基于动态图注意力聚合多跳邻域的实体对齐*
2022-11-28汪浣沙黄瑞阳宋旭晖余诗媛胡楠
汪浣沙,黄瑞阳,宋旭晖,余诗媛,胡楠
(1.国家数字交换系统工程技术研究中心,河南 郑州 450002;2.中国人民解放军战略支援部队信息工程大学,河南 郑州 450002;3.郑州大学 软件学院,河南 郑州 450001)
0 引言
实体对齐任务指利用模型或算法判断多个不同表示的实体是否指代现实世界中的同一对象,随着知识图谱因其结构性表示知识等优势而在各大自然语言处理与计算机视觉领域任务中广泛应用,实体对齐作为知识图谱补全任务的重要组成部分受到越来越多研究者的关注。
现有实体对齐方法主要分为基于转移距离模型与基于图卷积网络模型,即利用转移距离模型或图卷积网络将多源实体表示为低维向量并计算相似性以找到对齐实体对。目前主流的基于图卷积网络的实体对齐模型常使用传统的静态图注意力网络对实体进行特征提取与语义建模,但静态图注意力网络注意力函数存在单调性,即对于任意查询节点i,图注意力网络都倾向给予同一节点j 更高的注意力权重,这将会严重影响网络的特征提取能力。而文献[1]所提出的动态图注意力网络中每个查询(Query)对键(Key)的注意系数都有不同的排序,因此具有更强的表示能力。图1 展示了静态与动态图注意力网络注意力倾向示意。

图1 静态、动态图注意力网络注意力倾向对比
针对该问题,本文提出了一种基于基于动态图注意力聚合多跳邻域的实体对齐方法,基于AliNet 架构,方法首先使用图卷积层建模目标实体的单跳节点表示,其次应用动态图注意力网络获得多跳节点注意力系数并建模,再次利用逐层门控网络聚合图卷积层与动态图注意力层输出的单跳、多跳节点信息,最后拼接通过外部知识预训练自然语言模型提取的实体名称属性嵌入并进行相似度计算。
本文的主要贡献如下:
(1)基于AliNet 模型架构,应用动态图注意力网络于实体对齐任务中,使模型获得了更强表示能力的同时提高了模型的鲁棒性;
(2)模型使用逐层门控网络改进AliNet 模型中所使用的门控机制,使其更为全面合理地聚合节点的单多跳特征;
(3)利用经外部知识预训练的类BERT 模型翻译提取实体名称属性语义嵌入,并与结构嵌入进行拼接,以寻求目标实体的更优表示;
(4)通过实验验证了应用动态图注意力网络、翻译、提取、拼接实体名称属性语义嵌入的有效性。
