncased已经在大规模的文本数据上提前进行了训练,因此预训练模型内已经包含了非常多的先验信息,所以输入文本通过预训练模型进行编码必定可以获得更好的编码特征表达,从而当BERT作为编码器时可以取得更好的实验结果。
第三,从实验结果可以看出,极性数据集SemEval的实验结果要明显优于IMDB的实验结果。造成这一现象的原因是SemEval数据集主要来自用户推文,因此包含了各种类型和各类领域的极性数据;而IMDB主要来自电影评论这一单独领域。实验结果说明丰富多样的极性数据相较于单一来源的极性数据往往可以取得更好的实验增益效果。尤其是当共情数据集的来源也较为丰富时,例如以Buechel共情数据集为例,它同样来自各式各样的用户推文,从表2的实验结果可以看出,此时极性SemEval数据集的辅助增益效果明显优于极性数据集IMDB。
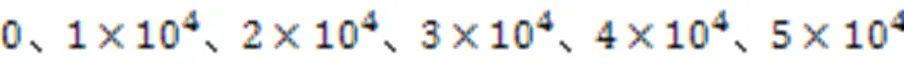
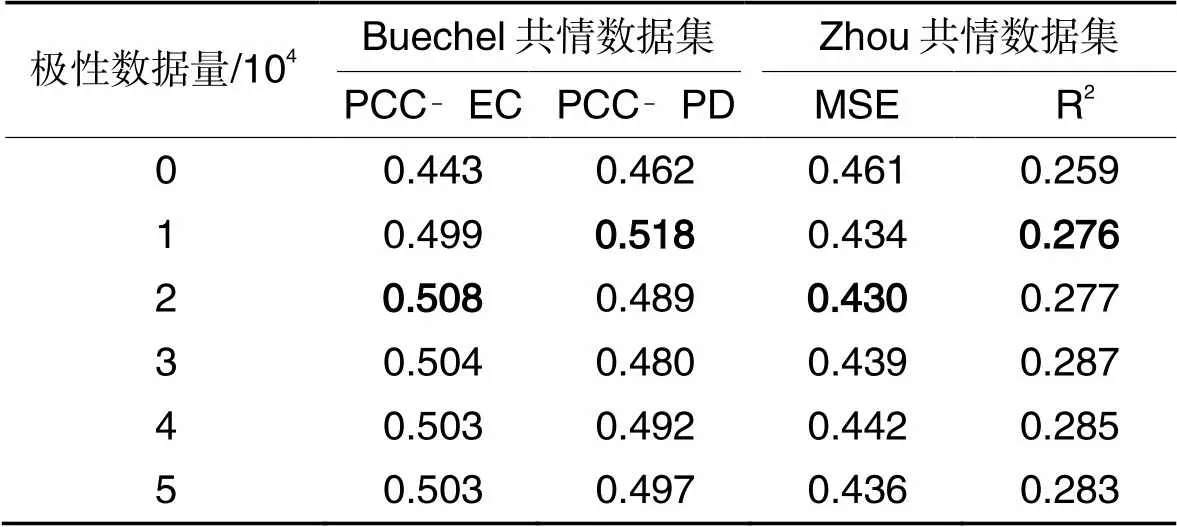
表3 基于不同极性数据量的消融实验结果
3.3 同相关工作的比较
同相关工作的比较主要分为两类,分别是不进行迁移学习的工作,即只使用共情数据进行共情预测的方法,例如前馈神经网络(Feedforwardl Neural Network, FNN)、卷积神经网络(Convolutional Neural Network, CNN)等,这些不进行迁移学习工作的实验结果直接来源于文献[8-9];第二类比较的工作为利用共情数据进行迁移学习的相关工作,例如双向对抗迁移网络(Dual Adversarial Transfer Network, DATNet)[23]、基于自注意力的对抗迁移网络ADV‑SA(ADVersarial transfer learning with Self‑Attention)[24]等,本文同样复现了这些方法并进行比较。