复杂场景下无人驾驶模拟仿真
2022-11-23王军茹陈子岐王军平
王军茹,陈子岐,王军平
(1.北京信息科技大学 自动化学院,北京 100192;2.中国科学院 自动化研究所,北京 100190)
0 引言
从全人类驾驶到全自动驾驶的过程被国际汽车工程学会(Society of Automotive Engineers,SAE)分为6级,即SAE Level 0级别至SAE Level 5级别。目前大概处于2.5~3级。无人驾驶的研究方法有4种:1)闭门测试:即简单测试场单车测试;2)蛮力测试:即让无人驾驶汽车在实际道路网上行驶数百万英里;3)测试场综合测试:即在包含高速公路、隧道、乡间小路、城市交叉口等各种各样的道路形式上进行测试;4)交通仿真+测试场联合测试:即先采取模拟的方式进行测试,基于此开展各种各样复杂场景的测试研究,再进行测试场测试。“交通仿真+测试场联合测试”是当前最领先的测试研究方法,也是各研究机构和高校在无人驾驶领域研究的热点[1]。
近几年来由于深度学习的兴起,人工智能的飞速发展,传感器的更新换代,以及机器视觉的应用,自动驾驶成为人工智能领域最热门的研究方向之一。自动驾驶高速发展的同时,也面临着高精度传感器的标准化,通信、大数据处理以及立法问题等诸多挑战。近几年随着通用处理器(general processing unit,GPU)的飞速发展,云机算力呈指数性提高,使得模拟环境的仿真程度与真实环境相差无几。面对诸多挑战以及关系到行车人员的生命财产安全,基于无人驾驶模型的模拟仿真具有极其重要的意义[2]。
深度学习是推动人工智能革命最重要的技术之一,从图像分类到文本识别,基于深度神经网络的模型在实验中不断被证实明显优于传统模型。实现车辆自动驾驶需要大量标签数据进行训练,而深度学习领域的发展为收集和维护这些数据集提供了便利条件[3-4]。基于视频摄像头拍摄和感知驾驶周围环境,进而产生驾驶车辆所需控制信号,进行无人驾驶模拟仿真是目前无人辅助驾驶的主要研究方向[5-7]。无人驾驶模拟仿真中目前还存在着复杂场景的数据难以融合、动态环境下建模困难和稳定性差及精度低等问题。深度强化学习不仅能利用现有数据,还可以通过对环境的探索获得新数据,并循环往复地更新迭代现有模型。因此目前在无人驾驶研究中深度学习适合于已知场景特征数据下的模拟仿真,而深度强化学习更适合于现实场景动态变化情况下的训练和测试[8-11]。
