变工况下基于联合适配与对抗学习的滚动轴承故障诊断
2022-11-23王志超刘维鸽杨延西史雯雯
王志超,徐 江,刘维鸽,杨延西,史雯雯
(1.中国重型机械研究院股份公司,陕西 西安 710018;2.西安理工大学自动化与信息工程学院,陕西 西安 710048)
0 前言
旋转机械在工业生产中发挥着重要作用,如带钢冷轧线、带钢酸洗线、带钢彩涂线等都存在多个转动轴承,都属于旋转机械的范畴,在工业生产中应用广泛。旋转机械普遍运行在恶劣的工作环境下并且长期处于高速旋转,极易发生损坏。一旦某个旋转机械零部件故障失灵,很有可能导致整体加工系统的损坏,甚至威胁操作人员的安全。目前,针对这类易损零部件,大多工厂车间都是采用定期维护的策略来预防故障的发生,实际效果也不尽理想。况且,一些旋转机械安装在一些大型设备的内部,其拆卸与安装都十分麻烦,对其检修一次可能会耽误数小时的生产,对生产计划有很大影响。因此,了解旋转机械的故障机理,掌握故障发生的规律,提出科学有效且经济可行的运维策略是十分必要的。
在现有的大多数数据驱动的智能故障诊断方法中,一个重要前提是训练数据与测试数据同分布,而在实际工业中,由于机器工况的变化、环境噪声的干扰、轴承质量等因素,训练数据与测试数据的分布通常存在差异,导致诊断性能显著下降,需要建立具有较强泛化性能的故障诊断模型,以适应不同工况的场景。迁移学习为解决这类问题提供了新的思路,可以将相关领域学到的知识进行迁移,以帮助提高训练数据较少的目标任务的学习性能,放松了源数据集和目标数据集必须具有相同的分布的假设,以减少重新收集足够大的训练数据的需要。因此,本文主要以滚动轴承的故障诊断为主要研究内容,以深度学习框架中的卷积神经网络作为基础网络框架,结合迁移学习方法构建模型进行轴承故障诊断,对滚动轴承智能故障诊断的发展具有重要促进意义。
针对全监督情况固定工况下基于卷积神经网络的滚动轴承故障诊断,提出的模型可以实现较高的准确率,噪声干扰下也有着较好的鲁棒性。然而在许多实际应用中,某些工况下的样本由于客观条件的限制可能很难采集,大量的训练样本可能来自某个特定工况。除此之外,轴承的运行状态参量——载荷和速度,也会随着时间和空间的变化而变化,导致轴承的训练数据和测试数据工况不同。因此需要用某个工况训练的模型可以有效地对其他工况的样本进行故障状态判别。由于工作条件的不同,测试数据的分布可能与训练数据的分布不一致。而基于深度学习的“端到端”模型不仅需要大量标记数据,且要求训练数据集与测试数据集同分布。因此基于卷积神经网络的模型已不能满足此类情况的需求,诊断性能会降低。另外,有标签的数据在某些机器上很难获得,如果要对某一工况下的数据进行故障诊断,通常只能采集到少量无标签数据。手动标记数据和从头开始构建一个模型都是复杂而耗时的。
