基于自适应多目标强化学习的服务集成方法
2022-11-30郭潇李春山张宇跃初佃辉
郭潇,李春山,张宇跃,初佃辉
基于自适应多目标强化学习的服务集成方法
郭潇,李春山*,张宇跃,初佃辉
(哈尔滨工业大学(威海) 计算机科学与技术学院,山东 威海 264209)(∗通信作者电子邮箱lics@hit.edu.cn)
当前服务互联网(IoS)中的服务资源呈现精细化、专业化的趋势,功能单一的服务无法满足用户复杂多变的需求,服务集成调度方法已经成为服务计算领域的热点。现有的服务集成调度方法大都只考虑用户需求的满足,未考虑IoS生态系统的可持续性。针对上述问题,提出一种基于自适应多目标强化学习的服务集成方法,该方法在异步优势演员评论家(A3C)算法的框架下引入多目标优化策略,从而在满足用户需求的同时保证IoS生态系统的健康发展。所提方法可以根据遗憾值对多目标值集成权重进行动态调整,改善多目标强化学习中子目标值不平衡的现象。在真实大规模服务环境下进行了服务集成验证,实验结果表明所提方法相对于传统机器学习方法在大规模服务环境下求解速度更快;相较于权重固定的强化学习(RL),各目标的求解质量更均衡。
服务集成;强化学习;异步优势演员评论家算法;多目标优化;自适应权重
0 引言
服务互联网(Internet of Services, IoS)是由跨网跨域跨世界的服务构成的复杂服务网络形态。通过互联网与新一代信息技术感知大规模个性化顾客需求,IoS可以高效聚合互联网中的异构跨域服务,形成适应性的综合服务解决方案和价值链,为顾客及相关参与方带来价值[1-2]。本质上,IoS是基于各种服务网络叠聚,由海量异质跨界跨域的服务组成的、动态演化的复杂系统。每个服务能够解决或部分解决客户需求,都有对应的服务提供商,并可根据服务功能的相似性聚集形成一定的服务种群。
由于IoS中的服务精细化、专业化的趋势,导致服务提供商将服务的功能具体化、单一化。明显地,功能单一的服务无法满足用户复杂多变的需求。例如,某用户提出个人的服务需求“2021年8月在威海短期旅游一周”,这个需求包含了衣、食、住、行、景点、安全等多方面的要求。然而在真实服务场景中不存在一个服务能满足上述所有需求,需要第三方服务平台对服务资源进行集成和调度,形成服务资源的集合来满足用户需求。因此,许多科学家提出了服务集成调度方法,将多个服务组合成为一个服务集来满足用户需求。
上述方法存在两个缺陷:首先,传统方法大都只考虑用户需求的满足,未考虑IoS生态系统的可持续性。采用这些方法进行服务集成,会导致某些服务被频繁地调用,其他服务处于空闲状态。长此以往,IoS生态将会萎缩,变成少数服务提供商的自留地。其次,传统的多目标优化模型需要在初始阶段人工设定各个目标的权重,如果权重设置不当,会导致最终服务决策质量的降低。
针对上述问题,本文提出了基于自适应多目标强化学习的服务集成模型。该模型首先在基于马尔可夫决策过程(Markov Decision Process, MDP)的强化学习(Reinforcement Learning, RL)框架下对服务集成调度问题进行建模和形式化;然后选择异步优势演员评论家(Asynchronous Advantage Actor‑Critic, A3C)算法框架下的RL算法作为模型的主体算法,再结合多目标优化策略使集成模型可以在满足用户功能需求的同时促进服务生态网络健康发展;最后引入权重自适应方法平衡各子目标回报值,使每个子目标回报值在循环迭代的过程中保持增长。