本文主要研究在深度学习框架下无人驾驶模型对周围复杂场景的感知、图像识别,并在行进状态下对模拟仿真控制决策的传统算法进行改良,在卷积神经网络(convolutional neural network,CNN)的基础上对图像主要识别区域进行重新划分,以达到匹配硬件条件来减少训练时间和提高训练精度的目的,对无人驾驶模型在行进状态下决策控制做出适应环境变化的调整以达到决策的准确性。
1 仿真方案设计
本文设计的无人驾驶模拟仿真方案分为3个部分:复杂场景的特征感知及训练数据融合到动态环境中;无人驾驶模型的建立和训练;最后于AirSim平台进行自适应仿真测试对模型保真度进行分析。模型的保真度是对模型与真实对象间差别的描述,保真度越高越接近真实的对象,无人驾驶仿真模型的保真度就是仿真与真实无人驾驶车辆行进控制的接近程度。系统整体设计方案如图1所示。
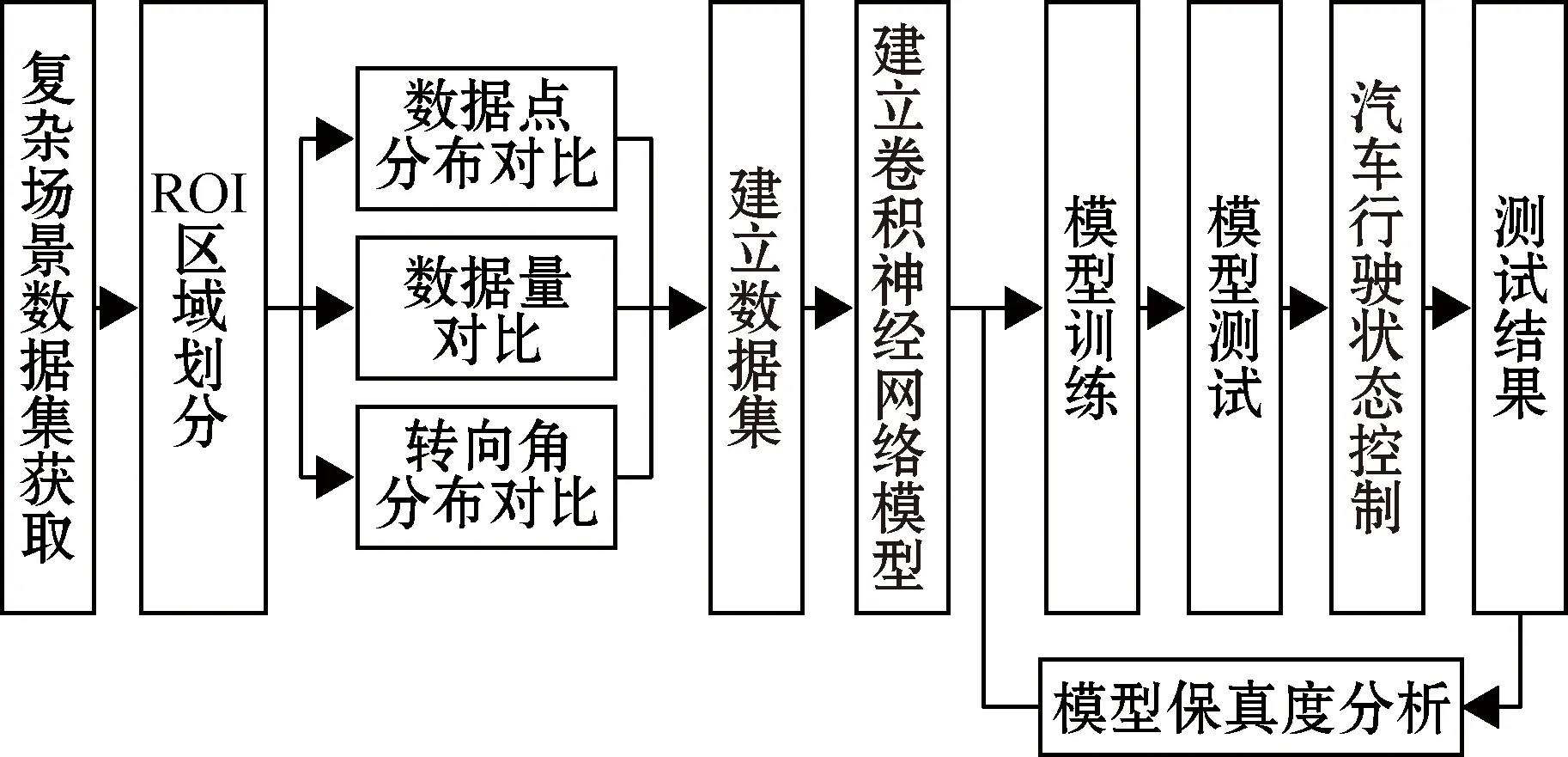
图1 整体设计方案
从场景图像处理开始,采用AirSim平台作为模拟器,使用微软在2018年采集的山地场景图像数据集作为复杂场景的初始图像数据集。从版本 1.2 开始,AirSim 能够支持多载具,允许创建多个汽车来控制它们,但多个车辆控制非常复杂。本文研究复杂地形环境下单个汽车无人驾驶仿真控制。
本文采用在机器视觉和图像处理中使用频率最高的关注区域(region of interest,ROI)技术,勾勒出需要处理的区域(路面场景),并对场景图像进行不同驾驶策略的分析。在处理数据集方面采用matplotlib函数对复杂场景数据集进行分类归纳,最终分析数据点的分布并对缺少的训练数据进行补齐和数据融合,将最后得到的数据集进行整合用于模型训练和测试。
在场景图像数据集建立完成后,进行基于Anaconda平台的Python3.5语言的算法编程,采用Keras API的深度学习框架作为前端,与之匹配的TensorFlow作为后端架构,并采用在深度学习无人驾驶领域表现良好的CNN结构进行模型的构建,在本地进行多个周期的模型训练和测试,得出不同损失值的模型。
2 复杂场景特征感知
