编码器-解码器模型合成汉英语码转换文本
2022-11-16黄哲莹刘作桢徐及赵庆卫
黄哲莹 刘作桢 徐及 赵庆卫
(1.中国科学院大学,北京 100049;2.中国科学院声学研究所语音与智能信息处理实验室,北京 100190)
1 引言
“语码转换”(Code-Switching,CS)是指在一句话中出现语言切换的现象[1-3]。随着全球化的发展,越来越多的人掌握了两种或者两种以上的语言,CS在人们的日常交流中非常普遍,由此催生了人们对CS自然语言处理(Natural Language Processing,NLP)技术的需求[4]。语言模型建模是多个NLP任务的上游工作,虽然单语种语言模型已经能非常成功地被应用到多个自然语言处理任务中[5-7],但是CS语言建模仍旧是一项非常艰巨的挑战,CS文本数据的稀缺问题就是其主要挑战之一。CS文本数据的稀缺,会大大降低语言模型的性能。当前主流的研究思路有3种,(1)构建跨语言词向量,将不同语种的单词映射到一个共享的向量空间[5,8-9],这种方法不受CS 文本数量的限制,但是它却没有对跨语种的词序列依赖关系进行建模。(2)使用基于矩阵语言框架理论、等价约束理论、功能头约束理论等主要语言学理论来合成CS 文本数据[10-11],但是这类方法需要额外的对齐器、句法分析器来处理两个单语种句子,而现存的研究中利用到词对齐器和词性标注器性能都不容乐观,并且对于语法结构、句法结构差别巨大的两种语言而言,反而会加剧问题,比如汉语与英语在语法结构、句法结构上迥然不同,由此这个方法会导致后续双语CS 文本的生成自然度比较差。(3)将基于神经网络的单语种语言模型扩展为基于神经网络的CS语言模型,输入与输出采用共通的跨语种词向量[12],并将类合并到神经网络语言模型中,但是这种方法仍然受CS文本数据稀缺问题的限制。
为了解决CS文本数据稀缺的问题,本文采用合成CS 文本的思路,本文在第2 节提出了基于编码器-解码器模型合成CS 文本的方法,从有限的CS 文本与大量单语种平行语料中学习CS 语言学规则与语种内部的语言学规则,来合成CS 文本。在第2 节提出的方法中,在合成文本时,由于解码器缺少及时的语言学约束指导,生成文本自然度较低,为了解决这个问题,本文在第3 节提出基于带复制机制的编码器-解码器模型合成CS 文本的方法,在基于编码器-解码器模型的CS 文本生成器的基础上,增加了一个门控,用来决定从解码器的预测结果还是从编码器的输入源文本中产生下一个词。该方法在合成阶段为解码器提供及时的语言学约束指导,提升了合成文本的自然度。第4节对第2节、第3节提出的方法进行实验。
