分形理论引导的图像临界差异感知阈值估计
2022-11-18郭嘉骏姜求平邵枫
郭嘉骏,姜求平,邵枫
宁波大学信息科学与工程学院,宁波 315211
0 引 言
人眼视觉系统(human visual system, HVS)对处在一定阈值以下的图像内容变化/失真是无法察觉的,该阈值称为临界差异(just noticeable difference,JND)阈值(Macknik和 Livingstone,1998),通常用于消除图像中的视觉冗余,对提升图像压缩比以及信息隐藏效率具有重要的指导意义。近年来,针对JND阈值估计模型的研究取得了较大进展。根据计算域的不同,现有的JND模型可分为子带域JND模型和像素域JND模型两类。
子带域的JND模型(Watson,1993;Ahumada和Peterson,1997;Zhang等,2005;Wei和Ngan,2009;Bae和Kim,2017)通常在DCT(discrete cosine transform)以及DWT(discrete wavelet transformation)变换域的子带上进行,这类JND模型主要以对比度敏感函数(contrast sensitivity function, CSF)、亮度适应性以及空域掩蔽效应等因素作为重点。在估计JND阈值时,通常通过将输入图像进行固定尺寸的图像块划分来进行域变换,然后对每个块进行JND阈值计算。考虑到块划分操作会在一定程度上破坏图像内容的空域相关性,因此基于变换域的JND阈值估计模型往往不能很好地估计空域结构特性引起的空域掩蔽效应。考虑到像素间的空域相关性,基于像素域的JND模型根据每个像素与周围像素之间的空域相关性来估计每个像素点的JND阈值。由于不需要进行域变换,像素域JND阈值模型通常具有较高的计算效率。
像素域JND模型主要考虑亮度适应性和空域掩蔽效应对人眼可察觉阈值的影响(Chou和Li,1995;Yang等,2005)。亮度适应性是指人眼的光感受器细胞会自适应地调节信号转换效率,使人眼的视觉敏感度在低亮度和高亮度区域都会明显下降。亮度适应性方程可以由韦伯定理简单推导获得,该定理已广泛用于JND阈值估计。空域掩蔽效应是由视觉刺激间的交互作用产生的,该效应涉及一套非常复杂的视觉感知机理,至今仍然没有一套能够广为接受的计算模型。亮度对比度掩蔽效应作为一个影响空域掩蔽效应的基本因素,很自然地用来简单地描述与估计空域掩蔽效应。例如,Chou和Li(1995)根据4个方向(0°、45°、90°、135°)像素的最大亮度变化值来估计空域掩蔽效应。从以上模型的特性来看,图像边缘等具有较高亮度对比度的区域获得的JND阈值相对较大。然而,考虑到人眼对于边缘区域高度敏感,边缘区域仅能够容忍非常少量的噪声以及失真,因此传统的亮度对比度掩蔽模型通常容易高估边缘区域的JND阈值。为了解决这一问题,Yang等人(2005)在Chou和Li(1995)JND阈值计算模型的基础上,加入了边缘保护算法,避免了对边缘区域JND阈值估计过高。Yang等人(2005)利用Canny边缘检测算子提取图像中的边缘区域,并对边缘区域做保护处理来降低JND阈值。然而,Yang等人(2005)的模型仍然局限于仅采用亮度对比度掩蔽方程来刻画空域掩蔽效应,虽然图像的强边缘区域能够得到保护,但JND阈值在次/弱边缘区域处也因此被高估,而且处于纹理区域的JND阈值依然没有得到一个准确计算,始终还是被低估。Liu等人(2010)为了更加准确有效地估计图像纹理区域的JND阈值,首先将图像分解为结构和纹理两部分,接着在图像的结构分量上通过Canny算子提取边缘信息,再通过对比度掩蔽方程计算边缘区域和纹理区域的空域掩蔽强度,并对纹理区域的JND阈值赋予更高的权重,将这两部分进行融合,得到最终的空域掩蔽计算模型。