实验结果如表4、5所示。从表4、5可以看出,本文方法Bi‑LSTM+AL+AT+HN与BERT+AL+AT+HN的实验结果无论在Buechel共情数据集上还是在Zhou共情数据集上,都取得了最好的结果。具体分析而言,相较于不进行迁移学习的工作,例如CNN,FNN、BERT、Random Forest等,本文方法的性能明显更优。这是因为本文方法可以通过大规模的极性分类数据集帮助小规模的共情分析数据集学习到更好的公共特征表达,从而使共情预测的性能更好。除此之外,相较于DATNet、ADV‑SA等进行迁移学习的工作,本文方法的实验结果也更优。这是因为本文方法不仅通过对抗学习的方式降低了两个任务间领域差异所带来的干扰;也通过设计Hinge‑loss的方式减少了两个任务间标签差异所带来的干扰,从而使学习到的可迁移的公共特征对于不同的领域、不同的标签都是普适且高效的。
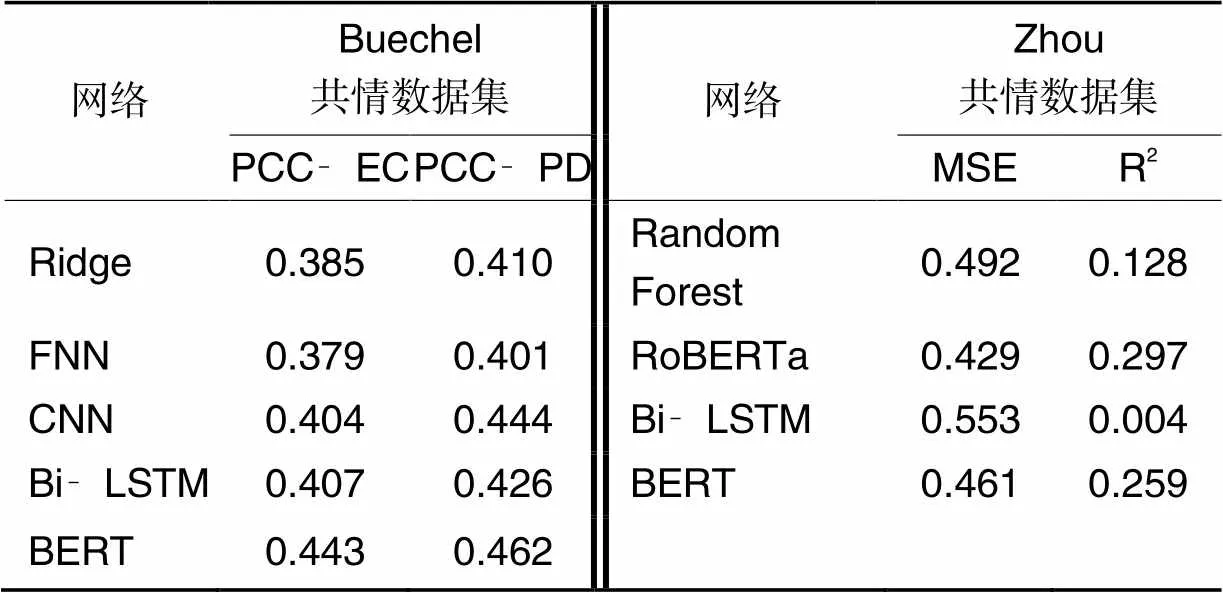
表4 不进行迁移学习的实验结果
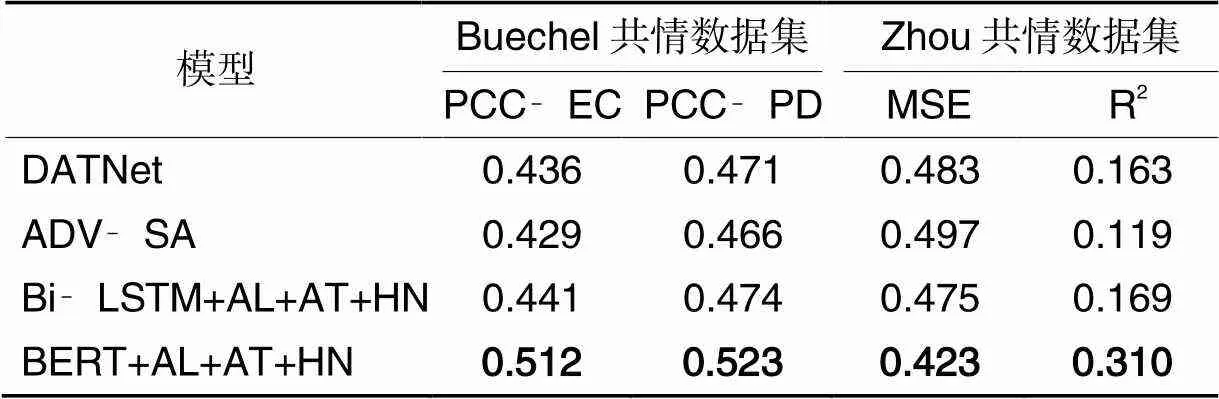
表5 进行迁移学习的实验结果
3.4 样例分析
本文选取了两条来源于Buechel共情数据集中的样例作为分析目标,两条样例分别对应高共情与低共情。实验结果如表6所示,每条样例包括两个共情标签,分别是EC和PD,标签的取值范围是1~7。将该样例内的情感词通过添加下划线的方式进行凸显,表6中的Baseline为BERT模型的实验结果。
示例1: I am soto hear that, and I am realabout that you canit. I believe it!