由于基于卷积神经网络的模型已不能满足某些工况的需求,且诊断性能低,数据采集困难等,需要通过迁移学习的方法对模型和带有标签的数据进行重用。因此本文在深度卷积神经网络模型中引入了迁移学习,提出了一种多尺度卷积联合适配对抗网络,来有效解决变工况情景下的故障诊断问题。通过对不同的迁移学习算法进行分析,设计了故障诊断模型,并进行实验对模型进行了验证。在进行实验时,专门研究了比较坏的一种情况,即目标域为无标签数据,该探索对于无标签数据智能故障诊断的发展具有重要意义。
1 特征迁移学习算法
迁移学习方法多种多样,其核心思路就是通过利用已有样本、参数或特征,使用已有领域知识来完成目标领域知识的学习。其中,基于实例的迁移学习方法当某些特征是源(目标)域特定使用时,重新加权样本不能减少域差异,适用于源域和目标域相似度较高的情况。基于模型的迁移学习方法所迁移的知识被编码到模型参数、模型先验知识、模型架构等模型层次上,不过其大多假设目标域是有标签的样本。基于特征的迁移学习算法可以应用在域间相似度不太高甚至不相似的情况。考虑到本文研究的是半监督变工况条件下的轴承故障诊断,因此决定采用基于特征的迁移学习算法,将来自源域和目标域的数据映射到共同的特征空间,通过距离度量将域差异最小化。然后使用映射之后的源域和目标域数据在新的特征空间上训练目标分类器。
基于特征的迁移学习重点就是要找到一个距离度量准则,这是量化迁移学习中两域差异的重要手段,可以用来衡量源域和目标域的相似性。选择一个好的度量准则对于迁移学习模型的训练至关重要,不仅可以很好地度量源域和目标域间的差异,量化两域的相似程度,还要能够作为准则,在进行迁移训练时可以利用方法或模型对该度量进行优化,以增加源域目标域的相似性,从而完成迁移学习。本文模型用到了特征迁移学习中的JMMD距离,后续对比实验用到MK-MMD距离及CORAL。
1.1 MK-MMD
许多研究人员通过最大均值差异(Maximum Mean Discrepancy,MMD)来减小域差异,MMD最早在文献[1]中提出,并被许多其他研究人员用于迁移学习。可以用作衡量两个数据分布差异的度量准则,MMD的主要思想是当两个数据的分布线性不可分时,将数据映射到一个高维空间中,然后在此空间衡量两个数据分布的差异。MMD在计算两数据分布差异时引入了核函数,可以解决数据在高维空间难以计算的问题,在迁移学习领域应用广泛。
再生核希尔伯特空间(RKHS)中定义的MMD算法就是求得两数据集在高维空间的均值差异,具体公式为
(1)
式中,xi为数据集X的第i个样本;yj为数据集Y的第j个样本;n为数据集X的样本个数;m为数据集Y的样本个数;φ(·)为到高维空间的映射函数;H为距离,是由φ(·)将数据映射到RKHS中进行度量的。
