融合场景信息的图像美学属性评价
2022-11-18李雷达段佳忱杨宇哲李亚乾
李雷达,段佳忱,杨宇哲,李亚乾
1.西安电子科技大学人工智能学院,西安 710071; 2.OPPO研究院,上海 200032
0 引 言
图像美学质量评价通过计算机模拟人对美的感知,对图像做出美学质量的判断。随着图像数据的爆发式增长,图像美学质量评价在图像推荐(Deng等,2017)、相册管理(Joshi等,2011)、图像增强(Liu等,2010;Chaudhary等,2018)以及图像检索(Luo和Tang,2008;Zhang等,2017)等众多领域中有着重要的应用需求,在计算机视觉领域的研究中也受到越来越多的关注。目前的图像美学质量评价研究主要集中在3个任务上:1)美学分类。将图像分为高美学质量和低美学质量(王伟凝 等,2016)。2)美学分数回归。预测图像的总体美学分数(Kong等,2016)。3)美学分布预测。预测图像不同美学等级的概率(Yan等,2016;Jin等,2018)。从美学二分类到美学回归,再到美学分布,可以提供的美学信息越来越丰富,但可解释性依然较弱。图像具有丰富的美学属性,例如内容、亮度、景深和色彩等,这些属性反映了图像与摄影规则的契合程度,为美学质量评价的结果提供了更易被人所理解的依据(Szegedy等,2015)。
图像的美学属性预测,对于提高美学评价模型的可解释性以及提升评价的总体性能具有重要意义(Tang等,2013)。通过研究摄影图像中美学属性的特点,可以发现决定审美体验的美学属性与图像的场景类别存在很强的关联性。例如在以人像为主的肖像图中,观察者更关注图像前景而不是背景的细节,审美体验主要与构图、景深等属性相关;而在以自然风光为主的风景图像中,尽管图像中可能包含人,观察者更加关注整幅图像的构图和色彩,审美体验主要由图像的内容趣味性、色彩丰富性、颜色和谐性等属性决定。如图1(a)(b)是来自图像美学属性数据集(aesthetics and attributes database,AADB)(Kong 等,2016)中的高美学图像,但图1(a)是人物肖像,景深在各属性之中最为突出;而图1(b)是自然风光,色彩和谐、光线和色彩鲜明度等属性更为突出。基于美学属性与场景信息相互关联的特点,本文提出了一种利用场景信息来辅助图像美学属性预测的深度网络模型,用以同时预测图像的美学属性和整体美学分数。具体地,本文构建了一个双流的深度残差神经网络,一支网络基于场景预测任务进行训练,以提取图像的场景特征;另一支网络提取图像的美学特征。然后融合这两种特征,通过多任务学习的方式进行训练,以预测图像的美学属性和整体美学分数。

图1 不同场景的图像及美学属性标注示例Fig.1 Two example images with different scene categories((a) high aesthetic image of people; (b) high aesthetic image of natural scenery)
1 相关工作
1.1 基于深度学习的图像美学质量评价方法
