基于主题模型的胶囊内镜图像序列筛查
2022-11-24农桂仙胡怀飞刘海华
农桂仙 潘 宁 陆 恒 胡怀飞 刘海华*
1(中南民族大学生物医学工程学院,武汉 430074)
2(医学信息分析及肿瘤诊疗重点实验室,武汉 430074)
3(东部战区总医院消化内科, 南京 210002)
引言
消化道疾病,特别是下消化道疾病,由于早期症状不明显,且缺乏普适的检测手段,对公众健康造成极大威胁。无线胶囊内窥镜(wireless capsule endoscopy, WCE)的出现,为肠道疾病可视化诊断提供了有力的工具[1-3]。由于利用WCE 检测会产生大量的图像(每病例约5 ~8 万幅),因此,为了提高疾病诊断效率,很多学者提出基于人工智能的计算机辅助诊断方法[4-8]。而这些建议的方法大多忽视了图像序列中气泡和杂质等干扰图像对疾病诊断的影响。据统计,每例WCE 图像中,气泡和杂质等干扰图像约占总量的25%[9],而具有组织异常病变的图像仅占5%左右[10],这给基于人工智能的疾病诊断带来极大困扰。因此,开展对WCE 图像序列中干扰性图像(气泡和杂质图像,其它图像称为正常图像)自动筛查方法的研究,有利于提高临床上计算机辅助诊断的性能和效率。
针对干扰性图像筛查,已有学者提出了一些方法[9,11-15]。如,Shipra 等[11]提出在HSV 颜色空间下,利用Canny 算法和分水岭算法对图像进行分割,并以边缘像素总数与最终的区域像素总数的比例确定该区域是否为气泡。这些方法主要根据气泡的颜色和纹理特征,通过设置相关阈值,对图像中的气泡进行分割和检测。这种基于传统特征的气泡图像检测方法通常不稳定且普适性较差,误检和漏检的可能性较大。另外,对于WCE 杂质图像的自动检测方法目前很少有报道。因此提出了基于深度学习的WCE 特征提取,并结合主题模型,对气泡和杂质图像自动筛查的方法。
WCE 图像序列中气泡和杂质等干扰图像,主要是指在图像中气泡和杂质占据图像较大面积的图像(见图1),其语义信息非常明显。因此,通过语义分析获取气泡和杂质图像语义特征,从而实现对气泡和杂质图像自动筛查。目前,语义分析方法被大量用于自然图像分类中[16-20]。其中,主题模型是一种用于语义分析的工具[21],目前最常用的主题模型有基于贝叶斯估计的pLSA[22]和LDA[23]。基于此,一些学者将主题模型应用于WCE 图像序列的分割[24-25],以获取胶囊内镜图像序列中不同部位的关键帧。此外,Yuan 等[26]基于颜色和纹理描述符,通过pLSA 模型对WCE 图像中的多种异常进行分类。然而,基于人工设计的传统特征描述算子往往不能有效描述WCE 图像。为此,提出通过卷积自编码的方法获取图像特征,并利用pLSA 模型对WCE 图像序列中气泡和杂质等干扰图像筛查的方法。
