融合优化特征提取结构的目标检测算法
2022-11-30向南潘传忠虞高翔
向南,潘传忠,虞高翔
融合优化特征提取结构的目标检测算法
向南*,潘传忠,虞高翔
(重庆理工大学 两江国际学院,重庆 401135)(∗通信作者电子邮箱xiangnan@cqut.edu.cn)
针对DETR对小目标的检测精度低的问题,基于DETR提出一种优化特征提取结构的目标检测算法——CF‑DETR。首先通过结合了优化跨阶段部分(CSP)网络的CSP‑Darknet53对原始图进行特征提取并输出4种尺度的特征图;其次利用特征金字塔网络(FPN)对4种尺度特征图进行下采样和上采样后进行拼接融合,并输出52×52尺寸的特征图;最后将该特征图与位置编码信息结合输入Transformer后得到特征序列,输入到作为预测头的前向反馈网络后输出预测目标的类别与位置信息。在COCO2017数据集上,与DETR相比,CF‑DETR的模型的超参数量减少了2×106,在小目标上的平均检测精度提高2.1个百分点,在中、大尺寸目标上的平均检测精度提高了2.3个百分点。实验结果表明,优化特征提取结构能够在降低模型超参数量的同时有效提高DETR的检测精度。
目标检测;小目标;DETR算法;特征提取;跨阶段部分网络;特征金字塔网络;Transformer
0 引言
目标检测是一项应用型研究,其目的是在数字图像中快速准确地检测出目标物体的种类和位置。随着近年来硬件的发展以及深度学习的广泛应用,基于深度学习的目标检测取得了突破性的进展。深度学习中的卷积神经网络(Convolutional Neural Network, CNN)能够提取数字图像信息的特征,提升了目标检测的精度。现代基于深度学习的目标检测方法大多是在文献[1]提出的CNN基础上,通过不断地卷积间接地得到目标信息,需要考虑大量的边界框、anchor以及窗口中心点等信息。本文提出一种以DEtection TRansformer(DETR)算法[2]为基础,结合改进跨阶段部分(Cross Stage Partial, CSP)网络[3]与特征金字塔网络(Feature Pyramid Network, FPN)[4]结构的目标检测算法,该算法无需考虑anchor、边界框等信息,能直接输出目标物体在图像中的类别以及位置信息,在保证目标检测的速度同时能够进一步提升在小目标物体上的平均检测精度(Average Precision, AP)。
1 相关研究
近年来,基于CNN的目标检测算法逐渐成为主流的检测算法。基于CNN的目标检测算法基于阶段数的不同,可分为单阶段、二阶段、多阶段。Grishick等[5]提出了R‑CNN(Regions with Convolutional Neural Network)二阶段目标检测算法,需要先在图像上获取候选区域,再对候选区域进行分类和回归,在传统的方法上引入深度学习方法极大提高了检测的精度。Cai等[6]提出的Cascade‑RCNN作为多阶段目标检测算法,其检测步骤与二阶段相似,不同的是多阶段目标检测算法会反复修正候选区域,在不降低检测速率的情况下提高了目标检测的准确率。二阶段目标检测算法在精度上取得了阶段性的胜利,但是由于体量大而无法达到实时同步检测的速度。