MMD的关键在于如何找到一个合适的φ(·)作为一个映射函数。但是这个映射函数在不同的任务中都不是固定的,所以是很难去选取或者定义的。如果不能知道φ(·),MMD的求解步骤如下,首先对式(1)的平方进行分解,可以得到:
(2)
MMD的目标函数中含有类似内积的计算,这可以联想到SVM中核函数的定义:
k(x,y)=φ(x)·φ(y)
若将核函数引入MMD的目标函数中,可以避免内积无法计算的问题,则可以表示如下:
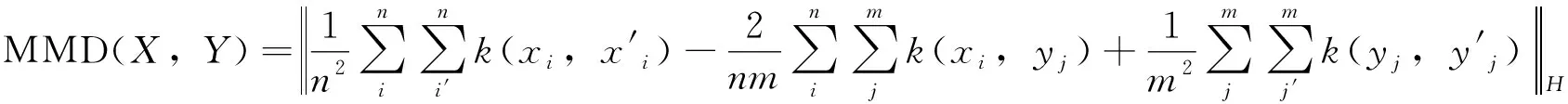
考虑到高斯核函数可以把数据映射到无穷维空间,因此通常选用高斯核作为核函数。高斯核函数的定义为
k(x,x′)=exp(-‖x-x″‖2/(2σ2))
式中,βu不同核的加权参数(本文βu=1)。
1.2 CORAL
CORAL即相关对齐算法,也可以作为一种度量准则,描述两个数据间的分布差异。核心思想是先计算出源域数据和目标域数据的协方差,随后白化并重着色源域数据的协方差,通过调整网络参数,使得两域数据分布的协方差损失最小,从而使源域和目标域分布的二阶统计数据保持一致。此方法的思想比较简单,旨在对齐数据的二阶特征,而最大均值差异是将数据映射到高维空间,对齐数据的一阶特征。CORAL不用再进行进行核函数的选择,对源域和目标域进行的非对称变换,而最大均值差异对两个数据域进行的是同一种核函数的变换。CORAL算法具体定义如下:
(3)
式中,Cs为源域数据的协方差矩阵;Ct为目标域数据的协方差矩阵; ‖‖F为范数,用来衡量两个矩阵的距离。
由式(3)可以知道,如果要使目标函数最小,需要寻找到一个矩阵,当其对应的线性变换作用于源域时,目标函数值可以尽可能地小,从而源域和目标域数据的二阶统计特征差异达到最小。在传统机器学习的跨域迁移中可以直接使用CORAL算法,但对于深度学习网络来说,网络每一层都是对输入数据进行卷积、激活或者池化后的特征表示,因此无法获得矩阵的值。针对这一问题,文献[4]提出了Deep CORAL算法,对原始CORAL算法进行了改进,使得CORAL算法可以应用于深度学习网络,进行深度迁移学习模型的训练。CORAL损失定义为源域目标域特征的二阶协方差距离,用式(4)表示。
(4)
式中,d为每个样本的维数。
源域数据的协方差矩阵Cs和目标域数据的协方差矩阵Ct分别按照式计算得到:
式中,Xs为源域训练样本;Xt为目标域训练样本;ns为源域训练样本个数;nt为目标域训练样本个数;1为元素均等于1的列向量。
利用微积分的链式求导法可以输入特征的梯度进行计算,计算方法如下:
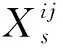