2 基于编码器-解码器模型的合成CS 文本的方法
本节使用了基于循环神经网络的编码器-解码器模型来构建生成双语CS 文本数据的生成器。这个生成器从有限的CS文本隐式地学习CS的语言学约束规则,从大量单语种平行语料中隐式地学习语种内部的语言学约束规则,然后利用单语种平行语料来生成双语CS的文本数据。
如图1 所示,基于编码器-解码器模型的CS 文本生成器,由一个编码器、一个解码器、一个注意力机制构成。本文使用一个双向的长短时记忆网络(Bidirectional Long-Short Time Memory,BLSTM)作为编码器,使用一个单向长短时记忆网络(Unidirectional Long-Short Time Memory,LSTM)作为解码器,使用一个基于内容与位置的方法作为注意力机制。
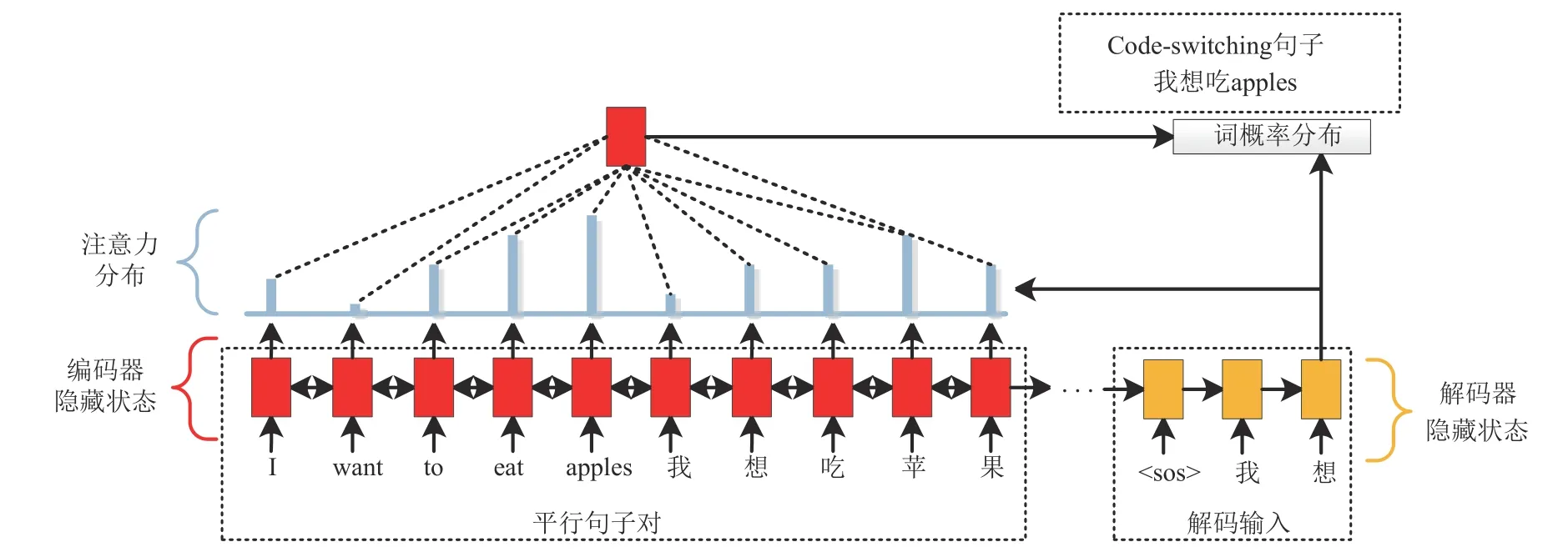
图1 基于编码器-解码器模型的CS文本生成器Fig.1 The Encoder-Decoder based code-switching text generator
编码器输入一个词序列X=[x1,…,xL],L是输入词序列的长度,词序列包括汉语-英语平行句子对、英语-汉语平行句子对、汉语句子、英语句子、汉英CS 句子5 种。编码器将词序列编码成编码向量序列H=[h1,…,hL],如公式(1)所示:
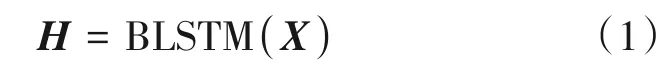
注意力机制在每一个输出时间步t,接收解码器的隐含状态st-1,计算注意力权重向量at=[at,1,…,at,L],并作用于编码向量序列,产生第t个输出时间步的上下文向量ct,如公式(2)所示:

模型学习到的注意力权重表示着语种内部语言学约束规则、跨语种语言学约束规则。
解码器接收上下文向量ct与前一个输出时间步t-1的输出词,并结合解码器的隐含状态st-1,得到解码器的当前隐含状态st,再经过输出层映射预测当前标签的词概率分布Pvoc(wt)=,V是输出的词汇表大小,如公式(3)所示:
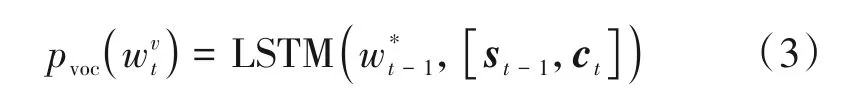
该生成器的训练目标函数是参考序列与预测序列的交叉熵,如公式(4)所示:

解码器输入的参考序列种类包括:汉语-英语平行句子对、英语-汉语平行句子对、汉语句子、英语句子、汉英CS句子5种。
值得注意的是,编码器输入的5 种序列与解码器输入的5种参考序列,在训练阶段,不需要呈现一一对应的关系,可以有9种组合呈现,如表1所示。
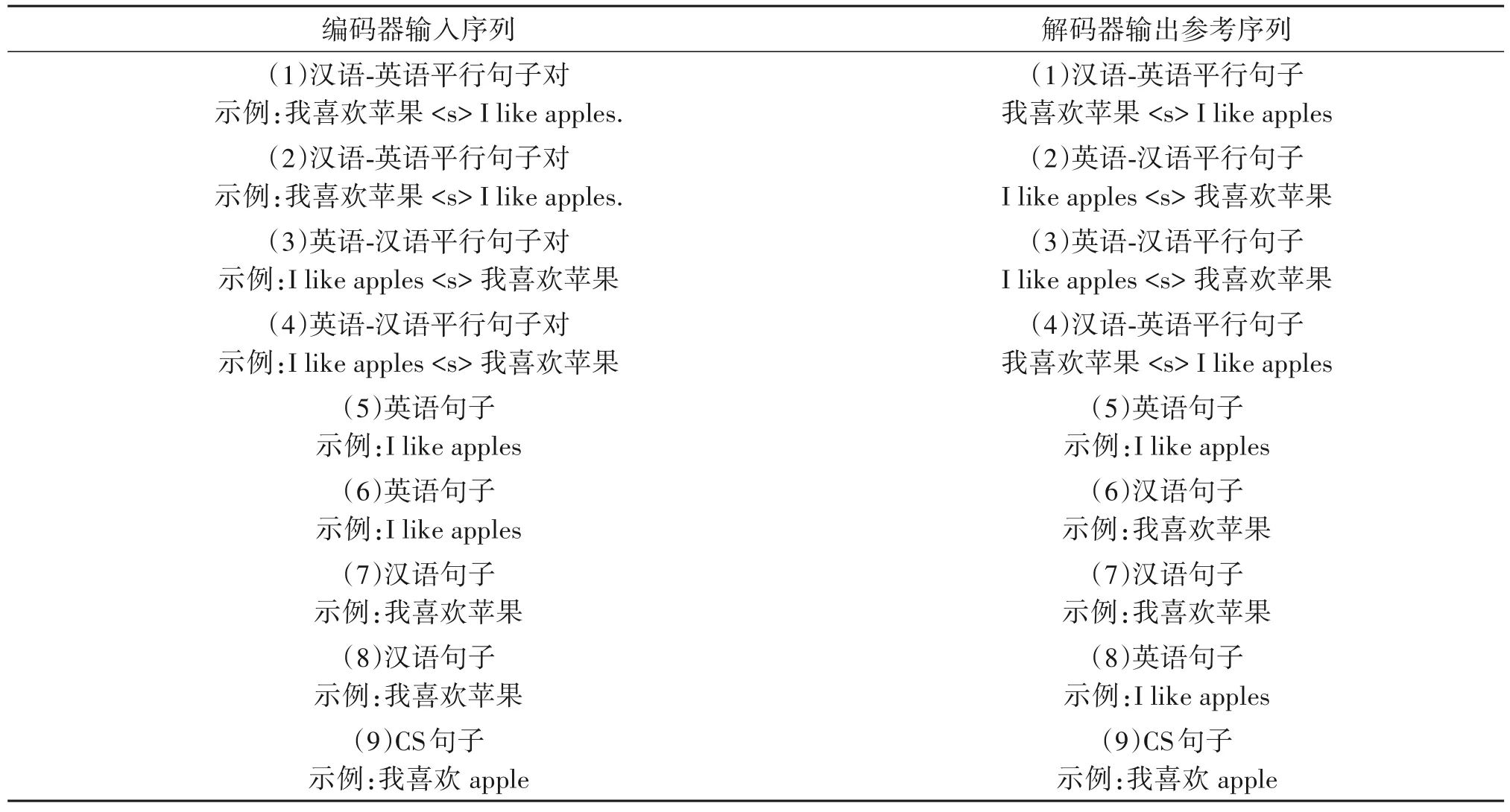
表1 输入序列与输出参考序列的组合Tab.1 Combinations of input sequence and output reference sequence
3 基于带复制机制的编码器-解码器的合成CS文本的方法
基于编码器-解码器模型的文本生成器,由于在解码过程中,解码器没有显示地接收及时的语言知识指导,导致合成的词序列受到较少的语种内部语言学约束与跨语种的语言学约束,即合成文本自然度低。为了解决此问题,在此基础上,本小节为编码器-解码器引入了复制机制,如图2 所示。在基于编码器-解码器模型的CS 文本生成器的基础上,增加一个门控,它决定了生成器产生的下一个词,到底是从解码器中预测出来的,还是从编码器的输入源文本中拷贝过来的。门控概率pgen∈[0,1]表示当前词选中解码器预测的词(来自预测的词汇表分布)的概率,而1 -pgen则表示当前词选择复制文本词的概率。
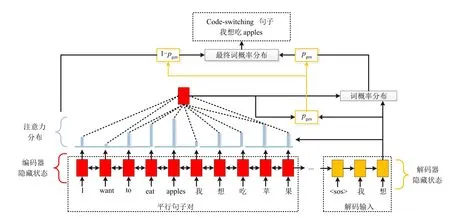
图2 基于带复制机制的编码器-解码器模型的CS文本生成器Fig.2 The Encoder-Decoder based code-switching text generator with copy mechanism
pgen是由编码器的上下文向量ct、解码器的隐含状态st、解码器当前的输入即上一输出w*t-1共同计算的
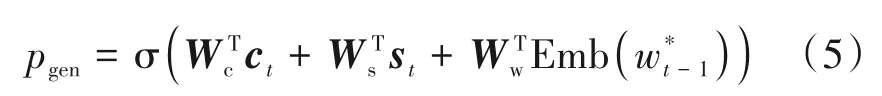
其中,Wc、Ws、Ww都是可训练的参数矩阵是词的嵌入向量。
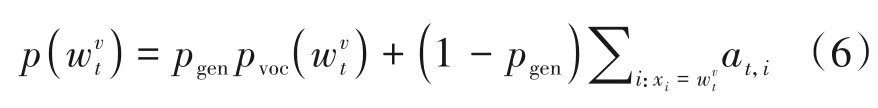
该生成器的训练目标函数是参考序列与预测序列的交叉熵,如公式(7)所示:
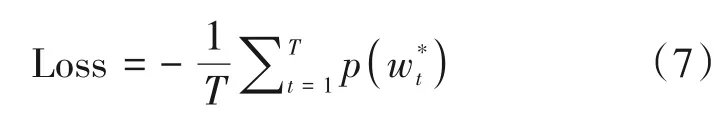
4 实验结果与分析
4.1 数据集