尽管Liu等人(2010)方法使图像纹理区域JND阈值估计的有效性与准确性得到了提升,但忽视了HVS对图像内容规则(有序)区域和不规则(无序)区域噪声的容忍度是完全不同的,规则(有序)区域的JND阈值会远小于不规则(无序)区域的JND阈值。针对人眼对图像规则(有序)和不规则(无序)区域会表现出不同的敏感程度,Wu等人(2013a)分别从结构不确定度、自由能理论(Wu等,2013b)以及模式复杂度(Wu等,2017)等方面描述图像的规则(有序)性,且建立了相应的掩蔽方程,并通过与亮度对比度掩蔽方程融合构建得到新的空域掩蔽模型。除以上模型外,现有研究还考虑了其他因素引起的掩蔽效应对JND阈值的影响。例如,视网膜中心凹掩蔽(Bae和Kim,2017;Chen和Guillemot,2010;Chen和Wu,2020)、熵掩蔽(Wu等,2013b;Liu等,2010;Wang等,2020)和视觉关注度(Chen和Wu,2020;Niu等,2013)。许辰等人(2019)提出一种基于稀疏表示的结构信息和非结构信息分离模型,并应用于自然图像的JND阈值估计,使JND阈值模型与人眼视觉系统具有更好的一致性。Shen等人(2021)通过深度学习的方法估计图像结构信息对JND阈值的影响,并设计了一个新的JND阈值估计模型。
相比于早期的JND模型,以上经典模型在一定程度上提升了JND阈值估计的准确性,但都存在不足之处。Wu等人(2017)提出的基于模式复杂度的掩蔽效应直接计算图像块的方向多样性,对模式复杂度进行度量并构建其对应的空域掩蔽方程,但不能很好地刻画图像内容的纹理粗糙度对空域掩蔽效应的影响。通常,模式复杂度较高的区域具有较强的空域掩蔽效应,模式复杂度较低但是纹理粗糙度很高的区域也具有较强的空域掩蔽效应,只有模式复杂度较低同时纹理粗糙度较低的区域具有的空域掩蔽效应才会很弱。Chen和Wu(2020)采用的视觉关注度只考虑到了视觉关注区域分布的普遍性而忽略了不同图像内容的特殊性,在感兴趣区域偏离图像中心的情况下,其模型会对此区域的JND阈值做出不合理的估计。
为了解决以上问题,本文提出一种基于分形维数的图像JND阈值估计模型。首次引入分形理论(Mandelbrot,1977,1982)对图像的纹理粗糙度进行定量分析,通过计算图像块的分形维数度量纹理粗糙度,并在此基础上提出一种新颖的融合纹理粗糙度的空域掩蔽计算方法。此外,考虑到人眼视觉系统的选择性视觉注意机制,即人眼对图像中的部分感兴趣区域视觉关注度更高,引入视觉显著性对估计得到的JND阈值进行感知一致性修正,最终构建一个更加精确且更加符合人眼视觉感知特性的JND阈值估计模型。
1 基于分形维数的纹理粗糙度估计
分形理论(Mandelbrot,1977,1982)首先由Mandelbrot于1975年提出。分形理论为研究自然界中不规则、复杂和自相似的物体提供了强有力的数学基础。自然图像的大部分强度表面可以用各向同性分形来建模(Pentland,1984),分形分析中的一个基本概念是分形维数。分形维数是复杂形体不规则性的量度,根据尺度δ测量某些测量空间m(·)中给定点集E的幂律表现,总结了E的不规则性和统计自相似性。具体为
mδ(E)∝δ-FD
(1)
式中,mδ(E)是给定点集E在尺度δ上的一些度量。对于图像,该度量可以是强度、梯度或其他局部图像特征。