1.3 JMMD
通常深度神经网络的输入数据会经过多层的特征变换和抽象,提取到的特征随着网络层数的增加逐渐从一般特征过渡到具体特征,以此学习输入数据的特征与输出标签之间的复杂映射关系。最大均值差异已经被广泛用于衡量源域边缘分布和目标域边缘分布的差异,由于联合分布不容易于操作和匹配,MMD或者MKMMD还不能解决此类问题。所以当输入数据与输出数据的联合分布发生变化时,如何有效地进行迁移学习是一个难点。另外当源域和目标域的差异增大时,数据特征和分类器的可迁移性会极大地降低,也不利于迁移学习模型的训练。为解决问题, 而定义的MMD和MK-MMD不能用于解决由输入和输出的联合分布,联合最大均值差异(JMMD)被设计为测量源域和目标域之间的经验联合分布差异。考虑到在把源域数据和目标域数据输入深度神经网络后,即使经过多层特征变换和抽象,源域联合分布和目标域联合分布的变化仍然会停留在多个域特定高层的网络激活中。因此,可以使用这些域特定层的激活的联合分布来近似推出原始的联合分布,从而实现源域和目标域的域适应。JMMD为希尔伯特空间中两个联合分布的差异,具体定义为
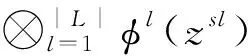
由于在深度卷积神经网络中,多个域特定层中网络激活的联合分布的变化与输入数据的特征与输出标签的联合分布的变化相似。因此JMMD可以通过测量源域数据和目标域数据的经验联合分布的核平均嵌入之间的希尔伯特-施密特范数(Hilbert-Schmidt Norm),来对齐多个域特定层的激活的联合分布。
JMMD经验估计值可以表示为经验核平均嵌入之间的平方距离,
式中,ns为源域样本数量;nt为目标域样本数量;L为适配的总层数。
2 多尺度卷积联合适配对抗网络
2.1 网络模型
不同工况下进行轴承故障诊断,源域数据和目标域数据差异性增大,因此比起固定工况下诊断难度更大。针对此场景提出了一种多尺度卷积联合适配对抗网络(MSCJACN),通过缩小两域数据间的分布差异,使得源域训练的模型可以很好地迁移到目标域。提出的MSCJACN模型框架由故障识别和域自适应两大模块组成,模型总体框架如图1所示。
(1)故障识别。故障识别模块包括特征提取器和故障状态分类器两部分,通过一维多尺度卷积神经网络来实现。具体网络参数见表1。包括一个输入层,一个多尺度特征融合层、四层卷积池化层,两个全连接层和一个Softmax输出层。Softmax层之前为特征提取器,Softmax层为故障状态分类器。特征提取器试图从原始输入信号中自动学习故障特征。故障状态分类器基于提取的特征来识别轴承故障类型,并且在对网络进行训练时,损失函数会依据源域输入的真实标签和分类器的预测输出计算误差,然后将误差进行反向传播来训练网络。故障状态分类器使得网络可以利用有标签的源域数据进行有监督训练,以提高分类准确性。