本文实验使用了两个数据集:(1)东南亚汉语-英语(South East Asia Mandarin-English,SEAME)数据集[13]的文本标注,包含了具有100802个句子的训练集和具有6276个句子的测试集,其中大部分是汉英CS 的句子;(2)OpenSubtitles 数据集的汉语-英语平行文本数据子集[14],这个子集的数据均是汉语与英语的平行句对,包含了11203286 个汉语-英语平行句子对。
4.2 实验设置
语言模型的性能间接地反映了合成文本数据的质量,进而可验证本章所研究方法的有效性。本文实验采用了两个指标来衡量语言模型的性能,在SEAME 测试集的困惑度与识别解码结果。以下实验采用的语言模型是基于3-元文法的CS语言模型,采用的识别框架是基于隐马尔可夫的识别框架。为了更清晰地展现CS合成文本数据的质量,本文又将SEAME 测试集由整体划分为三个部分,即纯中文句子的子集、纯英文句子的子集、CS句子的子集,因此实验结果记录表格除了记录在SEAME 测试集上的整体困惑度以外,还将记录各3-元语言模型在纯中文句子子集、纯英文句子子集、CS 句子子集上的困惑度。
实验(1):首先设置一个基线系统实验,只采用真实的CS 文本数据(SEAME 的训练集)来训练3-元统计语言模型。
实验(2):在基线系统的基础上,设置一个单语种数据与真实CS文本数据混合的实验,这是为了排除单语种数据对语言模型性能的影响。
4.3 基于编码器-解码器模型的方法合成CS 文本的质量测试实验
我们首先训练一个基于编码器-解码器模型的CS 文本生成器,采用的训练数据是由OpenSubtitles汉-英子集按照表1的9种组合方式扩展而成。然后利用该生成器合成CS文本,编码器输入“汉-英平行句子”、“英-汉平行句子”、“汉语句子”、“英语句子”,解码器输出汉英CS 文本序列。使用不同数量的合成文本进行以下实验。
实验(3):设置一个采用等同于真实数据量(约10 万条语句)的1 倍的CS 合成数据的实验,这是为了最直观地观察合成数据的质量。
实验(4):设置一个等同于真实数据量的2倍的CS合成数据的实验,这是为了直观地观察随着合成数据的增长,能否对使用该数据训练生成的语言模型的性能有提升效果。
实验(5):本小节设置一个等同于真实数据量的3 倍的CS 合成数据的实验,这个实验的设置目的与实验(4)的目的相同,因为我们在实验中发现,使用2 倍合成数据相比于只使用1 倍合成数据,并不能降低语言模型的困惑度,并且困惑度远高于只使用真实数据的基线系统,即实验(1),于是本小节继续加大合成数据量,到达3倍。
