深度学习的表格到文本生成研究综述
2022-11-15奚雪峰崔志明周悦尧仇亚进
胡 康,奚雪峰,3+,崔志明,3,周悦尧,仇亚进
1.苏州科技大学 电子与信息工程学院,江苏 苏州215000
2.苏州市虚拟现实智能交互及应用重点实验室,江苏 苏州215000
3.苏州智慧城市研究院,江苏 苏州215000
自然语言处理(natural language processing,NLP)是人工智能的主要研究方向之一。自然语言处理领域有众多研究方向,如文本分类、情感分析、命名实体识别、信息抽取、文本摘要、问答系统。文本生成,通常被正式称为自然语言生成(natural language generation,NLG),是自然语言处理中最重要但也是最具挑战性的任务之一[1]。文本生成的目标是从各种形式的数据(如文本、数字、图像、结构化知识库和知识图)中生成人类语言的可理解文本[2]。
表格是日常生活中常见的数据形式,但在深度学习中却没有得到很好地利用。表格含有丰富的信息,但是并不适合人直接获取信息。由此诞生了新的研究方向“表格到文本生成(table-to-text)”。正因为表格这种结构化数据在日常生活中常见且蕴含大量信息,所以表格到文本生成任务有重要的研究意义与价值。
理解表格含义并描述其内容是人工智能中的重要问题,它有潜在应用,如问题回答、构建对话代理和支持搜索引擎[3-10]。随着近年研究不断深入,表格到文本生成系统已经应用于新闻、医疗诊断、金融、天气预报和体育广播等领域[11]。
1 任务描述
表格到文本生成,是指语言模型通过输入表格并生成描述表格的文本。模型生成的文本应该语句流畅,充分表达表格信息且不能偏离表格事实。该任务的训练数据中含有属性、值以及描述表格的文本,表格到文本生成数据集实例如图1所示。

图1 Wikibio数据集实例Fig.1 Example of Wikibio dataset
1.1 任务形式化描述
表T是I个实体ei的无序集合,表示为T:={e1,e2,…,ei,…,eI}。不同实体ei是一组Ji无序记录{ri,1,ri,2,…,ri,j,…,ri,Ji},其中记录ri,j被定义为一对键ki,j和值vi,j。每个表与文本描述y相关联。将描述y的前t个单词称为y1:t,因此可以将单词完整序列记为y1:T。数据集D是N个对齐对(表T、描述文本y)的集合[11]。
RotoWire 数据集包含NBA 比赛记录的一部分(共628场),以及从黄金文档中选择的记录。该文档只提到比赛记录的部分信息,但可能会以复杂的方式表达它们。除了捕捉写作风格外,语言模型还应该选择类似记录内容,清晰表达表格信息并适当排序[12]。对于数据集D中的每个表T,目标函数旨在生成尽可能接近基本表格事实y的描述文本。该目标函数在整个数据集D上优化如下对数似然:
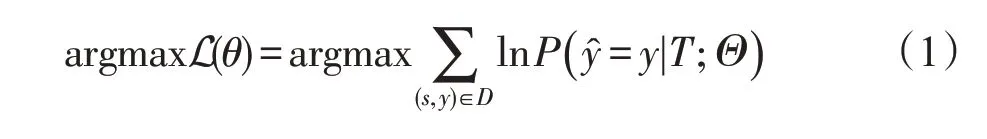
1.2 任务难点
目前表格到文本生成模型需要面对越来越复杂的表格,并生成更长、结构更复杂的文本描述。模型生成的文本经常出现错误的描述或表格中完全没有提到的内容[11]。复杂的句子结构给模型生成流畅且准确的文本描述带来了挑战。当前表格到文本生成模型面对两大问题:描述什么,如何描述[12]。
(1)描述什么:表格有着丰富的信息,并不是所有信息都将在文本描述中被提及。如何正确选择表格中的重要内容是该领域研究难点之一。
(2)如何描述:随着生成文本长度的增加,文本变得逻辑混乱,可读性差。如何准确且连贯地描述表格内容,并在复杂句子结构中保证正确的前后逻辑关系,是该领域研究的重点问题。
2 研究方法
目前主流的表格到文本生成的神经网络模型,大部分都使用长短期记忆网络(long short-term memory,LSTM)[13-14]和编码器解码器(encoder-decoder)体系结构[15]。在训练中表格数据首先由编码器(encoder)顺序地编码成固定大小的矢量表示。然后解码器(decoder)以该矢量表示为条件解码并生成单词。随着注意机制[16-17]的引入,一方面,在每个解码步骤控制计算聚焦于重要元素的上下文,另一方面,复制机制[18-19]处理未知或罕见单词,这些系统能产生流畅且领域全面的文本描述[11]。在生成阶段使用beam search[20-22]来扩大搜索空间以生成更好的文本描述。
2.1 表格到文本生成的序列到序列架构
在机器翻译领域,最经典也是最常用的就是序列到序列架构(sequence-to-sequence architecture)[23],这种架构在表格到文本生成领域也适用。其主要思想是:由编码器将输入的表格信息编码为蕴含大量信息的稠密向量,然后让解码器利用这个稠密向量,根据任务需求解码出表格内容相应的文本描述。其结构如图2所示。

图2 带有注意力机制的序列到序列架构Fig.2 Sequence-to-sequence architecture with attention mechanism
2.1.1 LSTM语言模型
循环神经网络(recurrent neural network,RNN)[24]是一种用于处理序列数据的神经网络。与一般的卷积神经网络(convolutional neural network,CNN)[25-26]相比,循环神经网络的隐藏状态能更好地处理序列形式数据中前后关联的信息,例如同一个词语会因所处上下文不同而有不同的意思。LSTM是一种特殊的RNN,LSTM可以缓解长序列训练过程中的梯度消失和梯度爆炸问题。表格到文本生成任务的输入通常为较长的序列,这种情况下LSTM 有优于RNN 的良好表现。其结构如图3 所示。其中,遗忘门(forget gate)会控制LSTM的细胞单元是否遗忘信息。

图3 LSTM结构Fig.3 LSTM structure
2.1.2 编码器
编码器的目标是:将可变长度的源序列x={x1,x2,…,xn}转换为固定长度的连续向量。最基本的编码器使用卷积神经网络(CNN)或递归神经网络(RNN),而整个编码过程为:将嵌入(embedding)后的输入序列压缩投影到模型需要的维度,而这个被压缩的序列蕴含输入序列的全部信息(即语义)。最直接的方式是:将编码器最后一层最后一个时间步的隐藏信息作为整个输入的语义信息,也可以对最后的时间步的各层隐藏状态求平均值作为语义信息。
2.1.3 解码器
解码器根据由编码器编码得到的语义信息,解码生成表格的文本表述序列。最基本编码器也是RNN,而整个解码的过程是:解码器RNN直接将语义信息作为初始隐藏状态,在第一个时刻以<eos>等特殊标识符作为输入,在这之后以前一时刻的输出作为当前时刻的输入不断循环生成序列,直到生成<eos>特殊标识符为止。
在训练时间方面有两种训练方法:一种是一直使用解码器的输出作为下一时刻的输入,这样会给予模型更大的灵活性,同时使得模型训练时间更长;另一种是无论解码器生成的是什么,均以正确的下一个token 作为解码器的输入,这样会削弱模型的灵活性,但会加速模型训练。其计算过程如下:

