基于Transformer的端到端路面裂缝检测方法
2022-11-19王慧民张兴忠郭美青
刘 军,王慧民,张兴忠,张 婷,郭美青
(太原理工大学 软件学院,太原 030024)
路面裂缝作为常见的公路病害,已成为公路养护任务中最关心的问题,轻微裂缝不及时处理就会发展成大面积龟裂甚至坑槽等严重病害,为安全运行埋下隐患[1]。同时,路面裂缝具有形状不规则、尺寸不一及背景复杂等特点,如何自动检测路面裂缝是一项具有挑战性的任务。因此路面裂缝检测技术和识别算法已成为近几年的研究热点[2]。
传统的路面裂缝检测算法主要依赖于数字图像处理技术和人工设计的特征提取器。文献[4]利用移动平均自适应阈值分割和Hough变换,实现对高速公路细小裂缝的自动检测。文献[5]通过改进遗传规划算法,对混凝土路面裂缝进行检测。这些方法在路面裂缝数据集上取得了较好的效果,但是,实际检测中泛化性能较差,仅依靠人工先验设计的特征提取器无法满足实际任务的要求。
近年来,深度学习技术取得快速发展,深度学习检测算法在众多任务上表现优异[6-9]。目前,在路面裂缝检测任务中,大量研究工作基于卷积神经网络展开[10-14]。文献[12]在Faster R-CNN基础上,利用数据增强和引入多任务增强的候选区网络,提高了裂缝检测精度。文献[13]提出了可形变SSD模型,使用可形变卷积增强模型在复杂环境下的检测精度。文献[14]基于Yolov3对路面裂缝实现实时检测。上述方法中,基于卷积神经网络的检测方法在设计阶段引入大量归纳偏置,如权重共享和标签分配原则等,虽然模型收敛性较好,但是会影响建模能力。其次,大多数方法不可避免地使用低效的非极大值抑制(non-maximum suppression,NMS)后处理操作,阻碍了端到端的训练和检测。除此之外,特征提取过程中下采样操作会减小特征图分辨率,丢失裂缝细节信息。相比卷积操作,transformer中自注意力机制动态建模特征序列重要程度[15],采用一种序列到序列的学习方式,具有更小的归纳偏置[16]。
2020年,Facebook AI基于transformer提出的DETR(object detection with transformer)[17]检测算法为目标检测提供了全新范式,该方法无需NMS后处理,实现了端到端检测。之后,基于transformer的基础网络Swin Transformer[18]在多个视觉任务上达到最好性能(state of the art,SOTA).
受上述工作启示,提出了一种基于transformer的端到端路面裂缝检测方法,其创新性主要体现在以下方面:1) 实现了真正的端到端路面裂缝检测,无需NMS后处理操作,裂缝检测精度MAP达到84.2%,优于基准方法;2) 结合多尺度特征融合和深度可分离卷积(depthwise separable convolution)[19],提出了一种多尺度特征提取骨干网络Multi-scale Transformer,能够提取细节丰富的裂缝纹理特征;3) 通过使用Pre-LN Transformer结构,有效加快模型收敛速度;4)提出了完全交并比损失(complete intersection over union loss,CIoU Loss)[20]和L1 Loss结合的联合回归损失,有效提升了模型检测效果。