实验(6):设置一个采用3倍的合成文本数据与真实CS数据混合的实验。
实验结果如表2 所示,1 倍合成数据训练的语言模型在测试集上困惑度与2 倍合成数据、3 倍合成数据的结果是相近的,它们与基线实验(1)相比,在单语种句子上的困惑度、在CS 句子上的、整体困惑度都提高了相对100%以上。3 倍合成数据与真实训练数据的混合集所训练的语言模型,与基线相比,在各困惑度指标上也都有所提高。我们分析认为,基于编码器-解码器模型的CS 文本生成器,在生成文本的过程中,由于解码器输入缺少及时的语言学指导,导致解码器输出的词序列,受到较少的同语种内部的语言学约束与跨语种间的语言学约束,即它生成的词序列自然度不高。
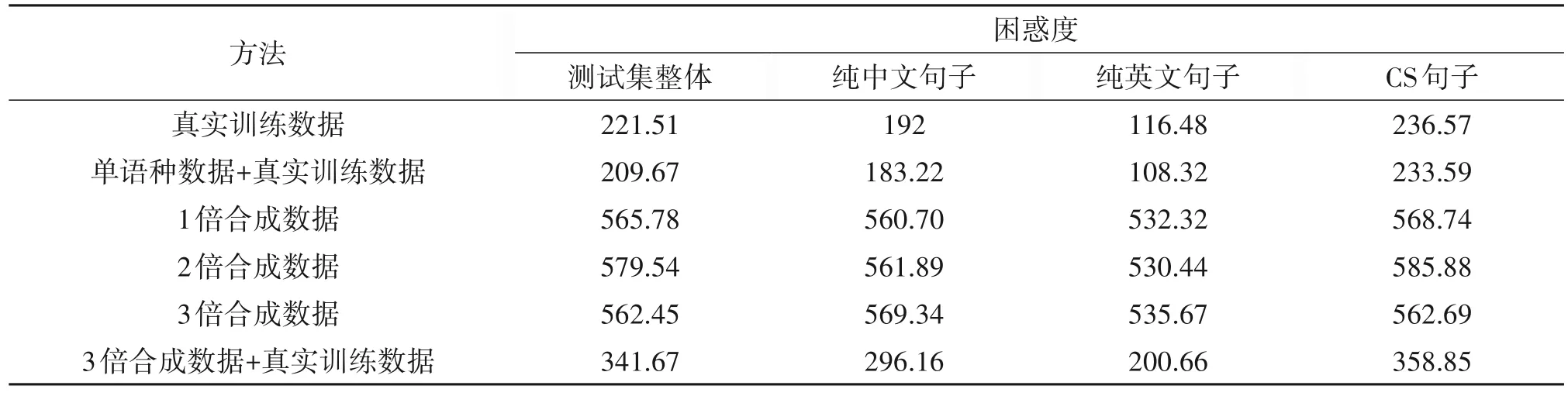
表2 基于编码器-解码器模型的CS文本生成器合成文本所训练的3-元文法语言模型在SEAME测试集上的困惑度Tab.2 The perplexity on the SEAME test set of 3-gram language model trained on Synthetic text generated from Encoder-Decoder based code-switching text generator
4.4 基于带复制机制的编码器-解码器模型的方法合成CS文本的质量测试实验
我们首先训练一个带复制机制的基于编码器-解码器模型的CS文本生成器,采用的训练数据与第4.3小节实验相同,在使用该生成器合成文本时,编码器的输入设置与解码器的输出设置也分别与第4.3 小节实验相同。使用不同数量的合成文本进行以下实验。
4.4.1 困惑度测试
实验(7):设置一个采用等同于真实数据量(约10 万条语句)的1 倍的CS 合成数据的实验,这是为了最直观地观察合成数据的质量。
实验(8):设置一个等同于真实数据量的2倍的CS合成数据的实验,这是为了直观地观察随着合成数据的增长,能否对使用该数据训练生成的语言模型的性能有提升效果。
实验(9):设置一个等同于真实数据量的3倍的CS 合成数据的实验,这个实验的设置目的与实验(8)的目的相同,因为我们在实验中发现,使用2 倍合成数据相比于只使用1 倍合成数据,能降低语言模型的困惑度,并且使得困惑度接近于只使用真实数据的基线系统,即实验(1),于是本小节继续加大合成数据量,到达3倍。
