基于高光谱成像技术的发芽小麦分类研究
2022-11-23张玉荣卢冠镪张咚咚潘运宇周显青
张玉荣,卢冠镪,吴 琼,张咚咚,潘运宇,周显青
河南工业大学 粮食和物资储备学院,粮食储藏与安全教育部工程研究中心,河南省粮食产后减损工程技术研究中心, 河南 郑州 450001
我国人口众多,粮食安全不仅是维持社会稳定和发展的重要前提,也是实现国家安全的重要基础[1]。小麦收获前遇到阴雨天或在水分含量高时储藏均容易发芽,从而造成产量及品质降低[2-3]。小麦穗发芽严重地区的小麦一般可减产6%~10%,而较为严重的年份产量损失则高达20%[4],芽麦比例高于标准规定值也会导致小麦难以出售或低价出售而造成严重的经济失损。有学者认为依据小麦品质的变化可以将萌动和发芽归为一类[5],且发芽小麦含量不超过15%时,对其食用品质无明显影响[6],而有的学者认为发芽前后小麦的诸多营养成分均发生较大变化,对小麦品质的影响十分明显[7]。
在实际检验工作中依据GB 1350通过感官评价对小麦发芽进行判断,GB 1350中规定小麦发芽包括未突破种皮的萌动和突破种皮的发芽。突破种皮的可以通过肉眼直接观测挑选,而未突破种皮的萌动粒由于特征不明显,容易受到主观因素的影响,造成很大误差,目前为了更准确地判断小麦的阶段需要通过核磁共光谱法、降落数值法、免疫层析法、α-淀粉酶法、X-射线检测法等试验方法。由于生化实验测定以及分子实验测定操作烦琐、耗时、成本较高,对样品具有破坏性,因此探索一种快速无损检测小麦发芽的方法势在必行[8-9]。高光谱成像技术于20世纪80年代初期兴起,是光谱和图像相结合的快速无损检测技术。对于高光谱成像技术在农产品检测领域中的研究主要集中在果蔬、肉类以及种子相关品质检测等方面。目前高光谱成像技术在小麦籽粒检测方面应用比较广泛,琚书存等[10]利用高光谱获取健康小麦和感染赤霉病小麦的高光谱图像,通过主成分分析提取光谱特征,Fisher线性判别分析和BP神经网络模型进行识别,发现一阶导数(1ST)-主成分分析(PCA)-BP神经网络的组合识别赤霉病粒的正确度可达91.67%。郝传铭等[11]将高光谱图像进行波段选择和数据降维并与高分辨率图像融合识别小麦的不完善粒,对小麦发芽状态的无损检测提供了新思路。