Visual-simulation region proposal and generative adversarial network based ground military target recognition
2022-11-28FnjieMengYongqingLimingShoGihongYunJuyingDi
Fn-jie Meng ,Yong-qing Li ,F-ming Sho ,Gi-hong Yun ,Ju-ying Di
a Department of Space Test and Launch,Noncommissioned Officer School,Space Engineering University,Beijing,102299,China
b Department of Mechanical Engineering,College of Field Engineering,Army Engineering University of PLA,Nanjing,210007,China
ABSTRACT Ground military target recognition plays a crucial role in unmanned equipment and grasping the battlefield dynamics for military applications,but is disturbed by low-resolution and noisyrepresentation.In this paper,a recognition method,involving a novel visual attention mechanismbased Gabor region proposal sub-network(Gabor RPN)and improved refinement generative adversarial sub-network(GAN),is proposed.Novel central-peripheral rivalry 3D color Gabor filters are proposed to simulate retinal structures and taken as feature extraction convolutional kernels in low-level layer to improve the recognition accuracy and framework training efficiency in Gabor RPN.Improved refinement GAN is used to solve the problem of blurry target classification,involving a generator to directly generate large high-resolution images from small blurry ones and a discriminator to distinguish not only real images vs.fake images but also the class of targets.A special recognition dataset for ground military target,named Ground Military Target Dataset(GMTD),is constructed.Experiments performed on the GMTD dataset effectively demonstrate that our method can achieve better energy-saving and recognition results when low-resolution and noisy-representation targets are involved,thus ensuring this algorithm a good engineering application prospect.
1.Introduction
Environmental perception has become one of the most fundamental capabilities of unmanned equipment in both military and civilian[1-3].The research of recognizing ground military target in complex ground battlefield is becoming the key to grasp the battlefield dynamics.However,target recognition for both military and civil fields are facing hinder of blur,illumination and significant variations in scale in uncontrolled settings.
Great progress has been made in object recognition using deep learning methods.Such methods like Faster region with a convolutional neural network(Faster R-CNN)[4]and Single Shot Multi-Box Detector(SSD)[5]learn deep representations from a region of interest(ROI)and perform classification based on the learned representations.However,at large distance,targets always appear small and their content blurry.It is difficult for traditional random weight kernels to learn rich features due to the objects’poorquality appearance and structure.The feature enhancement of blurry targets has become the key to its detection and classification.In addition,the training of traditional random weight kernel requires a large amount of computation,which is not friendly to computing platform.
The retina is the core of the eye"s visual function,which encodes the optical signals of the visual world,including the information of light intensity,shape,color and movement,into digital pulse signal series and transmits them to the brain through the neural network[6-8].A simple rule of thumb is that a person does not need a whole new set of sensory cells in visual system to fit new environmental situations.Therefore,fixed weight kernels simulating retina structure and attention mechanism can improve training efficiency and initial accuracy of neural network.In addition,most modern CNN-based object classifier uses the down-sampled convolutional feature map,which loses most spatial information and is too coarse to describe small targets.
To address the key target detection and classification in uncontrolled settings,we proposed a novel visual attention mechanism-based recognition method.The work and innovation of this paper mainly include the following contents:
·By analyzing the structure of human retina,we improved the traditional Gabor filter and proposed central-peripheral rivalry 3D color Gabor filter,which has stronger ability to express features.
·Based on the inherent error resiliency of the networks and the similarity between convolutional kernels and 3D color Gabor filters,we introduced Gabor kernels into low-level layers of CNNs,and proposed visual attention mechanism-based Gabor RPN.
·We improved a refinement GAN[9-11]to eliminate the poorquality appearance of tiny objects and improved its discriminator to have additional classification ability.
The rest of our paper is organized as follows:In Section 2,we introduce the related work.In Section 3 we give an overview of the method firstly and present the detail of our ground military target recognition method.The experimental evaluation is provided in Section 4.Finally,we presented some conclusions and future work in Section 5.
2.Related work
2.1.Ground military target recognition
In general,object recognition mainly includes two stages-detection and classification[12].The detection stage focuses on the location and size of targets,and the classification stage determines what class the targets belong to.Methods of ground military target recognition mainly include digital image-based methods and infrared image-based methods.Compared with the latter,digital image sensors have lower cost,longer detection range and richer features captured.Modern digital image-based ground military target detection methods can be divided into humanengineering-features-based methods(e.g.,Histogram of Oriented Gradient(HOG)[13],Scale-Invariant Feature Transform(SIFT)[14],Support Vector Machine(SVM)[15])and deep-learning-based methods.Human-engineering features are easier to be understood and computation efficient,but the methods based on these features are often poor in robustness and can be only adapt to simple scenario.Shenpei Chen et al.[16]recognize armored target based on local part and latent support vector machine.Congli Wang et al.[17]detect armored target based on a global threshold value and two-dimensional morphological haar wavelet.In recent years,with the breakthrough of deep learning algorithm and on-board computing platforms,military target recognition based on digital image and deep learning algorithm has aroused extensive interest.Haoze Sun et al.[18]detect armored target with a top-down aggregation(TPA)network and multi-branch RPNs framework.Quandong Wang et al.[19]apply faster region convolutional neural network(Faster R-CNN)and a coarse image pyramid solve the recognition problems of armored target.Fanjie Meng et al.[20]Focused on the task of fast and accurate armored target detection in ground battlefield and propose a detection method based on multiscale representation network(MS-RN)and shape-fixed Guided Anchor(SF-GA)scheme.Although many efforts have been applied to military target recognition,most efforts apply too idealistic conditions or fail to classify targets in detail.
2.2.Recognition of small objects
Recognizing small objects is notoriously challenging due to their low resolution and noisy representation[21].Small object recognition is required in a great many real-world applications,such as traffic sign recognition[1,2],pedestrian detection[22],the recognition of small faces[23],and so on.Some efforts[21-24]have been devoted to dealing with the problems of small object detection and recognition.Increasing the scale of input is a straightforward way to enhance the resolution of small objects[25].However,in most occasions,larger input is hard to get and increasing the scale of input images often results in heavy time.Some others[26-28]have focused on developing network variants to generate multi-scale features with multiple layers of lower-level features.However,shallow but fine-grained intermediate convolutional features often cause many false positive results.Other approaches focus on deblurring methods to refine low-resolution images.Most existing deblurring methods heavily rely on prior models to solve the ill-posed problem,and assume the priori that gradients of natural images have a heavy-tailed distribution[29].
