针对遥感影像的MSA-YOLO 储油罐目标检测*
2022-11-28李想特日根赵宇恒陈文韬徐国成
李想,特日根,赵宇恒,陈文韬,徐国成
(1.长光卫星技术股份有限公司,吉林 长春 130000;2.吉林省卫星遥感应用技术重点实验室,吉林 长春 130000;3.吉林大学 材料科学与工程学院,吉林 长春 130000)
0 引言
近年来,随着高分辨率光学卫星遥感影像处理技术的快速发展,基于遥感影像的目标识别取得了大量成果。其中,对地表自然形成或人造物体进行识别一直是从业人员的关注重点之一。储油罐是在石油、天然气等石化行业中使用的设备,用于储存在环境温度下为液态的原油或者其他化工产品度下为液态的原油或者其他化工产品。按照储油罐的不同用途,分为固定顶型和外浮顶型。利用遥感影像的太阳高度角和内外阴影参数,可以对外浮顶储油罐的满油率进行估算,通过满油率数据在能源期货价格的预测模型中进行回归分析,不但可以为能源期货交易机构提供参考,还能对我国原油的采购及存储等起到指导作用。而在上述工作中,首要任务是在高分辨率遥感影像中实现固定顶和外浮顶储油罐的高效识别与分类。
对于储油罐检测算法,国内外研究人员在传统图像处理领域已经取得很多成果。早在2013年,Kushwaha等提出了一种基于形态学方法和图像拆分/合并的分割技术,对明亮的固定顶圆形储油罐进行检测[1]。在2018年,Jing 等提出了一种基于形状导向的显著性的储油罐检测框架,提取轮廓形状提示作为目标信息来指导选择性显著值的计算,消除高对比度背景的干扰,准确地定位到储油罐[2]。随着卷积神经网络(Convolutional Neural Network,CNN)和机器学习技术的迅速发展[3],许多基于卷积神经网络的模型在储油罐检测中表现出较好的结果。2015 年Zhang 等人提出一种将卷积神经网络与方向梯度直方图特征相结合的方法,使用方向梯度直方图提取局部区域的形状信息,并使用卷积神经网络提取储油罐的周围特征[4]。Girshick 等提出基于区域卷积神经网络[5](Region-based Convolutional Neural Networks,R-CNN)和升级版本Fast R-CNN[6],取得了较高的检测精度。Ren 和Girshick 等人又提出了Faster R-CNN 算法[7],进一步提高了目标检测效果,但仍存在检测速度缓慢的弊端。针对此类问题Joseph Redmon 等在2015 年提出了YOLO 算法[8],该算法将对象检测框架划为空间分隔边界框的回归问题,仅需要一步操作就可以完成目标检测任务。在之后的2016 年和2018 年又推出YOLO9000[9]和YOLOv3[10]两次升级版本,在检测的速度和准确率上都取得较好效果[11-13]。在此基础上Bochkovskiy 等人于2020年发布的YOLOv4 对YOLOv3 提出了五种改进方式和二十余个改进技巧,在平均精度和速度上也远超YOLOv3版本[14],但由于高分辨率的遥感影像尺寸过大,同时YOLOv4 模型复杂,推理时间仍比较慢,因此在储油罐检测工程化应用中存在适用性不足的问题。