采集和处理场景数据是无人驾驶模拟仿真的第一步,首先需要对场景数据进行ROI区域增强。场景数据中,除去与驾驶策略相关的路面情况外,还有诸多干扰因素,如天空、飞鸟和远处的山脉等。故如果针对整张图像进行处理,会大大增加处理时间,且由于天空光照的存在,也势必会对路面造成影响。matplotlib函数中原算法ROI区域划分较大,除囊括了行驶道路以外,还包括了一部分远端相对模糊的路面和部分无关环境要素(树木、山坡等)。如图2显示的是原算法策略ROI区域增强效果。本文舍弃原算法中对更远处场景做出预处理来提高后期模型训练的长时策略;针对于匹配小数据量的训练集对其进行改进,专注于短期路程的即时策略。

图2 原算法策略ROI区域增强
改良算法策略ROI区域增强效果如图3所示。算法改良后虽然处理场景数据时减少了对更远距离场景的长久规划能力,但却在短距离的即时策略中能保证更高的精确度,综合设计硬件条件,减小ROI区域能最优化处理速度和精度。从图2和图3对比可以看出,改良后的ROI更偏重当前路面的复杂情况,同时少量兼顾未来路况,在节省算力的同时,能更精确提取当前环境特征,提高了在山路中山石、坡路、急弯等复杂路况的鲁棒性。

图3 改良算法策略ROI区域增强
本文中驾驶策略分为正常行驶策略(normal)和转向策略(swerve)两种,分别对应驾驶中直行策略和转弯策略。不同策略下行驶情况如图4所示。
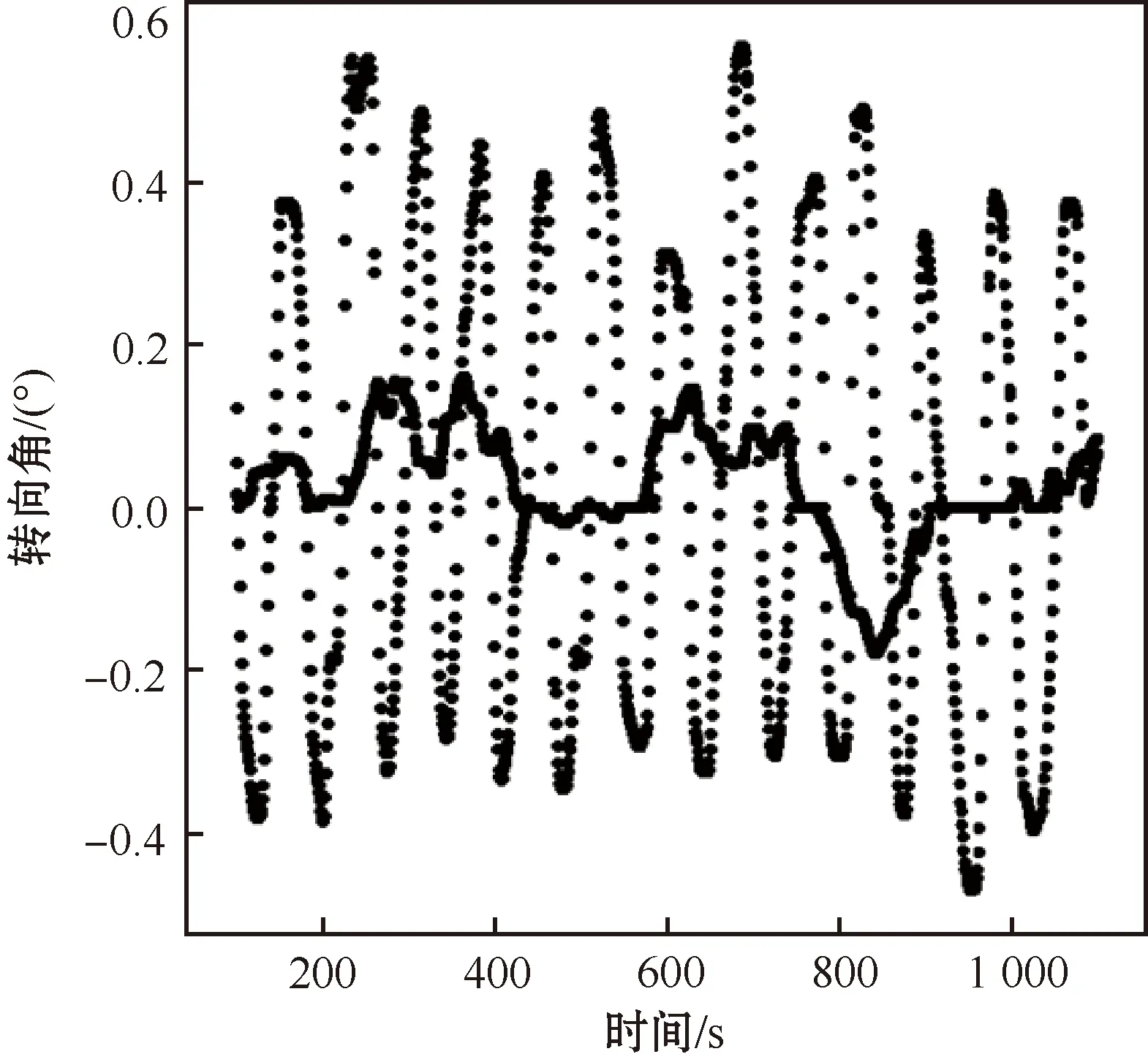
图4 不同驾驶策略数据点分布
从图4可以看出,两种不同的行驶策略存在明显差异:实线表示正常行驶的驾驶策略,从数据中可以直观发现其转向角基本为零,这就能保证汽车可以正常沿直线行驶而不至于偏离正常车道过多;虚线代表的是转向策略,很容易发现其转向角在一个很大范围内不断波动,而将此策略代入汽车模型中,就会出现汽车在道路上左右摇摆的状况,导致汽车行驶状态不稳继而引发安全问题。
将图4中不同行驶策略下的场景数据点数量进行汇总计算,其中有25.51%(11 925个)的数据点为转向策略,有74.49%(34 814个)的数据点为正常行驶策略,转向策略可供使用的场景数据较少,会导致训练不完整。本文设计的模型完全依靠场景数据集来提供训练信息和测试数据。为了能处理模型最终遇到的所有可能出现的急转弯,并在偏离道路时能进行自我修正,需要想办法来解决转向数据点不足的问题。本文采用了垂直翻转公差方法解决转向数据点不足,具体方法是:对于搜集到的有效数据点,把图像绕Y轴翻转,同时将转向角的符号也取反。这样可实现可用的数据点数量的翻倍,进行简单的数据融合就可以将其全部编入训练集中。
