基于通径分析和相空间重构的光伏发电预测模型
2022-11-23李博彤李明睿刘梦晴
李博彤,李明睿,刘梦晴
(1. 国网冀北电力有限公司,北京 100054; 2.天津大学 电气自动化与信息工程学院,天津 300072; 3.天津大学 管理与经济学部,天津 300072)
0 引 言
光伏发电的低运营成本和化石燃料能源对环境的不利影响,促进了光伏发电在世界范围内的发展。2021年全球光伏装机容量达到150万千瓦,与2020年相比增长了15%[1]。为了满足可再生能源发电的高利用率和灵活调度满足电网需求,电力系统运营商进行光伏发电预测通常从提前一天[2-3],不断刷新结果提前一个或半个小时[4-5]。对于预测精度而言,气象条件作为外部因素,不可控的变化会对光伏出力产生显著影响,增加预测的不确定性[6]。电网中光伏出力的不确定性和高随机性对光伏预测方法提出了更高的精度要求。受气象因素影响的光伏发电功率预测成为研究的热点。
随着人工智能的快速发展,基于人工智能的光伏预测方法得到了广泛的应用。文献[7]采用长短期记忆(Long Short-Term Memory, LSTM)预测光伏功率输出,并采用粒子群优化方法优化LSTM模型参数以获得更好的性能。文献[8]结合支持向量回归(Support Vector Regression, SVR)模型和卫星图像处理4年历史卫星图像进行光伏发电预测。文献[9]基于支持向量回归(SVR)和粒子群算法进行光伏功率预测,并采用粒子群算法对SVR的参数进行优化。与SVR算法相比,其精度有所提高。作为一种拥有较强非线性处理能力的机器学习方法,SVR比其他机器学习方法具有更高的精度,比深度学习方法有更低的计算成本。上述工作主要集中在参数优化和模型组合方面来提高预测精度。然而,原始数据的波动特性没有通过前面提到的方法进行消除或减弱,这可能会影响预测的准确性。
对原始数据进行数据处理可以进一步提高预测方法的准确性。例如,文献[10]采用小波包分解技术对原始功率序列进行分解重构,并验证了小波包分解对预测精度的积极作用。其将分解后的原始时间序列集成到预测模型中,与传统预测方法相比,降低了预测误差。文献[11]在数据处理阶段采用了相空间重构技术[12],解决了光伏功率波动特性的问题,通过实例验证了相空间重构技术方法在光伏发电功率预测中的有效性。然而,上述文献都忽略气象环境的复杂性,只遵循一种原则来处理数据,导致未被该原则考虑的预测日的预测误差较大。例如,文献[11]的方法在晴天的绝对百分比误差远低于10%,而在阴天和雨天的绝对误差通常在20%左右。
为了提高不同天气条件下的预测精度,可以将原始的光伏功率数据集和气象因子数据集划分为典型的数据簇,进行预测模型的训练,即基于天气分类的方法。文献[13]训练13个针对可能的太阳辐射特征的短期预测模型,并为待预测日确定最合适的模型,该方法比单个机器学习模型的性能提高了约20%。然而,其对模型的分类数目的确定并没有进行详细的研究。同样,文献[14]利用k-means聚类将数据集根据气象条件类型划分为不同的聚类,再进行功率预测。