估计图像表面分形维数的技术很多。一种行之有效的方法是差分盒计数法(differential box-counting,DBC)。相较于其他方法,DBC方法在效率、精度和通用性方面具有很大优势(Sarkar和Chaudhuri,1994)。DBC方法将M×M的灰度图像I视为3维点集{(x,y,z)|z=I(x,y)},其中(x,y)表示像素点的空间位置坐标,z表示像素点的灰度值。假设原图像分割成大小为s×s的图像块(s是处于(1,M/2]区间内的整数),分割后的图像块与原图像比例关系为r=s/M。将这些图像块视作原图像上事先划分好的s×s的网格,每个网格上分别放置一列s×s×h的盒子,h表示单个盒子的高度。h与网格大小s和图像灰度级G之间的关系为
G/h=M/s
(2)
式中, 表示向下取整。
假设第(i,j)个网格中的最小灰度值和最大灰度值分别落在第k个框和第l个框中,则第(i,j)个网格上最小灰度值和最大灰度值的高度差为
nr(i,j)=(l-k+1)
(3)
式中,nr为有效高度差。集合全部网格的有效高度差,可以得到覆盖整个图像需要的盒子总数。即
(4)
然后,定义图像I的DBC分形维数为
(5)
考虑到Nr会因不同的r值而变化,这里从logNr/logr的最小二乘线性拟合中估计得到分形维数,记为dDBC。正常而言,dDBC的取值范围是[2,3)(Sarkar和Chaudhuri,1994)。dDBC越大意味着图像的纹理越粗糙,即纹理表观变化越不规律。当dDBC=2时,图像没有纹理,十分平坦。图1展示了拥有不同纹理的图像,其中,图1(a)—(c)的分形维数分别为2.000、2.251和2.780。可以看出,分形维数能够较好地反映纹理的粗糙度。

图1 不同的纹理图像Fig.1 Images with different textures((a) dDBC=2.000; (b) dDBC=2.251; (c) dDBC=2.780)
按同样的思想,将分形维数应用于图像块,从而可以描述一个局部图像块的纹理粗糙程度,最终得到描述图像局部纹理复杂度的图像。图2展示了基于图像块的DBC估计,其中,图2(b)为由DBC方法估计得到的纹理粗糙度图像。
2 JND阈值估计模型
2.1 方法简述
根据上述思想,可以计算得到原始图像每个图像块的分形维数,进而得到原始图像的纹理粗糙度图像。基于图像的纹理粗糙度,首先构建纹理掩蔽效应,并进一步结合对比度掩蔽效应得到空间掩蔽模型。另外,考虑传统的人眼的亮度自适应特性,通过融合空间掩蔽特性和亮度适应性得到初步的JND阈值估计模型。最后考虑人眼的视觉注意机制,引入图像空域显著性图,对每个像素点的JND阈值进行感知一致性调节,最终得到更加精确且更加符合人眼视觉感知特性的JND模型。本文方法的流程如图3所示。

图2 基于图像块的DBC估计Fig.2 Block-level DBC estimation((a)original image;(b) corresponding DBC-based texture coarseness map of (a))
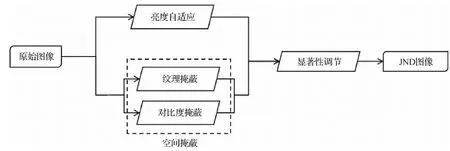
图3 基于分形理论的图像临界差异阈值估计模型流程Fig.3 Pipeline of the proposed JND profile
2.2 JND阈值的初步估计
初步的JND阈值估计模型包括亮度适应性LA(luminance adaptation)和空域掩蔽效应SM(spatial masking)两部分。其中,空域掩蔽效应包括对比度掩蔽效应CM(contrast masking)和纹理掩蔽效应TM(texture masking)。纹理掩蔽由亮度对比度和纹理粗糙度两方面共同决定。亮度对比度较高的区域具有较强的掩蔽效应。但是,亮度对比度高但是纹理粗糙度低的区域,其视觉掩蔽效应是较弱的。只有当亮度对比度高且纹理粗糙度也很高的区域,其视觉掩蔽效才是很强的。例如,条形图案图像(如图1(b))相比于平坦图像(如图1(a))具有更高的亮度对比度,其掩蔽效应也更强。但是,当它与同时具有高亮度对比度和极高纹理粗糙度的图像(如图1(c))进行比较时,图1(b)的空域掩蔽效应远弱于图1(c)。因此,本文同时考虑纹理粗糙度Ct和亮度对比度Cl对掩蔽效应的影响,以构建更加准确的纹理掩蔽模型。