针对传统的储油罐检测算法效率低下且达不到工程化标准,以及深度学习算法在使用场景上有欠缺的问题,本文提出了一种储油罐检测算法MSA-YOLO,该算法基于YOLOv4 算法进行改进:对YOLOv4 算法的网络层进行修剪,降低网络复杂度,在保证识别准确率的情况下提升推理速度;同时通过自适应锚框和优化NMS的方式,进一步提升模型收敛速度和识别准确率。
1 算法模型
1.1 YOLOv4 算法
Bochkovskiy 等人在2020 年4 月发布的YOLOv4 算法,其Backbone 使用了CSPDarknet53 结构,该结构取消了算力消耗较高的计算瓶颈结构,同时减少了参数使之更容易训练。Neck 部分主要采用了空间金字塔池化[15]和路径聚合网络[16]的方式,可以更好地提取融合特征。Head 部分将网络的输出数据与真实标注数据对接,进行损失值的计算,同时重新组织数据格式,对特征图进行解码,并对原始网格单元中的(x,y,w,h)值分别做相应的激活等。
YOLOv4 中的多尺度检测策略通过上采样生成三个尺度的融合特征图,分别用来识别大、中、小三类物体,如表1 所示,输入图像通过下采样生成13×13 的大尺度特征图、26×26 的中尺度特征图和52×52 的小尺度特征图。以COCO 数据集[17]为例,大尺度特征图对应的锚框为(142,110)、(192,243)和(459,401),中尺度特征图对应的锚框为(36,75)、(76,55)和(72,146),小尺度特征图对应的锚框为(12,16)、(19,36)和(40,28)。
如图1 所示,9 个默认锚框分别以蓝色边框(大)、绿色边框(中)和红色边框(小)进行区分,蓝色边框和红色边框的尺寸与真实储油罐尺寸差距较大,绿色边框的尺寸与真实储油罐尺寸较为一致。因此对于尺寸较为固定的储油罐检测中,默认锚框与目标的尺寸相差较大,不利于模型的加速收敛。与此同时,随着锚框数量的增加,预测滤波器中的卷积滤波器数量线性增加,这将导致网络规模变大,并增加训练时间。
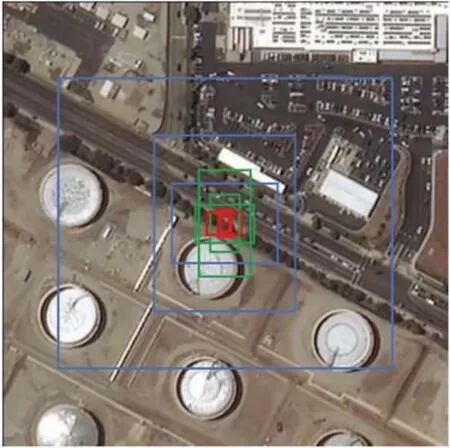
图1 YOLOv4 默认锚框
在目标检测算法中,IoU(Intersection over Union)和NMS(Non-Maximum Suppression)具有重要的意义。IoU 代表的是“预测边框”和“真实边框”的交集和并集的比值[18]。在YOLOv4 优化损失函数的过程中使用边界框回归的方式,IoU 损失公式如式(1)所示:

NMS 用于确保出现在多个候选框中的物体仅被计算一次,滤出其他可预测同一对象的边界框,保留最高的置信度[19]。NMS 算法的步骤如下:
(1)将所有边界框进行置信度大小排序;
(2)保留置信度最高的边界框,移除与该边界框IoU 大于阈值的边界框;
(3)对于剩下的所有边界框执行步骤(2),直到无法继续移除边界框为止,算法结束。
在本文所述的高分辨率大尺寸遥感影像检测中,有两个步骤均使用到了NMS:
(1)在预测过程中,使用NMS 过滤检测框;
(2)在将检测框融合到大尺寸原始图片上时,使用NMS 过滤相邻小尺寸图片重叠部分的检测框。
基于IoU 的NMS 在过滤检测框的过程中存在着明显的缺点,即当两个检测框不相交时,LIoU的值始终为1,无法给出优化的方向,回归速度慢。
1.2 遥感影像的目标识别
现阶段,在高分辨率大尺寸遥感影像中检测较小物体仍是一个重大挑战,以吉林一号光学遥感卫星拍摄的2021 年6 月的美国库欣区遥感影像为例,其尺寸为14 166 像素×10 742 像素,分辨率为0.75 m。该影像覆盖范围超过100 平方公里,包含1.5 亿个像素,而其中的待检测储油罐对象尺寸仅为几十像素。YOLOv4 网络可识别的图像输入像素大小多为416×416、608×608等,与遥感影像的尺寸差距过大,无法直接进行高分辨率大尺寸遥感影像的识别。
2 算法优化
2.1 MSA-YOLO 网络结构
在YOLOv4 的检测过程中,对于尺寸不同的目标采取多尺度检测的方式。对于标准大小的储油罐,直径从6.1 m 到91.5 m 不等,直径超过61 m 的储油罐被称为中大型储油罐[20]。经调查研究,监控区域的储油罐大小直径从20 m 到70 m 不等,以中大型储油罐为主。在尺寸为416×416、分辨率为0.75 m 的图片上,储油罐罐顶尺寸为26.67 像素至93.3 像素,通过计算真实标注框数据,带有阴影的储油罐尺寸所在区间为54 像素至133像素,该区域基本符合中尺度特征图的预测区间。由于储油罐的尺寸相对固定,因此为了降低模型的复杂度,减少计算量,加快推理速度,以适应对大尺寸遥感影像的快速检测,需对YOLOv4 的网络层执行剪枝操作[21]。
为了适合储油罐尺寸特性,可将YOLOv4 头部多尺度检测中用来识别大尺度和小尺度的分支进行剪枝,仅保留识别中尺度的分支,并将路径聚合网络的上采样模块与高层语义信息进行结合,建立储油罐的特征检测层。如图2 所示,在MAS-YOLO 算法的网络结构图中,训练数据经过CSPDarknet53 骨干网络,提取目标特征;通过基于剪枝的YOLOv4 头部模块,在中尺度特征图上训练出储油罐识别模型。
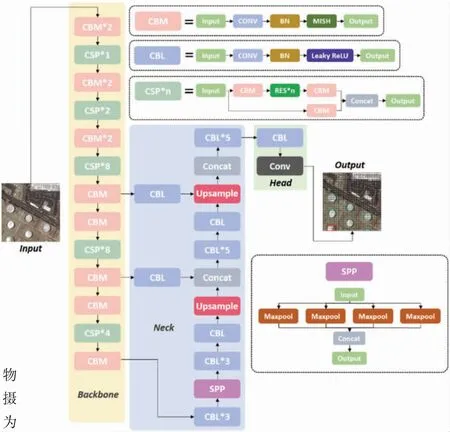
图2 MSA-YOLO 算法网络结构图
2.2 自适应锚框
为了降低模型的复杂度,同时适应储油罐的尺寸特性,MAS-YOLO 算法仅需保留中尺度特征图对应的3 个锚框。在校正锚框尺寸的过程中,使用k-means++聚类算法[22]。未使用k-means 算法[23],主要是因为两者对于聚类中心初始化的方式不同。其中k-means 算法中随机初始化k 个聚类中心,而k-means++算法生成k 个相互距离更远的聚类中心点,最大程度地避免了聚类中心初始化敏感度的问题。聚类中心数量(下文用k 表示)与IoU 和IoU 变化率的对应关系如图3 所示。