文献[15]对气象因子进行聚类分析从而选择相近日集合,其预测误差也得到了降低。然而,上述文献都没有研究数据集聚类选择气象因子的基本原理(即辐射、温度和相对湿度等气象因子的选择和忽略)。对于特定的光伏发电系统,气象因子可以是多样且独特的。没有统一的标准来规定最有影响力的目标。确定主导气象因子,需要对气象因子与光伏发电量的相关性进行量化。为此,文献[16]定义了Pearson相关系数来量化这一关系。但这种相关性分析忽略了气象因子之间的相互作用。事实上,相关分析得出的结论,即光伏功率输出与温度呈正相关并不准确。此外,由于没有考虑相对湿度与太阳辐射、温度等其他主导因素的依赖关系,因此高估了光伏发电中相对湿度的影响。为了考虑气象因子之间的相互依赖关系,通径系数分析 (Path coefficient Analysis, PA)[17]将所有输入变量对输出结果的相关性分解为直接影响和间接影响,仅根据直接影响识别主导变量,有效地消除了变量对结果的相互依赖关系。
综上所述,文中提出了一种基于数据处理的短期光伏发电预测混合模型(Hybrid PV Power Forecast, HPF)方案。首先,采用通径系数分析对历史数据集进行处理,减少气象因子之间的相互依赖关系,量化光伏出力和气象因子的相关性,并确定主导气象因子作为相似日选择的标准。随后,利用相空间重构技术对非线性光伏功率时间序列进行处理,捕捉数据波动规律,并按照该规律对数据集进行重构,该过程抑制了原始数据集的混沌特性。最后,基于SVR建立光伏功率预测模型。实验结果表明文中提出组合式预测模型的预测精度高于其他预测模型。
1 数据处理技术和建模方法
1.1 通径系数分析
通径系数分析方法是基于多变量线性回归方程,分析多个自变量和因变量之间的线性关系[17],其一般形式如下:
y=b0+…+bixi+…+bkxk
(1)
式中y为输出向量(文中为预测光伏功率);b0是常数;bi是回归系数;xi是输入向量;k是独立向量的总数。回归系数bi描述了独立向量对输出向量的影响大小,例如b1表示x1对y的影响程度,b1越大,x1对y的影响程度越大。
由于光伏预测模型中多个输入向量之间不是相互独立,即xi可以通过其他输入向量xj(i≠j)来对y产生影响。这个过程可以通过分解回归系数bi来实现,即将bi分解成xi对y的直接影响以及xi通过其他独立向量xj对y的间接影响。
(2)
式中bi值是通过计算xi和y之间的Pearson相关系数得到的;ri,j是xi和xj之间的Pearson相关系数;pi,y是xi对y的直接通径系数;ri,jpj,y是xi通过xj影响y的间接通径系数;cov()是协方差函数。
通过这种方式,可以分解多个变量之间的相互作用,得到直接路径系数pi,y和间接路径系数ri,jpj,y。
1.2 相空间重构
光伏发电输出功率的原始时间序列存在混沌现象,可以解释为不确定性和随机性运动,影响了光伏功率预测的准确性[12]。相空间重构技术可用于对原始时间序列进行预处理,抑制混沌现象。相空间重构技术以延迟时间τ和嵌入维度m,将一维光伏功率时间序列{x(i) |i=1,…,N}映射到相空间,如式3所示。

