基于模仿强化学习的固定翼飞机姿态控制器
2022-11-23付宇鹏邓向阳朱子强余应福闫文君张立民
付宇鹏,邓向阳,朱子强,方 君,余应福,闫文君,张立民
(海军航空大学,山东烟台 264001)
0 引言
飞行控制系统中,姿态控制器的设计原则是使飞机能够随时准确达到所需的正常过载姿态[1-2]。传统的姿态控制通常采用经典的PID(Proportion Integration Differentiation)控制,具有良好的工程适应性[3]。随着现代控制理论和智能控制方法的不断发展,模糊控制等一些新的控制方法被引入姿态控制中,并发挥了良好的控制效果。无论是经典控制理论还是现代控制理论,都需要对被控模型进行数学建模并设计其参数,但这无疑会产生一定的工作量。此外,对于六自由度(6-DoF)飞机模型[4]来说,由于各控制变量,如发动机推力,各操作面如升降舵、方向舵、副翼的偏转角相互耦合,传统单输入、单输出控制器需要首先完成各变量的解耦,理论复杂,计算量大。文献[5-8]中提出了基于神经网络的多变量PID(MPIDNN)算法,能够实现简单问题或环境的解耦,但实际飞机空气动力学模型复杂,MPIDNN 中神经元数量较少,很难拟合实际模型,因此极少实际应用在飞行控制系统中。
近年来,深度强化学习(Deep Reinforcement Learning,DRL)在围棋、游戏、自动驾驶等领域取得突破性发展,能够达到甚至战胜人类专家的水平,成为学术界研究的热点。
强化学习框架,如图1 所示。智能体(Agent)以“试错”的方式进行学习,通过与环境交互获得的奖赏(Reward)指导行为,目标是使智能体获得最大的奖赏。其本质可有效实现拟合过程的自学习,因此具备飞机姿态控制器中模型建立和参数自动调节的能力。

图1 强化学习框架Fig.1 Structure of Reinforcement Learning
目前,强化学习在控制领域取得了一定的进展。文献[9]利用DDPG 算法训练得到的控制器能够实现对旋翼无人机位置控制;文献[1]利用采样池Actor-Critic算法,通过选择基本指令实现了固定翼无人机轨迹跟踪。但目前,强化学习设计姿态控制器难度较大,故普遍采用简化的飞机空气动力学模型[10]。然而,采用强化学习算法训练模型时:一方面存在数据利用低、收敛速度慢的问题;另一方面,模型效果依赖奖励函数设计。在姿态控制中,不当的奖励函数会导致模型姿态转移不符合人类习惯。
为此,本文提出1 种基于模仿强化学习(Imitation Reinforcement Learning,IRL)的姿态控制器。受控对象由飞机空气动力学模型和增稳系统组成,控制器根据不同飞机状态,输出增稳系统控制指令,从而实现飞行姿态快速变换。
1 基于IRL算法的控制器设计
1.1 基于神经网络的姿态控制器设计
传统的PID 姿态控制器通常只能控制1 个通道,如俯仰角、滚转角的响应。由于航向和滚转通道具有较高耦合性,如果独立控制滚转角误差和航向角误差,会出现滚转角首先稳定,而航向仅仅由方向舵缓慢调节的情况。此外,在输入误差跳变或输出响应时间较长等的条件下,传统PID 控制器存在积分饱和现象,会带来滞后和较大超调的情况,需要采用超限削弱等技术缓解,但这将带来额外的调节参数。而且,对于高阶非线性系统或惯性大的系统,PID 控制器调节能力有限[11]。鉴于此,本文利用神经网络的强拟合能力实现飞机姿态控制器设计。
基于神经网络模型的姿态控制器原理图,如图2所示。控制器采用神经网络结构,根据受控对象当前状态输出控制指令,实现姿态变换。其中,受控对象为六自由度固定翼飞机模型,由空气动力学模型和增稳系统组成,增稳系统输出副翼、升降舵、方向舵偏转指令,当各操纵面变化时,气动模型根据对应的Cl、Cm、Cn等气动系数,计算模型各部分合力和合力矩[12-13]。增稳系统中利用包括角速度反馈、过载反馈和控制指令前馈[14-16]等方式提高系统稳定性。
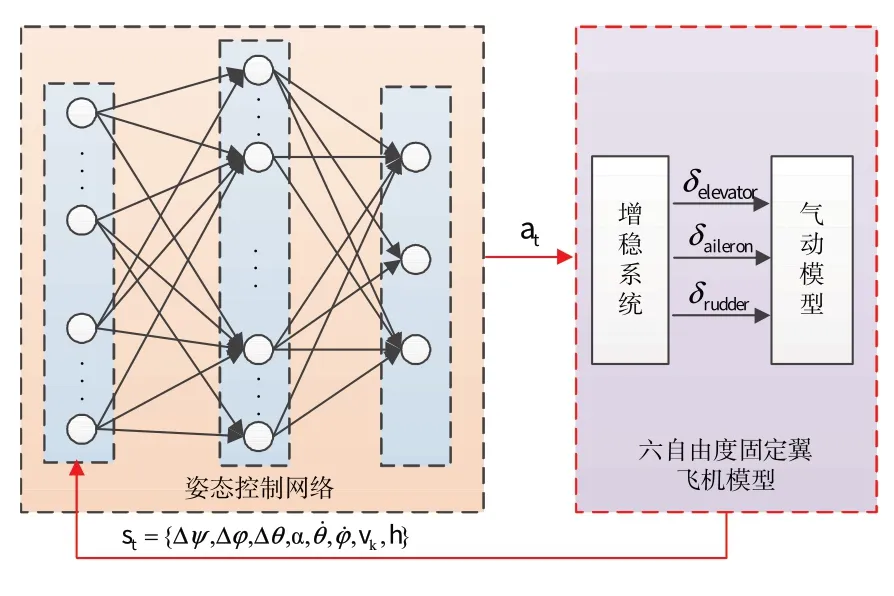
图2 基于神经网络姿态控制器Fig.2 Neural Network based attitude controller


