基于用电与环保指标对比学习的企业排污量动态监测方法
2022-11-22梁小姣马春玲马传国辛少菲史玉良
梁小姣,马春玲,马传国,辛少菲,程 林,史玉良,3
(1. 国网山东省电力公司东营供电公司,山东 东营 257100; 2. 山东大学软件学院,山东 济南 250101;3. 山大地纬软件股份有限公司,山东 济南 250200)
0 引 言
当前企业环保监测多依赖于环保监测设备采样进行离线分析/在线监测,故不可避免由于多重因素干扰(如设备老化、设备故障、采集点环境因素等)而影响监测精准度,甚至存在监测数据造假、故意破坏监测设备等恶劣事件。电力作为工业生产活动中必不可少的能源,尤其在“双碳”目标推动下,作为公认的清洁能源[1],工业生产电气化水平必然将进一步提高,而电力数据高实时性、高渗透性和高覆盖性等特点,可及时、准确、全方位地反映企业生产状况和环保设备使用状况[2],进而可对相应环保指标监测数据进行监测/校正。故本文基于重点排污监测企业用电数据,实现企业排污量的监测,辅助完善环保指标检测。当前有关机构已开展电能产出/消耗与排污量间关联性的研究。如杨训政等[3]基于历史污染物排放数据与发电机组输出功率间的关系,采用递归网络+批规范化等算法,实现对发电机组污染物排放量的预测,但当前工业企业未实现针对运行机组的用电量监测,且仅部分企业实现排污量日监测;安军等[4]针对双高企业建立“企业甄别-污染预警-配合停/限电-用电监测-异常纠正-恢复生产”的限时工作响应流程,通过电力绿色调度降低大气污染排放量,然而并未量化计量企业用电量与排污量的关联;刘忠辉[5]通过改进智能电表实现对治污设备启停的实时在线监测,旨在细化监测目标提升对企业气体污染物排放的监测,但硬件改进及运维成本高,不利于推广应用。上述文献均表明,电力数据与环保数据之间存在关联性,但均未实现二者的跨域量化关联。在当前算法研究中,GAN[6]在跨领域学习中表现优异,其基于博弈论的领域对抗训练,可实现不同领域的自适应学习。本文基于已有的研究基础及技术开展企业排污量监测,主要改进内容如下:
1)为实现企业用电负荷与环保特征的关联分析,并保留不同企业及设备间的细节差异信息[7],本文采用对比学习实现用电-环保特征的跨域动态关联映射,通过在投影空间中拉近相似实例,推远不相似实例,实现在企业缺乏排污数据时,也可根据充足的相似样本及自身用电负荷做出合理排污预测。
2)为提高生成数据与实际数据的全局相似度与一致性,监测数据生成是以相似企业历史排污均值数据为基础,结合映射编码数据提取数据分布间的差异和动态的变化量信息进行的数据复现,故并采用Wasserstein距离构建损失函数,有效避免生成数据失真。
3)鉴于GAN生成数据存在不稳定性,故采用模型预测控制(model predictive control, MPC)构建最小化控制目标函数,通过多目标及多约束条件限制,保证生成数据的稳定性及动态跟踪性能,且在后期离线模型产生偏移时,其滚动优化可参数微调保证模型监测的准确性。
1 整体模型构建过程
本文通过用电信息采集系统、烟气连续排放监测系统获取用电负荷数据和烟气环保指标监测数据,对获取的各类采集数据基于行业、生产规模、监测方式及监测设备进行阶梯级分类,并完成数据预处理后,构成可用样本集。整体数据处理流程如图1所示。

