基于时频注意力机制与U-Net的骨导语音鲁棒增强方法
2022-11-16张玥张雄伟孙蒙
张玥 张雄伟 孙蒙
(中国人民解放军陆军工程大学指挥控制工程学院,江苏南京 210007)
1 引言
环境噪声常常对人们的语音交流带来不便,语音增强是减少噪声对语音通信干扰的重要技术手段。目前,语音增强技术已取得很大发展,传统增强方法[1-3]、基于深度学习的增强方法[4-7]层出不穷,在处理平稳噪声时能够取得较好的增强效果。然而,当语音信噪比低、噪声环境复杂时,现有语音增强方法效果将大幅下降。骨导语音是骨导麦克风直接通过与说话者声带、头骨等的接触拾取振动而产生的语音信号,因此能从声源处屏蔽环境噪声,得到较为纯净的语音信号,在复杂噪声环境下具有重要的应用价值。然而,由于人体发声的机理以及目前传感器等设备制作水平的限制,骨导语音高频信息丢失、部分清音音节缺失、听感沉闷、不够清晰,因而语音可懂度较低,难以直接应用于正常通信[8]。研究骨导语音增强算法,对提高低信噪比环境下的语音通信质量,促进骨导语音应用的推广具有重要意义。
目前,骨导语音增强方法有传统方法与基于深度学习的方法。传统的骨导语音增强方法有谱减法、维纳滤波法等频域法以及基于高斯混合模型、基于最小均方误差法等统计方法。传统骨导语音盲增强方法从多方面较好的分析了骨导语音的频谱特征,找到骨、气导语音的相关性,为后续工作打下了良好基础。近年来,深度学习迅速发展并在各领域均得到广泛应用。基于深度学习的方法较于传统方法能够更好的学习骨导语音与气导语音的语谱特征,能够获得更好的增强效果[9-12]。Liu[9]等提出了一种深度去噪自编码器方法,利用深度神经网络(Deep Neural Networks,DNN)增强骨导语音高维频谱特征,以提高语音质量和可懂度。郑[11]等提出了一种基于长短时记忆网络-循环神经网络(Long Short-Term Memory-Recurrent Neural Network,LSTM-RNN)的骨导语音盲增强方法,利用LSTMRNN 结构对骨、气导语音高维对数谱之间的转换关系进行建模,有效地捕捉了上下文信息重构骨导语音高维幅度谱。基于深度学习的骨导语音增强方法通过分析骨导语音低频频谱成分推测出高频信息,重构出全频带的语音,生成语音在质量及可懂度方面均有较大提升。然而目前应用于骨导语音增强方法的深度神经网络在骨导语音样本有限的情况下难以充分学习骨导语音特性,对于未知说话人的语音集鲁棒性不强。