1 相关工作
早期开源知识图谱主要利用众包手工标注或基于实体符号特征的相似度计算机制进行实体对齐,该机制效率低下、泛化能力差。随着表示学习展现出其对语义特征的优秀建模能力,部分研究者尝试应用知识图谱表示学习技术于实体对齐任务中,其核心思想是通过算法在低维向量空间寻求实体与关系的低维向量表示,并对该向量进行相似度计算从而获得潜在的对齐实体对。
基于表示学习的实体对齐技术按照知识图谱表示学习机制可分为基于转移距离与基于图卷积模型两种。基于转移距离模型的核心思想是将实体与关系映射到同一向量空间后将关系视为低维向量空间中头尾实体向量的平移,如TransE[2]、TransH[3]、TransR[4]、RotatE[5]、HAKE[6]等模型。随着图卷积网络的不断发展,部分研究者尝试利用图卷积网络在学习图结构节点、边表示上的优势,从而更好地学习知识图谱的实体、关系嵌入,进而提高实体对齐的准确率与效率,如GCN-Align[7]、GMNN[8]、MuGNN[9]、NAEA[10]、HMAN[11]等模型。实体属性作为实体的重要组成,在早期实体对齐任务中大多仅视为属性三元组以优化通过关系三元组所训练获得的实体特征。而利用文本预训练模型可较好地获取文本深层语义信息,因此基于对齐实体属性语义相似性以优化知识图谱表示学习嵌入已成为重要的研究方向。
为了克服静态图注意力网络的局限性并利用实体属性语义信息,本文提出了一种基于动态图注意力聚合多跳邻域的实体对齐模型(Entity Alignment Based on Dynamic Graph Attention Aggregation in Multi -hop Neighborhood,DGAT-EA)。该模型受AliNet[12]的模型架构启发,首先使用图卷积层建模目标实体的单跳节点表示,其次应用动态图注意力网络获得多跳节点注意力系数并建模,再次利用逐层门控网络聚合图卷积层与动态图注意力层输出的单跳、多跳节点信息,最后拼接通过外部知识预训练自然语言模型提取的实体名称属性嵌入并进行相似度计算。经在DBP15K 中的3 个大规模跨语言数据集上评估,该模型与使用静态图注意力模型相比获得了一定的提升,证明了应用动态图注意力及融入实体语义信息对实体对齐任务的积极效果。
2 基于动态图注意力聚合多跳邻域的实体对齐模型