最后使用matplotlib对搜集到的场景数据进行汇总和观察。正常策略和转向策略转向角分布分别如图5和图6所示。图中横坐标为归一化的角度,纵坐标为转向角归一化处理后单位时间(1s)内在正常策略和转向策略下转向角出现的次数,即出现的频率。从图中可以看出,正常行驶策略中,方向盘的角度几乎总是为0,而在模型仿真行驶过程中,如果这部分没有被降采样的话,会导致模型总是将转向角预测为0,导致汽车将无法转弯;而在转弯策略中,汽车出现了急转弯策略而不是出现在正常行驶策略中,也正验证了上文中对可用数据点场景图像Y轴翻转获得新数据点的操作可行。
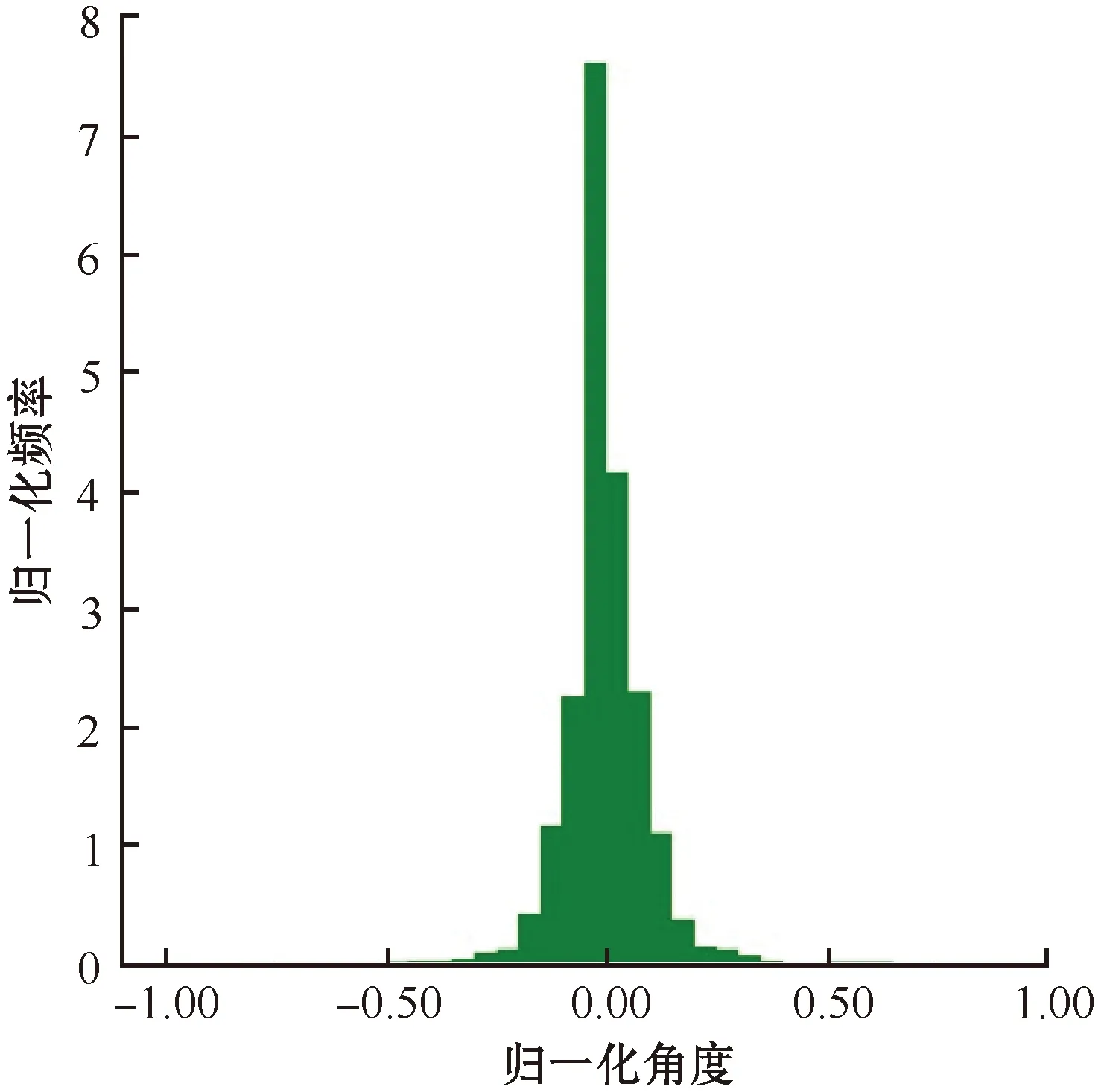
图5 正常策略转向角分布
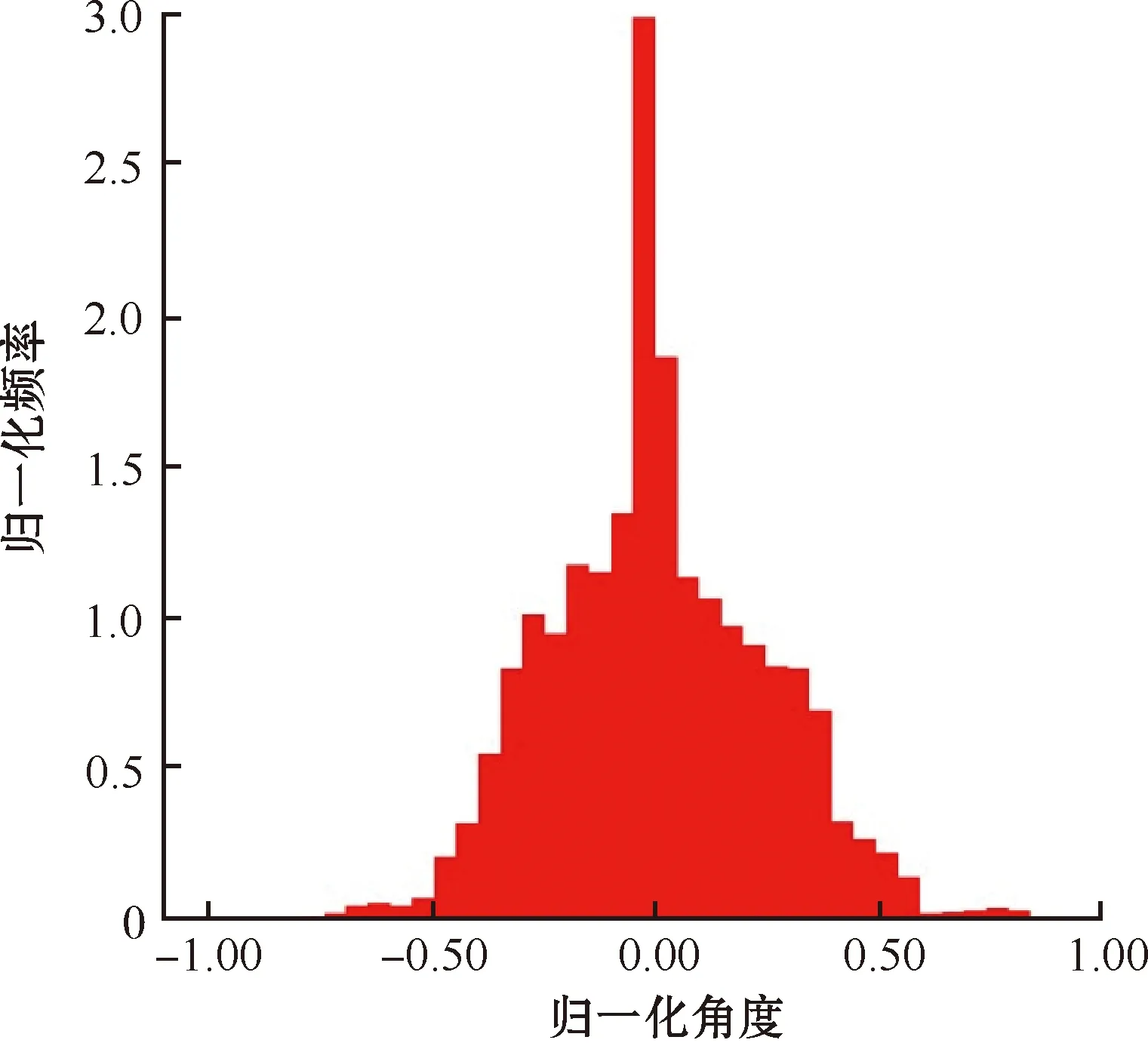
图6 转向策略转向角分布
在此基础之上,需要将原始场景数据合并为适合训练的压缩数据文件。本文使用h5py函数生成.h5文件,此格式支持大型数据集而无需一次性将所有数据读入内存,且可以与Keras无缝对接。
3 静态模型创建及训练
3.1 卷积神经网络模型建立
系统模型由输入层、3个卷积与池化层、2个全连接层和输出层构成。整个系统的输入是感知的场景特征数据和汽车的状态参数,输出的是汽车的转向角,其中汽车的状态参数包括转向角、油门和刹车的状态以及图像初始缓冲和初始位置等,通过状态Input函数输入模型。此次设计的卷积神经网络架构如图7所示。
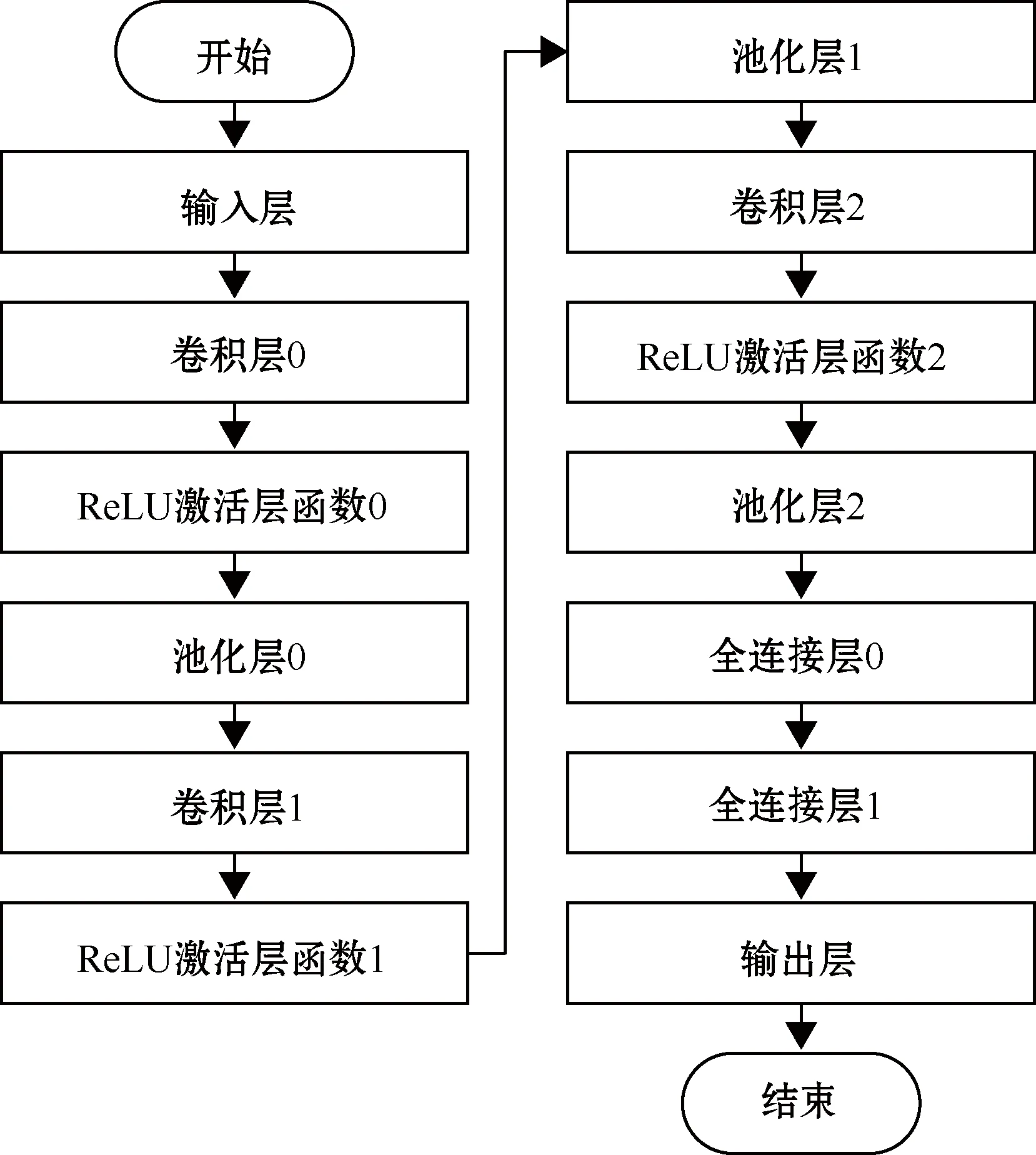
图7 卷积神经网络架构