由上述可知,dDBC越大的区域,其表面纹理越粗糙,对应的视觉掩蔽效应也就越强,即人眼对处于该区域内的图像内容能容忍的失真程度越大。因此,基于纹理粗糙度的掩蔽效应,记为Ct,对其进行估计的具体形式为
Ct(p)=(log2dDBC(p))α
(6)
式中,α为幂指系数,设置为4.85,p为该区域内的某个像素点。
亮度对比度Cl可以通过计算图像的梯度幅值进行简单表示,即
(7)
式中,Gv和Gh分别表示像素点p沿垂直和水平方向的梯度大小。
通常,纹理掩蔽效应的强度随亮度对比度Cl和图像纹理粗糙度Ct的增大而增大,并且只有当亮度对比度高且纹理粗糙度也很高的区域,其视觉掩蔽效应才是很强的。鉴于以上考虑,本文提出的纹理掩蔽效应采用相乘的方式对这两部分进行融合,即
TM=f(Ct)·f(Cl)
(8)
式中,f(Cl)与f(Ct)分别由非线性变换得到,具体为
(9)
f(Cl)=log2(1+Cl)
(10)
式中,β1是全局比例因子;β2表示指数参数,它控制非线性变换曲线的形状,较大的β2对应于更快的增益;β3为极小的正常数,主要是为了避免分母为零的情况。通过一系列主观测试,最终设置β1=0.6,β2=2.5,β3=0.1。
研究表明,人眼对光强变化的反应是非线性的,随着亮度对比度的增加,JND阈值增加的比例应减小(Legge和Foley,1980)。为此,Legge和Foley(1980)、Watson和Solomon(1997)和Foley(1994)引入了一种用于计算亮度对比度的非线性换能模型计算亮度对比度掩蔽效应
(11)
式中,α和β分别设为16和26。
本文将对比度掩蔽与纹理掩蔽都统一纳入空域掩蔽。一般来说,这两种掩蔽效应是并发的,但也有可能在某些情况下,其中一种掩蔽模式起主导作用。例如,对于规则边缘区域,对比度掩蔽效应起主导作用;而对于不规则区域,提出的纹理掩蔽则会成为主导。换句话说,本文认为掩蔽效应较强的一个将会起主导作用,因此取这两种掩蔽效应强度的较大者来表示最终的空域掩蔽效应
SM(p)=max(TM(p),CM(p))
(12)
此外,HVS对不同的背景亮度具有不同的视觉灵敏度,因此同样需要考虑HVS对不同亮度的视觉敏感性程度。研究表明,人眼在黑暗环境中对视觉刺激的敏感度较低,随着背景亮度的增加,HVS的视觉敏感度会随之提升;但是当背景亮度大于某一阈值时,其视觉敏感度又会减弱(Yang等,2005)。因此,不同背景亮度的JND阈值也是不同的。反映HVS对不同背景亮度具有不同视觉敏感性的亮度适应性函数通常可以用分段函数表示,具体为
(13)
式中,B(p)代表背景亮度,是像素点p局部邻域的平均亮度值。
最终,采用经典的掩蔽非线性可加性模型(nonlinear additivity model for masking,NAMM)(Yang等,2005)对亮度适应性函数和纹理掩蔽函数进行融合,得到初步的JND阈值图。即
JND(p)=LA(p)+SM(p)-T×min{LA(p),SM(p)}
(14)
式中,参数T是为了消除LA与SM之间的重叠导致JND阈值过高估计设定的约简系数。
2.3 视觉显著性调节
HVS具有视觉注意机制,即场景中的部分显著区域能够更加吸引人眼的视觉注意力,人类大脑在处理和感知图像时,会更多地获取显著性区域上的信息而无意识地忽略次要区域的信息。从这个角度而言,图像显著性区域JND的阈值理应更低,而非显著性区域JND阈值相对较高。因此,对于图像的JND阈值估计,应考虑图像内容视觉显著性的影响。