实验(10):设置一个等同于真实数据量的4 倍的CS 合成数据的实验,这个实验的设置目的与实验(9)的目的相同,因为我们在实验中发现,使用3 倍合成数据相比于只使用2 倍合成数据,能降低语言模型的困惑度,并且使得困惑度略低于只使用真实数据的基线系统,即实验(1),于是本小节继续加大合成数据量,到达4倍。
实验(11):设置一个采用3 倍的合成文本数据与真实CS 数据混合的实验,设置这个实验的是因为,在实验(10)与实验(9)的对比中,我们发现,采用4 倍合成数据与采用3 倍合成数据的效果相差无几,为了获得更好的语言模型,此实验将真实数据采纳进来,将3倍合成数据与真实数据混合,以期使得模型的困惑度进一步降低。
实验结果如表3所示,与基线系统(实验(1))相比,单语种数据的加入(实验(2))能够降低语言模型在纯中文与纯英文上的困惑度,然而对CS的句子基本没有作用,对转换点处也基本无影响,这是因为单语种数据增强了语言模型对单语种词序列内部依赖关系进行建模能力,但是由于单语种不存在CS现象,因此无法增强语言模型对跨语种词序列的建模能力。
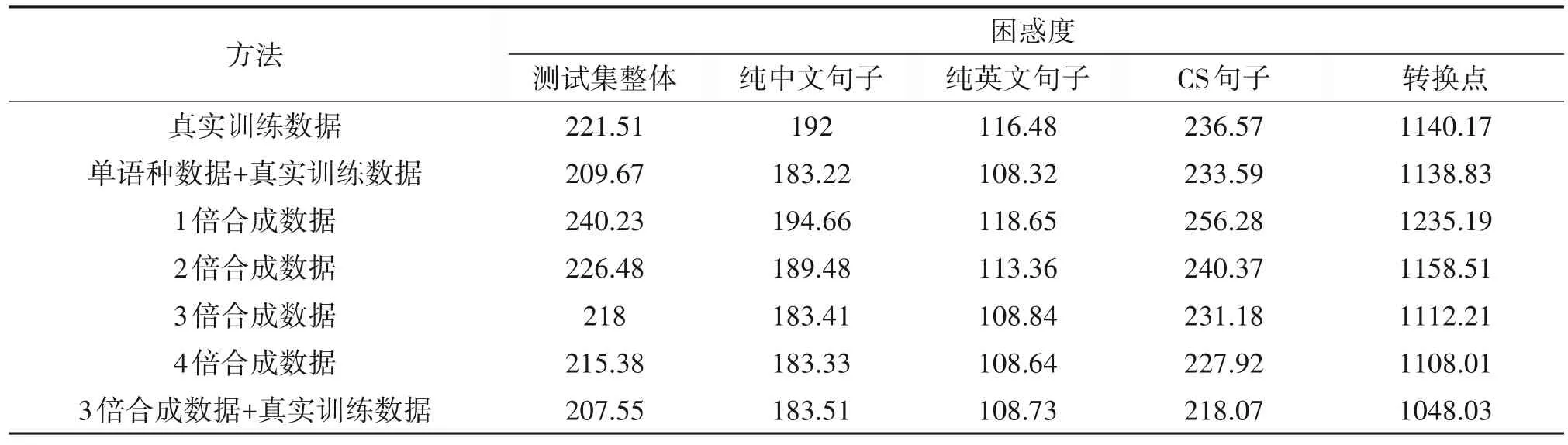
表3 基于带复制机制的编码器-解码器模型的CS文本生成器合成文本所训练的3-元文法语言模型在SEAME测试集上的困惑度Tab.3 The perplexity on the SEAME test set of 3-gram language model trained on Synthetic text generated from Encoder-Decoder based code-switching text generator with copy mechanism
与基线系统相比,仅采用1 倍合成数据(实验(7)),对纯中文与纯英文的困惑度基本没有影响,然而却让CS 句子困惑度增加了约20,这是因为,1倍合成数据中,存在大量中文-中文、英文-英文的关系,而且这些关系是来源于源数据,质量高,因此,实验(7)对纯中文、纯英文的困惑度接近于基线系统。又因为1 倍合成数据中的CS 都是合成的,质量比真实的训练数据低,因此,该系统在CS 句子上与在转换点的困惑度都有所增加。实验(7)相比于实验(3),在纯中文句子、纯英文句子、CS句子、整体测试集上的困惑度指标分别降低了相对65.28%、77.71%、54.94%、57.54%。我们分析认为,复制机制的加入,使得在解码阶段,复制的原文为解码器提供了及时的语言学指导,导致生成的词序列受到较多的语种内部的语言学约束与跨语种间的语言学约束,生成的文本自然度较高。
