手语识别与翻译综述
2022-11-15闫思伊薛万利袁甜甜
闫思伊,薛万利+,袁甜甜
1.天津理工大学 计算机科学与工程学院,天津300384
2.天津理工大学 聋人工学院,天津300384
根据全国第二次残疾人抽样调查,目前我国听障人数接近3 000 万,是国内最大数量的残障群体,手语是听障人士交流表达的主要手段。无障碍沟通是广大听障人群打破信息孤岛、进行平等社会交流的重要途径[1]。实现听障人士无障碍沟通的主要需求是健听人士能够知晓听障人的手语表达。随着人工智能技术的发展特别是计算机视觉研究与自然语言处理研究的进步,使得这一需求的实现成为可能。手语识别与翻译研究正是为实现上述需求的具体研究任务。如图1所示,手语识别是指将手语视频中所做手语动作对应的文字注释(Gloss)顺序地识别出来,而手语翻译是指将对应的手语视频直接翻译为健听人交流时所用的自然口语语句。
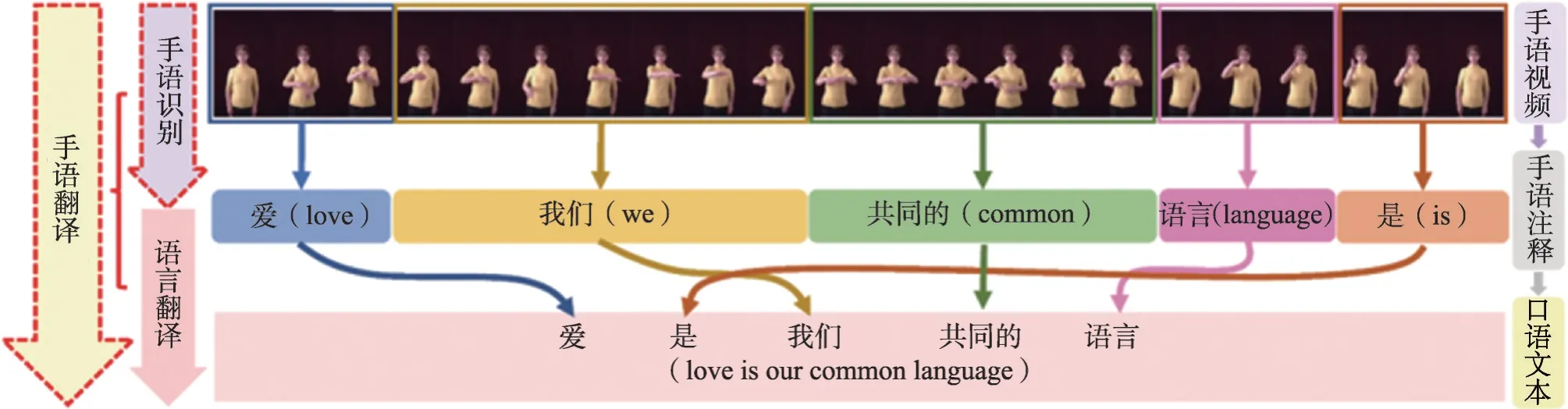
图1 手语识别和翻译流程Fig.1 Pipeline of sign language recognition and translation
手语识别和翻译研究主要包括视觉感知和语言理解两部分:基于计算机视觉技术感知手语视频图像对应深层特征;基于自然语言处理理解手语视频对应文本信息。这种基于感知和理解的研究思路,更接近人的思考过程。
当前,对于手语识别与翻译的研究主要集中在手语识别任务。手语识别的目标是将手语视频自动翻译成相应的手语注释。根据所使用的数据集不同,手语识别可以细分为孤立词手语识别和连续手语词识别[2]。
孤立词手语识别是一种细粒度的动作识别,每个视频只对应一个手语的注释[3-8]。孤立词手语识别的主流方案是将整个句子分割成若干手势片段,再进行单独识别[9]。孤立词手语识别主要关注对注释场景的分割,方法上更类似于动作识别研究。为了避免像孤立词手语识别一样,需要大量人力对手语视频中的手语手势进行分割,因此,引入连续手语识别研究。
连续手语识别是指将一个手语视频,在弱监督的情况下(只进行句子级别的标注而非帧级标注),映射为一个注释序列(gloss sequence),且该注释序列中Gloss顺序与视频中对应的手势片段的顺序一致,即符合手语语法的文本序列。相较于孤立词手语识别,连续手语识别不再需要对手语视频中的手势片段进行繁重的人为分割。
基于自然语言发展而来的手语,其目的是快速便捷地利用肢体动作、面部表情等进行交流,因而形成一套独特的语法规则。通常,一段手语视频对应听障人士表达的文本序列会和对应的听障人士理解的自然语言序列存在差异性。为了便于健听人群对手语的理解,需要对手语视频进行翻译研究以得到对应的呈现口语化的自然语言文本序列,这一过程就是手语翻译研究。手语翻译研究的目标是从连续手语视频中提取对应的符合自然语言语法规则的文本表达。因此,手语翻译研究任务需要结合计算机视觉感知和自然语言处理理解。根据不同研究范式,手语翻译框架可分为:手语视频到文本(sign2-text,S2T)和手语视频到注释到文本(sign2gloss2text,S2G2T)。S2T是将连续的手语视频直接翻译成口语句子,而S2G2T 利用连续手语识别模型从手语视频中提取注释序列,然后通过一个预训练的Gloss2Text网络来解决手语序列(sign sequence)到自然语言文本的翻译[10]。
当前,在手语识别与翻译方面的综述,国外具有代表性的工作,如2020年Koller[11]对使用德国手语数据集的相关研究工作进行综述报告,该综述涵盖从1983 年至2020 年约300 项工作,并对其中约25 项研究进行了深入分析。但报告仅对RWTH-PHOENIXWEATHER-2014[12]数据集上的研究工作进行总结,缺乏基于其他数据集的研究工作介绍。国内相关手语识别与研究方面的综述则更多关注手语识别方面[13-15]。为了便于研究者对手语识别与翻译、主流手语数据集及评测指标等方面进行快速全面的了解,本文对当前主流手语识别和翻译研究进行了详细的概括和总结。
1 手语识别和翻译研究工作总结