(3)
式中Xi是相空间中的第i个点;x(i)是时间序列中的第i个点。
τ和m上的选择对于降低高维相空间中的混沌特性至关重要。为了获取最优的τ和m,C-C方法[12]可以采用嵌入窗口tω来最小化关联积分,保证相空间重构结果的准确性。基于C-C方法对光伏功率原始数据进行相空间重构过程涉及以下四个步骤:
(1)将时间序列{x(i) |i=1,…,N}分成t个子序列,如下所示(t是子序列的总数):
(4)
(2)计算关联积分。关联积分是相空间中两点之间的距离小于常数rl的概率的累积分布函数:
(5)
式中Cs是第s个子序列的关联积分;M=N-(m-1)t是重建相空间中状态量的总数;Θ()是Heaviside函数;当(rl- ||Xi-Xj||)≥0时输出1,否则输出0。根据BDS统计结论,当m= 2,3,4,5时,对应的常数rl=σl/2,l=1,2,3,4,其中σ是时间序列的标准差;
(3)为确定子序列的最优延迟时间,定义统计量S(m,M,rl,t),其为所有子序列的相关积分差:

(6)
和式(6)的最大值和最小值之间的偏差(m,t):
(7)
(4)分别计算m的所有取值下式(6)和式(7)的平均值,即:
(8)
(9)
当获得式(8)的第一个过零点或式(9)的第一个局部最小值点时,此时对应的t视为最优延迟时间τ。为了估计最优m,需要先计算最优嵌入窗口,最优嵌入窗口通过合并式(8)和式(9)来获取:
(10)
当得到式(10)的全局最小点时,对应的t被标识为最佳嵌入窗口tω。则,m可以由下式获得:
(11)
1.3 SVR预测模型
SVR是一种用来建立输入输出之间回归关系的机器学习算法[8,18]。在光伏发电预测中,利用SVR算法训练预测模型,将原始非线性数据集投影到高维特征空间中,转化为线性回归问题,如图1所示。
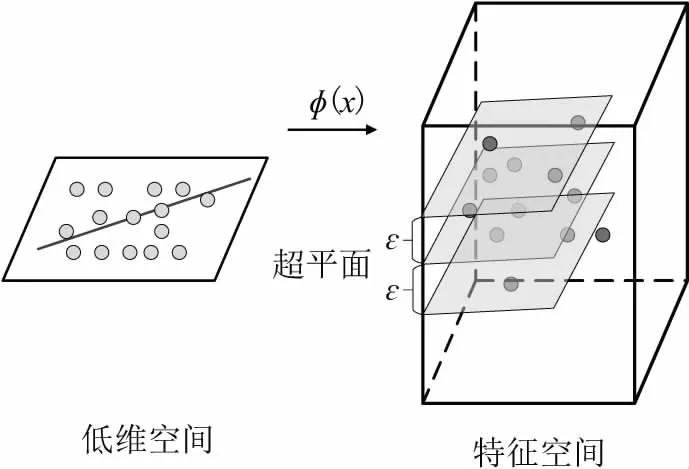
图1 回归分析中的SVR原理图
给定数据集{xj,yj}(j=1,2,…,n,n)是样本总数,xj是输入向量,yj是对应的目标值),通过映射函数φ()映射到高维线性空间,并在该线性空间中建立回归估计函数,计算预测值为:
f(xj)=ωTφ(xj)+b
(12)
式中f(xj)表示预测值;φ()表示映射函数;ω表示特征空间的特性向量;b表示特征空间的截距,其形式为低维空间的线性回归方程。根据结构风险最小化原理[19],参数ω和b可以由式(13)求得。
(13)
其中C表示惩罚因子;ξj表示松弛变量。式(13)中的映射函数一般可由核函数代替,文中用较为常见的高斯核函数,如下所示:
(14)
其中G为高斯核函数的宽度。通常情况下,参数C和G的直接影响模型的准确度,为了获得更加精确的SVR预测模型,可以利用网格搜索方法搜索最优参数C和G。
2 HPF光伏预测模型架构
本节提出了一种新颖的HPF的光伏预测方案。HPF首先利用通径系数分析来量化各气象因子对输出功率的影响从而选出主导的气象因子,用于相似日的选取;然后,HPF采用基于C-C方法的相空间重构技术重新整合数据,进一步提高精度。最后,HPF采用SVR建立光伏预测模型。
2.1 气象因子的权重分析和选择
HPF方案使用通径系数分析来量化所有气象因子对光伏功率输出的影响,然后确定主导的气象因子。考虑到气象因子的相互依赖关系,对其直接效应和间接效应进行量化,如图2所示。

