基于卷积神经网络和近红外光谱的茶叶品种和等级鉴别
2022-11-24圣阳,焦俊,滕燕,马鑫,李春,蒋玲*
圣 阳, 焦 俊, 滕 燕, 马 鑫, 李 春, 蒋 玲*
(南京林业大学信息科学技术学院,江苏南京 210037)
茶叶不仅具有很高的经济价值,而且茶叶中富含茶多酚、氨基酸、咖啡碱等物质[1],有益人体健康,深受消费者的喜爱。不同品种和等级的茶叶在价格上相差巨大,市场上茶叶销售以假乱真、以次充好的现象时有发生[2]。感官评审法通过对茶叶外形、汤色、香气、滋味等方面对茶叶品种和等级进行鉴别[3],但是这种方法主观因素影响大,缺乏准确性。理化方法主要用于茶叶内部成分的检测[4],主要有气相色谱[5]、液相色谱[6]等方法。这些理化方法不仅检测成本高,而且测试周期长、操作复杂、专业性要求高,所以急需对茶叶品质实现快速、无损、低成本检测[7]。
近红外光谱(Near Infrared Spectroscopy,NIRS),波长范围在780~2 500 nm[8],可以用于含氢基团物质的定性定量检测,具有快速、无损、简单的特点[9]。目前已有学者将近红外光谱应用于茶叶检测相关领域,实现对茶叶品种[10]、产地[11]、等级[12]和是否发生霉变[13]的鉴别。目前大多采用主成分分析法(Principal Component Analysis,PCA)进行光谱特征提取,降低模型的复杂度,但PCA仅从数据方差最大的方向对数据进行压缩[14],没有考虑到近红外光谱的实际物理特征,降维后的数据丢失了光谱的原始信息,模型的可解释性低。而联合区间偏最小二乘法[15](synergy interval PLS,siPLS)、连续投影算法[16](Successive Projections Algorithm,SPA)、竞争性自适应重加权算法[17](Competitive Adaptive Reweighting Algorithm,CARS)可以在保留原始光谱信息的基础上,实现对光谱的特征提取,在实际应用中可以仅对特征波长附近的光谱数据进行采集,提高检测的效率。Ren等[18]采用PCA+SVM方法快速分析评价红茶的品质,并区分红茶产地,鉴别不同产地红茶地理起源,准确率达94.3%。Meng等[19]利用PCA+BP-ANN对福建三个品种的茶叶样品进行鉴别,识别准确率达到95.6%。
卷积神经网络(Convolutional Neural Network,CNN)具备局部感知,权值共享的特点[20],模型的运行效率较高,从而被广泛应用在计算机视觉,自然语言处理,语音识别等领域。近年来有学者利用近红外光谱与卷积神经网络相结合检测夏威夷果[21]、烟叶[22]、花椒[23]等,对在茶叶品种和等级的鉴别还少有文献报道。使用机器学习或者深度学习模型通常需要大量的样本数量保证模型的准确性和稳定性,而采集大量的光谱数据需要很高的成本,可采用数据增强的方式扩充数据集。
基于以上背景,本文对茶叶光谱数据进行预处理,分别采用联合区间偏最小二乘法(siPLS)、连续投影算法(SPA)、竞争性自适应重加权算法(CARS)选取光谱特征波长,对特征波长数据建立基于CNN的茶叶品种和等级的鉴别模型,最后使用平移法、线性叠加法、添加噪声法对光谱数据集进行数据增强,验证特征提取结合卷积神经网络模型的稳定性。
1 实验部分
1.1 样品收集与制备
