动态一致自信的深度半监督学习
2022-11-15刘子荣罗金涛
李 勇,高 灿+,刘子荣,罗金涛
1.深圳大学 计算机与软件学院,广东 深圳518060
2.广东省智能信息处理重点实验室,广东 深圳518060
大型神经网络的成功依赖大量有标记的数据,当缺少标记数据时模型往往会过拟合。但在实际情况下,建立具有良好标记的大型数据集需要大量的人力和物力,当数据集的标注需要专业知识时(例如,医学影像数据集),所需成本会极大增加[1]。与有标记数据不同,无标记数据可以更容易被获取。深度半监督学习方法可以利用无标记数据来提升监督学习方法的性能,从而减少大型神经网络对有标记数据的需求。
许多早期的深度半监督学习方法的流程主要分为两个阶段:第一个阶段,使用大量无标记数据进行无监督训练,初始化神经网络每一层的权重;第二个阶段,以监督方式使用有标记数据对网络微调(finetuning)[2]。在一些复杂的任务中,无监督学习不能明确对任务有用的知识,因此会学习到一些与任务无关的知识噪声导致半监督学习方法性能下降[3]。为了解决这个问题,很多新的深度半监督学习方法[4-6]被提出。这些半监督学习方法的损失函数由无监督损失和有监督损失两部分组成,并在训练过程中同时利用无标记和有标记数据训练网络,取得了更好的效果。
目前,很多主流的深度半监督学习方法可以分为两类:熵最小化和一致性正则化[5]。熵最小化又叫自信预测,通过促进模型在无标记数据上产生低熵预测(自信预测)使模型输出自信的预测结果,增大模型对某个类别的预测概率,提升模型预测的准确度。最小化无标记数据预测概率分布的熵值,可以有效减少类别概率分布的重叠,促进类间的低密度分离。一致性正则化促使模型在输入受到干扰时仍产生相同的输出分布来增强模型的泛化能力,从而有效扩大模型对样本分布的支持来提升模型的性能。但上述两种类型的深度半监督学习方法都存在一定局限性。大部分熵最小化半监督学习方法并不能灵活调节预测概率的分布趋势,很容易促进错误预测产生。在训练的前期,模型对大部分数据的预测会发生变化,促进自信预测的强度过大可能会对模型的训练产生较强的负面影响,若促进强度过小,会导致自信促进的幅度不足,使模型不能有效输出自信预测的结果。很多一致性正则化损失中所有无标记数据损失的权重是相同的,而模型对无标记数据预测的正确度是不同的,因此对所有无标记数据的一致性损失共用一个不变的权值是不合理的[7]。为了解决上述问题,本文提出了一种用于深度半监督学习的无监督损失函数,称为动态一致的自信损失(dynamic consistency and confidence loss,DCCL)。该损失函数由动态加权一致性正则化(dynamic weighted consistency regularization,DWCR)和自信促进损失(self-confidence promotion loss,SCPL)组成,其中DWCR 通过对数据的一致性损失进行动态加权,可以减少错误预测及数据差异带来的负面影响。SCPL 能灵活调节促进模型输出自信预测的强度,实现类间的低密度分离,提升模型的分类性能。本文将DCCL与监督损失结合,提出了名为动态一致自信(dynamic consistency and confidence,DCC)的深度半监督学习方法。本文的主要贡献有以下三点:
(1)针对样本间的差异以及错误预测的负面影响,提出了一种简单有效的动态加权一致性损失DWCR,实现了对无标记数据一致性正则化损失的动态加权。
(2)提出了一种新的促进模型产生自信预测的无监督损失SCPL,并能灵活调节促进强度,实现灵活可控的熵最小化。
(3)提出了一种新的半监督学习方法DCC,并在不同数据集上进行了大量的实验,实验表明了该方法的有效性。
1 相关工作
目前很多先进的半监督学习方法都采用了熵最小化与一致性正则化作为无标记数据的损失函数。本章将回顾一些与DCC有关的深度半监督学习方法。
熵最小化通常使用信息熵或KL散度实现,如式(1)和式(2)所示:

一致性正则化半监督学习方法是通过减少扰动前后数据预测的差异来提升模型的泛化性能。很多一致性正则化半监督学习方法的不同之处体现在对输入数据的扰动方式(增强方式)和减少预测差异的方法。Laine 等[9]提出了Π-model,该方法对输入的图像进行两次随机增强,并最小化预测的平方差异来提升模型的泛化性能,由于同一张图像会通过网络两次,文献[9]同时给出了Π-model 的另一版本Temporal Ensembling,通过记录模型对无标记数据历史预测的指数加权移动平均,作为模型对图像不同增强的预测,加快了训练进度。文献[10]提出的MeanTeacher模型采用了双网络模型,即教师网络与学生网络,教师模型的参数来自学生模型参数的指数加权移动平均,在训练过程中分别向两个网络中注入不同的噪声,并将预测平方差异最小化实现一致性正则化。Rasmus 等[4]也采用了双网络模型进行半监督学习,但与MeanTeacher不同的是其扰动方式是向其中一个网络中添加高斯噪声,并在训练过程中最小化两个网络每一层输出的平方差异来增强泛化性能。Sohn 等[1]提出的FixMatch 对无标记图像采用了两种强度不同的图像增强方式,在训练过程中筛选具有可靠预测的弱增强图像,并将预测概率与对应强增强图像预测计算交叉熵,作为无标记数据的损失函数。虽然很多一致性正则化半监督学习方法有效增强了模型的泛化性能,但它们并没考虑不同数据的差异和错误预测的负面影响。
2 本文提出的方法
本章主要介绍提出的动态一致自信(DCC)的深度半监督学习方法,包括模型的整体结构、无监督损失以及总体半监督损失函数和算法流程描述。
2.1 DCC模型整体结构
大多数效果较好的神经网络会在训练过程中最小化模型在训练数据上的平均误差,称为经验风险最小化(empirical risk minimization,ERM)[11]。但ERM容易使大型神经网络在训练数据不足时过拟合,当使用在训练数据分布之外的例子对模型进行评估时,模型会给出错误的预测结果。数据增强是解决上述问题的一个有效的方法,使用增强后的数据训练网络可以实现模型对训练样本分布支持的扩大[11]。本文提出的半监督学习模型采用了两种强度不同的图像增强方式:弱增强和强增强。弱增强是只对训练图像采用翻转、裁剪操作,并不会造成原始图像的失真。强增强采用Cutout[12]和RandAugment[13]使增强后的图像产生严重的扭曲,从而造成一定程度的失真[1]。考虑到有标记和无标记图像的差异性,本文对有标记数据只采用弱增强的方式实现图像增强,将增强后的图像送入深度神经网络得到预测结果并计算有监督损失Ls。而对无标记数据同时进行强增强和弱增强处理后送入深度神经网络并得到对应的预测结果,根据弱增强图像和强增强图像预测结果构建一致性正则化损失,并单独使用弱增强图像预测结果构建促进自信预测的损失函数。由于模型对增强后的无标记数据的预测正确性未知,本文提出了一种度量预测正确度(自信度)的方式,并根据弱增强无标记图像预测的自信度,对数据的一致性损失进行加权得到动态加权一致性正则化函数Lud,减少了错误预测的负面影响。Luc表示自信促进损失函数,鼓励模型产生自信的预测。最终的损失函数Loss由Ls、Lud以及Luc三部分组成,整体的模型架构如图1所示。

图1 DCC模型总体结构Fig.1 Overall structure of DCC model
2.2 损失函数
本文中有标记数据的标记采用了one-hot编码方式,并使用交叉熵损失函数作为模型的有监督损失函数,其公式描述可表示为:

其中,B为训练batch 中有标记数据的数量,pi是模型预测的类别概率。
一致性损失可在输入数据受到干扰时使模型仍产生近似相同的概率分布,以此增强模型的泛化能力,常见的一致性损失函数可表示为:

其中,pwi是由argmax(fθ(w(ui)))得到的对弱增强无标记数据ui预测的one-hot 编码,表示弱增强ui的第k类编码元素,C为样本的类别数目。psi=fθ(s(ui))是模型对强增强ui预测概率分布,表示强增强ui属于第k类的概率。fθ(·)为参数模型,w(ui)表示对ui弱增强,s(ui)表示对ui进行强增强。μ是一个常数,用于调节一个batch 中无标记数据所占有的比例。通过最小化式(4)可以减小不同增强方式的无标记数据预测的差别,从而实现一致性正则化。
由于模型对所有无标记数据预测的准确度是不同的,例如模型很容易正确预测某些数据,但错误预测另一些数据,如果直接采用具有错误预测的数据进行一致性正则化会对模型的训练产生负面的影响。通常模型预测的最大类别概率越小,预测的类别概率信息熵越大,不同类别概率的差异就越小,因此预测的准确度就越低。基于上述分析,本文提出了一种度量模型预测自信度(confidence level,CL)的方法,其公式描述表示为:

其中,Emax=lbC表示预测分布的最大信息熵,其中C为类别数目。E表示预测概率分布的信息熵。式(5)对应的图像如图2所示。当模型对某一类别的预测概率非常高时,预测类别概率的信息熵E接近0,此时CL接近1,反之若信息熵E较大,CL接近0。

图2 CL函数图像Fig.2 CL function image
本文将预测自信度CL与式(4)进行结合得到了动态加权一致性正则化(dynamic weighted consistency regularization,DWCR)损失函数,其公式描述为:

其中,CLi是无标记数据ui的CL值。式(6)中每一个无标记样本都有一个单独的CL值,并根据模型预测的类别概率分布变化而变化。当数据的预测概率不具有区分度时,CL具有较小的值,这减少了具有错误预测数据的一致性损失所占的比例,使错误预测产生的负面影响降低。
通常模型输出低熵预测能够促使决策边界通过数据的低密度区域,实现类间的低密度分离[14]。而实现这一目的需要在损失函数中加入一项最小化类别概率分布信息熵的损失函数,如式(7)所示:


其中,m是一个超参数用于调节促进模型产生自信预测的力度。对于一个二分类问题,考虑第i个样本的信息熵损失和SCPL损失分别如下:

在半监督学习方法的训练过程中,促进模型产生自信预测可以使决策边界通过数据的低密度区域。但是,当促进自信预测的强度过大,则会加速错误预测的产生,导致决策边界处于错误的位置。图3展示了式(9)和式(10)的函数图像,通过调节式(10)中的指数m,SCPL 可以具有不同的数据分布,从而更灵活地调节促进模型产生自信预测的力度。最终DCC的损失函数如式(11)所示:
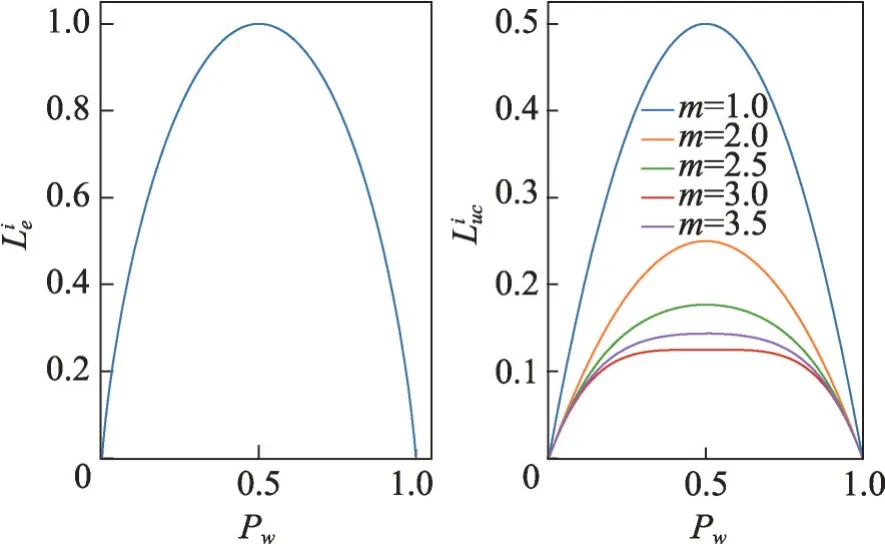
图3 信息熵最小化损失和SCPLFig.3 Information entropy minimization loss and SCPL