1 路面裂缝检测模型
1.1 CrackFormerNet模型架构
路面裂缝检测模型CrackFormerNet架构如图1所示,包含特征提取网络Backbone、编码器-解码器网络Encoder-Decoder以及预测网络Predictor三部分。首先,特征提取网络使用本文提出的Multi-Scale Transformer骨干网络,通过将不同下采样倍率特征图融合,提取图像中富含裂缝细节信息的抽象特征图FB,该骨干网络将在1.2节介绍。然后,编码器-解码器网络使用Pre-LN Transformer结构,先将特征图FB沿空间维度展开,得到序列化的特征表示SB.之后,利用Pre-LN Transformer中的Encoder结构对输入特征序列SB进行上下文建模,得到图像的全局特征表示SE,Decoder结构基于输入的全局特征表示SE和目标查询向量Object Queries,得到裂缝特征序列SD.最后,预测网络使用经Relu激活的多层感知机对输入的裂缝特征序列SD进行非线性映射,得到预测框集合Box Set,包含裂缝的类别信息和位置信息。其中,类别包括纵向裂缝、横向裂缝、龟裂、坑槽以及背景“No Object”五类目标,背景类检测时不显示。
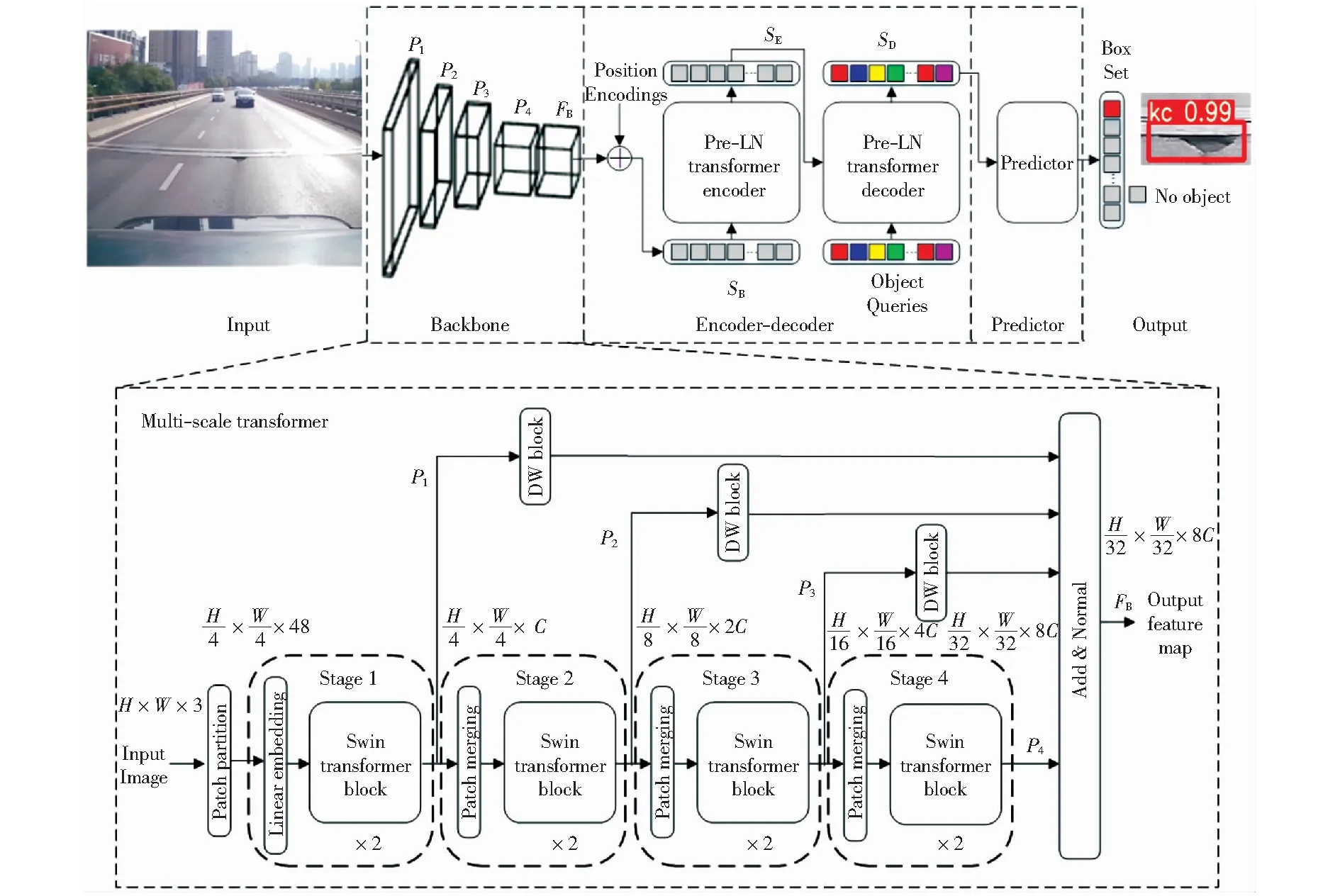
图1 CrackFormerNet模型架构图
1.2 Multi-Scale Transformer骨干网络
为提升细小裂缝检测效果,改善特征提取过程中细节信息丢失的问题,在Swin Transformer基础上,结合多尺度特征融合和深度可分离卷积提出了一种Multi-Scale Transformer骨干网络。该网络采用基于窗口的自注意力机制[18],在计算量相对输入图像尺寸线性的情况下,提取图像抽象特征;多尺度特征融合机制将各阶段不同下采样倍率特征图进行融合,保留深层抽象特征和浅层细节特征;深度可分离卷积可在空间和通道维度上统一不同下采样倍率特征图形状,同时,相较普通卷积,计算量和参数量更少。
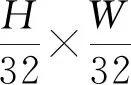
(1)
式中:DW为深度可分离卷积操作,Pi为不同下采样倍率特征图。
图1中两层连续Swin Transformer Block结构如图2所示,利用窗口多头自注意力模块W-MSA仅关注窗口内图像特征,保证图像局部性和提高计算效率。然后,基于移位窗口多头自注意力模块SW-MSA将特征图沿水平和竖直两个方向平移半个窗口长度实现不同窗口间特征的交互,计算如式(2)-式(5)所示:

图2 两层连续的Swin Transformer Block结构
(2)
(3)
(4)
(5)
其中,St-1为输入特征序列;St+1为输出特征序列;W-MSA为窗口多头自注意力模块;SW-MSA为移位窗口多头自注意力模块;MLP为多层感知机,LN为层归一化处理。
1.3 Pre-LN Transformer编码器-解码器
文献[21]研究发现调整transformer结构中层归一化位置能加快模型收敛速度。受此启发,本文在编码器-解码器网络中使用Pre-LN Transformer结构,将层归一化放置在残差连接内部,如图3所示,在Multi-Head Self Attention、Multi-Head Cross Attention、和FFN的残差连接内部,先经层归一化,将输入数据分布统一为高斯分布,再做自注意力变换和前馈网络映射。

图3 Pre-LN Transformer结构图
具体地,在Pre-LN Transformer结构中,研究层归一化位置从Multi-Head Self Attention、Multi-Head Cross Attention和FFN各部分残差连接的整体角度进行分析。在原transformer结构中各模块均采用后置层归一化的残差连接结构,而Pre-LN Transformer结构中,使用前置层归一化的残差连接结构,如图4所示以Multi-Head Self Attention为例,左图为Post-LN连接,右图为Pre-LN连接。

图4 Post-LN连接与Pre-LN连接结构示意图
编码器-解码器网络使用多头自注意力模块Multi-Head Self Attention,通过将输入特征序列映射到多个特征子空间,提取输入序列的不同特征信息,如式(6)所示:
Mul_h(Q,K,V)=Con(h1,…,h8) .
(6)

(7)
式中,σ为softmax操作,dk为输入特征序列元素维度,等于256.
解码器中交叉注意力模块与多头自注意力类似,不同点在于交叉注意力模块的K、V来自编码器结构中建模的图像全局特征表示SE,Q来自解码器中Object Queries的自注意力特征序列。通过交叉注意力模块,按照“查询”的思想,在编码器建模的图像全局特征中去提取与某类Object query相关的特征,然后生成相应的特征序列。通过设置Object Query的数量,实现对每张图像预测包围框数量的控制,Object Query采用随机初始化,并在训练过程中通过反向传播算法进行学习。
1.4 联合回归损失设计
为提升裂缝检测效果,提出了CIoU Loss和L1 Loss结合的联合回归损失。相比DETR检测方法中使用GIoU Loss和L1 Loss回归损失函数,本文联合回归损失函数中的CIoU Loss能够从目标的重叠面积、中心点距离和长宽比一致性三个维度考虑,对预测框和真值标签间的距离进行准确评估,解决了GIoU Loss在预测框和真值标签包含情况下退化为IoU Loss的问题。同时,该损失函数具有更好的收敛性。联合回归损失函数LJoint定义如式(8)所示:
(8)