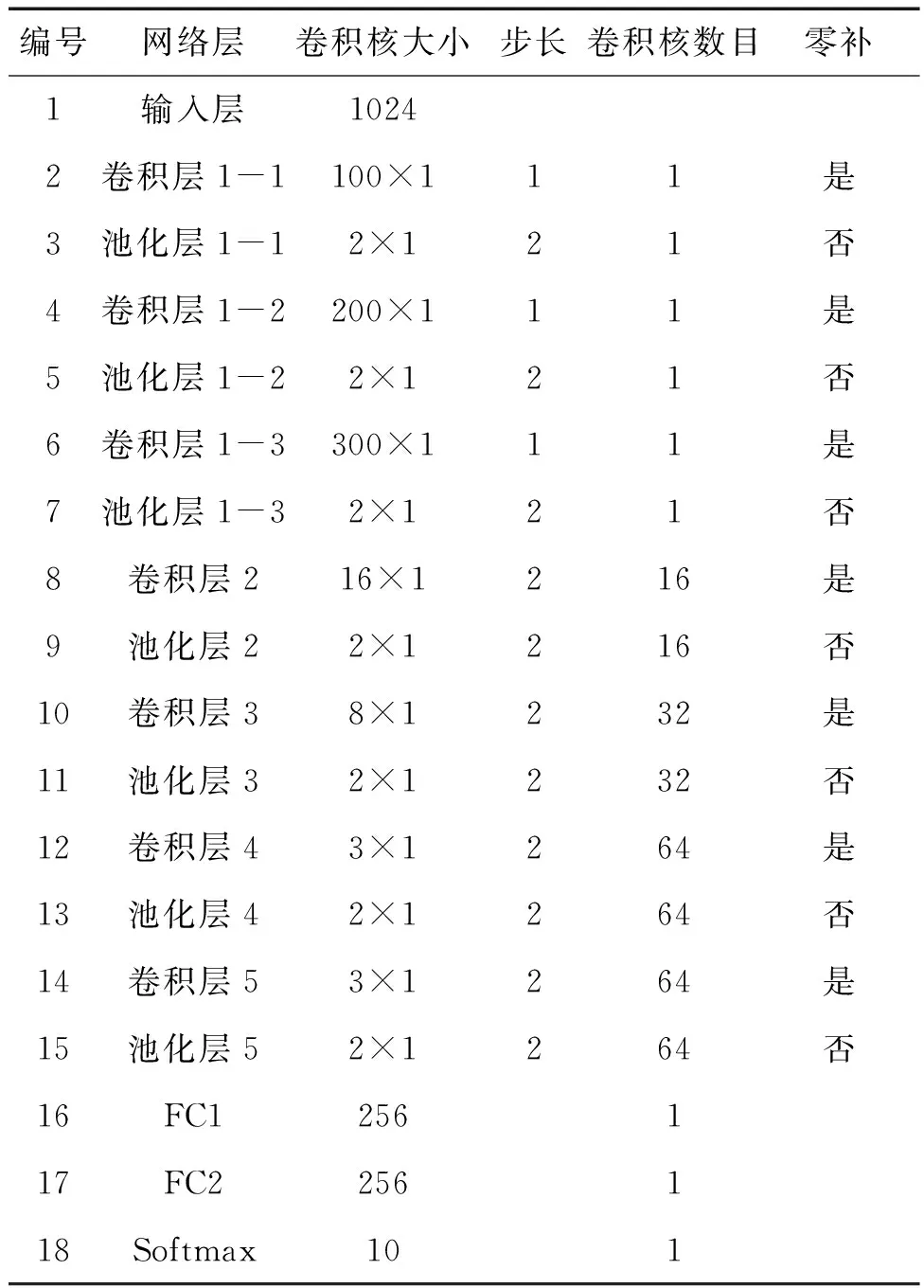
表1 一维卷积神经网络结构参数
(2)域自适应。域自适应模块由联合分布适配器和域判别器组成,域自适应模块连接到故障识别模块的特征提取器,来帮助一维CNN学习域不变特征。学习域不变特征意味着,无论从中学习源域数据还是目标域数据,这些特征都应服从相同或几乎相同的分布。如果特征是领域不变的,则使用源领域数据训练的健康状况分类器能够有效地对从目标领域数据中学到的特征进行分类。
联合分布适配器用来对网络高层提取的具体特征进行适配。前面已经对深度神经网络的可迁移性进行了分析,低层网络提取的是通用特征,高层网络提取的是具体特征,高层中特征的可迁移性低,因此需要对高层的特征进行适配,在网络最后两个全连接层上添加适配网络,使用联合最大均值差异(JMMD)来减小源域数据和目标域数据的分布距离。
域判别器采用了对抗学习的思想,用来判断输入的训练样本是源域样本还是目标域样本,同时计算域判别损失。在特征提取器和域判别器之间添加一个特殊的梯度反转层(GRL),使得特征提取器和域判别器的训练目标相反,从而形成一种对抗关系。在反向传播更新参数的过程中,域判别器的训练目标是尽可能地将输入的训练样本分到其所属的域。由于GRL的存在,特征提取器的训练目标是使域判别器不能正确判断输入的训练样本来自哪一个域。当域判别器不能正确区分源域样本和目标域样本时,特征提取器的任务就完成了。此时,在某个空间内源域数据和目标域数据已经被混合在一起了,即源域和目标有了相同或相似的分布。MSCJACN使用了两层完全连接的二进制分类器作为域判别器,第一层全连接层后的特征经过ReLU激活之后,采用Dropout进行随机丢弃,再经过一层全连接层,最终提取的特征传递到最后的Softmax层,Softmax输出层具有2个神经元判断输入的训练样本是源域样本还是目标域样本。
2.2 目标函数
为了使得源域训练的模型能够很好地迁移到目标域,本文提出的MSCJACN网络模型具有三个优化对象。
(1)最小化源域数据集上的故障状态分类错误。为了完成迁移故障诊断,MSCJACN应该能够识别轴承的健康状况并学习域不变特征。故障识别模块旨在识别机器的健康状况。因此,MSCJACN的第一个优化目标是最小化源域数据上的健康状况分类错误。对于具有健康状况类别的数据集,其目标函数采用交叉熵损失函数为
式中,Gf为是参数为θf的特征提取器;Gc为是参数为θc的类预测器。
因此,目标一的优化目标为
ψ1=minL1(θf,θc)