于是单阶段端到端的YOLO算法[7-9]、RetinaNet算法[10]、EfficienDet算法[11]等优秀目标检测算法被提出。在2020年,Bochkovskiy等[12]提出了YOLOv4算法,这是YOLO目标检测算法的第四代版本,作为轻体量模型在检测精度堪比二阶段的同时检测速度大幅提高。YOLOv4的Backbone是在CSP‑Darknet53基础上引入CSP结构的CSP‑Darknet53,与作为Neck部分的PANet(Path Aggregation Network)算法[13]搭配后,大幅提高了算法的精度与速度。江金洪等[14]在YOLOv3的基础上提出了深度可分离卷积,显著地降低了超参数量,提高了运算效率。徐利锋等[15]提出将FPN结构应用到DenseNet,构建多尺度特征模块以达到提高小目标检测精度的目的。
DETR是Facebook AI Research提出的基于Transformer算法[16]的端到端目标检测算法,属于单阶段端到端目标检测算法的延伸,它没有非极大值抑制(Non‑Maximum Suppression, NMS)处理步骤,没有anchor,在COCO2017数据集上训练300个epoch后的检测精度与Faster RCNN算法[17]相当,但在小目标的检测上存在精度不足的问题。
针对DETR在小目标检测精度低的问题,本文工作主要体现在以下两个方面:1)基于DETR的baseline修改其Backbone部分,将ResNet[18]替换为优化CSP结构的CSP‑ Darknet53,并将输出阶段由1个增加到4个;2)引入Neck部分,通过改进FPN结构扩充输出特征图尺度,降低小目标的漏检率。
1.1 DETR原理
DETR结构如图1所示,由作为Backbone的特征提取网络ResNet50、Transformer Encoder‑Decoder和Prediction Heads组成。ResNet50可分为5个阶段,对图片进行特征提取后在第5个阶段输出特征图。先对原始图进行位置编码,然后调整为Backbone输出特征图同等尺度,将重新调整尺度的位置编码与特征图进行结合后输入Transformer编解码器。经过Transformer处理好的数据分别输入前向反馈网络集(Forward Feedback Network, FFN)后便可得到预测的类别和位置信息。DETR的总体思路是把检测看成一个集预测的问题,并且使用Transformer来预测边界框的集合。DETR利用标准Transformer架构执行传统上特定于目标检测的操作,从而简化了检测的流水线技术。
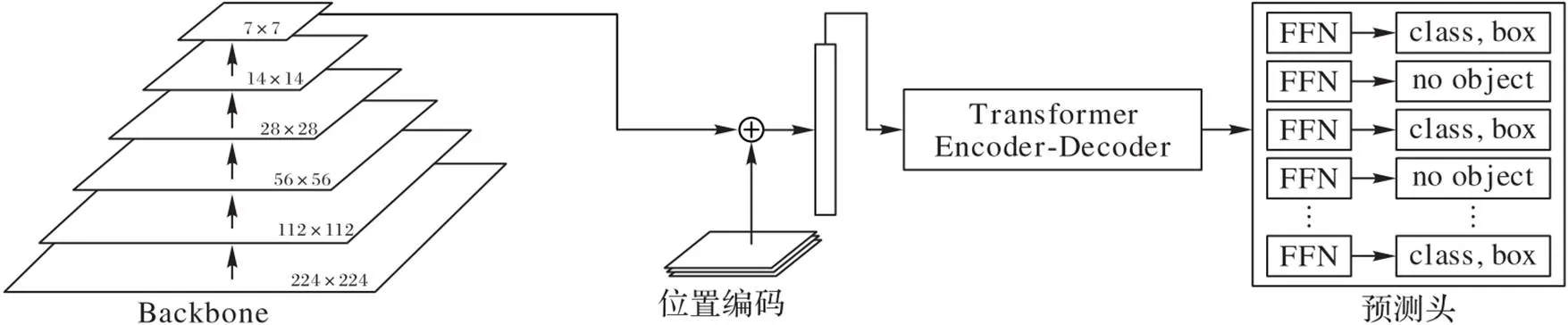
图 1 DETR网络结构
最初的检测方法中,无论是R‑CNN系列还是YOLO系列,均无法像生物一般直接标记指出物体的位置与类别,而是用密集的先验覆盖整幅图中可能出现目标的部分,然后预测该视野区域中目标的类别与位置。DETR将检测方法回归到了本质,不需要考虑anchor,也没有非极大值抑制(Non‑ Maximum Suppression,NMS)等,采用真正的端到端。并且在300个epoch训练后的DETR,在检测速率上达到28 FPS(Frames Per Second),与高度优化的Faster RCNN[15]持平,且在大目标检测效果上DETR的APL值为61.1,要优于Faster RCNN的52.0。