Keras中的Conv2D是最常用的二维卷积层,可对二维的输入进行卷积训练。在第一层“convolution0”时设定其输入的“input_shape”参数为样本图像训练集里的参数。img_stack=Conv2D(16,(3,3),name=“convolution0”,padding=‘same’,activation = activation) (pic_input),在第一层卷积“convolution0”中,设定其卷积核的数目即输出的维度为16,且卷积层大小为(3,3)。padding为Keras中Conv2D的补0策略:padding =‘valid’表示只进行有效卷积而不对边界数据进行补0,即不处理边界数据;padding = ‘same’则与之相反。在卷积神经网络中补0是最为常见的操作,且在无人驾驶的图像识别方面,不对边界数据进行处理很容易造成图像处理不完全,导致汽车驾驶过程中出现无法判断的局面,故此选择补0策略。其部分结构具体如图8所示。
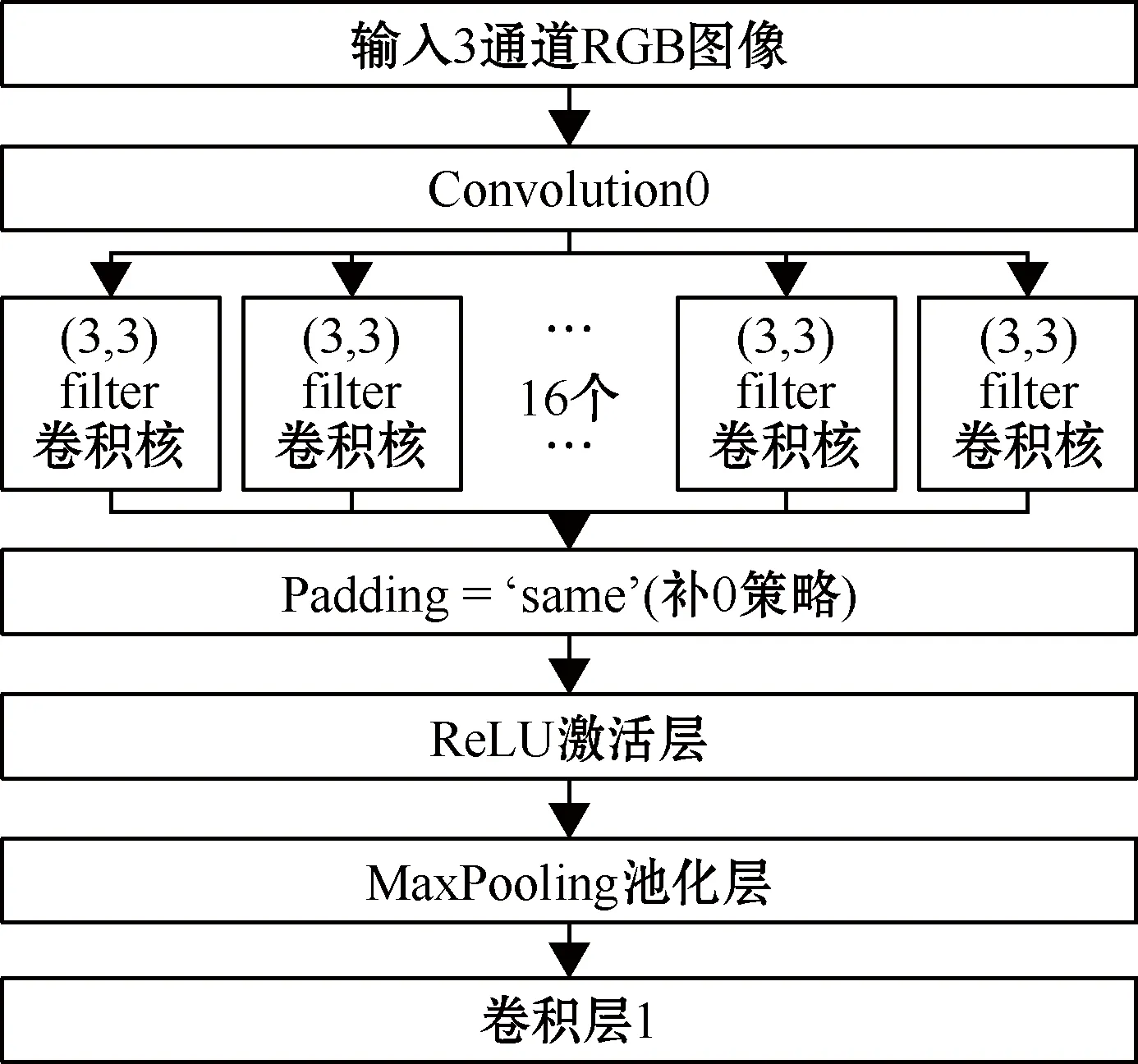
图8 部分卷积层与池化层结构
使用MaxPooling2D函数进行池化层的添加。当输入经过卷积层时,若感受视野比较小,步长stride比较小,得到的特征图(feature map)比较大,可以通过池化层来对每一个feature map进行降维处理,输出的深度不变,依然为feature map的个数。池化层也有一个池化视野(filter)来对feature map矩阵进行扫描,对池化视野中的矩阵值进行计算,MaxPooling即为取池化视野中矩阵的最大值。模型中的全连接层通过Dense函数来进行添加,全连接层起着将所有参数汇总整理并从所有参数中选出最具代表性的参数的作用。
由AriSim平台收集到的数据为三通道的RGB图像。待优化参数过多易导致模型过拟合,为避免这种现象,先对原始图像进行卷积特征提取,把提取到的特征导入全连接层网络,再使用全连接网络计算出分类评估值。在卷积层末尾和全连接层中采用dropout函数,目的在于舍弃一部分数据而防止过拟合现象发生。图7中两个全连接层具体设计如图9所示,图中从“第二层结点”(6 948个)到“fiter全连接层结点”(64个)进行一次全连接,从“fiter全连接层结点”到第三层结点(10个)进行第二次全连接,主要作用是对数据进行降维操作。
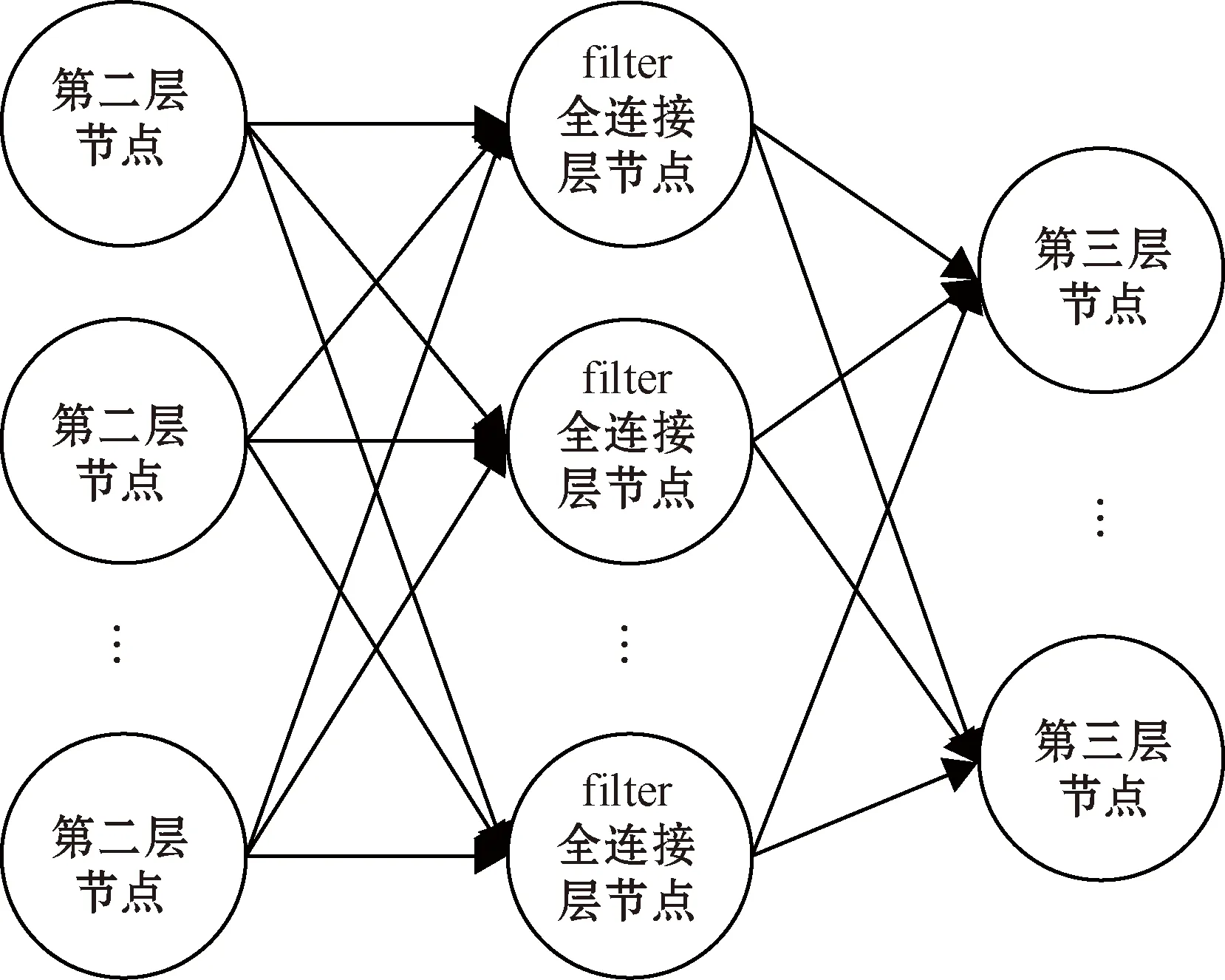
图9 全连接层结构
3.2 模型训练结果与损失值