本文受AliNet 模型以端到端的方式缓解对应实体邻域结构的非同构问题的启发,提出了一种基于动态图注意力聚合多跳邻域的实体对齐模型DGAT-EA,模型架构主要分为图卷积层、动态图注意力层与属性嵌入层。图卷积层负责聚合表示实体单跳节点特征,动态图注意力层则利用动态图注意力机制获取多跳邻域的注意力系数并聚合实体的多跳节点特征表示,属性嵌入层利用预训练模型获取实体属性嵌入,最后利用逐层门控网络对单跳与多跳信息进行聚合并拼接实体属性嵌入以获得最终的实体表示,其训练过程如图2 所示。
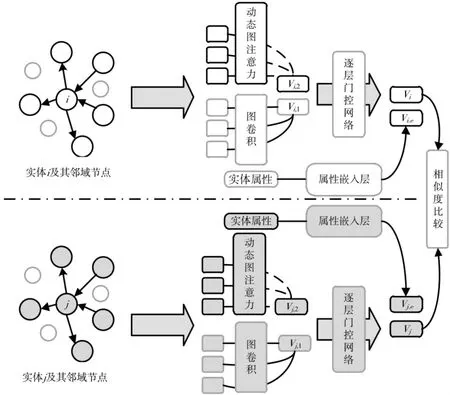
图2 基于动态图注意力聚合多跳邻域的实体对齐模型架构及训练流程
2.1 图卷积层
模型的图卷积层负责对输入的节点特征及其单跳邻域特征向量进行递归聚合从而学习该节点的单跳特征表示。其核心思想是通过对于每个实体迭代增加其邻居节点的特征信息以提高实体特征的表示能力。
基于该思想,在本模型中实体在图卷积第l 层的隐含特征表示可以表示为[13]:
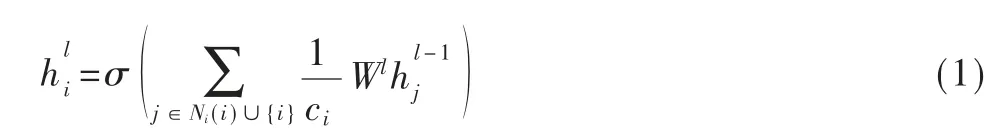
式中,Ni指代实体i 的一跳邻域节点集,ci为归一化常数,本模型图卷积层中不使用激活函数。
2.2 动态图注意力层
模型的动态图注意力层负责计算目标实体的两跳邻域节点的注意力权重,以突出有用的多跳邻居节点,并对其特征进行聚合,从而更好地表征目标实体特征。

通过对所有邻居节点进行加权求和便可得节点经过图注意力网络后得到的输出特征:

式中,σ 为激活函数。
对于实体对齐任务,传统图注意力网络的局限性主要体现在共享权重矩阵与静态性两方面。
在实体对齐任务中,知识图谱中的实体节点与其邻接节点通常具有较大差异,因此若应用共享的权重矩阵W 将导致模型难以正确区分实体节点与邻接节点,从而降低模型的表示能力。为了解决该问题,模型使用两个不同的矩阵W1、W2分别对实体节点与邻接节点进行线性变换,其修改后的注意力系数计算公式如下:
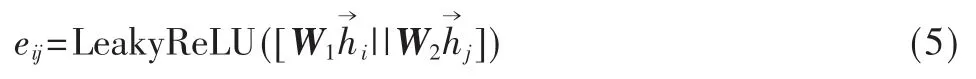