1 相关工作
随着IoS的不断发展,更多的服务组合方法被提出。张龙昌等[3]利用服务之间的余弦相似性,根据服务质量(Quality of Service, QoS)属性对Web服务进行组合。他们提出了一种基于多属性决策理论的混合QoS组合的Web服务组合算法CHQoS‑WSCA,可用于评价由实数、区间值、三角模糊数和直觉模糊数描述的QoS信息。朱志良等[4]建立了Web服务的QoS属性相似度模型和功能属性相似度模型。服务之间的相似性可以从不同的角度来度量,Web服务的组合是通过语义相似性实现的。Tripathy等[5]提出了一种基于图的服务组合多粒度组合和选择模型。在该模型中,每个节点被表示为一个服务簇,通过Bellman-Ford算法找到最短路径,从而得到最优组合结果。Wu等[6]对所有满足用户需求的服务进行了组合,然后查找服务集群以找到合适的服务来替换组合过程中不可用的服务。Abdullah等[7]通过人工智能编程提出了一种新的服务组合模型。该模型生成了一个基于I/O集群技术的分层任务网络(Hierarchical Task Network, HTN),以实现服务集群规划。他们还提出了一种基于功能属性类的Web服务聚合方法,可以有效地生成HTN问题域。Cai等[8]首先根据输入和输出参数的相似性对所有功能相似的服务进行组合;然后使用服务日志决定要选择的服务;最后,通过反馈机制返回用户的反馈,提高下一个用户的满意度。Bianchini等[9]基于本体论将服务分为三个不同的级别,从服务描述中获取语义关系,通过语义关系生成本体结构,通过输入、输出和功能相似性建立服务发现模型,实现服务的发现和组合。Wang等[10]提出了一种半经验的组合方法,以实现规则组合和实时组合,通过相似性度量将具体服务和历史需求划分为不同的簇,然后通过统计分析确定服务簇和需求簇之间的对应概率。
上述研究大多从QoS角度考虑服务组合,这导致QoS高的服务被大量使用,使整个服务生态系统出现寡占性强的特性,不利于IoS的健康发展。而且在多个目标值(QoS值)集成时需要用到先验知识设定各目标权重,而大多数情况下服务提供平台缺少这种先验知识。因此需要一种既能够满足用户功能需求又可以保证服务生态系统健康发展且可以自适应调整多目标值权重的方法。
2 基于自适应多目标强化学习的服务集成
本文提出的基于自适应多目标强化学习的服务集成方法首先使用基于MDP的强化学习对服务集成问题集成形式化定义,然后选择A3C框架下的强化学习算法作为模型的主体算法,再结合多目标优化算法使该模型集成的服务组合可以在满足用户功能需求的同时促进服务生态网络健康发展,最后引入权重自适应方法平衡各子目标回报值,使每个子目标回报值增速在循环迭代的过程中保持增长。
2.1 形式化定义
由于在开放和动态环境中使用RL进行服务集成具有明显的优势,首先在基于MDP的RL框架下形式化定义IoS环境中的服务集成问题。MDP是离散时间随机控制过程,特别用于对不确定域中的顺序决策进行建模。MDP的关键组成部分正式定义[11]如下:
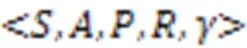
在IoS环境下,需要在MDP框架下形式化定义服务集成:
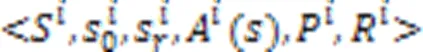
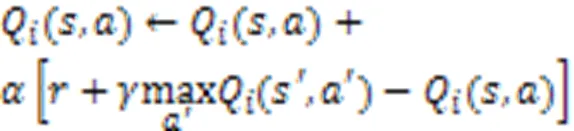

2.2 面向多目标强化学习的服务集成方法
完成服务集成问题的形式化定义后,需要选取具体的RL框架解决服务集成问题。基于价值的RL方法可以单步更新网络的超参数,但该方法通过预测动作的价值间接得到最优动作,适用于离散有限动作的RL任务。基于策略的RL方法虽然可以直接预测动作,但是一个情节结束之后才能够逆向更新网络的超参数,导致超参数更新较慢。相较于基于价值的RL方法,基于策略梯度的RL方法更适用于连续动作决策的RL任务。演员评论家(Actor‑Critic, AC)模型结合了上述两种方法的优点,既能够有限步更新网络的超参数,也能够直接预测状态的动作[13]。AC模型框架如图1所示。
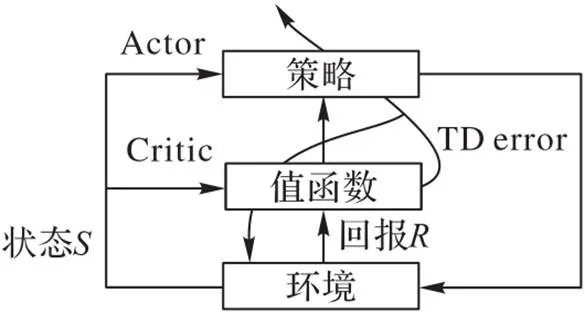
图1 AC模型框架
本文选择A3C算法作为服务集成问题的基础算法,该方法是目前基于AC模型表现得最好的框架之一。
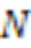
多目标强化学习不同于传统RL的点在于学习Agent同时要优化多个目标,每一步学习Agent得到一个回报向量,而不是一个标量值[14]。

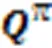
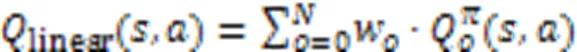
权重向量本身应该满足方程:

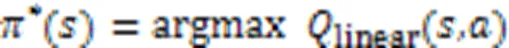
在IoS中,同时考虑用户本身的功能需求以及服务生态系统的健康发展,将用户需求的功能匹配和服务网络系统的复杂性作为多目标优化的子目标值。目前对网络系统的复杂性的研究主要体现在结构复杂性、节点复杂性以及各种复杂性因素之间的相互影响等领域上,包括小世界特性、无标度特性、度匹配特性等。本节主要借鉴文献[15]的定义与Qi等[16]构建的服务生态系统演化指标体系,在该体系下对服务生态系统的组织结构的复杂度进行分析。
2.2.1小世界特性
小世界网络模型主要包括Watts和Strogatz提出的WS小世界模型[17]和Newman和Watts提出的NW小世界模型[18]。小世界网络的核心特征为特征路径长度短而集聚系数高。其中特征路径长度(Characteristic Path Length, CPL)表示网络的平均路径长度,其定义为:
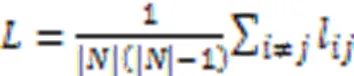
集聚系数描述网络当中节点的邻接节点之间也互相邻接的比例,因此可以定义为:
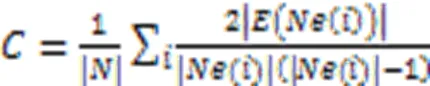
为了对网络的小世界特性进行量化,Watts和Strogtz进一步将小世界网络与具有相同连边概率的ER随机网络进行比较,并将具有与随机网络相似的特征路径长度但是比随机网络高得多的集聚系数的网络定义为小世界网络。因此小世界特性的量化标准为:

2.2.2无标度特性
无标度特性指网络当中的分布满足幂律分布特征,由Barabasi和Albert于1999年提出[19]。在无标度网络当中绝大多数的节点的度非常低,而少部分的节点的度则非常高,在整个网络当中占据核心的位置。目前对网络的无标度特性进行量化分析主要有两种方法:
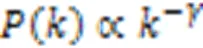
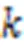

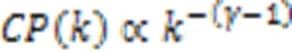
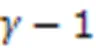
2.2.3度匹配特性
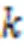
Newman[21]对于识别网络节点之间的匹配关系进行了量化,进一步提出了网络整体的匹配系数:
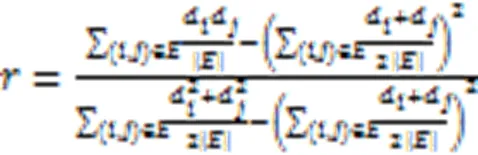
本文将利用Pastor‑Satorras等的方法识别网络的匹配性,利用Newman的匹配系统量化网络的匹配程度。
2.3 权重自适应多目标服务集成算法
在单个Agent中只需要考虑到自己,把自己优化得最好就可以了,但是涉及多Agent,研究多个Agent之间的关系以提升整体效果或者完成多Agent的目标任务时,需要参考博弈论的成果[22-24]:
遗憾的是指学习器现实的收益与学习器使用某种固定策略获得的最大收益之间的差异,即

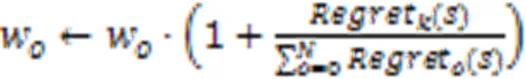
再根据式(16)保证权重总和为1:
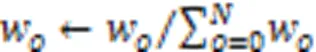
最终服务集成算法如算法1所示。
算法1 权重自适应A3C多目标强化学习算法。
13) End for
17) End while
24) End for
26) End while
3 实验与结果分析
3.1 实验设置
本文提出的服务集成方法在连续迭代循环中运行,直到达到收敛点。由于传统机器学习算法无法在连续状态空间中运行,而自适应权重会导致状态空间连续,因此分别将基于蚁群算法的多目标服务集成算法和基于A3C强化学习算法的多目标自适应权重服务集成算法与基于A3C强化学习算法的多目标集成算法进行对比,比较它们的求解速度、求解质量以及各目标求解质量。
所有模拟实验都于搭载四核心Intel Core i5‑6300HQ CPU的个人计算机上运行,内存为16 GB,采用Windows系统运行Pycharm软件,利用Python语言编写程序。蚁群算法与A3C强化学习算法各项参数如表1所示。

表1 蚁群算法与强化学习算法参数设置
3.2 实验数据

测试环境中子目标数量固定为四个,分别为:功能匹配、小世界特性、无标度特性和度匹配特性,其可用的具体服务共946个。
3.3 实验结果
将通过两组实验分别对比三种算法的求解速度和求解质量与子目标求解质量,其中总目标值为各子目标值加权相加。