与仅采用1 倍合成数据(实验(7))相比,采用2倍合成数据(实验(8)),可稍微降低纯中文(2.7%相对下降)与纯英文的困惑度(4.4%相对下降),这是因为,合成数据量加大,则训练数据中的英文-英文、中文-中文数量增加。同时,采用了2 倍合成数据的系统,相比采用1 倍合成数据的系统,在CS 语句上,困惑度有6.2%的相对下降,这是由于CS 数量翻倍了,有助于语言模型更好地对跨语种词间依赖关系进行建模。
受实验(8)启发,本小节继续加大合成数据量,设置了采用3倍合成数据的实验(实验(9)),结果显示,进一步加大合成数据量,可以进一步使得困惑度降低,相比于实验(8),实验(9)在纯中文、纯英文、CS 的三个困惑度指标上,分别获得了相对下降3.2%、4.0%、3.8%。同时,实验(9)第一次超越了基线系统。
受实验(9)启发,本小节继续加大合成数据量,设置了采用4 倍合成数据的实验(实验(10)),结果显示,进一步加大合成数据量,在三个困惑度指标上虽然超越了实验(9)系统,但是性能提升微弱。
实验(10)引发了我们思考,语言模型性能不是随着合成数据的增长而呈现线性提升的趋势,当合成数据到达一定的量之后,语言模型性能的提升会受到瓶颈限制,如果再增加合成数据,也许可能还会有极其微弱的持续提升,但是却会耗费大量计算资源,得不偿失,因此,我们适可而止,在实验(11)中,将3 倍合成数据量作为我们所研究的文本生成方法的最合适的产出量,将3 倍合成数据与真实训练数据混合到一起是比较合适的比例。实验(11)在纯中文、纯英文上的困惑度,与实验(9)基本保持一致,在CS句子上的困惑度,比实验(9)有5.7%,比基线有7.8%的相对下降,在SEAME 整体测试集上,比实验(9)有4.8%的相对下降,比基线有6.3%的相对下降。
4.4.2 解码性能测试
为了进一步验证基于指针生成网络合成CS 文本的方法,所合成的文本质量与语言模型的性能,本文进一步展示第4 节中设置的实验(1)-实验(2)、实验(7)-实验(9)、实验(11)共6 组语言模型在语音识别系统中的性能表现。6 组实验均在SEAME 测试集上进行识别解码。