市售的5种茶叶分别是龙井、雨花茶、碧螺春、金骏眉和铁观音,分别制备30个样本共计150个样本。将市售的4个不同等级的龙井茶叶,分别制备30个样本,共计120个样本。所有样本低温避光储藏,具体信息如表1所示。实验前,将不同品种和等级的茶叶样品粉碎成粉末,并通过100目筛后,取茶叶粉末2 g压片制成样品。

表1 5个品种和4个等级茶叶样品信息Table 1 Sample information of five varieties and four grades of tea
1.2 近红外光谱采集
实验使用美国PerkinElmer Lambda 950紫外-可见近红外分光光度计,对压片样品进行漫反射光谱扫描,波长范围800~2 500 nm,设置间隔为1 nm,每个样品进行3次光谱采集,取3次采集光谱的均值作为该样品的光谱。维持室温在25 ℃左右,相对湿度保持在45%~50%,测试前仪器预热3 min以保证仪器的稳定性。
1.3 光谱预处理
由于检测器检测到的光谱信号不仅包含样品信息,还有各种仪器干扰信息,这些干扰信息会影响所建立模型稳定性和可靠性,因此有必要在数据处理前对采集的光谱数据进行合理的处理[24],从而减弱甚至消除非目标因素对光谱信息的影响。本文用小波分析(WT)算法对光谱数据进行平滑去噪预处理。
1.4 特征波长选择
1.4.1 siPLSsiPLS是一种常用的特征变量筛选方法,是联合同一次区间划分后的子区间建立的PLS模型,最终筛选出精度较高的特征变量。为了得到最佳的筛选结果,需要对子区间的划分数及联合区间数进行优化,以交互验证均方根误差(Root Mean Square Error of Cross Validation,RMSECV)为评判标准,Bias是检验样品的预测值与真实值之间的整体平均偏差。
1.4.2 SPASPA是一种使矢量空间共线性最小化的前向变量选择算法,在有效信息获取和降低共线信息的研究中取得了较好的效果。通过投影方式选取线性关系最小的波长组合,从光谱信息中寻找含有最低冗余信息的变量组,使得变量之间的共线性达到最小,同时保留原始数据的绝大部分特征,被选取的特征波长物理意义明确,具有很强的解释能力,因此,可以有效地提高建模的速度以及模型的稳定性。
1.4.3 CARSCARS算法利用自适应重加权采样手段选出PLS模型中回归系数绝对值相对较大的波长点,去除权重相对较小的波长点,并使用RMSECV值最低的子集,可以有效地寻找到变量的最优组合。
1.5 模型的方法及评价指标
1.5.1 CNNCNN是深度学习中最经典的模型之一,它巧妙的减少了参数数量并且达到了全连接神经网络实现不了的效果。CNN的基本结构通常由卷积层、池化层和全连接层三个部分组成,具体细节又可以分为滤波器、步长、卷积操作和池化操作等。由于近红外光谱是一维信号,因此采用的卷积核为一维卷积核。池化是一种非线性的降采样方法,主要是对卷积层输出的特征值进行降维,减少运算规模。目前,池化方式主要分为最大值池化和平均值池化两种方式,本工作则采用最大池化法对模型进行降采样处理。为了防止过拟合现象,本模型选择交叉熵函数(Cross-entropy)与模型权重系数L2正则化的结合作为模型的损失函数(Loss function)。
(1)
其中
(2)