2.3.Generative adversarial networks
With the development of deep learning,great improvements have been achieved on super-resolution[9,10,30,31].Among the super-resolution methods,GANs draw attention,since they can avoid the black-box constructing representation by the low-level features and generate interpretable and discriminative features for object detection[21].A GAN learns a generative model used to complete end-to-end mapping via an adversarial training process.Besides,most CNN-based methods use down-sampling kernels[32],which reduces the size of feature maps and cannot be applied to small objects in uncontrolled settings.
GANs were first introduced to generate realistic-looking images from random noise[9].So far,GANs have achieved impressive results in image generation[33],image editing[34],representation learning[35],image annotation[36],image super-resolution[21,22],and character transferring[37].Recently,GANs have been applied to super-resolution images[10],and have obtained promising results(e.g.,super-resolution GAN).However,conventional discriminators are only trained to distinguish real images vs.fake images(generated by a generator network),which is detrimental to system efficiency.To address these problems,we design a generator and classification discriminator for ground military targets to classify multi-scale ground military targets in the wild.
3.Proposed method
3.1.Overview of our method
At large distance,ground military targets always appear small and their content blurry.Such targets are difficult both to detect and to classify.In order to recognize ground military targets in reallife situations,we propose a target recognition method,which is illustrated in Fig.1.
Our method includes two components,i.e.,a Gabor region proposal sub-network(Gabor RPN)and a refinement generative adversarial sub-network(refinement GAN).The Gabor RPN is used to crop the low-resolution and high-resolution region of interests(ROIs)as outputs.Inspired by the retina encoding the optical signals of the visual world,we propose central-peripheral rivalry 3D color Gabor filter to simulate retina structure and form the primary feature attention layer of Gabor RPN.According to the fusion attention feature,we designed two branches to predict the shape and position of the target respectively in Gabor RPN.The next refinement GAN,including a generator and discriminator,is used to eliminate the poor-quality appearance of tiny targets and classify all ROIs.The low-resolution ROIs are fed into the generator,which is pretrained as associative network between blurry and clear targets.The generator directly reconstructs clear 4×super-resolution images from small blurry ones.Then,the high-resolution ROIs and reconstructed super-resolution images are fed into the discriminator,which is improved to be able to distinguish not only real images vs.fake images(reconstructed by the generator network)but also the class of ground military targets.The problems of target location and classification are solved by the Gabor RPN and refinement GAN respectively.
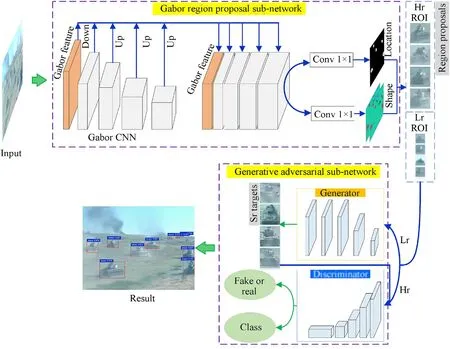
Fig.1.Overview of our method.Lr ROI and Hr ROI represent low-resolution regions of interest(ROIs)(less than 32 pixels in height)and high-resolution ROIs(larger than 32 pixels in height),respectively.Sr represents super-resolution(or fake)image generated by generator network.
3.2.Retina simulation Gabor filter
The retina is an important organ to perceive the external environment and also an efficient feature extraction structure.It is the core of the eye"s visual function,which encodes the optical signals of the visual world into digital pulse signal series and transmits them to the brain.As shown in Fig.2,the structure of the retina is very complex.The retina includes five major types of neural cells:rod cell,cone cell,horizontal cell,bipolar cell and ganglion cell.The direction of information flow is opposite to the ray incidence direction.Rod and cone cells are the first level photoreceptor cells.The bipolar cells transmit the processed information to ganglion cells and amacrine cells,which produce nerve impulses.Horizontal cells lie between first level photoreceptors and bipolar cells.
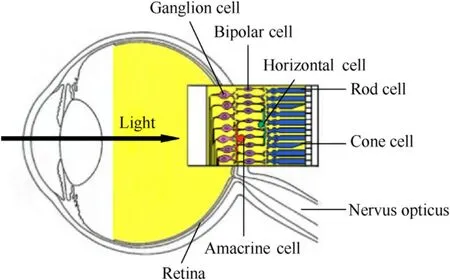
Fig.2.Eye and retinal structure.
The retina has specific responses to different excitation.The rod cells are sensitive to light intensity,but have no color sensitivity.There are three types of cone cells,which are sensitive to red,green and blue respectively.Horizontal cells give negative feedback to photoreceptor cells and bipolar cells,which results the bipolar cells and ganglion cells form a central-peripheral rivalry receptive field.Fig.3 shows the central-peripheral rivalry receptive field and its response to excitations.According to the response of the center to the excitation,the central-peripheral rivalry receptive field can be divided into center-on type and center-off type.The center-on type outputs positive response to the central positive excitation.Accordingly,the center-off type outputs positive response to the boundary positive excitation.
Riaz et al.used two-dimensional(2D)Gabor filters as cell receptor field function to sim γ ulate its characteristics and responses[6,7].A 2D Gabor filter is a combination of a 2D Gaussian function and an oriented complex sinusoidal grating,which can be expressed as:
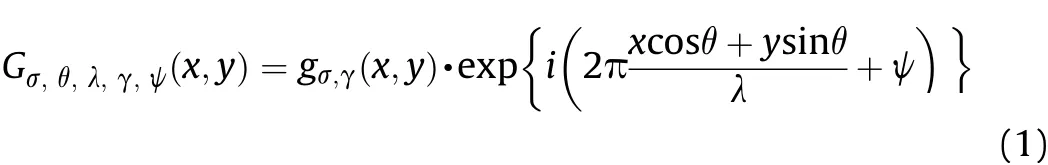
whererepresents the coordinates of a pixel,gσ,γ(x,y)is a Gaussian envelope,the rest represents a sinusoidal grating.σ denotes the standard deviation of a Gaussian envelope,which controls the receptive field of Gabor filters.represents the aspect ratio of the space.θ,λ,ψ represents sinusoidal grating orientation,wavelength and phase shift.The Gaussian envelope is defined as
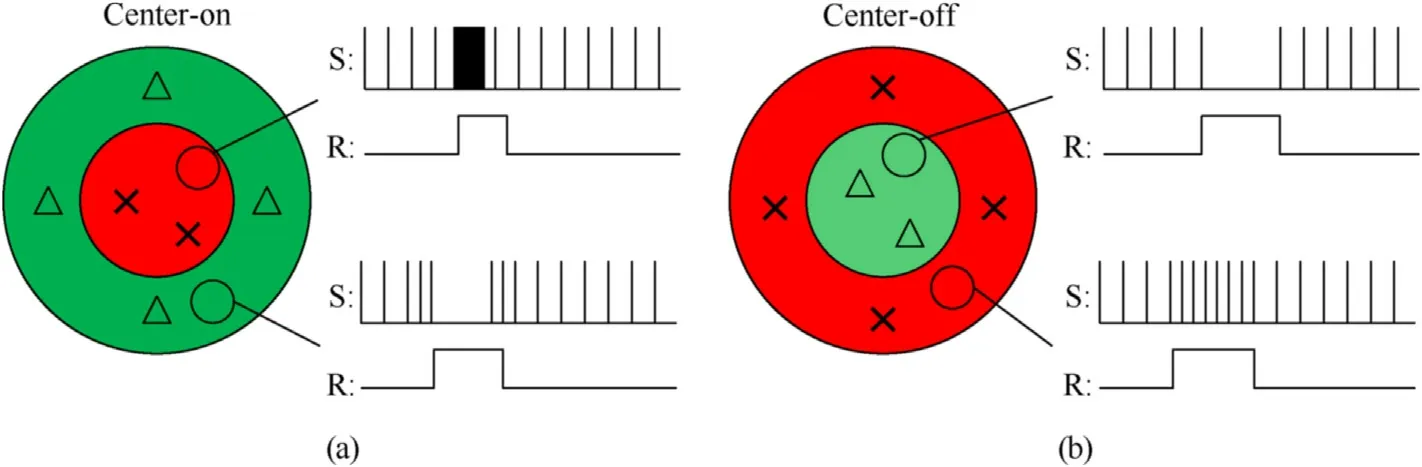
Fig.3.The central-peripheral rivalry receptive field and its response to excitations:(a)Center-on;(b)Center-off.
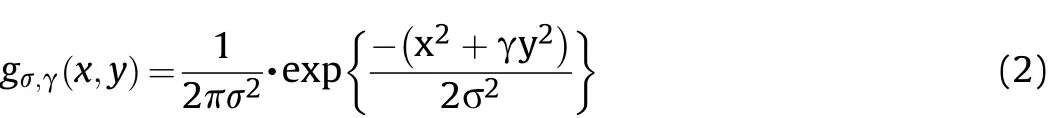
According to the shape of Gaussian envelope,traditional 2D Gabor filter has only simulated center-on type of central-peripheral rivalry receptive field and the color information has been missed.In this work,we simulate the two types of central-peripheral rivalry receptive field in the retina and propose central-peripheral rivalry 3D color Gabor filter.In our improved Gabor filter,there are two kinds of Gaussian envelope to simulate the central-peripheral rivalry receptive field,which can be expressed as:
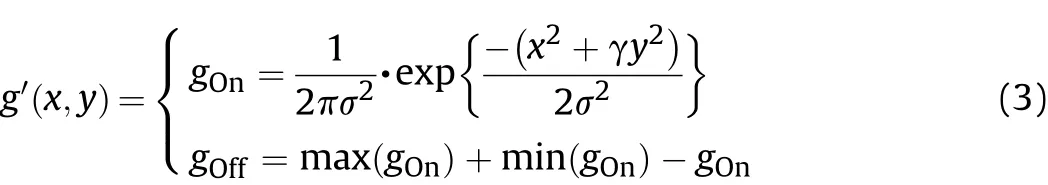
wheregOnandgOffare used to simulate center-on and center-off type of receptive field.The 3D and 2D features of improved Gaussian envelopes are shown in Fig.4.
The other one characteristic of neural cells in retina is that they have strong directional selectivity.Most neural cells in retina only respond to the fringe in a particular direction.Such characteristic can be simulated by the sinusoidal grating part of Gabor filters.However,traditional 2D Gabor filter lost the color information.Rod and cone cells are the first level photoreceptor cells.They are sensitive to light intensity and color of red,green and blue respectively.In order to simulate the color sensitivity,we extend 2D Gabor filter to 3D RGB color space.In RGB color space,the color value of red,green and blue are[255,0,0],[0,255,0]and[0,0,255]respectively.In our central-peripheral rivalry 3D color Gabor filter,there are three kinds of filters sensitive to red,green and blue,respectively.The three kinds of color Gabor filters are defined as:

Fig.5 shows the comparison of traditional 2D Gabor filter and our central-peripheral rivalry 3D color Gabor filter.
3.3.Training efficient Gabor convolutional kernels
Much works has proved the advantage of Gabor filters in spatial information extraction,including edges and textures[38,39].Compared with the training of traditional random weight kernels,the optimization of Gabor filters is much simpler with few parameters.Hence,the combination of CNNs with Gabor filters is a valid process to reduce the computational energy and time consumption of networks.Fig.6 shows the visualization of CNN kernels through the deep convolution neural network visualization toolbox“Yo shin ski/Deep-Visualization-Toolbox”[40]and our novel central-peripheral rivalry 3D color Gabor filter.The visualization result indicates that most convolutional kernels are similar to some structural central-peripheral rivalry 3D color Gabor filter.
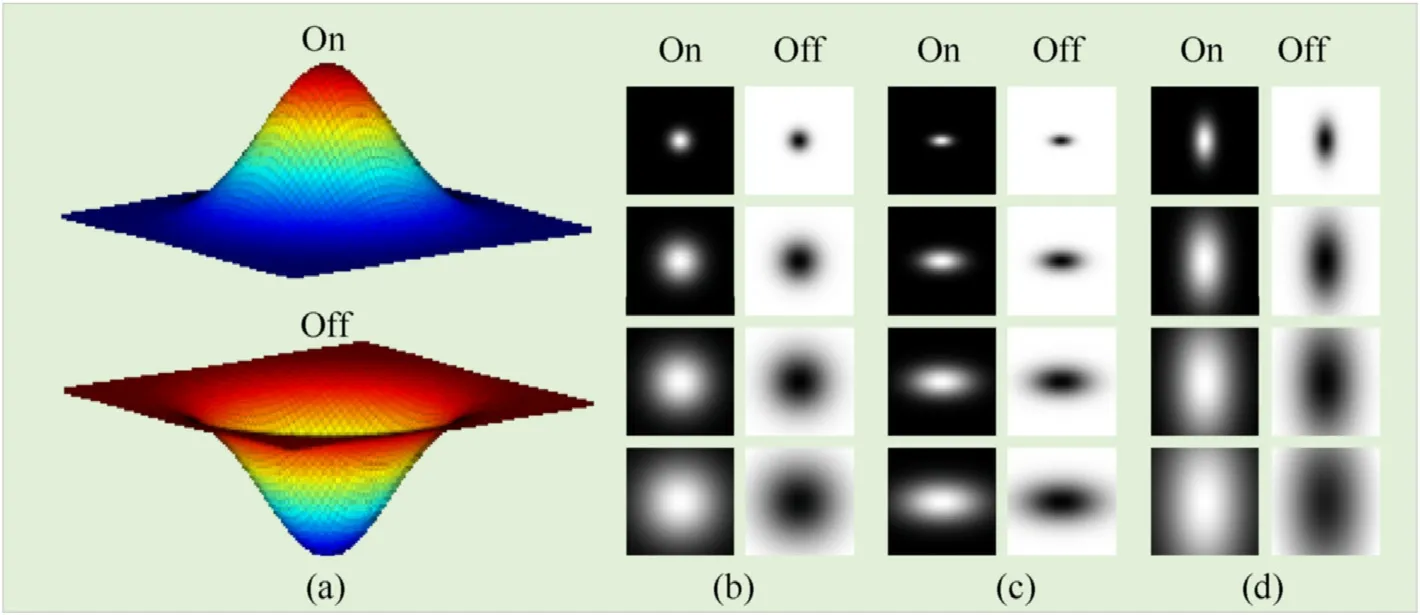
Fig.4.3D and 2D features of improved Gaussian envelopes.On represents center-on type and Off represents center-off type.(a)3D features of improved Gaussian envelopes;(b)2D features of improved Gaussian envelopes with σ=4:4:16,γ=1;(c)2D features with σ=4:4:16,γ=0.5;(d)2D features with σ=4:4:16,γ=2.
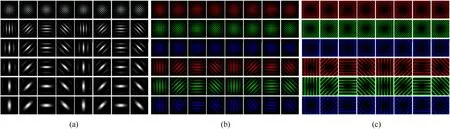
Fig.5.The comparison of traditional 2D Gabor filter and our central-peripheral rivalry 3D color Gabor filter.(a)Traditional 2D Gabor filter;(b)Center-on 3D color Gabor filter;(c)Center-off 3D color Gabor filter.
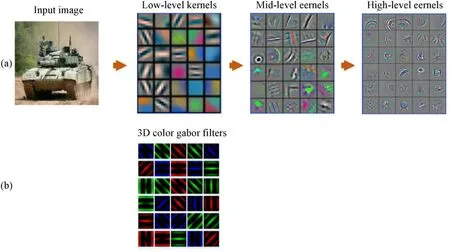
Fig.6.Convolutional kernels of each level by visualizing a pretrained convolutional neural network(CNN)model and 3D color Gabor filters.
Based on the inherent error resiliency of the networks and the similarity between convolutional kernels and 3D color Gabor filters,we introduce Gabor kernels into low-level layers of CNNs,and propose Gabor CNNs to extract the deep features of ground military targets.More importantly,a significant fraction of the computation-heavy components in the training process is eliminated by incorporating highly expression efficient Gabor kernels into CNNs.In order to select the appropriate Gabor filter bank,we design a multi-population genetic algorithm(MPGA)training method to 3D color Gabor filters.The parameters to be optimized include the standard deviation of a Gaussian envelope σ,the aspect ratio of the space γ,wavelength of sinusoidal grating λ and phase shift of sinusoidal grating ψ.The orientations θ are equally spaced.A simple multi-population genetic algorithm is an iterative procedure,which includes three genetic operators,called reproduction,crossover,and mutation.The global error is used as the cost function of MPGA optimization.The MPGA training method is shown in Fig.7.
The MPGA optimization for Gabor convolutional kernels is as follows:
1.A small number of samples are extracted from each class,and the preliminary CNN is trained as the evaluation structure;