2015 年,Olaf[13]等首次提出了U-Net 结构并将其应用于生物医学图像分割中。U-Net 为对称的“编-解码结构”,利用卷积层与池化提取特征与上下文信息,同时利用跳跃连接对同一层编码、解码层的语音谱信息进行拼接,实现多尺度的特征融合。Olaf等的实验表明,U-Net结构对于生物医学图像类小样本数据集能够从极少的训练图像中充分学习数据特征,相比于滑动窗口卷积网络取得了更高的性能指标。近年来,U-Net 被大量应用于语音增强领域中,体现出了较好的降噪能力以及泛化能力[14-17]。目前骨导语音数据集未有公开数据集,使用数据集为实验室声暗室录制,可用训练样本较少,因而相对于气导语音增强的数据集,骨导语音是小样本数据集。因此,我们采用U-Net 结构作为增强模型的主干网络。然而,骨导语音在高频部分缺失严重,与气导语音在高维频谱差异较大,需要从低频部分提取语音信息重构高频部分。为使UNet 结构在训练过程中能够更加关注骨导语音的低频信息以及时域上的能量分布,在U-Net 结构的基础上引入了时频注意力机制。
注意力机制可以使神经网络专注于某些重要输入信息或特征。在语音增强中,注意力机制可以为输入的语义信息分配不同的权重,因此可以引导模型关注学习重要语义成分,而较少关注噪音或干扰信息,从而提高生成增强语音的纯净度[18-22]。Zhang[18]等将频率注意力机制引入到时间卷积网络(Temporal Convolutional Network,TCN)中,引导TCN有选择地强调具有重要语音信息的频率特征,提高了网络的表示能力,增强语音的语音质量与可懂度指标均得到了提升。Bahareh[19]等在U-Net 中引入了通道注意力机制,在U-Net 结构的每一层均加入注意力,引导网络在每一层上均决定最关注哪些特征,该方法在CHiME-3 数据集上展示了当时最优性能。Hao[20]等在LSTM 结构基础上采用了注意力机制,当模型在预测增强语音时,注意力机制计算输入和当前语音帧之间的相关性,并为输入提供权重。实验表明,与LSTM 基线相比,该模型在语音质量和可懂度方面均能取得更好的性能,并对不可见的噪声条件具有更好的泛化能力。以上工作表明,注意力机制可以引导神经网络模型充分学习语音重要特征信息,提升增强语音的质量以及模型的泛化能力。对于骨导语音,低频信息与时域成分较为丰富,因此可以利用时频注意力机制引导模型学习骨导语音的有效时频成分。
为了充分关注骨导语音的时频信息,在训练数据较少的情况下充分利用现有特征,我们将时频注意力机制引入U-Net 结构中,引导模型充分学习骨导语音谱的低频信息,重构高频成分。论文的剩余部分结构组织如下:第2 节介绍骨导语音增强方法的模型结构,第3 节进行仿真实验和结果分析,第4节对全文工作进行总结。
2 骨导语音鲁棒增强方法模型结构
2.1 骨导语音产生的数学模型