(9)
(10)
(11)
式中:IOU为预测框和真值标签的交并比;ρ为预测框中心点和标签中心点的距离;q为预测框和标签最小闭包区域的对角线长度;v为长宽比参数,用于度量二者长宽比的一致性。α为正权重系数,重叠面积较高的预测框具有更高的回归优先级,尤其是在二者不重叠的情况。
2 路面裂缝数据集
2.1 数据集构建
利用车载相机采集某市周边高速公路路面图像,图像分辨率为2 048像素×1 536像素,经筛选,得到3 174张图像。模拟真实巡检场景,采集到包含油渍、车道线等噪声干扰以及不同光照条件下的裂缝图像。图5所示为路面裂缝示例图,包括纵向裂缝、横向裂缝、龟裂和坑槽四类。使用LabelImg对裂缝图像进行数据标注,按照VOC数据集格式,构建路面裂缝数据集。其中,LabelImg为图像标注工具。

图5 路面裂缝示例图
2.2 数据集分析
对路面裂缝数据集标签进行统计分析,共计5 961个目标。其包围框尺寸分布情况如图6(a)所示,纵坐标为包围框相对原图的高度占比,横坐标为宽度占比。由图6(a)可知,包围框大小分布不均,总体来说,相对原图尺寸包围框面积占比较小,多为小目标,检测时需保留图像细节特征。图6(b)为裂缝形状分布情况,可以看出不同裂缝形状差异较大,长宽比不定,增加了检测难度。

图6 包围框尺寸和形状分布图
3 实验结果与分析
3.1 实验环境
本文实验使用深度学习服务器进行,其配置为Intel i9-9900K处理器和NVIDAI GeForce TRX 2080Ti显卡x2.操作系统为 Ubuntu16.04,实验所依赖深度学习框架和库函数包括Pytorch 1.5.0、CUDA 10.1以及CUDNN 7.6.5等。
3.2 模型训练
实验前,先将2.1节中路面裂缝数据集按照7∶2∶1划分为训练集、验证集和测试集三部分,基于该数据集开展实验。训练过程采用AdamW[22]优化器对模型参数进行更新,设置初始学习率为10-4,特征提取网络学习率为10-5,权重衰减系数为10-4.设置批处理尺寸Batch Size为4,两块2080Ti显卡同时训练,每块卡单次处理2张图像。本文提出的Multi-Scale Transformer骨干网络训练使用Swin Transformer-T[18]作为基础结构,其复杂度(模型参数和计算量)与Resnet50[23]、RepVGG-A2[24]相当,实验更具对比性。实验中其它参数细节参照文献[17]进行设置。
3.3 评价指标
本文使用以下指标来评估各方法的裂缝检测性能。
1) 平均均值精度(mean average precision,MAP)
均值精度(average precision,AP)是通过对单个类别目标的P-R曲线(Precision-Recall)进行积分,得到不同召回率下的平均检测精度,如式(12)所示。其中,p为精准率,r为召回率,p(r)表示当召回率为r时所对应的精准率。而平均均值精度MAP则是对各个类别的AP再求平均,如式(13)所示。其中,Num(Classes)为检测裂缝类别数,设置为4.MAP能够实现不同类别目标检测效果的全面评估,MAP越大,目标检测越准确。本文中,AP和MAP的IoU阈值设为0.5,若预测框类别预测正确,且重叠面积大于该值则认为检测成功。

(12)
(13)
2) 每秒帧率(frames per second,FPS)
统计各方法在当前实验环境下使用单块2080Ti显卡处理100张图片所需时间,计算出每秒能检测的图片帧数。
3.4 实验结果与分析
为评估本文方法性能,分别从检测精度、检测速度和算法收敛性三方面对比本文方法与其它检测方法,具体分析如下。
3.4.1检测精度和速度对比
为验证本文方法检测效果,在自建路面裂缝数据集上对比了常见的基于卷积神经网络检测方法(Faster RCNN、SSD及Yolov3)和基于transformer的检测方法(DETR及本文方法),实验结果如表1所示。本文方法在路面裂缝检测数据集上取得了最好的检测效果,MAP达到84.2%,证明了本文方法的有效性。相较DETR检测方法,本文方法在横向裂缝、龟裂以及坑槽等多个检测任务上取得性能提升,尤其对坑槽类小目标检测任务上效果提升尤为明显。
检测速度对比如表1所示,可以看出基于CNN的单阶段检测方法(SSD及YOLOv3)在检测速度方面明显优于两阶段检测方法(Faster RCNN)和基于transformer的检测方法(DETR及本文方法)。相比DETR,本文方法检测速度下降2.8 f/s,主要由于Multi-Scale Transformer骨干网络为保留裂缝细节特征带来一定的计算开销,但是检测精度得到明显提升。

