黑龙江省红松人工林林分乔木层可加性碳储量模型
2022-11-29辛士冬姜立春
辛士冬, 姜立春*, 穆 林
(1.东北林业大学林学院,森林生态系统可持续经营教育部重点实验室,黑龙江 哈尔滨 150040;2.东丰县国有总场大兴林场,吉林 辽源 136300)
CO2是温室气体的重要组成部分,如何有效降低大气中CO2的浓度一直是人们关注的焦点[1]。森林生态系统约占陆地碳储量的80%,是世界上除海洋之外最大的碳库,其固定大量碳被认为是森林对人类社会环境做出的重大贡献[2-3],因此,森林生态系统的碳储量评估受到世界各国的重视。
国内外许多专家和学者评估了各种森林植被的碳储量,这对于了解全球森林碳库和碳平衡起到了推动作用[4-7]。但对于大尺度的碳储量评估,主要的方式有实测数据外推和遥感反演,而实测数据外推是以单木碳含量为基础估算林分碳储量,然后汇总成整个地区的乔木层碳储量,大尺度的森林调查结果一般都是汇总成含有林分变量信息的数据表[8-10],因此传统的从单木到林分碳储量的推算方法已经限制了大尺度碳储量估算的应用,且在从单木碳储量汇总到区域碳储量的过程中,也将会产生复杂的误差传递。虽然大面积的森林碳储量评估可以通过遥感反演实现,但在卫星获取数据的过程中,会受到大气的干扰,影响碳储量估算的精度[11]。考虑到以上因素,在林分水平上建立林分乔木层碳储量预测模型依然是估算大尺度森林碳储量相对有效的方法。而且我国已经获取了9次全国森林资源清查数据,从中比较容易得到评估森林碳储量的林分因子,这为大尺度森林碳储量的准确快捷评估提供了良好的基础。
尽管我国培育人工林是多种用途的,主要包括木材产出、环境保护、固碳、水土保持,以及调节区域气候等[12],但人工林乔木层是森林生态系统的重要组成部分,并且人工林以相对较高的生产力在固碳方面发挥了重要的作用,培育人工林也被认为是提高森林覆盖率和固定大气中二氧化碳的重要途径之一。因此,准确估算人工林乔木层的碳储量有助于理解全球碳循环的机制以及制定减缓全球变暖的相关政策[13-14]。本研究以黑龙江省三大造林树种之一的红松(Pinuskoraiensis)为例,使用聚合法、平差法、分解法构建可加性林分碳储量模型,并对比分析3种方法的预测精度,旨在为森林乔木层的碳储量估算探索出更准确的方法,并为大尺度森林碳储量的估算提供技术支持。
1 材料与方法
1.1 数据获取与预处理
数据来源于黑龙江省红松人工林主要分布区域,分别为帽儿山林场(127°18′0″~127°41′6″E,45°2′20″~45°18′16″N)、孟家岗林场(130°32′42″~130°52′36″ E,46°20′16″~46°30′50″N)、东京城林业局(128°07′45″~130°02′35″E,43°30′30″~44°18′45″N)和林口林业局(129°40′~130°34′E,45°51′44″~45°59′30″N)。黑龙江省气候类型为寒温带与温带大陆性季风气候,山地土壤类型以暗棕壤为主。