Fig.7.The MPGA training method of 3D color Gabor filter bank.
2.An initial populationPwith a constant size 4kis randomly generated.kis the number of Gabor convolutional kernels.Genes of each individual represents the parameters to be optimized;
3.The global error of each initial individual corresponding is calculated;
4.The next generation,including the best individual from the previous generation,is created through reproduction,crossover,and mutation;
5.Each individual in the new generation is evaluated by global error and the best individual are saved;
6.If the search goal is achieved,or an allowable generation is attained,the best individual corresponding to Gabor kernels is returned as the solution;otherwise,return to step 3.
3.4.Gabor region proposal network
The Gabor RPN is used to crop the low-resolution and highresolution region of interests(ROIs)as outputs.In our Gabor RPN,the first component is the shared intermediate convolutional layers.Different from other typical architecture,the low-level layer consists of rivalry color Gabor filters.The Gabor convolutional layer simulates human retina structure and enhance the edges and color features of ground military targets.The original stride of ResNet-50 is 32,which makes the final feature maps are too coarse to tiny targets.We reduce the effective stride to{4,8,16,16}pixels.Besides,ground military targets less than 32×32 or even 16×16 pixels will have been down-sampled to 2×2 or 1×1 in the last convolutional layer,which means that the feature maps are useless for detection and recognition.To address the problem,we use skip connections to guarantee the classifier access to information from features at multiple spatial resolutions,which will especially help detect tiny targets.To deal with different resolutions of feature maps,deconvolution[41]using fixed bilinear interpolation weights and max pooling are used for up-sampling and down-sampling.As shown in Fig.1,down-sampling is operated at layer below the second level layer.Conversely,up-sampling is used above the second layer.For the final fusion features,we use two branches to predict the anchor location and shape like in Ref.[42].The first branch yields a probability map of an object"s center existing at that location.The second branch yields a two-channel map that contains the anchor shape.
For Gabor convolutional layer,we use the same network structure combined with MPGA for training.For each populationPin different generation,the selection of best individual can be expressed as:

whereIndrepresents individual in each population,is the predicted value of thekth sample andykis its label value.
The rest framework is optimized in an end-to-end fashion using a multi-task loss.The jointly loss can be expressed as:
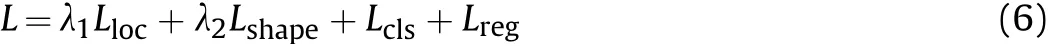
whereLlocis the anchor localization loss,Lshapeis anchor shape loss,Lclsis conventional classification loss andLregis regression loss.In this work,we take Focal Loss[43]asLloc,which can be expressed as:

wherey∈{±1}specifies the ground-truth class andp∈[0,1]is the model"s estimated probability.Lshapecan be expressed as:

where(w,h)and(wg,hg)denote the predicted shape and groundtruth shape of anchor.L1the smooth L1 loss.
Inspired by the ability of the human cognitive system to detect and recognize objects,semantic is helpful to improve performance on detect small objects[24].Semantic is formulated as image evidence beyond the object extent.Fig.8 shows some examples of military targets in ground battlefield.In addition to the features of target itself,the background semantic information surrounding the target may also contribute to target recognition.Such semantics include target cluster,muzzle fire and smoke of target when firing,dust brought by target when moving and so on.All of this environment provides extra information to determine that the detected object is indeed a ground military target.
Since contextual information contributes to the object detection,we except that it will help to effectively detect small military target.We focus on leveraging the semantic information to improve the performance of small targets detection.In Ref.[24],the experiment result shows that semantic context is most useful for small instances,but accuracy for large objects improves little.To balance the efficiency and performance on detection,different strategies are used for large and small objects when using context.Fig.9 shows the different strategies for multi-scale objects detection in our work.
3.5.Refinement generative adversarial network for classification
To further identify ground military targets,we need to classify targets and non-targets area detected by region proposal methods.But the classification accuracy always suffer restriction from poorquality appearance and structure of small targets.Much efforts have been devoted to recognize small objects.Such work can be divided into two main categories.In the first category,the scale of input images is increased to enhance the resolution of small objects and its feature maps extracted from multiple layers.In this method type,increasing the scale of input images often results in heavy time consumption and unpredictable classification.In the other category,network is developed to generate multi-scale representation which enhances high-level small-scale features with multiple lower-level features layers.However,the multi-scale representation constructed by low-level features just works like a black-box and cannot guarantee the constructed features are interpretable and discriminative enough for object recognition[22].We argue that a preferable way to effectively represent the small objects is to discover the intrinsic structural correlations between small-scale and large-scale objects.In this work,we use an improved Generative Adversarial Network to reconstruct clear super-resolution ground military targets from small blurry ones and classify them with each other and non-targets area.
In the seminal work,Generative Adversarial Network(GAN)is introduced to generate realistic-looking images from random noises.GAN learns a generative model via an adversarial training process.In our work,we take low-resolution region of interests,classification labels and high-resolution region of interests as samples to train our refinement GAN.As shown in Fig.10,letG1,G2,…,GnandD1,D2,…,Dnrepresent the generators and discriminators in each iteration respectively.The generators are trained to generate images as close as real data from low-resolution ROIs.The output fake imagesI1,I2,…,Ingenerated by generators are used to fool the discriminators.For each discriminator,its inputs include a fake image and real image.The discriminators are trained to distinguish the real images and the fake image as accurately as possible.With constant adversarial training,final generatorGngenerate a fake image closed enough to the real image and final generatorDnhas enough classification accuracy.

Fig.8.Examples of ground military targets with semantic information.

Fig.9.Different strategies for multi-scale ground military targets detection.(a)for small targets(less than 32px tall);and(b)for large targets(larger than 32px tall).
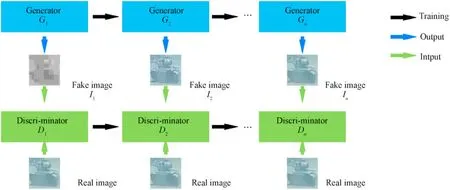
Fig.10.The training process of Generative Adversarial Network.
To address the problems of small targets classification by using reconstruction capability of the GANs,we take small ground military targets as inputs and reconstruct them.We designed a generator networkGαoptimized along with a discriminatorDβ.The generator networkGα directly generates clear 4×high-resolution targets from the small ones.More importantly,our discriminator was improved to distinguish not only real images vs.fake images(generated by generator network),but also the class oftargets.The learning objective for our generator is formulated as:ROIs,our method saves the computational energy of reconstructing high-resolution ROIs.
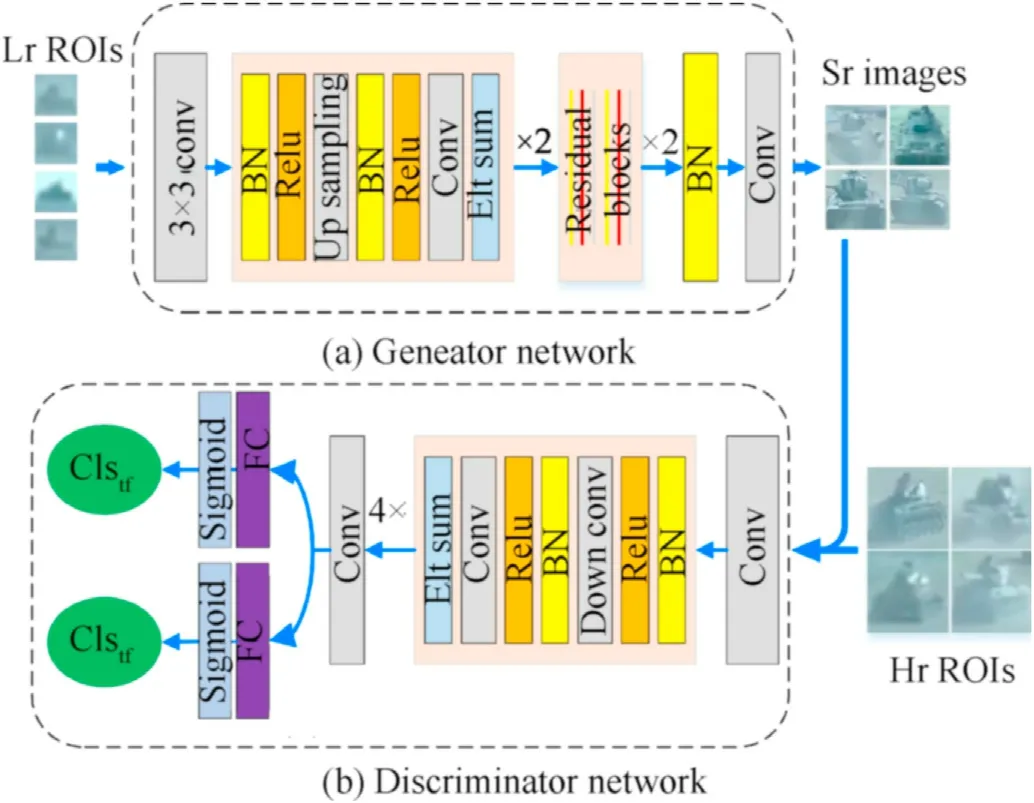
Fig.11.The architecture of the Generative Adversarial Network for ground military target classification.Sr represents the super-resolution targets reconstructed from blurry small ones.Clstf represents the result of true or fake images classification.Clscl represents the result of targets classification.Lr ROI and Hr ROI represent small region of interest(less than 32px tall)and large region of interest(larger than 32px tall)detected by our efficient Gabor region proposal network.FC represents fully connected layer.
4.Experiment
4.1.Dataset for ground military target recognition
At present,public open recognition datasets for general targets have been published,such as Tsinghua-Tencent 100 K[45]and WIDER FACE[46],both of which emphasize small targets.However,such datasets do not contain ground battlefield scene and cannot be used in ground military target recognition.In this work,we built a dataset dedicated to ground military target based on ARTD[39],named Ground Military Target Dataset(GMTD).We selected 3000 ground battlefield scene images from the ARTD for the tank target,randomly.In addition,8036 images are captured by video and game or downloaded from the internet for scout car,transporter and rocket launcher.Like ARTD,each image is normalized to a size of 1024×768 pixels and various battlefield scenes(such as jungle,desert,grassland and city)are included.The graphical image annotation tool LabelImg[47]is used to annotate battlefield scene images in PASCAL VOC format[48].Targets including tank,scout car,transporter and rocket launcher have wide range from 10×10 pixels to more than 700×700 pixels,with an emphasis on small targets.In all the battlefield scene images,8000 images and 20896 targets were randomly selected used as the training samples,while the remaining 3036 images and 9236 targets were used as the test samples.We report the performance for difference sizes of targets,including small targets(size<32×32 pixels),medium-sized tar-