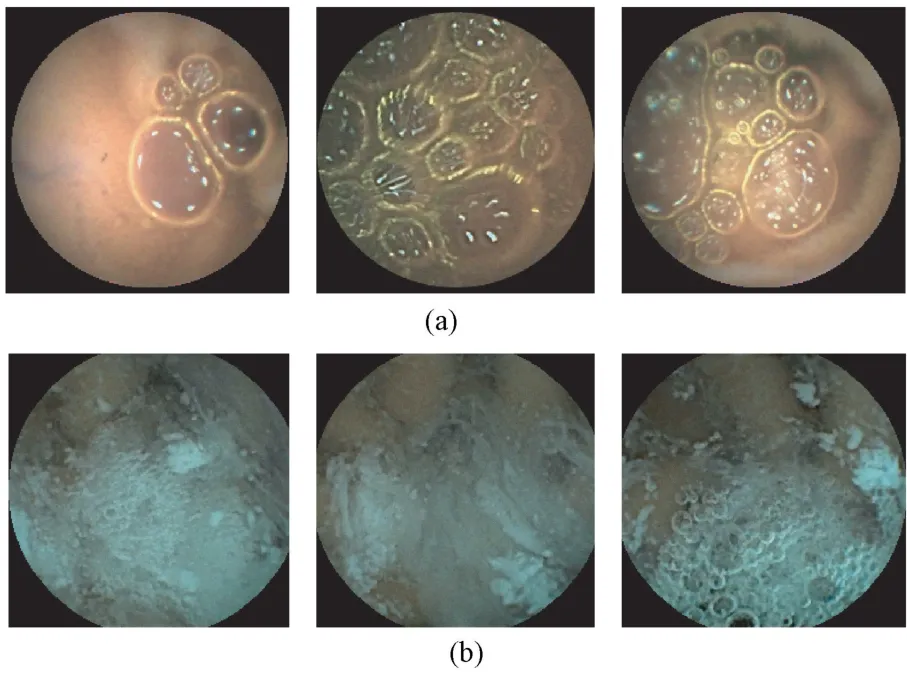
图1 胶囊内镜序列图像。(a)气泡图像;(b)杂质图像Fig.1 Wireless capsule endoscopy sequence images.(a)Bubble images; (b)Impurity images
1 材料和方法
本研究提出一种基于主题模型的WCE 图像语义分析算法,从而筛查WCE 图像序列中的气泡和杂质图像。该算法主要分为3 个部分:视觉单词构建、词频统计和主题分析,如图2 所示。首先,视觉单词的构建。在训练集的每幅图像中随机提取一定数量的图像块(patch),通过卷积自编码器提取图像块特征,利用K-Means 算法对图像块特征进行聚类,从而构建视觉单词。其次,词频统计。从测试集中每幅图像有规律地获取图像块,并提取图像块特征,然后根据图像块的特征,判断其与视觉单词的距离,以最小距离将图像块特征划入某一类视觉单词中,从而得到测试集的各幅图像中的视觉单词分布。最后,利用主题模型(pLSA/LDA),对测试集的词汇分布数据进行拟合,获得每幅图像中各个主题的概率分布,以图像中最高概率主题对图像进行分类,从而筛查WCE 图像序列中的气泡和杂质图像。
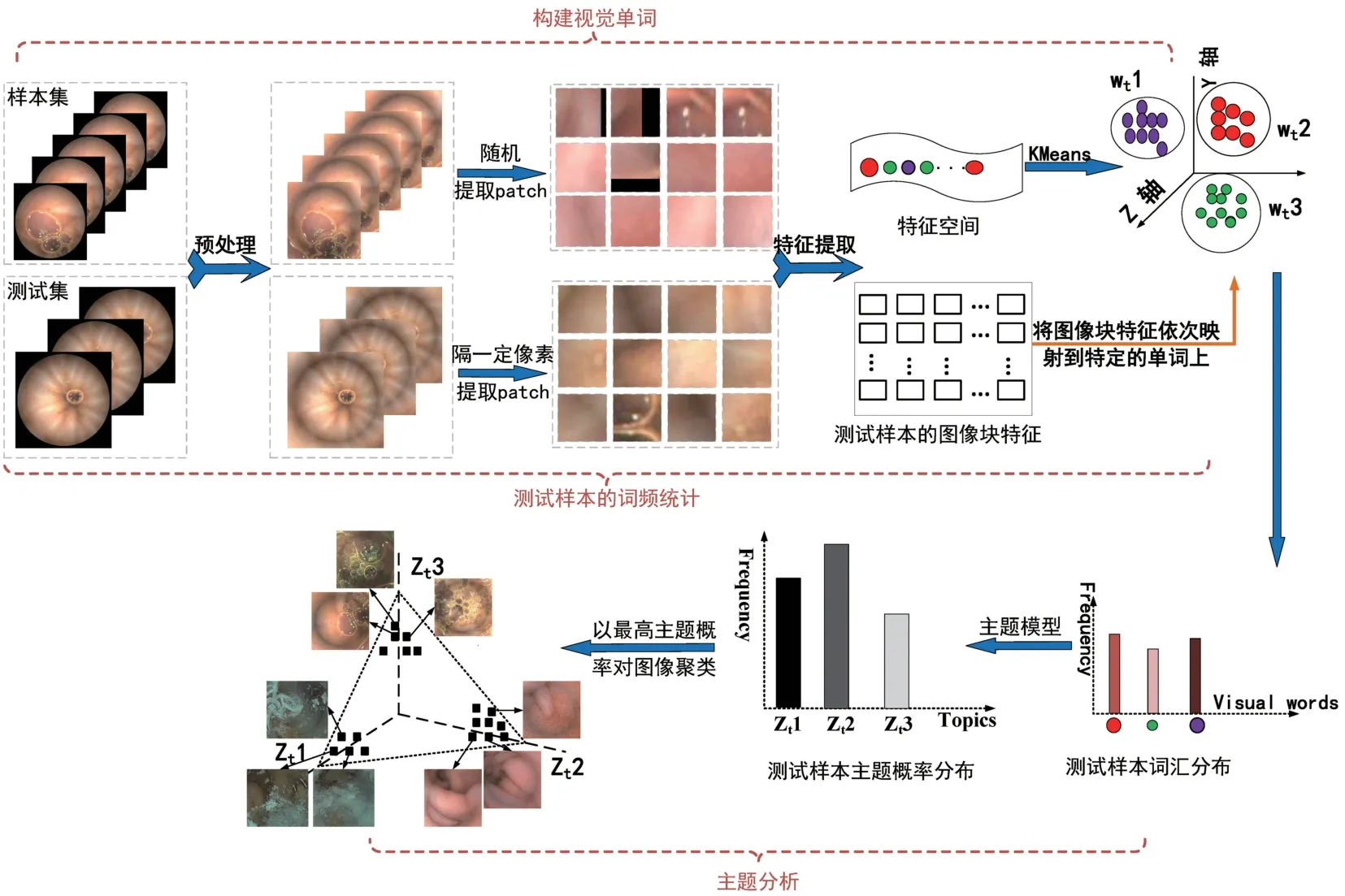
图2 胶囊内镜图像场景分析算法Fig.2 The scene analysis algorithm of capsule endoscopy images
1.1 特征提取
卷积自编码器的结构和传统自编码器相似[27-28],包括一个编码器和一个解码器。对于输入x,传统自编码器可以通过编码函数f(x) 得到编码数据h,解码器通过解码函数g(h) 将编码数据h重构输出y。而卷积自编码器是采用卷积层代替传统自编码器的全连接层,即将权重矩阵与输入、输出的内积变成了卷积操作,其编码和解码的函数表达式分别由式(1)和式(2)定义,有
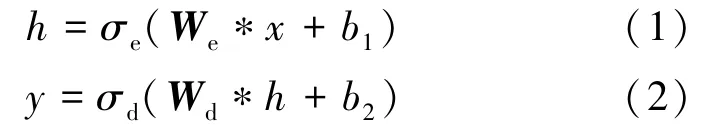