图3 不同聚类中心数量的平均IoU 与平均IoU 变化率
(1)IoU 与k 值呈 正相关,k 值越大,IoU越大。
(2)当k<3时,IoU 值较小且变化幅度较大;当k≥3时,平均IoU 大且变化幅度较小。
(3)当k<3时,IoU 变化率大且变化幅度较大;当k≥3时,平均IoU 变化率小且变化幅度区域稳定。
由于随着k 的增加,锚框尺寸趋于接近,因此取k=3时,既可以减少锚框带来的误差,也可以加快训练的收敛速度。如表2 所示,在初始锚框选择的应用中,当k=3时,k-means 算法的IoU 为78.72%,k-means++算法的IoU 为79.13%;k 为1至9时,k-means算法的平均IoU 为78.74%,k-means++算法的平均IoU 为79.74%。综上所述,k-means++平均IoU 更大,精确度更高。

表2 聚类算法比较 (%)
因此,对数据集进行聚类中心为3 的聚类分析,得到3 个自适应锚框,尺寸分别为(60,32)、(42,67)和(72,91),在图4(a)中分别用红色边框表示;同时对数据集内全部对象尺寸进行统计,得到储油罐对象的平均尺寸为(68.2,68.3),在图4(a)中用绿色边框表示。如图4(a)所示,3 个尺寸的自适应锚框均有宽(或高)度与平均尺寸保持一致,同时还保留自身的另一个高(或宽)度的独立性,以适应各种尺寸的储油罐对象。如图4(b)所示,三个自适应锚框基本可以分别覆盖大、中、小三种尺寸的储油罐,锚框的形状非常接近储油罐的真实形状,较默认锚框相比更为准确,以便MSA-YOLO 网络更容易地学习对锚框的小幅调整,创建更准确的边界框。

图4 自适应锚框示意图
2.3 CIoU-NMS
2.3.1 CIoU-NMS 算法
针对两个检测框不相交时,传统IoU 回归速度慢的缺点,GIoU[24](Generalized Intersection over Union)对此进行了优化,如式(2)所示:

其中C 表示包含两个框的最小矩形,可以对两框不相交的情况进行优化。而当两个候选框完全相交时,GIoU 损失则退化到IoU 损失,收敛速度同样会减慢。DIoU[25](Distance Intersection over Union)在GIoU 的基础上,对于不同距离、方向、面积和比例的预选框都能做到较好的回归,如式(3)所示:

其中b 和bgt分别代表预选框和目标框的中心点,ρ2(b,bgt)代表两个中心点的欧式距离,c 代表能同时覆盖两框的最小矩形的对角线距离。DIoU 可以在预选框与目标框不重叠时,为预选框提供移动方向,也可以最小化两个目标框的距离。但当两个框中心点重合时,ρ2(b,bgt)和c 值都不变,DIoU 此时需引入框的宽高比,即CIoU(Complete Intersection over Union),宽高比所占的比例与IoU 呈正相关,最终,CIoU 如式(4)所示:
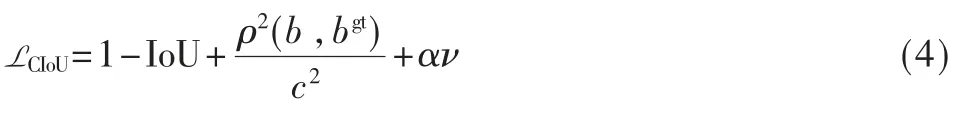
其中α 是权重函数,ν 用来度量宽高比的一致性,如式(5)和式(6)。
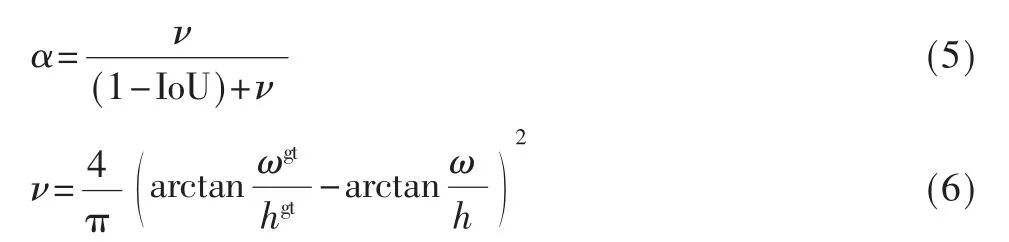
图5 为同一储油罐对象的真实边框与多种情况的预测边框示意图,其中G 为真实边框,其余为预测边框,对每一种情况分别计算不同的IoU 损失如表3 所示。

表3 不同的IoU 方式与结果
结论如下:
(3)对于图5(c)、5(d)和5(e),真实边框与预测边框完全相交,GIoU(C,G)=GIoU(D,G)=GIoU(E,G),DIoU(C,G)≠DIoU(D,G)≠DIoU(E,G),GIoU 无法提供优化方向;
(4)对于图5(e)和5(f),两框中心点重合但预测边框宽高比不同,CIoU(F,G)≠DIoU(F,G)≠GIoU(F,G)≠IoU(F,G),DIoU 无法提供优化方向,此时仅CIoU 可以提供优化方向。