式中,zi为第i个节点的输出值;C为输出节点的个数,即分类的类别个数;p(i)是输出的概率值;W为模型权重;λ为正则化参数。
1.5.2 模型评价指标本研究将识别准确率(Accuracy)作为茶叶品种和等级鉴别模型的判别指标。
(3)
其中,Ncorrect为测试集中预测正确的数量;Ntotal为测试集样本总数量。
2 结果与讨论
2.1 光谱分析
用小波函数Daubechies的正交小波基Db3进行光谱信号去噪,其中分解尺度为4。图1为随机选取某一样本处理前后的光谱,从中可以看出平滑去噪效果明显。
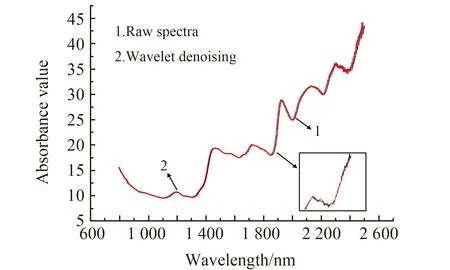
图1 随机选取样本的原始光谱和小波变换处理后的光谱Fig.1 Original spectrum of randomly selected samples and the spectrum after wavelet transform
图2(a)和(b)分别为5个不同茶叶品种和4个不同龙井茶等级经预处理后的近红外光谱。可以看出不同品种和等级的茶叶光谱变化趋势相似,如在1 400~1 500 nm,1 900~2 000 nm,2 200~2 400 nm范围内有强度不同的吸收峰,由吸收峰的位置结合茶叶化学组分分析,以上吸收峰依次为氨基酸(R-NH),茶多酚(=C-H),咖啡碱(-OH)类化合物。不同品种和等级茶叶的茶多酚、氨基酸和咖啡碱等物质成分的含量有差异,这些差异是应用近红外光谱实现茶叶品种和等级快速检测的光谱信息基础。要进一步找到与茶叶更为密切的特征波长,需要利用化学计量学方法对隐含特征波长进一步挖掘[25]。

图2 5种茶叶预处理后的平均光谱(a)和4个等级龙井茶叶预处理后的平均光谱(b) Fig.2 Average spectra of 5 kinds of tea after pretreatment(a) and average spectra of 4 grades of Longjing tea after pretreatment(b)
2.2 特征波长选择
2.2.1 siPLS特征波长选择以5种茶叶光谱数据为例,4:1划分训练集和测试集,经反复比较,当划分区间数为20,联合区间数为4,对应选取的子区间的波数范围为1 215~1 300 nm,1 500~1 585 nm,1 800~1 885 nm,2 200~2 285 nm波长区间,一共340个波长变量,最优波长区间如图3(a)所示。此时测试集的RMSECV最小为0.0435,相关系数r为0.9992,如图3(b)所示。
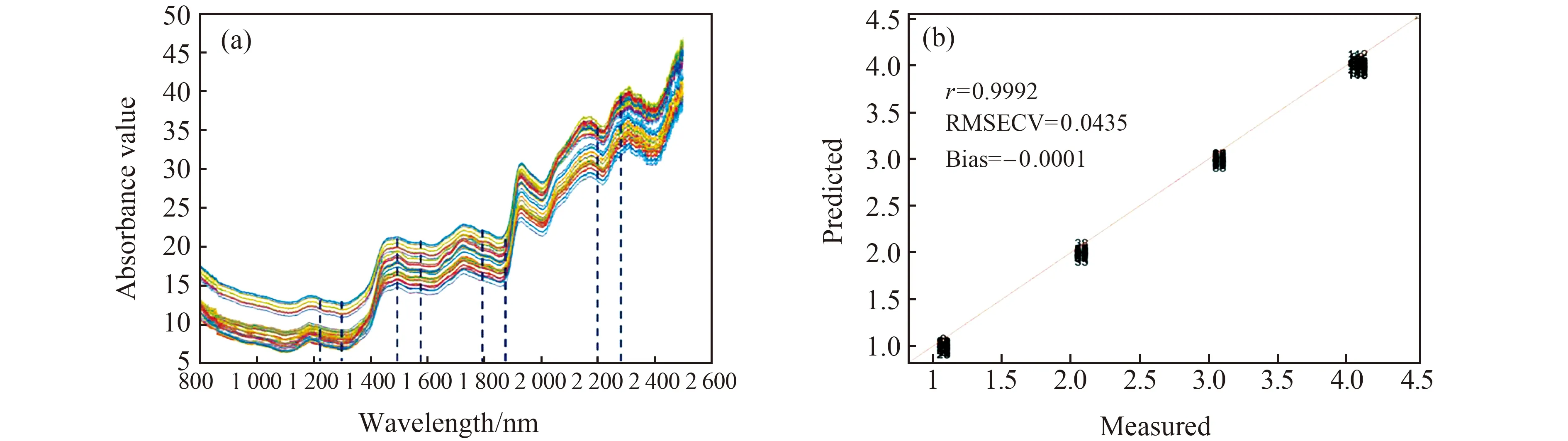
图3 siPLS选取的最优子区间(a)和相关系数及误差(b) Fig.3 Optimal subinterval(a) and correlation coefficient and error(b) selected by siPLS
2.2.2 SPA特征波长选择SPA在选取截取后的训练集光谱数据的特征波长点时,利用均方根误差(Root Mean Square Error,RMSE)最小化原则选出均方根误差的导数变小的过渡点,在过渡点之前冗余信息被剔除。由图4(a)可知最后选取的特征波长数为15个,RMSE为0.0634。图4(b)为选取的15个特征波长,依次为912、1 186、1 506、1 621、1 734、1 877、1 902、1 937、2 024、2 185、2 216、2 327、2 376、2 409、2 452 nm,这些波长基本都在茶叶光谱的吸收峰附近。