图2 气象因子的通径系数分析图
在实际计算过程中,由于气象因子具有不同的量级,需要对其进行标准化。气象因子时间序列x(i)的标准化结果为:
(15)
式中xi,std是第i个时间序列的标准化值;i是第i个时间序列的平均值;δi是x(i)的标准差。
利用气象因子的标准化结果式(15)作为输入,分析直接通径系数pi,y。确定直接通径系数较大的气象因子为主导因子,并将主导因子作为选择相似日的标准,而直接通径系数低的气象因子可以忽略不计。
文中在确定了主导因子后。利用主导因子构建特征向量,用于从样本中选择与待预测日气象状况相似的相似日集合。文中采取主导气象因子的平均值和最大值作为特征向量来搜索与待预测日相似的集合。待预测日的特征向量值可以从前一天的天气预报中得到。同样的,为了减小特性向量的量级差异,将特征向量归一化为:
(16)
式中vi是定义的特征向量;vi,nrm是归一化值;min[vi]是特征向量的最小值;max[vi]是特征向量的最大值。
通过定义加权欧氏距离,在历史数据集中搜索相似日集合:
(17)
式中D为历史样本和待预测日之间的加权欧氏距离;pi,y,re为第i个特征向量的重新计算的直接通径系数;vi,fcst为待预测日的第i个特征向量的值。D值越小表示历史样本与待预测日的相似性更高。最后,将D值最小的5个历史日识别为相似日集合,用于后续的相空间重构和光伏功率预测模型的训练。
2.2 时间序列的分解和重构
文中提出的HPF方案采用了前文介绍的基于C-C方法的相空间重构,以抑制识别出的相似日集合的光伏功率时间序列的混沌特性。通过式(4)~式(11)计算过程,获取最佳延迟时间τ和嵌入维数m,将光伏功率时间序列重建成式(3)的形式。基于C-C方法的相空间重构对光伏功率时间序列进行混沌抑制主要通过编程实现,在此不再详细说明。需要注意的是由于不同天气条件下的混沌特征不同,相空间重构将时间序列分为阴雨天和晴天分开处理,得到不同的τ和m值,用来重构数据。
2.3 光伏预测功率模型建立
选取相似日的所有历史光伏功率数据,采用最优τ和m值重构成形式如式(3)所示,作为SVR预测模型训练的输入。取矩阵式(18)中对应的列向量作为输出,对模型进行训练。
(18)
如图3所示,建立最优的SVR光伏功率预测模型。在预测阶段,将待预测日的时间序列在相同τ和m下进行重构,将重构矩阵输入到训练好的SVR模型,以完成光伏功率预测,得到相应的输出。整个HPF方案的框架结构如图4所示。

图3 光伏输出的SVR预测模型

图4 完整的HPF光伏功率预测方案 Fig.4 The complete HPF PV power forecast scheme
3 算例仿真与分析
选取位于美国内华达州拉斯维加斯大学的气象站记录的两年气象数据[20]来评估提出的HPF预测模型的准确性。气象数据记录尺度为分钟级,包含2019年1月~2020年12月共计24个月。包括典型阴雨天和晴天。评估的重点是可能有阳光的白天时间,从上午4点~晚上8点,共计16个小时。HPF选择与文献[21-22]中相同四种典型气象因子,辐射强度(R)、温度(T)、相对湿度(H)和风速(W)。SVR光伏功率预测模型在MATLAB中实现,SVR工具包在文献[20]中可获得。采用平均绝对百分比误差(MAPE)和均方根误差(RMSE)来评价HPF的精度,其定义为:
(19)
(20)
式中n为预测的一天的总数据样本数(文中n=16×60=960)。
3.1 气象因子量化结果和相似日选择
为待预测日选择相似日集合前,先按式(2)进行通径系数分析,量化气象因子对输出功率的影响,以识别主导气象因子。利用两年时间序列分别得到典型晴天和阴雨天的相关系数,如图5所示。可以看出,无论在在晴天和阴雨天下,R与光伏功率输出P的相关性最大,相关系数接近于1,并且T、H与P也高度相关。从气象因素的相互影响看,除R&W外,其余4个气象因子均显著相关。晴天和阴雨天的关键差异在于W&P和R&W上的相关系数大小。阴雨天的相关系数相对得到了增大。这可以解释为,在阴雨天,风速增加可以减少云的阴影效应,从而增加光伏板上太阳辐射,增加了输出的功率。