(2)最小化源和目标域数据集之间的JMMD距离。域适应模块旨在学习域不变特征。域适应模块包括分布差异度量和域分类器。高级特征直接影响迁移故障诊断的有效性。为了减小从不同域学习到的特征之间的分布差异距离,采用联合分布适配器直接测量两域之间的分布差异距离。因此,MSCJACN的第二个优化目标是使源域数据和目标域数据之间的联合分布差异距离JMMD最小。为了计算高级学习特征在不同域之间的分布距离,JMMD损失为
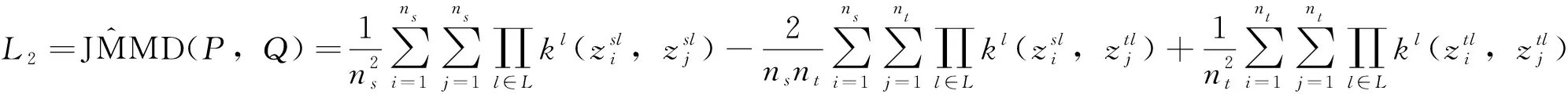
因此,目标二的优化目标为
ψ2=minL2
(3)最大化源和目标域的域分类错误。如图1所示,域分类器与特征提取器连接。如果域分类器无法区分源域和目标域之间的特征,则特征是域不变的。因此,MSCJACN的第三个优化目标是最大化源和目标域数据上的域分类误差。域分类损失采用二分类交叉熵损失函数:
因此,目标三的优化目标为
ψ3=maxL3(θf,θd)
最终的目标损失函数可以写成
L=L1(θf,θc)+λL2-μL3(θf,θd)
式中,λ为JMMD损失L2的惩罚系数;μ为域分类损失L3的惩罚系数。
因此,最终的网络优化目标为
ψ=minL=min{L1(θf,θc)+λL2-μL3(θf,θd)}
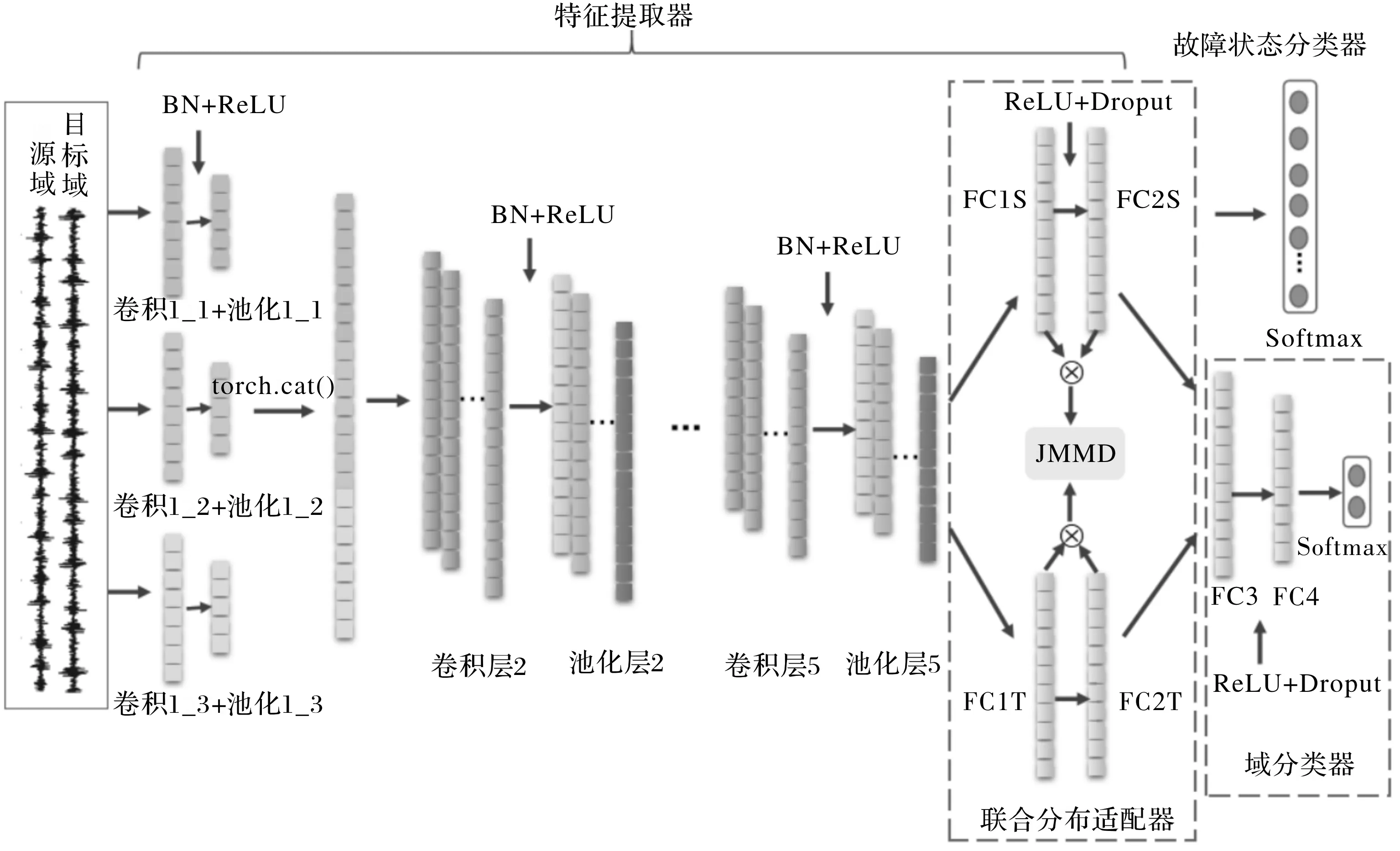
图1 多尺度卷积联合适配对抗网络(MSCJACN)框架图
3 实验验证
3.1 数据集构建
依旧采用CWRU数据集对实验模型进行验证,如表2所示,数据集是在四个不同的电动机负载(0HP,1HP,2HP和3HP)下采集,分别对应于四个不同的运行速度(1 797 r/min、1 772 r/min、1 750 r/min和1 730 r/min)。对于迁移学习任务,将这些不同的工作条件视为不同的迁移学习任务,因此仍然将CWRU轴承数据集分为四个子数据集,包括数据集A、B、C和D。在不同的数据集之间进行迁移故障诊断,任务A→B表示源域是电机负载等于0 HP的数据,而目标域是电动机负载等于1 HP的数据。因此,此数据集中总共有十二种迁移学习设置。
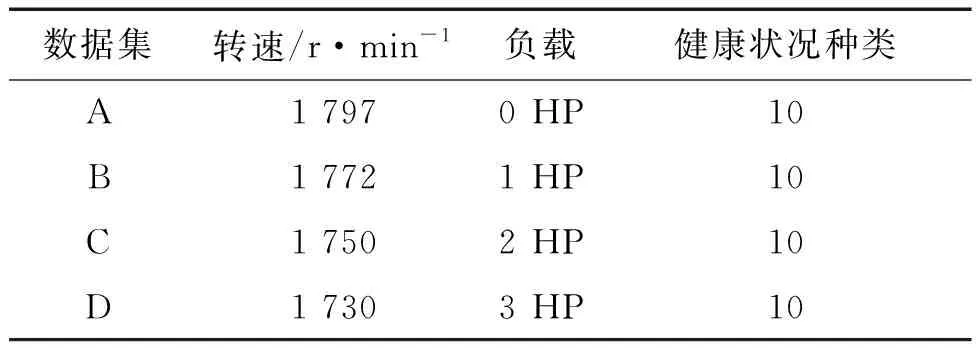
表2 CWRU轴承数据集
负载不同,加速度传感器采集的信号也会有差异。如图2所示,是故障尺寸为0.007 inch对应的四种负载(0HP,1HP,2HP和3HP)下的外圈故障信号,可以看出在负载不同时,信号的幅值、相位及波动周期也具有较大差异。因此变负载情况下的故障诊断比固定工况下的故障诊断更具难度。
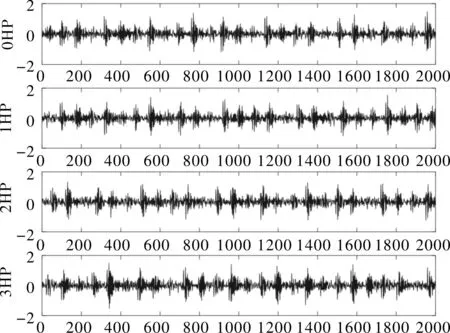
图2 四种负载下的轴承外圈故障信号
