结合域适应学习的糖尿病视网膜病变分级诊断
2022-11-18宋若仙曹鹏赵大哲
宋若仙,曹鹏,赵大哲
1.东北大学计算机科学与工程学院,沈阳 110819; 2.医学影像计算教育部重点实验室,沈阳 110819
0 引 言
糖尿病视网膜病变(糖网)(diabetic retinopthy,DR)是最常见且严重的糖尿病微血管并发症之一,是致盲的主要病因。据国际糖尿病联合会统计,2019年糖尿病人群占全球糖尿病患者的9.3%(4.63亿),预计2030年达到10.2%(5.78亿),到2045年将上升至10.9%(7亿),其中约1/5的患者经受了糖网的侵害(Saeedi等,2019;Tilahun等,2020)。临床医学研究发现,定期的眼底筛查和早期诊断可以减少98%视力丧失情况的发生(Crossland等,2016)。糖网诊断需要专业医生识别出眼底图像的异常病理特征并划分病变的严重程度,但糖网人群数量巨大导致人工诊断无法满足需求。因此,迫切需要一种计算机辅助医疗自动诊断方法,短时间内得到更准确的诊断结果,帮助医生提高诊断效率。
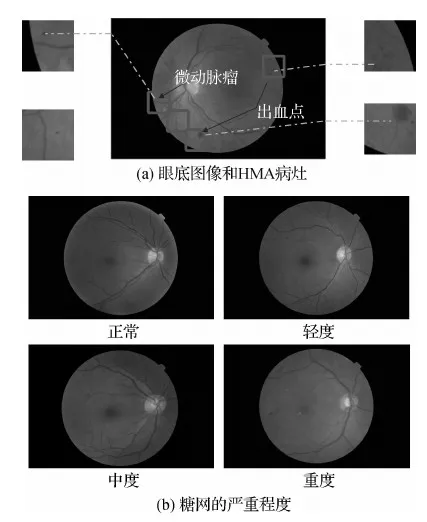
图1 HMA病灶以及糖网的严重程度Fig.1 HMA lesions and severity of DR((a) fundus images and HMA lesions;(b) severity of DR)
糖网分级诊断问题可以视为糖网多分类问题。微动脉瘤(microaneurysms,MA)和出血点(hemorrhages,H)是糖网早期阶段出现的病理特征(Khan等,2020),图1显示了HMA(hemorrhages and microaneurysms)病灶和糖网不同程度的视网膜图像实例。卷积神经网络(convolutional neural network,CNN)在糖网多分类任务中表现出令人印象深刻的分类性能(Khatun和 Hossain,2019)。在特征表征学习方面,深度学习相比于传统线性系统、核函数方法或浅层神经网络,得到的深度特征具有更强拟合目标函数的能力,避免了传统方式显示特征提取的过程。然而,基于深度学习的糖网诊断方法仍存在以下3个亟待解决的问题:
1)目前,糖网多分类的性能主要取决于HMA的检测精度(Cao等,2017)。以像素为单位对医学图像上的标注是十分昂贵的,费时费力的同时需要专业的医生进行勾勒,不同医生的标注标准也有差异,降低了数据的可靠性。因此,在HMA检测和分类流程中,病灶标签缺失导致传统的监督学习方法无法进行有效训练和学习。
2)在传统模式下,训练数据与测试数据需要保持独立且相同分布的约束条件(Tan等,2018),但单一数据集数据稀缺,致使衍生出多个数据集融合以提高分类性能的方法。Voets等人(2019)在Kaggle数据集构建基于InceptionV3 CNN的分类器,移植到Messidor数据集完成糖网诊断。Zago等人(2020)选择5层CNN模型训练DIARETDB1(standard diabetic retinopathy database calibration level 1)数据集提取HMA病理特征构建分类器,在Messidor数据集测试糖网分类性能。但这些方法忽略了不同数据集的数据分布、采集方式等因素影响导致的特征差异,引发跨域数据异质性问题。
3)识别医学图像的疑似病变区域是非常重要的,可为医生和患者提供诊断决策的视觉参考(Wang等,2017)。但深度学习缺乏直观的可解释性,没有给出与临床病理学相关的分类依据。
问题1)和问题2)属于数据问题,深度学习模型依赖于临床数据的数量和质量。问题3)是深度学习模型本身的问题,无法在语义上解释模型的预测是现有基于深度学习的计算机辅助诊断方法的瓶颈。为了解决上述问题,本文提出一种结合适应学习并协同注意力机制构成弱监督的网络模型(weakly-supervised network with attention mechanism and domain adaptation,WAD-Net)。病灶标签的缺失是弱监督学习问题(Cheplygina等,2019),本文借助于多示例学习(multiple instance learning,MIL)框架的“示例—包”思想建立“病灶—影像”关联关系,不依赖于有标记的HMA训练样本,只需要全局的图像级监督诊断信息实现“病灶—影像”的映射,进而高效自动地对糖网病变诊断。除此之外,针对数据异质性问题,采用迁移学习(transfer learning,TL)在样本层面进行跨域迁移,缓解数据异质性对模型的影响,提高方法的泛化能力。同时,结合注意力机制定位细粒度高度疑似HMA的位置,提高全局的分类性能和解释性。整体模型能够预测糖网病变的严重程度,并且评估局部样本对最终分类决策的重要性。最后,WAD-Net实现端到端的糖网分级诊断方法,抑制其他无关样本对性能的影响,提供模型预测的可解释性,并与几种方法相比获得了较好效果。
1 相关工作
基于对抗的深度迁移学习因良好的迁移效果和较强的实用性受到大家认可。随着深度神经网络的发展,深度迁移学习广泛用于解决跨域数据异构问题。其中,典型方法包括基础生成对抗网络(generative adversarial network,GAN)和跨域图像特征映射的循环一致性对抗网络(cycle-consistent generative adversarial networks,CycleGAN)。
Goodfellow等人(2014)提出GAN的定义。GAN由生成器(G)和判别器(D)两部分组成,如图2所示。G的输入是服从某一分布pz的随机向量z,输出可以看做满足采样pg分布的生成样本G(z)。假设真实样本服从pdata,在真实数据量理想的状态下,训练GAN模型,让G学习至与pdata分布相近的函数,目的是生成类似于真实数据x的样本欺骗D。而D的输入是x与G(z)的组合,目的是判断输入的数据是真实的还是伪造的。G和D对抗训练最终会达到纳什平衡状态,D无法区分样本的来源,说明G学习到了真实数据的分布。基于该思想,传统GAN的目标函数设计为