其中,α和β是两个超参数,用于平衡两个无监督损失所占的比例。当α的值过大时,具有错误预测数据的一致性正则化损失的负面影响将会增强,而过小的α会降低一致性正则化的性能。过大的β值会使SCPL的自信促进力度过大而产生错误预测,当β的值过小时会导致SCPL的自信促进作用较小,不能有效实现低熵预测。算法1描述了提出的DCC算法流程。
算法1动态一致自信的深度半监督学习

3 实验
为了验证提出的动态一致自信(DCC)的深度半监督学习方法的有效性,在CIFAR10、CIFAR100 以及SVHN三个数据集上进行了实验,并与Π-model[9]、PseudoLabel[2]、Mixup[11]、VAT[8]、MeanTeacher[10]、Mix-Match[14]、Temporal Ensembling[9]、EnAET[5]深度半监督学习方法进行对比。为了保证实验的公平性,实验中所有半监督方法都使用“Wide ResNet-28-2”[15]作为骨干网络,该网络有1.5×106个参数。实验设置batch 中有标记数据的数量B=128,超参数μ=7,并对模型使用带有动量的标准SGD[16]优化器,将动量设置为0.9。另外,本文使用余弦学习速率衰减,其中η=0.03 是初始的学习速率,t是当前的batch训练步数,T=400×29是总体batch训练步数。本文方法采用Pytorch1.6深度学习框架实现,利用GeForceRTX2080Ti 11 GB显卡进行运算加速,并使用NvidiaApex混合精度工具加速训练。
3.1 数据集
CIFAR10 数据集由训练集和测试集组成,共包含10 个类别的彩色图像,其中训练集共有50 000 张图像,测试集由10 000张图像组成[9]。
SVHN 是Google 街景门牌号码数据集,数据集中的每张图像包含一组0~9的数字,其中训练集包含73 257个数字,测试集由26 032个数字组成[10]。
CIFAR100 数据集共有100 个类别的图像,每个类别有600 张图像,其中500 张图像组成训练集,剩下的100张图像作为测试集[15]。
3.2 实验结果及分析
为了更好地验证DCC 的性能,本文从数据集中随机挑选一定数目的图像和对应的标记组成有标记数据,其中每种类别的有标记数据数目相同,剩下的图像作为无标记数据,并将该划分过程重复3次。在得到的3个数据集上进行3次独立实验,报告平均分类错误率和标准差,并将最低的错误率加粗显示。对每个数据集,实验设置三种不同数目的有标记数据。