王新忠等[12]利用主成分分析结合支持向量机鉴别黄瓜种子的活力。Singh等[13]利用高光谱成像系统在1 000~1 600 nm范围内收集了正常小麦种子和发芽小麦的图谱,建立分类模型识别两种小麦,分类器的准确度为98.3%。Chen等[14]通过近红外高光谱成像系统收集不同时间发芽试验后的小麦高光谱数据,并将胚乳与胚分别处理,得出高光谱可以反映小麦发芽特性的结论。张婷婷等[15]利用多种预处理方法建立光谱与单籽粒小麦生活力模型,在比较不同特征提取方法后进一步优化模型,最终确定MC-UVE-CARS-SPA-PLS-DA模型对种子发芽率预测可以达到93.1%。
本文利用高光谱对不同发芽程度的小麦进行扫描,对比4种预处理方法筛选出最优的预处理方法。利用数据处理方法建立小麦发芽程度识别分类的最佳模型,探索一种快速、无损检测小麦发芽的方法,为精确地检测小麦发芽提供理论依据。
1 材料与方法
1.1 试验材料
采用河南省周口市2019年新收获的新麦26、百农307以及兰考198的小麦种子。在实验室清理后密封贮存在4 ℃的冰箱中。
1.2 芽麦制备
小麦发芽试验参考GB/T 5520,每2 h观察1次,挑选出不同发芽状态的小麦,包括鼓泡(小麦胚部吸水膨胀,但种皮还未破裂)、皮裂(小麦胚部种皮破裂且未分化芽尖)、露白(小麦胚部突破种皮且分化出2或3个芽尖)、芽0.5(芽长度为籽粒长度的1/2)、芽1(芽长度等于小麦籽粒长度)5类,干燥后备用。小麦种子发芽状态见图1。
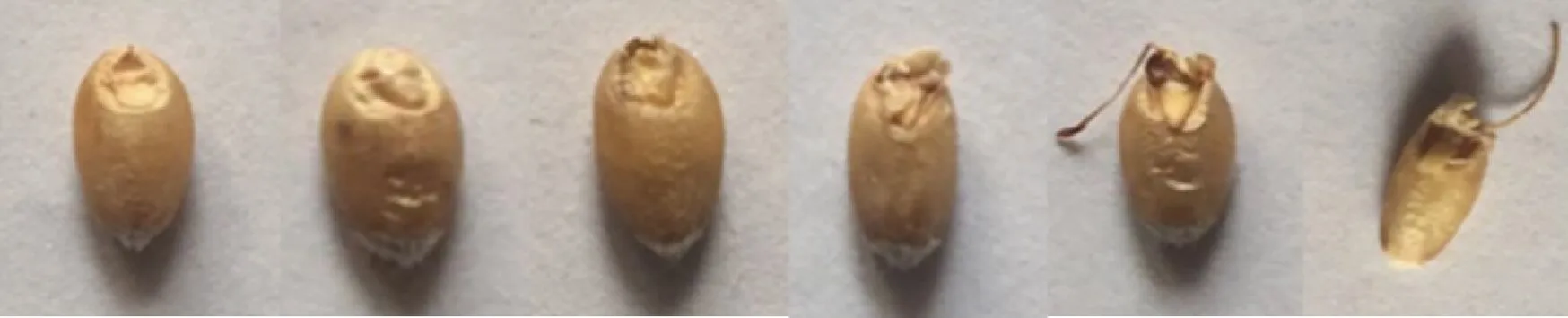
注:从左往右分别为原始小麦(未经过任何处理的小麦)、鼓泡、皮裂、露白、芽0.5、芽1。图1 小麦种子发芽状态Fig.1 Images of germination status of wheat seeds
1.3 试验方法
1.3.1 高光谱图像采集
近红外增强型的高光谱成像系统如图2所示,扫描光谱范围为850~1 700 nm。核心部分包括光源、光谱相机、电控移动平台、计算机控制软件等部分。为了使采集的图像更加准确地反映出样品的实际形态,优化后的采集参数设置:电机前进速度4.8 mm/s,曝光时间15 ms,帧速5,物距12.5 cm。每次取小麦籽粒20粒左右,腹沟朝下随机摆放于移动平台上,通过Spec View软件控制进行采集。采集前进行黑白板校正,去除暗电流以及外界光线对图像的影响。