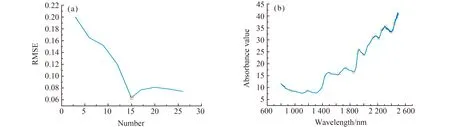
图4 SPA特征波长选取个数(a)和选取的特征波长(b)Fig.4 Number of SPA characteristic wavelengths selected(a) and selected characteristic wavelengths(b)
2.2.3 CARS特征波长选择对预处理后的训练集光谱数据使用CARS进行特征波长选择,经反复尝试,本实验将蒙特卡罗采样次数设定为50,采用5折交叉验证。由图5(a)可知,随着取样运行次数的增加,选取变量的数量逐步递减。由图5(b)可知,RMSECV值先缓慢递减后递增。RMSECV值递减,说明种茶叶光谱数据中部分无用的信息被剔除,RMSECV值递增,说明茶叶光谱数据中有部分重要信息被剔除。当RMSECV值达到最小时,各变量的回归系数如图5(c)中竖线处,此时的采样运行次数是17,RMSECV=0.014,CARS提取的最优波长点数量为19。所选取的特征波长依次为891、972、1 190、1 233、1 421、1 463、1 537、1 549、1 635、1 689、1 735、1 748、1 901、1 967、1 973、2 004、2 112、2 134、2 219 nm。

图5 CARS特征波长选取取样变量数(a)、RMSECV(b)和回归系数路径(c) Fig.5 CARS characteristic wavelength selection sampling variable number(a),RMSECV(b) and regression coefficient path(c)
2.3 基于CNN的茶叶品种和等级鉴别
2.3.1 CNN搭建在建模之前先对光谱数据集进行划分,按照4∶1划分训练集和测试集,并采用5折交叉验证,输出为模型的平均正确率。CNN通常由卷积层(Convolutional layer)、池化层(Pooling layers)与全连层(Fully connected layers,FC)等构成。卷积层用于提取特征,池化层可以减小卷积层提取的特征维数,从而加速神经网络收敛,全连接层可将网络前端输出的特征还原给输出层,最后由输出层输出分类结果。对特征波长选取后的光谱数据,搭建了5层的卷积神经网络,包括了3个卷积层和2个全连接层,具体实现过程如图6所示,卷积层均使用大小为1×3×1的卷积核(kernel),步长(stride)设置为1,池化方式采用最大池化(Max Pooling,MP),卷积层的卷积核数量(kernel number)分别为32、64和128,将卷积运算后的光谱数据输入到全连接层,两个全连接层的神经元个数分别为256和512个(以siPLS提取的茶叶特征波长数据为例,SPA和CARS结构与之相同)。
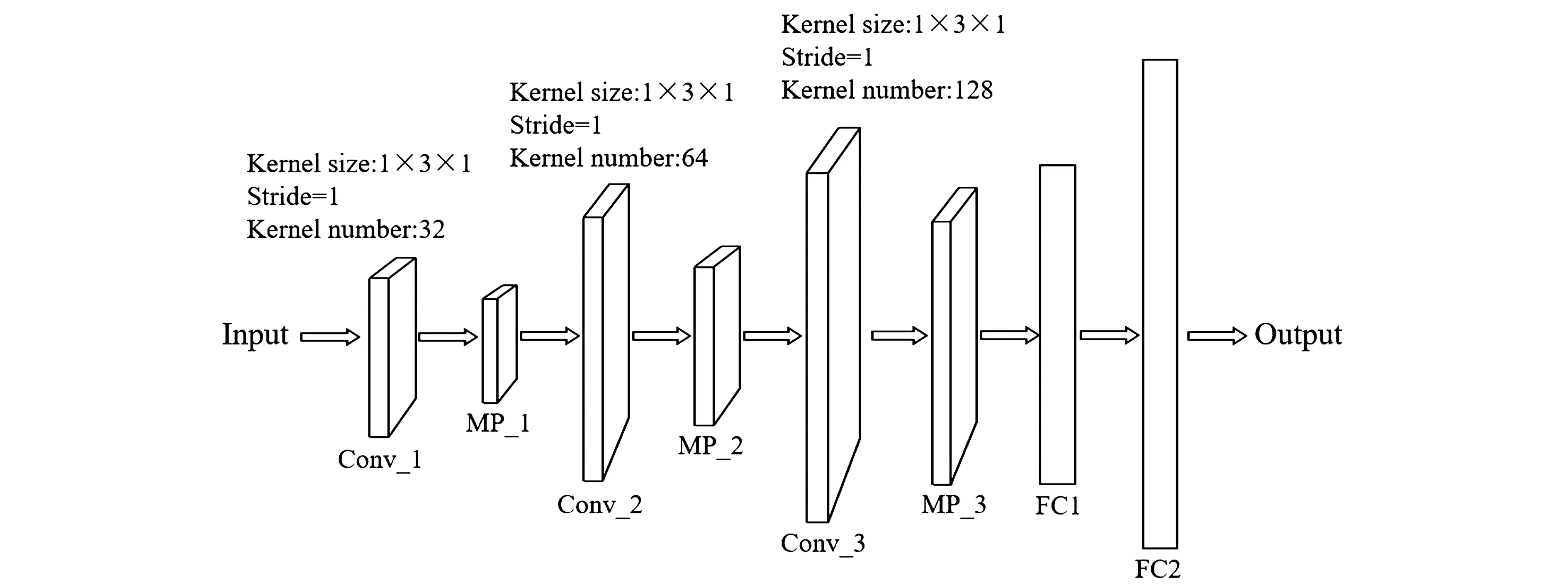
图6 卷积神经网络结构图Fig.6 Convolution neural network structure diagram