CIFAR10 数据集上划分了250、1 000 和4 000 三种数目的有标记数据,对于所有不同划分下的实验统一采用参数设置α=2.0,β=0.1,m=9。模型在CIFAR10 上训练共占用显存为5 101 MB,在上述三种不同数目有标记数据的划分上的训练耗时分别为37.95 h、24.67 h、22.62 h。在CIFAR10上的实验结果如表1 所示,随着有标记数据增加,所有方法的错误率都有所下降。在所有不同的划分中DCC方法的错误率都是最低的,比次优的方法EnAET 的分类性能分别提升了32.07%、32.52%、22.43%(计算方式为(errorA-errorB)/errorA)。EnAET 中虽然也使用了一致性正则化损失,但所有数据损失的权重相同,并没有考虑模型对不同数据预测的准确性差异,而具有错误预测数据的一致性损失会对模型的训练产生负面影响,降低模型最终的分类性能。
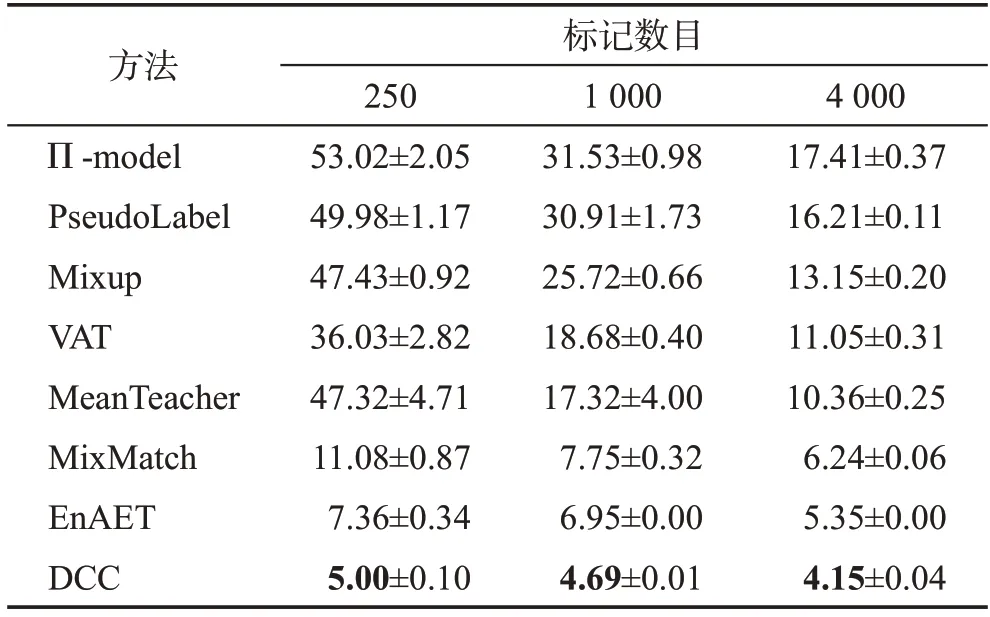
表1 不同半监督方法在CIFAR10上的错误率Table 1 Error rates of different semi-supervised methods on CIFAR10 单位:%
SVHN 数据集上划分了250、1 000 和4 000 三种数目的有标记数据,并设置α=2.0,β=0.5,m=9。模型在SVHN 上训练共占用显存为5 101 MB,在上述三种不同数目有标记数据的划分上的训练耗时分别为39.35 h、25.13 h、23.13 h。实验结果如表2所示,在不同数目的有标记数据下,DCC 的错误率仍是最低的,但是随着标记数据的增加,DCC与其他方法错误率之间的差距在缩小。在4 000 个有标记数据的情况下,DCC 的分类性能只比次优方法提升了2.60%,而在250 和1 000 个有标记数据的情况下,比次优方法的分类性能分别提升了9.35%和6.85%。可能的原因是DCC方法的动态加权一致性正则化和自信促进损失在标记数据较少的情况下从无标记数据中学习相关类别特征知识的能力比其他方法更强,随着有标记数据的增加,这种优势会减少。

表2 不同半监督方法在SVHN上的错误率Table 2 Error rates of different semi-supervised methods on SVHN 单位:%
CIFAR100数据集上划分了1 000、5 000和10 000三种数目的标记数据,并设置α=0.5,β=0.1,m=9。模型在CIFAR100上训练共占用显存为5 103 MB,在上述三种不同数目有标记数据的划分上的训练耗时分别为24.30 h、23.73 h、23.32 h。实验结果如表3 所示。虽然本文缺少某些对比方法在1 000和5 000个有标记数据上的错误率信息,但是DCC 的性能仍具有优势。DCC 在只有1 000 个有标记数据存在的情况下错误率为48.66%,比次优方法的分类性能提升了17.15%。随着有标记数据的增加,DCC 的错误率进一步降低,但是在有标记数据较多的情况下优势并不大,该结果与在CIFAR10、SVHN 数据集上的一致。