图2 高光谱成像系统Fig.2 Hyperspectral imaging system
1.3.2 高光谱图像处理
黑白板校正后,采用二维中值滤波函数对原始图像去噪,然后采用大津法(OTSU)计算背景与小麦籽粒的阈值,转化为二值图像,随后利用开闭运算去除二维中值滤波处理,如图3e所示。在MATLAB中采用八连通域和regionprops工具获取小麦籽粒的像素点。根据质心位置以最小外接矩形将小麦籽粒框起来并将其标记排序,如图3f所示。提取出的小麦的像素点上下左右各加5个像素点成为一个感兴趣区域,如图3g所示。然后对小麦进行掩膜,结果见图3h,整体流程如图3所示。转化后的二值图像对去噪后原始图像进行遮挡,将背景完全去除,保留小麦籽粒的完整信息。对原始小麦进行掩膜去除背景,在ENVI 5.1中选中整粒小麦作为感兴趣区域,最终获得3 302粒不同发芽状态小麦的平均光谱数据。

注:a为原始图像,b为灰度图像,c为去噪后图像,d为二值图像;e为开闭运算处理结果,f为连通域获取标记,g为单籽粒小麦分割,h为掩膜结果。图3 获取感兴趣区域流程Fig.3 Flow chart of ROI
1.3.3 样本集与光谱预处理
高光谱的光谱数据集,可能有个别光谱数据偏离大量数据统计的情况发生[16],参与后续计算会影响试验结果的准确性,在一定程度上降低了淹没现象[17],故需对异常值进行剔除。通过Kennard-Stone(K-S)法以4∶ 1划分训练集2 631个、测试集658个。对小麦种子光谱曲线采取Savitzky-Golay(S-G)卷积平滑法、导数法、标准化等预处理。
Savitzky-Golay卷积平滑法[18]是目前应用较为广泛的去噪方法,移动窗口宽度(常称平滑点数)的影响明显低于移动平均平滑法。通过多项式对移动窗口内的数据进行多项式最小二乘拟合,其实质是一种加权平均法[19]。既能去噪提高分析信号的信噪比,又可较好地保留光谱中有用的信息。