实验结果如表4 所示,相比于基线系统实验(1),单语种数据的加入(实验(2)),其主要作用是在解码过程中,对英文-英文或者中文-中文的词间依赖关系提供更可靠的路径选择信息,但是对识别结果只有0.7%的混合错误率相对下降,这是因为,语言模型依旧没有更好地指导跨语种词间的路径选择。实验(7)、实验(8),仅用合成数据训练的语言模型,不能提升系统的识别性能,这也是因为语言模型依旧没有更好地指导跨语种词间的路径选择。根据第4.4.1小节,实验(9)的困惑度稍微低于基线系统,因此,实验(9)(39.40%)对解码系统的路径选择指导能力应该与基线(39.26%)保持相近。最后,实验(11)相对基线,识别混合错误率仅有1.3%的相对下降,提升效果甚微。虽然本小节的识别结果收效甚微,但也可能是声学模型的性能限制了,但这样的识别结果已经足以证明,本章研究的CS文本数据合成方法是可行的,以后有进一步研究的必要。
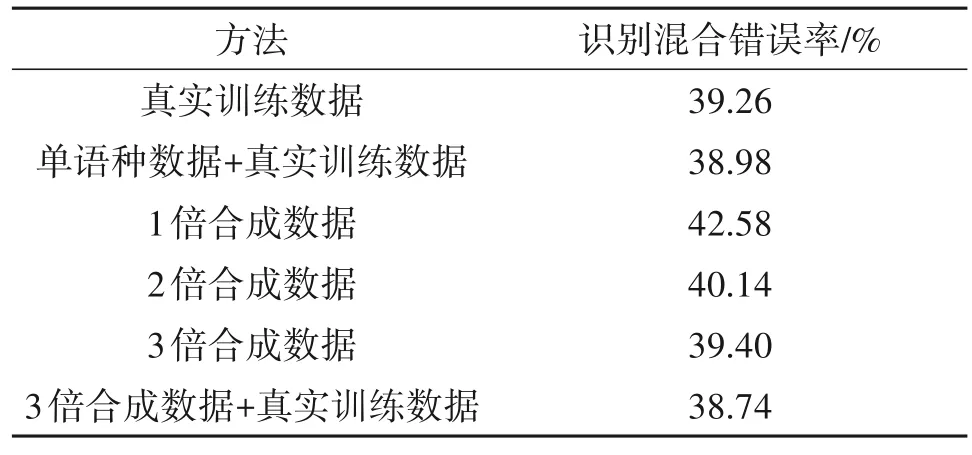
表4 基于带复制机制的编码器-解码器模型的CS文本生成器合成文本所训练的3-元文法语言模型在SEAME测试集上的识别混合错误率Tab.4 The mixed error rate on the SEAME test set of 3-gram language model trained on Synthetic text generated from Encoder-Decoder based code-switching text generator with copy mechanism
5 结论
本文构建的基于编码器-解码器模型的CS文本生成器学习单语种内部的语言学约束同时也学习跨语的语言学约束,并且利用单语种平行语料合成大量的CS文本数据来扩充训练双语CS语言模型的训练数据库。但是该模型合成的CS 文本自然度较低,为了解决此问题,在该模型基础上,增加一个门控,它决定了生成器产生的下一个词,到底是从解码器中预测出来的,还是从编码器的输入源文本中拷贝过来的,形成了基于带复制机制的编码器-解码器模型合成CS 文本的方法。最终本文的方法使得语言模型在SEAME 整体测试集上的困惑度有13.96的绝对下降,识别混合错误率有相对1.3%的下降。由此验证了,本文提出的方法,可以合成自然度较高的CS 文本,从而能够缓解CS 文本数据稀缺的问题。