而传统图注意力网络的静态性则体现为给定一组节点和一个训练过的图注意力层,对于任意查询节点i,注意函数α 都有相同的最大倾向节点j。由邻接节点与实体关系的有限性以及softmax 函数与LeakyReLU 函数的单调性可知,针对任意节点i 都存在节点j 使得最大化,以至于静态图注意力网络总是倾向于赋予节点j 最大的注意力系数而忽视不同输入节点i 与节点j 的不同关系。因此静态图注意力对于实体对齐任务中不同查询输入i 与不同节点j 具有不同相关性的情况,难以较好建模。
为了解决传统图注意力网络由于其静态性所导致的表示能力不足等问题,本文尝试将文献[1]所提出的动态图注意力网络模型应用于实体对齐任务中。动态图注意力网络在注意力机制计算时先对拼接后的多跳节点特征应用非线性函数LeakyReLU 再输入前馈神经网络其表达式如下所示:
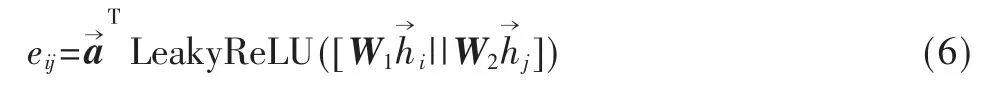
综上,模型的动态图注意力层通过对目标节点与邻接节点使用不同权重矩阵增强了图注意力网络对于节点的辨别能力,并应用更适合实体对齐任务的动态图注意力机制,增强了传统图注意力机制的特征提取能力,因此能够更好地获得目标节点的多跳特征聚合。
2.3 逐层门控网络
逐层门控网络负责对图卷积层输出的单跳节点特征与动态图注意力层输出的多跳节点特征进行聚合从而获得目标实体更为全面的特征表示。AliNet 中的门控机制函数可以表示为:

式中,M 为门控网络权重矩阵,实际训练时dropout 率为0,g 为门控机制函数表示动态图注意力层的输出。
为了更为全面合理地聚合节点的单多跳特征,同时为了增强门控网络的拟合能力以及提高网络在多跳节点小范围变化时的敏感性,模型改进AliNet 模型中所使用的门控机制。逐层门控机制函数如下所示:
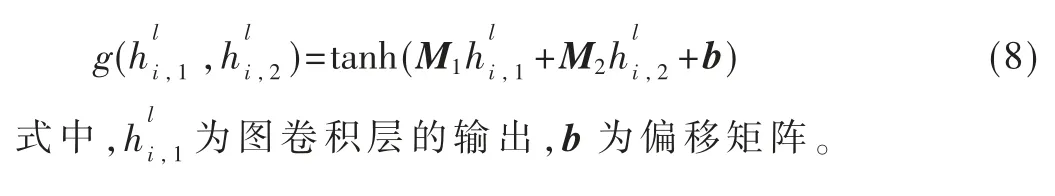
逐层门控网络使用两个不同的权重矩阵分别获取节点的单跳与多跳信息,全面聚合节点特征,且增加了偏移矩阵b 以增强门控网络的表征能力。增加非线性因素时使用tanh 函数代替ReLU 函数以提高输出对节点特征变化的敏感性,且扩展值域以更灵活地平衡单多跳特征的不同权重,其最终节点特征如下所示:
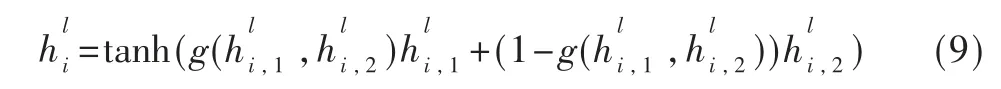
2.4 属性嵌入层