导数法在光谱分析中十分常见。通过求导可以消除基线漂移或背景引起的误差,可提高原始光谱的分辨率和灵敏度,分辨出重叠峰,但会放大光谱中高频的噪声信号[20],根据采样点数不同可分为直接求导法和Savitzky-Golay卷积求导法(1ST、2ND)[21-22]。
标准化(autoscaling)又称均值方差化,光谱标准化变换是将均值中心化处理后的光谱再除以校正集高光谱阵的标准偏差光谱[23]。标准正态变量变换(SNV)主要是用来消除固体颗粒大小、表面散射以及光程变化对NIR漫反射光谱的影响[24]。该算法是对一条光谱(基于光谱矩阵的行)进行处理。
1.3.4 特征波长提取
高光谱扫描得出的光谱波长范围较大,包含信息量较大,相似的化学信息可能会产生相同的光谱信息。通过对一些数据降维的方法可以筛选出具有代表性、相关性较高的特征波长代替全波长的光谱建立模型,在满足模型性能的稳定以及准确度的情况下可以优化数据结构,提高运算速度[25]。选择竞争性自适应加权算法(CARS)[26],利用蒙特卡洛抽样根据偏最小二乘的系数选择特征波长[27]。
1.3.5 建模方法
最小二乘支持向量机(Least squares-support vector machine,LS-SVM)是一种传统的非线性监督型建模分析、模式识别和函数估计算法,采用最小二乘线性系统作为损失函数,通过解一组线性方程组代替传统SVM采用的较复杂的二次规划方法,从而降低回归或分类预测模型的计算负荷量,加快运算速度和准确度,核函数与正则化参数的取值会影响模型的泛化性能。
1.3.6 LS-SVM参数寻优
核函数与正则化参数的确定对模型性能起到关键作用,通常按照经验或试凑法,会影响模型精度[28]。PSO是一种进化计算技术,从鸟群觅食的行为受到启发,由Eberhart和Kennedy提出[29]。用无质量的粒子模拟鸟群中的个体,有速度与方向两种属性,在空间中寻找最优解,记录个体的最优解,并且与其他粒子交换信息。群体中的粒子根据个体当前最优解与群体当前最优解调整速度与方向,直到找到全局最优解[30]。原理是随机产生具有一定速度和方向、适应度的粒子,在空间中寻找最优解。
2 结果与分析
2.1 不同发芽状态小麦籽粒的平均光谱