假定语音激励信号为e(t),如图1 所示,骨导语音x(t)与气导语音y(t)声源为同一激励信号。骨导语音为激励信号通过人体头骨、颌骨、喉骨等路径传输而形成的语音信号,设传播路径函数为hB(Ct)。气导语音为激励信号通过声道、口腔、鼻腔等传输而形成的语音信号,设其传播路径函数为hAC(t)。则骨、气导语音产生可用公式(1)、公式(2)表示:
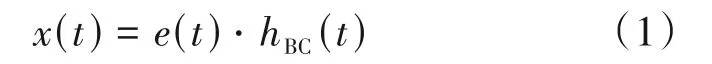

图1 骨导语音与气导语音传输路径图[8]Fig.1 Transmission channels for bone-conducted speech and air-conducted speech[8]
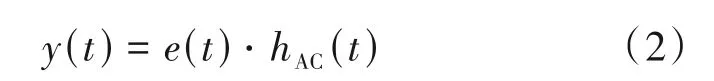
由于实际骨导语音采集的过程中其传播路径函数hBC(t)不仅与骨导传感器放置位置有关,还与说话人骨骼特性、发声音节等密切相关,因而hB(Ct)为一复杂非线性函数,目前仍无法进行数学建模。
2.2 增强方法总体架构
骨导语音增强方法的总体架构如图2所示。数据预处理阶段,将骨导语音与对应的气导语音分帧、加窗,进行短时傅里叶变换(Short-Term Fourier Transform,STFT)得到对应的骨导、气导语音幅度谱。而后对幅度谱进行取对数操作,得到对数幅度谱。计算出对数幅度谱频率方向每一维的均值和方差后进行归一化,得到归一化后的骨导语音谱与气导语音谱。

图2 增强方法总体架构Fig.2 Overall architecture of the enhancement method
训练阶段,将骨导语音谱作为输入,对应的气导语音谱作为目标对结合时频注意力机制与U-Net的增强模型进行训练,学习骨、气导语音的谱映射关系。训练损失函数选择均方误差(Mean Squared Error,MSE),在最小化增强语音与对应气导语音MSE的目标下优化模型参数。
增强阶段,将测试集中的骨导语音经过STFT、取对数、归一化后得到对数幅度谱。将归一化后的幅度谱经过训练好的增强模型得到增强语音的幅度谱。对生成的幅度谱进行反归一化及指数运算,最后经过逆短时傅里叶变换(ISTFT,Inverse STFT)生成增强语音。
2.3 时频注意力机制结构
语音在时域与频率方向的能量分布对于预测语音频谱同样重要。为引导模型有选择性地学习骨导语音中具有重要信息的时频特征,本文提出了一种时频注意力机制(Time-Frequency Domain Attention,TFDA),在时域与频率方向为输入语音分配相应的权重。