whereIlrdenotes the target candidates with low-resolution,Ihrrepresents the standard targets with high-resolution,andyis the common label ofIlr,Ihr.Unlike[9],the input of our generator is lowresolution images rather than the random noise.Unlike[21],our discriminator distinguishes not only real images vs.fake images,but also the class of ground military targets.Fig.11 shows the architecture of our Generative Adversarial Network for targets classification.In our generator network,a deep CNN architecture,which has shown effectiveness for image super-resolution in Ref.[10],is adopted in the generator.There are two fraction-stride convolutional layers(i.e.,up-convolutional layer)in the generator network.Hence,the generator up-samples low-resolution targets and outputs 4×super-resolution ones.We employ VGG19[44]as our backbone network in the discriminator.There are two parallel fully connected layers in the discriminator.The first fully connected layer output the probability of the input being a real image and the second output the class of targets or non-target areas.The detail architecture of the generator and discriminator network are shown in Table 1.

Table 1The detail architecture of the generator and discriminator network.
In[9],authors normalize the region of interests before reconstruction.Unlike[9],we take different strategies to deal with lowresolution and high-resolution ROIs.In detection process,the lowresolution ROIs are used as inputs to generate super-resolution images in the generator network.The high-resolution ROIs alone and super-resolution images are adopted as inputs of the discriminator.The class of super-resolution images represent the class of low-resolution ROIs.Each class of targets and non-target areas are output by the discriminator.Compared to the normalization of each gets(32×32 pixels<size<96×96 pixels),and large targets(size>96×96 pixels).The numbers of instances corresponding to these three divisions are 4808,3829 and 599,respectively.This evaluation scheme helps us determine the performance of the system for the detection and classification of targets of different sizes.
In the training of improved refinement Generative Adversarial Network(GAN),input samples include low-resolution ground military targetsand their corresponding highresolution ground military targetsand labels.It is difficult to obtain multi-resolution information for the same target in same ground battle scene.Hence,we detect each frame of the video in dataset GMTD and construct 2000 pairs of multiresolution training samples by selecting multi-resolution targets with same spatial position and category.The sample selection process is shown in Fig.12.
4.2.Implementation details
For ground military target detection,we use the pre-trained Resnet50 model[49]to initialize our Gabor region proposal subnetwork.For ground military target classification,we adopt a deep CNN architecture to initialize the generator,which showed effectiveness for image super-resolution in Ref.[24].We employ VGG19[44]as our backbone network in the discriminator.Following[24],we perform down-sampling directly by convolutional layers with a stride of 2.The implementation is based on the publicly available super-resolution GAN[10]and Finding Tiny Faceframework[24]built on the TensorFlow platform[50].The lowresolution ROIs fed into the generator of refinement GAN are normalized to a size of 16×16 pixels to get 64×64 pixels outputs.
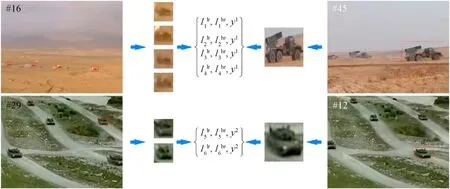
Fig.12.Sample selection process for improved refinement Generative Adversarial Network.
The whole network is trained with Adam,with a momentum of 0.9 and a weight decay of 0.0005,using a single NVIDIA GeForce GTX 3090 GPU with 24 GB of memory.
4.3.Evaluation metrics for detection and classification
As already mentioned,in order to recognize ground military target,we propose a recognition method which includes two components,i.e.,a Gabor RPN and a refinement GAN.In the experiments using our method,we employ the recall,detection accuracy and detection time to quantitatively evaluate the Gabor region proposal sub-network.Recall means the number of samples that are labeled as positive that are actually predicted by the detector,and is formulated as:

wheretprefers to a true positive andfnrefers to a false negative.The relationship betweentpandfnis shown in Table 2.

Table 2The relationship between true positive(tp),false negative(fn),false positive(fp),and true negative(tn).
Detection accuracy is the proportion of the samples that the system has predicted correctly,and is formulated as:

In order to evaluate the GAN refinement sub-network,we compare the deep features of small targets and super-resolved targets and calculated the classification accuracy of each target class.The classification accuracy of theith class of ground military target can be expressed as:

4.4.Performance of Gabor kernels
Commonly,CNN-based feature-extraction is a purely datadriven technique that can learn robust representations from data.Trainable random kernels in CNNs are adjusted step-by-step to the appropriate value through continuous cycle iteration of samples to express the depth characteristics.In this work,we replace shallower convolutional layers with novel central-peripheral rivalry 3D color Gabor filter.In order to demonstrate the training efficiency of Gabor convolutional layers,we conducted an experiment as in Ref.[51]to calculate the energy consumption of the training process.In Fig.13,the pie charts represent a comparison of the energy consumption distributions with and without Gabor convolutional layers across different segments in same model.The energy consumption of the error and loss functions represents a small fraction(~1%)in both cases.The energy consumption of the deep convolutional layer(Conv3~5)and weight update in both cases are the same in training.However,the energy consumption of the shallower convolutional layer(Conv1~2)in the network with Gabor convolutional layers,which is about 1%,is far less than that in the conventional CNN.Of the 9.6%of energy consumption required for the shallower convolutional layer(Conv1~2)in the conventional CNN,8.3%can be saved by using the optimized Gabor convolutional layer,since the Gabor filters do not require gradient computation or weight update.
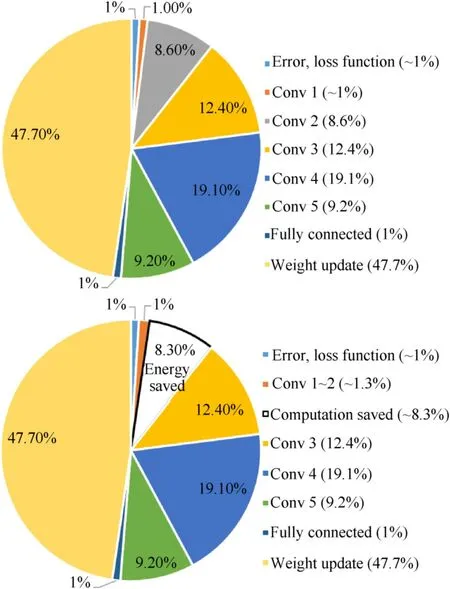
Fig.13.Energy consumption across different segments in the model used in this study,both with(left)and without(right)Gabor convolutional layers.
4.5.Detection performance of Gabor region proposal sub-network
In order to further verify the effectiveness of 3D color Gabor kernels and context fusion for ground military targets detection in Gabor region proposal sub-network,the performance of the three detection methods is compared on small,medium and large targets from the GMTD databases.The details of each method are described as follows:
M1:Region proposal network based on traditional Resnet50 model,which has same structure with our Gabor region proposal network;
M2:The fusion of M1 and context;
M3:Gabor region proposal network.
Table 3 shows the comparison of the average recall on each size between the above three methods.With the increase of groundmilitary target scale,recall rate increases obviously.This shows that the scale of the detection object directly affects the detection accuracy and the space for improving the detection accuracy mainly lies in the small targets.With the diminution of size,the average recall of the first method has a significant decrease.The average recall of second method and our Gabor region proposal network are significantly higher than the first method.This improvement is due to context information that enriches the features of small targets.Moreover,for small and medium targets,our Gabor RPN achieve higher recall rate,which demonstrates the feature-enhancement advantage of 3D color Gabor kernels.
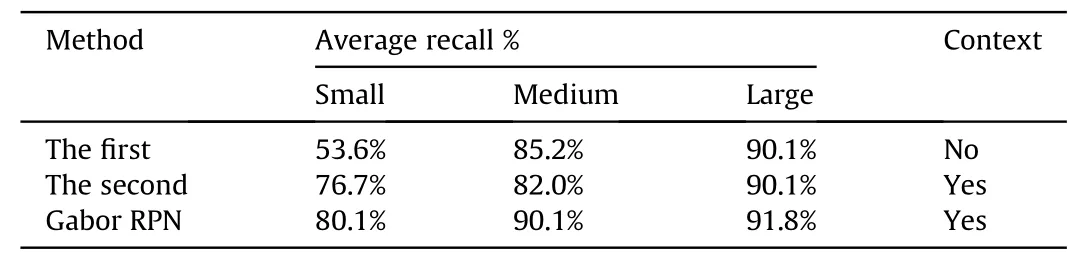
Table 3The comparison of the average recall on each size between the three methods.
To verify the superiority of the Gabor RPN,we compare our approach with other state-of-the-art approaches in terms of the average recall and accuracy of ground military target detection.The results of this comparison are shown in Table 4.It can be observed that the Fast R-CNN and Faster R-CNN perform well for large targets,however their average recall and accuracy for small and medium-sized targets are much lower.Compared with the model of Zhu et al.[45],the proposed Gabor RPN performs well in terms of average recall;the model returned values of 89.2%(vs.84.2%for the model of Zhu et al.),95.4%(vs.91.1%),and 92.0%(vs.88.3%)for small,medium-sized,and large targets,respectively.That is,our Gabor RPN makes a large improvement in average recall over the model of Zhu et al.,i.e.,of 5.0%,4.3%and 3.7%for small,medium and large-sized signs,respectively,demonstrating its superiority in detect smaller ground military targets.However,the improvement in accuracy is not obvious,since the region of interest cropped by the Gabor RPN includes areas without ground military targets,which achieve a larger average recall.The discriminator of the GAN refinement sub-network is used to identify the content represented by the targets,classify regions of interest in detail,and improve the classification accuracy.
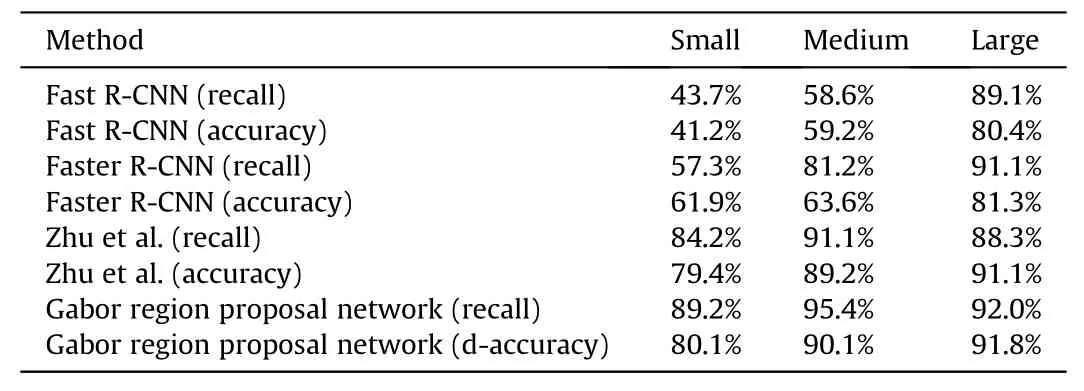
Table 4Comparison of the performance of the Gabor region proposal network used in this study with other state-of-the-art models.
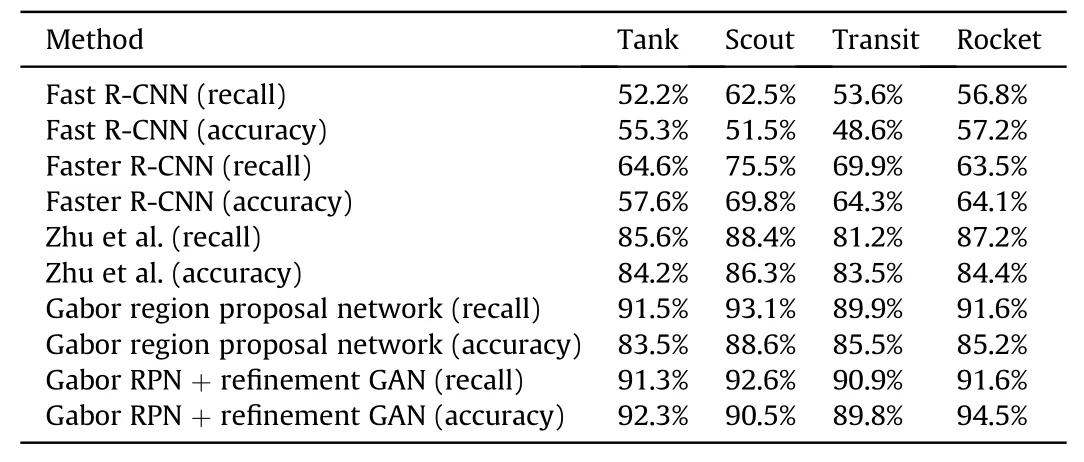
Table 5Comparison of recall rate and classification accuracy for each category of the GMTD dataset(R:recall,A:accuracy).
Comparisons of accuracy-recall curves for different models and different sizes of target are provided in Fig.14.
4.6.Performance of refinement
In order to demonstrate the refinement capabilities of our improved GAN,that is,showing the super-resolution images quality and the difference of deep features between superresolution images and real images,we feed the low-resolution ground military targets into the generator and extract deep features in discriminator for linear combination.Fig.15 shows visualizations of some of the super-resolution ground military targets and its deep features.The first row shows the original small targets.Rows 2,3,and 4 show the super-resolution targets constructed by bicubic interpolation,our refinement GAN sub-network and standard targets,respectively.The deep features of super-resolution targets in discriminator obtained by interpolation and GAN refinement sub-network are shown in rows 5 and 6.The last row shows the deep features of standard targets.By comparing thesuper-resolution targets reconstructed by different methods,it can be seen that the reconstructed targets by the generator in the refinement GAN are closer to the standards than the traditional interpolation method.More importantly,the deep features of targets reconstructed by refinement GAN sub-network resemble features of standard targets better,which is beneficial to the classification network.One can conclude that the generator successfully learns to transfer poor representations of small targets to super-resolution representations similar to those of large ones,validating the effectiveness of the refinement GAN sub-network.