虽然DETR对大目标检测精度有所提升,但是仍然存在以下问题。DETR采用ResNet50作为特征提取网络,ResNet50由众多的1×1卷积层和3×3卷积层组成。由于池化操作的下采样会导致部分特征信息丢失,而且经过不断卷积,最后输出的位置信息较少。在Transformer阶段由于位置信息的缺乏,DETR检测小目标时易发生漏检及错检。针对以上问题,本文提出了CF‑DETR(DETR combined CSP‑ Darknet53 and FPN)目标检测方法。
1.2 CSP‑Darknet53+FPN
CSP‑Darknet53结构如图2所示,由下采样卷积层以及包含1×1卷积层和3×3卷积层残差模块的CSPResNet结构组成。相较于ResNet50与ResNet101,CSP‑Darknet53的最小输出尺寸更大,能输出的阶段数更多,所以会有更好的FPN结构效果。相较于YOLOv3的Darknet53,结合CSP结构后Backbone的超参数量大幅减少,能够有效提高检测速率。以416×416尺度的图像作为输入,经过一次步长为2的下采样卷积后通过第一个阶段的一次残差后得到2倍下采样特征图。继续下采样通过2次残差得到尺度为104×104的4倍下采样特征图。通过后续的卷积下采样与残差块,依次得到作为输出的8倍下采样尺度52×52特征图、16倍下采样尺度26×26特征图、32倍下采样尺度13×13特征图。
FPN是传统CNN增强图片信息进行表达输出的一种方法。其目的是改进CNN的特征提取方式,以使最终输出的特征更好地表示出输入图片各个维度的信息。它可以分成两个阶段进行:自底向上的通路,即自下至上的不同维度特征生成;自上至下的通路,即自上至下的特征补充增强。自底向上的通路就是特征提取网络的前向过程,即CSP‑Darknet53中各尺度特征图的生成;自上至下的过程采用上采样结合同等大小的特征图进行融合,最终可输出多个尺度的特征增强的特征图。
在CNN中,在多次卷积下,低层的特征图含有较少的语义信息,但是含有较多的位置信息;而高层的特征图中则含有较多的语义信息,但是含有较少的位置信息。CSP‑Darknet53采用了类似ResNet的方式,使用了大量跳跃连接结构保证了训练不会出现梯度弥散的现象。CSP‑ Darknet53还采用了步长为2的卷积层代替最大池化操作实现下采样,这样不仅减少了下采样过程中的计算量,还极大地保留了更多低层的特征信息。所以使用CSP‑Darknet53结合FPN结构进而将高层与低层的信息相融合,可以提升目标检测的准确率。
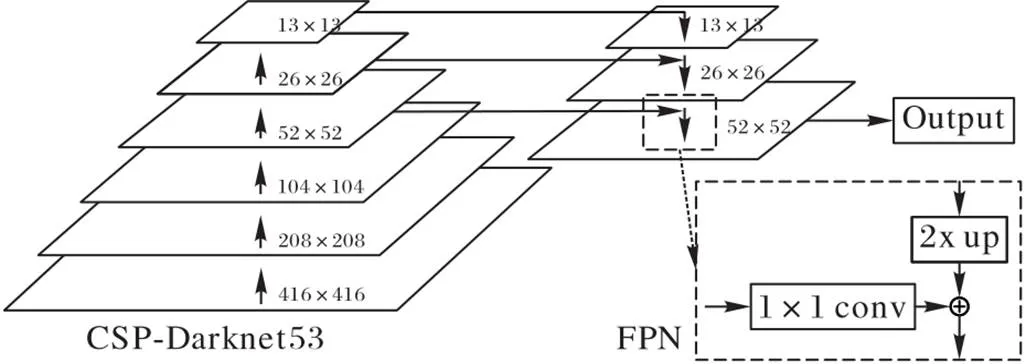
图 2 结合FPN结构的Darknet53
2 CF‑DETR原理
本文提出的CF‑DETR目标检测方法是在DETR算法主框架下使用改进CSP‑Darknet53,同时结合FPN结构的改进方法。如图3所示,其中前端数据输入在包含改进CSP结构的Backbone中进行预处理,在对数据处理前的Neck部分采用FPN结构对特征图进行上采样与下采样后融合,进而放大特征图尺度,从而保留更多小目标的特征信息。经过Neck部分的FPN输出的52×52尺度的特征图结合位置编码输入Transformer进行编译码后,通过预测头输出预测目标的类别和位置信息。CF‑DETR在增加网络深度、提高检测精度的同时,使模型轻量化,大幅降低模型检测所需超参数量。