式中,σe和σd分别表示为编码器和解码器的激活函数;We和Wd为权重矩阵;b1和b2为偏置项; *为卷积操作。根据任务和所需要达到的目标,卷积自编码器会自动学习训练样本的特征,将WCE 图像块实现在低维空间上的特征表达,其结构如图3所示。图中卷积自编码器网络由一个编码器和一个解码器组成,为非完全对称的结构,其编码器和解码器中的卷积层数量、通道数存在差异。编码器第一层采用一层标准3×3 卷积,输入为3 通道的RGB 图像,输出通道为64。然后,借鉴VGG16 的结构,构建2+3+3 的卷积模块(2、3 表示该模块的卷积层数量),每个模块后接一个下采样操作,将特征图尺寸减半。编码器总共包含3 次下采样操作,最终将图像块尺寸压缩到原始图像块的1/23。最后,使用一层卷积将通道数压缩为16。
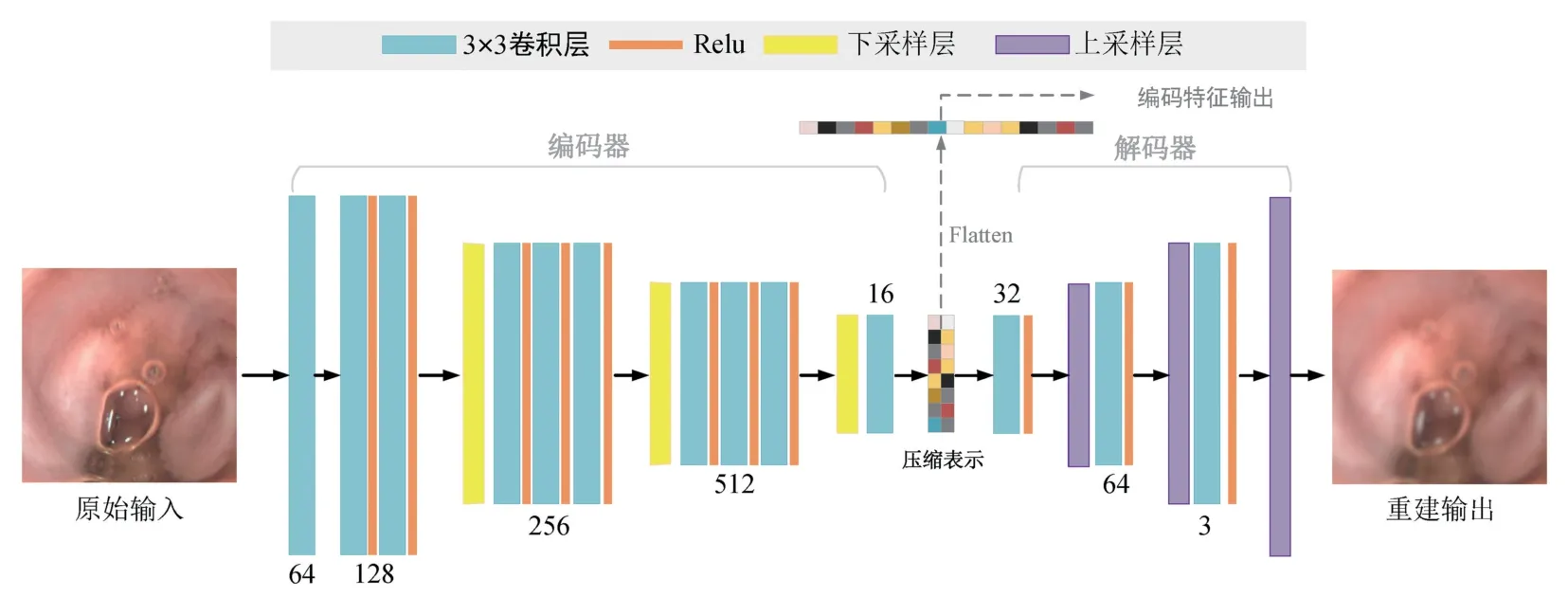
图3 卷积自编码器网络Fig.3 Convolutional auto-encoder networks
为了提高网络编码部分的能力,编码部分采用复杂结构,但解码部分采用简单结构,即在每个相同的特征图尺寸下的模块结构均只包括卷积层、激活层和上采样层,经过3 层上采样将压缩图像重构输出到原始图像块大小。卷积自编码器在训练过程中,完全对称结构主要实现从数据输入到输出的重构,主要关注编码能力和解码能力。而在此主要关注网络的编码能力,复杂的编码结构可以学习到图像更深层次的特征,通过简单的解码结构有助于编码部分生成更具有代表性和鲁棒性的特征。
在训练阶段,将胶囊内镜图像块输入图3 的卷积自编码网络中,目标函数采用L1(平均绝对误差)损失,有

式中,Xi、Yi分别表示网络的第i个图像块输入和输出。‖·‖1表示L1范数。网络训练时采用Adam优化器[29],其中一阶矩和二阶矩指数衰减率设置为β1=0.9,β2=0.999,数值稳定常数ε=10-8。
为了后续构建视觉单词,将编码器提取的图像特征进行矢量化。假设编码器获取的特征图尺寸为W ×H ×c,这里W和H为压缩后的图像块大小,c为通道数。将这些特征图展平,形成长度为W × H×c的一维特征矢量,用于下一步的构建视觉单词和词频统计。
1.2 视觉单词构建和词频统计
由于所获取的图像块的特征不能直接作为视觉词汇使用,因此需要根据图像块特征矢量之间的相似度,将相似的图像块特征进行聚类,从而用有限类的特征表达一定的视觉含义,即构建视觉单词。设包含了杂质、气泡和正常图像在特征空间的样本特征集为X ={x1,x2,x3,…,xn},利用K-Means聚类算法[30],将样本划分为C1,C2,…,Cm, 共m类。为了简单起见,将每类Cj在特征空间中的均值矢量作为视觉单词wj,有

式中,Nj为Cj中特征矢量xi的个数。因此,在图像特征空间中构造了由m视觉单词组成的字典。