随着深度学习在计算机视觉领域的成功,目前的图像美学质量评价方法也主要采用深度学习方法。研究者们首先将深度神经网络应用到美学质量评价的特征提取阶段,即先使用深度神经网络自动提取图像的美学特征,再使用这些特征训练支持向量机等模型来进行美学分类。Dong等人(2015)使用预训练的AlexNet提取图像的美学特征,然后使用提取的特征训练支持向量机分类器对图像美学质量进行分类。与此同时,研究者们也尝试将深度学习同时应用到美学质量评价的特征提取阶段和美学决策阶段,进而设计端到端的美学评价模型。Lu等人(2015)设计了一种双通道卷积神经网络模型,同时将原始图像和随机裁剪之后的图像输入网络提取特征,然后将两种特征联合起来,训练深度模型来实现美学评价。Ma等人(2017)使用目标检测方法以及显著性、纹理等低级别信息提取更多的图像块,进而构建多通道深度网络模型,实现了较好的美学评价性能。Li等人(2020)提出了一种性格辅助的多任务深度网络模型,其考虑审美的主观偏好,结合用户的个性特征预测,同时实现了对图像的大众化和个性化美学评价。
目前的图像美学评价方法主要集中于3个任务,即美学二分类、美学分数回归以及美学分布预测,但现有方法缺乏美学评价的细节描述(王伟凝 等,2012)。上述提到的应用美学属性的方法也没有关注美学属性本身,而是将属性用作预测整体美学分数或等级的中间特征。由于深度网络强大的特征学习能力,预测图像的美学属性也变得更加便捷,近年来开始出现一些图像美学属性预测的方法。Kong等人(2016)提出了属性自适应的深度卷积神经网络用于审美评分预测,在预测美学评分的同时给出了美学属性的评价结果。Malu等人(2017)通过使用具有合并层的深度卷积网络对美学分数和美学属性进行联合学习,合并层收集深度网络各层的全局平均池化特征,然后使用多任务的方法同时学习美学分数和美学属性。在此基础上,Pan等人(2019)使用多任务深度网络来同时学习美学分数和属性,通过对抗学习来探索真实美学分数和属性中固有的联合分布,以进一步提高美学属性和美学分数的预测准确率。
1.2 图像美学属性数据集
Kong等人(2016)构建了一个图像美学属性数据集AADB。该数据集包含了从Flickr网站上下载的10 000幅图像,并且所有图像都标注了11种美学属性,即平衡元素(balance element)、内容(content)、色彩和谐(color harmony)、景深(dof)、光线(light)、对象(object)、三分法则(rule of thirds)、色彩鲜明度(vivid color)、重复性(repetition)、对称性(symmetry)和运动模糊(motion blur)。如果某种属性对于图像的整体美感有积极的贡献,评分者标注1分;如果某种属性降低了照片的整体美感,评分者则标注-1分。每幅图像至少由5名被试给出评分,然后计算其平均值作为该属性的得分。此外,每位被试还对图像的整体美学给出1~5分的评价,同样取平均作为最终的美学分数。
Kang等人(2020)构建了一个可解释的图像美学数据集(explainable visual aesthetics dataset, EVA)。EVA数据集包含4 070幅图像,每幅图像包含至少30名评分者的标注。除了整体的美学评分外,EVA数据集还提供了光线和颜色(light and color)、构图和景深(composition and depth)、质量(quality)和语义(semantic)4种美学属性的评分。同时,EVA数据集还将所有图像分为6类场景:动物(animal)、建筑与城市景观(architecture and city scenes)、人类(human)、自然田园风光(natural and rural scenes)、静物(still life)以及其他(other)。此外,EVA数据集还提供了用户标注图像美学分数的难度、美学属性对整体美学的相对重要性等信息,使标注具有更好的可解释性。