其中,f()是非线性函数,st=f(yt-1,st-1)是RNN 在时间步t的隐藏状态。
2.2 表格到文本生成的注意力机制
虽然基于RNN 和Sequence-to-Sequence 架构的模型给予文本生成(NLG)领域巨大帮助。但是它也存在缺陷,如在表格到文本生成任务中,当需要生成的表格描述很长时,将如此复杂的语义压缩到定长的序列中并且不丢失太多信息,这本身就是个困难的任务。与此同时,解码器还需要从这样信息高度浓缩的向量中解码出对应的语义序列,而且RNN 在长序列时会出现梯度消失等问题,因此整个任务很复杂。为突破解码器过于依赖单一定长稠密向量去生成序列这一瓶颈,研究人员提出了注意力机制。
注意力机制[16-27]最早起源于计算机视觉模仿人类的视觉注意力,人类不会关注于目光所及的所有事物,而是把注意力聚焦于某一小块区域。在自然语言处理领域也是如此。
如图2 所示,解码器在解码的同时,不仅仅依赖于编码器所给出的语义向量,同时也关注原始输入序列对应部分。比如翻译“I like apple”为中文时,当解密生成“我”字时,解码器会更多地去关注原始序列中的“I”,而对“like”和“apple”则会给予更少的注意力。注意力机制能避免模型过度地依赖单一向量,从而出现解码瓶颈的问题。
2.3 表格到文本生成的指针网络
注意力机制的出现,让文本生成模型的能力有质的飞跃。不过序列到序列架构仍然存在问题,在自然语言处理的相关任务中如表格到文本生成,输出序列的词汇表会随着输入序列的改变而改变,但是序列到序列架构并不能很好地解决这一问题。因为这类问题,输出的元素往往是输入元素集合的子集。基于这一特点,研究人员提出指针网络(pointer network)[27-28]的模型结构,其类似于编程语言中的指针。传统的注意力机制是给予输入序列一系列权重,而指针网络的想法是:有时需要生成出现在源词汇表中的单词,但此时目标词汇表中没有该单词。既然注意力机制能重点关注原始序列某一部分,则选择注意力权重最大的那个元素复制到生成序列中,这样就解决了传统序列到序列架构存在的问题。原始注意力机制公式如下:
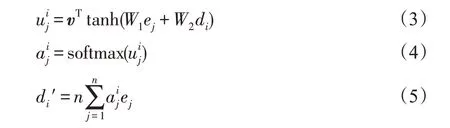
其中,j∈(1,2,…,n)。改进原始的注意力机制,从而得到指针网络公式:
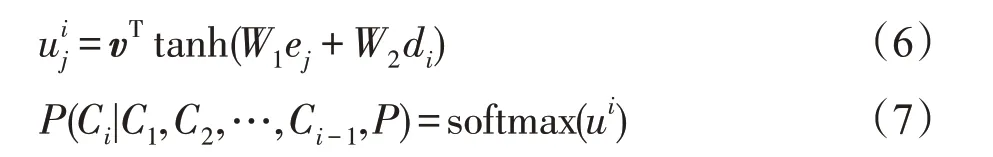
传统的带有注意力机制的序列到序列模型在训练时,编码器先对输入序列进行编码,然后对编码后的向量做相应的关注,最后解码器对施加注意力后的向量进行解码从而得到预测结果。但是指针网络,得到预测结果的方式是输出概率分布α,也即所谓的指针。换句话说,传统带有注意力机制的序列到序列模型输出的是针对输出词汇表的概率分布,而指针网络输出的则是针对输入词汇表的概率分布。
2.4 表格到文本生成的集束搜索
目前表格到文本生成模型已经较为完善,但在模型生成文本时,没有合适的策略。可选的策略有贪心搜索,即每一次都选择当前时间步在词汇表中概率最大的词。但是,目标是生成一个序列,这个序列在所有由模型生成的序列中概率最大,然而贪心搜索的策略并不能很好地完成任务。序列到序列模型常使用集束搜索(beam search)进行解码,这种策略减少了贪婪搜索做出的局部最优但全局次优决策的可能[29]。
集束搜索是一种启发式的策略,可以视作一种特殊的广度优先搜索。在搜索时会建立搜索树,并根据不同需求选择不同的排序算法,根据排序算法对当前层各节点对应的搜索路径进行排序并裁减掉得分较低的节点,直到剩余预先指定个数(超参数beamsize),然后继续在剩余节点中进行搜索。
令tn为n时刻选择的词汇,C为编码器输出的语义向量,T为最终生成结果。集束搜索通过不断重复上述步骤使得P(T|C)最大,集束搜索公式如下:

集束搜索过程的示例如图4所示。

图4 集束搜索示例Fig.4 Sample diagram of beam search
3 表格到文本生成模型
基于上述的研究方法,研究人员提出新颖的深度神经网络模型。为使得模型能够提取出表格的结构信息,Liu 等[30]提出表格结构感知模型。表格有大量信息,但是表格的描述一般会围绕关键信息进行描述,Ma 等人[31]提出以表格关键事实为中心的模型。表格有多个维度的信息,而大部分研究却忽略这个事实,Gong 等人[32]便提出对行、列、时间三个维度信息进行编码的三维层次编码器模型。Puduppully等人[33]提出内容选择与计划模型,来解决表格到文本生成模型在内容选择方面表现不佳,模型难以保持句间连贯的问题。将数据视作线性数据的方式会使得行与行之间的实体失去区别,Rebuffel 等人[11]提出基于Transformer的层次编解码模型。表格到文本生成的困难之一是输入的数据太大,朴素的模型无法找到在描述中应该提到数据的哪一部分,Iso 等人[34]提出显著内容选择、跟踪和生成模型。预训练模型在自然语言处理领域有优秀的表现,但是在表格到文本生成领域,因为预训练模型通常难以感知表格的结构而不能很好地提取表格信息。为解决这个问题,Gong等[35]基于GPT-2预训练模型提出Table-GPT。表格到文本生成领域的模型有通病:会产生不符合表格信息的文本描述,俗称“幻觉”。为解决这个问题,Rebuffel等[47]提出多分支解码器模型,通过调整不同分支的权重来控制模型产生幻觉。
3.1 表格结构感知模型
表格结构感知模型(structure-aware Seq2seq)[30],通过模仿人类描述维基百科信息的写作方法来构建模型。先从宏观角度来规划整个文本描述的内容结构;在描述更加细节的信息时再具体思考选择表格中哪些信息,摘抄哪些词语,如何连词成句。该模型采用经典的序列到序列架构,从局部和全局两种角度来分别提取表的内容信息和结构信息。本地寻址使用内容编码和字级注意力实现,而全局编码使用字段级注意力实现。本地寻址决定在生成描述时具体选用哪个词,但仅依靠微观的视角很难生成复杂而准确的描述,因为表格到文本的任务中,表格有多种结构且表格中关键字的顺序也不同。为能够适应不同的表结构,模型应该具备宏观角度观察表的能力。因此Liu等提出全局寻址,来帮助模型在生成表格描述时选择关注表格中的哪些信息。这样的两层结构,可以达到对表格的内容和结构双重信息进行编码的目的。对表格信息充分提取后,在解码阶段模型也使用双重注意力机制。该双重注意力机制分别对应于编码器的词级注意和字段级注意,这种机制能对表信息进行充分的还原。
在Wikibio数据集上的实验表明,模型优点在于:能够利用表内容以及表结构信息生成连贯且准确的表述。模型缺点在于:模型单独复制内容的能力和长文内容排序能力有待提高。模型结构如图5所示。
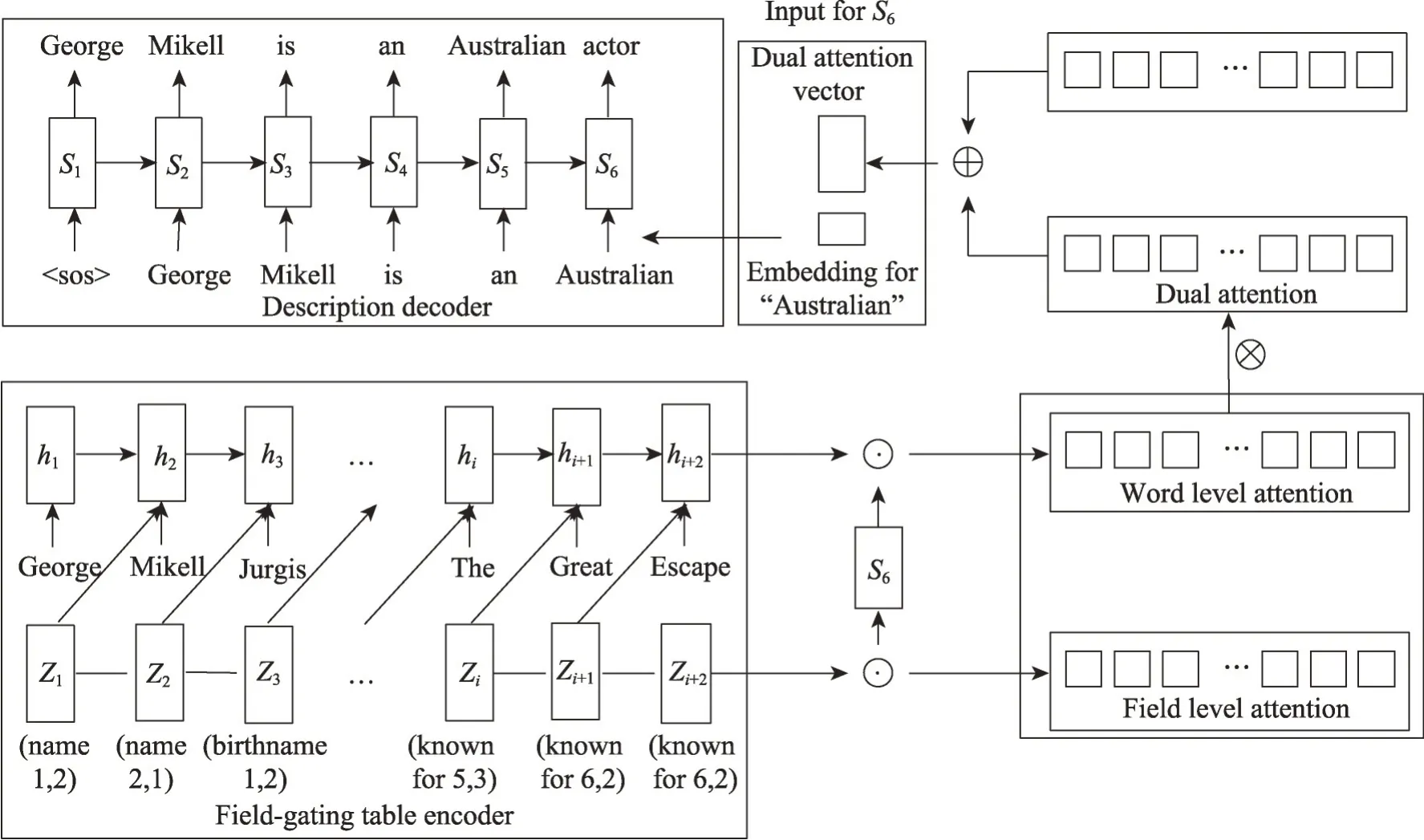
图5 表格结构感知模型Fig.5 Table structure perception model
3.2 以表格关键事实为中心模型
深度学习依靠数据来驱动。传统的序列到序列模型拥有较多参数,在数据匮乏时表现不好。因此Ma等提出新的“小模型”,这种模型可以在数据匮乏的情况下有优秀的表现。与传统的表格到文本的工作类似,该模型将表格到文本任务分为两个过程:关键事实预测与表层实现。
在第一阶段,使用“表格到重点”的模型,从表格中抽取出关键事实。关键事实也可称为共现事实,即同时出现在表格和文本表述中的字符。该模型采用BI-LSTM(bi-directional long short-term memory network)以及多层 感知机(multilayer perceptron,MLP)分类器来预测二进制序列,这个序列决定是否选择每个元素作为关键事实。
在第二阶段,Ma等[31]构建一个序列到序列模型,该模型以第一阶段选择的关键事实作为输入并生成描述表信息的文本。其中关键事实预测模型在训练时所需要数据量很少,不像其他模型那样有着大量数据刚需;而表层实现模型可以用伪并行语料集进行训练。这种伪并行数据集可以利用Ma 等提出的算法,利用无标记数据进行构造。为能够充分利用未标记的文本语料库,Ma 等提出一种可以有效降低两个任务阶段之间误差传播的去噪声数据增强方法。同时在表层实现模型的输入中随机增加或删除某个词以增加数据噪声。通过加入噪声并将这些数据作为对抗性的例子,可以有效地提高表面实现模型的鲁棒性。通过实验,该模型可以在只有1 000 个样本的情况下在传记生成数据集上取得27.34 BLEU[36]分数。
模型优点在于:利用少量数据即可训练出效果不错的模型。模型缺点在于:与使用大量数据训练所得的模型相比,表格信息抽取能力不够优秀,有待提升。模型结构如图6所示。

图6 以表格关键事实为中心模型Fig.6 Model centered on table key facts
3.3 表格三维层次编码器模型
表格所包含的信息十分复杂,表格也有不同维度。人在写表格的文本描述时,会从不同的维度展开。但是在以往的表格到文本的相关研究工作中,并没有按照这样的思路,仅仅将表格视作一维的序列记录。Gong等[32]发现这个问题并提出一种从三个维度对表格进行建模的模型。Gong 等认为,表格主要信息来源于行、列和时间三个维度,而不仅仅依赖于行这个单一维度。表格信息丰富,每一列都包含一种属性的信息,在人们的日常描述中,通常不会将所有数据全部描述出来,而是在一列中选择重要的数据进行描述。与此同时,表格属性在时间上有相关性,比如NBA 比赛数据、股市数据等,在对表格的描述中往往会将一个时间段上的信息进行横向对比,以获取时间维度上的信息变化。因此只有从更多维度去提取表格中的信息,模型才能有更好的表现。Gong等将表格到文本分成三个步骤:
首先是为更好地学习表格中单元格的信息,利用三种自注意力(self-attention)模型分别提取表单元格在行、列、时间三种维度的信息。例如对行的信息编码的计算方式如下所示:

然后利用记录融合门从三个维度的信息中提取出更为重要的信息,并将它们组合为稠密向量,其计算方式如下所示:

为获得某一行的表示,使用均值池化方法将同一行中的单元格转化为需要的表示,并利用内容选择门[33]来过滤掉不重要的信息。在解码阶段,因为编码器提供记录级和行级两种表示,所以使用双重注意力机制。生成单词时,模型首先选择重要的行,然后关注重要记录。Gong 等在NBA 篮球比赛的数据集RotoWire[12]上进行实验,实验结果表明该模型在BLEU分数上有显著提升,并且能提取列和时间维度上的信息,这是其他模型做不到的。
模型优点在于:能从多个维度充分抽取表格信息。模型缺点在于:生成文本描述时缺乏宏观的内容计划,长期内容排序能力不足。
3.4 表格内容选择与计划模型
尽管当前模型能够产生较为流畅的文本,但这些模型并不能很好地捕获到类似于人类写作中的长距离关系,这对模型生成长文本不利。神经文本生成技术在内容选择方面表现不佳,难以保持句间连贯,同时模型也不能很好地组织文本描述的行文顺序[12]。为应对以上这些问题,Puduppully 等[33]提出一种模型,不同于以往表格到文本的Seq-to-Seq模型直接将表编码后生成文本,该模型显式地建模内容选择和内容规划步骤,从而减轻模型的解码难度。内容选择和规划机制可以根据输入的表格内容产生内容计划。内容计划会指明表格中哪些记录需要详细描述而哪些信息无关紧要,同时指明重要信息按照什么顺序去组织。在文本生成阶段,使用双向LSTM模型将内容计划编码,并以此为解码器的输入,通过解码生成文本描述。同时模型拥有复制原文的能力,在每个时间步判断由模型生成新的词还是从源表中复制词。
一种明确的内容规划机制对于生成长文本有重要帮助,内容规划可以表示文本的高级结构。同时将复杂任务拆分成简单子任务也会降低模型训练难度。传统循环神经网络会生成重复的句子,但内容规划机制可以解决此问题。有宏观信息的指导,模型能清晰地聚焦于当前所需要生成的内容,降低产生冗余内容的可能性。清晰的结构也使模型生成文本的过程更有解释性。表格内容选择与计划模型在RotoWire 数据集上进行实验,利用自动评分和人工评估的实验表明,该模型能够改善RotoWire 数据集的模型最优水平。
模型优点在于:在文本结构组织、内容排序等方面表现优秀。模型缺点在于:需要更多细节导向的计划,对多个事实和实体的推断能力不强。模型结构如图7所示。