三种算法总目标值与迭代次数的关系如图2所示;三种算法总目标值与收敛时间的关系如图3所示。由图2、3可以看出,由于环境规模较大,传统机器学习算法收敛速度比A3C强化学习算法慢得多。从迭代次数来看,强化学习算法在40次迭代以内便可收敛,而蚁群算法则需要至少220次迭代,从收敛时间来看强化学习算法也有着明显的优势。而两种算法在整个学习过程中获得的累计回报基本相同,说明A3C强化学习算法在保证求解质量的同时能够保证较快的求解速度。而对于权重固定与自适应的多目标强化学习算法的收敛速度相近、总回报值相近,说明权重自适应的多目标优化算法不会影响算法的整体求解速度与求解质量。

图2 三种算法总目标值‒迭代次数图
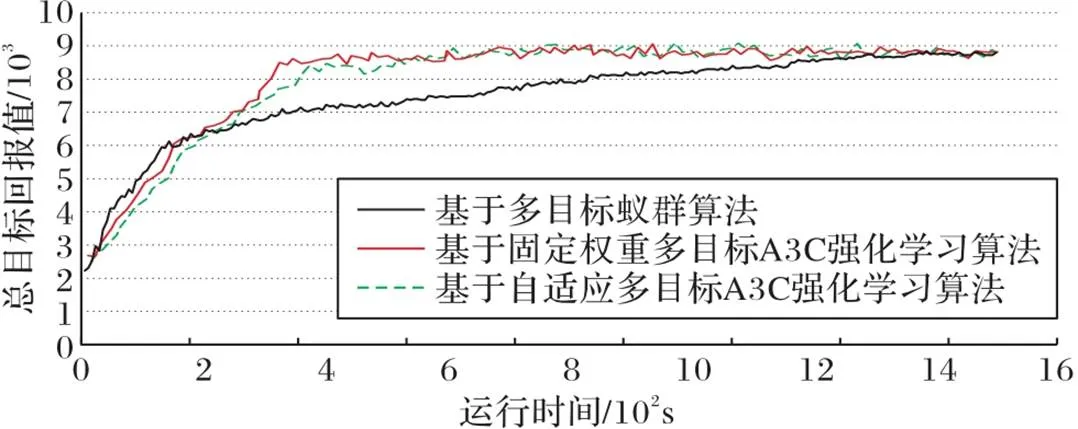
图3 三种算法总目标值‒时间图
三种算法子目标回报值与迭代次数的关系如图4所示。在这里选取功能匹配与小世界特性两个子目标进行分析,其中图4(b)表示小世界特性目标回报值,图4(c)表示功能匹配目标回报值。
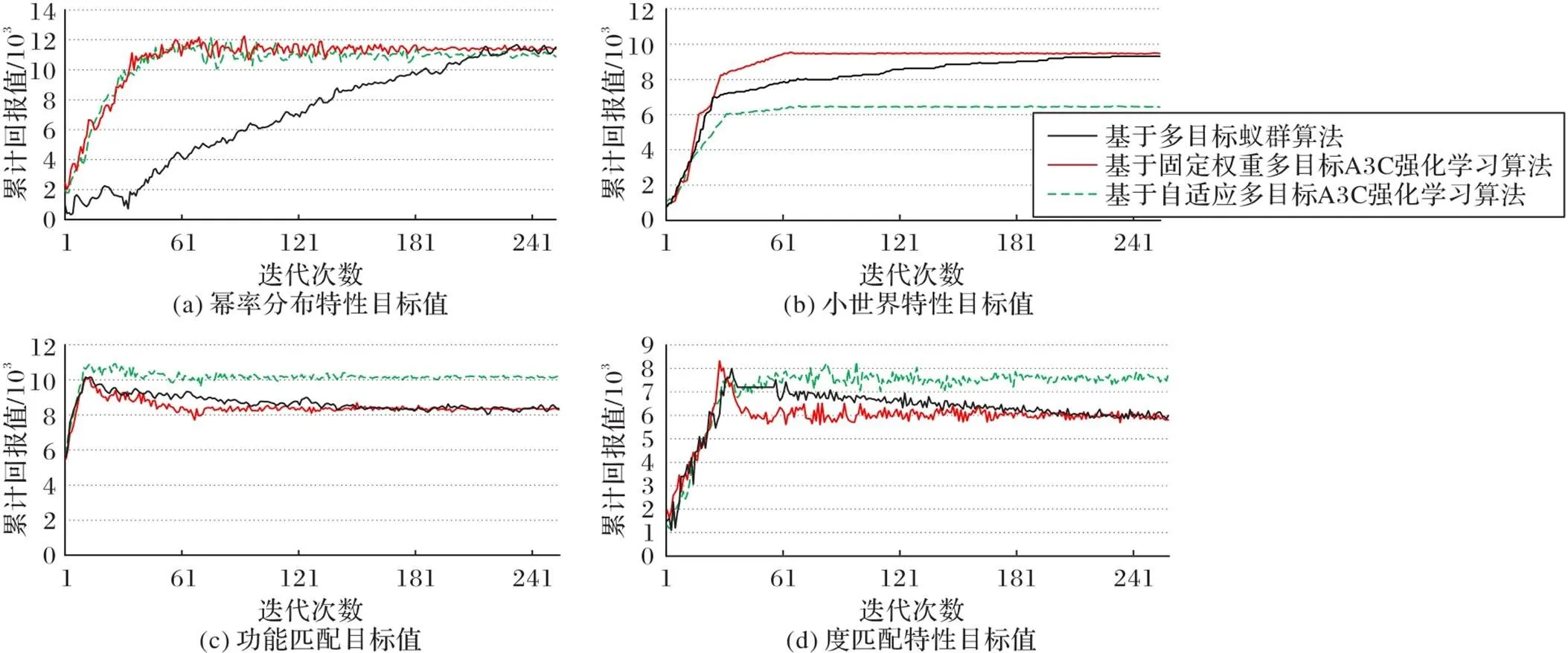
图4 三种算法子目标值‒迭代次数图
由图4可以看出,在三种算法总目标求解质量相近的基础上,在幂率分布特性这一子目标下也有相同的求解质量,整体上来看权重固定的强化学习算法与蚁群算法除了收敛速度不同外有着相似的结果。这两种算法虽然在小世界特性这一子目标下有着更优的效果,但是在功能匹配与度匹配特性这一子目标下却出现了累计子目标回报值随迭代次数增加反而减小的现象,这说明在训练过程中出现了牺牲该目标换取全局最优的情况,但本文算法并未出现这一情况,说明本文算法能够保证每个子目标都随着循环迭代而增加,可以更好地平衡各个目标的回报值之间的比重,尽管一部分子目标没有达到最好的效果,但每一个子目标的回报值都随着迭代次数的增加而增加,结合图2、3可知,引入权重自适应的多目标优化算法没有影响总体目标值。
4 结语
本文提出了一种基于自适应多目标A3C强化学习的服务集成方法,该方法利用MDP对服务集成优化问题进行建模,并引入了强化学习的组合优化模型,简化了组合优化过程。同时基于遗憾值对多目标权重进行动态调整,在保证总体目标回报值最大的情况下不牺牲各个子目标回报值,使每一个子目标回报值都能随着训练增大。在数据集Programable Web上与传统机器学习算法中的蚁群算法和权重固定多目标强化学习算法进行对比分析的结果表明,本文方法相较于其他两种方法在大规模服务环境下对于服务集成收敛更快、耗时更短,在整体求解质量相近的情况下保证了各子目标的求解质量。然而多目标优化的应用场景一般较为复杂,尤其是子目标之间的关系更加复杂,本文方法将子目标平等对待,有时不能很好地体现子目标之间的优先关系,因此今后我们将针对这类问题做进一步的研究。
[1] FLETCHER K K. A quality‑based web api selection for mashup development using affinity propagation[C]// Proceedings of the 2018 International Conference on Services Computing. Cham: Springer, 2018: 153-165.