变工况诊断一般应用场景的限制是源域有充足的带标签数据,而目标域只有少量的无标签数据,为了使得源域训练的模型迁移到目标域,可以实现对目标域数据故障状态的准确判别,需要对此场景进行准确模拟。因此在构建数据集时,应该对源域数据集进行增强,目标域数据集不需要增强,并且源域数据带标签,目标域数据不带标签。以数据集A为源域,数据集B为目标域举例。采用滑动窗口对数据集A的样本数据进行重叠采样来扩充数据,每个数据集的每种故障类型的样本取固定长度120 000,按照样本长度为1 024,采样间隔为132去采样,可得到每个数据集每种故障类别的样本数为902,数据集A中有十种故障类别,取80%作为训练数据,20%作为测试数据,因此数据集A的训练集=902×10×80%=7 216,数据集A的测试集=900×10×20%=1 804。数据集B不需要进行数据扩充,就按照样本长度1024去采样,可得到每个数据集每种类别的样本数为117,同样80%作为训练数据,20%作为测试数据,最终数据集B的训练集=117×10×80%=936,测试集=117×10×20%=234。其他的迁移学习设置数据集构建方式和上述举例一样,作为源域的数据训练集大小为7 216,测试集大小为1 804,作为目标域的数据训练集大小为936,测试集大小为234。最终构建的数据集如表3所示。
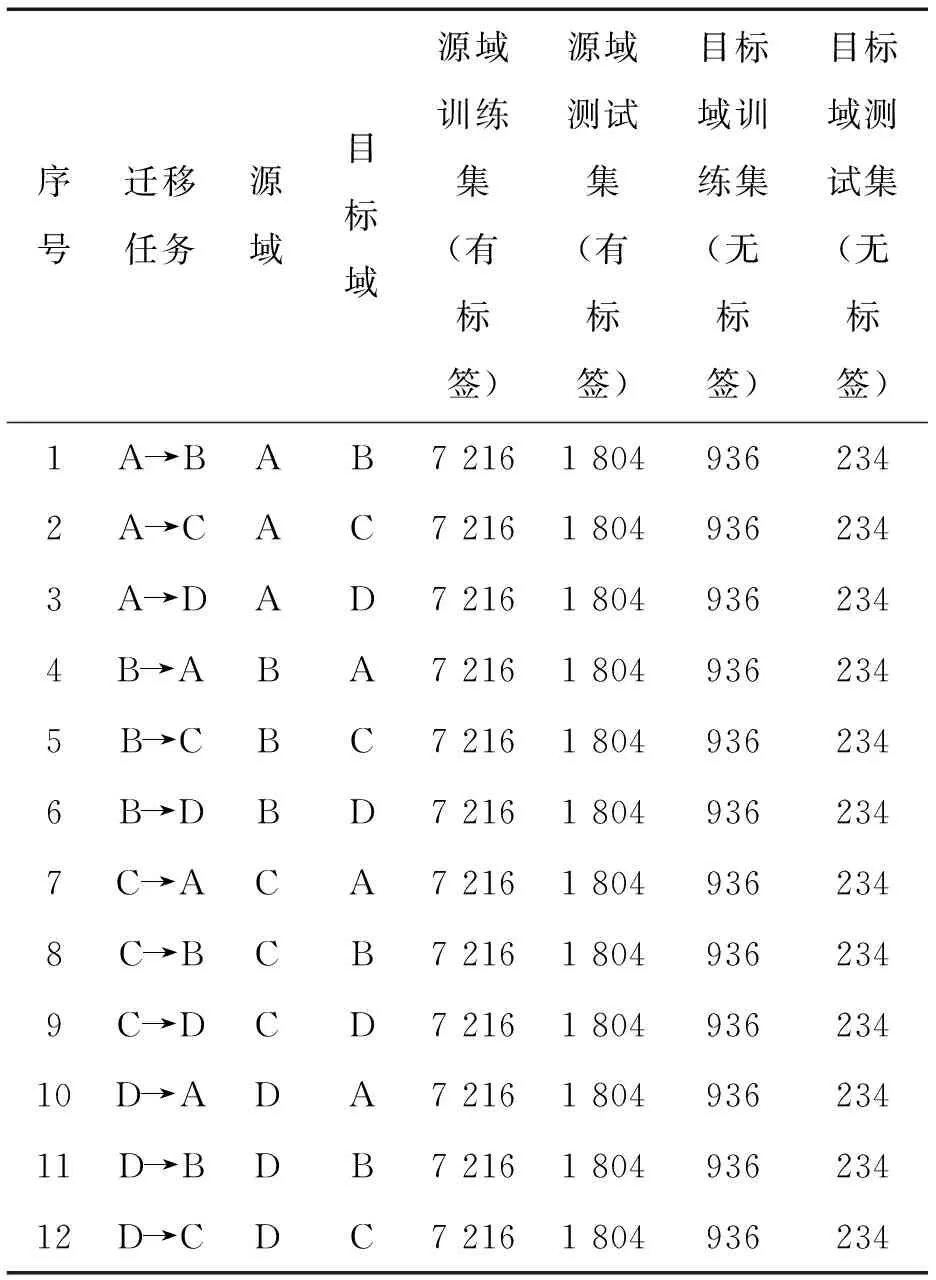
表3 实验数据划分
3.2 实验设置及结果分析
实验平台在Python3.7.10+Pytorch1.3.1上搭建模型并进行实验。模型迭代周期epoch设置为60。前30 epoch先利用数据量充足的带标签源域样本训练网络,此时网络的目标函数只有交叉熵损失函数,得到预训练模型。第30 epoch激活迁移学习策略,网络中同时输入带标签源域数据和无标签目标域数据,此时网络的目标函数为交叉熵损失函数、JMMD损失及域分类损失三部分,对预训练模型的参数进行微调。训练时采用小批量的Adam算法来进行反向传播,每批大小batch_size设置为64。初始学习率设置为0.001,并分别在第40 epoch和50 epoch中衰减,即学习率乘以0.1。JMMD损失和域分类损失的惩罚系数和采用渐进式训练,使用公式从0增加到1, 表示从0变为1的训练进度。达到最大迭代周期,即可得到最终的故障诊断模型,可对不同工况的目标域数据进行故障类别诊断,具体诊断框图如图3所示。
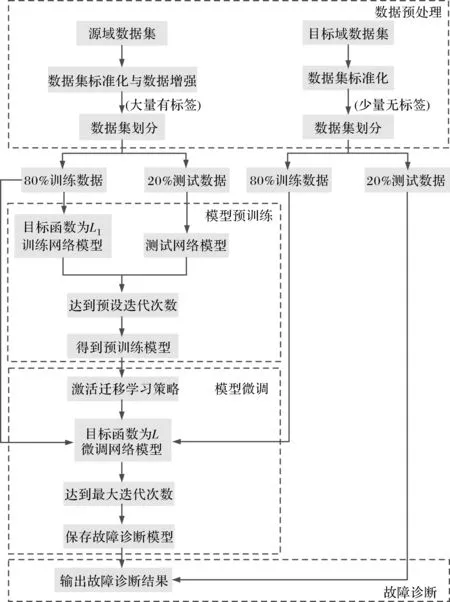
图3 基于MSCJACN的轴承故障诊断框图
为了验证本文提出的MSCJACN网络在变工况场景故障诊断的有效性,将本文模型与MS-1DCNN模型,在12种迁移任务下进行实验模型,应用于CWRU数据集。最终测试集的诊断结果如图4。