图7 表格内容选择与计划模型Fig.7 Table content selection and planning model
3.5 表格内容层次编解码模型
传统的表格到文本的任务通常采用序列到序列架构的编码器解码器模型,这给表格到文本模型提出两个挑战:如何更好地理解结构化的数据,如何生成表格对应的描述。传统的模型结构中,编码器将输入序列编码为固定大小的线性序列。这种将数据视作线性数据的方式会使得行与行之间的实体失去区别。而Liu等[37]提出对单实体结构进行提取。与此同时,大多数表格到文本的模型使用递归神经网络(RNN)作为编码器,但这需要将待输入元素按照顺序输入,这种数据输入方式在无形中对无序序列(即表格中的实体集合)做出了内部有顺的假设。Vinyals 等[38]证明,这种默认的假设对模型的学习成绩有显著影响。
为弥补上述两个问题,Rebuffel 等[11]提出分层的模型,通过分层编码器来捕获数据信息以及结构化信息。首先底层编码器会对所有单元格进行编码,接着高层编码器会对表结构进行编码。为了充分利用编码器的层次化结构,解码器端拥有两种不同的层次化注意力机制,以此来计算需要馈送给解码器的上下文向量。为避免对数据内部顺序进行假设,在表格到数据的模型中引入Transformer Encoder[39],以确保所有元素或实体无论它们位置在哪,模型对每个元素或实体都可以进行良好的编码。在解码阶段,Rebuffel等同样提出两种不同的层次化注意力机制。一种是关注整个表格的所有记录:首先处理实体,然后处理与这些实体相对应的记录。在描述一场比赛时,通常专家决定提到一个球员时都会自动地报告他的得分,而不考虑其具体的价值,因此诞生了另一种按键来引导的分层注意力机制:高层注意力机制仅仅关注记录键的表示,而不将注意力分散到整个记录表示。在RotoWire基准测试上的实验评估表明,该模型在BLEU得分方面有优秀表现。
模型优点在于:可以通过比较实体来实现自动推理和丰富描述等任务。模型缺点在于:可能导致错误的事实,内容排序等方面有待提高。模型结构如图8所示。
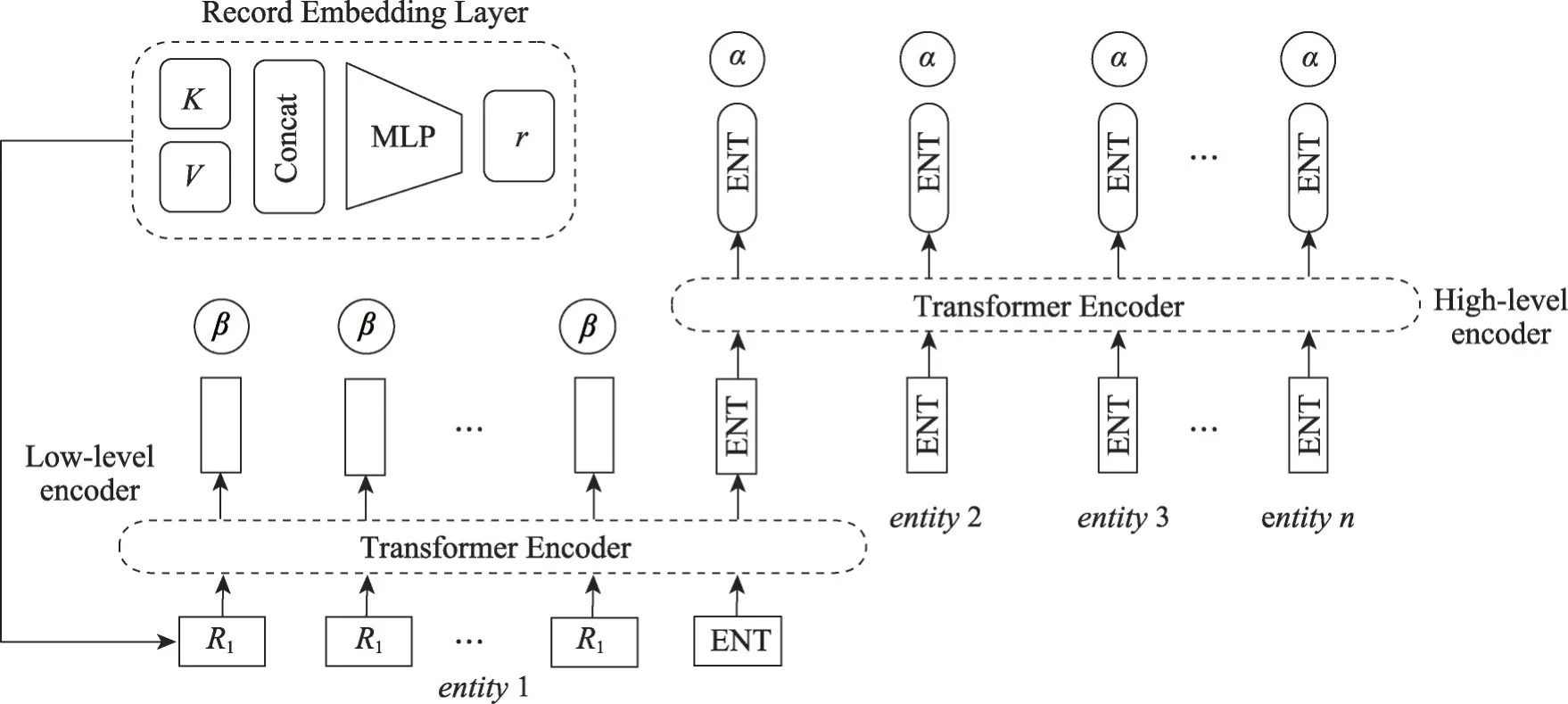
图8 表格内容层次编解码模型Fig.8 Table content level encoding and decoding model
3.6 表格显著内容选择、跟踪和生成模型
表格到文本的模型已经可以应用于天气、金融和体育等各个领域。这些模型在结构简单的短文本描述中有优秀的表现,但是在更加复杂的表格数据中生成长篇的文本描述仍具有挑战性。困难之一是输入的数据太大,朴素的模型无法找到它的显著部分,即确定应该描述数据哪一部分。此外,在描述表格数据时,显著部分[34]会移动,比如提到某位名人的事迹或是某位球员在比赛中的表现时,显著部分会移动。
现有的模型不能有效注意到显著性移动这一问题,导致在生成文本描述的过程中,会出现张冠李戴的现象。通过避免这样的错误并追踪显著性,来帮助模型生成质量更高、更可靠的文本描述。Iso 等提出的显著性追踪模型由两个模块组成,一个模块用于显著性追踪,另一个模块用于文本生成。跟踪模块会选择并跟踪表格中的显著性信息,并且当检测到显著性信息发生转变时,跟踪模块会选中相应的记录并且及时更新选择模块中的显著性状态变量。显著性转换计算公式如下:
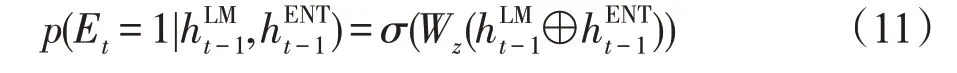
选择实体的概率公式如下:
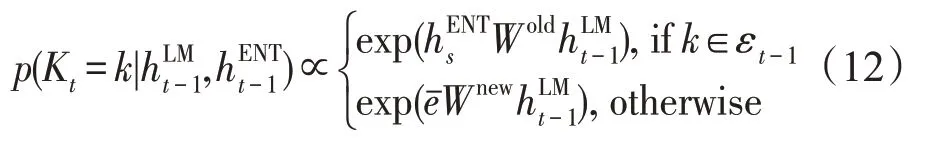
在生成文本时,模型聚焦于跟踪模块选中的文本,这样有指导信息的生成方式能降低模型生成难度。同时对于NBA 球赛这种表格中数字较多的数据,提出一种对数字的灵活表示方法。通过模型的学习,动态选择数字是用阿拉伯数字表示还是英语单词表示。
同时Iso等还讨论了作者信息对模型生成能力的影响。作者信息通常包括,作者在描述表格时,会选择哪些需要提及的数据记录,如何组织语言以及写作风格等。通过融入作者信息可以帮助模型生成高质量文本。在RotoWire-modified 数据集上,显著性追踪模型有优秀表现。
模型优点在于:充分抽取表格信息,准确描述表格重要信息。模型缺点在于:处理复杂语言表达时会出现错误(如平行结构),并且没有考虑表结构信息。
3.7 TableGPT模型
数据对于表格到文本领域的模型训练很重要,没有大量数据的支撑很难训练出能力优秀的模型。然而,在现实世界中收集所有领域的大规模标注数据集是不现实的。这就对模型在少样本情况下的训练提出更高的要求。最近,预训练模型在自然语言处理领域的各个研究方向均有优秀的表现。通过在大规模未标记的数据集上进行预训练,使得预训练模型获得语言知识[40-42]。并且预训练模型可以方便地应用于较少的数据进行微调,从而推广到下游任务,为少样本情况下的模型训练提供有效的帮助。虽然预训练模型有优点,但是在表格到文本领域利用预训练模型存在一些问题。首先,预训练模型GPT-2 的自然语言输入与表格到文本的结构化数据输入之间存在较大的差异。其次,表格信息不像自然语言输入是线性的,表格拥有丰富的结构化信息,而传统的预训练模型并没有对应方法去理解表格的结构化信息。此外,表格到文本领域模型有通病,模型会产生不符合表格信息的文本描述,俗称为“幻觉”。而预训练模型并不能解决这个问题。为缓解上述问题,Gong等提出TableGPT[35],它可以在少样本的情况下对表格到文本的模型进行训练。为应对自然语言的线性序列与结构化数据表格两种输入之间的差距,Gong等提出一种表格转换模块,即利用模板将结构化表格转化为自然语言。为应对表结构信息提取不充分的问题,在多任务学习框架下提出表结构重构的辅助任务。该任务要求GPT-2 在对结构化表格进行信息提取时,必须将结构化信息嵌入到表示向量中,重建分类器的计算细节如下所示:
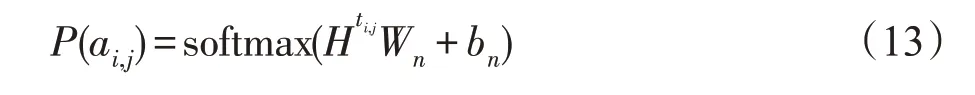
此外,为解决模型的“幻觉问题”,利用内容匹配任务来帮助模型通过最优传输(Chen等人)技术来正确地描述表格中的信息。该技术可以测量生成的文本信息与表格中的信息之间的距离,并将该距离作为惩罚加入到模型训练中,具体计算方法如下所示:

在人、书、歌曲三个数据集上的实验都表明[43],该模型在表格到文本的少样本情况下有优秀的表现。该模型优点在于:不需要大量数据且可以在多个领域中快速迁移。该模型缺点在于:文本描述的内容组织、宏观结构有待提高。
3.8 多分支表格信息解码器模型
使用基于深度学习的方法来解决DTG任务已使技术性能突飞猛进[12,30,33-44],训练所使用数据的质量直接决定模型的性能,因此研究人员往往使用大型语料库来训练模型并评估模型在不同任务上的表现。不过,这些大型语料库往往是通过从互联网上的资源以及程序来构建的。虽然互联网上的资源很容易获取,但包括不完全匹配的源目标对,模型的输出经常受到过度生成的影响[45-46],即训练实例中未对齐的有歧义片段,在推理过程中会导致类似的未对齐输出,即所谓的“幻觉”。实验调查显示,现实生活中DTG系统的最终用户,更关心可靠性而不是可读性,因此解决表格到文本模型的“幻觉”问题就变得至关重要[47]。
为解决“幻觉”问题,Rebuffel 等[48]提出一种多分支加权解码器,以及一种词级标注过程。这种词级标注过程通过依存分析,基于共现和句子结构以减少单词匹配过程的失败次数,同时仍然可以在复杂环境中产生正确标签。该多分支加权的解码器以对齐标签为指导,充当词级控制因子,在训练过程中该模型能够区分对齐和未对齐的单词,并学习生成准确的描述,而不会被不真实的参考信息误导。该模型在Wikibio数据集的实验上有优秀的表现。
该模型优点在于:多分支加权方法允许在推理时手动控制以此生成低“幻觉”文本。上述方法使得在噪声数据集上训练神经模型成为可能,而不需要手工制作数据。该模型缺点在于:生成长文本的流畅性有待提高。模型结构如图9所示。

图9 多分支表格信息解码器模型Fig.9 Multi-branch table information decoder model
4 评价方法
在自然语言生成领域,通过评测模型的生成结果可以反映出模型能力的好与坏,评测方法是模型训练的关键。在表格到文本生成领域常用的评价方法有:BLEU(bilingual evaluation understudy)、ROUGE(recall-oriented understudy for gisting evaluation)、关系生成(relation generation,RG)、内容选择(content selection,CS)、内容排序(content ordering,CO)。
4.1 BLEU
BLEU[36]得分是文本生成任务中常用的评价指标,在2002 年被提出。BLEU 以“生成文本与目标文本越接近,则生成文本质量越高”的核心思想来设计计算方法。它通过计算生成的候选句子和参考文本之间n-gram()n∈1,2,3,4 的共现次数来评估机器输出和人输出之间的对应关系。

BLEU 有便捷、快速等优点,是一种可以在模型训练中快速、准确给出评价的指标。但是,BLEU 并没有考虑语言表达的准确性,评价结果会受常用词干扰,生成短句的得分往往比长句高,并且没有考虑到词语的相似性以及同类型的表达方式。
4.2 ROUGE
ROUGE[49]是BLEU 的改进版,专注于召回率而非精度,在2004 年被提出。它会查看有多少个参考译句中的n元词组出现在输出之中,这样能知道模型生成的文本有多少出现在参考文本中,有没有缺失信息。
ROUGE 基于模型输出和参考文本之间的最长公共子序列(longest common subsequence,LCS),其中公共子序列要求相同顺序的词,但允许在任一序列的中间添加其他未覆盖的词。最终ROUGE-L 评分是F 度量(F-measure),基于在任何参考文本上达到的最大精度和最大召回率。其中准确率、召回率计算为LCS 的长度除以系统输出和引用的长度。ROUGE大致分为以下四种,常用的是前两种。
4.2.1 ROUGE-N
ROUGE-N 将BLEU 的精确率优化为召回率,最基本的ROUGE的计算方法如下:

其中,分母是n-gram的个数,分子是参考文本和自动生成文本公有的n-gram的个数。
4.2.2 ROUGE-L
ROUGE-L 将BLEU 的n-gram优化为公共子序列,ROUGE-L计算方法如下:

其中,LCS(X,Y)是X和Y的最长公共子序列的长度,m、n分别表示参考文本和模型生成文本的长度,Rcls、Plcs分别表示召回率和精确率(下文同理)。
4.2.3 ROUGE-W
ROUGE-W为改进基本的LCS方法,通过记住到目前为止所遇到的连续匹配的子序列长度来计算加权最长公共子序列(weighted longest common subsequence,WLCS)。ROUGE-W的计算方法如下:
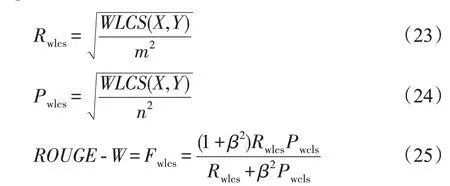
4.2.4 ROUGE-S
ROUGE-S在参考文本和模型生成文本进行匹配时,不要求n-gram之间必须是连续的,可以“跳过”几个单词。ROUGE-S的计算方法如下:

其中,SKIP2(X,Y)是X和Y之间跳跃双字节匹配的次数,β控制Rskip2和Pskip2的相对重要性,C是组合函数,例如C(4,2)=6。
虽然ROUGE 指标改进了上面提到的BLEU 的缺点,就是不考虑语言表达(语法)上的准确性,测评精度会受常用词的干扰,但是ROUGE指标无法评价模型生成文本的流畅性。
4.3 抽取评价
BLEU 可能是评估短文本生成的一种相当有效的方法,但研究人员发现它在长文本生成方面并不令人满意。并且它主要奖励流畅的文本生成,而不是鼓励捕获表格中最重要信息,也不是鼓励以特别连贯的方式描述信息[12]。因此在2017 年,研究人员提出以下三种指标来更好地评价表格到文本生成模型的能力好坏。
4.3.1 关系生成
关系生成(RG)[12]鼓励系统更好地生成包含正确信息的文本。该方法通过测量,得到同时出现在生成文本和表格s中的关系r的精度和绝对分数,分别表示为RG-P和RG-Count。
4.3.2 内容选择
内容选择(CS)[12]根据提到的表格信息衡量生成的文本与参考文本的匹配程度。测量从生成文本中提取的唯一关系r的精确度和召回率,分别表示为CSP和CS-R,其中唯一关系r也是从y1:t中提取的。
4.3.3 内容排序
内容排序(CO)[12]通过分析生成文本中表格信息的排序情况,测量从生成文本提取的信息序列与从参考文本y1:t提取的信息序列之间的归一化Damerau-Levenshtein距离[50]。
5 实验
接下来介绍RotoWire、Wikibio数据集,以及前面提到的模型在这些数据集上的实验结果。
5.1 RotoWire的实验结果对比
本节在RotoWire[12]上训练和评估文中介绍的模型。RotoWire 是篮球比赛总结的数据集,配有相应的框和行得分表,摘要写得很专业,结构也比较好,长度也比较长(平均337 个单词)。记录类型的数量为39 个,记录的平均数量为628 个,词汇表大小为1.13×104个单词,token 计数为1.6×106。数据集非常适合文档规模的生成。
实验结果如表1 所示[11-12,33,51]。其中Hierarchical Transformer对应于表格内容层次编解码模型;NCP+CC 对应于表格内容选择与计划模型;Three Dimensions Encoder 对应于表格三维层次编码器模型;STG 对应于表格显著内容选择、跟踪和生成模型。其中Count 表示计数、P 表示精确度、R 表示召回率、DLD表示Damerau-Levenshtein距离。
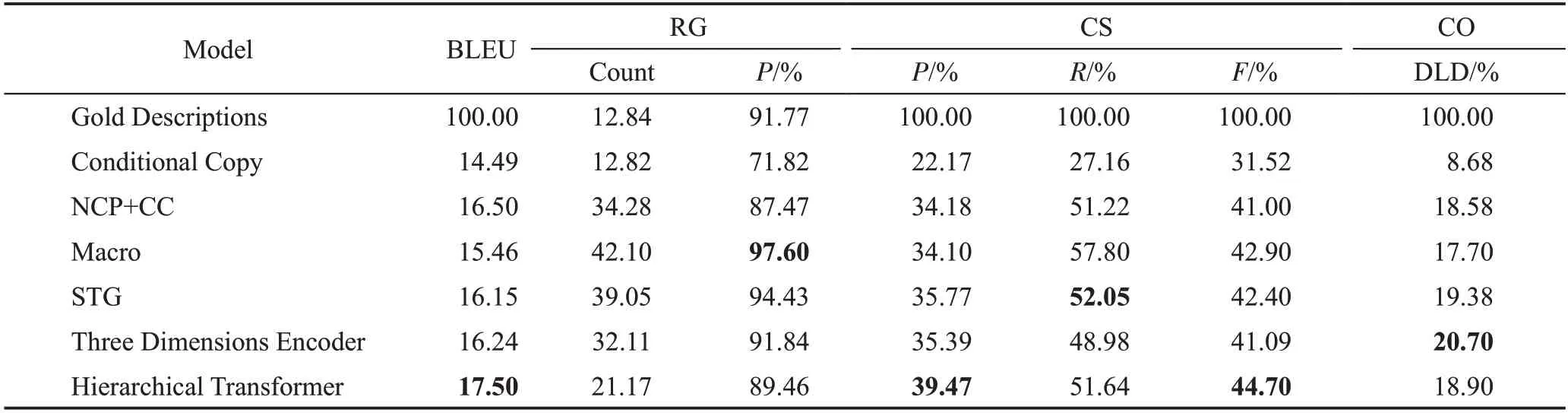
表1 RotoWire实验结果Table 1 Experiment results of RotoWire
5.1.1 各模型特点
(1)表格内容层次编解码模型(Hierarchical Transformer)获得最高的BLEU 评分,但是RG-Count 等指标表现一般,即关系生成的能力有待提高。这是因为该模型没有内容计划等组件,在生成文本时模型不能有效组织文本内容及结构。
(2)表格显著内容选择、跟踪和生成模型(select,track and generate model,STG)在关系生成方面表现得很好,获得了最高的评分。这归功于显著性追踪模块能够辨别显著性内容以及显著性何时转移,这对关系生成十分重要。
(3)表格三维层次编码器模型(Three Dimensions Encoder)整体表现优秀,从多个维度抽取表格信息这是其他模型所没有的优势,同时解码器的双重注意力机制能保证优秀的生成效果。并且三个维度的信息抽取,使得模型生成的文本包含更加丰富多样的信息。
(4)表格内容选择与计划模型(NCP+CC)的内容选择能力十分优秀。因为该模型显示建模内容选择以及文本计划机制,在模型生成文本时指导模型选择正确的内容信息。
5.1.2 性能分析比较
(1)BLEU
内容层次编解码模型的BLEU得分最高,这相较于非层次化模型,层次化模型有更优秀的编码能力,可以生成更流畅的文本描述。值得注意的是,内容层次编解码模型性能优于内容选择与计划模型(NCP+CC),这表明在编码过程中,通过模型去捕获表格结构信息比预测文本计划来指导文本生成更有效。
(2)关系生成(RG)
模型需要理解表格内容以及结构化信息,从而生成正确的事件、关系描述。显著内容选择、跟踪和生成模型(STG)和宏观计划模型(Macro)在关系生成方面都有着非常优秀的表现,这得益于这两个模型有着从宏观角度观察表格、生成文本的能力。在描述表格数据时,显著部分[34]会移动,比如提到某位名人事迹或是某位球员在比赛中的表现时,显著部分会移动。一般的模型很难捕获显著部分的移动,而表格显著内容选择、跟踪和生成模型通过显著内容追踪机制提取了这种信息,从而在关系生成方面有着优秀的表现。宏观计划模型有着另一种思路,该模型使用先生成宏观计划再生成具体内容的两步策略,这种任务的解耦合降低了任务难度,使模型可以更容易地生成宏观计划,以此指导模型文本生成过程,并促进了正确关系的生成。
(3)内容选择(CS)
在内容选择方面,不同模型各具特色。三维层次编码器模型通过多个维度观察表格,可以抽取到行、列和时间三个维度的信息,这种机制更贴近人类的书写习惯,也使得生成的文本描述有更丰富的信息。层次化模型通过层次化编码机制,从表格中抽取了更多的信息。同时该模型编码器部分使用Transformer 而不是RNN,Transformer 通过直接比较表格信息之间的关系,避免了RNN 对输入元素顺序的假设,这有利于模型提取正确信息,从而选择正确的表格内容。显著内容选择、跟踪和生成模型通过其独特的显著内容追踪机制,在显著内容发生转变时,能及时感知并选择新的显著内容,这使得对内容选择能力有不小提升。
(4)内容排序(CO)
尽管模型可以生成流畅的文本描述,但文本内容的排序可能并不合理。三维层次编码器模型有着优秀的内容排序能力。该模型有行级编码器,可以从更高层次看待表格数据,解码器生成每个单词时,首先选择重要的行再选择记录,这样的机制对内容排序有着指导意义。显著内容选择、跟踪和生成模型在内容排序方面同样有着优秀表现。该模型在生成文本的同时动态更新显著内容编码信息,这有利于模型产生更好的内容排序。
5.1.3 层次化模型分析比较
将非层次化模型(Flat)、内容层次编解码模型-k(Hierarchical Transformer-k)和内容层次编解码模型-kv(Hierarchical Transformer-kv)进行对比,结果如表2 所示。与其他模型相比,非层次化模型的得分较低,这证明了分层编码器对表格数据结构进行编码的有效性。这是因为非层次化模型在编码过程中丢失了区别不同实体的边界信息,所以非层次化编码器很难对存在多个实体的表格进行有效编码。
内容层次编解码模型-kv是指在解码时模型的注意力关注每一个记录。内容层次编解码模型-k是指在解码时模型仅关注每一个实体(一个实体有多个记录信息),即模仿人类书写习惯:以人为单位,提到某人时会自动报告其比赛得分,这种宏观角度的注意力机制使得该模型有着更好的内容选择能力。
将三维层次编码器模型中的三维编码器分别替换为LSTM、CNN、Self-Attention、Transformer 进行对比,结果如表2所示。可以发现没有三维层次编码器的帮助,所有层次化模型的表现都不好。为了评估该模型每一个组件的贡献,分别将行、列、时间等单维编码器从模型中移除,所有不完整的模型表现都变差,这说明三个维度的信息和记录融合门都非常重要。同时位置编码也非常重要,它保证了模型能够提取表格结构信息。结果表明,该模型中每一个组件对整体性能都有贡献。