视觉单词模型主要用于构建表达这类图像所需的词汇。而对于这类图像的每张需要测试的图像而言,就需要分析其包含不同视觉单词的情况,其分析步骤如图2(b)所示。首先从测试图像分割大小相同的图像块(尺寸与上述视觉单词构建的块大小一致),然后由卷积自编码网络获取图像块的特征矢量。设每幅测试图像提取的图像块特征矢量为y1,y2,…,yp,其中p为图像块数量,且为常数。然后,计算每个特征矢量yi与每个视觉单词之间的距离,即计算wj与yi的欧式距离EDij,有

在此基础上,根据距离最近原则标注不同特征矢量隶属于不同的视觉单词,即
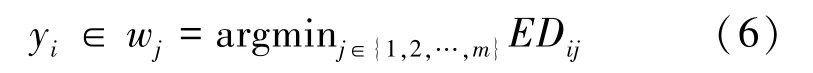
为此,可获得每幅图像d中图像块特征所属不同视觉单词wj的分布情况,即词频统计矢量v∈Rm,其中每个元素为图像d中视觉单词wj出现的频数n(d,wj) 。设图像测试集由l幅图像构成,即D ={d1,d2,d3,…,dl},则所有测试图像词频统计情况构成混合矩阵Λ ={v1,v2,…,vl}∈Rl×m,其中该矩阵每列就是每幅图像词频矢量v, 矩阵中每个元素Λij =n(di,wj) 为图像di中出现wj的频数。
1.3 主题分析
根据图像视觉词汇分布矩阵,采用pLSA 主题分析模型检测WCE 序列中气泡和杂质图像。假设胶囊内镜图像的语义对应于模型中的潜在变量z∈Z{z1,z2,…,zk},为不可观测变量;所给的WCE 序列图像d∈D{d1,d2,…,dl} 对应模型中的文档,文档中所包含的词汇对应于所构建的视觉单词w∈W{w1,w2,…,wm},D和W为可观测变量。通过构建视觉单词和词频统计(详见1.2 节),将测试集表达为元素为Λij =n(di,wj) 的矩阵。由此,可以通过图像和单词的联合概率分布对图像主题混合概率p(di |zk) 和各个场景主题下的视觉单词分布p(wj |zk) 进行拟合估计,pLSA 的联合概率分布为

式中,p(z) 为先验值,通常将其设置为p(z)=1/k,可以使用期望最大(expectation-maximization, EM)算法对模型参数进行估计[21]。
首先,计算期望步骤,即E步,计算潜在变量的后验概率p(zk |di,wj),需要初始化模型参数p(di |zk) 和p(wj |zk),并计算期望函数L的值。其中,后验概率计算公式为
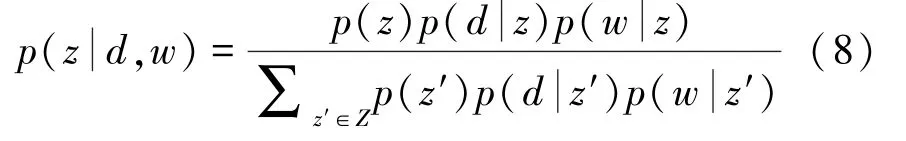
然后,最大化步骤,即M步,通过最大化期望函数L来更新后验概率p(di |zk) 和p(wj |zk),参数更新结果的好坏在一定程度上依赖于参数初始化,L函数为