表1 检测方法性能对比
本文方法检测结果可视化如图7所示,图7(a)中,在不同光照条件下对纵向裂缝和龟裂进行了准确检测,由此可见本文方法对不同光照强度具有一定的鲁棒性。在图7(b)左图中,准确检测出纵向裂缝,树木阴影未对裂缝检测造成不利影响。同时,在右图中在车道线旁的纵向裂缝也被准确检测出来。可视化结果进一步证明了本文方法的有效性,对不同光照强度、路面阴影以及车道线等干扰因素具有一定的鲁棒性。

图7 路面裂缝检测效果可视化
3.4.2模型收敛性对比
我们对DETR检测方法和本文方法进行收敛性对比实验。在相同实验环境及硬件配置下,两模型分别训练300个轮次,损失loss变化曲线和平均均值精度MAP变化曲线如图8所示。
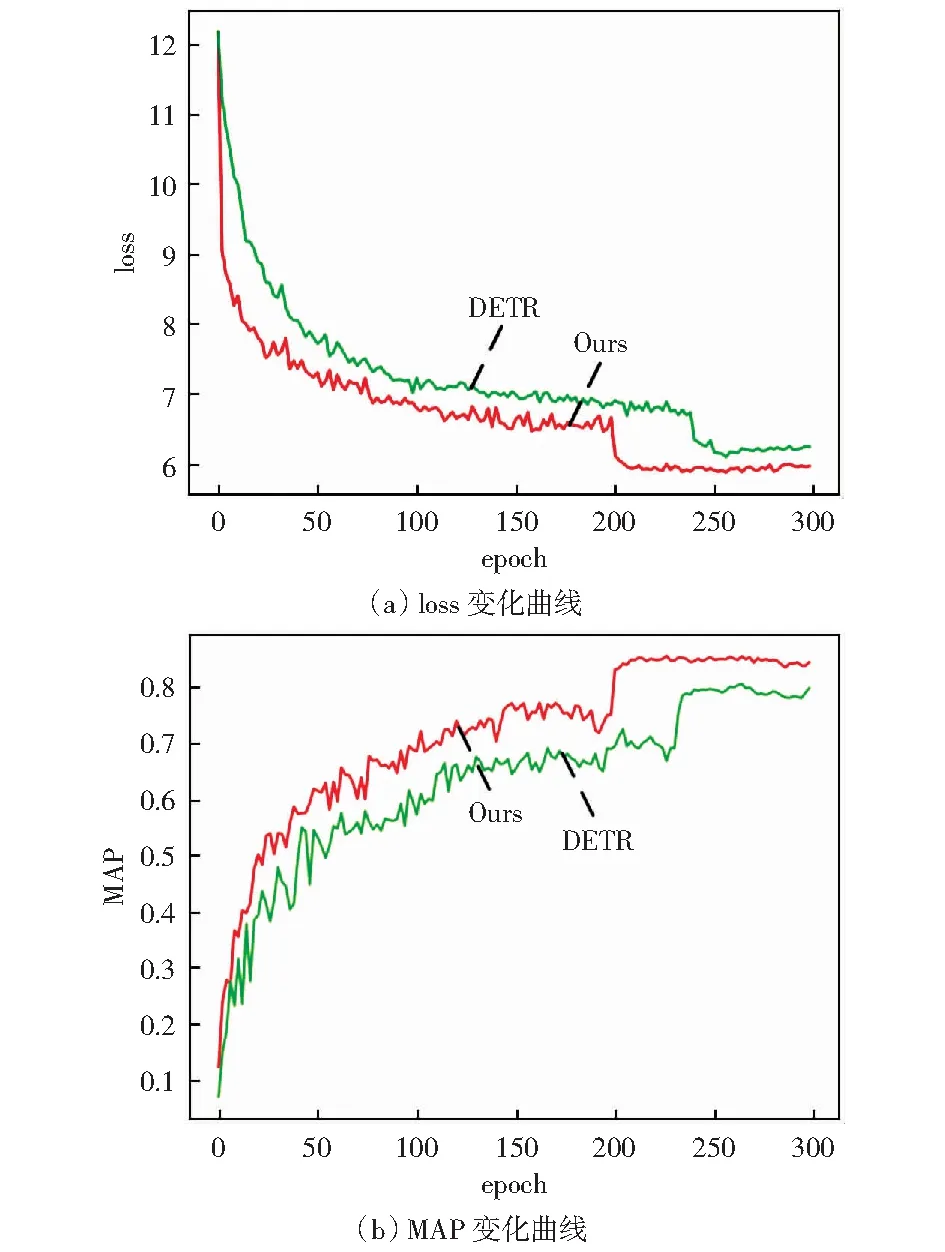
图8 训练过程中loss和MAP变化曲线图
图8(a)中损失曲线前期不断下降最终趋于稳定,由此可见两方法均训练充分。相比DETR检测方法,本文方法收敛速度更快,在204轮左右达到收敛,而DETR方法需要250轮左右才能收敛,本文方法所需收敛轮次仅为DETR的81.6%.从图8(b)可以看到本文方法的平均均值精度MAP也显著优于DETR.经分析,模型收敛速度加快是由于在编码器-解码器阶段使用Pre-LN Transformer结构,通过在残差块内部使用层归一化,有效降低了输出层附近参数梯度,加快了模型收敛。同时,联合回归损失,通过直接最小化预测框和标签中心点间归一化距离,在二者包含情况下依然奏效,进一步加快了模型的收敛。
3.4.3消融实验
为验证各组件改进对路面裂缝检测效果的实际增益,本文设计了消融实验,结果如表2所示。对比实验A、B和C可以看出,三者仅特征提取网络不同,相比ResNet-50来说,通过采用RepVGG-A2和Multi-Scale Transformer骨干网络提取裂缝图像特征,模型MAP能够分别得到0.5%和2.1%的提升。由此看出,Multi-Scale Transformer网络具有更强的裂缝特征提取能力。而且,对于路面裂缝这类形状不规则目标,保留浅层的裂缝纹理细节特征能够有效提升裂缝检测效果。对比实验C和D,发现Pre-LN Transformer对裂缝检测精度提升不大,其增益主要体现在上节“模型收敛性对比”部分中能够加速算法收敛。对比实验D和E,发现通过采用CIoU Loss和L1 Loss结合的联合回归损失,MAP能够提升1.2%.表2中实验结果表明,Multi-Scale Transformer骨干网络和联合回归损失均可有效提升路面裂缝检测精度,其中,Multi-Scale Transformer骨干网络对裂缝检测精度提升效果更为明显。