[2] ALMARIMI N, OUNI A, BOUKTIF S, et al. Web service API recommendation for automated mashup creation using multi‑ objective evolutionary search[J]. Applied Soft Computing, 2019, 85: No.105830.
[3] 张龙昌,张成文.混合QoS聚类的服务组合[J].北京邮电大学学报,2011,34(5):57-62.(ZHANG L C, ZHANG C W. Hybrid QoS‑clustering web service composition[J]. Journal of Beijing University of Posts and Telecommunications, 2011, 34(5): 57-62.)
[4] 朱志良,苑海涛,宋杰,等. Web服务聚类方法的研究和改进[J]. 小型微型计算机系统, 2012, 33(1):96-101.(ZHU Z L, YUAN H T, SONG J, et al. Study and improvement on web services clustering approach[J]. Journal of Chinese Computer Systems, 2012, 33(1): 96-101.)
[5] TRIPATHY A K, PATRA M R, KHAN M A, et al. Dynamic web service composition with QoS clustering[C]// Proceedings of the 2014 IEEE International Conference on Web Services. Piscataway: IEEE, 2014: 678-679.
[6] WU L, ZHANG Y, DI Z Y. A service‑cluster based approach to service substitution of web service composition[C]// Proceedings of the IEEE 16th International Conference on Computer Supported Cooperative Work in Design. Piscataway: IEEE, 2012: 564-568.
[7] ABDULLAH A, LI X N. An efficient I/O based clustering HTN in Web Service Composition[C]// Proceedings of the 2013 International Conference on Computing, Management and Telecommunications. Piscataway:IEEE, 2013: 252-257.
[8] CAI H H, CUI L Z. Cloud service composition based on multi‑ granularity clustering[J]. Journal of Algorithms and Computational Technology, 2014, 8(2): 143-161.
[9] BIANCHINI D, DE ANTONELLIS V, MELCHIORI M. An ontology‑based method for classifying and searching‑Services[C]// Proceedings of the Forum of First International Conference on Service Oriented Computing, LNCS 2910. Cham: Springer, 2003: 15-18.
[10] WANG X Z, WANG Z J, XU X F. Semi‑empirical service composition: a clustering based approach[C]// Proceedings of the 2011 IEEE International Conference on Web Services. Piscataway: IEEE, 2011: 219-226.
[11] QUAN L, WANG Z L, LIU X. A real‑time subtask‑assistance strategy for adaptive services composition[J]. IEICE Transactions on Information and Systems, 2018, E101.D(5): 1361-1369.
[12] GAO A Q, YANG D Q, TANG S W, et al. Web service composition using Markov decision processes[C]// Proceedings of the 2005 International Conference on Web‑Age Information Management, LNCS 3739. Berlin: Springer, 2005: 308-319.
[13] ZHANG Y Z, CLAVERA I, TSAI B, et al. Asynchronous methods for model‑based reinforcement learning[C]// Proceedings of the 3rd Conference on Robot Learning. New York: JMLR.org, 2020: 1338-1347.
[14] RUIZ‑MONTIEL M, MANDOW L, PÉREZ‑DE‑LA‑CRUZ J L. A temporal difference method for multi‑objective reinforcement learning[J]. Neurocomputing, 2017, 263: 15-25.
[15] IANSITI M, LEVIEN R. Strategy as ecology[J]. Harvard Business Review, 2004, 82(3): 68-78, 126.
[16] QI Q, CAO J. Investigating the evolution of Web API cooperative communities in the mashup ecosystem[C]// Proceedings of the 2020 IEEE International Conference on Web Services. Piscataway: IEEE, 2020: 413-417.