Fig.14.Comparisons of the overall detection performances of various models for small,medium-sized,and large ground military targets using the GMTD dataset.RPN refers to region proposal network.

Fig.15.Visualizations of part super-resolution ground military targets and its deep features.

Fig.16.The processing time comparison in detection and classification.
4.7.Analysis of processing time consumption
Our ground military target recognition method including two steps:detection and classification.Correspondingly,the processingtime of our method including the time of cropping the lowresolution and high-resolution region of interests(ROIs)by Gabor region proposal sub-network and the time of ROIs reconstructed and classified by refinement generative adversarial sub-network.In order to demonstrate the balance between efficiency and ability to detect small objects of our method,we compare the average processing time of using M2 with our method(Gabor RPN+refinement GAN).We also analysis the average processing time of each steps of our method.Fig.16 shows the processing time comparison.As shown in Fig.14,the average detection time of our method is 371 ms and the time of method2 is 393 ms.Our Resnet50-based detector runs at 2.7FPS on 1024×1024 pixels image.Compared with detection time,the time of refinement and classification in our method is little.The reason is that in ground military targets detection,the Gabor RPN dealing with whole ground battlefield scene images.While refinement and classification,the GAN reconstruct the low-resolution ROIs and classify highresolution ROIs and reconstructed super-resolution images.The number of ROIs in same scene is generally 5 to 7 with few pixels.In summary,the rate of our method can meet the actual requirements.More importantly,our method has stronger recognition ability for small targets.

Fig.17.Examples of ground military target recognition results obtained by different methods.(a)for Fast R-CNN;(b)for Faster R-CNN;(c)for method in Zhu et al.;and(d)for our method.
4.8.Overall performance of recognition method
In order to demonstrate the advantages of the refinement GAN and our recognition method,the recognition performance of popular recognition methods and our ground military target recognition method in each class is compared on the GMTD dataset.Table 5 shows the comparison results of recall rate and classification accuracy for each category of the GMTD dataset.Our approach achieves the best performance in most categories in which small signs are most common and the accuracy is improved obviously,especially when the refinement GAN is added.
Some examples of the recognition results are shown in Fig.17.Columns 1 and 2 show the recognition results of Fast R-CNN,Faster R-CNN respectively.columns 3 shows the recognition results of the method in Ref.[45],and columns 4 shows the recognition results of our ground military target recognition method.It can be seen from the first column of result that both traditional method and our ground military recognition method can detec and classify largescale target in ground battlefield.However,traditional recognition methods failed to deal with small-scale target shown in row 2 to 4 of the figure.Through the reconstruction of low-resolution targets based on refinement GAN and effective detection based on Gabor RPN,Our ground military target recognition method has obvious advantages in dealing with small-scale targets.Such recognition results make our method benificial to the actual military application.
5.Conclusions
In this work,a novel visual-simulation region proposal and generative adversarial network based method is proposed to address the open challenge of ground military target recognition in real-life situations.The method includes two components,i.e.,a Gabor region proposal sub-network and a refinement generative adversarial sub-network,which are used to address detection and classification problems,respectively.In the Gabor RPN,novel central-peripheral rivalry 3D color Gabor filters are proposed to simulate the structure and imaging mechanism of retina and introduced the filters into low-level layers of CNNs to enhance the deep features of targets.According to the fusion attention feature,we designed two branches to predict the shape and position of the target respectively.In the refinement generative adversarial subnetwork,a generator,which is pretrained to directly reconstruct clear 4×super-resolution images from small blurry ones,is used to eliminate the poor-quality appearance of small targets.A discriminator,which is improved to be able to distinguish not only real images vs.fake images(reconstructed by the generator network)but also the class of targets,is used to classify the targets finally.Extensive experiments have demonstrated the effectiveness of training-efficient Gabor convolutional layers,the superiority of the Gabor region proposal sub-network for ground military target detection,and the superiority of the GAN refinement sub-network for ground military target classification.In the future,we will focus on unifying Gabor RPN and refinement GAN into a single featureextraction process to improve system efficiency and expand the target categories in GMTD.
Funding
This work was supported by the National Key Research and Development Program of China(No.2016YFC0802904),National Natural Science Foundation of China(No.61671470),Natural Science Foundation of Jiangsu Province(BK20161470).
Declaration of competing interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
杂志排行

Defence Technology的其它文章
- Defence Technology
- The SSA-BP-based potential threat prediction for aerial target considering commander emotion
- Preparation and characterization of HMX/NH2-GO composite with enhanced thermal safety and desensitization
- Interception probability simulation and analysis of salvo of two electromagnetic coil launched anti-torpedo torpedoes
- Damage behavior of the KKV direct hit against fluid-filled submunition payload
- Formation of adiabatic shearing band for high-strength Ti-5553 alloy:A dramatic thermoplastic microstructural evolution