本研究共收集了207块红松人工林样地数据(红松蓄积合计≥65%),样地面积100~900 m2,样地的设置考虑了林缘效应的影响,样地面积通过罗盘和测绳确定,闭合差不得超过0.5%,设置样地完成后,使用皮尺根据样地面积对样地进行分割,之后,对样地树木进行标记,在此过程中排除树高低于1.3 m和胸径小于5 cm的树木,记录各树木的树高、胸径,以及郁闭度等样地信息。外业数据收集完成后,整理样地信息,通过每木检尺数据计算得到林分基本信息(表1),并根据已构建的红松人工林单木生物量模型以及样地内含有的天然林或人工林树种(如白桦、云杉、樟子松、蒙古栎等)的单木生物量模型[15-16],计算各样地内各树种的单木总生物量以及单木各分项生物量,然后将各样地单木总生物量、单木各分项生物量分别求和,得到各样地单位面积内乔木层各分量生物量和总生物量。以得到的样地各分量生物量为基础,结合红松人工林和其他树种的各分量(树干、树枝、树叶、树根)的含碳率[17],最终相加后得到林分总碳储量以及各分量碳储量,碳储量统计信息见表2。

表1 红松人工林林分基本信息

表2 红松人工林林分碳储量统计信息
1.2 基本模型的构建
异速生长方程可以较好地反映树木的生长过程,被广泛应用于生物量和碳储量的估算[18-22]。因此,本研究以异速生长方程为基础构建林分碳储量模型,并分析林分碳储量与林分因子(林分断面积、林分平均直径、林分平均高等)的相关关系,结果表明林分断面积(G)和林分平均高(H)更适合于作为林分碳储量模型的自变量,考虑到模型的预测应具备可加性(相容性),即树干、树枝、树叶和树根的碳储量相加等于总碳储量,所以本研究也将3种可加性方法(聚合法、平差法、分解法)引入林分碳储量模型构建过程中,基本模型的形式如下:
C=αGβHγ。
(1)
式中:C为碳储量;G、H分别为林分断面积和林分平均高;α、β、γ为模型参数。
1)聚合法:由Parresol[23]提出,该方法不仅保证了各分量(树干、树枝、树叶、树根)相加等于总量(即生物量相容性),而且表示了各分量间的相关关系。本研究引入聚合法构建可加性碳储量模型,基于聚合法的模型形式如下:
(2)
式中:Ci为各分量碳储量;s、b、l、r、t分别代表总量、树干、树枝、树叶和树根;G、H分别为林分断面积和林分平均高;αi、βi、γi为模型参数;εi为各模型残差项。
2)平差法:由唐守正等[24]提出的可加性方法,将总量一步平差为树干、树枝、树叶和树根各分量,各分量所占比例之和为1,只是总量及各分量模型需要单独进行拟合。基于平差法的模型形式如下:
(3)
(4)
(5)
(6)
(7)
3)分解法:由唐守正等[25]提出的可加性模型结构(总量等于各分量相加),将总量一步直接分配给各分量,总量与各分量进行联合估计。基于分解法的模型形式如下:
(8)
式中:αi、βi、γi、m1、m2、m3、k1、k2、k3、f1、f2、f3为模型参数;m1=αs/αb,m2=αl/αb,m3=αr/αb;k1=βs-βb,k2=βl-βb,k3=βr-βb;f1=γs-γb,f2=γl-γb,f3=γr-γb。
1.3 异方差的消除
由于本研究以异速生长方程为基础构建林分碳储量模型,而异速生长方程普遍存在异方差现象,所以构建模型过程中应采取适当的措施消除异方差现象,使模型的残差呈随机分布。目前,消除异方差的主要方法为对数转换或加权回归,本研究选择加权回归消除模型的异方差[26-27]。具体步骤如下:
1)本研究中的聚合法和分解法使用SAS模块 PROC MODEL以及似乎不相关回归(NSUR)对碳储量的总量及各分量模型进行联合拟合,总量控制直接平差法使用最小二乘法(OLS)对总量及各分量模型进行拟合。
2)计算总量及各分量模型的残差平方,再对各模型中的自变量和平方后的残差进行对数转换,之后使用SAS模块 PEROC REG逐步回归进行自变量的重复拟合,最终挑选参数显著的自变量,具体公式如下:
(9)

1.4 模型评价
以决定系数(R2)、均方根误差[RMSE,式中记为σ(RMSE)]作为各模型拟合过程的评价指标。模型检验采用留一交叉验证法进行检验[30-31],具体采用平均误差绝对值[MAE, 式中记为σ(MAE)]、相对误差绝对值[MPE, 式中记为σ(MPE)]、平均相对误差[MRE, 式中记为σ(MRE)]用于各模型的检验评价。以上评价指标具体公式如下:
(10)
(11)
(12)
(13)
(14)

2 结果与分析
2.1 林分碳储量模型参数估计
基于聚合法、平差法和分解法可加性碳储量模型的参数估计值见表3、表4。

表3 林分碳储量模型(聚合法、平差法)参数估计值
基于3种方法的林分碳储量模型的标准误(SE)均较低,只有分解法参数m1的标准误相对较大,其余参数的标准误均低于0.1。
2.2 林分碳储量模型拟合
利用全部的样本对林分碳储量模型进行拟合,由表5可知,基于3种可加性方法的总量及各分量碳储量模型的决定系数(R2)均为0.93~0.98,表明本研究构建碳储量模型的拟合效果较好,均方根误差(RMSE)为0.33~3.94 t/hm2,以总量和树根碳储量模型的R2相对较大,树叶碳储量模型的R2相对较小,3种模型间总量和树干碳储量模型的RMSE相对较大。并且3种可加性碳储量模型间R2和RMSE的差异较小,总量及各分量碳储量模型RMSE的差值均小于0.02 t/hm2,只有基于分解法的树干碳储量模型和基于聚合法的总量碳储量模型的表现稍好。基于聚合法和平差法的总量和树枝模型,以及基于分解法的总量模型的权函数为林分平均高(H)和林分断面积(G)构成,其余模型均使用林分断面积(G)进行校正。

表5 林分碳储量模型拟合优度
2.3 林分碳储量模型检验
为了比较3种可加性方法的预测精度,使用留一交叉验证法对各碳储量模型进行检验,具体检验结果见表6。由表6可以看出,基于3种可加性方法的各碳储量模型的平均误差绝对值(MAE)为0.26~2.47,由于树叶的林分碳储量实测值相对较小,而相对误差绝对值的分母由总量及各分量的实测值相加得到,因此,树叶碳储量模型的MPE相对较大。3种可加性方法的平均相对误差(MRE)表明:除树叶外大部分的总量及各分量模型的预测值略微偏高(-3.41%~-0.34%),基于3种可加性方法的碳储量模型均以树叶的预测值略微偏低(1.84%~2.93%)。表明以林分变量构建可加性碳储量模型是一种可行的建模方式,能够准确地预估红松人工林林分总量及各分量碳储量。从MAE和MPE还可以了解到,3种可加性碳储量模型之间存在较小的差异,具体表现为:基于聚合法的总量、树根、树枝、树叶碳储量模型的MAE和MPE略低于平差法和分解法相应的模型,基于平差法的树干碳储量模型表现相对较好,并且基于平差法的总量、树根、树枝碳储量模型的MAE和MPE均低于分解法相应的模型,综上所述,基于3种可加性方法林分碳储量模型的预测精度排序为聚合法>平差法>分解法。