研究中给定图像的主题数k,通过图像-视觉单词的混合矩阵拟合出图像主题概率p(di |zk),以最高主题概率对WCE 图像进行分类。
1.4 实验设计
1.4.1 数据来源
所使用的WCE 图像来源于南京东部战区总医院的消化道内科,且图像数据集中的气泡图像、杂质图像由临床经验丰富的医生进行注解。该图像数据集由10 000幅240 像素×240 像素的图像组成,且来自于20 例不同患者的WCE 图像序列,其中气泡图像,杂质图像和正常图像分别为3 340、3 330、3 330 幅。在实验过程中,将数据集中的各类图像按照1 ∶1的比例分为训练集和测试集,且根据交叉验证的方法评估所提出方案的筛查效果。
1.4.2 评价指标
为了从数据集中筛查杂质和气泡两类图像,主要使用准确率( Acc)、误检率( Mis)、查准率( Pre)和召回率( Rec) 来评价所用方法的性能,即:

式中,TP 表示正样本被正确识别为正样本数, TN表示负样本被正确识别为负样本数, FP 表示负样本错误识别为正样本数, FN 表示正样本被错误识别为负样本数。
2 结果
2.1 参数选择
在所提出的筛选方法中涉及到多个参数,如图像块尺寸、视觉词汇(单词)数以及主题数3 个参数等,这些参数设置会影响最终的分类结果。为此,依据WCE 图像的纹理特点,通过实验分析来选择合适的相关参数值。需要注意的是,在实验分析某个参数时,其它参数保持不变。
1)图像块大小:由于气泡和杂质图像语义上非常明显,结合所采用的卷积自编码器的特点,因此图像块尺寸选取稍大且为8 的倍数,如: 24×24,32×32,40×40,48×48,56×56。实验采用卷积自编码器提取特征,在pLSA 模型上进行分类,视觉单词数和主题数分别为35 和12,实验结果如图4 所示。从图4 中可以看到,当图像块尺寸增大时,pLSA 取得的分类性能越好,但当图像块尺寸大于40×40 时,分类性能呈下降趋势。其中,图像块尺寸为56×56 时,模型分类结果略小于图像块尺寸为40×40 的结果,而图像块尺寸越大,计算量越大。因此,在后续的实验中,图像块尺寸固定为40×40。
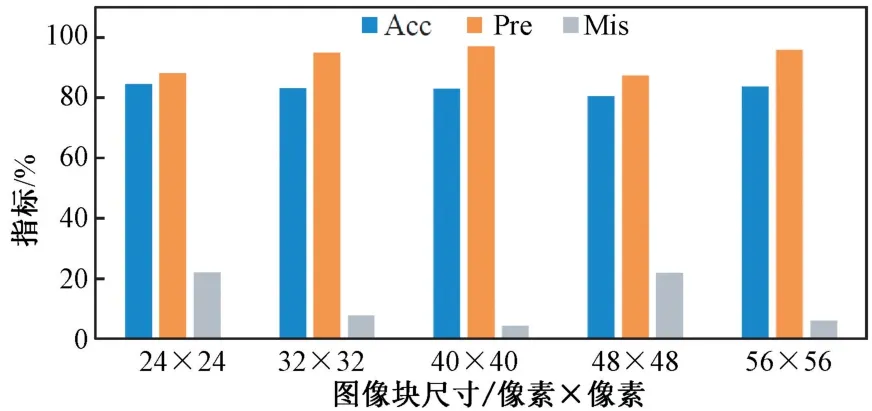
图4 不同图像块尺寸的实验结果Fig.4 The results of different image patch sizes