2 方 法
基于摄影学知识可知,特定美学属性的重要性很大程度上取决于图像的场景类别。因此,即使整体美学表现相同,不同场景的图像中不同属性对于整体美学的重要性程度也存在很大的差异。受此启发,本文提出了一种端到端的双流多任务卷积神经网络模型来预测图像的美学属性以及整体的美学分数。图2为本文提出的美学评价模型框图,该模型由双流深度残差网络组成,一支网络基于场景预测任务进行训练,以提取图像的场景特征;另一支网络提取图像的美学特征。然后融合这两种特征,通过多任务学习的方式进行训练,以预测图像的美学属性和整体美学分数。基于这样的模型设计,本文方法可以有效地利用图像场景语义信息,以此来优化图像美学属性的预测,进而取得优秀的性能。本文方法步骤如下:
1)图像场景分类。由于审美标准的多样性、主观性和模糊性,图像美学质量评价任务具有很强的挑战性(Nanay等,2019)。因此,使用大规模视觉识别数据集ImageNet对双流深度网络进行预训练,以加快模型收敛(Deng等,2009)。预训练完成后,为了利用图像的场景信息来辅助美学属性预测,首先基于EVA数据集训练双流模型中的第一个分支网络来预测图像场景类别。EVA数据集中将图像分为了动物、建筑与城市景观、人类、自然田园风光、静物和其他等6类(Kang等,2020)。在训练时,将残差网络各层特征全局平均池化(global average pooling, GAP)后拼接以得到图像的特征。与传统深度网络只保留最后一层特征的方法相比,这种方法能够同时保留深度网络中低层次和高层次的特征,有利于提升深度神经网络的性能。具体地,先对深度网络中每一层的特征进行全局平均池化。用i表示深度网络的第i层,特征Fi的尺寸为hi×wi×ci;对其进行全局平均池化后,特征尺寸变为1×1×ci。将来自深度网络各层的所有特征连接到一起,即
(1)
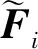
接着,将图像的整体特征φ(x)输入到网络的全连接层(FC),再通过softmax层输出图像属于6类场景的概率。这里,使用交叉熵损失函数(cross entropy loss function, CE)来衡量分类的误差,交叉熵损失计算为
(2)
式中,N为样本总数,p(xi)和q(xi)分别为样本xi的真实概率分布和预测概率分布。
2)特征融合。完成场景预测分支网络的训练后,需要提取图像的美学特征,并融合场景特征和美学特征进行训练。本文使用特征串联的方法融合双流网络得到的两种特征(Cao等,2018)。特征串联将两个及以上的图像特征图在通道或数量维度上进行拼接,多用于利用不同尺度特征图的语义信息,以增加通道数的方式实现更好的性能。与特征元素点乘或者相加减的融合方式相比,特征串联运算量较少,并且保留了更多的图像信息。