注意力机制结构如图3所示。首先将输入信息经过平均池化访问全局信息提取特征,而后通过全连接层将特征连接,最后通过激活函数Sigmoid 根据已获取的特征信息生成相应的权重,将所得与原输入相乘后输出得到预测语音谱。
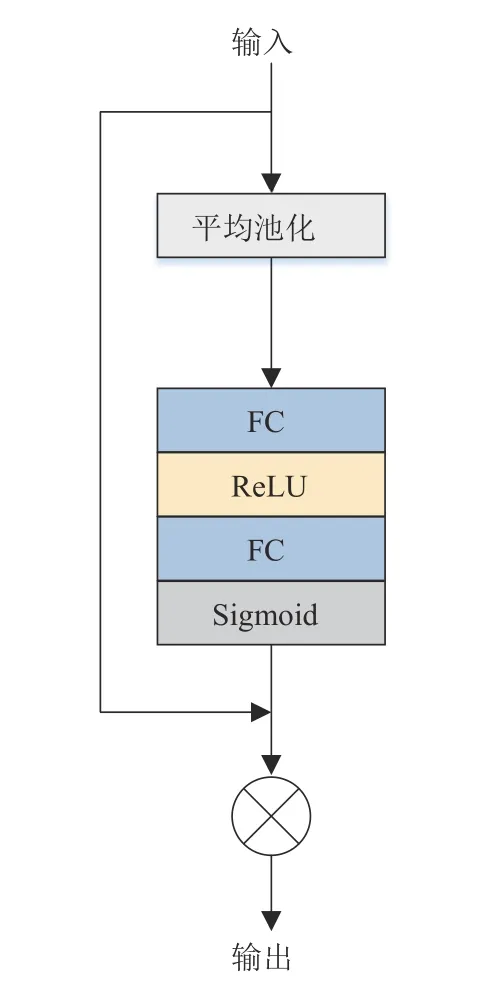
图3 注意力机制结构图Fig.3 Attention mechanism structure diagram
在此基础上,在时间与频率维度上均引入了注意力机制,并设置可学习的权重将分别经过时间、频率维度注意力机制的语谱以及原语谱连接,得到预测语谱输出。时频注意力机制结构图如图4 所示。假定输入语谱X∈R1×T×F,沿时间方向对X进行全局平均池化后生成特征模型Yt∈R1×F,其公式为:

图4 时频注意力机制结构图Fig.4 TFDA mechanism structure diagram
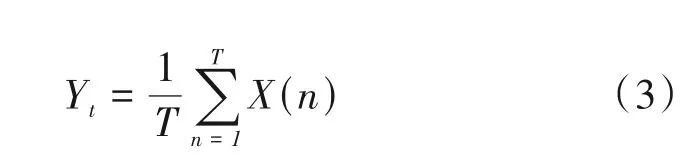
同理,沿频率方向对X进行全局平均池化后生成特征模型Yf∈R1×T,其公式为:
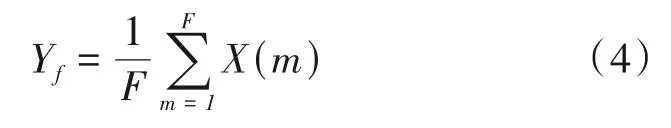
经特征模型Yt、Yf经过全连接层连接特征信息并经过激活函数生成语音谱沿时间、频率方向的权重Wt、Wf,公式为:
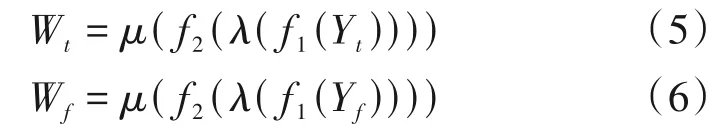
其中,f1、f2为两层全连接层,λ、μ分别为ReLU 和Sigmoid 激活函数。将获得的时间、频率方向的权重Wt、Wf权重与原输入相乘获得估计语音谱XT'、XF',公式为:

其中⊗为向量乘法。最后设置可学习的权重α、β、γ将时间、频率方向的估计语音谱XT'、XF'和原输入语谱X连接,其中α+β+γ=1,得到最终估计语谱X',其公式为:
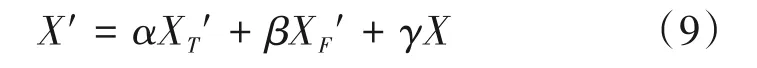
2.4 结合时频注意力机制与U-Net的网络架构
我们选择U-Net结构作为骨导语音增强方法的主干网络。U-Net 结构最早被提出应用于医学图像分割,能够从极少的训练图像中充分学习数据特征。U-Net 结构近年来也被广泛应用于语音增强中,并得到了较好的增强效果。目前骨导语音集训练数据较少,因此我们利用U-Net多尺度特征融合、高效提取特征的优势学习骨导语音频谱特征,建立骨、气导语音的频谱映射关系。