将1.3.2中处理过的高光谱小麦图像在ENVI5.1中提取感兴趣区域内的平均光谱。由于光谱在850~870 nm以及1 650~1 700 nm处噪声较大,因此剔除这两部分光谱,取870~1 650 nm范围内光滑的波谱曲线进行分析。由图4可知,随着小麦发芽程度的增加光谱曲线逐渐变高,其中露白、芽0.5、芽1 小麦的光谱曲线几乎重合,与原样产生较大差别。皮裂期的光谱也明显高于原样,接近另外3种发芽程度较深的小麦。鼓泡期光谱也有小幅度地升高。由于发芽过程中淀粉、蛋白质等被大量消耗,很多C—H、O—H、N—H等化学键断裂或振动,致使出现了明显的波峰与波谷[31-32]。不同发芽程度的小麦内部化学信息的变化都十分明显地反映在光谱曲线上。
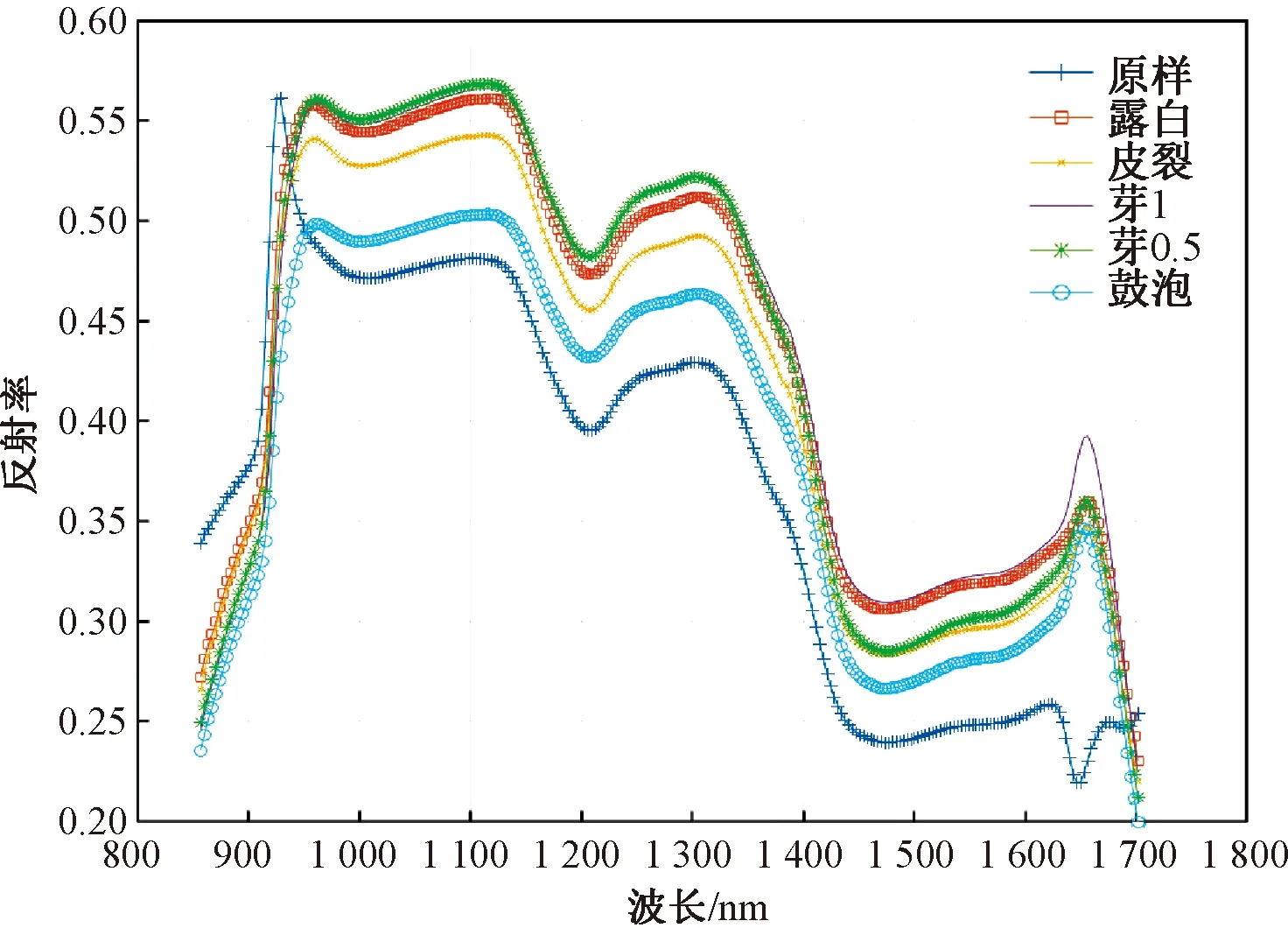
图4 6种发芽状态小麦种子的平均光谱Fig.4 Average spectra of wheat seeds in six sprouted status
2.2 光谱预处理方法对分类模型的影响
对小麦种子光谱曲线采取Savitzky-Golay卷积平滑法、导数法、标准化等预处理,结果如图5所示。将4种预处理后的光谱信息分别建立LS-SVM分类模型,识别结果见表1。与原始光谱模型相比,经预处理后,对不同发芽状态小麦的识别准确率均有提高,其中SNV识别准确率最高为91.70%,提升了2.44%,除芽0.5和皮裂外,各个发芽期小麦均在SNV时识别准确率最高。S-G(5点)处理结果不太理想,与原始光谱建立的模型基本相同,准确度提升有限。其中导数处理准确度提升不明显的原因可能是在放大特征的同时噪声信息也被放大。SNV预处理后准确度最高,因此将其作为最优的预处理方法。
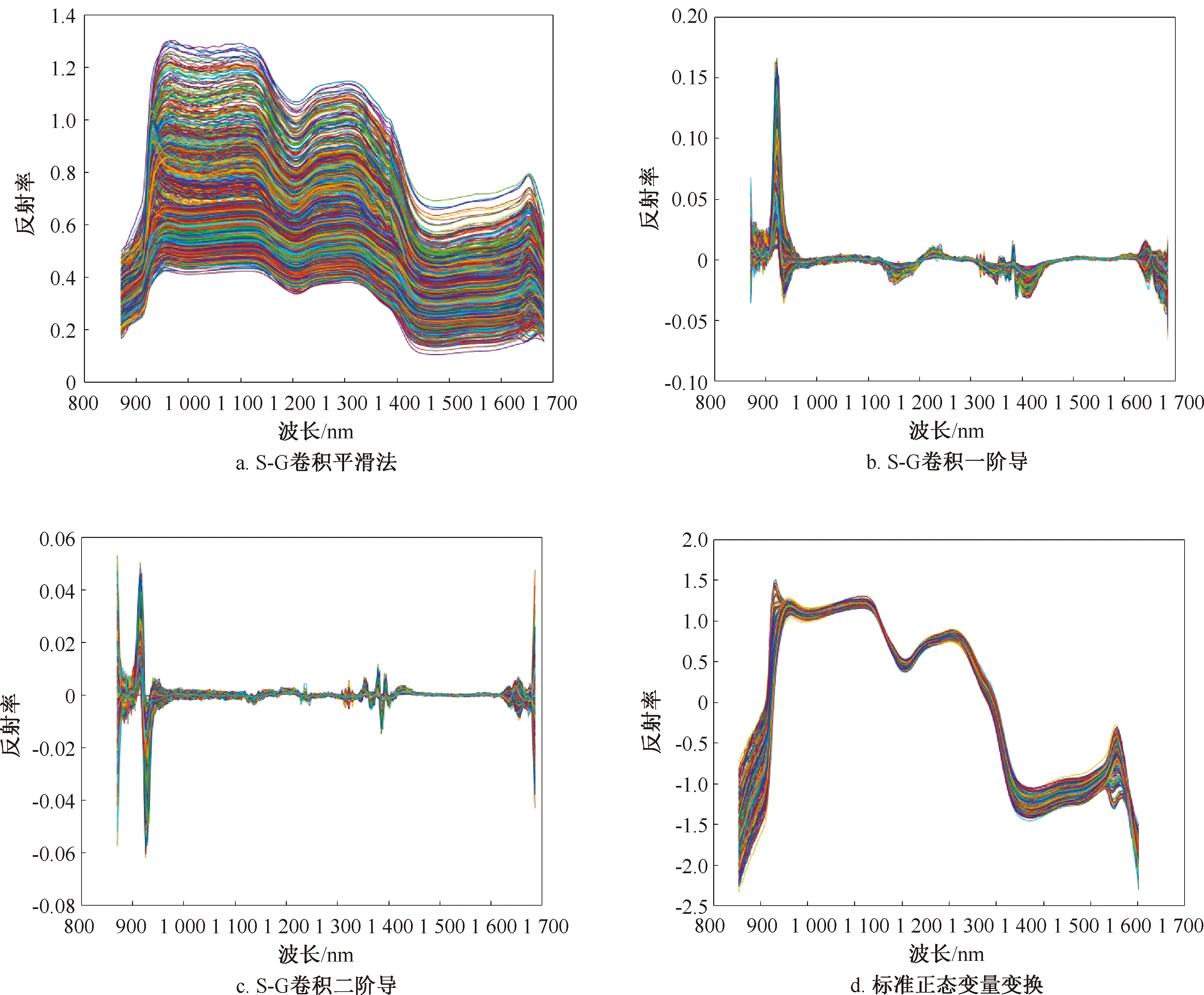
注:a、b、c窗口宽度为5。图5 小麦种子光谱曲线预处理结果Fig.5 Pretreatment results of spectra of wheat seeds

表1 基于不同光谱预处理方法建立LS-SVM的分类结果Table 1 Classification results of LS-SVM based on different spectral preprocessing methods
2.3 基于粒子群法的LS-SVM参数寻优