如图2所示,场景预测分支训练完成后,将该分支网络中各层的特征全局平均池化后在通道上拼接以得到场景特征。同样地,将美学特征提取分支中各层的特征全局平均池化后在通道上拼接以得到美学特征。令φ1(x)和φ2(x)分别表示来自双流深度网络的场景特征和美学特征,其尺寸分别为1×1×c1和1×1×c2,将其在通道上进行拼接以完成特征串联
(3)
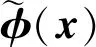
3)美学属性损失动态加权。对于每一种图像美学属性,需要获得其回归分数,本文使用均方误差(mean square error, MSE)损失函数来衡量预测值与真实值之间差异程度,计算方式为
(4)
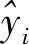
针对多种美学属性,Malu等人(2017)采用为各属性损失分配固定权重,然后加权求和的方式来设置损失函数,其计算为
(5)
式中,N为美学属性的个数,wi为分配给第i种属性的权重,yi表示第i种属性的真实分数,x表示输入模型的图像,fi(x)表示第i种属性的预测值,LMSE(fi(x),yi)表示第i种属性的均方误差损失。
上述损失函数之中的权重wi值始终固定不变,需要依据先验知识确定。为了避免不当的权重设置影响模型性能,本文采用属性损失动态加权的方案,利用深度网络自动学习权重,损失函数为
(6)
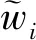
3 实 验
3.1 数据集
实验中,采用EVA数据集训练场景预测分支,用AADB数据集训练美学属性和整体分数。在具体实现中,将EVA数据集划分为3 470幅图像的训练集和600幅图像的测试集;将AADB数据集划分为:训练集8 500幅图像,验证集500幅图像,测试集1 000幅图像。此外,由于数据集中重复性、对称性和运动模糊这3种属性的标注分数大多数为零,因此采用与Kong等人(2016)和Malu等人(2017)类似的做法,只对其余8种美学属性及整体美学分数进行学习。
3.2 实验设置
本文的双流网络均使用ResNet50作为主干网络。ResNet独特的残差结构设计使其可以克服网络层数过深造成的梯度消失问题,因而性能优异(He等,2016)。此外,模型在训练之前先使用数据集ImageNet进行预训练,使模型初步具备提取特征的能力。实验中,将EVA数据集中的图像缩放至256× 256×3大小作为网络输入。实验中网络训练所使用的机器配置为i7-10700 CPU和NVIDIA GTX 1660 SUPER GPU,batch大小设置为 12,epoch设置为15,使用Adam优化算法,主干网络学习率设置为 1E-5,全连接网络学习率设置为 1E-6。
在训练完图像场景预测分支之后,固定此分支参数,使用AADB数据集训练美学属性及整体美学分数。具体地,将图像美学特征与场景特征相融合;由于经过了全局平均池化(GAP),最终得到的特征尺寸大小为30 214 ×1×1。接着将融合特征输入全连接网络,以预测美学属性和整体美学分数。实验中,将数据集中的图像缩放至256× 256×3 大小作为网络输入。此处的batch大小设置为12,epoch设置为25,使用Adam优化算法,主干网络学习率设置为 1E-5,全连接网络学习率设置为 1E-6。