图5 同一储油罐对象的真实边框与多种预测边框
与其他几种方法相比,CIoU 更符合目标框回归的机制,将目标与锚框之间的距离、重叠度和尺度都涵盖在内,使得目标框回归更加稳定,最大程度地避免了训练过程中的发散问题。
2.3.2 CIoU-NMS 在预测过程中的使用
对于尺寸为416×416 的输入图像,经过目标识别算法网络,最终生成26×26×2=1 352 个边界框。通过NMS,从多个预测的边界框中保留最佳边界框。如图6 所示,以测试图片中的两个储油罐为例,使用CIoU-NMS,得到置信度最高的检测结果。

图6 CIoU-NMS 在预测过程中的应用
2.3.3 CIoU-NMS 在融合过程中的使用
在遥感影像识别过程中,需将全部416×416 尺寸的小图检测到的边界框融合到原始图像上,如图7 所示,尺寸较大的矩形框代表三张相邻的416×416 尺寸的检测图像,尺寸较小的多个矩形框分别代表每张检测图像上的储油罐检测结果。在20%尺寸的重叠区域中,三个储油罐分别被三张检测图像检测了7次,生成7 个预测框,此时需要使用CIoU-NMS,保留置信度最高的三个边界框,得到最终的识别结果。

图7 CIoU-NMS 在融合过程中的应用
2.4 高分辨率大尺寸遥感影像的处理
针对储油罐检测的过程中无法直接把高分辨率大尺寸遥感影像输入网络进行识别的问题,本文基于SIMRDWN[26]项目编写识别程序,对遥感影像进行处理,步骤如下:
(1)程序读取原始尺寸的遥感影像。
(2)程序使用scikit-image[27]对原始影像通过滑动窗口的方式进行切割。如图8 所示,为了不遗漏待检测对象,相邻图片带有20%尺寸的重叠部分,最终将原始图像生成多幅尺寸为416×416 的图像。

图8 通过滑动窗口进行图像切割
(3)将全部图像输入MSA-YOLO 网络进行目标识别,输出每一幅图像对应的储油罐识别结果文本文件。
(4)将全部识别结果文本文件作为输入,执行坐标转换函数,输出为每个储油罐在原始图像大小的真实坐标值(x,y,w,h)。
(5)将全部储油罐的坐标值使用OpenCV-Python 的cv2.imwrite()方法绘制到原始图像上,识别程序结束。
通过该程序的处理,解决了深度学习算法对高分辨率大尺寸遥感影像的识别问题,具有现实意义。
3 数据集
3.1 MSA-YOLO 数据集
在MSA-YOLO 数据集的制作中,主要使用了吉林一号光学遥感影像数据,同时也包括了开源遥感数据集,如NWPU VHR-10 数据集[28-30]、DOTA 数据集[31-32]、RSOD数 据集[33-34]、AID 数据集[35]等。数据集中共包含2 025 幅原始遥感图像,通过顺时针旋转60°、90°、180°和270°扩充至10 125幅,其中20%(2 025 幅)作为测试集,20%(2 025 幅)作为验证集,其余60%(6 075 幅)作为训练集,共包含60 760 个固定顶储油罐和137 320 个外浮顶储油罐,共计198 080 个储油罐。
3.2 高分辨率大尺寸遥感影像数据集
高分辨率大尺寸遥感影像数据集包含从2020 年8月至2021 年6 月吉林一号卫星星座系列拍摄的美国库欣区156 幅遥感影像。单幅影像尺寸均在10 000×10 000像素以上。该数据集均作为测试集,用以验证MSA-YOLO模型在高分辨率大尺寸遥感影像上的识别效果。
4 实验配置与结果分析
4.1 实验配置与评价标准
本研究实验配置的CPU 为Intel Xeon,GPU 为Tesla V100 SXM2,内存为26 GB,操作系统为Ubuntu 18.04。优化算法训练参数设置如表4 所示。
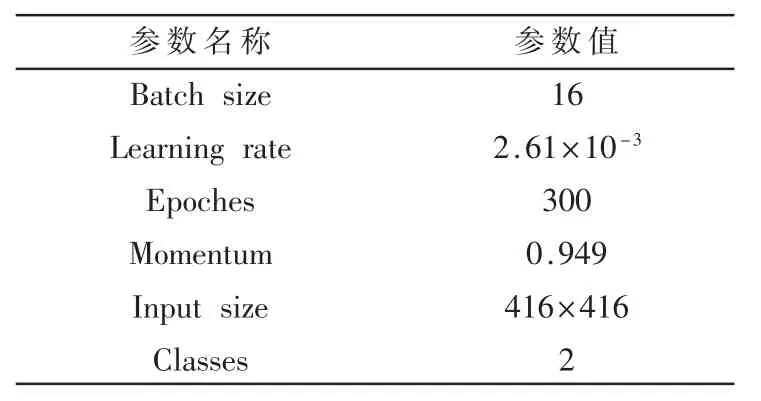
表4 MSA-YOLO 算法训练参数设置
为了验证模型的性能,本文采用精确率、召回率、mAP@.5 和F1-score 四个技术指标和模型大小、推理速度和训练速度三个性能指标进行评价,如式(7)~式(10)所示。