PSO参数设置:学习因子c1=1.5,c2=1.7,种群规模sizepop= 20,最大迭代次数200,惯性因子(w) 0.6,核函数选择径向基函数(RBF),正则化参数(gam)最小值(popmin)0.01,最大值(popmax)1 000,迭代最大速度Vcmax=k×popcmax,迭代最小速度Vcmin=-Vcmax,核函数参数(sig2)最小值(popmin)0.01,最大值(popmax)100,迭代最大速度Vgmax=k×popgmax,迭代最小速度Vgmin=-Vgmax。适应度函数为训练集的识别准确率。研究前将所有变量做归一化处理,作为训练集和测试集输入函数。优化SNV-LS-SVM模型的适应度变化曲线见图6,得到gam和sig2的最优解分别为132.437 7和79.19,训练集的识别准确度为100% 。
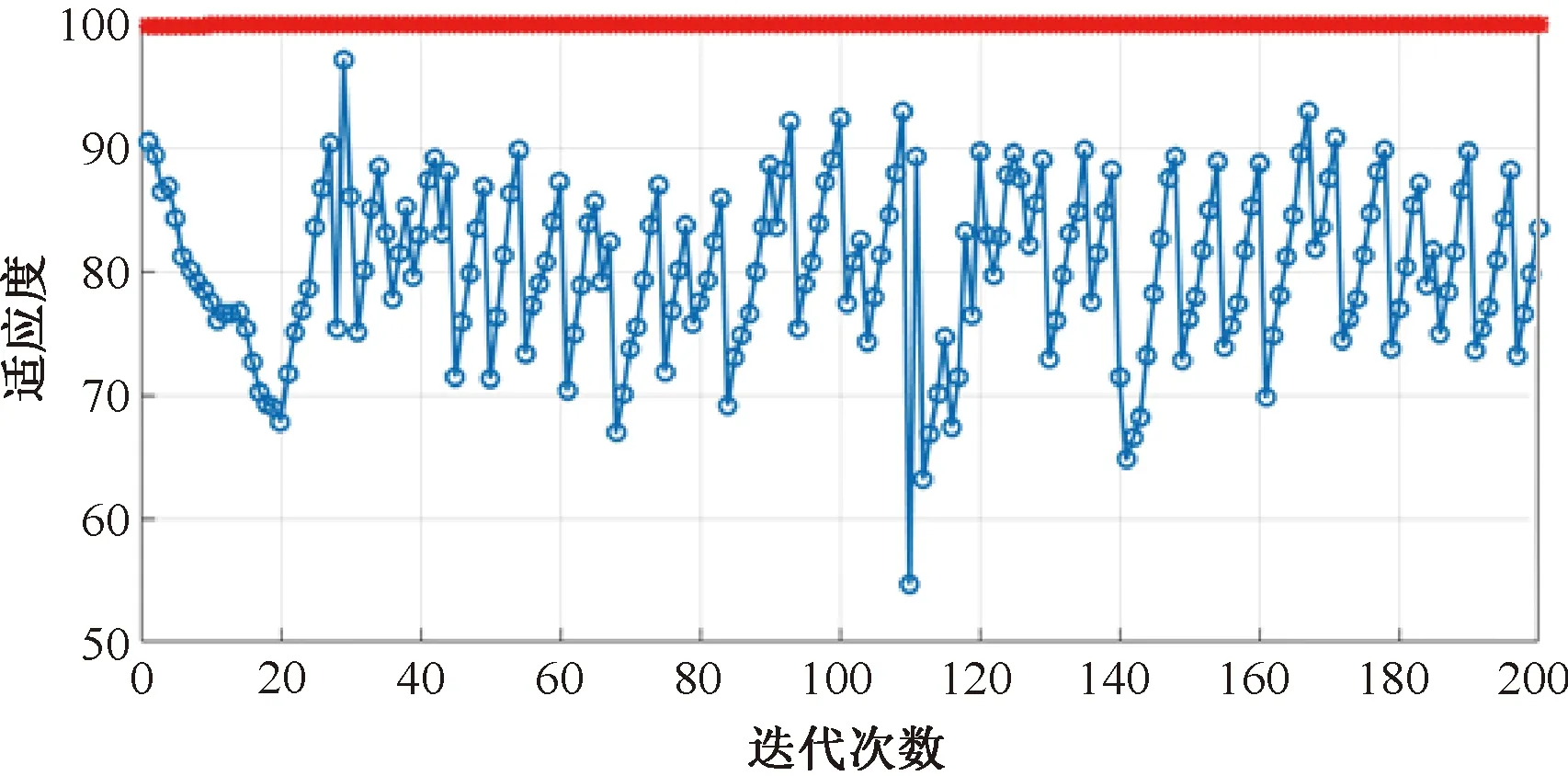
图6 基于PSO算法优化SNV-LS-SVM模型的适应度曲线Fig.6 Adaptation curve of SNV-LS-SVM model optimized by PSO algorithm
将优化后的参数代入发芽小麦分类识别LS-SVM模型中对测试集进行预测,分类准确率见表2。由表2可知,gam和sig2经PSO优化过后建立的模型对各个发芽状态的小麦识别率均有提高,其中对原样、露白、芽0.5的小麦识别的准确率提升比较大,分别为2.54%、2.54%、2.57%。与优化前相比,部分芽1的小麦被识别成芽0.5状态下的小麦,导致对芽1小麦的识别率下降;整体的识别率提升了1.57%,表明参数优化起到了良好的效果。

表2 PSO优化LS-SVM模型的分类结果Table 2 Classification results of PSO optimized LS-SVM model
2.4 特征波长提取与建模
利用竞争性自适应重加权算法(CARS)对经过SNV预处理的光谱进行特征波长的选取。衰减指数法(EDF)根据所占权重剔除相关性不大的波长。由图7a可知,在50次的采样过程中,采样的前期变量保留数快速下降,后期采样保留数下降较为缓慢,充分说明在筛选变量过程中的“粗选”和“慢选”两个阶段。