(1)
式中,x为真实数据,V(G,D)为传统GAN的目标函数,为期望。
传统GAN的主要目标是最小化pg与pdata之间的距离,然而KL(Kullback-Leibler)散度的度量方式会出现梯度消失和模式崩溃的问题(陈佛计 等,2021)。

图2 GAN的基本结构和计算流程Fig.2 Basic structure and computation procedure of GAN
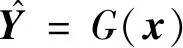
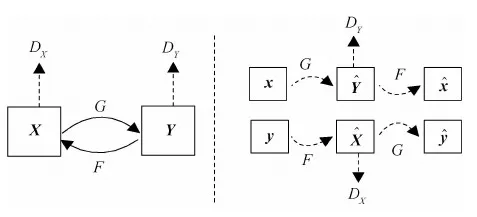
图3 CycleGAN模型原理Fig.3 Principle of CycleGAN model
2 方 法
针对糖网多分类问题,提出一种结合域适应学习并协同注意力机制构成的弱监督网络模型(WAD-Net),输入整幅彩色眼底图像,输出糖网的病变等级和高疑似病灶的位置信息。整幅眼底图像视为全局样本X,每个X都有一个分类标签y,疑似病灶视做局部样本x。源域训练样本选择仅包含HMA病灶位置信息的IDRiD(Indian diabetic retinopathy image dataset)数据集(Porwal等,2018),目标域训练样本选择仅包含图像水平病变等级信息的Messidor数据集(Decencière等,2014)。WAD-Net 算法流程如图4所示。整体流程为:1)对图像进行切片和数据增强的预处理操作;2)基于目标域多分类预测结果,指导跨域生成新样本完成域适应;3)利用源域已标记的样本与跨域中生成的新样本,先后分别通过预训练和微调过滤目标域X中不相关的x;4)建立多类多示例模型及注意力学习构建x与X之间局部—全局的映射关系,实现弱监督多分类诊断。
2.1 基于注意力机制的弱监督多分类网络
注意力机制(Mnih等,2014)最早在视觉图像领域提出,结合循环神经网络(recurrent neural network,RNN)结构模拟人类对整幅图像中关键特征集中观察的能力,根据每个特征对于特定的分级结果的重要程度分配不同的注意力权重,提取更具影响力的特征信息。Yang等人(2016)针对文本分类任务提出层次注意力机制(hierarchical attention network,HAN),融合了自注意力权重的计算,即

图4 结合适应学习的糖网分级诊断算法Fig.4 DR grading diagnosis algorithm based on domain adaptive learning

(2)
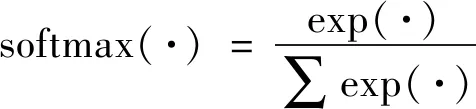
算法描述如下:

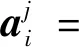
(3)

(4)
(5)

2.2 域适应
HMA信息可从其他不同分布的数据集收集。为了克服跨域异质性障碍,与病灶相关的局部样本通过GAN迁移学习的方式生成人工新样本对源域HMA分类器微调,实现渐进的域适应。在传统GAN中,跨域信息是对等的,如局部—局部的模式,但本文与传统跨域模式不同,是局部—全局模式,解决了跨域数据粒度,实现了端到端的GAN扩展。
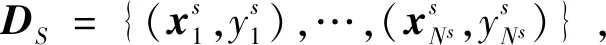
基于传统GAN的目标函数和网络结构存在很多变体(Lucic等,2018;Karras等,2020),本文侧重改进生成器网络。G:S→T方向的GS→T和与其相关Qt的目标函数分别定义为

(6)
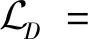
(7)
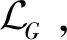
理论上,对抗性训练可以学习跨域的映射关系。但数据量很大时,会诱导G学习出多种与DT分布匹配的数据,不能保证学习到的映射函数可以将xs映射到有用的xt。为了进一步减少可能的映射空间,引入了CycleGAN模型的循环一致性损失,具体为
(8)

(9)
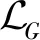
(10)

2.3 跨域HMA分类
在视网膜图像分类前,为了获取更好的分类结果,X中不相关的x应该被过滤掉。但由于Messidor数据集只包含病变等级注释信息而没有HMA的位置信息,因此借用IDRiD数据集构建了基于VGG-16(Visual Geometry Group)(Simonyan和Zisserman,2015)网络结构的源域HMA分类模型。特征学习过程是针对尺寸为128×128像素Patch级别的图像,由于尺寸较小故选择浅层网络即可实现有用信息的学习,还可以提升训练效率。训练目的是最小化与CNN参数相关的代价函数,即
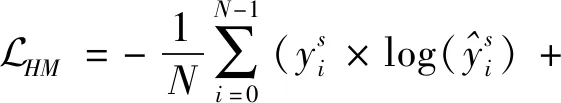
(11)
2.4 训练细节
(12)
式中,λc、λg和λh表示可调的超参数。大量实验表明,λc∶λg∶λh=1∶1∶1性能最好。在训练过程中,每一批次不一定更新所有的模型参数(Larsen等,2016),WAD-Net的更新规则为
(13)
式中,θ为判别器的训练参数。
2.5 网络结构
判别器D采用马尔可夫判别器(PatchGAN)(Li和Wand,2016)的体系结构,如图5所示。D分别由5个卷积层、4个激活层和3个批归一化层交替网络构成,卷积层的步幅均设置为2,以增大输出特征的感受野,批归一化层的使用可以提高D的泛化能力。此外,D在Patch级别建模而不是全局图像,有效捕获高层特征信息,提高收敛速度和重建图像质量。