3.3 实验结果
3.3.1 美学属性预测结果
在对AADB数据集训练集8 500幅图像进行25次完整的训练之后,模型趋于稳定。实验结果采用斯皮尔曼相关系数(Spearman rank-order correlation coefficient,SRCC)来衡量,用以表征预测结果与真实值的一致性。将本文基于场景信息的图像美学属性预测方法与现有方法的性能进行对比,实验结果如表1所示。由于结合了图像场景地语义信息,本文图像美学属性预测方法在性能上表现更加优秀。与Kong等人(2016)方法相比,本文基于ResNet主干网络,通过融合双流ResNet网络得到的图像场景与美学特征,实现了更好的性能。与Malu等人(2017)的方法相比,虽然都使用ResNet网络提取场景信息,但本文引入图像场景分支网络,由于场景信息与美学属性之间存在较强的关联性,融合场景信息提高了图像美学属性预测的性能。在表1中,本文方法在大多数属性以及整体美学分数预测上都取得了最好的性能,但对平衡元素和三分法则属性预测的相关系数较低,分别为0.251 4和0.173 1。为了探究潜在的原因,本文分析了AADB数据集中平衡元素和三分法则两种属性的分数分布,如图3(a)(b)所示。可以发现,AADB数据集中,上述两种美学属性的分数大多集中在[-0.25, 0.25]范围内,样本分布高度不平衡,缺乏正负样本,从而导致深度网络学习困难,预测结果相关系数较低。图3(c)(d)中给出了内容和对象两种美学属性的分数分布统计,可以发现相比于平衡元素和三分法则属性,内容和对象属性的标注分数分布明显更为均衡,正负样本数量较多,因而有利于深度网络的训练,属性预测较为容易,相关系数相对较高。由此可见,平衡元素和三分法则预测结果较差是源于AADB数据集标注的局限性。
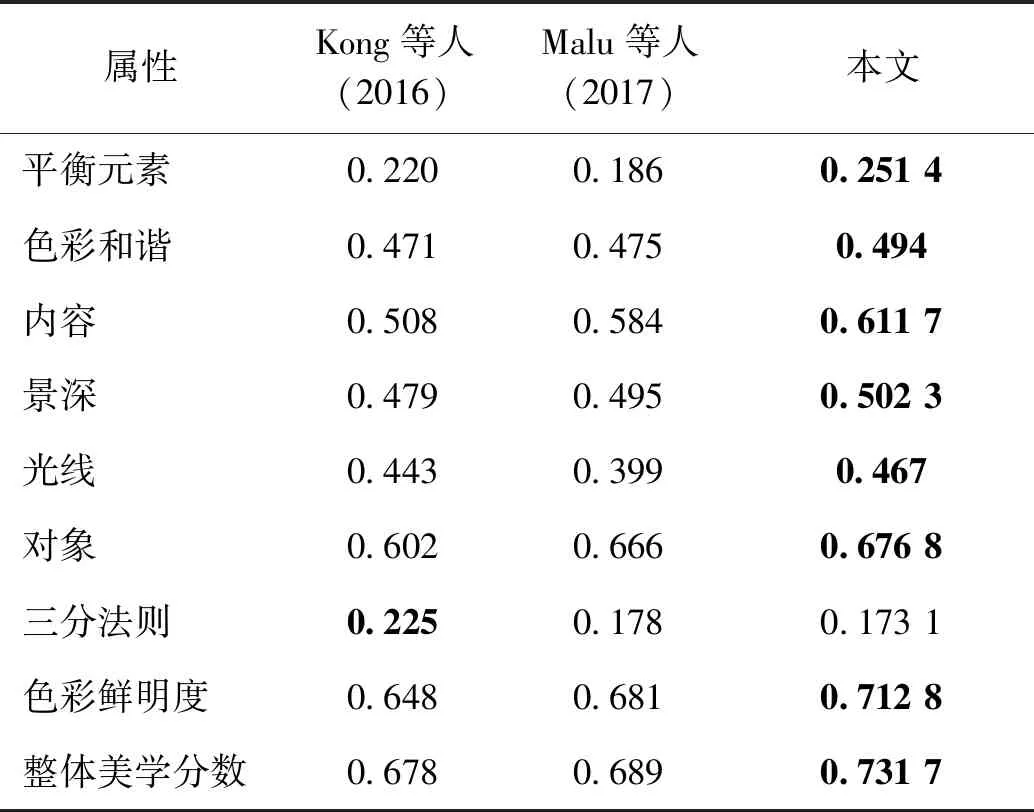
表1 美学属性以及整体美学分数的斯皮尔曼相关系数Table 1 Spearman rank-order correlation coefficient of aesthetic attributes and overall aesthetic scores
在模型的计算复杂度方面,比较了本文方法与已有方法的模型参数量(params)以及每秒浮点运算次数(floating-point operations per second, FLOPs),见表2。与Kong等人(2016)方法相比,本文方法舍弃VGG16(Visual Geometry Group 16-layer network)网络,使用轻型网络ResNet50作为主干网络,模型的参数量和计算量都大幅压缩。与Malu等人(2017)方法相比,在主干网络均为ResNet50的情况下,本文方法因为使用了双流网络架构,在模型参数量上约为它的两倍,在模型计算量上与之接近。总体而言,本文方法在保证模型计算复杂度较小的前提下,实现了更好的预测性能。
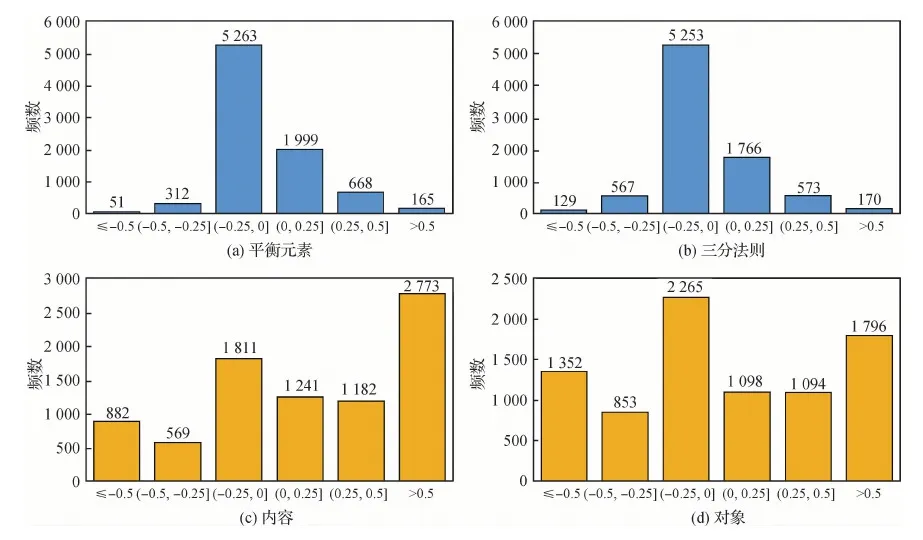
图3 AADB数据集中4种美学属性的分布直方图Fig.3 Histogram distribution of four aesthetic attributes on AADB dataset((a) balance element; (b) the rule of thirds; (c) content; (d) object)

