赣中天然闽楠单木冠幅预测模型的研究
2022-11-29单凯丽宁金魁欧阳勋志
单凯丽,臧 颢,潘 萍,宁金魁,欧阳勋志
(鄱阳湖流域森林生态系统保护与修复国家林业和草原局重点实验室,江西农业大学林学院,江西 南昌 330045)
树冠是树木积累有机物的主要场所,它决定了树木的生产力和活力[1],其大小的评判指标有冠幅、树冠横断面积、树冠长度、树冠率、冠基高度等,其中冠幅是最易准确测量和最常用的指标之一,常被作为单木生长模型[2]、生物量模型[3]、枯损模型[4]等中的预测变量。因此,越来越多国内外学者开始构建冠幅预测模型。近年来,有学者利用树木因子、林分因子和立地条件等建立了冠幅模型[5-7],如Thorpe等[8]以不列颠哥伦比亚省中北部的3个树种为研究对象,用空间邻域法比较竞争对冠幅模型的影响,发现添加与相邻木大小和距离相关的竞争因子可极大提高模型精度;雷相东等[9]以落叶松云冷杉林9个树种为研究对象,发现林分密度指数、林木竞争指数、树冠比和枝下高等因子对冠幅模型有显著影响;贺梦莹等[10]以长白落叶松(Larixolgensis)-水曲柳(Fraxinusmandshurica)混交林为研究对象,发现与距离无关的竞争因子对冠幅具有直接影响;覃阳平等[11]以杉木(Cunninghamialanceolata)为研究对象,构建与单木大小和单木竞争相关的冠幅模型,结果发现与竞争有关的冠幅模型精度显著高于与竞争无关的冠幅模型。总体看来,不少学者研究表明竞争对冠幅预测有显著影响。
构建冠幅模型的方法多从传统最小二乘法向混合效应模型转变,混合效应模型处理重复测量数据和纵向数据有一定优势,此模型的随机效应参数可以解释不同区域或样地间的冠幅曲线变化,固定效应参数可以解释冠幅的平均水平变化[12-13]。如Raptis等[14]以黑松(Pinusthunbergii)为研究对象,构建样地水平的非线性混合效应冠幅预测模型,结果表明混合效应模型的预测能力优于传统回归模型;符利勇等[12]和韩艳刚等[15]研究树木冠幅模型时均得出相同结果。近年来,由于机器学习具有对自变量和因变量不需要做分布假定等优点,在生态学、林学等各领域受到广泛关注,如分析气候变量与木材密度的关系[16]、预测林分生物量[17]、立地质量评价[18]等,主要形式有增强回归树(boosted regression trees,BRT)和随机森林(random forest,RF)等,然而应用机器学习建立冠幅预测模型的研究目前尚鲜见报道。
闽楠(Phoebebournei)为樟科(Lauraceae)楠属(Phoebe)的常绿乔木树种,其材质优良,纹理美观,具有重要的经济和生态价值。受各种因素的影响导致其近于枯竭,现为国家二级濒危保护植物,我国仅在福建、江西、湖南、湖北、浙江等海拔1 000 m以下的山地常绿阔叶林中有零星分布。为了解闽楠的生长规律和提高闽楠天然次生林的林分质量,不少学者逐渐对现存的天然闽楠开展了相关模型研究:曹梦等[19-20]建立了闽楠的单木生长模型和相容性生物量模型,褚欣等[21]建立了闽楠直径分布预估模型,欧建德[22]建立了林下闽楠更新层生境质量模型等,但对闽楠冠幅预测模型的研究还鲜见报道。本研究以江西省吉安市的天然闽楠为研究对象,采用普通最小二乘法(OLS模型)、混合效应模型、增强回归树(BRT)和随机森林(RF)4种建模方法添加某一种竞争指标,构建单木冠幅预测模型,选出拟合和预测最优的模型形式来分析竞争对冠幅模型的影响,为提高冠幅的预测精度和科学经营提供参考。
1 材料与方法
1.1 研究区概况