模型训练结果和损失值如表1所示,表中为两组训练结果。从训练过程中可以看出模型两轮训练分别在第5次和第3次损失值骤降,而大多数损失值超过0.001的模型则基本由于损失值过大而无法使用。经过多轮对比和筛选后,最终拟选用损失值在0.000 8以下的模型进行模拟仿真环境下的测试。
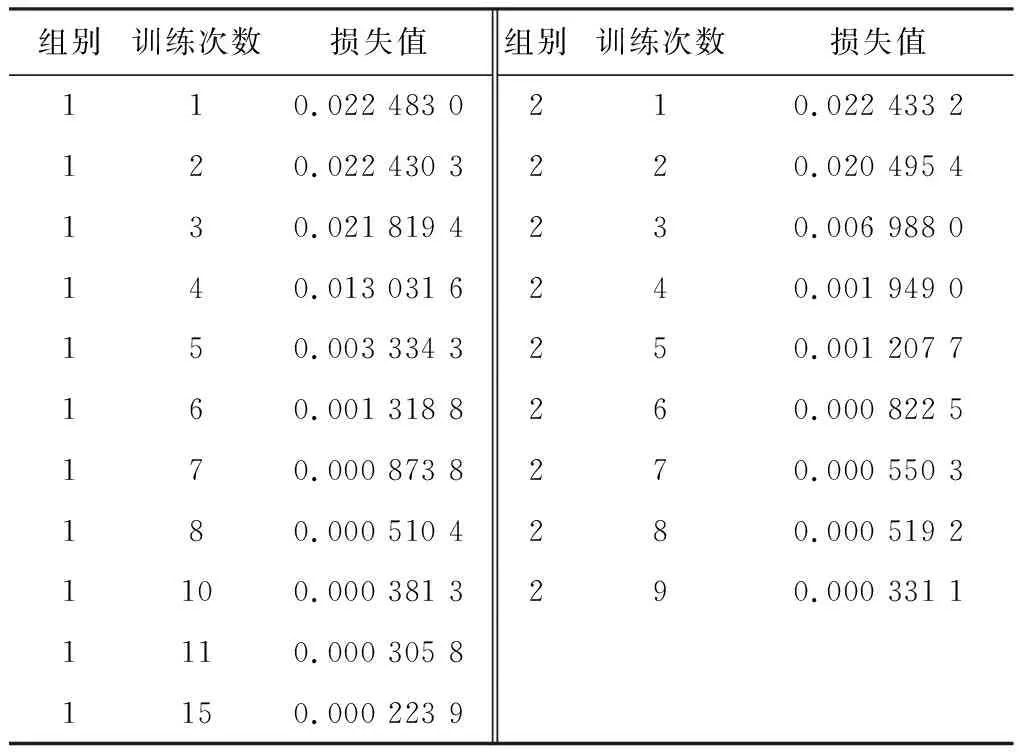
表1 两组已训练模型与损失值
4 动态参数调节与模型测试
无人驾驶车辆仿真在动态环境下首先需要一个网络摄像头进行环境量的输入,即场景获取;其次要导入上一步训练好的模型;之后在设定汽车初试状态后,进行车辆行进状态控制。
4.1 初始状态设定
自动驾驶汽车初始状态的设定如表2所示,即转向角为0,油门和刹车均处于关闭状态;图像缓冲初始为一个可填入59×255的3通道RGB图像数组的numpy的0数组;初始位置则返回一个1行4列的0数组用来为后续实时位置更新填补。
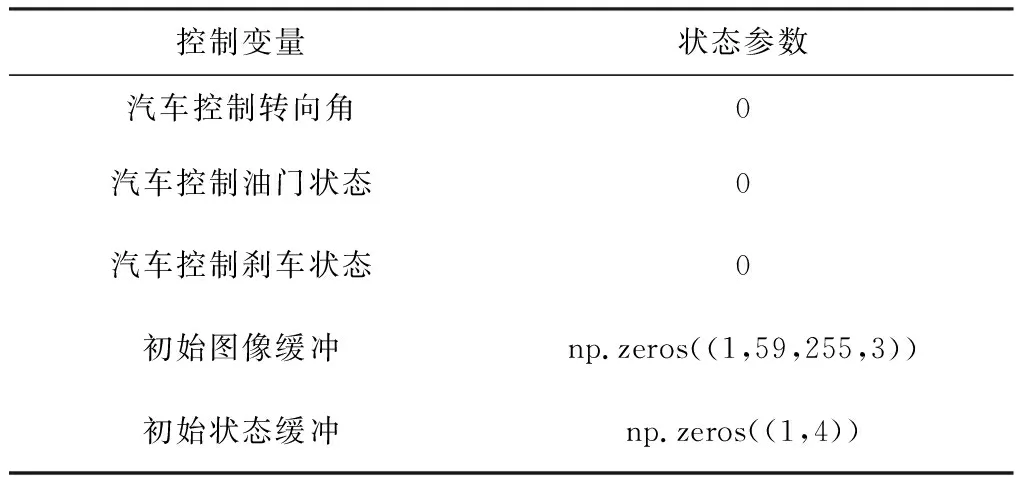
表2 汽车初始状态设定
4.2 动态环境状态控制参数调节
原始前端测试算法并未对自动驾驶汽车动态环境下的行进状态进行控制,在针对处理的图像进行静态建模后,对动态行进仅仅设定了一个初始速度,并无动态环境中的行进控制,这种参数设定方式在动态环境下自动驾驶汽车模型极易在行进过程中失控,导致出现事故。
本文将算法进行改进,添加了对汽车车速过低或超速时的控制来应变复杂的道路场景,算法流程如图10所示。当车速低于3.5 m/s进行加速,车速高于5.5 m/s时进行减速处理,即将车速控制在3.5 m/s和5.5 m/s之间。系统中原算法对汽车行进状态控制仅有最低速度限制(车速低于5 m/s时踩下油门控制汽车前进),而针对地势复杂且急弯较多的山间路况,原来设定的最低速度不能满足复杂路况的行车需要。在经过多次仿真实验之后,原算法的最低车速5 m/s调整为3.5 m/s,同时为了保证汽车在下坡路段以及突遇急弯不会造成速度过快从而导致汽车方向失控,在多次模拟实验后确定了一个最高限速值5.5 m/s。经多次模拟实验测试结果显示,此速度控制在多个模型下行驶状态良好,可作为行进状态的参数设置参考。
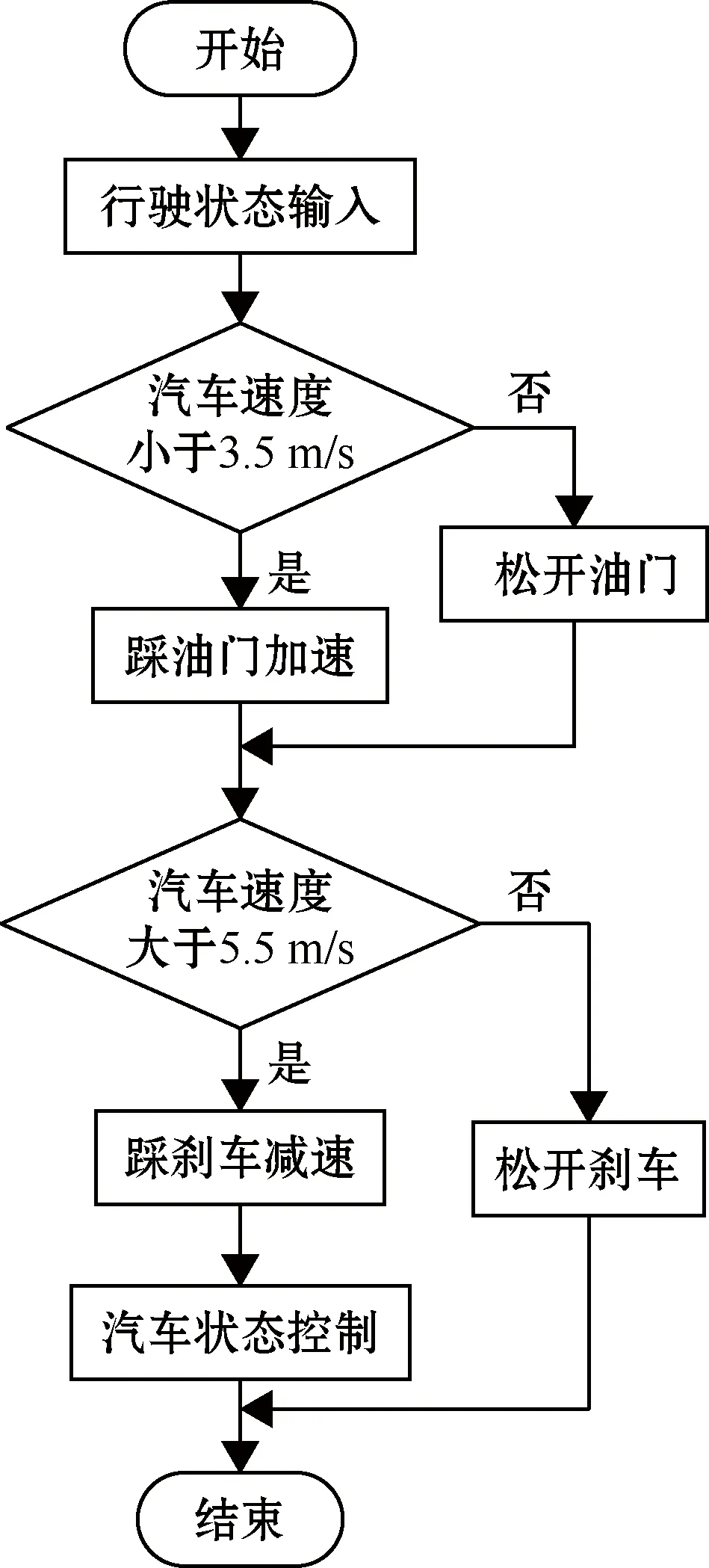
图10 动态环境状态控制算法流程