表2 模型计算复杂度比较Table 2 Comparison of computational complexity of model
图4给出了本文模型评分的4个示例。与Malu等人(2017)方法相比,本文方法在整体上表现更好,与真实值更为接近。Kong等人(2016)方法并未开源,且性能相比Malu等人(2017)方法较差,故并未比较。
3.3.2 美学分数预测结果
将本文方法在AADB数据集上的美学分数预测结果与现有方法进行比较,对比方法有:
1)PAR(photo aesthetics ranking network)。Kong等人(2016)训练一个输入为两幅图像的孪生网络模型,并通过分数回归直接预测美学。
2)MT-DCNN(multi task deep convolutional neural network)。Malu等人(2017)使用具有合并层的深度卷积网络来联合学习美学分数和属性。
3)PAAL(predict attributes through adversarial learning)。Pan等人(2019)使用多任务深度网络来同时学习美学分数和属性,然后通过对抗学习,探索真实美学分数和属性中固有的联合分布。
4)NIMA(neural image assessment)。Talebi和Milanfar(2018)提出EMD(earth mover’s distance)损失函数,用于美学分布预测。
5)UIAA(unified formulation of image aesthetic assessment)。Zeng等人(2020)将原来的分数标注重组成更稳定的高斯分布,并利用交叉熵损失进行美学分布学习。
表3中给出了本文算法与上述对比算法在AADB数据库上美学分数预测的实验结果。从表中可以看出,本文方法的斯皮尔曼相关系数处于领先水平。这证明了本文方法不仅可以有效地预测出图像的美学属性,在图像整体美学分数预测上也实现了优秀的性能。
3.3.3 消融实验
为了充分验证场景信息对美学属性预测的辅助作用,本文设计了一个消融实验。采用双流网络结构,融合图像的场景信息来辅助美学属性预测。消融实验中,本文去掉网络中预测场景的分支,直接使用多任务学习的方法预测美学属性以及整体美学分数,除此之外的其余设置保持一致。实验结果如表4所示,从表4中可知,在融合图像场景信息后,大多数的美学属性以及整体美学分数的预测准确率都得到提升,这也表明了将场景信息应用于美学属性预测的合理性。总体而言,本文方法在相同条件下提升了图像美学属性预测以及整体美学分数的预测准确率。

图4 模型评分示例(为了便于展示,属性分数被标准化为0~1)Fig.4 Test cases of our proposed method(for ease of presentation, attribute scores are normalized to 0 to 1)((a)case 1;(b)case 2;(c)case 3;(d)case 4)

表3 整体美学分数的斯皮尔曼相关系数Table 3 Spearman rank-order correlation coefficient of overall aesthetic scores