表3 不同半监督方法在CIFAR100上的错误率Table 3 Error rates of different semi-supervised methods on CIFAR100 单位:%
3.3 消融实验
为了进一步验证提出DCC 方法的有效性,本文在CIFAR10、SVHN、CIFAR100 上分别用250、250、1 000 个有标记数据进行消融实验,并设置原始一致性正则化损失的整体权重为1,实验结果如图4 所示。由于原始基于一致性正则化损失的半监督学习方法(Original)将所有无标记数据同等对待,错误的预测会对模型的训练产生较大的负面影响,从而导致分类错误率较高。将动态一致性加权引入到原始的一致性正则化半监督学习方法(Original+DWCR)中去可以减少错误预测的一致性损失对训练过程的负面影响,使模型的分类性能得到提高。而自信促进损失则可以鼓励模型产生自信度更高的预测,促进类之间的低密度分离,因此引入自信促进损失的动态加权一致性正则化半监督学习方法(Original+DWCR+SCPL)能进一步提升模型的性能。

图4 消融实验结果Fig.4 Ablation experiment results
3.4 参数敏感性分析
本文提出的DCC深度半监督学习方法的损失函数主要涉及三个超参数α、β和m。为了研究模型对超参数变化的敏感性,本文在CIFAR10、SVHN 和CIFAR100 数据集上分别取250、1 000 和1 000 个样本作为有标记数据,其余样本作为无标记数据并进行了实验,结果如图5所示。
本文在具有不同数目的有标记数据的数据集上研究了模型性能对α的敏感性,α的取值范围为{0.1,0.5,1.0,2.0,3.0},结果如图5(a)所示。当α的值在[1.0,2.0]范围内,DCC在SVHN和CIFAR10上具有较好的性能。而在CIFAR100 上,当α的值在[0.5,1.0]范围内,DCC具有较好的性能。过小的α会导致所有无标记数据一致性损失的权值过小,不能有效增加模型的泛化能力,而过大的α会使具有错误预测数据的一致性损失权值较大,从而对模型的训练产生负面影响,降低模型的分类性能。
图5(b)展示了在不同数据集上模型性能对β的敏感性,其中β的取值范围为{0.05,0.10,0.50,1.00}。当β的值在[0.10,0.50]的范围内,DCC 在SVHN 和CIFAR10上具有较好的性能。而在CIFAR100上,当β的值在[0.05,0.10]范围内,DCC 具有较好的性能。过大的β会使SCPL的促进作用过强,从而导致错误预测的发生,对训练产生负面影响,最终降低模型的分类性能。
图5(c)展示了模型对m变化的敏感性。当m的取值范围在[8,10]内,模型在所选数据集上均具有较好的性能。过小的m会使SCPL函数具有较大梯度,不利于模型的训练,而过大的m会使SCPL 的值过小,导致促进产生自信预测的效果较弱。

图5 DCC对参数的敏感性Fig.5 Sensitivity of DCC to parameters
4 结束语
本文提出了动态一致自信的深度半监督学习方法,其无监督损失函数由动态加权一致性正则化和自信促进损失组成,并使用交叉熵损失函数作为监督损失函数。动态加权一致性正则化使用每个无标记数据的自信度CL作为动态一致性权值,在无标记数据上进行一致性训练,有效增强了模型的泛化性能。自信促进损失能灵活调节促进模型输出自信预测的强度,有效实现类间的低密度分离,从而增强模型的分类性能。在多个数据集上的大量实验表明,提出的动态一致自信的深度半监督学习方法的性能优于目前较先进的深度半监督学习方法。未来的工作会进一步探索不同无标记数据自信促进损失的差异以及对自信促进损失函数的动态加权。