4.3 模型自适应推断结果
在两组训练好的模型中分别取损失值在0.000 8以下的模型进行测试,其表现大致分为4种情况:
1) 受干扰多,下坡路表现差(损失值在0.000 381 3~0.000 873 8之间);
2) 表现最好,直行策略完美且失误极少(损失值0.000 331 1);
3) 出现过拟合情况但不严重,可正常行驶但表现不稳定,行驶路程最远(损失值0.000 223 9);
(4) 过拟合情况严重且无法正常行驶,直线路段“S”形行驶过多(损失值在0.000 223 9~0.000 381 3之间)。
4.4 不同损失值模型的保真度区别
以下对自适应推断测试的4种结果进行详细分析。
1) 损失值处于0.000 381 3~0.000 873 8之间的模型在测试中表现不尽如人意,尽管其损失值相比表现最好的模型差了0.000 5左右,但在实际测试中受到外界干扰过多(光照,砂石,桥梁等),出现难以在转弯时正确判断转向角度而导致车辆发生冲出车道外的情况。同时测试模型优劣的第一个关键点就是在相对平稳路面行驶速度稍快的第一个下坡路段,而此损失值范围内的模型在测试过程中无一例外在第一个下坡路段速度过快,且不好把控方向而冲出车道外无法正常驾驶,如图11所示。

图11 冲出车道无法正常行驶状态
2) 经多次测试,保真度最高的模型为第二组中一个训练了9次、损失值为0.000 331 1的模型,也验证了微软官方给出的最终损失值应维持在0.000 3左右最佳的情况。此模型在多次测试中几乎无失误,直线行驶无摆动且能长时间保持在车道中间靠右侧的方位行驶,顺利通过第一个下坡路段的评判点后,于第二个下坡急转弯表现优异。
3) 第一组训练15次且损失值达到了early stopping的最低值0.000 223 9的模型是众多过拟合模型中保真度较高的一个模型。因其训练次数过多且损失值较低,使其具备了一定程度上的学习能力。此学习能力并非机器自主学习后对完全未观察过的场景进行识别,而是在原有路面信息的基础上拥有一定识别未添加入训练集的路面的能力,并能行驶约1.5倍完美拟合模型的行驶距离,但该模型不能作为最终模型。无人驾驶涉及驾驶和乘车人员的生命财产安全,相对于横向性能优越性的高低,应更侧重于稳定性的提升。在面对未知路面时,如果技术不够成熟,应选择稳妥的驾驶方式保证安全性,而非一味追求性能而忽略安全,这也是许多国家没有对无人驾驶汽车进行明确立法的原因之一。