图5 判别器的网络结构Fig.5 The network structure of discriminator
弱监督多分类网络的特征学习与G的encoder结构相同,如图6所示。之后,通过展平层(Flatten)对多维特征一维化。接下来,全连接层FC1获取嵌入式特征并通过嵌套(Lambda)重组为FC2,注意力机制层(Attention)位于特征提取和随机失活(Dropout)之后,计算每一个局部样本的权重信息,将其与FC2的特征向量通过(Multiply)相乘,完成局部—全局的特征映射。最后,附加两个全连接层FC3与FC4和softmax激活函数输出0~1之间判定类别的预测分数。

图6 弱监督多分类网络Fig.6 Weakly-supervised multi-class network
生成器G采用encoder-decoder的网络结构,如图7所示。encoder对输入图像下采样,捕获图像整体的上下文信息,由VGG-16特征提取的13个卷积层Conv2D和5个下采样层即最大池化层(Maxpooling2D)组成。decoder执行上采样,具有与encoder下采样相同数量的上采样层(UpSampling2D),将输出的图像分辨率与输入图像的分辨率维度相匹配,实现精确定位。下采样与上采样层之间通过(Concate-nate)设置跳跃连接(Isola等,2017),使输入与输出之间共享轮廓、颜色等低层特征,并对特征进行实例归一化(InstanceNormalization)加快训练模型的收敛速度。
3 实验结果与分析
3.1 实验设置
实验在8块NVIDIA GTX 1080TI显卡和128 GB内存的Centos7.7服务器上进行,使用 Python3.6.9版本的深度学习框架Keras搭建整体网络模型。
实验在ISBI 2018 IDRiD子挑战1(https://idrid.grand-challenge.org/)和Messidor(http://www.adcis.net/en/third-party/messidor/)两个公开数据集上进行,采取10倍交叉验证的方式评估WAD-Net算法在眼底图像上的分类效果。
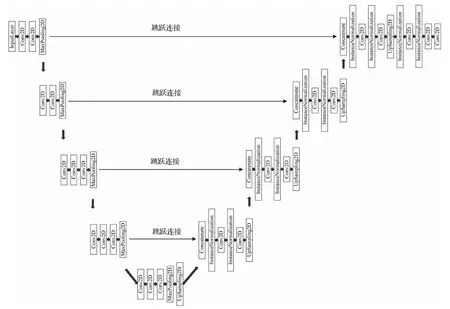
图7 生成器的网络结构Fig.7 The network structure of generator
IDRiD数据集由50°视野的KowaVX-10α数字眼底照相机拍摄捕获,包含516幅JPG格式的彩色眼底图像,尺寸均为4 288×2 848像素,其中81幅带有像素级病变标记信息,表1显示了每种病变类型的图像数量。IDRiD数据集采用原始图像与标记图像像素位置对应的方式注释信息。根据Messidor数据集的分级评估标准,H和MA两个主要的病变数据可作为迁移对象。
Messidor数据集由45°视野的Topcon TRC NW6非散瞳视网膜相机在3个眼科部门拍摄捕获,包含1 200幅TIF格式的彩色眼底图像,有1 440×960像素、2 240×1 488像素、2 304×1 536像素3个规格,为每幅图像提供0~3之间病变等级的标记信息。表1和表2显示了不同阶段的病变特征和数量。