图7b是交叉验证的标准差的变化曲线,采用的是十折交叉验证。由图7b可知,交叉验证标准差随着采样次数的增加,呈缓慢降低又急速升高后趋于稳定。在第14次采样时交叉验证标准差达到最小值,为0.778 7。说明前14次采样,光谱中大量的无关信息被去除,之后标准差增大说明光谱的特征信息被逐渐去除,导致模型效果变差。由图7c回归系数路径可知,标准差最小次数为14次。因此保留采样14次后的波长,共提取49个特征波长在850~1 700 nm分布情况,如图8所示。
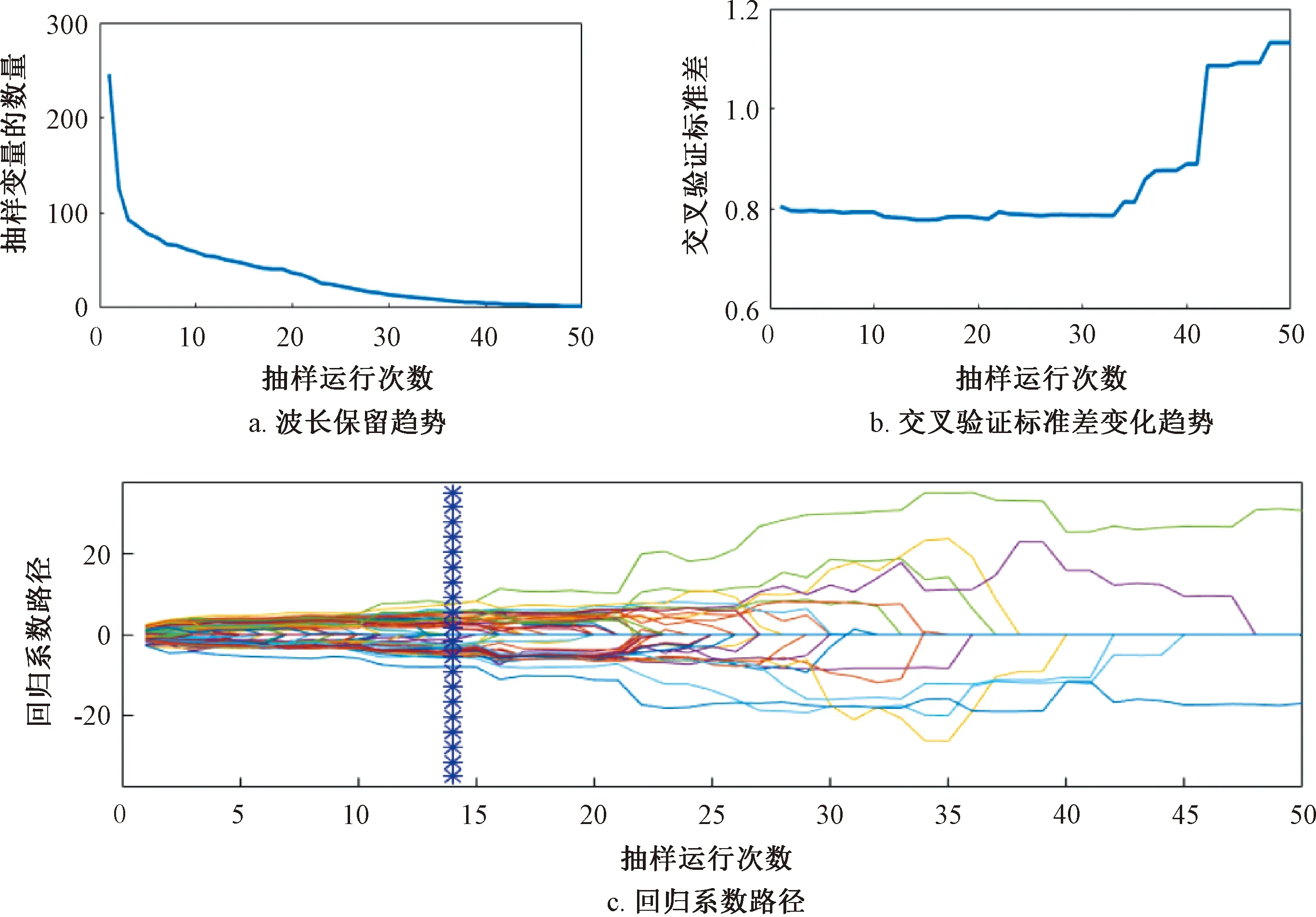
注:“*”表示标准差最小的次数。图7 CARS筛选小麦种子光谱特征波长过程Fig.7 Spectral characteristic wavelength process of wheat seeds screened by CARS
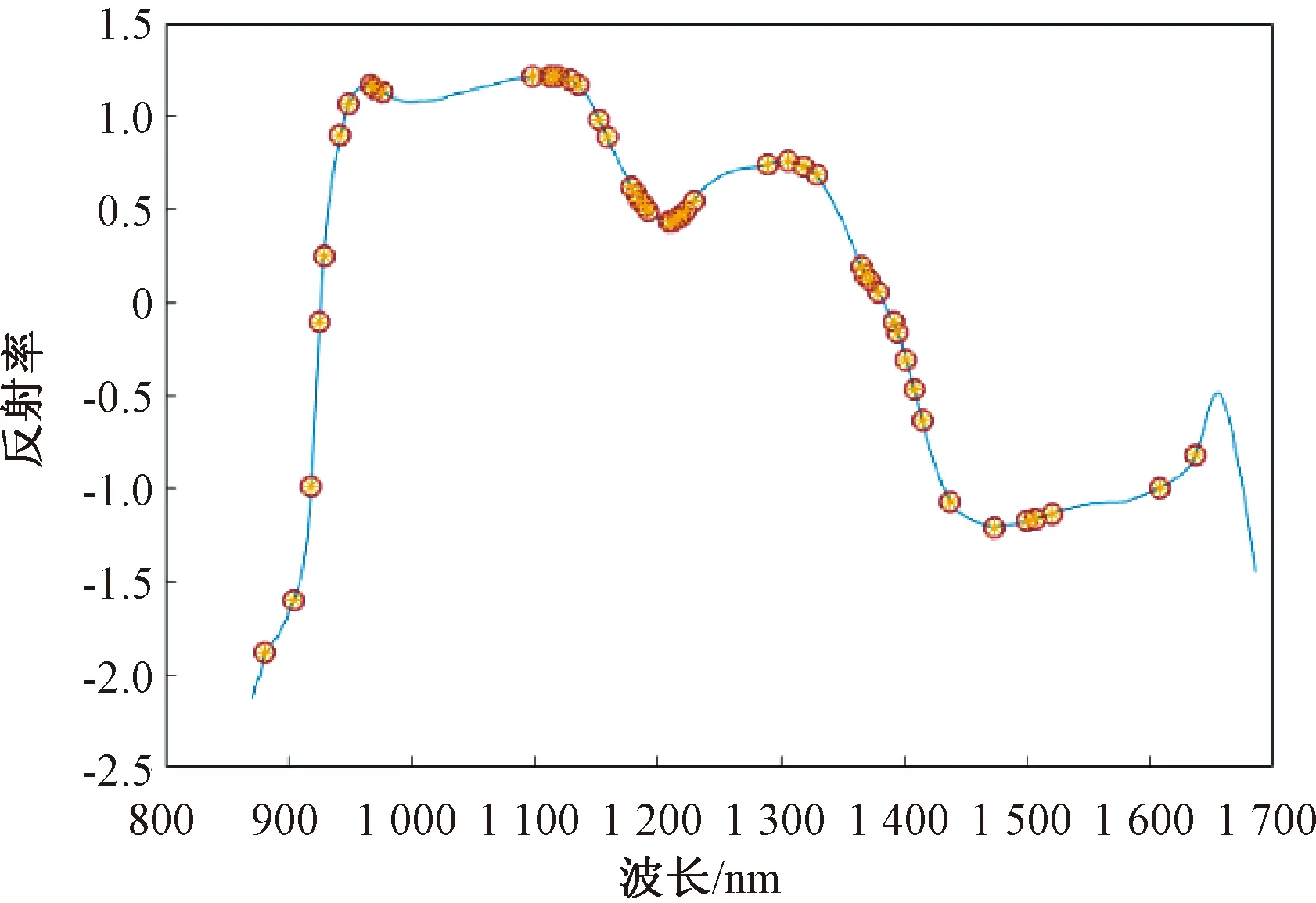
图8 特征波长提取结果Fig.8 Extraction results of feature wavelength
筛选出来与小麦发芽状态相关性最好的49个(全波段的19.14%)特征波长,进行SNV处理,将其作为自变量输入到PSO优化后的LS-SVM模型中,得到简化后的分类识别模型,识别结果如表3所示,与全波段的小麦发芽状态的识别模型(表2)进行比较可知,原样、鼓泡、皮裂以及芽1状态下的小麦识别准确率均有较大提升,分别提高了2.48%、3.80%、2.13%、4.05%,而露白与芽0.5状态下的小麦准确度均有不同程度的下降。其原因可能是特征波长提取后仅保留了19.14%的光谱信息,剔除的光谱信息中有部分与这两种发芽状态相关性较好的信息被去除,参与训练信息减少致使模型的性能降低,而这部分信息对另外4种发芽状态的小麦噪声信息较多,剔除后提升了模型的性能。将256个波段减少至49个波段,并且整体识别准确率为94.13%,提高了1.06%,说明CARS算法来选择特征波长是合适的,对模型性能的提升有一定帮助。

表3 特征波长下POS-SNV-LS-SVM分类识别结果Table 3 Classification and recognition results of POS-SNV-LS-SVM under characteristic wavelengths