1.2 IRL算法设计

控制网络πθ(st)根据当前状态st输出动作at,θ表示网络参数。初始化时,通过行为克隆技术,将专家经验数据作为标签,对πθ进行监督学习。利用损失函数ℒbc( )θ反向传播和梯度下降更新网络参数θ,得到预训练模型。
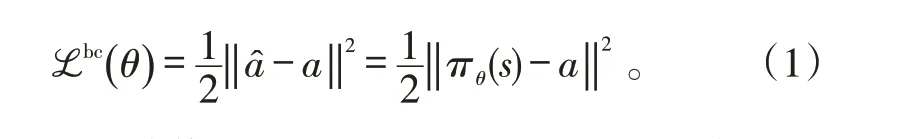
在此预训练模型基础上进行强化学习训练。飞机姿态的状态转移过程可以认为是马尔可夫决策过程(MDP),如式(2)所示,即环境当前状态转移到下一状态的概率仅与当前状态和动作有关。

在状态转移时,智能体将获得环境反馈的奖励rt,在本设计中,将其表示为式(3),为三通道奖励之和。回合期望回报表示为式(4),网络在训练过程中目标即为得到最大的期望回报R。

根据飞机各通道响应特点,滚转通道响应最快,航向变换速度较慢,因此,本文将其分别设置为0.2、0.1和0.7,即期望控制器实现带坡度转弯,实现姿态快速转换。

此外,为避免智能体陷入不停旋转、尽快死亡等获得较大奖励的局部最优解,奖励函数额外设置惩罚项,包括角速度限制和空速、高度限制。
本文以近端策略优化算法(PPO)[17-18]作为强化学习网络参数训练算法。PPO算法是1种Actor-Critic方法,Actor 网络即上述控制网络πθ(st),输出动作at,Critic 网络输出价值函数Vφ(st)。期望得到最大回报,因此,目标函数为:

用来衡量在当前状态下某个动作与其他动作相比的优劣,如果该动作优于其他动作,则反馈正奖励,否则反馈负奖励,即惩罚。Ât表示时刻t的优势函数的估计,Ât一般采用目前应用较多的广义优势估计(generalized advantage estimator,GAE)方法。定义为式(8)(9)[20]:




表1 IRL算法流程Tab.1 Algorithm IRL
2 系统仿真
本文强化学习训练环境采用OpenAI gym 平台,固定翼飞机空气动力学模型是基于JSBSim开源平台F-16 模型,其中,气动系数使用了NASA 公布的F-16风洞试验数据[13]。
2.1 网络训练结果
网络结构参数和算法超参数设计,如表2 所示。为了提高算法训练速度,训练基于并行分布式计算框架ray平台,设置rollout worker数量为40,当样本数达到回合buffer size 时,各worker 计算策略梯度,由learner更新10次网络参数。