[17] WATTS D J, STROGATZ S H. Collective dynamics of ‘small‑world’ networks[J]. Nature, 1998, 393(6684): 440-442.
[18] NEWMAN M, BARABÁSI A L, WATTS D J. The Structure and Dynamics of Networks[M]. Princeton, NJ: Princeton University Press, 2006: 304-308.
[19] BARABÁSI A L, ALBERT R. Emergence of scaling in random networks[J]. Science, 1999, 286(5439): 509-512.
[20] VÁZQUEZ A, PASTOR‑SATORRAS R, VESPIGNANI A. Internet topology at the router and autonomous system level[EB/OL]. [2021-12-05].https://arxiv.org/pdf/cond‑mat/0206084.pdf.
[21] NEWMAN M E J. Scientific collaboration networks. Ⅰ. Network construction and fundamental results[J]. Physical Review E, Statistical, Nonlinear, and Soft Matter Physics, 2001, 64(1): No.016131.
[22] FOSTER D P, YOUNG H P. Regret testing: a simple payoff‑ based procedure for learning Nash equilibrium[D]. Baltimore, MD: University of Pennsylvania, 2003: 341-367.
[23] HART S, MAS‑COLELL A. A reinforcement procedure leading to correlated equilibrium[M]// Economics Essays: A Festschrift for Werner Hildenbrand. Berlin: Springer, 2001: 181-200.
[24] ORTNER R. Regret bounds for reinforcement learning via Markov chain concentration[J]. Journal of Artificial Intelligence Research, 2020, 67: 115-128.
Service integration method based on adaptive multi‑objective reinforcement learning
GUO Xiao, LI Chunshan*, ZHANG Yuyue, CHU Dianhui
(,(),264209,)
The current service resources in Internet of Services (IoS) show a trend of refinement and specialization. Services with single function cannot meet the complex and changeable requirements of users. Service integrating and scheduling methods have become hot spots in the field of service computing. However, most existing service integrating and scheduling methods only consider the satisfaction of user requirements and do not consider the sustainability of the IoS ecosystem. In response to the above problems, a service integration method based on adaptive multi‑objective reinforcement learning was proposed. In this method, a multi‑objective optimization strategy was introduced into the framework of Asynchronous Advantage Actor‑Critic (A3C) algorithm, so as to ensure the healthy development of the IoS ecosystem while satisfying user needs. The integrated weight of the multi‑objective value was able to adjusted dynamically according to the regret value, which improved the imbalance of sub‑objective values in multi‑objective reinforcement learning. The service integration verification was carried out in a real large‑scale service environment. Experimental results show that the proposed method is faster than traditional machine learning methods in large‑scale service environment, and has a more balanced solution quality of each objective compared with Reinforcement Learning (RL) with fixed weights.
service integration; Reinforcement Learning (RL); Asynchronous Advantage Actor‑Critic (A3C) algorithm; multi‑objective optimization; adaptive weight
This work is partially supported by National Key Research and Development Program of China (2018YFB1402500), National Natural Science Foundation of China (61902090, 61832004), Natural Science Foundation of Shandong Province (ZR2020KF019).
GUO Xiao, born in 1999, M. S. His research interests include service computing, knowledge engineering.
LI Chunshan, born in 1984, Ph. D., professor. His research interests include service computing, knowledge engineering.
ZHANG Yuyue, born in 2000. His research interests include knowledge engineering.
CHU Dianhui, born in 1970, Ph. D., professor. His research interests include service computing, intelligent manufacturing.
1001-9081(2022)11-3500-06
10.11772/j.issn.1001-9081.2021122041
2021⁃12⁃06;
2021⁃12⁃29;
2022⁃01⁃13。
国家重点研发计划项目(2018YFB1402500);国家自然科学基金资助项目(61902090, 61832004);山东省自然科学基金资助项目(ZR2020KF019)。
TP315
A
郭潇(1999—),男,黑龙江伊春人,硕士,主要研究方向:服务计算、知识工程;李春山(1984—),男,山西吕梁人,副教授,博士,CCF会员,主要研究方向:服务计算、知识工程;张宇跃(2000—),男,江西南昌人,主要研究方向:知识工程;初佃辉(1970—),男,山东潍坊人,教授,博士,CCF高级会员,主要研究方向:服务计算、智慧制造。