表1 IDRiD数据集中的糖网病变类型Table 1 Type of DR lesions in IDRiD database

表2 Messidor数据集的糖网分级标准Table 2 Criteria of DR grading in Messidor database
为了评估算法性能,采用准确率(accuracy,AC)、精确率(precision,PR)、召回率(recall,RE)、加权调和平均数(micro-F1)、ROC(receiver operating characteristic)曲线下面积(area under curve,AUC)和ROC曲线6种评价指标进行验证。
3.2 有效性验证
为了验证WAD-Net算法在糖网多分类任务中的有效性,对其涉及的基于注意力机制的弱监督分类、域适应和疑似HMA过滤进行有效性评估,并研究各部分对糖网分级决策的贡献程度。为确保公平比较,所有对比方法均采用10倍交叉验证的方式评估其泛化性能。进行有效性验证的模型包括:
1)ResNet50。利用ResNet50网络结构构建的图像水平分类模型;
2)WAD-Net-1。深度WAD-Net-1模型将所有局部样本视为疑似HMA,不过滤不相关的局部样本;
3)WAD-Net-2。结合源域HMA分类器不参与跨域微调过程的深度WAD-Net-1模型;
4)WAD-Net-3。利用源域HMA分类器辨别目标域中局部样本的类别,给予每个样本一个伪标签。之后根据伪标签信息微调WAD-Net-2模型;
5)WAD-Net-4。在WAD-Net-2模型中源域HMA分类器通过GAN对生成的局部样本进行微调。利用微调后的模型对全局样本过滤并输入WAD-Net-1模型中,但不含有注意力机制。
实验结果如表3所示。可以看出,WAD-Net算法的准确率、召回率、micro-F1和AUC指标都表现出最优的分类结果,HMA病灶的弱监督多分类网络的泛化能力远优于图像水平的监督学习方法,也证明了利用弱监督多分类网络对糖网诊断的有效性。
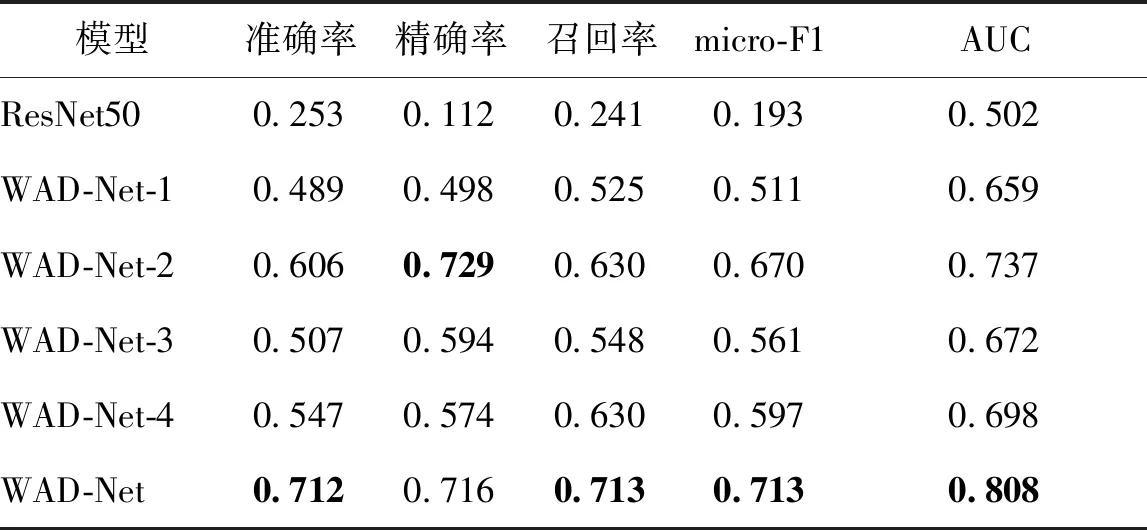
表3 WAD-Net算法组件的比较Table 3 Comparison of components of WAD-Net algorithm
图8显示了对比方法的ROC曲线。可以看出,WAD-Net的AUC值明显高于其他方法,说明此算法对不同类别病变严重程度的区分能力很强,可以发现HMA病理特征的细微变化。
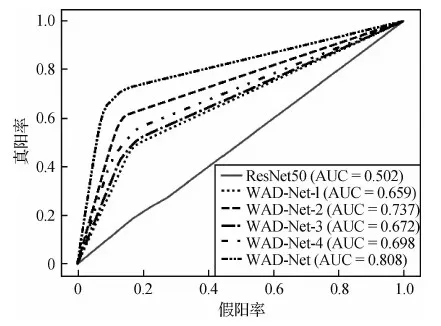