图 3 CF‑DETR网络结构
2.1 改进的CSP‑Darknet53
为提高融合多尺度特征和准确识别小目标的能力,本文改进了CSP‑Darknet53多尺度特征图输出网络,称为Im‑CSPR(Improved CSPResNet),其结构如图4所示。为了避免CSPR(CSPResNet)对于前段通道特征图的语义信息提取的忽视,Im‑CSPR将原本的特征图通过两个阶段6次Split卷积形成4个与原特征图尺寸大小相同、但通道数为原特征图1/4的子特征图,并对前后段通道的子特征图进行残差卷积处理以充分提取图像的语义信息。Im‑CSPR保留了ResNet的特征复用特性的优点,同时也通过截断梯度流,防止了过多的重复梯度信息。这一思想通过设计分层特征融合策略并用于ResBlock层来实现。
在特征提取过程中经过卷积层数越多的特征图,所经历的卷积核越多,在众多卷积核超参数的特征提取后所蕴含的语义信息越丰富。由于卷积过程涉及大量卷积核超参数,所以增加了内存成本与计算瓶颈。设卷积核大小为,输入通道数为,输出通道数为,则一个卷积层的超参数的数量可由式(1)计算得到。
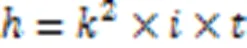
而ResBlock中使用的一个1×1卷积结合一个3×3的卷积后叠加组成,那么在CSP结构中可计算卷积所需超参数量如式(2)所示。
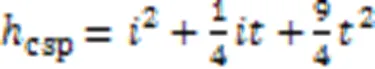
Im‑CSPR结构中计算卷积所需要的超参数量如式(3)所示。
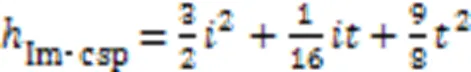

一般情况下,输入的图片矩阵以及后面的卷积核,特征图矩阵都是方阵,设卷积输入矩阵大小为×,卷积核大小为,卷积步幅为,padding为,则卷积后产生的特征图大小可通过式(4)计算获得。
本文输入图像大小为416×416像素。Im‑CSPR将输出阶段由CSP‑Darknet53的三个阶段增加到了四个阶段,经过5次为2、为2、为1的下采样卷积后,输出的特征图尺度由13×13、26×26、52×52、104×104这组不同尺度组成。
在Backbone特征提取的前向过程中,特征图的大小在经过某些层后会改变,而在经过其他一些层时不会改变。本文将不改变特征图大小的层归为一个阶段,这样就能构成特征金字塔。原本的CSP‑Darknet53第二个阶段中对104×104尺度的特征图进行两次残差,Im‑CSPR额外地将第一次残差后的104×104尺度的特征图进行输出。将有较多位置信息、尺度较大的104×104特征图输入FPN,再对多尺度的特征图进行融合处理。相较于ResNet50只输出1个阶段,Im‑CSPR包含4个输出阶段,将多尺度特征的语义信息与位置信息输出到Neck阶段进行特征增强,从而提高了目标检测的准确率。
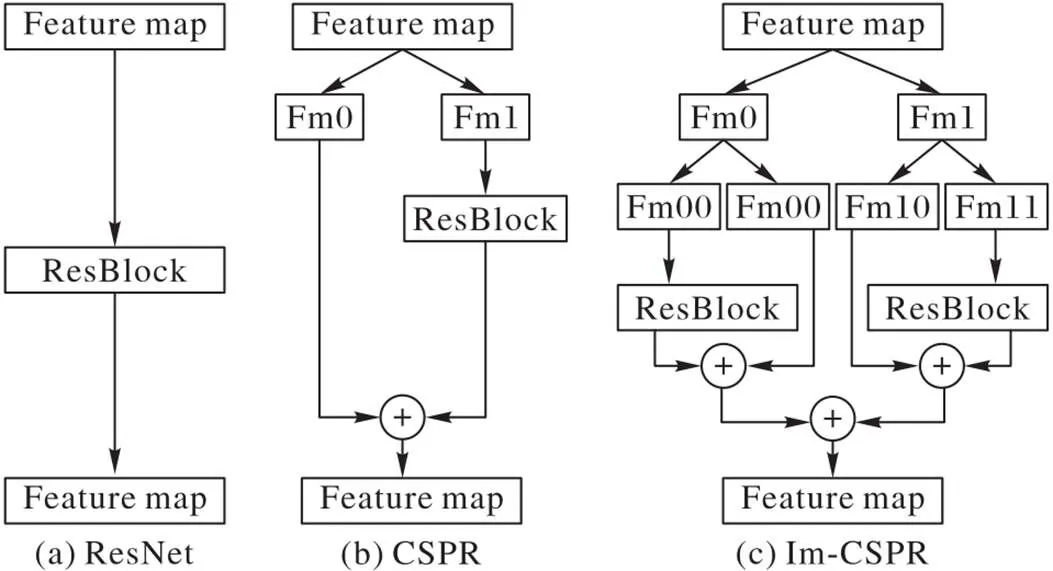
图 4 三种不同残差结构的对比
2.2 改进的FPN