2.5 分类结果可视化
为了将分类结果更加直观地表现出来,将获得的小麦高光谱图像由最优模型识别,将不同发芽状态的以伪彩色形式显示出来,并统计个数,计算发芽小麦占比,结果如图9所示。图9中右侧彩条的颜色从下向上分别代表原样、鼓泡、皮裂、露白、芽0.5与芽1,共6类。由于PSO-SNV-CARS-LS-SVM的整体准确率为94.13%,因此仍保持原来6类的输出结果。其中将皮裂、露白、芽0.5、芽1小麦共有449粒小麦统一归为发芽小麦,计算发芽占比。模型预测658粒中发芽小麦有448粒,发芽小麦实际占比为68.24%,预测值为68.08%,准确率为99.78%。图9中共有18粒小麦,其中,有1粒发芽小麦错分为鼓泡小麦,预测发芽小麦有12粒,占比为66.67%,因此,预测发芽小麦占比的准确率为97.71%。

图9 发芽小麦种子光谱分类结果可视化Fig.9 Visualization of spectral classification results of germinated wheat seeds
3 结论
采集不同发芽状态小麦的高光谱图像并提取小麦籽粒的平均光谱,建立全波段的偏最小二乘回归(PLSR)、LS-SVM的分类模型,通过比较测试集的准确率,选取准确率更高的LS-SVM作为建模方法,同时使用4种方法对原始光谱进行预处理,再次建立LS-SVM模型,比较发现SNV处理后的光谱建立的LS-SVM模型识别准确率更高,再通过PSO对LS-SVM模型的正则化参数(gam)与核函数的参数(sig2)进行寻优,将结果代入模型中识别准确度提升到93.14%。通过CARS算法选取了49个特征波长,建立PSO-CARS-SNV-LS-SVM模型,准确率为94.13%,与全波段相比稍有提升。最后将分类结果可视化,将皮裂期及以后的3类算作发芽小麦计算芽麦占比,对预测集658粒小麦的芽麦识别准确率为99.78%。表明了利用高光谱成像技术,将化学计量学和图像处理技术相结合,进行鉴别不同发芽小麦种子是可行的。本研究为快速、无损、便捷检测小麦种子发芽分类研究建立了相关的分类模型和对高光谱成像技术检测小麦种子发芽程度提供了理论依据。