图5 气象因子和光伏输出之间的相关系数
得到相关系数后,直接通径系数可以通过式(2)进一步计算,如表1所示。可以看出,T对P上的直接通径系数为-0.27,这与晴天和阴雨天下的的相关系数0.34和0.52大不相同。通径系数值为负数,意味着温度越高,功率输出越低。这也正是光伏板的工作特性。然而,相关系数结果显示T与P正相关,这与事实相悖,这也说明了相关性分析在多变量相互作用下分析的不准确性。实际上,相关系数是多个气象因子相互作用的综合结果。例如,R&P和R&T相关性为正,因此T通过R对P有间接的正作用。考虑到T对P的负直接作用以及T通过R对P的间接正作用后,T对P的相关系数可能为正。
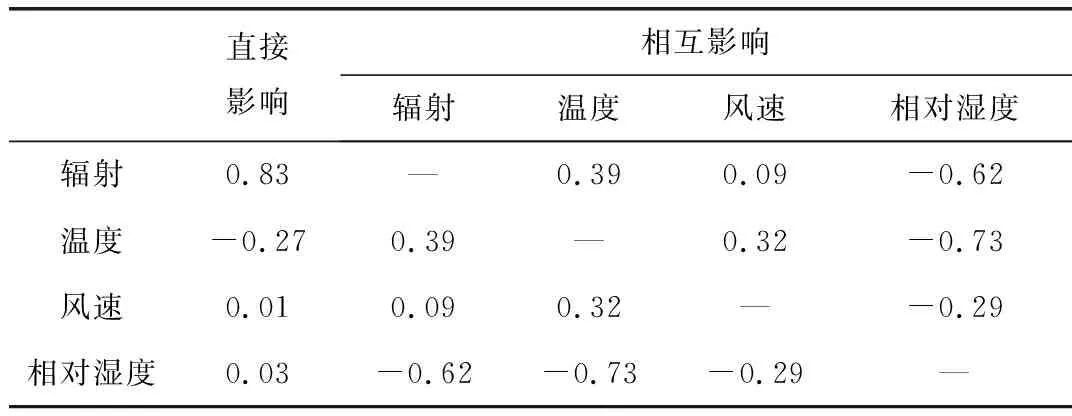
表1 气象因子的通径系数 Tab.1 Path coefficients of meteorological factors
通径系数分析的另一个差别是在P&H的关系,结果表明H对P的直接通径系数基本为0,而相关性分析的结论则是P&H具有负相关性。其实,这是因为H&T和H&R高度相关,H是通过影响这二者间接对输出功率产生影响的,而其并没有直接的作用。
在HPF方案下,计算出的直接路径系数pi,y消除了气象因子相互依赖的间接影响。从表1的通径分析结果可以看出,研究中有两个主导气象因子,即辐射和温度。为了选择相似日集合,需要先构建特征向量,HPF方案将辐射分解为平均辐射(表示为Ravg)和最大辐射(表示为Rmax),用于描述辐射强度平均和波动的总体特征;而温度的惯性较大,一天内的变化幅度基本不大,只取平均温度(Tavg)。因此,Ravg,Rmax和Tavg被定义为相似日选择的特征向量。重新计算特征向量在光伏发电上的直接通径系数如表2所示。

表2 特性向量的通径系数Tab.2 Path coefficients of feature vectors
根据式(17),从731天的历史数据中找出与待预测日最接近的相似日集合(文中共5天)。以2021年7月12日为例,加权距离最小的相似日集合如表3所示。在表3中可以看出,5个相似日辐射的MAPE基本小于5%,而温度的MAPE保持在6%的误差内。辐射的均方根误差一般在21 W/m2之内,考虑到日平均辐射值为400 W/m2,这是可以接受的。温度的RMSE在2 ℃左右。可以看出,选取的5个相似日集合的气象条件十分接近于待预测日气象特征。

表3 相似日选择结果Tab.3 Similar days selection results
3.2 光伏功率时间序列混沌抑制


图6 相空间重构结果
利用最优的时间延迟和嵌入维数参数,将一维原始时间序列分解重构为式(3)形式的高维,用于SVR模型训练。对于晴天的时间序列,其中嵌入的维度m1=4,可以扩展为4个维度,对应于SVR模型中的4个输入。对于阴雨天的时间序列,可以展开为3个维度,对应SVR模型中的3个输入。相空间重构过程表明,在阴雨天下,以时延大的短序列作为输入训练数据可以提高精度;在晴天下,以时延小的长序列作为输入训练数据也可以提高精度,这将在下一小节中得到验证。
3.3 HPF预测评估
仿真分析了2021年的四个季节,包括典型的晴天和阴天,时间范围为4:00~20:00。在所有季节中随机选取连续的3天,将所提出的HPF方案与两种方法进行比较:(1)传统的SVR预测方法;(2)基于天气分类(Weather Classification Based, WCB)的SVR预测方法(只选相似日,不经相空间重构)。这些预测方法之间的比较如图7~图10所示。
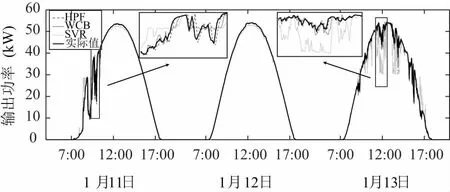
图7 三种方法在2021年1月11日~1月13日预测结果