3.3.4 不同场景图像中美学质量与属性的相关性
为了进一步分析美学属性的预测结果,同时分析美学属性与场景类别的关联性,本文统计了模型预测结果中不同场景类型图像的整体美学分数与各属性的斯皮尔曼相关系数,见表5。
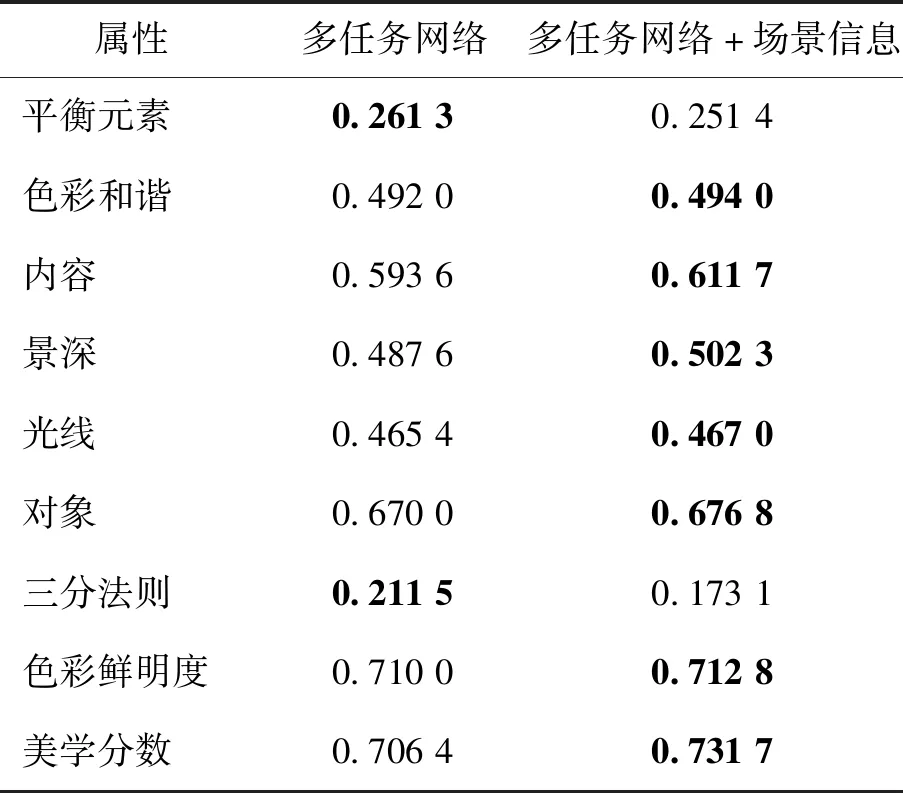
表4 美学属性以及整体美学分数的斯皮尔曼相关系数Table 4 Spearman rank-order correlation coefficient of aesthetic attributes and overall aesthetic scores
从表5中数据可知,不同的美学属性在不同场景类别的图像中与整体美学的相关程度各不相同。例如,景深属性在动物与静物场景中均与美学分数高度相关,分别为0.826 6与0.720 2,这也符合这两类图像的拍摄规则:大量地使用微距镜头与浅景深以凸显被拍摄的主体,而在其他场景图像中并不突出。色彩和谐、光线和色彩鲜明度均为光照色彩方面的属性,它们在自然田园风光场景的图像中与美学分数相关度很高,这也与自然景观图像大多色彩丰富且鲜明的规律相吻合。而在建筑与城市景观场景图像中,由于城市建筑的色彩较为单调,色彩类的属性与美学相关程度较低。除了内容和三分法则属性外,大多数美学属性呈现出与特定图像场景相关的特性。内容属性在所有场景类型的图像中与美学相关程度都很高,这是由于内容作为最基本、最重要的美学属性, 在几乎所有的摄影作品之中都十分重要。而三分法属性则在全场景图像中都表现较差,出现这个结果的原因一方面是上文提到的AADB数据集中三分法则属性标签分布不均衡,导致预测困难;另一方面是三分法则往往仅适用于特定情景的图像中,而在实际的拍摄中很多场景并不十分注重三分法则的运用(尤其是业余摄影)。
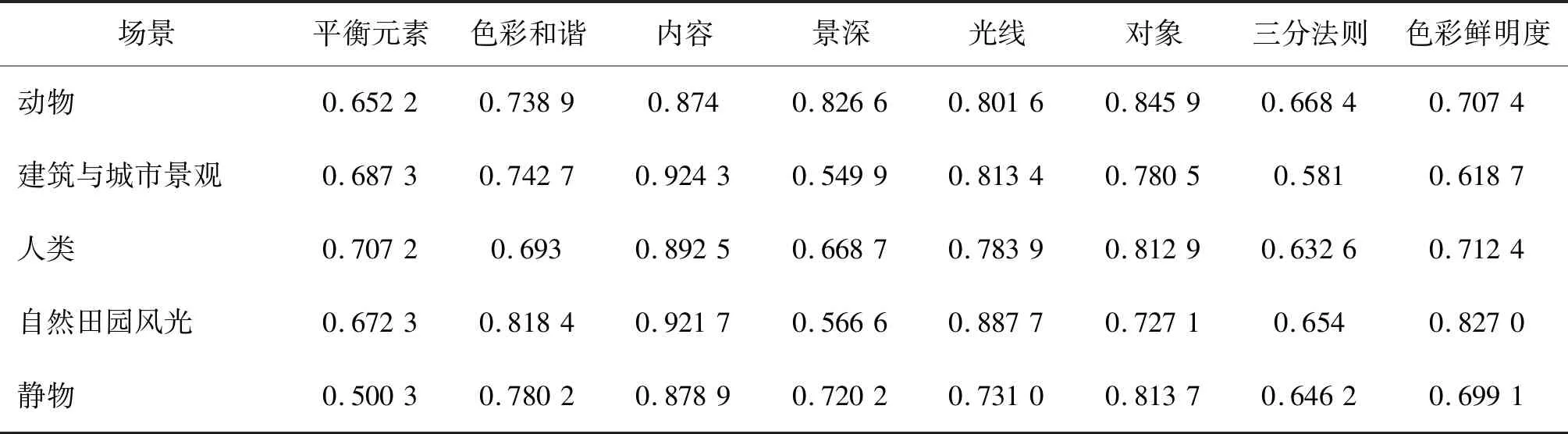
表5 各场景图像中美学属性与整体美学分数相关系数Table 5 Correlation coefficient between aesthetic attributes and overall aesthetic score in each scene image
综上所述,在不同场景类别的图像中,图像的美学属性对整体美感的形成起到不同程度的作用;本文提出的方法结合这一规律来预测图像的美学属性,预测结果也符合已有的摄影规则和认知规律。结合场景信息,本文设计的美学属性预测模型取得了较好的性能。
4 结 论
本文提出了一种基于场景辅助的图像美学属性预测方法,通过充分挖掘图像场景与美学属性的关系,实现美学属性和美学分数的准确预测。现有的美学质量评价方法大多并未利用场景信息,或者仅仅简单、浅显地利用了场景信息与图像美学的联系,因而在美学属性预测方面的性能有限。从实验结果来看,本文方法在美学属性以及整体美学评分预测上均取得了较好的结果。场景信息在美学属性预测中的积极作用,表明了场景信息与美学属性的紧密相关性,也表明了场景信息在图像美学质量评价研究中的重要性。未来的研究需要更加深入地挖掘场景语义与图像美学的深层次关联机制,进而构建新的学习框架,进一步提升图像美学质量评价的性能,增强图像美学评价的可解释性。