图8 对比方法的ROC曲线Fig.8 ROC curves of the comparative methods
总结实验结果可得:1)由于训练集数量有限,而且病灶因与视网膜图像上其他正常组织(血管片段等)在颜色和纹理特征方面相似,导致其全局变化不明显,致使传统的监督学习方法不能充分训练图像水平的分类模型;2)没有任何过滤的弱监督多分类网络取得较差的分类结果,表明全局样本中存在大量无关的局部样本对方法的分类性能产生了负面影响;3)WAD-Net-2模型的分类效果低于WAD-Net方法,说明跨域数据集之间不符合独立且同分布的假设,因此数据异质性会使整体分类性能下降。另外,由于跨域数据分布不一致,WAD-Net-3可能产生错误的HMA分类标签;4)对比WAD-Net-4与WAD-Net的分类结果,可以看出结合注意力机制不仅能够提供病理医学上的可解释性,而且提高了全局的分类性能。
从图8的ROC曲线下面积AUC值的实验结果可知,WAD-Net算法每个组件的使用都有助于糖网分级诊断性能的优化,但贡献程度不同。WAD-Net-2网络与WAD-Net-1网络相比,AUC值提高了11.8%,是疑似HMA过滤组件的作用。WAD-Net网络与WAD-Net-3网络相比,AUC值提高了20.2%,是域适应组件的作用。WAD-Net网络与WAD-Net-4网络相比,AUC值提高了15.8%,是基于注意力机制的弱监督分类组件的作用。显然,域适应组件对糖网诊断分级决策的贡献最高,充分说明跨域GAN迁移方法从传统的“局部—局部”模式扩展到“局部—全局”模式解决了跨域粒度受限的数据异质性问题。
由于采取“局部—全局”模式的糖网分类决策需要考虑病灶区域与背景区域的比例关系,目标域数据集中多个样本以随机采样的方式选取,评估病灶区域和背景区域在不同糖网严重程度1~3的比例分别为1/16、1/9和1/6,如表4所示,存在特征类别不平衡问题。去除黑色背景操作指在整幅图像中去除非视网膜区域的黑色切片,计算保留的有内容的切片数量在整幅图像的占比;HMA过滤操作指整幅图像经过HMA分类提取出疑似HMA的切片,计算疑似HMA与有内容切片数量的占比;注意力机制操作指疑似HMA切片经过注意力机制得到高疑似HMA,计算高疑似HMA与疑似HMA切片数量的占比;无操作是指对整幅图像没有任何行为,计算真实病灶切片数量与整幅图像占比。全局样本通过去除黑色背景区域和跨域HMA分类器以及注意力机制过滤掉大量不相关的局部样本,将比例收缩为1/2、2/3和4/5,比例关系达到平衡状态,最终为背景区域分配的权重逐渐降低。