2.3.2 CNN训练与测试CNN的训练和优化依赖于损失函数,损失函数计算预测值和真实值之间的误差,通过反向传播算法将误差从最后一层反向传播至网络各层并更新权值。更新后的参数继续参与训练,循环往复,直到损失函数值达到最小,即达到了最终训练的目的。损失函数下降采用Adam优化器[26],选择训练过程中最佳梯度下降方向,可加速模型的收敛。学习率(learning-rate)初始化为0.01,dropout设置为0.5,迭代次数设置为500后开始训练。如果测试集损失值相比上一个训练周期没有下降,则经过50个周期后停止训练,以防止过拟合,不同模型在茶叶品种和等级鉴别的结果如图7所示。
图7(a)、7(b)为全光谱结合卷积神经网络建模结果,训练集损失值(loss)和测试集损失值(val_loss)在训练过程中迅速下降,模型为过欠拟合状态,模型的准确度较低。经过特征波长选取后,相比图7(c)、7(d) 的siPLS+CNN模型和图7(e)、7(f)的SPA+CNN模型,图7(g)、7(h)的CARS+SPA模型测试集精度更高,模型训练效果更好。

图7 全光谱品种鉴别结果(a)、全光谱等级鉴别结果(b)、siPLS+CNN品种鉴别结果(c)、siPLS+CNN等级鉴别结果(d)、SPA+CNN品种鉴别结果(e)、SPA+CNN等级鉴别结果(f)、CARS+CNN品种鉴别结果(g)、CARS+CNN等级鉴别结果(h)Fig.7 Full spectra variety identification results(a),full spectra grade identification results(b),siPLS+CNN variety identification results(c),siPLS+CNN grade identification results(d),SPA+CNN variety identification results(e),SPA+ CNN grade identification results(f),CARS+CNN variety identification results(g),CARS+CNN grade identification results(h)
表2为采用不同特征提取方法结合CNN模型对5种茶叶和4个茶叶等级分类检测的结果,在全光谱范围类,卷积神经网络模型在茶叶品种和等级鉴别的精度仅有66.7%和75%,这是由于全光谱中含有许多无用信息且变量数过多。经过特征波长提取后的光谱数据再结合卷积神经网络模型,在茶叶品种和等级的鉴别上可以实现更好的检测精度,其中siPLS+CNN对品种和等级区分分别达到了91.67%和93.33%的准确率,SPA+CNN提高到95.83%和96.67%的准确率,CARS+CNN将准确率进一步提升到97.72%和98.67%。

表2 特征提取及卷积神经网络建模结果Table 2 Results of feature extraction and convolution neural network modeling