2)视觉词汇数和主题数:采用卷积自编码器和传统的特征提取方法,分别在不同视觉词汇数以及不同主题数的条件下进行实验,其中,传统的特征提取方法包含LBP、HOG、SIFT 以及HSV 颜色空间,实验结果如图5 和图6 所示。图5 为主题数为12的情况下,pLSA 模型在不同视觉单词数下的气泡图像、杂质图像和正常图像的分类结果。从图中可以看出,卷积自编码器(C-AE)的特征提取方法在不同的视觉单词数下所获得的分类性能最优,且在单词数为35 时分类准确率( Acc)最高。

图5 不同视觉词汇大小对分类准确率的影响(pLSA 模型)Fig.5 The effect of different visual vocabulary sizes on classification accuracy(pLSA)
针对不同的主题模型:pLSA 和LDA,固定视觉单词数为35,选择最佳的主题数。从图6 可以看出,当两者主题数分别为12 和18 时,分类准确率最高,当两者的主题数分别大于12 和18 时,准确率呈小幅度下降趋势。根据上述实验,将视觉单词数设置为35,pLSA 模型和LDA 模型的主题数分别设置为12 和18。

图6 不同模型中,不同主题数对分类准确率的影响。(a)pLSA 主题模型;(b)LDA 主题模型Fig.6 The effect of different number of topics on classification accuracy. (a) pLSA; (b) LDA
2.2 实验结果
采用2.1 节的参数设置,即视觉单词数为35,pLSA 主题数为12,LDA 主题数为18,对数据集进行10 次随机划分,进行气泡和杂质图像的筛查实验与分析,实验结果取10 次划分的均值。
首先,针对不同特征提取方法,即HSV、HOG、LBP、灰度SIFT 和卷积自编码器,对分类结果的影响进行实验,结果如表1 所示。从表1 可以看出,无论是pLSA 还是LDA 模型,卷积自编码器特征提取方法较传统特征提取方法所取得干扰图像筛查性能高,即较高准确率、较高的查准率和较低误检率。虽然HOG 特征提取方法,特别是RGBHOG 也能获取比较好的查准率和误检率,但如表2 所示,卷积自编码器的召回率( Rec)更高。
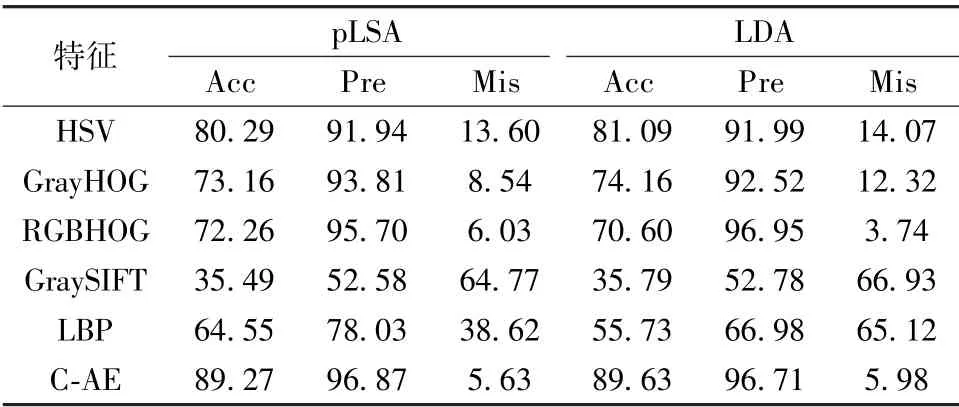
表1 pLSA 和LDA 中不同特征提取方法的分类结果(%)Tab.1 The results of different feature extraction methods in pLSA and LDA (%)

表2 C-AE 和RGBHOG 的召回率(%)对比Tab. 2 The comparison results ( Rec/% ) of C-AE and RGBHOG