研究区位于江西省吉安市(113°48′~115°56′E,25°58′~27°57′N),属亚热带季风气候,年平均气温17.1~18.6 ℃,年平均降水量1 360~1 577 mm,年无霜期281 d,地形以丘陵、山地为主,母岩以花岗岩、砂岩为主,土壤以红壤为主。植物资源丰富,森林覆盖率达到67.6%,该地植被类型主要以常绿阔叶林为主,针叶林主要是以杉木、马尾松(Pinusmassoniana)为主。
1.2 数据获取
本研究对赣中吉安市的安福县、井冈山市及遂川县的闽楠天然次生林分布区域进行踏查,选取人为活动干扰程度相对较轻且林分在分布区域内具有代表性的地块设置典型样地进行调查。样地大小依据其分布地形和群落分布情况等因素而定,样地面积为400 m2(20 m×20 m)或600 m2(20 m×30 m),总共25块样地。样地调查主要内容包括胸径2 cm以上林木的胸径(DBH)、树高(H)、位置(X和Y坐标)以及东南、西北2个方向的冠幅半径等基本因子。共调查样木1 778株,其中闽楠1 011株,本研究所指单木冠幅(crown width,WC)为东西、南北两个方向的平均值。样地基本概况见表1。

表1 样地数据统计表
1.3 模型选取
1.3.1 OLS模型
冠幅模型的建立是为了预测单木冠幅时更加简便和准确,因此需要选用容易获取的测树因子作为自变量。在以前的研究中,最常见的冠幅基础模型仅以胸径为解释变量,本研究选用11种常用的冠幅(CW)-胸径(DBH)模型[22-24](包括线性、非线性方程)作为构建闽楠单木冠幅模型的备选基础模型(表2),通过评价指标选出精度最优的基础模型。

表2 备选基础模型
1.3.2 基于样地水平的混合效应模型
用混合效应模型可以有效地处理重复测量的数据,并且克服一般线性模型中反应变量必须具有独立和等方差的缺点。本研究建立基于样地水平的单水平混合效应模型,在选取最优的OLS基础模型中添加竞争因子,模型的所有参数均视为混合效应参数,以不同的组合形式进行混合效应模型拟合和检验,比较模型的精度,其一般形式为:
(1)
式中:β为固定效应向量;uk为k样地的随机效应向量;DBH为林木胸径;εk为误差项,且与参数uk相互独立;P表示uk或εk服从正态分布;D为样地对应的随机参数的方差协方差结构矩阵;Qk为k样地内误差效应的方差协方差矩阵。
1.3.3 增强回归树
增强回归树(BRT)结合了统计和机器学习的两种算法,其核心思想是通过不断地随机选择和自我学习生成多重分类回归树,再将这些回归树集合起来,构成一个更大的分类树,以此来提高稳定性和精度[25-26]。在模型拟合时,共有4个参数需要设置:①损失函数的形式为“gaussian”;②收缩参数(shrinkage),决定了单棵决策树在模型建立过程中的相对贡献率,本研究设置为0.05;③树的棵数,控制模型的迭代次数,过大或过小会有过拟合或欠拟合的风险,本研究设置为1 000;④交互深度(interaction depth)采用交叉验证。
1.3.4 随机森林
采用随机森林(RF)这一集成学习算法组合若干互不相关的决策树。在模型拟合时,共有2个参数需要设置:①树的棵数(n),一般而言,当棵树在n>500时整体误差率便趋于稳定,但仍需依据具体数据而定,为保障预估结果的可靠性且不会影响计算效率,本研究设置n=1 000;②树节点抽选的变量个数(m),基于n=1 000,通过选取由不同的m值对模型进行调优,通常取值为所有变量数的1/3[27],本研究中该参数设置为2。
1.4 竞争指标的选择和确定