表4 病灶区域与背景区域比例的变化Table 4 Variations of the ratio between lesion region with the background region
结合表3的模型性能,WAD-Net-1表示去除黑色背景区域得到有内容切片的模型,WAD-Net-2表示跨域HMA分类器过滤得到疑似HMA样本的模型,WAD-Net表示注意力机制提取高疑似HMA样本的模型。随着背景权重的降低,糖网的分类准确率逐渐升高,意味着模型一步步地解决了病灶区域与背景区域特征类别比例不平衡的问题,使糖网的分类结果对其并不敏感,也说明WAD-Net可以有效辨别图像中有用的病灶信息。
3.3 消融实验
3.3.1 图像切片尺寸的影响
上述实验均采用固定的切片尺寸128×128像素获取局部样本来分析全局糖网的诊断效果。为验证图像切片尺寸对WAD-Net算法性能的影响,在Messidor数据集上测试WAD-Net-128和WAD-Net-256的指标性能,实验结果如在图9所示。可以看出,切片尺寸为128×128像素的WAD-Net获得了更好的结果。这意味着较大的切片无法准确捕捉到有意义的疑似HMA区域和发现病理特征的细微变化。此外,较大的切片会带来巨大的计算成本,影响方法在实际应用中的使用价值。
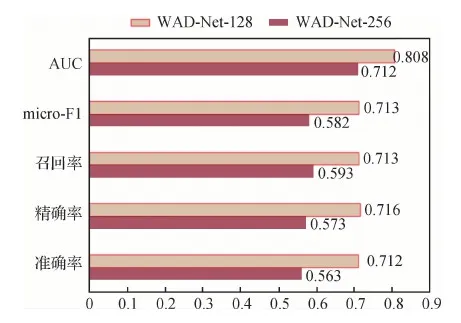
图9 切片尺寸对WAD-Net性能的影响Fig.9 Influence of the patch size on WAD-Net performance
3.3.2 注意力机制层的影响
WAD-Net 算法结合多类多示例学习的思想设计了弱监督多分类网络,将局部样本概率分布向量或局部样本的特征向量聚合成全局表示。为了证明注意力机制的优势,将其与其他的池化操作进行比较,分别为全局最大池化(global max pooling,GMP)、全局平均池化(global average pooling,GAP)和全局LSE池化(global log-sum-exp pooling,GLP)(Wang等,2018),实验结果如表5所示。可以看出,注意力机制的性能指标都要好于其他池化方法,主要是更深层级地定位了高疑似HMA的病变区域,提高了分类性能。