图1 整体模型数据处理流程图
本文针对样本分类分别开展建模训练及测试,并以某区域某类重点排污监测企业的用电数据与氮氧化物监测指标作为背景。首先企业将基于时间窗口的用电负荷差值数据作为输入数据,通过用电-环保动态关联映射模型,即以对比学习算法实现用电负荷差值数据与环保指标监测差值数据的关联映射及聚类分类,实现不同企业的差异化动态特征提取,输出排污监测数据的Encoder编码数据;随后,Encoder编码[8]数据结合相似企业历史排污均值数据输入企业排污监测模型,该模型通过GAN生成器生成排污监测数据,判别器保证生成数据符合真实样本数据分布规律,并采用Wasserstein距离构建的损失函数,完成模型的初步参数调节;最后,以模型预测控制(model predictive control, MPC)构建以误差最小为目标的控制函数,并基于数据预测趋势进行企业排污监测模型微调,保证输出企业排污量监测数据的精准度与稳定性。
1.1 对比动态关联特征提取
本文基于实际用电数据与实际环保数据开展用电-环保动态关联映射模型训练,具体过程如图2所示。以小时级为时间窗口,通过时间窗口滑动分别获取企业的历史用电负荷差值数据[9]和历史排污监测差值数据,共同构成训练数据集合 τ,随机从训练数据集合抽取M个企业样本数据构成一个分枝训练集合A,共计生成作用于上下2个分枝的两个训练集合,分别为历史排污监测差值数据集合A1、历史用电负荷差值数据A2,每个分枝中包含M个企业的样本数据,其中,上分枝样本数据固定,下分枝数据动态更新。随机抽取某一企业的历史某类排污监测差值数据输入上分枝,并将对应时刻的用电负荷差值数据输入下分枝,t表示采样时间窗口,为采样时序同维列向量,n表示某一企业的日监测采样数量,两者互为正例,i,j∈ (1,2,···,n)。训练时,上枝与下枝内的其他任意输入同企业或不同企业的样本数据Pj与Xj,均为的负例。
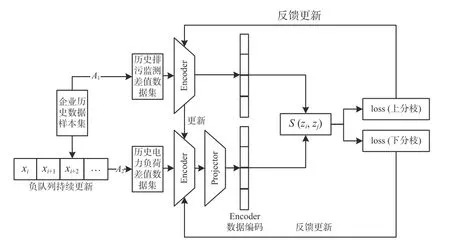
图2 用电-环保动态关联映射训练过程
然后,构造一个表示学习架构,通过该架构将训练数据投影到一个超平面表示空间内。为使正例距离能够拉近,负例距离推远,上下分枝采用双塔非对称结构,内部层级和神经元数均不同。历史排污监测数据集合Pt数据进入上分枝,经特征编码器Encoder,Encoder模块共计4层,每层包含多注意力机制+求和归一化处理+前馈神经网络(采用两层全连接层+层级规范化(layer normalization,LN)+ReLU激活函数+线性激活函数)+求和归一化处理[10],从而将输入样本数据映射为超平面表示空间中的向量zp。下分枝前一部分架构与上分枝架构相同,但中间各层的神经元个数不同,且参数不共享,输出表示为hx=fθ′(x),接着输入非线性变换结构Projector(采用两层全连接层+ LN+ReLU),输出为zx=gθ′(hx)。向量zx和zp矩阵内部结构与数量一致。在表示空间中,为实现电量数据与环保指标的关联分析,需使表示正例电量差值数据和排污监测差值数据映射后的表示向量z重合或者距离尽可能相近,距离负例样本较远,故采用表示向量L2正则后的点积作为距离度量标准,以表示空间向量间的相似性:

为在表示空间中使正例距离近,同时任意负例之间的距离远,故采用如下损失函数:
上分枝损失函数:

下分枝损失函数:
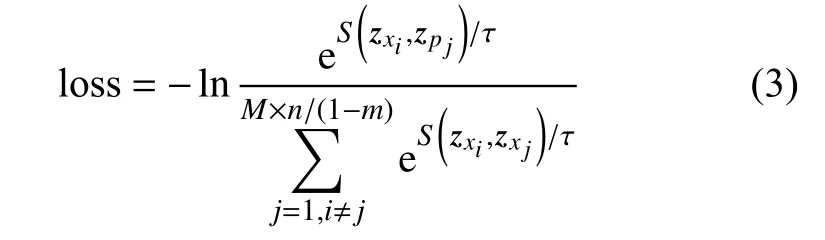
式中:τ——温度超参,表示难度识别惩罚系数,用以拉开正例样本与相似度高的负例样本的距离,避免模型基于高难度负样本进行参数调整导致模型崩溃;
M——企业个数;
n——某一企业的日监测采样数量;
上分枝基于损失函数loss反向传播进行梯度更新模型参数 θ,由于企业用电负荷数据的样本数据量相对排污监测数据多,故下分枝历史用电负荷数据A2的负例样本是不断更新的,即不断有新的负例样本进入A2,并按照先进先出更新负样本队列,上下分枝参数不共享。下分枝采用动量更新机制,参数更新方式如下:

式中:θ′——下分枝的模型参数;
m——权重调节系数。
当开始进行模型训练时,随机初始化模型参数θ′,当一个批次的训练数据集计算完成后,上分枝模型参数θ经反向传播进行梯度更新,同时,使用式(4)更新下分枝对应的参数θ′,m取较大数值0.9~0.99。相对上分枝参数更新,下分枝为维护更大的负样本队列,故参数变动缓慢而稳定,从随机数值小步而缓慢地向最优值迭代。故模型整体表示空间分布会根据排污监测样本的相似度与距离实现上枝的映射分布,用电负荷差值数据跟随排污监测差值数据映射空间移动并结合用电负荷数据样本间距离进行映射分布。
通过损失函数反向调节模型参数完成模型训练,输出为表示数据分布映射的Encoder数据。对比学习使相似企业相似的用电负荷差值数据分布和排污监测差值数据分布经过上下分枝的生成器编码后,可获取对应的动态数据分布空间映射,而不同的企业或不同时间段的样本数据在空间映射中相离,从而在实现关联分析的同时保持样本数据的个体差异。
1.2 构建企业排污监测模型
基于用电-环保动态关联映射模型获取训练数据集的Encoder输出编码[11],即企业历史电量数据和历史排污监测数据经过Encoder/Encoder+Projector的输出编码,由于在对比学习过程中,相似企业相似样本的历史电量数据和历史排污监测数据在表示空间是近邻关系,故二者的Encoder输出编码距离是相近的,本文旨在通过用电量数据监测企业排污量。故在企业排污监测模型训练阶段,输入样本的Encoder数据提取的为企业排污动态变量信息,基于对比学习聚类分类后的均值排污数据基础进行数据生成。此部分的训练过程如图3所示。

图3 排污监测数据生成训练过程
本文借鉴基于自动编码器的GAN算法构建监测模型,并在此基础上进行算法适应性改进。企业排污监测模型输入数据为Encoder排污编码+相似企业历史排污均值数据,生成器[12]架构与Encoder层级相同,均为4层,每层为多注意力机制+求和归一化处理+编码器-生成器注意力机制+求和归一化处理+前馈神经网络(采用两层全连接层+层级规范化+ReLU激活函数+线性激活函数)+求和归一化处理,4层输出末端为单层全连接神经网络+ReLU激活函数,输出生成排污数据;判别器为3层神经网络结构,为卷积层+求和归一化处理+卷积层+求和归一化处理+全连接层,输出损失函数。对生成排污数据与对应输入数据的真实排污监测数据计算Wasserstein距离,结合相似样本生成的损失函数loss如下:

式中:Pg——生成数据的集合;
Pr——实际数据的集合;
——生成数据样本;
p——实际数据样本;
用以保证生成数据靠近真实样本数据,但不会超过真实样本数据;
——生成数据与真实数据间的抽样构成数据,通过对抽样构成数据加梯度惩罚来稳定梯度变化;
λ——权重;
D(p,)——生成样本与实际样本的Wasserstein距离,表示点从曲线移动到pi曲线的最短距离集合,计算公式如下:
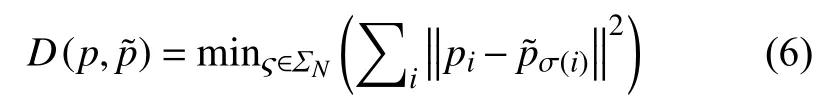
式中:pi——t时刻的实际排污监测数据;
——生成数据;
σ(t)——t时刻的真实数据映射到生成数据的σ(t)时刻的生成排污监测数据,由于实际数据与生成数据的元素个数相同,且数据测度相同,故Wasserstein距离采用二次差值衡量;
ΣN——N个元素的所有排序排列构成的集合。
训练过程如下:
1)初始化生成器参数 θg和 判别器 θd。
2)迭代训练过程中,生成器训练一次,而判别器需进行多次训练。主要过程包括训练判别器,固定生成器参数,更新最大化判别器损失函数。判别器损失函数公式如下:

其中,为实现基于相似样本数据实现曲线拟合生成,加入历史相似样本的均方误差判别条件。
训练生成器,固定判别器参数,更新最小化生成器损失函数:

其中,δ为可学习参数。
3)在基于上述获取的生成器基础上,进行生成器参数微调,即采用MPC建立目标函数,从而保证生成样本数据的稳定性。定义控制目标为:在连续时间步内,生成排污数据与实际排污数据总量误差尽可能小,从而保证生成排污数据的连续性与稳定性;在用电数据产生变量时,生成排污数据与实际排污数据变化时间点误差尽可能小,从而保证生成数据可以有效捕获用电数据变动量而非仅拟合排污数据值;用电数据变动量生成的监测输出变动量与实际排污变动量误差尽可能小,从而约束生成排污数据产生不必要的跳变。控制目标如下:
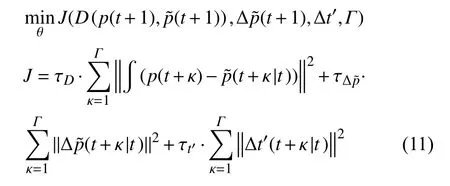
满足约束如下:

式中:J——目标函数;
p(t+1)——在t+1时间步内的实际排污数据;
Δt′——指在用电数据发生百分比超过20%的跳变时,生成排污数据与实际排污数据变化时间点误差;
Γ——未来 Γ个时间步;
随后,随机o次微调生成器参数 θd,并求解未来Γ个时间步的控制目标函数值,得到o组控制序列并排序,获取最小控制目标函数值J,并将其第一个微调控制量 θd作用于生成器,并进入下一个时刻,重复上述过程直至J小于设定阈值或者其梯度值接近于0,固定参数,输出模型。基于预测跟踪控制可有效提高生成器生成数据的稳定性,并在输入数据发生变化时可动态跟踪其变化轨迹,从而保证企业设备在不同运行状态切换时,生成排污监测数据接近实际排污数据。
训练完成后,用电-环保动态关联映射模型输入电量数据及部分排污采样点数据,输出Encoder编码,编码输入企业排污监测模型,输出企业排污量监测数据,由于Encoder编码关注数据的差异性、动态性和泛化性,而并不是数据本身,故监测数据是基于聚类获取的相似企业的历史排污均值数据基础,并结合用电数据变化量进行的数据复现,保证基于企业用电量数据实现其排污量的监测。尤其随着该类企业的排污监测数据样本的增加与更新,可基于预测跟踪控制模块不断微调模型参数,从而提高监测精准度。