表3为特征提取结合支持向量机(Support vector machine,SVM)、K近邻(K-nearest neighbor,KNN)、极端梯度提升(Extreme gradient boosting,Xgboost)、随机森林(Random Forest,RF)、梯度提升决策树(Gradient Boosting Decision Tree,GBDT)模型在茶叶品种和等级的鉴别结果(仅列举CARS特征提取方法),模型参数均已调到最优,其中CARS+Xgboost模型表现最好,在品种和等级鉴别分别实现91.56%和93.33%的正确率,但和特征提取结合卷积神经网络模型结果仍有差距。

表3 特征提取结合其他分类模型结果Table 3 Results of feature extraction combined with other classification models
2.3.3 模型稳定性验证针对机器学习模型所需样本量大的问题,本文采用平移法、添加噪声法和线性叠加法三种数据增强的方法对原始的光谱数据进行扩充。图8为随机选取的铁观音茶叶原始光谱通过不同方法的数据增强结果,图8(a)为平移法生成的光谱数据,将原始光谱的横坐标随机左右移动1~5 nm实现。图8(b)为通过线性叠加法生成光谱数据,将两个随机样本光谱数据求和之后再除以比例生成。图8(c)为添加噪声法生成的光谱数据,通过添加1~20 dB的高斯白噪声得到。
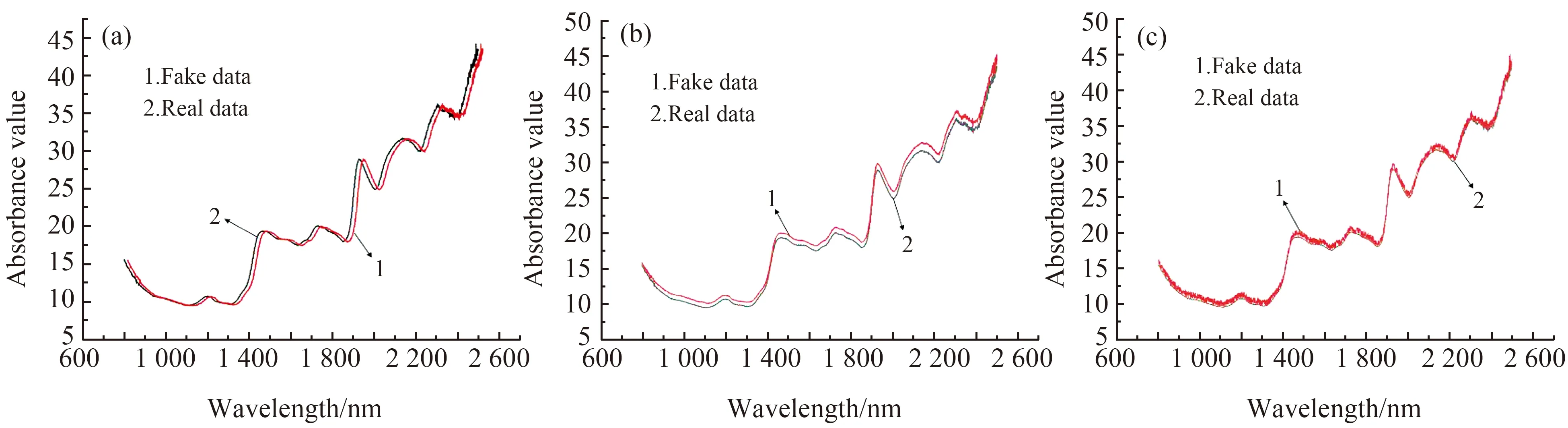
图8 平移法(a)、线性叠加法(b)和添加噪声法(c)Fig.8 Translation method(a),linear superposition method(b) and noise addition method(c)
利用以上3种方法将原始光谱5个不同品种和4个等级的茶叶各扩充500个光谱数据,将增强的光谱数据和原始光谱数据混合建模,按照4∶1的比例划分训练集和测试集,采用5折交叉验证,CARS+CNN模型的分类结果如表4所示(仅列举CARS+CNN模型结果)。CARS+CNN模型在原始光谱的茶叶品种和等级的鉴别准确率为97.72%和98.67%,通过表4的结果可知,扩充后的数据集在CARS+CNN的建模结果和原始光谱结果非常接近,平移法和线性叠加法对模型的精度略有提升,而添加噪声法使模型精度略有下降。总之,CARS+CNN模型在三种不同数据增强方法扩充的数据集都实现了和原始光谱建模相近的结果,说明了原始光谱建立的CARS+CNN模型具有很好的稳定性。

表4 数据增强的卷积神经网络建模结果Table 4 Data-enhanced convolutional neural network modeling results
3 结论
本文利用近红外光谱技术,通过对光谱数据进行特征提取,对选取后特征数据建立卷积神经网络模型,实现了茶叶品种和等级的鉴别。其中SPA+CNN对茶叶品种和等级识别率分别达95.83%和96.67%,CARS+CNN对茶叶品种和等级识别率分别达97.72%和98.67%,为后续相应装置的研发提供了模型支持。同时,特征提取结合卷积神经网络模型在茶叶品种和等级鉴别结果优于传统的分类模型。本文使用平移法、线性叠加法、添加噪声法对光谱数据集进行数据增强,验证了特征提取结合卷积神经网络模型的稳定性。因此,特征提取结合卷积神经网络的方法,可以实现近红外光谱茶叶品种和等级的高精度鉴别,为茶叶品种和等级的快速鉴别提供帮助,减少专业人员的感官评审工作量,可作为传统化学检测法的有效补充。