表2 层次化模型实验结果对比Table 2 Comparison of experiment results of hierarchical models
5.1.4 内容选择模型分析比较
将表格内容选择与计划模型(neural content selection and planning model,NCP)、编码器-解码器模型(encoder-decoder,ED)分别结合联合拷贝(joint copy,JC)、条件拷贝(conditional copy,CC)进行实验比较,结果如表3 所示。其中w是作者信息。表格内容选择与计划模型与两种复制机制的结合都比普通编码器-解码器模型优秀。表格内容选择与计划模型与条件拷贝相结合(NCP+CC)的整体表现最优,其生成的文本最流畅。该模型相较于编码器-解码器模型(ED+CC)性能有着不小提升,尤其在内容选择方面提升最多,这表明内容选择与计划机制有利于提升内容选择能力。

表3 内容选择模型实验结果对比Table 3 Comparison of experiment results of content selection models
相较于表格内容选择与计划模型,表格显著内容选择、跟踪和生成模型(STG)在关系生成方面性能提升最多。该模型在文本生成过程中通过追踪显著内容的变化情况,动态更新编码信息,在关系生成方面这种机制比模型直接预测文本计划更有指导意义。
5.2 Wikibio的实验结果对比
Wikibio数据集包含来自英国维基百科的728 321篇文章,分为3个子部分,分别提供582 659个训练实例、72 831个验证实例和72 831个测试实例。它使用每篇文章的第一个句子作为相关信息框的描述。该数据集有数据量较大、词汇丰富等特点。每个描述中平均有26.1个单词,表中也出现9.5个单词。表格中平均包含53.1 字和19.7 个属性。实验结果如表4所示[30,44,48]。其中Structure-aware Seq2seq对应于表格结构感知模型,MBD 对应于多分支表格信息解码器模型。

表4 Wikibio实验结果Table 4 Experiment results of Wikibio
5.2.1 各模型特点
(1)表格结构感知模型表现最好,BLEU 和ROUGE两项指标都取得最高分,这归功于表内容信息、表结构信息的充分抽取,并在解码阶段使用双重注意力机制确保生成文本的高质量。但是由于数据噪声,该模型生成的文本存在“幻觉”问题。
(2)多分支表格信息解码器模型(multi-branch decoder,MBD)虽然得分低于表格结构感知模型,但是由于词级标注过程,模型在训练过程中不会受到未对齐数据的影响,有效改善了“幻觉”问题。
5.2.2 性能分析比较
(1)BLEU
表格结构感知模型在BLEU指标中得分最高,这归功于该模型的表格结构感知编码器。传统的方法只是简单地将表格词编码与表格字段编码做拼接,再一起输入给编码器进行编码,这种方式忽略了表格的结构信息,使得模型无法有效地对表格进行编码。表格结构感知编码器通过在LSTM中加入字段控制门,以此对记忆单元的内容以及何时更新进行有效控制,这种机制有助于模型理解表格的结构信息,从而提高模型生成文本的质量。
(2)ROUGE
表格结构感知模型生成的文本与参考文本最相似,这得益于双重注意力机制。该机制中词级注意力关注表格记录之间的关系,字段级注意力对模型生成的描述和表格记录的信息相关性进行编码。词级注意力和字段级注意力的聚合可以在表格内容与其模型生成的描述间建立更精确的联系,这保证了模型生成高质量文本描述。
5.2.3 “幻觉”情况分析比较
由于数据集通过程序在互联网中收集整理而成,数据中存在未对齐的表格-文本对。这样的噪声将对模型训练产生影响,导致模型生成表格未提及的内容,俗称“幻觉”。即使是表现优秀的表格结构感知模型也会出现“幻觉”。
将标准编码器-解码器模型(Stnd)、多分支编码器解码器模型(Hsmm)、分层模型(Hier)、多分支表格信息解码器模型(MBD)进行对比,结果如表5 所示。可以发现,除了多分支表格信息解码器模型,唯一幻觉率较低的模型(Stnd_filtered),其使用的训练数据是按照幻觉分数清洗后的数据,获取这样的数据成本较高。

表5 “幻觉”情况实验结果对比Table 5 Comparison of experiment results of“hallucination”
在一般的数据集中进行训练,其他模型很难避免“幻觉”问题。而多分支表格信息解码器模型可以很好地应对这一问题。利用解码器中内容、幻想和流畅度三个分支,实现对文本描述三种要素的控制,并且可以手动设置不同分支的权重以达到降低幻觉的目的,因此多分支表格信息解码器模型可以生成幻觉率极低并且十分流畅的文本。
6 目前挑战和未来发展趋势
6.1 主要的挑战分析
(1)内容选择。结构复杂的表格中存在多种属性,每种属性有多个值,并且表格在不同维度均含有信息,模型不能有效理解表结构及其内容,这给模型生成文本描述带来困扰。
(2)内容排序。当模型生成文本时,没有优秀的机制去引导模型描述什么,按照什么顺序描述。导致模型尽管可以生成流畅的文本,但很难保持句间连贯,生成文本的排序也不恰当。
(3)“幻觉”问题。当前数据集中存在不完全对齐的表格-文本对,这导致即使最优模型也会出现脱离表格内容的文本描述,俗称“幻觉”。
(4)理解表格中的数字。许多数据集(如Roto-Wire)中存在大量数字,普通embedding 方法无法表示这些数字在表格中的含义,因此模型很难理解表格中的数字。
6.2 未来发展趋势
(1)高效的表格编码器。目前已有多种对表格编码的方式,它们分别针对于内容选择、内容排序等问题,但都有局限性,不能全方位提取表格信息。因此如何全面地理解表格结构、理解表格中的数字、抽取表格多维信息,还有较大的研究空间。
(2)使用预训练模型。由于预训练模型输入与表格到文本输入之间存在较大差异,在该领域应用预训练模型十分困难。但是预训练模型有着丰富的语言知识,使用价值极高。因此如何转换表格输入形式,表示表格结构信息,从而高效使用预训练模型是未来研究中急需解决的问题。
(3)提高文本描述准确性。对于文本描述,用户更关心其信息的准确性,因此如何最大程度减少“幻觉”文本的出现是未来研究重点之一。
(4)构建高质量数据集。现有数据集主要是通过程序在互联网中收集整理而成,因此存在较大的噪声。表格到文本生成领域的研究需要更加干净的数据集来减少噪声对模型训练的影响。
7 总结
本文描述了表格到文本的任务背景、任务难点以及主流研究方法。同时介绍了表格结构感知模型等表现优秀的表格到文本生成新模型,这些模型在主流数据集上进行的实验中表现优秀。与此同时,还介绍了表格到文本领域较为通用的评价方法,如BLEU、ROUGE等。对各种先进的模型在Wikibio和RotoWire 等公用数据集上的实验结果进行了比较与分析,并分析了各模型在不同指标下的优势与劣势。最后总结了该领域目前的挑战并展望了未来的发展趋势。