图5 为结合时频注意力机制与U-Net 的网络架构。输入骨导语音谱首先经过2.2节中时频注意力机制,生成权重与原输入相乘得到估计语谱后,经过包含5 层卷积层的U-Net 结构中。U-Net 结构为“编-解码结构”,编码阶段包含5 次卷积和4 次下采样操作。输入语谱首先经过3×3的卷积操作提取特征,通过线性校正单元ReLU 后进行下采样,下采样操作通过2×2的最大池化完成数据降维。每次卷积操作后,特征图通道数增加一倍(第一层有所不同),每次下采样操作后,特征图长宽减半,最终得到了通道数为256,大小为T/16×8 的特征图。而后对特征图进行解码,解码阶段首先进行上采样,上采样操作通过2×2的核进行特征映射。经过上采样的特征图通道数减半,长宽加倍。为了避免出现梯度消失和梯度爆炸问题,每层上采样后将编码阶段对应的特征通过跳跃连接与上采样后的特征图串联拼接。拼接后的特征图通过3×3的反卷积进行解码,解码后的特征图通道数减半,最后一层得到通道数为16,大小为T×129 的特征图后经过1×1 的反卷积得到全频带的估计语谱图。
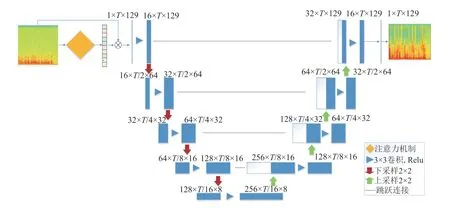
图5 结合时频注意力机制与U-Net的网络结构图Fig.5 U-Net combined with TFDA mechanism structure diagram
3 仿真实验与结果分析
3.1 实验设置
3.1.1 数据集
目前,国际没有公开的骨导语音数据集,实验数据集利用实验室喉振式骨导麦克风与高保真麦克风录制。数据集中共包含20 名男生、40 名女生,每人共200 条语音,语音长度平均在3~4 s,原采样频率为32 kHz。实验中将数据集做降采样,生成采样频率为16 kHz的语音。
单说话人骨导语音增强中训练、验证与测试集为同一说话人的全部语音。选取其中两名男生、两名女生的语音集进行对比实验,每人均为200 条语句。随机选择其中140 条语句作为训练集,20 条语句为验证集,40条语句为测试集进行实验。
未知说话人骨导语音增强中训练、验证、测试集中均包含多个不同说话人的全部语音,且说话人未有重合。未知说话人骨导语音增强利用全部20 名男生与40 名女生语音集进行对比实验,每人均为200 条语句。随机选取其中14 名男生、28 名女生的全部语句作为训练集,2 名男生、4 名女生的全部语句作为验证集,剩余4 名男生、8 名女生的全部语句为测试集进行实验。
3.1.2 网络参数设置
(1)U-Net
基于U-Net 的骨导语音增强包含5 层卷积层,其中通道数为[1,16,32,64,128],输出通道数为[16,32,64,128,256],卷积核大小为3×3,步长为3,填充数为1;4 层池化层,池化层大小为2×2;5 层反卷积层,前4 层通道数为[256,128,64,32],输出通道数为[128,64,32,16],卷积核大小为3×3,步长为3,填充数为1,最后一层输入通道数为16,输出为1,卷积核大小为3×3,步长、填充数为1。