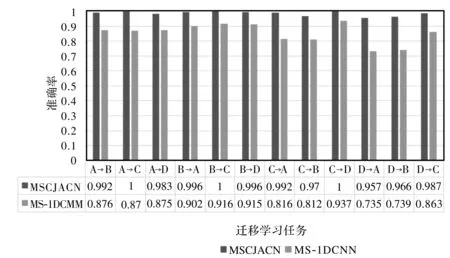
图4 MSCJACN与MS-1DCNN在12种迁移任务上的诊断结果对比
本文模型和仅由源数据训练的MS-1DCNN之间的唯一区别是,在本文模型中添加了域自适应模块,而结果表明,本文的MSCJACN比仅由源数据训练的MS-1DCNN具有更高的分类精度。可以看出MSCJACN在加入域自适应模块后,在变工况场景诊断精度仍然很高,而没加迁移学习的MS-1DCNN模型诊断性能不稳定,且识别精度都低于MSCJACN。尤其在工况差距比较大时,MS-1DCNN模型诊断性能大大降低,比如D→A的迁移,诊断准确率只有73.4%,而MSCJACN依然可以达到约95.7%的识别率。这意味着,迁移学习可能是促进具有未标记数据的机器的智能故障诊断成功应用的有前途的工具。
为了进一步证实本文提出的模型在变工况迁移故障诊断时的优越性,把本文模型的域自适应部分替换为其他经典的迁移学习方法。如图5所示,构建的模型只有域自适应部分不同,故障识别部分的结构相同。即JMMD+域判别器、多核最大均值差异MK-MMD、相关对齐算法CORAL。三种方法在12种迁移学习任务上的结果如表4所示,将此结果绘制成折线图如图6所示。
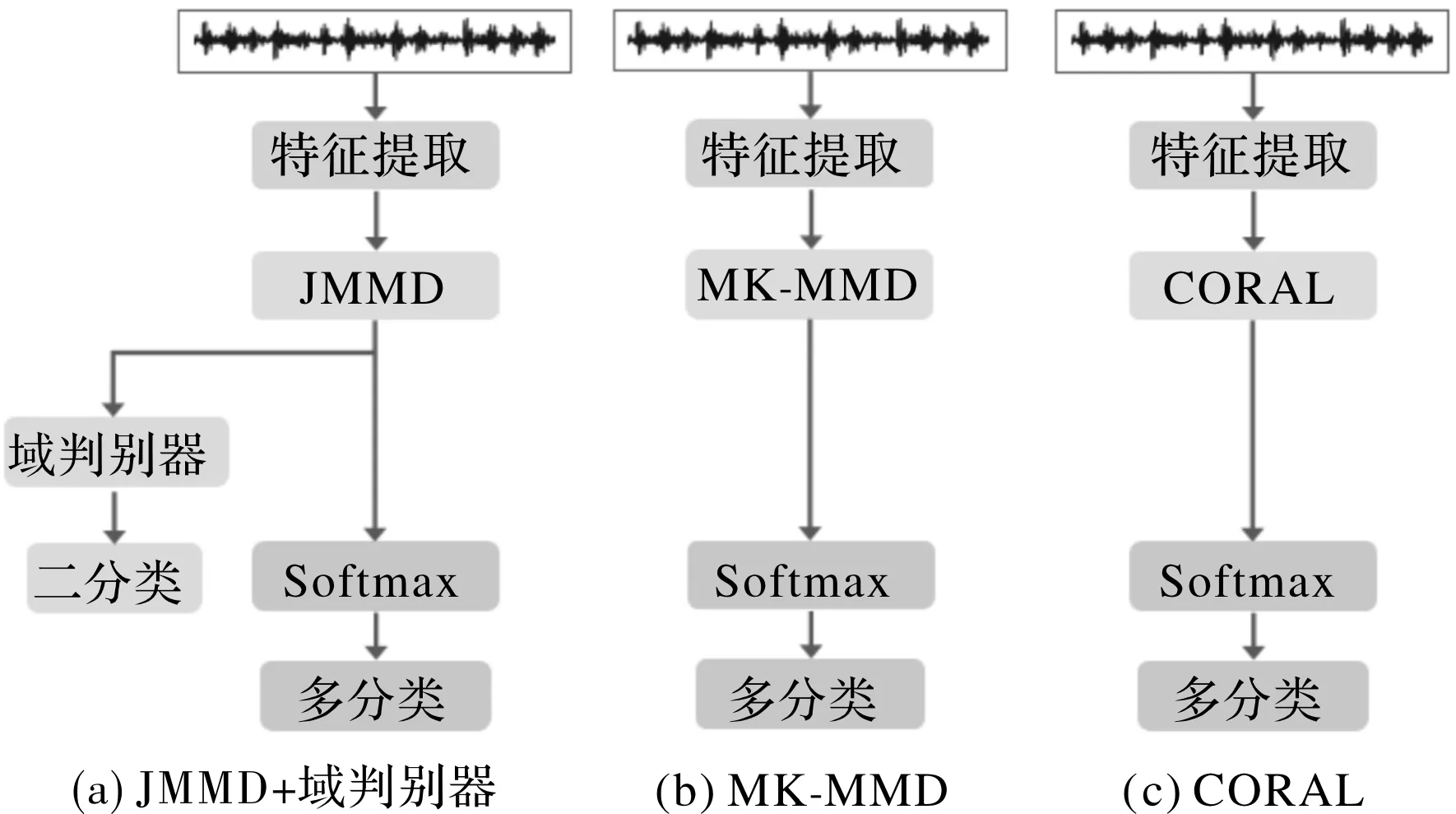
图5 不同的域自适应模块
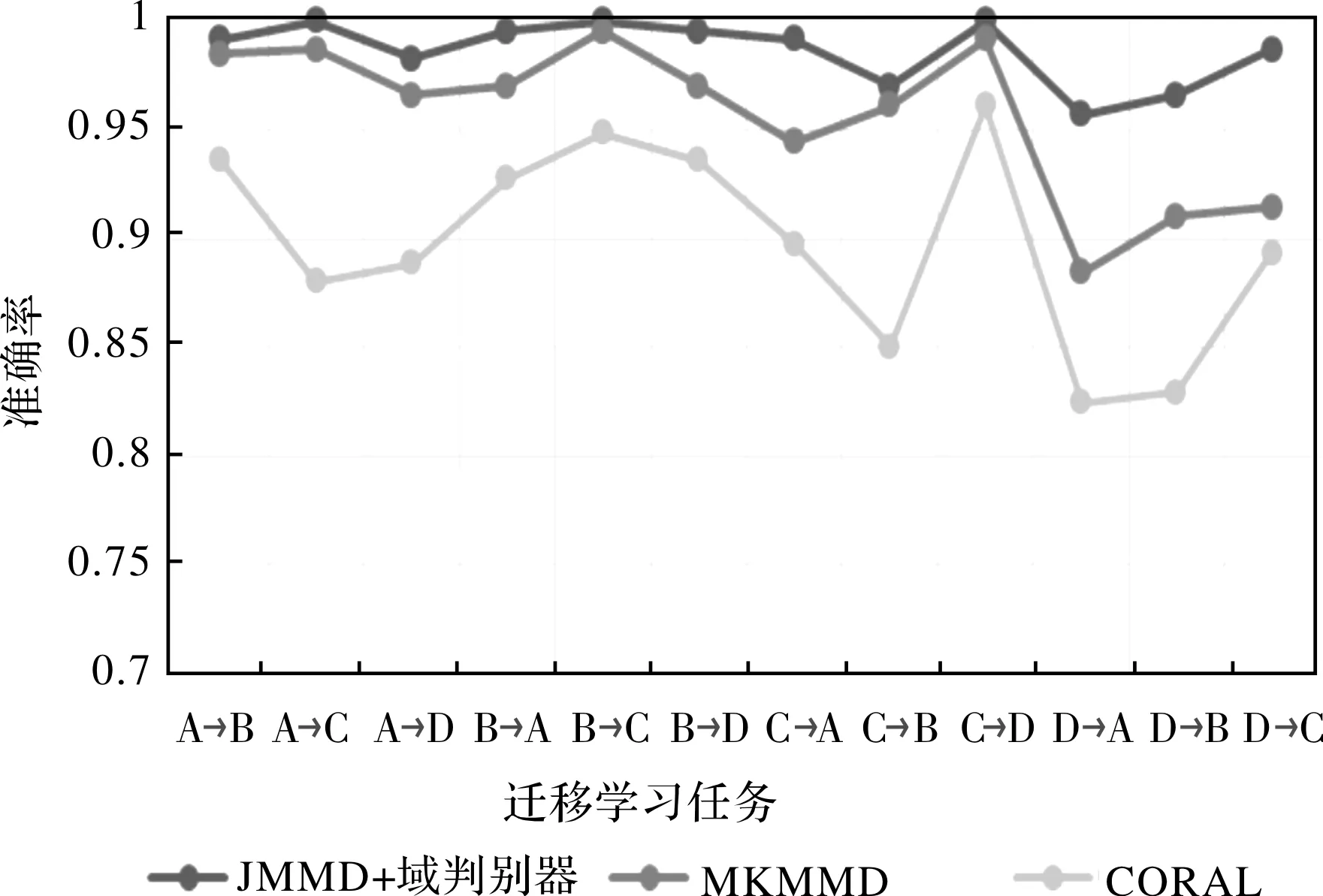
图6 三种域自适应模块在12种迁移任务上的诊断结果
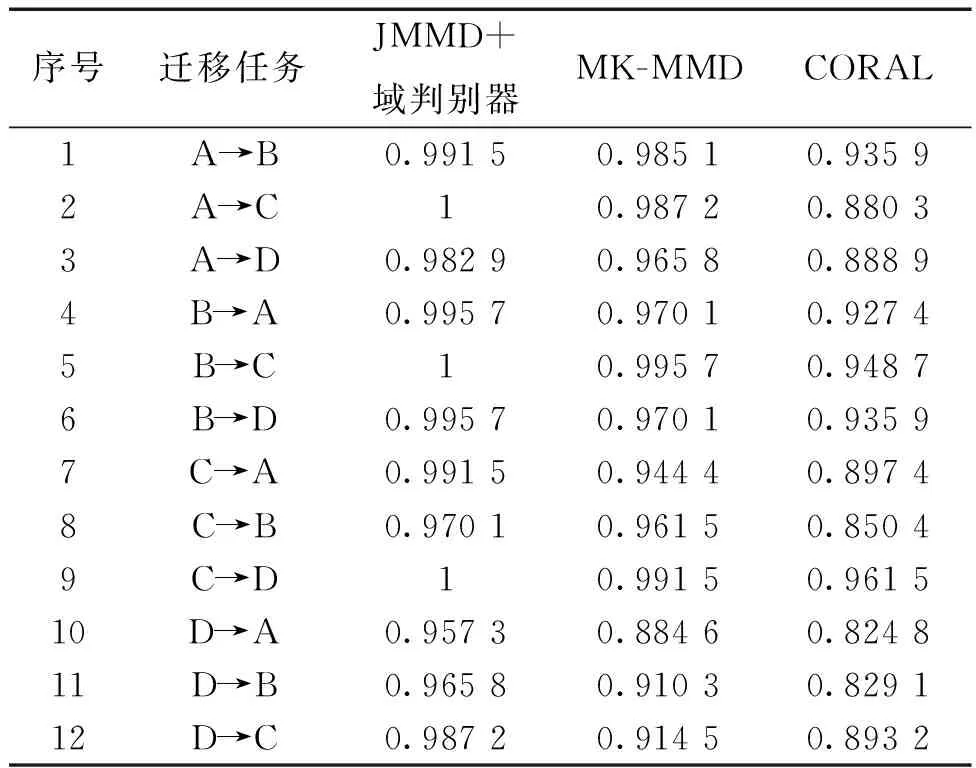
表4 不同的域自适应模块在12种迁移任务上的诊断结果
从实验结果可以看出,本文提出的JMMD+域判别器的方式比起其他迁移学习方法在迁移故障诊断上更具优势,并且诊断效果依次为:JMMD+域判别器最优,其次是MK-MMD,最后是CORAL。JMMD+域判别器的方式最高可以达到百分之百识别正确,在D→A识别效果最差,但也可以达到95.7%识别准确,而MK-MMD只有88.46%,CORAL只有82.48%。
4 结束语
针对变工况故障诊断问题,在深度学习框架中引入了迁移学习,提出了一种多尺度卷积联合适配对抗网络(MSCJACN),通过缩小两域数据间的分布差异,使得源域训练的模型可以很好地迁移到目标域,可有效解决目标域可用训练样本不足的问题。并且专门针对比较坏的一种情况,即目标域只有少量的无标签数据,在12组迁移学习任务上进行实验,均达到了很高的准确率。与其他迁移学习方法进行对比实验,MSCJACN的性能表现也更优。