FPN是利用深度CNN固有的多尺度、多层级的金字塔结构去构建,同时使用一种自上而下的侧边连接方式,在多尺度构建了高级语义的特征图。这就需要使用FPN来融合多层特征以及改进CNN的特征提取。DETR的ResNet50直接输出缩小到原尺寸1/32的下采样特征图去检测目标,所以当目标在输入为416×416像素大小的原图中,其所占的像素面积小于13×13时,是无法检测到的。为了降低这一小目标物体容易被误筛的概率,引入了改进的FPN结构。
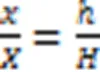
CF‑DETR中引进了FPN结构以减小输出特征图的下采样倍数,增大输出特征图的尺度。FPN往往用于上采样并配上三个尺度逐渐缩小的特征图,改进的FPN结构通过输入四个不同尺寸的特征图,对多尺度特征图进行上采样与下采样相结合的方法进行处理。最终拼接融合后输出一张52×52的特征图,从而保留更多的位置信息并提高小目标检测的精度。
2.3 损失函数
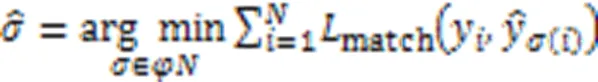
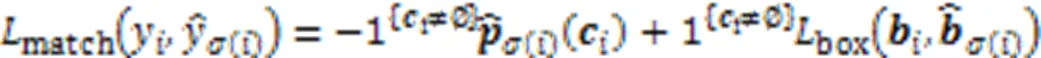

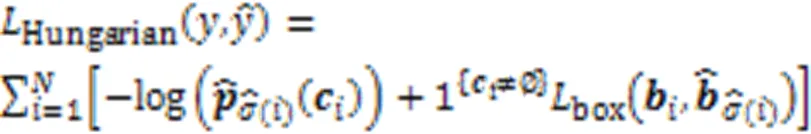
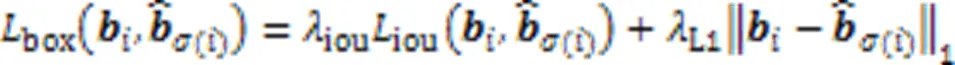
3 实验结果与分析
3.1 数据集的选取
本文实验选取COCO2017数据集进行训练与验证。COCO2017数据集一共有五种标注类型,本次实验使用实例类型的标注信息。COCO2017包含90个类,训练集包含共11 GB大小的118×103张图片,验证集包含共1 GB大小的5×103张图片。训练集中平均每张图片包含7个目标,最多单张图片包含63个目标,这些目标覆盖小、中、大三种尺寸。本文实验会计算每个训练轮次后验证集的AP值并记录log文件中。
3.2 实验环境及实验过程
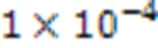
3.3 评价指标
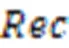
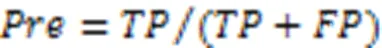
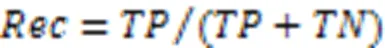
3.4 实验结果
选取DETR不同Backbone模型中的DETR‑R50‑DC5、DETR‑R50、DETR‑R101、DETR‑Dn53‑FPN与CF‑DETR进行对比实验,以验证本文方法CF‑DETR的有效性。其中DETR‑R50‑DC5、DETR‑R50、DETR‑R101在50个epoch下训练结果的实验数据根据Facebook AI实验室所发布的数据作为参照;DETR‑Dn53‑FPN则为DETR模型使用Darknet53作为Backbone并结合FPN结构,且未加入CSP结构的消融对比实验所用模型。模型参数量对比数据如表1所示,模型精度对比如表2所示。