采用经典的GBVS(graph-based visual saliency)(Schölkopf等,2007)方法计算视觉显著性。GBVS方法能够对图像的显著性区域做出较为准确的描述,并同样具有显著性区域向中心偏移的特点,相较于Chen和Wu(2020)提出的显著性描述方法更符合视觉感知特性。图4展示了一些原始图像及其对应的GBVS显著图。
为了将GBVS融入2.2节中的JND(p),将GBVS显著图中每个像素点的数值进行量化,作为对应像素点初始JND阈值的调制因子。Hadizadeh (2016)对JND的显著性建模给出了新的思路。随着更高的视觉显著性,空间对比度掩蔽曲线的转折点被推到更高的频率,通过sigmoid函数对基于DCT的JND模型进行显著性调节。
同理,在空域中,HVS对显著性区域的信息获取较多,对非显著性区域的信息获取较少,同样符合sigmoid函数的特点。因此,用sigmoid函数对JND模型进行显著性调节依然合理有效。将原始图像的GBVS图记为GM,GM中元素的取值在(0,1)范围内,其数值大小反映像素点的显著性程度,取值越接近1,显著性越强。视觉显著性越强的区域的失真越容易被人眼察觉,其对应的JND阈值也越低。根据以上分析,将GM(p)作为sigmoid函数的变量,计算得到基于视觉显著性的JND阈值调制因子

(15)

图4 原始图像及其对应的GBVS视觉显著图Fig.4 The original images and their corresponding GBVS-based visual saliency maps((a) original images; (b) corresponding GBVS-based visual saliency maps of (a))
式中,γ1,γ2和γ3为控制参数,本文设置γ1= 1.59,γ2=9.91,γ3= 1。γ2= 9.91保证sigmoid函数值的上界近似为1,而γ1=1.59和γ3=1是通过主观实验确定的参数。选出20名受试者,测试用的图像通过式(14)计算出其JND阈值图后,按JNDrefine(p)=JND(p)×Gc(p)对JND阈值进行调节并注入噪声,由大到小控制噪声的注入量,具体方法为
FJND(p)=Fori(p)+τ·R(p)·JNDrefine(p)
(16)
式中,FJND为噪声污染图,Fori为原图,τ为噪声控制因子,R是与原图等大小的随机噪声模板,其中的各个元素均为1或-1,JNDrefine表示JND阈值图像。当75%的受试者恰好察觉到失真时,发现对于几乎所有图像来说,当γ1= 1.59且γ3= 1时,90%的受试者认为图像的主观视觉效果最好。最终的JND模型也定义为
JNDrefine(p)=JND(p)×Gc(p)
(17)
3 实验结果
3.1 与其他模型的比较
为验证本文提出的JND模型的性能,与Liu等人(2010)的模型、Wu等人(2013b)的模型、Wu等人(2017)的模型以及Chen和Wu(2020)模型进行比较。实验时,分别根据以上5种JND模型对原始图像按式(16)进行加噪处理。
图5展示了由5种不同JND阈值模型指导得到的加噪图像视觉效果对比。图5(b)—(f)的峰值信噪比(peak signal-to-noise ratio,PSNR)分别为30.23 dB、30.24 dB、30.20 dB、30.24 dB和30.20 dB。可以看到,尽管原始图像注入了几乎相同程度的噪声,但呈现的视觉效果(视觉感知质量)大不相同。1)Liu等人(2010)的方法对纹理细节的描述仅采取了简单的空间对比方法,无法准确估计复杂区域与平坦区域的可视性阈值。该方法将图像分为纹理图与结构图,并对两图分别进行JND建模,再通过非线性可加性模型(Yang等,2005)得到最终的JND模型。