(2)时频注意力机制
本文所采用注意力机制首先经过池化层提取特征,而后经过两层全连接层将特征连接,全连接层输入通道数为129,输出通道数为129,激活函数分别采用ReLU 与Sigmoid。设置参数α为可学习的三维向量,将α各维权重经过Softmax归一化后与经时域、频域注意力机制的语谱以及原输入语谱相乘,求和得到估计语谱。
(3)对比实验设置
我们选取了语音增强领域中获得较好效果的三种注意力机制进行对比实验。文献[18]中FAA参数设置与本文频域注意力参数相同。文献[21]中Attention 经过三层全连接层,输入节点数分别为129、40、40,输出节点数分别为40、40、129;第一层全连接层后连接一层LSTM 用于连接前后文语音信息,节点数为40,而后经过Softmax 进行归一化;Attention 采用激活函数Tanh 与Sigmoid。文献[22]中AttNet 首先经过两层LSTM 层,节点数均为256,而后经过两层全连接,输入节点数为256、300,输出节点数分别为300、300,采用激活函数ReLU。
模型训练时,设置batch_size 为8,采用Adam 优化器,为了防止网络出现过拟合,初始学习率为0.00001,最高学习率为0.001,设置dropout 为0.2。由于注意力机制模型相较于U-Net 结构参数量小、结构简单,为了避免出现参数更新速度不匹配的问题,设置U-Net参数每训练3轮更新一次参数。
3.1.3 评价指标
实验采用感知语音质量评估(Perceptual Evaluation of Speech Quality,PESQ)与短时客观可懂度(Short-Time Objective Intelligibility,STOI)作为衡量生成语音质量的客观评价指标。
PESQ 是将参考语音与待测语音进行预处理,在时间上进行对准后进行滤波,分析两个信号时频上的差值得到的评估分数。PESQ 得分范围在-0.5~4.5之间,得分越高,语音质量越好。
STOI的计算首先需要移除语音信号的静音区,而后将语音经STFT 变换得到时频域特征,再对时频点进行三分之一倍频分析,最后进行归一化和裁剪计算待测试语音和干净语音之间短时谱向量的相关系数。STOI 的结果范围在0~1 之间,代表单词被正确理解的百分比,值越大,表示语音可懂度越高。
3.2 结果与对比分析
3.2.1 单说话人骨导语音增强效果