图8 三种方法在2021年4月15日~4月17日的预测结果
光伏功率剧烈波动时,预测结果如图8所示。可以看出,此外SVR和WCB方法难以跟踪实测光伏功率输出,而HPF方法可以预测光伏功率输出的详细动态。特别地,HPF预测方法比WCB没有明显的滞后性,预测结果更准确。SVR、WCB和HPF在夏季和秋季的预测结果相似,分别如图9和图10所示。

图9 三种方法在2021年7月12日~7月14日预测结果
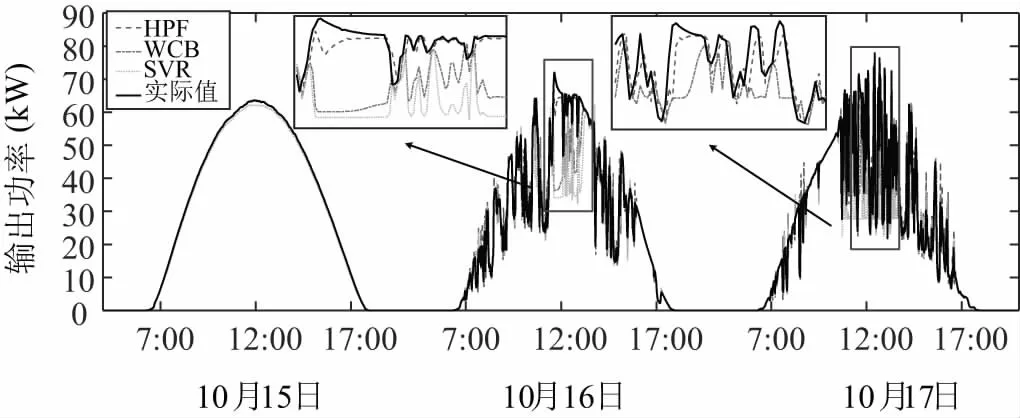
图10 三种方法在2021年10月15~10月17日的预测结果
从图7的冬季光伏功率预测中可以看出,HPF方法明显优于SVR和WCB方法,总体上跟踪了实测的光伏功率输出。从2021年1月11日的功率小波动日和2021年1月13日的功率大波动日放大图可以看出,HPF比WCB能捕捉到更多的功率波动动态,预报精度更高。
表4总结了12天晴天和阴雨天的平均MAPE和RMSE,并根据天气类型进行了分类。结果表明HPF晴天的MAPE值为0.81%,阴天MAPE值为7.45%,优于WCB(晴天0.89%,阴天9.94%)和SVR(晴天1.48%,阴天15.58%);另一方面,HPF在晴天和阴雨天的RMSE分别为0.57 kW和3.96 kW,这比WCB(晴天0.71 kW,阴天6.14 kW)和SVR (晴天1.07 kW,阴雨天8.79 kW)误差更小。

表4 三种预测模型的总体表现
4 结束语
文中提出了一种基于数据处理的短期光伏发电预测混合模型(HPF),该模型基于通径分析对相似日选择过程进行优化,并基于相空间重构对输入数据进行分解重构,用SVR完成预测模型训练。HPF的主要贡献是:使用通径系数分析衡量直接影响光伏发电量的气象因子的权重,消除气象因子之间的相互依赖关系。与传统的基于天气分类的方法相比,可以提高从历史数据集中相似日期选择的准确性,而传统的方法只将日期聚类成特定类型,既增加了工作量,聚类效果也不佳。文中使用相空间重构技术对相似日集合的时间序列进行处理,使其具有最优的时间延迟和嵌入维数,与传统预测方法相比捕捉更多的数据波动动态。该过程抑制了输入数据集的混沌特性,从而有效提高了基于SVR的预测模型精度。