表2 消融实验结果
同时,为比较Pre-LN Transformer中Multi-Head Self Attention、FFN和Multi-Head Cross Attention各部分残差连接方式对模型收敛性的影响,设计了对比实验,结果如表3所示。对比实验A、B,发现相比使用transformer网络,仅使用Pre-LN Multi-Head Self Attention结构,模型收敛轮次减少了33轮。对比实验B和C,发现使用Pre-LN FFN对模型收敛性影响不大。对比实验C和D,发现使用Pre-LN Multi-Head Self Attention模型收敛轮次减少了12轮。表3中实验结果表明,对多头自注意力和多头交叉注意力模块使用Pre-LN连接能够有效加速模型收敛,减少模型的训练轮次。

表3 Pre-LN Transformer各部分连接方式对模型收敛性影响
4 结论
针对路面裂缝检测场景下裂缝检测精度较低的问题,本文提出了一种基于transformer的端到端路面裂缝检测方法,使用本文设计的Multi-Scale Transformer骨干网络和并行解码的Pre-LN Transformer构建深度学习模型。同时,使用CIoU Loss和L1 Loss结合的联合回归损失,评估预测框和标签间距离。实验结果表明,本文方法能够准确检测多种路面裂缝,在路面裂缝数据集上MAP达到84.2%,对路面裂缝自动化巡检具有一定的实用价值。而且,相较DETR检测方法,模型具有更好的收敛性,收敛轮次压缩18.4%.但是,在检测速度方面本文方法相较基准方法还有一定差距。下一步将结合知识蒸馏和模型压缩,探索模型轻量化改进,提高裂缝检测效率。