其次,针对不同主题模型的性能也进行了实验评估。将pLSA、LDA 与传统的截断奇异值分解(TSVD)进行对比,在相同特征提取方式(C-AE)和实验参数设置(视觉单词数为35,主题数为12)的情况下,实验结果如表3 所示。从表中可以观察到,相较于传统TSVD 分析方法,pLSA 和LDA 更适用于图像语义分析。而在这两个主题模型中,当处于pLSA 最佳主题数时,LDA 的准确率仅次于pLSA。为了进一步讨论这两个模型的性能,在相同实验参数设置下,将主题数设置为LDA 的最佳主题数,即18,分别进行实验,实验结果如表4 所示,由表4 可见,在LDA 模型取得最好分类效果的主题数下,pLSA 模型取得了较好的分类性能。由此可见,pLSA 模型更适用于的分类任务。
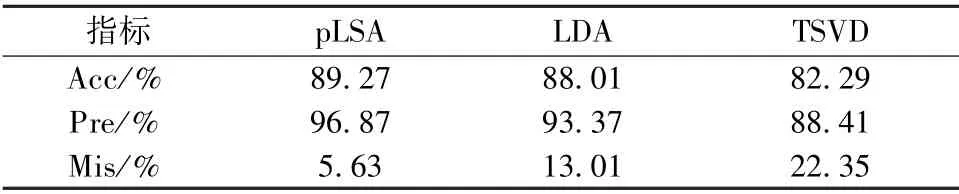
表3 不同主题模型的分类结果Tab.3 The results of different topic models

表4 pLSA 和LDA 的分类结果Tab.4 The results of pLSA and LDA
3 讨论
针对WCE 图像过多,影响疾病诊断效率,大多方法只是针对疾病进行区域检测,如文献[7]和[8],这些方法忽略了干扰图像对疾病检测的干扰。当气泡和杂质占图像四分之一以上时,会对疾病诊断造成很大干扰。参考Sivic 等[16]提出将主题模型用于WCE 图像语义分析,利用图像语义筛查WCE 图像中的干扰数据。在文献[16]中,以自然场景图像的尺度不变换特征构建视觉单词,由于胶囊内镜场景复杂,传统特征不稳定,可能会导致视觉单词无法充分表达图像内容,影响图像语义分析。因此,采用卷积自编码器提取WCE 图像块特征来构建视觉词汇,通过主题模型获取图像语义概率,根据语义概率分布来筛查WCE 图像的干扰数据。大量实验证明,通过非对称卷积自编码和主题模型对胶囊内镜图像语义进行分析,能有效筛查出胶囊内镜干扰数据,且获得比传统特征更好的分类性能。
在建议的气泡和杂质图像检测方法中,视觉单词是语义特征的集合,通过这些视觉单词可实现对图像内容的表达,从而使主题模型易于分析出图像语义。由此可见视觉单词的构建直接影响分类结果。然而,影响视觉单词构建的因素很多,主要包括两个方面:图像块尺寸和图像块特征。从图像块尺寸角度来看,块尺寸过小,则局部特征表达不充分;反之,块尺寸过大,局部特征抽象,细节不明显,依然会造成局部特征表达不充分,影响视觉单词构建的质量,从而影响分类性能。这一点可以从图4的实验结果中看出。在3 个评价指标上,分类性能随着图像块尺寸的增加整体呈现先上升后下降的趋势,且当块尺寸为40×40 时,分类性能最优。