2 算例分析
本文以国网某市公司建设的黄河流域污染防止监测系统作为实验数据源,系统界面如图4所示。
图4 黄河流域污染防止监测系统界面图示
其中,用电数据、环保数据的数据采集频率为24点/日,电力采集数据为用电负荷数据,环保监测指标为大气污染指标中的氮氧化物浓度,结合网络爬取气象及节假日数据。对获取的采集数据进行数据转换、数据标准化、异常值删除等预处理操作后,获取可用样本数据。对2 385家重点排污监测企业基于行业进行分类建模,选择2020年1月-2021年12月的历史数据为模型训练样本集,2022年1月-2022年4月的历史数据为模型验证样本集,为避免样本类别不均衡,仅选取企业正常生产的1/5的历史样本参与训练与验证,以2022年5月历史数据为模型测试数据样本集,实现企业排污量监测效果评估。
2.1 动态特征数据的空间分布
在训练阶段用电负荷数据与氮氧化物监测数据输入用电-环保动态关联映射模型后,于上下分枝获取企业排污监测模型的Encoder编码。为可视化展现用电负荷数据通过对比学习跟踪氮氧化物监测数据的空间分布规律,在保留企业排污细节信息的前提下,实现相似样本数据聚类与不相似样本在表示空间的相对均匀分布,为展示上下分枝分别生成的氮氧化物监测数据与用电数据的Encoder编码数据,采用极坐标进行展示,如图5所示。

图5 编码数据在极坐标中的对比图
由图5展现了“双塔”结构生成用电数据Encoder编码和排污数据Encoder编码在空间中的对称分布与关联性,其中,极坐标中的气泡的大小代表样本数据量,气泡数量代表样本聚类数量,气泡间的距离代表样本的相似度与差异距离。由于当前仅部分重点排污企业可实现氮氧化物的小时级采集监测,采集监测数据受限于有限量氮氧化物监测数据,故在训练过程中,上分枝氮氧化物监测数据样本不变,下分枝历史电量数据A2的负例样本是不断更新的,即不断有新的负例样本进入A2,并按照先进先出更新负样本队列,故下分枝映射后获取的左侧用电数据气泡样本量较大。从图中可以看出,二者的聚类中心基本重合,在训练过程中用电数据是根据氮氧化物监测数据的分布进行跟踪,故可基于用电数据提取氮氧化物监测数据的变量信息。同时对比学习使电量数据分布和排污监测数据分布经过上下分枝的生成器编码后,相似样本数据聚集到较近区域,在实现特征相关性分析的同时,可基于样本数据的个体差异进行聚类划分。受限于有限量氮氧化物监测数据,导致下分枝基于用电量数据拟合排污数据的编码产生偏差,如图5(b)的左侧三个样本集数据,此部分区域企业的氮氧化物平均单位电量排放氮氧化物指数低于5.89,排放氮氧化物的日监测数据采集样本数据未实现小时级,导致用电数据对应排污数据映射出现偏差。但在排污监测数据充分时,用电-环保动态关联映射模型能够忽略数据分布的浅层因素,可基于用电数据提取其排污指标数据的变化分布规律。
2.2 消融实验对比曲线精准度分析
本文在模型数据处理过程中,主要从以下3点内容进行改进:
1)企业排污监测模型生成器的输入编码为用电数据与氮氧化物监测数据对比学习获取的氮氧化物动态编码数据[13]。