模型的属性嵌入层负责将实体的属性信息转化为相应的语义嵌入,并与经门控网络聚合而得的结构特征进行拼接,进而进行相似度计算。本模型基于huggingface[14]库中的bert-base-multilingual-cased、opus-mt-zh-en、opus-mt-ja-en 模型分别处理来自DBP15K 的3 个跨语言数据集中的实体名称属性,并利用模型输出的pooler_output 获取属性嵌入并进行拼接。
3 实验
3.1 实验数据集
本文实验使用来自DBP15K[15]的3 个大规模跨语言数据集,此数据集基于中文、英语、日语和法语的DBpedia建立,表1 给出了数据集的统计数据。
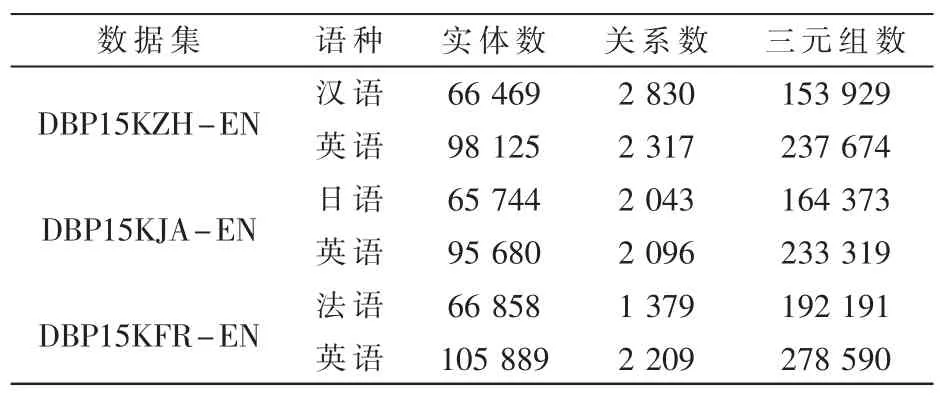
表1 DBP15K 数据集具体数据统计
3.2 实验配置
本文基于TensorFlow 深度学习框架进行实验研究,深度学习平台为TensorFlow2.0,编译环境为Python3.7.11,操作系统为Ubuntu18.04。实验硬件配置:CPU 为Intel®Xeon®Gold 6132 2.60 GHz,内存为256 GB,GPU 为Nvidia Geforce 3090 24 GB。
3.3 评测指标
本文实验采用在实体对齐任务中常用的Hits@n、平均倒数排序(Mean Reciprocal Rank,MRR)、平均秩(Mean Rank,MR)来客观评价各模型的实体对齐准确率。Hits@n、MRR 越大,MR 越小表示模型性能越好。其计算公式分别为:
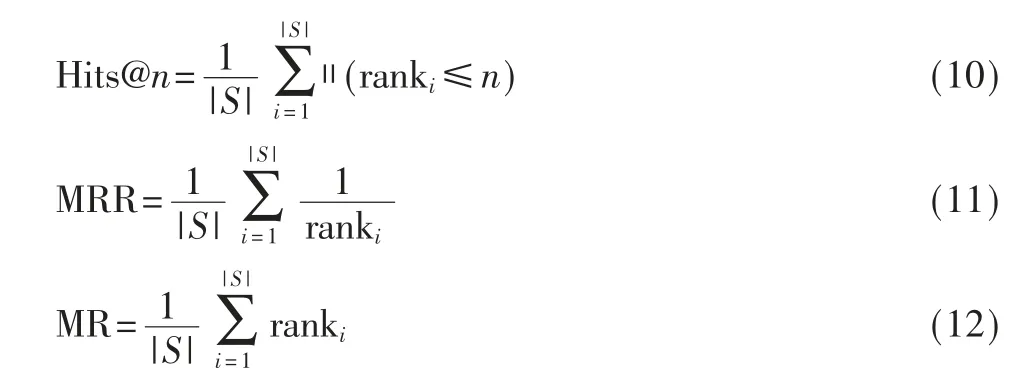
式中,S为总三元组集合,ranki为第i 个三元组的实体对齐预测排名,‖(x)表示Indicator 函数。
3.4 实验结果与分析
3.4.1 DGAT-EA 有效性分析
为了验证在实体对齐模型中融合实体属性语义信息、应用动态图注意力网络以及改良逐层门控网络的有效性,本文对DGAT-EA 与相似架构的AliNet 模型在相同实验配置与环境下进行了对比实验,并与其他实体对齐模型在DBP15K 数据集上的对齐结果进行比较。实验结果如表2 所示,其中最好结果加黑标注。
从表2 可得,在DBP15K 的3 个大规模跨语言数据集上DGAT-EA 模型与相似架构的AliNet 模型相比,各指标都获得了一定的提升,证明了融合实体属性语义信息、应用动态图注意力机制与逐层门控机制对提高实体对齐任务效果的积极作用。