示例2: This doesn’t sounde to me. If you are affected, then you should decide as an individual to find another options.
表6样例分析实验结果
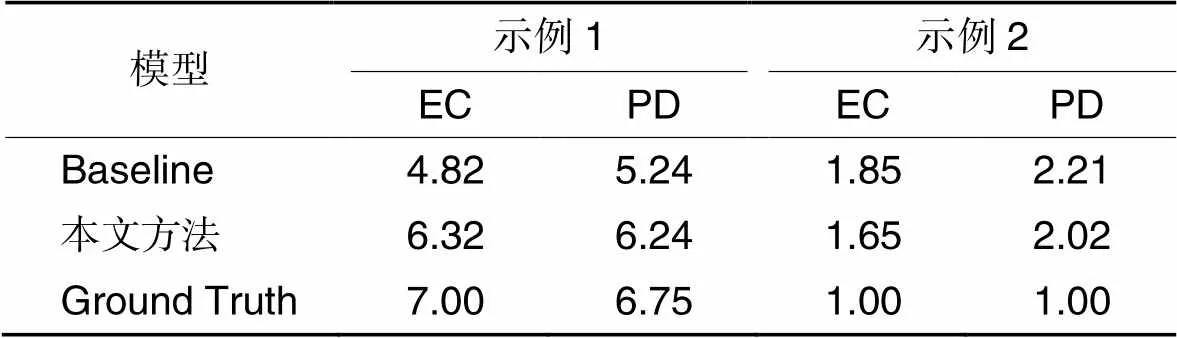
Tab.6 Experimental results of case analysis
从表6中可以得出两个结论:
首先是本文方法相较于传统方法可以更好地进行共情预测,这是因为本文方法可以更好地对句子内的情感词进行建模分析。以第一个样例中hopeful这一情感词为例,它在共情数据集内共出现13次,与此同时,它在极性数据集内出现了86次,其变形词“hope”“hopefully”在极性数据集内的出现次数更是高达468。因此,这些极性数据样例可以很好地帮助共情预测任务取得更好的实验结果。
其次,通过两条样例的实验结果可以看出,本文方法对于高共情值样例的预测精度要高于低共情值样例。这是因为,一般而言,高共情样例中往往包含更多的情感词汇与情感属性,而低共情值中相关信息较少,例如样例二中仅包含“not worrisome”这一个情感词汇。由于采用的辅助数据集为文本情感分类数据,其中包含大量的情感词汇与信息,因此在这些数据的辅助作用下,模型会对情感词汇、信息更为敏感。故本文方法对高共情值样例的预测精度与提升效果会更突出。
4 结语
为了解决数据量小所导致的文本共情预测准确率低这一问题,本文提出了一种新的迁移学习方法。该方法从拥有大量数据的极性分类任务中学习到可迁移的公共特征,并通过这些公共特征来辅助共情预测任务。具体而言,该方法首先通过注意力模块对公私有特征进行动态加权,从而使融合特征可以更好地进行共情预测。其次,针对共情预测与极性分类两个任务间领域与标签的差异,设计了一种对抗学习策略来降低两个任务间数据集领域不同所带来的差异;并设计了一种Hinge‑loss约束策略来消除两个任务间标签不同所带来的差异。实验结果也表明本文方法取得了较好的预测精度。
[1] BELLET P S, MALONEY M J. The importance of empathy as an interviewing skill in medicine[J]. Journal of the American Medical Association, 1991, 266(13): 1831-1832.