这种方法对图像的纹理细节缺乏正确的定义,对图像纹理细节的细腻与粗糙程度不能很好地进行评判,也未考虑人眼的视觉注意特性,从而会对图像部分区域的JND阈值做出不正确估计。从图5(b)可以看出,人物面部与颈部的噪声明显,而这些区域都是人眼比较关注的且都是纹理细节比较简单、有序的,本应分配更少的噪声。2)Wu等人(2013b)的方法首次考虑对图像无序内容的视觉掩蔽效应进行建模,将更多的噪声注入到头发、眼眶等不规则区域,在一定程度上取得了性能的提升。但是,该方法依然不能对人面部等人眼视觉关注度较高的区域的JND阈值做出准确估计。从图5(c)可以看出,这些区域依然存在较多的噪声,影响了视觉感知质量。3)作为Wu等人(2013b)方法的改进,Wu等人(2017)首次提出了模式复杂度的概念,通过计算图像纹理细节梯度的方向性来描述图像局部的模式复杂度。该模型能够准确描述图像的不规则区域,并在这些不规则区域中注入大量噪声,如图5(d)所示。人面部眼眶、皱纹和头发等不规则区域的噪声很大,其他有序或是平坦的区域几乎没有噪声的注入。但人物头发等有序区域上本可以在保证观看质量的前提下注入更多的噪声,说明该方法对纹理比较粗糙的区域的JND值估计并不准确。4)Chen和Wu(2020)采用非对称中心凹亮度掩蔽模型和非对称中心凹对比度掩蔽模型,虽然在对图像的JND阈值估计上引入了视觉关注度对其进行约束与调整,但该模型只考虑了人眼关注区域分布的普遍性,视觉关注区域集中在图像中心。从图5(e)可以看出,图像中央区域的噪声较小,其他区域的噪声很大,而对此图像而言,人眼的主要关注区域在整个人脸,这种方法不仅没有起到对原始图像JND阈值的有效修正,甚至产生了相反效果。此外,该模型对图像纹理细节的描述也仅是通过简单的梯度计算得到,没有考虑纹理的有序性与粗糙性的视觉掩蔽效应。以上因素均造成了图像JND阈值估计的不准确。5)本文模型不仅对图像的纹理细节做出了新的描述,综合考虑亮度对比度和纹理粗糙度的联合掩蔽效应,还在此基础上引入了更加准确的视觉显著性修正策略,能够比其他方法更加有效、准确地估计图像的JND阈值。如图5(f)所示,大部分噪声分布在头发等纹理比较复杂、无序和粗糙的区域,这都是人眼敏感度很低的区域。人脸眼部、嘴部及皱纹处虽然也是纹理无序、粗糙的区域,但这些是人眼比较关注的部分,因此噪声的注入量很小,这也使得观看者可以拥有更好的视觉体验,所以最终得到的噪声污染图像具有最好的视觉感知质量。

图5 本文JND模型与其他4种JND模型在引导噪声注入任务上的视觉效果比较Fig.5 Visual comparison between the proposed JND model and the other four existing JND models on JND-guided noise injection((a)original image;(b)Liu et al.(2010);(c)Wu et al.(2013b);(d)Wu et al.(2017);(e)Chen and Wu (2020);(f)ours)

图6 不同JND模型对两组自然图像在引导噪声注入任务上的视觉效果比较Fig.6 Visual comparison of different JND on two groups of natural images on JND-guided noise injection((a)original images;(b)Liu et al.(2010);(c)Wu et al.(2013b);(d)Wu et al.(2017);(e)Chen and Wu (2020);(f)ours)