表2中:AP表示平均检测精度;50表示广义交并比阈值为50%时的检测精度;S、M、L表示对小、中、大三种尺寸目标的检测精度。对比实验表明:未加Im‑CSPR结构的Darknet53+FPN使DETR检测精度提高了2.7个百分点,FPS降低了8,且超参数量相对DETR增加了63%,与其他对比模型比较,在小、中、大三种尺度的目标检测精度上均表现SOTA(State Of The Art)。而加入Im‑CSP结构的CF‑DETR的超参数量是所有对比DETR模型的中最小的,且FPS相对未加入Im‑CSP结构前增加了6。
本文模型检测效果如图5所示。Im‑CSPR‑Darknet+FPN结构的引入使检测速度有一定下降,虽然改进的CF‑DETR参数量少于对比的其他模型,但是由于其结构的复杂性使检测速率降低。本实验暂时只做了50个epoch训练结果的数据对比,通过更多epoch训练后的模型检测精度可以优于DETR对标的Faster RCNN模型。
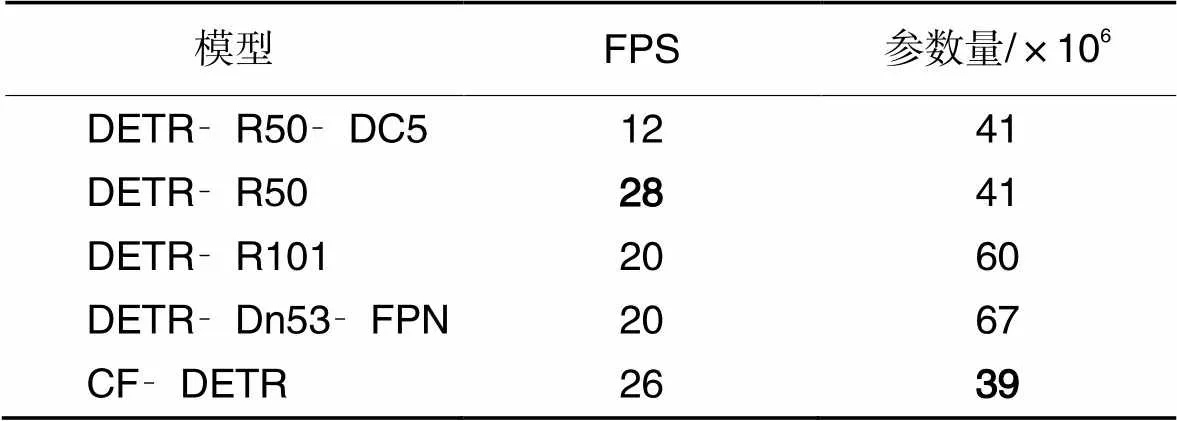
表1 模型参数量与每秒传输帧数的对比
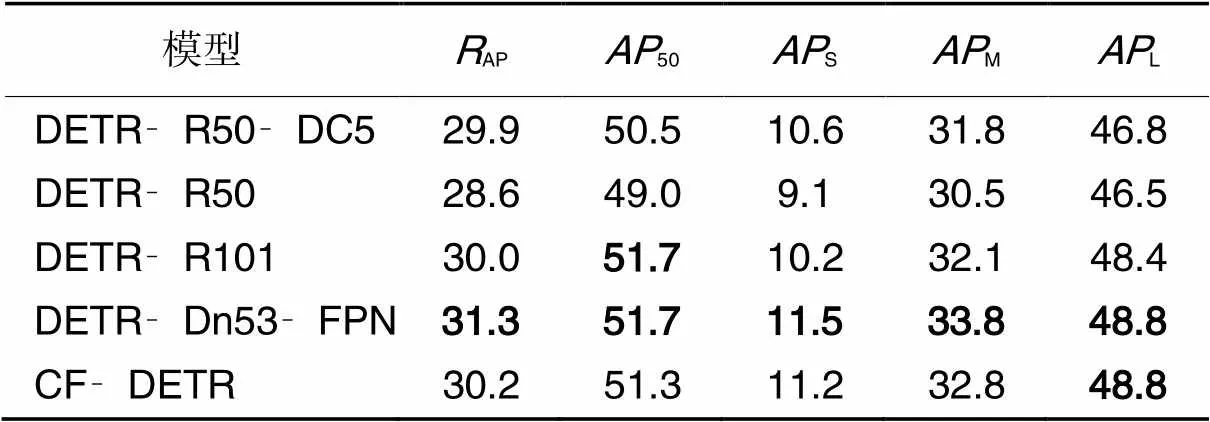
表 2 模型精度对比 单位: %

图 5 测试图片检测效果
4 结语
针对DETR模型在小目标检测上精度难以保证的问题,本文提出了CF‑DETR目标检测方法,融入了丰富的位置信息及上下文信息,同时减少了特征图下采样导致的特征丢失。实验结果表明CF‑DETR有效提高了小目标检测的精度,减少了小目标的错检漏检;但是由于引入FPN结构后模型复杂度增加,以及Im‑CSPR需要计算卷积次数的计算量增加,检测速度有所降低。虽然CSP结构对于超参数量的减少有较大作用,从而提高了模型的检测速率,但同时也降低了模型的检测精度。其他诸如DeepWise卷积结构、倒残差卷积结构这类降低超参数量结构的引入,可能在降低超参数量、提高检测速率的同时不降低检测精度。另一方面,在提高检测速率、降低超参数量的同时,引入注意力模块也可弥补检测精度不足的问题。下一步的研究计划就是如何平衡检测精度与检测速度的问题。
[1] KRIZHEVSKY A, SUTSKEVER I, HINTON G E. ImageNet classification with deep convolutional neural networks[C]// Proceedings of the 25th International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2012: 1097-1105.
[2] CARION N, MASSA F, SYNNAEVE G, et al. End‑to‑end object detection with transformers[C]// Proceedings of the 2020 European Conference on Computer Vision, LNCS 12346. Cham: Springer, 2020: 213-229.
[3] WANG C Y, LIAO H Y M, WU Y H, et al. CSPNet: a new backbone that can enhance learning capability of CNN[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. Piscataway: IEEE, 2020: 1571-1580.
[4] LIN T Y, DOLLÁR P, GIRSHICK R, et al. Feature pyramid networks for object detection[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 936-944.
[5] GIRSHICK R, DONAHUE J, DARRELL T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]// Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2014: 580-587.
[6] CAI Z W, VASCONCELOS N. Cascade R‑CNN: delving into high quality object detection[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 6154-6162.
[7] REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, real‑time object detection[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 779-788.
[8] REDMON J, FARHADI A. YOLO9000: better, faster, stronger[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 6517-6525.
[9] REDMON J, FARHADI A. YOLOv3: an incremental improvement[EB/OL]. (2018-04-08)[2021-09-23]. https://arxiv.org/pdf/1804.02767.pdf.
[10] LIN T Y, GOYAL P, GIRSHICK R, et al. Focal loss for dense object detection[C]// Proceedings of the 2017 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2017: 2999-3007.
[11] TAN M X, PANG R M, LE Q V. EfficientDet: scalable and efficient object detection[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 10778-10787.
[12] BOCHKOVSKIY A, WANG C Y, LIAO H Y M. YOLOv4: optimal speed and accuracy of object detection[EB/OL]. (2020-04-23)[2021-09-08]. https://arxiv.org/pdf/2004.10934.pdf.