[2] BATSON C D, FULTZ J, SCHOENRADE P A. Distress and empathy: two qualitatively distinct vicarious emotions with different motivational consequences[J]. Journal of Personality, 1987, 55(1): 19-39.
[3] BASCH M F. Empathic understanding: a review of the concept and some theoretical considerations[J]. Journal of the American Psychoanalytic Association, 1983, 31(1): 101-126.
[4] SOBER E, WILSON D S. Summary of: ‘Unto others: the evolution and psychology of unselfish behavior’[J]. Journal of Consciousness Studies, 2000, 7(1/2): 185-206.
[5] FUNG P, DEY A, SIDDIQUE F B, et al. Zara the supergirl: an empathetic personality recognition system[C]// Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Demonstrations. Stroudsburg, PA: Association for Computational Linguistics, 2016: 87-91.
[6] ALAM F, DANIELI M, RICCARDI G. Annotating and modeling empathy in spoken conversations[J]. Computer Speech & Language, 2018, 50: 40-61.
[7] MAJUMDER N, HONG P, PENG S, et al. MIME: MIMicking Emotions for empathetic response generation [EB/OL]. [2021-04-28]. https://arxiv.org/pdf/2010.01454.pdf.
[8] BUECHEL S, BUFFONE A, SLAFF B, et al. Modeling empathy and distress in reaction to news stories[EB/OL]. [2021-06-15]. https://arxiv.org/pdf/1808.10399.pdf.
[9] ZHOU N, JURGENS D. Condolences and empathy in online communities[C]// Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2020: 609-626.
[10] SHARMA A, MINER A S, ATKINS D C, et al. A computational approach to understanding empathy expressed in text‑based mental health support. [EB/OL]. [2021-05-09]. https://arxiv.org/pdf/2009.08441.pdf.
[11] PANG B, LEE L. Seeing stars: exploiting class relationships for sentiment categorization with respect to rating scales[C]// Proceedings of the 43rd Annual Meeting on Association for Computational Linguistics. Stroudsburg, PA: Association for Computational Linguistics, 2005: 115-124.
[12] ROSENTHAL S, FARRA N, NAKOV P. SemEval‑2017 task 4: sentiment analysis in Twitter[C]// Proceedings of the 11th International Workshop on Semantic Evaluation. Stroudsburg, PA: Association for Computational Linguistics, 2017: 502-518.
[13] BHATT H S, ROY S, RAJKUMAR A, et al. Learning transferable feature representations using neural networks[C]// Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: Association for Computational Linguistics, 2019: 4124-4134.
[14] MAAS A, DALY R E, PHAM P T, et al. Learning word vectors for sentiment analysis[C]// Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg, PA: Association for Computational Linguistics, 2011: 142-150.
[15] XIAO B, CAN D, GEORGIOU P G, et al. Analyzing the language of therapist empathy in motivational interview based psychotherapy[C]// Proceedings of the 2012 Asia Pacific Signal and Information Processing Association Annual Summit and Conference. [S.l.]: PMC, 2012: 6411762.
[16] KHANPOUR H, CARAGEA C, BIYANI P. Identifying empathetic messages in online health communities[C]// Proceedings of the Eighth International Joint Conference on Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2017, 2: 246-251.
[17] ZHOU K, AIELLO L M, SCEPANOVIC S, et al. The language of situational empathy[J]. Proceedings of the ACM on Human‑ Computer Interaction, 2021, 5(CSCW1): Article No. 13.
[18] DREDZE M, KULESZA A, CRAMMER K. Multi‑domain learning by confidence‑weighted parameter combination[J]. Machine Learning, 2010, 79(1): 123-149.
[19] PAN S J, YANG Q. A survey on transfer learning[J]. IEEE Transactions on Knowledge and Data Engineering, 2009, 22(10): 1345-1359.
[20] HUANG J, GRETTON A, BORGWARDT K, et al. Correcting sample selection bias by unlabeled data[C]// Proceedings of the 19th International Conference on Neural Information Processing Systems. Cambridge, MA: MIT Press, 2006: 601-608.