表2 IRL算法参数设置Tab.2 Parameter setting of IRL Algorithm
训练环境设置时,将F-16 飞机模型初始姿态角、角速度、空速和高度等状态随机设置,服从高斯分布,目标状态为恢复平飞,每回合时长限制60 s。仿真中网络训练平均奖励,如图3 所示。仅利用PPO 算法训练随机网络模型时,在初始400回合中回报较低,随训练回合数逐渐上升;IRL 算法在通过行为克隆对模型预训练后,回报初始值较高且快速实现收敛。由于平均回报与初始状态密切相关,比如大角度误差条件下,系统响应时间较长,平均奖励较低,反之较高,因此,当网络收敛后,平均奖励会在一定范围内波动。由于训练中随机采样经验数据集计算策略梯度,因此,在有效利用强化学习算法探索环境的同时,输出策略接近专家数据。
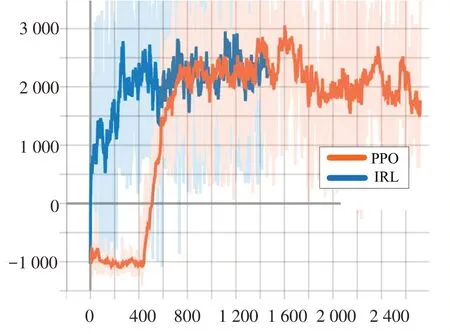
图3 平均奖励函数vs回合Fig.3 Average reward vs episode
2.2 姿态控制仿真
为了验证系统工作性能,本节进行了基于模仿强化学习算法的控制器与传统PID控制器的姿态角响应仿真对比。
图4 给出了基于模仿强化学习控制器(IRL Control)和PID 控制器(PID control)的俯仰角阶跃响应曲线。为了防止出现积分饱和现象,PID 控制器设计时使用超限削弱。飞行器初始保持平飞状态,俯仰角阶跃函数幅度为-30°~50°的响应中,在不改变控制器参数的情况下,两者均能实现稳定跟踪,同时无稳态误差。
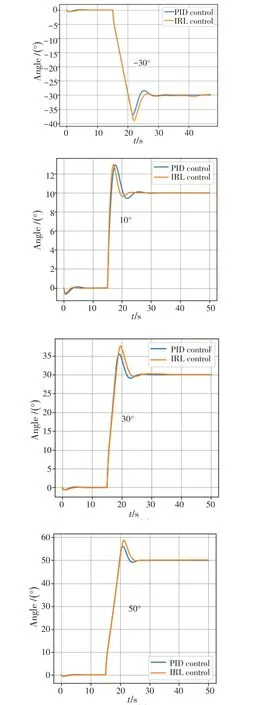
图4 俯仰角阶跃响应曲线Fig.4 Step response of pitch angle
图5 a)、b)分别为IRL 和PID 控制器在航向180°保持条件下的航向角仿真曲线和滚转角阶跃响应曲线。当阶跃函数幅度在30°以下、滚转角保持的需求下,PID控制器能够保持航向,但滚转角响应速度明显变慢,IRL控制器能够同时保持航向角和滚转角,说明IRL控制器在训练中能够根据当前状态对滚转和偏航通路参数解耦。当目标滚转角进一步变大,IRL 和PID 控制器均失去航向保持能力,IRL 控制器滚转角保持更好。


图5 航向角仿真曲线和滚转角阶跃响应曲线Fig.5 Simulation curve of yaw angle and step response curve of roll angle
图6为IRL控制器和PID控制器在目标航向阶跃变化下的姿态角响应曲线,图6 a)、b)分别表示当航向角由0°到90°和由0°到180°的响应情况。IRL 控制器在训练中以快速对准航向为目标,仿真结果表明IRL控制器能够实现与人类习惯相符的带坡度转弯,而后恢复目标姿态,实现快速偏转航向。单通路PID 控制器完全依靠方向舵偏转航向,因此,速度明显更慢。

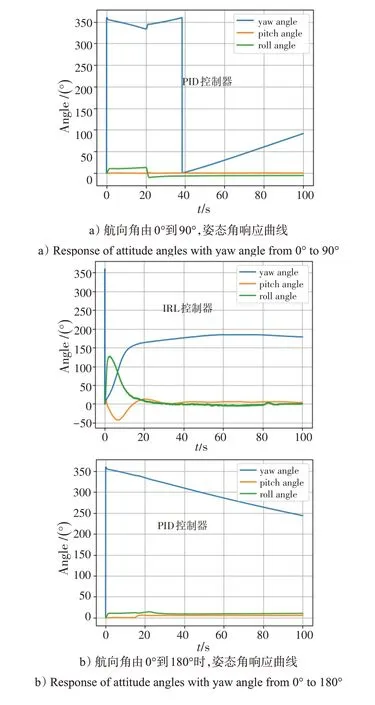
图6 IRL控制器和PID控制器的姿态角响应曲线Fig.6 Response curves of attitude angle for IRL controller and PID controller
通过比较分析可以证明,基于模仿强化学习算法训练的IRL 控制器能够高效地优化在不同角速度、角度、空速等条件下的姿态响应,根据当前状态输出增稳系统控制指令,实现快速姿态变换的目的,同时,能实现基于专家经验的带坡度转弯等动作。
3 结束语
本文提出了一种基于模仿强化学习算法的固定翼飞机姿态控制器,可实现对飞机姿态角的控制。相比传统PID 控制器,本文提出的模仿强化学习控制器核心优势在于能够通过智能体在学习过程中遍历状态空间,找到当前状态下的数值最优解,同时结合经验数据提高模型逼真度。
在仿真中发现一些问题,有待进一步研究:模仿强化学习控制器对于正误差角度和负误差角度的响应并不完全对称,控制器参数不方便调节;对专家经验数据准确性具有一定的要求。