图6给出了本文模型与其他4种模型在另外两组自然图像上的对比结果,与图5一样,5幅噪声污染图具有大致相同的PSNR,每幅图像的PSNR处于30.20~30.24 dB之间。可以看出,在注入相同量噪声的情况下,本文JND模型能够更加合理地分配噪声的注入位置,使最终得到的受噪声污染图像具有最好的主观视觉感知质量。
实验使用的图像库包括LIVE(Laboratory for Image & Video Engineering)图像库(Sheikh等,2005)、TID2013(tampere image database 2013)图像库(Ponomarenko等,2013)、CSIQ(categorical subjective image quality)(Larson等,2010)图像库及基于VVC(versatile video coding)的JND图像库(Shen等,2021)。
本文在上述4个图像库中分别选取了前10幅图像用于实验。共邀请了20人参加本次主观评测实验,每个人都具有正常的或矫正的视力。实验统计结果如表1—表4所示。其中,PSNR反映噪声的能量;VSI(visual saliency-induced index)是利用图像显著性特征图的失真计算图像质量的客观指标(Zhang等,2014),与主观感知具有高度一致性;MOS(mean opinion score)是被试者主观评分的平均值,评分标准如表5 所示。一般来说,在注入相同水平噪声(PSNR近似相同)甚至更多噪声(PSNR更低)的情况下,较好的JND模型将具有更高的VSI和MOS。
从表1—表4可以看出,相比于4种对比方法,本文JND模型不仅具有最低的PSNR,同时还具有最高的VSI及MOS,足以说明模型能够很好地引导噪声的分配,相较于其他对比模型具有更好的性能。

表1 在LIVE图像库上的模型性能比较Table 1 Models’ comparison performance on LIVE database
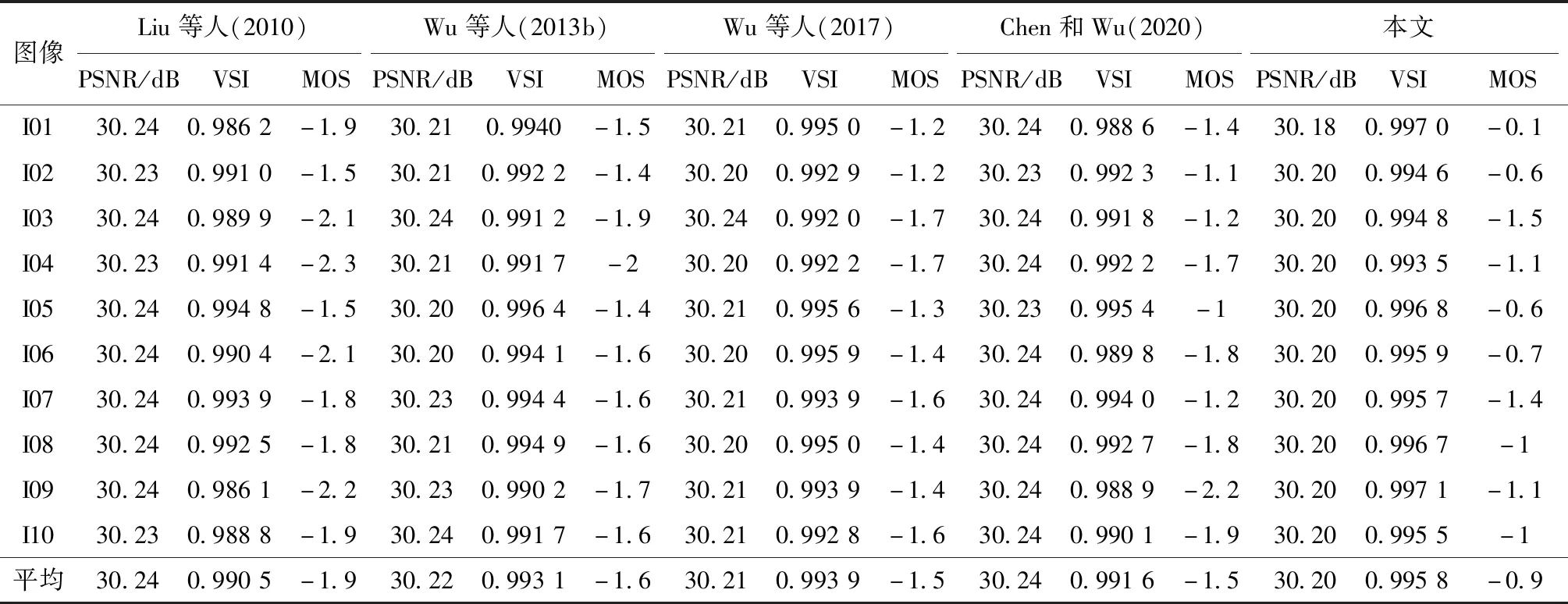
表2 在TID2013图像库上的模型性能比较Table 2 Models’ comparison performance on TID2013 database
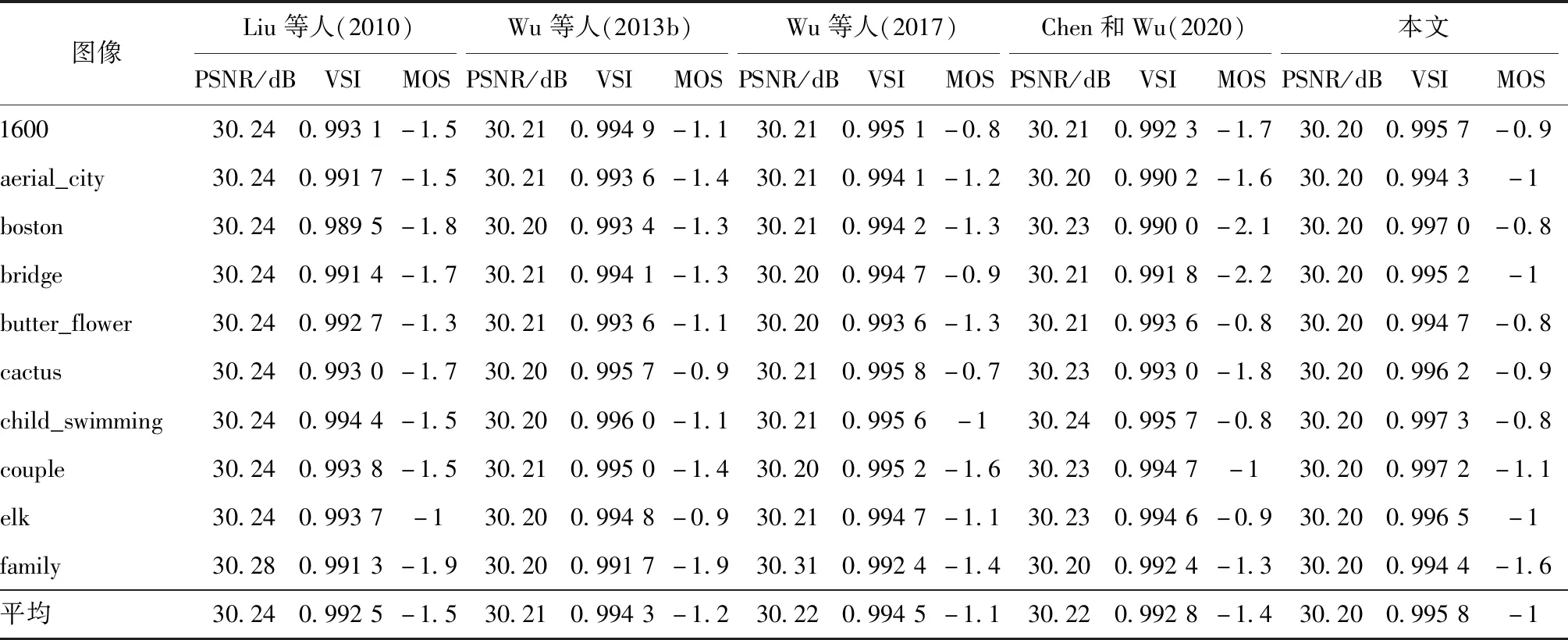
表3 在CSIQ图像库上的模型性能比较Table 3 Models’ comparison performance on CSIQ database

表4 在基于VVC的JND图像库上的模型性能比较Table 4 Models’ comparison performance on VVC based JND database

表5 与原始图像进行主观质量比较的评判标准Table 5 Judgment criteria for subjective quality comparison with the original image
对本文模型去掉对比度掩蔽效应与视觉显著性调节时的性能进行测试。图7展示了去掉这两个模块时得到的加噪图像的视觉质量对比结果。其中,图7(b)—(d)的PSNR在30.20~30.24 dB之间。可以发现,去掉对比掩蔽效应时(图7(c)),处理后的图像相对于考虑了对比度掩蔽效应时获得的结果(图7(b)),主观视觉质量差别不大,从客观指标VSI上也可以验证这一点,图7(b)的VSI为0.997 2,图7(c)的VSI为0.997 0。去掉视觉显著性的调节时(图7(d)),图像的感知质量明显降低,有大量噪声出现在人眼比较关注的区域(如人脸),且VSI同样有明显下降,为0.995 1,相较于图7(b)下降0.002 1。所以,模型中加入视觉显著性的调节是有必要的。