为比较竞争指标对冠幅预测模型的影响,在4种模型中分别添加不同的竞争指标,构建只含有一种竞争指标的冠幅-胸径模型,并对模型拟合优度进行比较。本研究选用与距离无关的竞争指标:林分每公顷断面积(AB)、胸径大于对象木的树木断面积之和(ABL)和林分密度指数(ISD);与距离有关的竞争指标:简单竞争指标(Hegyi)。其中Hegyi的计算以样地范围内胸径2 cm以上的闽楠为对象木,由于处在样地边缘的对象木,其竞争木可能位于样地之外,为了消除此影响,采用偏移法进行边缘矫正,在每个样地的上、下、左、右、左上、左下、右上、右下8个邻域平移原样地,形成9个区域组成的大样地[28]。大多学者以对象木为中心,一定半径内的植株或者距离最近的一定数量的植株为竞争木,这种方法已被广泛接受[29-30]。本研究计算Hegyi时竞争木的确定从两个角度出发:一是固定半径法,即以1 m为步长,竞争半径从1~10 m逐步扩大;二是固定株数法,即以距离对象木最近的植株从1~10株逐步扩大,分别计算简单竞争指标。公式如下:
(2)
(3)
式中:Hegyi为简单竞争指标,DBHi为对象木i的胸径,DBHj为竞争木j的胸径,Lij为对象木i与竞争木j之间的距离,R为1~10 m固定半径内竞争木的数量,N为1~10株固定株数的数量。
1.5 模型评价与检验
建模研究通常是将数据分为两个部分:建模数据和检验数据,有学者指出利用全部数据进行模型构建,同时单独采取检验样本进行模型预测能力的评价是不可取的。因此本研究将采用刀切法[31]用于建模和模型检验,具体是将25块样地依次剔除1块样地,24块样地数据用于建模拟合,剩余的1块样地数据用于模型检验,这样所有的样地都被作为建模数据集和检验数据集,每个样地都被验证一次。用25次重复得出的评价指标平均值和标准差值评价模型的拟合效果和预估精度,本研究模型建模评价指标为决定系数(R2)、均方根误差[RMSE,记为σ(RMSE)]、平均相对误差绝对值[RMA,记为σ(RMA)]和平均绝对误差[MAE,记为σ(MAE)],模型的预测检验指标采用RMSE、RMA和MAE。RMSE、RMA和MAE的值越接近0,而R2的值越接近1,说明模型的拟合精度越高。计算公式如下:
(4)
(5)
(6)
(7)
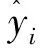
所有数据分析以及绘图均在R语言中完成,其中混合效应模型采用“lme”包,BRT采用“gbm”包,RF采用“Random Forest”包,图形采用“ggplot 2”包进行绘制。
2 结果与分析
2.1 基础模型的确定
利用刀切法进行建模和检验,得出模型最终评价指标值的平均值和标准差(表3)。

表3 基础模型的评价指标值
选择的11个基础模型在描述冠幅-胸径关系时,M8、M10和M11拟合不收敛,表3中已剔除。拟合收敛模型中,线性函数(M1)和二次项函数(M2)的拟合效果与检验效果都较其他模型略好,从检验结果看M2的RMSE值比M1的降低0.24%,RMA值相同,MAE值降低0.66%。因此选择M2作为基础模型。
2.2 竞争指标对冠幅-胸径模型的影响
2.2.1 对OLS模型的影响
将竞争指标分别添加到基础模型中进行冠幅模型拟合和检验,最终选出每个竞争指标的最优模型进行比较。拟合结果见表4,结果表明,每个竞争指标的添加都至少能保留1个参数,说明与冠幅存在竞争关系,且模型的拟合精度有所不同。ABL明显提高了模型精度,模型检验的RMSE、RMA、MAE值较未添加竞争指标分别降低了2.03%、1.11%和1.85%;AB和ISD添加则略微降低了模型精度,但不明显;而添加Hegyi的模型而言,模型精度相较不添加任何竞争指标模型略低,且随着Hegyi值的逐渐增加,几乎没有影响模型精度的变化(图1)。固定半径等于1 m时,模型的精度相对较高,与未添加竞争指标模型相比,模型检验的RMSE、RMA、MAE值分别提高了0.27%、0.32%和0.21%。总的来说,添加ABL时OLS模型的精度最高,其表达式如下:

表4 含竞争指标的4种模型的评价指标
(8)
式中:CWki和DBHki分别是k样地内对象木i的冠幅和胸径值;a0、b0、c0和c1为模型参数,εki为模型误差。
2.2.2 对混合效应模型的影响
以M2为基础模型构建冠幅-胸径混合效应模型。拟合结果(表4)表明,添加ABL时,模型精度略微降低,添加AB和ISD模型精度则出现明显降低,与未添加竞争指标相比,RMSE值分别提高了5.77%和5.87%,RMA值分别提高了3.74%和3.69%,MAE值分别提高了6.28%和6.41%;而就添加Hegyi的模型而言,随着固定半径和固定株数的增加,模型精度相较不添加任何竞争指标模型略低,且模型间精度没有明显变化(图1)。总的来说,不添加任何竞争指标的混合效应模型使得冠幅-胸径模型精度最高,其表达式如下:
(9)
式中,ui1、ui2和ui3为随机参数。
2.2.3 对BRT的影响
在BRT基础上添加竞争指标,拟合结果(表4)表明,添加竞争指标AB、ABL和ISD,模型的解释能力都未得到提高,与未添加竞争指标相比,模型预测的RMSE值提高了1.60%~3.54%,RMA值提高了3.88%~12.74%,MAE值提高了1.62%~6.20%;而就添加Hegyi的模型而言(图1),随着固定半径的增加,模型精度呈波动变化,但模型精度均比不添加竞争指标高,添加固定半径为7 m时,模型精度最高,与未添加竞争指标相比,RMSE值降低了2.80%,RMA值降低了2.02%,MAE值降低了1.51%。随着固定株数的增加,模型精度也呈波动变化,添加固定株数在4株以内的竞争指标,模型精度比不添加竞争指标模型低,当添加固定株数为4株时,模型精度较高,与未添加竞争指标模型相比,RMSE值降低了1.71%,RMA值降低了1.57%,MAE值降低了0.96%,总的来说,添加固定半径为7 m的Hegyi时BRT模型的精度最高。
2.2.4 对RF的影响
在RF基础上添加竞争指标,模型的解释能力都得到提高。拟合结果(表4)表明,就添加竞争指标AB、ABL和ISD而言,模型的精度表现为:AB>ABL>ISD,AB的添加明显提高了模型精度,与未添加指标模型相比,模型检验的RMSE、RMA、MAE值分别降低了10.65%、5.88%和7.25%;而就添加Hegyi的模型而言(图1),模型精度随着Hegyi值的逐渐增加,有明显的波动变化,且最优的模型均为添加AB的模型精度高。
2.3 模型精度比较
通过对比各个模型在检验数据集上的表现可知,4种模型对冠幅的预测能力均很好,但结果存在一定的差异。不添加竞争指标时,4种模型的预测能力表现为:混合效应模型>OLS模型>BRT>RF。从检验数据来看,混合效应模型的RMSE、RMA和MAE值要明显低于其他3种模型,RMSE值分别降低了32.62%、43.68%和46.03%,RMA值分别降低了24.53%、32.23%和37.95%,MAE值分别降低了31.16%、39.11%和43.02%。可见,不添加竞争指标时,混合效应模型的冠幅-胸径模型的精度是最高的;在添加竞争指标后,除混合效应模型外,其余3种模型方法的最优模型精度都得到提升。将添加竞争指标后4种建模方法的最优模型进行比较,模型预测能力发生变化:混合效应模型>OLS模型>RF>BRT,混合效应模型的精度依然明显高于其他模型,同时,RF在添加AB后,模型精度高于BRT的最优模型。但无论是否添加竞争指标,OLS模型和混合效应模型的精度都明显高于BRT和RF。将全部数据代入OLS最优模型和混合效应最优模型中,计算固定参数值、随机参数协方差组成以及模型拟合统计量,结果见表5,混合效应模型具有较高的精度,可以很好地模拟闽楠的冠幅和胸径的关系。