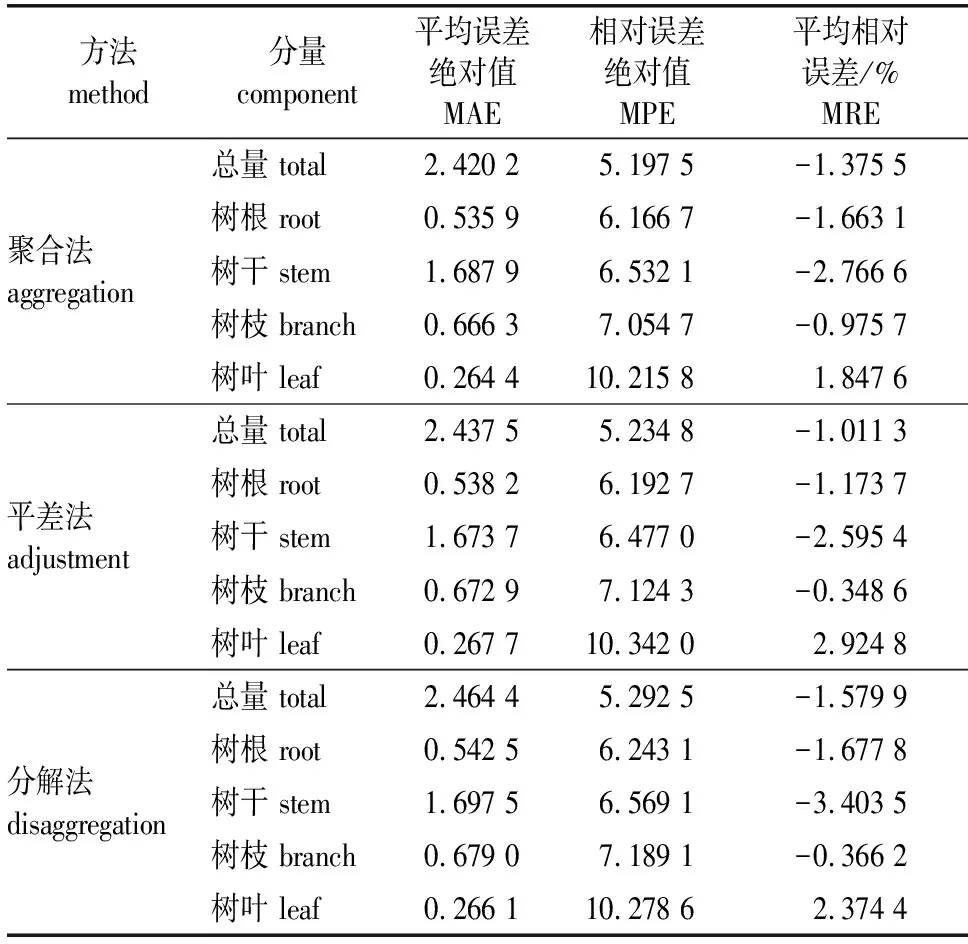
表6 林分碳储量模型检验结果
在评估大尺度的森林乔木层碳储量时,往往乔木层的总碳储量更容易受到关注,所以本研究进一步比较各种方法在不同林分断面积区间的预测精度,具体采用平均误差绝对值(MAE)和相对误差绝对值(MPE)来评价,结果见图1。可以发现:在林分断面积0~20 m2/hm2时,基于聚合法和分解法的林分总碳储量模型的预测能力均优于平差法,且分解法(MAE为1.35、MPE为 5.95)略优于聚合法(MAE为1.36、MPE为6.03);而在林分断面积≥20~40 m2/hm2时,基于聚合法的林分总碳储量的模型预测表现相对较好;当林分断面积≥40 m2/hm2时,基于平差法林分总碳储量模型的预测能力优于基于其他两种可加性方法的林分总碳储量模型。
3 讨 论
在3种可加性方法中,基于聚合法和分解法的优点在于将总量及各分项碳储量进行联合建模、联立求解,考虑总量及各分项之间的内在误差相关性(NSUR),分解法在模型构建过程中相对复杂。而平差法是以总量控制按比例平差得到各分项预测值,其优点在于简便,参数估计过程也更容易收敛。从预测精度来看,聚合法在总量、树根、树枝、树叶方面的预测能力均略优于平差法和分解法,而平差法在总量、树干、树枝方面的碳储量预测均略优于分解法。
贾炜玮等[19]构建了红松人工林林分碳储量模型预测系统,但该研究获取的红松人工林样地数据较少,共计36块,建模数据仅为样本量的80%,并且只是针对红松人工林的总碳储量进行了预测。而本研究收集了黑龙江省4个区域红松人工林207块样地,基于3种方法构建了红松人工林可加性碳储量模型预测系统,并采用留一交叉验证法对各模型进行检验,结果为基于聚合法的可加性碳储量模型系统在总体上可以提供相对准确的预测。
由于在数据收集过程中,没有完整地获取到各样地的林分年龄信息,因此,林分年龄未参与建模,并且本研究是以红松蓄积量占比≥65%的样地数据构建的碳储量模型,所以对于红松占比<65%以及树种组成比较复杂的红松人工林碳储量的预测有待于进一步研究。
森林乔木层是陆地生态系统重要的碳库,准确评估森林乔木层的碳储量,不仅可以为森林资源的管理和林业可持续经营提供重要的科学依据,又能为了解全球的碳循环过程及减缓温室效应提供基础资料。本研究采用聚合法、平差法和分解法构建了黑龙江省红松人工林林分碳储量模型。3种可加性方法的总碳储量及树干、树枝、树叶和树根碳储量的总体比较结果排序为聚合法>平差法>分解法。但当林分断面积为0~20 m2/hm2时评估红松人工林林分总碳储量,建议采用分解法的参数估计值;当林分断面积≥20~40 m2/hm2时,建议采用聚合法的参数估计值;当林分断面积大于40 m2/hm2时,建议采用平差法的参数估计值。基于国家森林清查数据,该研究成果可以为红松人工林林分碳储量的估算提供便捷和准确的预测。