2)在企业排污监测模型训练阶段,生成器生成的检测数据是根据企业S用电数据获取的动态编码结合相似企业历史排污均值数据复现企业S排污数据,同时损失函数采用Wasserstein距离计算生成排污数据与真实排污监测数据差值。
3)在模型初步训练完成的基础上,采用MPC建立以曲线误差最小为目标的控制函数,从而进行模型的二次微调。
本文通过消融实验,对上述内容以企业S为例进行生成曲线展示,如图6所示,为用电-环保动态关联映射模型、企业排污监测模型训练完成后,将用电数据输入用电-环保动态关联映射模型后,输出Encoder数据,随后Encoder数据输入企业排污监测模型,输出企业S氮氧化物排放量监测数据。示例企业S为某钢铁制品加工企业,企业S基于生产计划进行,小时级氮氧化物排放监测样本数据充分。对比实验方法如下:
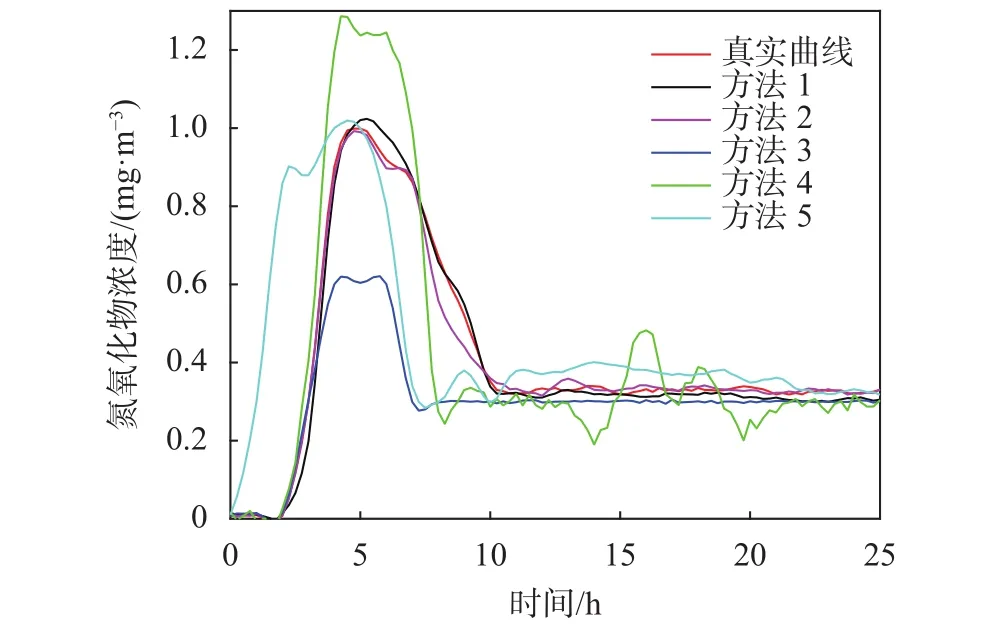
图6 氮氧化物生成曲线数据对比图
方法1:本文方法,即用电负荷数据作为用电-环保动态关联映射模型输入,采用对比学习获取Encoder排污编码,结合相似企业历史排污均值数据作为企业排污监测模型的输入数据,监测模型采用GAN生成器(生成监测数据)+判别器(判别曲线真假),采用MPC进行二次微调,输出氮氧化物监测数据。
方法2:在方法1的基础上,将企业S真实排污监测数据作为映射模型输入(即不采用对比学习获取Encoder排污编码),其他一致。
方法3:在方法1的基础上,将企业S排污监测设备故障时获取的排污监测数据作为映射模型输入(即不采用对比学习获取Encoder排污编码),其他一致。
方法4:在方法1的基础上,采用对比学习获取Encoder排污编码作为企业排污监测模型的输入数据(未结合相似企业历史排污均值数据),其他一致。
方法5:在方法1的基础上,不采用MPC进行二次微调,其他一致。
如图6所示,采用文中方法的方法1,与实际排污的真实曲线拟合度较高,小时级均值误差为1.89%,标准差为0.02,方法2直接将企业S真实排污监测数据作为映射模型输入,基本复现实际排污曲线,小时级均值误差为1.39%,标准差为0.02,由方法1和方法2可以说明,采用对比学习方法,用电数据可以捕获排污数据的动态变化信息,并通过本文方法实现排污曲线复现;方法3为企业S排污监测设备故障时获取的排污监测数据,并将其直接作为映射模型输入,由曲线可以看出其更多地基于相似企业排污数据均值进行变化,进一步说明采用用电数据提取动态特征,可以在排污监测设备故障时进行预警并复现实际排污数据;方法4为GAN生成器未结合相似企业历史排污均值数据进行数据生成,小时级均值误差为9.88%,标准差为0.1,由此可以看出仅基于GAN生成数据存在不稳定性及数据分散,难以拟合实际排污数据;方法5为不采用MPC进行二次微调,由曲线可以看出,生成曲线与实际曲线不仅误差较大,且由于其数据监测缺乏前瞻连续性,故导致其未捕获排污数据滞后于用电数据这一实际状态。
此外,本文选取29家重点排污企业进行5日氮氧化物排放浓度监测,采用均方根误差(root mean squared error,RMSE)对 12次实验结果进行排放浓度监测效果评价,并采用KL散度[14]衡量一个监测曲线数据分布相比实际数据分布的信息损失,二者均为数据越小,曲线拟合度越高,并对拟合曲线进行积分运算,从而获取企业累计排污量监测值,以平均绝对百分比误差(mean absolute percentage error,MAPE)对监测值与实际排污量进行监测精准度评价,如表1所示。