表5 池化操作对WAD-Net算法的影响Table 5 Influence of the pooling operations on WAD-Net algorithm
3.3.3 GAN架构变化的影响
为了更好地跨域迁移HMA的分类能力,本文 利用GAN生成目标域新样本微调模型。对此,将从损失函数的角度研究GAN架构变化生成的高质量新样本对糖网分类性能的影响。设计了几种方法:


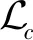
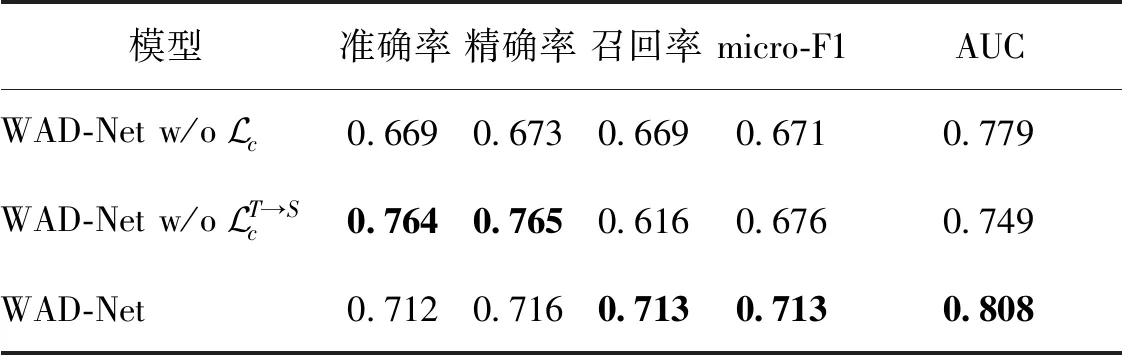
表6 GAN损失函数的变化对WAD-Net算法的影响Table 6 Influence of the change of GAN loss function on WAD-Net algorithm
3.4 与其他糖网诊断方法的比较
为进一步验证本文方法的性能,与几种最新糖网诊断方法进行比较,实验结果如表7所示。Alzami等人(2019)提出将分形维数与随机森林(random forest,RF)分类器相结合的方法实现糖网诊断。Seoud等人(2015)生成HMA病变概率图与位置、大小协同表示特征,并建立RF方法,两名眼科专家A和B分别对Messidor数据集手动划分病变的严重程度。Labhade等人(2016)采用统计矩和GLCM(gray level concurrence matrix)等纹理分析方法提取特征,然后基于支持向量机(support vector machines,SVM)、RF、自适应提升(adaptive boosting,AdaBoost)、梯度提升(gradient boost,GB)和高斯朴素贝叶斯(Gaussian naive Bayes,GNB)方法对这些特征进行分类。Li等人(2020)利用糖网和糖尿病黄斑水肿(diabetic macular edema,DME)疾病之间的相关性训练跨病注意网络。Luo等人(2020)通过自我知识蒸馏法定制模型进行糖网自动分级。这些现有关于糖网分类的深度学习方法不满足于多分类任务设置,为了公平性,对后两种最新的深度学习方法在同一运行环境下使用其各自发布的源代码测试多分类性能。以上研究均通过Messidor数据集验证各自方法的性能。