其中,TP、FP 和FN 分别代表真阳性(True Positive,TP)、假阳性(False Positive,FP)和假阴性(False Negative,FN);N 代表检测类别的数量,由于检测类别分别为固定顶储油罐(类别序号为0,标签为“Fixed_Roof_Tanks”)和外浮顶储油罐(类别序号为1,标签为“Floating_Roof_Tanks”),因此在本文中N=2。Model-size 即为模型生成的最优权重文件,主要存放训练过程中需要学习的权重和系数,以及包括训练次数、训练超参数等在内的其他参数信息,一般来说,在同样的网络结构下,Model-size 与模型复杂度成正比,Model-size 越大,模型越复杂。
4.2 实验结果与分析
4.2.1 MSA-YOLO
为了验证MSA-YOLO 算法的有效性,对MSA-YOLO数据集中2 025 幅测试图像中的储油罐进行了测试,结果如表5 所示。MSA-YOLO 算法的Precision 和Recall分别为89.25%和95.20%,mAP@.5 为95.65%,F1-score 为92.13%,Model-size 为153 MB,Detection-speed 为420.17 F/s,Training-speed 为47 s/epoch。与YOLOv4相比,mAP@.5低0.1%,F1-score 高0.28%,指标基本持平;而Modelsize 减少了62.13%,Detection -speed提升15.76 F/s,Training-speed 减少了6.1 s/epoch。实验结果表明,与YOLOv4 算法相比,经过剪枝操作的MSA-YOLO 算法在保证了准确率的前提下,模型的推理速度和训练速度更快,模型更小。

表5 MSA-YOLO 与YOLOv4 算法检测结果
为了验证MSA-YOLO 方法的有效性,本研究比较了四种目标检测算法,包括YOLOv3、YOLOv4、YOLOv5 和EfficientDet-D0[36]。在相同环境和数据集的情况下,五种算法的测试结果如表6 所示。