3.2 在图像压缩编码应用中的测试
在应用层面,JND模型可以用于指导图像编码。本实验将验证JND模型如何在保证图像视觉质量的情况下使用更少的比特对图像编码。实验采用与Wu等人(2017)同样的方法进行,用JND阈值对原始图像进行平滑处理,该过程可表示为

图7 对比度掩蔽效应与视觉显著性调节对模型性能的影响Fig.7 When removing the contrast masking effect and GBVS adjustment, the quality performance of the image processed by our method((a)original image;(b)noisy image guided by our model;(c)noisy image without contrast masking effect;(d)noisy image without GBVS)

(18)

图8展示了对图像coins-in-fountain的实验效果,图8(a)是原始图像经JPEG压缩后的结果,图8(b)是经JND平滑后的图像JPEG压缩后的结果,可以看出两者几乎拥有同样的视觉体验效果,但图8(a)为30 107个字节,而图8(b)为26 590个字节,字节数比正常JPEG压缩后的图像节约了12.0%。

图8 coins-in-fountain图像上的JND引导JPEG压缩实验Fig.8 JPEG compression experiment on the image of coins-in-fountain((a) JPEG compression;(b) JND+JPEG compression)
表6给出了LIVE库中前10幅图像的灰度图像关于此实验的对比结果。实验结果表明,通过本文的JND模型指导图像的JPEG压缩,在保证图像质量的前提下,编码时能平均节省12.5%的比特数。
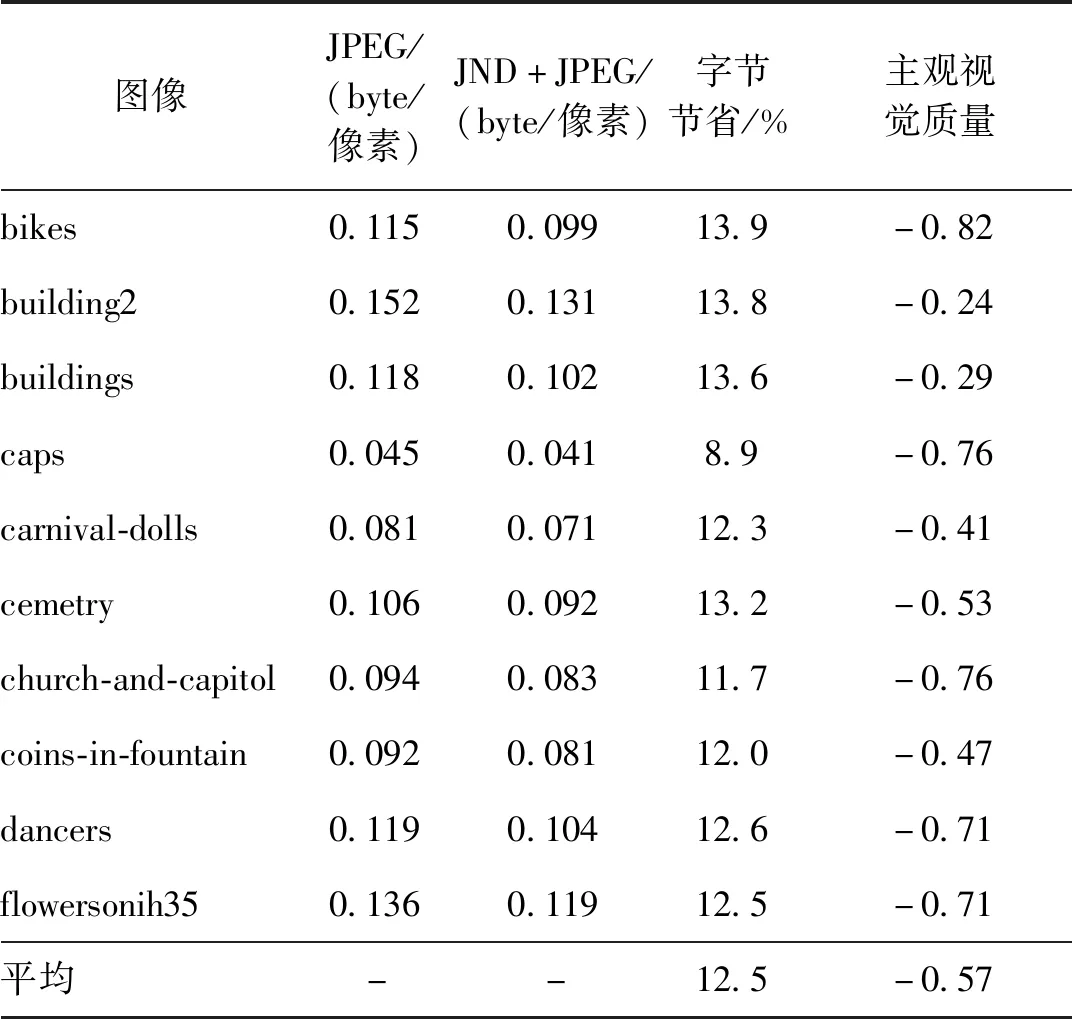
表6 基于JND引导的图像JPEG压缩实验Table 6 JPEG compression experiment of the first ten images in the LIVE
4 结 论
考虑到人眼视觉系统对具有粗糙表面的图像内容变化具有较低的分辨能力,本文基于经典的分形理论计算分形维数对图像局部区域的纹理粗糙度进行度量,并在此基础上提出一种新的基于纹理粗糙度的纹理掩蔽模型。将本文提出的纹理掩蔽模型与传统的亮度适应性相结合,估计得到初步的JND阈值。进一步考虑人眼的视觉注意机制,将图像内容的视觉显著性对JND阈值进行感知一致性修正,估计得到最终的JND阈值。总而言之,本文基于图像纹理的粗糙度和视觉显著性构建JND阈值估计模型,充分保证了图像JND阈值估计的准确性及可信度。实验结果表明,相比于对比模型,本文JND模型在引导噪声注入过程中充分考虑了图像纹理粗糙度对JND感知阈值的影响,并通过视觉显著性的调节使噪声尽可能避开人眼视觉感兴趣区域,使得经本文模型引导噪声注入得到的受噪声污染图像相较于现有模型具有更好的主观视觉质量和更高的客观质量评分。进一步地,感知冗余去除实验结果表明,在保持视觉质量的前提下,经由本文提出的JND模型平滑处理得到的JPEG压缩图像相比于原始JPEG压缩图像能进一步节省12.5%的字节数。
尽管本文提出的JND阈值估计模型取得了很好的效果,但是该模型没有考虑人眼的多尺度感知特性,探索多尺度感知影响下的图像纹理粗糙度对JND阈值的影响值得进一步研究;相比于静态图像,视频的应用更加广泛,未来将在该模型的基础上,进一步考虑时域掩蔽效应用于估计视频的JND阈值。