表7 WAD-Net与其他糖网诊断算法的性能比较Table 7 The comparison between WAD-Net algorithm and other DR diagnosis algorithms
从表7可以看出,本文算法在糖网分级诊断任务中显示了较大优势。Seoud等人(2015)使用留一法测试算法性能,训练集数量远大于本文采用的10倍交叉验证方式,测试集单一且计算时间长。相比于传统的其他算法,本文算法获得了较好的分类效果。与深度学习方法对比,可以发现WAD-Net跨域模型好于跨疾病的方法,有助于加强感兴趣的病灶特征,能够对病灶形态变化的学习有更好的认知。在准确率方面,本文模型比B专家的人工诊断性能提高了4.6%,表明模型的分类能力可以协助医生完成更精确的糖网诊断。
3.5 可解释性验证
基于深度学习的模型通常缺乏可解释性,这会阻碍医生在常规临床工作流程中接受模型的分类结果。因此,WAD-Net利用跨域HMA分类器和注意力机制解决深度学习的黑盒问题,输出糖网的严重程度和高疑似病灶的位置信息以支持其分类决策。图10展示了WAD-Net算法的工作流程,通过将切片的像素值与其相对应的注意力权重相乘创建热力图,接着重新计算切片的注意力权重,具体公式为
(14)
高疑似HMA的病变区域可以通过热力图识别出来。
4 结 论
提出一种端对端结合域适应学习的糖网自动分类方法,该方法协同注意力机制构成弱监督网络(WAD-Net),利用多示例学习中局部—全局的映射关系,并融入GAN的迁移学习思想和门控自注意力机制提高分类的泛化能力,有效实现对眼底图像的糖网分级诊断。传统的糖网自动分类算法大多基于HMA的精确定位,但由于病灶标签的缺失,很难采用传统的监督学习检测HMA的位置信息。为此,WAD-Net汲取弱监督学习思想,只需要图像水平的标记数据就能获取糖网的分类等级和高疑似病灶的病变区域。另外,在含有像素级病灶标注信息的IDRiD辅助数据集的帮助下,开发了一种跨域HMA分类器,通过域适实现目标域中不相关的局部样本的过滤,同时基于GAN迁移方法解决了跨域存在的数据异构问题。最后,借助注意力机制获取每个局部样本的权重分数,提供糖网分级诊断结果在医学图像上的依据,这对于计算机辅助医疗自动诊断在实际临床中使用具有重要意义。在公开数据集Messidor上的实验结果表明,与最新的几种方法相比,WAD-Net取得了较好的性能,存在很大优势,可以大幅地减少注释工作。
在未来工作中,将在糖网公开数据集EyePACs(www.eyepacs.org)和其他医学领域如癌症组织病理学图像中评估WAD-Net模型的性能。同时,扩展到其他含有弱监督且具有异质性数据的医学领域进行验证。

图10 糖网分类流程效果图Fig.10 Effect map of DR grading process((a)slighted DR;(b)moderated DR;(c)severed DR)