表1 曲线相似度评价表
由RMSE和KL散度可得,采用本文所述方法可对企业排污量进行相对准确的监测,可有效实现基于用电数据实现对排污监测数据的监测与预警。
2.3 生成数据的稳定性对比分析
为进一步说明本文采用MPC对模型监测数据的稳定性与连续性影响,以实际排污数据为基线,分别以本文采用MPC的排污监测数据曲线、本文不采用MPC的排污监测数据曲线、采用GAN生成器(此处无相似企业排污历史均值数据辅助输入)与实际排污数据计算误差进行对比分析,如图7所示。
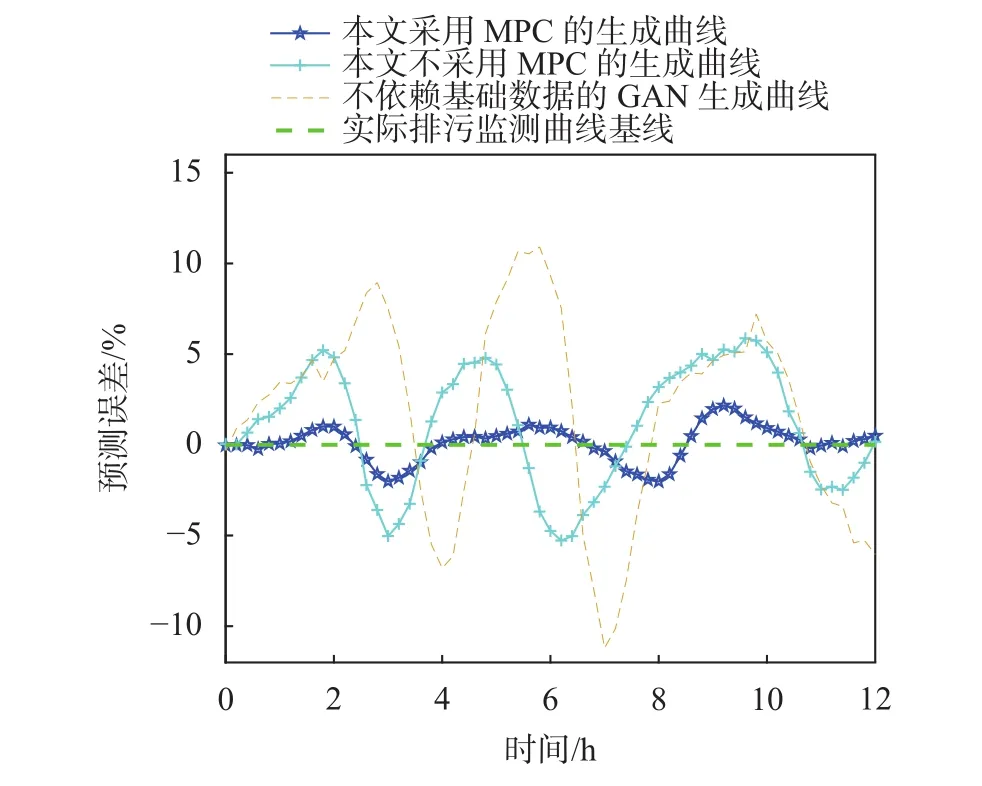
图7 12 h排污监测数据误差对比图
由图可以看出,本文所述方法为代表的采用MPC的排污监测生成数据曲线,与实际曲线误差较小,数据波动性较小,其通过定义控制目标为总量误差、时间点误差和变动量误差的降低,在模型二次微调阶段,基于该控制目标在实现时域预测追踪控制,从而提高了生成排污数据的连续性、稳定性与实时性;对比不采用MPC的排污监测生成数据曲线,其跟踪连续性与稳定性明显降低,表明模型二次微调阶段的可行性与有效性;而不依赖基础数据的GAN生成曲线,由于未基于历史数据基础进行数据生成,GAN生成数据的不稳定性,即使模型加入采用MPC的二次微调,其生成监测数据仍然与实际数据误差较大,表明本文采用相似企业排污历史均值数据辅助输入生成排污监测数据曲线可有效保障监测数据的稳定性,即在实际历史排污数据的基础上,通过用电数据捕获排污动态变量信息,从而生成排污监测数据。
3种方法的监测误差数据如表2 所示。通过对比分析可知,本文方法排污监测数据准确率均值能够达到98.92%,相较于不采用MPC,模型监测数据准确率均值提升2.36%,相较于不依赖基础数据的GAN生成曲线,模型监测数据准确率均值提升5.85%,对比分析可知采用MPC可提高生成数据准确率。通过对比分析3种方法的标准差可知,采用MPC生成的监测曲线相对的稳定性。与此同时, 本文方法监测误差跨度不高于5%,说明模型可有效捕获用电数据中的表现排污量的动态信息,模型趋势监测准确率明显提升。综上所述,仿真实验表明,本文方法不仅可基于用电数据监测排污量,且模型监测准确度与稳定性均较好,可辅助实现环保指标监测预警。

表2 12 h排污监测数据误差对比表
3 结束语
本文通过对比学习算法实现用电数据与环保指标的差值数据关联映射,作为上分枝环保差值数据的正例增强样本的下分枝用电负荷差值数据,与对应正例映射数据分布相拟合,并实现了“正例相吸,
负例相斥”样本数据聚类分类;基于排污编码数据结合相似样本排污均值数据,采用GAN算法生成企业排污监测数据,并以模型预测控制构建符合预测趋势发展的目标控制函数,进一步保证生成数据的稳定性与连续性。
由于根据用电数据实现企业的排污量监测尚处于初期探索阶段,故本文仅对某类型企业充足样本的氮氧化物24 点指标数据进行了研究与测试,后续随着点源排放监测数据的增多,可探索在样本不充分的情况下的多类指标的预测,从而为环保监测提供技术研究参考。