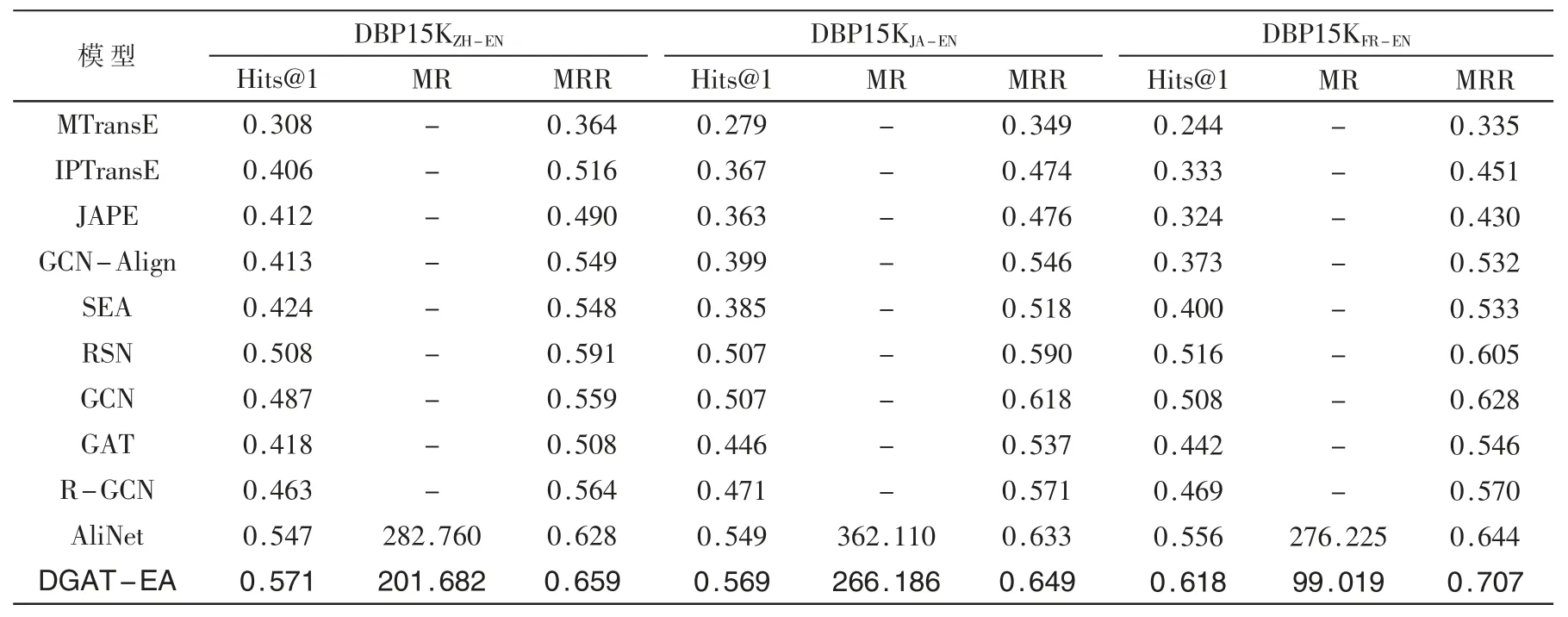
表2 实体对齐模型性能对比
3.4.2 消融实验
为了验证不同数据集效果优劣原因及各模型改进对效果的具体提升,本文将仅应用动态图注意力的模型、仅改用逐层门控网络的模型、未添加实体语义信息的模型与原模型作比较,结果如表3 所示,最好结果加黑表示,次好结果下划线表示。
如表3 所示,模型添加语义信息、应用动态图注意力网络或逐层门控机制后,各指标相比相似架构模型AliNet 均获得了一定的提高,充分地证明了添加实体属性语义信息、动态图注意力机制及逐层门控机制聚合单多跳节点特征对于实体对齐任务的有效性。
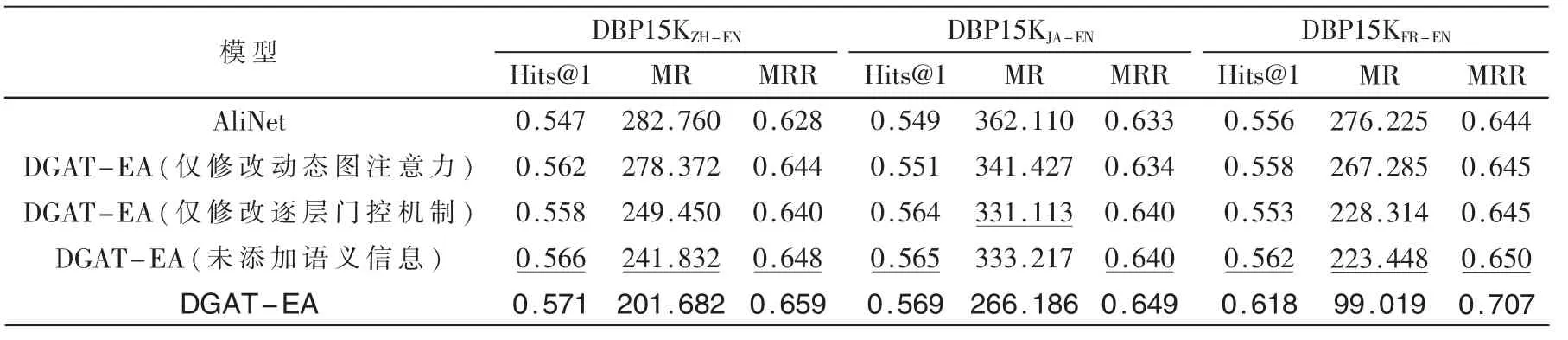
表3 消融实验模型效果对比表
在添加实体属性语义信息后,模型在DBP15KFR-EN数据集上收获了较高的指标提升,实体对齐受属性语义信息提升程度与特征提取模型的语义理解能力有较高相关性,因此实验尝试应用bert-base-multilingual-cased提取中文、日语实体属性。
由表4 可得,改用bert-base-multilingual-cased 提取属性嵌入后,在DBP15KZH-EN、DBP15KJA-EN数据集上指标并没有收获提高。本文猜测原因可能是相较日语、中文,法语与英语在形式和语法上更为相似,因此对于指代现实中相同实物的跨语言实体更易获得相似的语义嵌入,从而提高实体对齐效果。
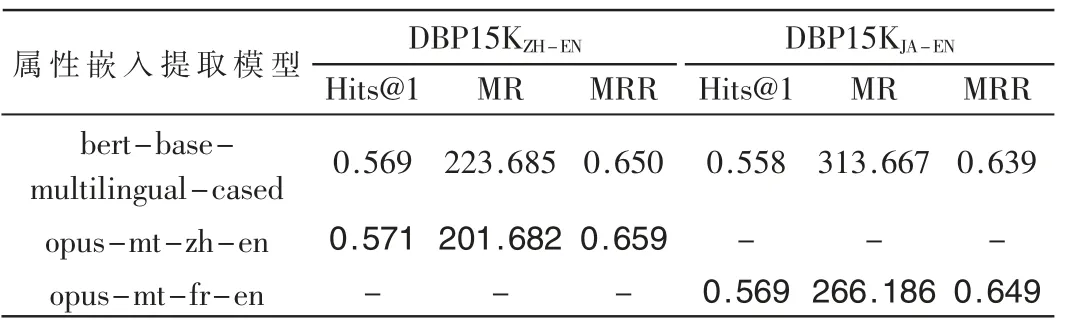
表4 使用不同属性嵌入提取模型实体对齐效果对比
4 结论
为了解决实体对齐任务中传统图注意力机制存在的难以拟合、有限注意及忽略实体属性信息等问题,本文尝试应用动态图注意力机制于实体对齐模型中,并使用RDGCN 模型中的逐层门控网络机制聚合目标实体的单跳与多跳节点特征,进而拼接经过外部知识预训练的BERT 类预训练模型所获得的实体属性嵌入,从而提出了基于动态图注意力聚合多跳邻域的实体对齐模型DGAT-EA,最后通过实验证明了融入实体属性信息、应用动态图注意力对于实体对齐任务的有效性。在后续的工作中,希望能优化传统图卷积网络对实体单跳节点特征的学习能力,同时为关系事先对齐建模从而提高模型的对齐效果,并通过优化代码实现过程以提高训练效率。