表6 不同的目标检测算法检测结果
测试结果表明,这五种检测算法的mAP@.5 分别为94.10%、95.75%、94.25%、81.50%和95.65%;Model-size分别为117 MB、404 MB、170 MB、15 MB 和153 MB;Detection -speed分别为434.78 F/s、404.41 F/s、294.12 F/s、268.72 F/s 和420.17 F/s;Training-speed 分别为58.9 s/epoch、53.1 s/epoch、68.9 s/epoch、184.8 s/epoch 和47.0 s/epoch。
从测试结果分析中可以看出,MSA-YOLO 算法的检测精度较高,mAP@.5 仅较YOLOv4 低0.10%,比其他三种算法分别高1.55%、1.45%和14.15%;F1-score 仅低于YOLOv5 算法0.77%,比其他三种算法分别高1.56%、0.28%和10.68%。在Detection-speed 方面,MSA-YOLO 算法仅慢于YOLOv3 算法14.61 F/s,比其他三种算法分别快15.76 F/s、126.05 F/s 和151.45 F/s;在Training-speed方面,MSA-YOLO 算法比其他四种算法分别快11.90 s/epoch、6.10 s/epoch、21.90 s/epoch 和137.80 s/epoch;在Modelsize 方面,MSA-YOLO 算法的模型比YOLOv3 算法的模型大36 MB,比EfficientDet-D0 算法的模型大138 MB,小于其他两种算法模型251 MB 和17 MB。但EfficientDet-D0算法比MSA-YOLO 算法mAP@.5 低14.15%,Detectionspeed 慢151.45 F/s;YOLOv3虽然Detection-speed仍比MSA-YOLO 算法快13.61 F/s,但mAP@.5 比MSA-YOLO算法低1.45%,从成本效益的综合角度来看,MSA-YOLO算法仍更为高效。
结合实验数据,可得到结论:
(1)MSA-YOLO 算法在与其他四种算法的比较中,mAP@.5 与YOLOv4 和YOLOv5 算法基本持平,而在Modelsize、Detection-speed 和Training-speed 上均占优;
(2)YOLOv3 与MSA-YOLO 算法相比,虽然Model-size和Detection-speed 均占优,但mAP@.5 和Training-speed差距较大;
(3)MSA-YOLO 算法各项指标均优于EfficientDet-D0。
综上所述,从成本效益的综合角度来看,MSA-YOLO算法更为高效。本文提出了一种基于YOLOv4 算法的其他算法进行剪枝算法的原因是其原本的mAP@.5 低于MSA-YOLO 算法,而剪枝算法通常不能提高模型的准确性[37]。五种算法的检测结果示例如图9 所示。

图9 5 种算法的检测结果
本文提出的MSA-YOLO 算法在保证了检测精度的前提下,改善了模型参数过多、体积过大的问题,同时大幅缩短了模型训练时间,提升了检测速度,具有一定的现实意义。
4.2.2 自适应锚框检测结果
如图10 所示,以训练过程中的前200 批次为例,使用默认锚框与使用自适应锚框的两次模型训练的平均损失均从初始的1 902 开始减少,在100 批次附近基本达到一致。在1 至100 批次的训练过程中,使用自适应锚框的模型训练,其平均损失收敛速度更快,更有助于模型的加速收敛。
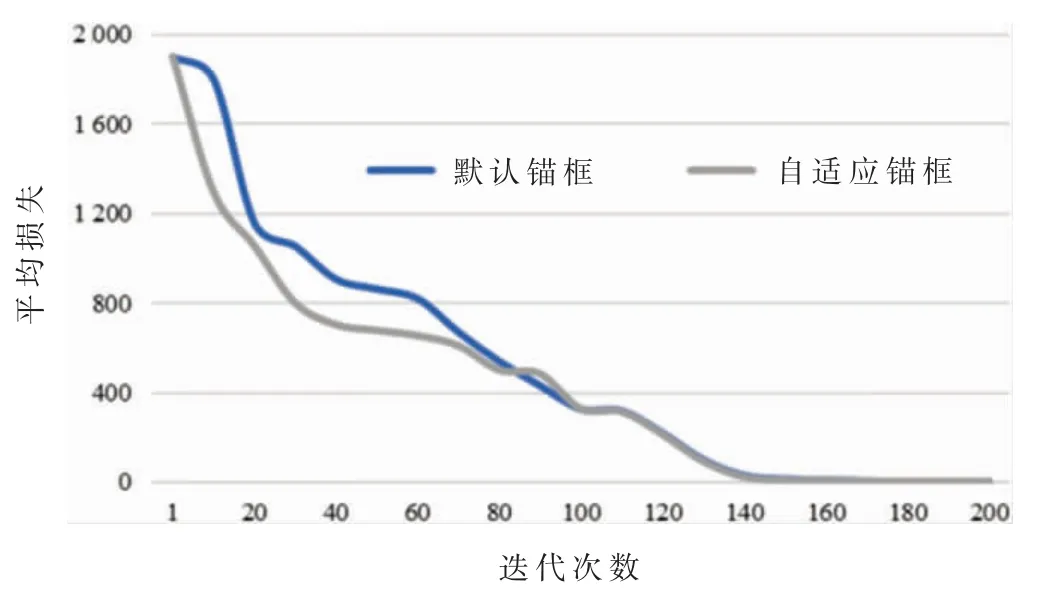
图10 默认锚框与自适应锚框的目标检测结果
4.2.3 使用CIoU-NMS 对MSA-YOLO 进行预测框优化结果
在实验中,通过设置nms_kind 参数,将NMS 方式从GreedyNMS 调整为CIoU-NMS,将两种配置分别进行训练,实验结果如表7 所示,使用CIoU-NMS 的Precision 和Recall 分别为91.35%和94.40%,比使用IoU 方式的Greedy-NMS 算法均提高1%,同时mAP@.5 提升0.42%,F1-score提升1%。实验结果表明,与基于IoU 的GreedyNMS 相比,基于CIoU 的NMS 具有更高的精度,有利于生成效果更好的模型。