从图像块特征角度来看,稳定、鲁棒的特征能构建具有代表性的视觉单词。因此,特征提取方式尤为重要。在特征提取方式的选取上,如表1 的实验结果所示,相较于HSV、GrayHOG、RGBHOG、LBP、GraySIFT 等传统特征提取方法,通过卷积自编码器网络提取的特征获得更好的分类效果和稳定的分类性能,在pLSA 模型上,其准确率和查准率分别最大可提升2.5 倍和1.8 倍、误检率最小可降低11.5 倍(较于GraySIFT)。而在自然图像场景语义分类任务中取得较好结果的SIFT 特征在本研究中效果不理想,反之,HOG 特征在研究中体现出了具有竞争力的分类性能,但准确率较低,漏检较多。其原因可能是卷积自编码器通过深度学习方式获得的特征更具普适性,有利于视觉单词构建。HOG方式虽然可以获得丰富的图像特征,但同时也包含了不必要的信息,导致构建出的视觉单词不足以表达图像语义信息。
不同的主题模型也影响分类结果。针对pLSA[22]、LDA[23]和TSVD 等3 种主题模型,在3 种指标,即准确率、查准率、误检率上,pLSA 均获得最优的性能表现,特别是其误检率低2 ~4 倍(相较于LDA 和TSVD)。筛查气泡和杂质时,相较于LDA模型,pLSA 模型取得较高的精度和较低的误检率,分别为96.87%、5.63%。然而,在分类过程中,分类结果会随着词汇数产生较大波动性。可能的原因是:其一,在构建视觉单词时,Kmeans 聚类算法实际应用中属于半监督算法,需要人为指定聚类个数,带有一定的主观性;其二,主题模型的分析结果也依赖于模型参数初始化。后续的研究中将重点构建稳定准确的视觉单词模型以及解决主题模型初始化问题,以提高胶囊内镜冗余数据筛查准确率,降低词汇大小对分类结果的影响。
4 结论
针对WCE 序列中干扰图像比较多,语义明显以及传统筛选方法普适性较差的问题,提出基于主题模型的WCE 图像语义分析方法,用于干扰图像筛查。该方法首先通过卷积自编码器获取WCE 图像局部特征,然后利用K-means 聚类算法对局部特征矢量进行聚类,从而构建视觉单词,并以此获取图像的词频矩阵,最后通过主题模型对词频矩阵进行主题分析,获取图像的语义分类。研究结果表明,该方法能有效筛查WCE 干扰图像,且通过卷积自编码器可以更有效地获取WCE 图像局部特征,提高图像筛查性能。在后续的研究中,将结合深度学习和语义分析的方法,从而进一步提升算法筛查性能。