表5 模型参数、方差估计值及评价指标
3 讨 论
3.1 竞争指标与冠幅模型的关系
本研究以赣中天然闽楠为例,选择AB、ABL、ISD和Hegyi4个竞争指标反映竞争对冠幅模型的影响。刘平等[32]以低山侧柏(Platycladusorientalis)人工林为研究对象构建单木冠幅模型,在一元线性回归模型基础上添加哑变量构建多元线性回归模型时,表明AB、ABL等因子与冠幅拟合具有相关性。雷相东等[9]以长白落叶松等树种为研究对象,用多元逐步回归法建立冠幅模型,表明AB竞争指标会显著影响枫桦和白桦的冠幅生长,ABL竞争指标会显著影响落叶松的冠幅生长。符亚健等[6]以华北落叶松(Larixprincipis-rupprechtii)为研究对象构建冠幅模型,结果表明对象木冠长(LC)、对象木竞争压力指数(ISC)和每公顷株数(M)与冠幅相关性较强。本研究得出与其相一致的结论,除混合效应模型以外,添加竞争指标的冠幅模型能够更好地预测冠幅生长。其中与距离有关的Hegyi添加,随着固定半径和固定株数的增加,对于OLS模型和混合效应模型没有明显影响,而BRT和RF会发生细微的波动变化,但变化幅度不大。Kuehne等[33]在研究森林增长和产量模型时,添加了与距离有关和与距离无关的竞争指标,比较两者对模型的影响,得出与距离有关的竞争指标更具有优越性。本研究所得结论与其不一致,这可能是由于研究对象是天然次生林中的闽楠,每株树可能同时受不同范围的竞争木影响,基于某一固定半径法或者某一固定株数法不能充分体现树木之间的竞争,所以控制竞争木数量或压缩范围的竞争指标不能很好体现在本研究中。竞争指标添加在混合效应模型中,模型的解释能力未得到很好的提高,这可能是由于样地水平的随机效应已经能够较全面地反映不同树木间的主要差异性[14],再添加竞争指标作用不大,类似的情况在一些树高-胸径模型研究中也出现过[34],并且减少模型中自变量的个数,也简化了模型形式。
3.2 不同模型对冠幅的预测效果
不同的建模方法对冠幅模型有着不同的预测能力。本研究通过比较4种模型的评价指标值,发现模型都具有良好的预测能力。在添加竞争指标前后,混合效应模型的预测能力都明显优于相应的OLS模型。吕乐等[35]在构建天然椴树(Tiliatuan)单木冠幅模型时也得出相同的结论。有学者在此结论的基础上,对混合效应模型进行更深入的研究,如田德超等[36]依据不同分位点构建长白落叶松冠幅混合效应模型;符利勇等[12]考虑了立地指数和样地2个随机效应构建了嵌套2水平的杉木冠幅混合效应模型;符亚健[37]综合考虑了地域效应、区组效应以及嵌套在区组里的样地效应构建华北落叶松冠幅非线性混合效应模型,均具有良好的预测能力。除此,本研究选用机器学习中常用的2种模型(BRT和RF)均没有传统OLS模型预测能力强,竞争指标的添加使得RF的模型预测能力高于BRT。这与Delgado等[38]不同建模方法比较的结论不一致,可能是由于BRT和RF出现过拟合的问题。李永亮等[39]通过多元线性回归、BP神经网络和自适应神经模糊系统3种方法构建杉木冠幅模型,发现后者更能实现智能预估。因此,在预测冠幅时,通过多种建模方法的比较选取最优模型十分必要,本研究的建模方法可为其他类似研究提供借鉴,但由于只选取了4种建模方法进行比较,没有联合多种模型进行建模,冠幅模型预估能力的提高还需要进一步探索,以构建最优的冠幅预测模型。