表1、表2 为结合不同注意力机制与U-Net 结构对于单说话人骨导语音增强得到的PESQ 与STOI效果。由表中数据计算可得,基于时频注意力机制与U-Net 的骨导语音增强方法较基于U-Net 的增强方法相比,对于4名单说话人的增强PESQ指标平均提升了5.8%,STOI 指标平均提升了2.7%,在与其他注意力机制的对比中也取得了较好的结果。实验结果表明,时频注意力机制对于单说话人的骨导语音集具有较好的增强效果,增强后的语音质量得到了较好的提升,语音更加清晰。
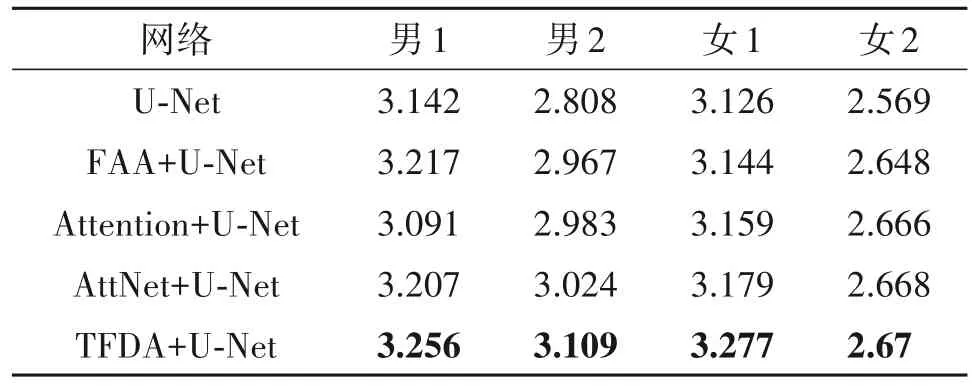
表1 不同网络结构对于4人骨导语音增强所得PESQ结果对比Tab.1 PESQ results of BC speech enhancement for four speakers with different networks

表2 不同网络结构对于4人骨导语音增强所得STOI结果对比Tab.2 STOI results of BC speech enhancement for four speakers with different networks
从表1、表2 可以看出,提出的时频注意力机制在四种注意力机制中对于不同说话人的预测语音PESQ 指标提升最大,STOI 平均提升最多,语音质量和可懂度都取得了较好的效果。对比4 名说话人结果发现,模型对于女2 取得的效果相对较低,提升较少。我们对比原骨导语音集后发现,女2 的骨导语音声音较轻,且在采集过程中掺杂了较多骨导麦克风与衣物摩擦而产生的噪声,因而增强后的语音中也掺杂了噪音的成分,语音质量相对较差。
图6 为男2 的骨、气导语音以及经过各网络结构增强后的语音语谱图对比。由图6(a)~(f)对比可以发现,经过时频注意力机制与U-Net 结构重构的语音高频部分频谱结构更加清晰,能量更强。
与文献[10]相比,对男1、男2、女1、女2的数据,PESQ 分别提高了13.1%、13.9%、14.3%与11.7%,平均提高了13.25%,证明了所提方法的有效性。
3.2.2 未知说话人骨导语音增强效果
结合不同注意力机制与U-Net结构对于未知说话人骨导语音增强所得PESQ 与STOI效果如表3 所示。由表中数据计算可得,基于时频注意力机制与U-Net 的骨导语音增强方法较基于U-Net 的增强方法相比,对于未知说话人的骨导语音增强PESQ 指标提升了4.4%,STOI 指标提升了1.3%,在与其他注意力机制的对比中也取得了最好的结果。
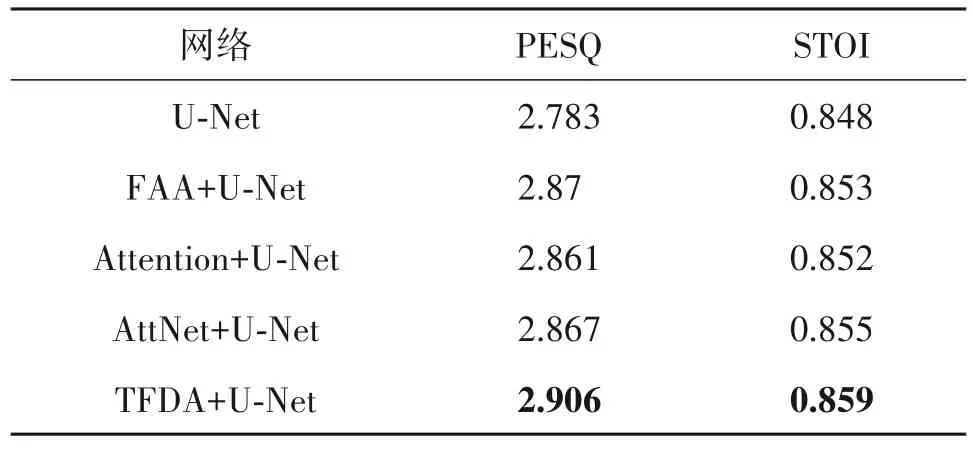
表3 不同网络结构对于未知说话人骨导语音增强所得PESQ、STOI结果对比Tab.3 PESQ and STOI results of BC speech enhancement for unknown speakers with different networks