[13] LIU S, QI L, QIN H F, et al. Path aggregation network for instance segmentation[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 8759-8768.
[14] 江金洪,鲍胜利,史文旭,等. 基于YOLO v3算法改进的交通标志识别算法[J]. 计算机应用, 2020, 40(8): 2472-2478.(JIANG J H, BAO S L, SHI W X, et.al. Improved traffic sign recognition algorithm based on YOLO v3 algorithm[J]. Journal of Computer Applications, 2020, 40(8): 2472-2478.)
[15] 徐利锋,黄海帆,丁维龙,等. 基于改进DenseNet的水果小目标检测[J]. 浙江大学学报(工学版), 2021, 55(2):377-385.(XU L F, HUANG H F, DING W L, et al. Detection of small fruit target based on improved DenseNet[J]. Journal of Zhejiang University (Engineering Science), 2021, 55(2): 377-385.)
[16] VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2017:6000-6010.
[17] REN S Q, HE K M, GIRSHICK R, et al. Faster R‑CNN: towards real‑time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(6): 1137-1149.
[18] HE K M, ZHANG X Y, REN S Q, et al. Deep residual learning for image recognition[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 770-778.
[19] REZATOFIGHI H, TSOI N, GWAK J, et al. Generalized intersection over union: a metric and a loss for bounding box regression[C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 658-666.
Object detection algorithm combined with optimized feature extraction structure
XIANG Nan*, PAN Chuanzhong, YU Gaoxiang
(,,401135,)
Concerning the problem of low object detection precision of DEtection TRansformer (DETR) for small targets, an object detection algorithm with optimized feature extraction structure, called CF‑DETR (DETR combined CSP‑Darknet53 and Feature pyramid network), was proposed on the basis of DETR. Firstly, CSP‑Darknet53 combined with the optimized Cross Stage Partial (CSP) network was used to extract the features of the original image, and feature maps of 4 scales were output. Secondly, the Feature Pyramid Network (FPN) was used to splice and fuse the 4 scale feature maps after down‑sampling and up‑sampling, and output a 52×52 size feature map. Finally, the obtained feature map and the location coding information were combined and input into the Transformer to obtain the feature sequence. Through the Forward Feedback Networks (FFNs) as the prediction head, the category and location information of the prediction object was output. On COCO2017 dataset, compared with DETR, CF‑DETR has the number of model hyperparameters reduced by 2×106, the average detection precision of small objects improved by 2.1 percentage points, and the average detection precision of medium‑ and large‑sized objects improved by 2.3 percentage points. Experimental results show that the optimized feature extraction structure can effectively improve the DETR detection precision while reducing the number of model hyperparameters.
object detection; samll target; DEtection TRansformer (DETR) algorithm; feature extraction; Cross Stage Partial (CSP) network; Feature Pyramid Network (FPN); Transformer
This work is partially supported by National Natural Science Foundation of China (61872051), Science and Technology Research Program of Chongqing Municipal Education Commission (KJQN202001118), Application Research Project of Banan Science and Technology Commission (2018TJ02).
XIANG Nan, born in 1984, Ph. D., associate professor. His research interests include affective computing, social computing, object detection.
PAN Chuanzhong, born in 1995, M. S. candidate. His research interests include object detection.
YU Gaoxiang, born in 1995, M. S. candidate. His research interests include object detection.
1001-9081(2022)11-3558-06
10.11772/j.issn.1001-9081.2021122122
2021⁃12⁃17;
2022⁃02⁃13;
2022⁃02⁃14。
国家自然科学基金资助项目(61872051);重庆市教委科学技术研究计划项目(KJQN202001118);巴南区科委应用研究项目(2018TJ02)。
TP391.41
A
向南(1984—),男,陕西旬阳人,副教授,博士,CCF会员,主要研究方向:情感计算、社交计算、目标检测;潘传忠(1995—),男,湖北咸宁人,硕士研究生,主要研究方向:目标检测;虞高翔(1995—),男,江西上饶人,硕士研究生,主要研究方向:目标检测。