[21] SUGIYAMA M, SUZUKI T, NAKAJIMA S, et al. Direct importance estimation for covariate shift adaptation[J]. Annals of the Institute of Statistical Mathematics, 2008, 60(4): 699-746.
[22] MALMI E, SEVERYN A, ROTHE S. Unsupervised text style transfer with padded masked language models[EB/OL].[2021-06-28]. https://arxiv.org/pdf/2010.01054.pdf.
[23] ZHOU J T, ZHANG H, JIN D, et al. Dual adversarial neural transfer for low‑resource named entity recognition[C]// Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: Association for Computational Linguistics, 2019: 3461-3471.
[24] CAO P, CHEN Y, LIU K, et al. Adversarial transfer learning for Chinese named entity recognition with self‑attention mechanism[C]// Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2018: 182-192.
[25] GRAVES A, FERNÁNDEZ S, SCHMIDHUBER J. Bidirectional LSTM networks for improved phoneme classification and recognition[C]// Proceedings of the 2005 International Conference on Artificial Neural Networks, LNTCS 3697. Berlin: Springer, 2005: 799-804.
[26] DEVLIN J, CHANG M W, LEE K, et al. BERT: pre‑training of deep bidirectional transformers for language understanding. [EB/OL]. [2021-09-01]. https://arxiv.org/pdf/1810.04805.pdf.
[27] KINGMA D P, AND BA J. Adam: a method for stochastic optimization. [EB/OL]. [2021-06-08]. https://arxiv.org/pdf/1412.6980.pdf.
Empathy prediction from texts based on transfer learning
LI Chenguang1, ZHANG Bo2, ZHAO Qian2, CHEN Xiaoping1, WANG Xingfu1*
(1,,230026,;2,230022,)
Empathy prediction from texts achieves little progress due to the lack of sufficient labeled data, while the related task of text sentiment polarity classification has a large number of labeled samples. Since there is a strong correlation between empathy prediction and polarity classification, a transfer learning‑based text empathy prediction method was proposed. Transferable public features were learned from the sentiment polarity classification task to assist text empathy prediction task. Firstly, a dynamic weighted fusion of public and private features between two tasks was performed through an attention mechanism. Secondly, in order to eliminate domain differences in datasets between two tasks, an adversarial learning strategy was used to distinguish the domain‑unique features from the domain‑public features between two tasks. Finally, a Hinge‑loss constraint strategy was proposed to make common features be generic for different target labels and private features be unique to different target labels. Experimental results on two benchmark datasets show that compared to the comparison transfer learning methods, the proposed method has higher Pearson Correlation Coefficient (PCC) and coefficient of determination (R2), and has lower Mean‑Square Error (MSE), which fully demonstrates the effectiveness of the proposed method.
transfer learning; text empathy prediction; text sentiment polarity classification; Nature Language Processing (NLP); deep learning
This work is partially supported by National Natural Science Foundation of China (92048301), Science and Technology Project of Anhui Electric Power Company Limited (52120018004x).
LI Chenguang, born in 1999, M. S. candidate. His research interests include emotion recognition, natural language processing.
ZHANG Bo, born in 1966, M. S., senior engineer. His research interests include power marketing service management.
ZHAO Qian, born in 1976, M. S., senior engineer. His research interests include power marketing service management.
CHEN Xiaoping, born in 1955, Ph. D., professor. His research interests include agent formal modeling, multi‑robot system.
WANG Xingfu, born in 1965, Ph. D., associate professor. His research interests include natural language processing, emotional analysis.
TP391.1
A
1001-9081(2022)11-3603-07
10.11772/j.issn.1001-9081.2021091632
2021⁃09⁃15;
2022⁃01⁃17;
2022⁃01⁃28。
国家自然科学基金资助项目(92048301);安徽省电力有限公司科技项目(52120018004x)。
李晨光(1999—),男,河南许昌人,硕士研究生,主要研究方向:情感识别、自然语言处理;张波(1966—),男,安徽淮南人,高级工程师,硕士,主要研究方向:电力营销服务管理;赵骞(1976—),男,安徽合肥人,高级工程师,硕士,主要研究方向:电力营销服务管理;陈小平(1955—),男,重庆人,教授,博士,主要研究方向:智能体形式化建模、多机器人系统;王行甫(1965—),男,安徽合肥人,副教授,博士,主要研究方向:自然语言处理、情感分析。