测试集相对应的骨、气导语音以及经过各网络结构增强后的语音语谱图如图7所示。对比图7(a)~(f)可以发现,经TFDA+U-Net 获得的增强语音对于骨导语音缺失的清音音节也实现了较好的恢复。实验结果表明,时频注意力机制对于未知说话人的骨导语音数据集同样具有较好的增强效果,模型鲁棒性较强。

图7 未知说话人经不同网络结构增强预测语音语谱图Fig.7 Predicted spectrograms of unknown speakers enhanced by different networks
3.2.3 时频注意力机制可视化分析
为探寻时频注意力机制对U-Net结构学习骨导语音时频信息的引导作用,实验将进入注意力机制前后的语音谱以及注意力机制做了可视化分析,结果如图8、图9所示。图8为经时频注意力机制前后语音波形图对比,图8(a)为输入骨导语音波形图,图8(c)为经过所提时频注意力机制的骨导语音波形图,图8(b)暗色为原波形,亮色为经注意机制后的波形。从图8(b)可以看出,注意力机制引导模型在时域上对于语音有声段部分波形进行了增强,语音幅度值增加。
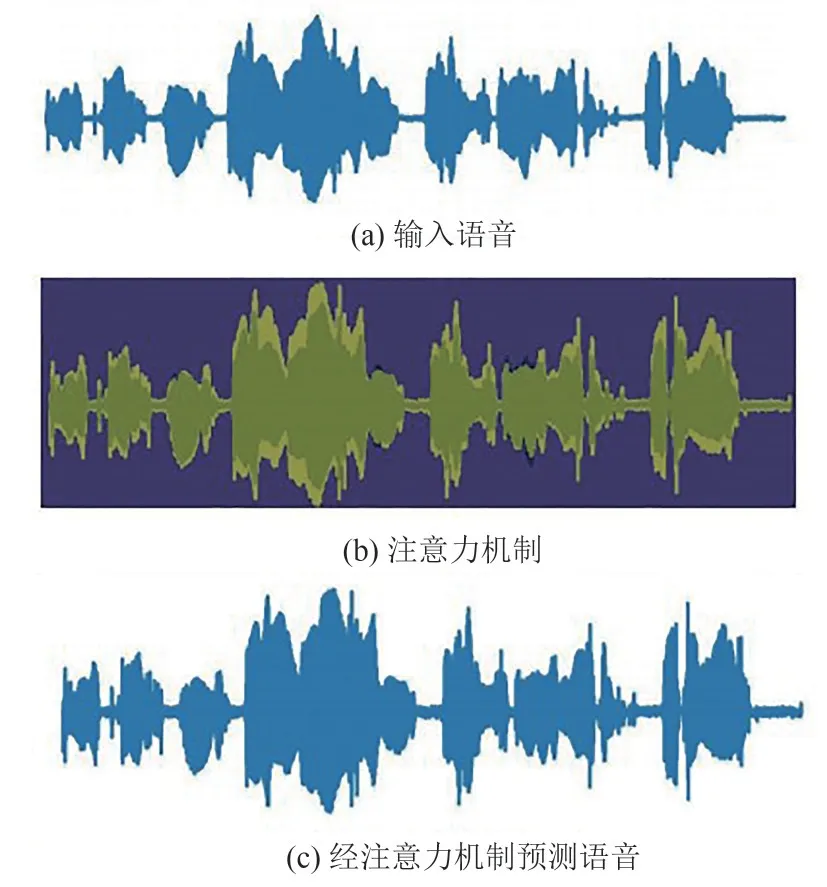
图8 经时频注意力机制前后语音波形图对比Fig.8 Comparison of speech waveforms before and after TFDA
如图9所示为经时频注意力机制前后语音语谱图对比,其中图9(a)为输入骨导语音语谱图,图9(c)为经过所提时频注意力机制后的骨导语音语谱图,图9(b)为注意力机制热力图,颜色越亮,注意力系数越大。经图9 对比可见,在骨导语音低频部分系数注意力系数较大,说明本文时频注意力机制引导模型在频域上较好地学习了骨导语音的低频语音信息与谐波结构。
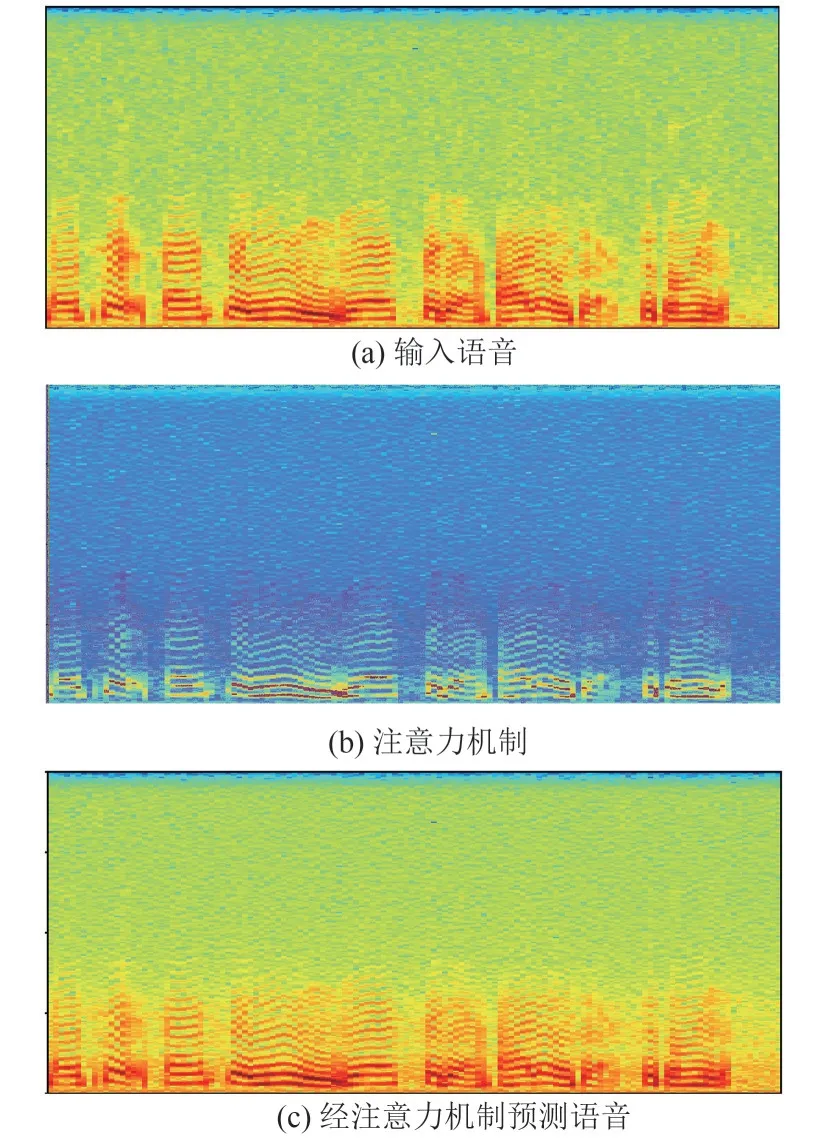
图9 经时频注意力机制前后语音语谱图对比Fig.9 Comparison of speech spectrograms before and after TFDA
4 结论
为充分利用骨导语音小样本数据集的时频特征,我们将时频注意力机制引入U-Net结构中,提出了结合时频注意力机制和U-Net结构的骨导语音鲁棒增强方法。该方法首先对骨导语音谱沿时间、频率方向按信息重要程度分配权重,对原输入标准化后以对应的气导语音谱为目标建立谱映射关系训练模型。仿真实验与注意力机制可视化分析结果表明与U-Net 基线以及结合其他注意力机制相比,所提出的结合时频注意力机制的方法对于单说话人与未知说话人的骨导语音增强均获得了最优效果,体现了模型的鲁棒性。