表7 使用IoU 与使用CIoU 的NMS 算法检测结果(%)
4.2.4 高分辨率大尺寸遥感影像的目标检测
本文对高分辨率大尺寸遥感影像数据集进行检测与统计,生成检测结果图片,如图11 所示。图11 为吉林一号高分03 号卫星拍摄的具有0.75 m 分辨率的美国库欣区遥感影像(局部),在该图中共有储油罐349个,用蓝色边框表示;其中TP 为344个,用绿色边框表示;FP为4个,用红色边框表示;FN 为1个,用黄色边框表示。该图Precision 为98.85%,Recall 为99.71%。

图11 高分辨率大尺寸遥感影像的目标检测结果
对于全部156 幅测试影像的总体识别结果如图12所示,其中满足Precision ≥95%的图片占60.31%;满足95%>Precision≥90%的图片占17.56%;满足90%>Precision≥80%的图片占9.92%;满足Precision≤80%的图片占12.21%。满足Recall ≥95%的图片占81.34%;满足95%>Recall ≥90%的图片占7.46%;满足90%>Recall≥80%的图片占10.45%;满足Recall≤80%的图片占0.75%。识别每幅影像的平均耗时为59.05 s,对每幅影像的预处理及后处理平均耗时为17.37 s,每幅影像平均总耗时为76.42 s。结合识别准确率与识别时间,该算法具有可行性。

图12 高分辨率大尺寸遥感影像的目标检测结果统计
5 结论
为了实现对美国库欣区遥感影像中储油罐的准确、实时地智能检测,本研究提出了基于优化YOLOv4 算法的储油罐检测方法MSA-YOLO 算法,并对其进行实验。主要结论如下:
(1)MSA-YOLO 算法通过对监控区域的环境调研,在保证模型检测精度的前提下,将目标识别模型的多尺度检测Head 层进行修剪,仅保留符合储油罐真实尺寸的输出尺度,同时使用k-means++算法对锚框进行优化,生成自适应锚框;同时使用CIoU 进行NMS 优化。经实验表明,MSA-YOLO 算法的平均精度为95.65%,检测速度可达420.17 F/s。
(2)在对比实验中,将MSA-YOLO 算法与当前主流目标识别算法进行对比,结果表明,MSA-YOLO 算法具有相对最高的准确率,最快的训练速度和检测速度,以及较小的模型尺寸,在能准确检测储油罐的前提下,可以满足实时性的要求。
(3)在对高分辨率大尺寸遥感影像的检测中,将遥感影像经过预处理后进入MSA-YOLO 识别网络,得到识别结果后,经过后处理生成检测结果,此过程准确率高,识别时间短,可为基于高分辨率大尺寸的遥感卫星影像中储油罐检测提供技术参考。
在快速准确地识别美国库欣区遥感影像中储油罐的前提下,进而通过区域内原油储量的计算和回归分析,可以挖掘出遥感数据在能源期货领域的巨大的应用价值,更早做出合理投资决策,为交易者和策略制定者提供信息优势。