4) 其他过拟合模型(损失值在0.000 223 9~0.000 381 3之间)过度的敏感性导致其在直线路段行驶时过多矫正行进路线,出现直行路段走“S”形线路的情况,不仅乘坐舒适度大大降低,在偶遇转弯路段时也会因车头在直线路段中刚好偏向另一侧而出现急打方向盘现象发生,容易造成安全事故。同时过拟合模型在通过下坡急转弯路段时,会由于过度躲避道路上的岩石而产生急转弯车身失控情况,严重时可如图12所示以高速冲出车道外造成危险。

图12 过拟合时汽车以高速冲出车道状态
4.5 仿真测试中正常行驶状态展示
对无人驾驶模型进行训练、测试和优化后,最终可观察到车辆在道路上行驶平稳且大部分时间是处于居中靠右的车道行驶,在处理急转弯和有可能出现偏离的道路时会做出相应的减速处理。然而,在行驶一段时间后,汽车最终会偏离道路并且与路面发生相撞,这是因为数据集过小汽车模型无法训练到更远的场景图像数据集。图13所示为汽车正常无人驾驶状态的4个特征位置点的行驶状态。

图13 正常无人驾驶汽车行驶状态
5 结束语
本文完成了复杂场景下无人驾驶模型的建立、训练和测试,对无人驾驶领域起到了一定的参考作用,具有实际意义。
在建模、训练和测试过程中,尽管训练集和测试集来自于相同的环境,但数据集之间的差异导致了模型的保真度出现了差异,而衡量保真度高低的重要指标则为训练时的损失值。本文研究总结如下:
1) 针对初始数据的处理方法进行改良,舍弃原本范围过大的ROI区域划分,针对原算法改良后虽然处理场景数据时减少了对更远距离的场景的长久规划能力,但却在短距离的即时策略中保证更高的精确度,综合设计硬件条件,减小ROI区域能最优化处理速度和精度,在后期的模型训练中表现也最为出色;
2) 针对动态环境下建模困难的问题,在原本静态建模基础上对其动态行进过程中的参数进行优化和补充,使其在动态环境下能保证足够的稳定性,面对不同的场景和地貌地形能做出正确的判断和行动;
3) 对模型保真度进行多次评估,在多次训练中对模型的损失值进行评估和总结,汇总训练结果后对其保真度进行基于多次训练的汇总结果评估,寻找出最优损失值的范围。