本章将分别从手语识别研究和手语翻译研究两方面进行相关工作总结。其中,手语识别研究将进一步细分为孤立词手语识别和连续手语识别;手语翻译研究将从手语视频到文本和手语视频到注释到文本两个分支进行简单介绍。
1.1 手语识别研究任务
手语识别框架通常包括视觉特征提取、识别模型两部分。前者用于手语视频的高维特征描述,后者则通过对齐约束提升模型的泛化能力。下面将分别从孤立词手语识别和连续手语识别两方面对当前主流研究方法进行总结。
1.1.1 孤立词手语识别
(1)基于非深度学习的视觉特征的孤立词手语识别
视觉特征提取是手语识别研究的关键。早期的孤立词手语识别研究,在视觉特征提取时以非深度学习的手工特征为主。例如,以手部形状特征作为视觉特征[16]。基于手形的方法可以反映相对简单的手势的含义,但无法应对复杂连贯手语视频下的手语识别任务。
为了解决具有连贯动作的孤立词手语识别,一些研究诸如,尺度不变特征转换(scale-invariant feature transform,SIFT)[17]、方向梯度直方图(histogram of oriented gradient,HOG)[18]、时空关键点(spatial temporal interesting points,STIPs)[19]和内核描述符[20]等二维特征描述子进行视觉特征提取。但特征仅在目标单一且清晰的情况下才能表现出良好的识别性能。为了解决手语视频中的手势遮挡挑战,研究者们提出了3D/4D 时间空间特征[21]和随机占用模式特征[22]。进一步,为了解决深度图中存在的噪声和遮挡问题,Miranda等人[23]使用时空占用模式[24]来表征人类手势的四维时空模式,以充分利用空间和时间的背景信息,同时允许类内多样性。Zhang等人[25]提出了一种基于隐马尔可夫模型轨迹建模的孤立词手语识别方法,重点设计了一种新的基于形状上下文的曲线特征描述符。
为了提升孤立词手语识别的鲁棒性,Yin 等人[26]设置了包含一组手语引用和相应的距离度量的鲁棒性模型。Zheng 等人[27]提出一种基于三维运动图的面向梯度金字塔直方图的描述子来识别人体手势的深度图,该描述子能够在不同空间网格大小下刻画局部信息。
在基于非深度学习的特征的孤立词手语识别研究中,在识别方案部分,通常采用的方法有模板匹配、字典学习、视觉词袋[28-29]、条件随机场[30]、随机森林[31]、支持向量机[32]和隐马尔可夫模型[33]等。支持向量机[34]由于具备较好的预测泛化能力而受到研究者的关注[35]。Pu 等人[36]将两种模态的手语视觉特征融合并输入到支持向量机分类器中进行训练。Kumar[37]通过离散小波变换提取手工特征经过处理后采用支持向量机进行分类。隐马尔可夫模型其变体在手语识别研究中同样得到广泛的应用。例如,Guo等人[38]利用隐马尔可夫模型状态自适应方法,建立每个手语词的学习模型。
(2)基于深度学习的视觉特征的孤立词手语识别
由于非深度学习的特征不能很好地适应手语复杂动态的手势及其他关键身体部位的变化,一些研究者采用深度学习的视觉特征进行孤立词手语识别中的视觉特征建模。考虑到长短时记忆网络能够很好地对时间序列的上下文信息进行建模,Liu 等人[39]提出了一种端到端的长短时记忆网络孤立词手语识别方案。Hu 等人[40]利用深度残差网络(deep residual network,ResNet)提取视觉特征信息,并进行全局与局部增强。Huang等人[2]提出一种基于注意力模型的三维卷积神经网络用于刻画手语视频的时空特征。Wang等人[41]融合二维和一维深度学习模型提取视频帧中的时空特征。Hu等人[42]在手部深度学习的特征模型中引入手部先验信息,提供从语义特征到紧凑手部姿态表示的映射。特别的,Wu 等人[43]提出一种通用的半监督分层动态框架用于手势分割和识别,将骨架特征和深度图像作为输入,利用学习后的隐马尔可夫模型进行推断。
1.1.2 连续手语识别
与孤立词手语识别相比,连续手语识别由于更复杂的手势动作、更长的视频序列表达而更具挑战性。早期的连续手语识别方法,主要基于孤立词手语识别展开研究[44]。例如,部分研究利用视频分割算法,将连续视频序列分割成若干视频片段,然后采用孤立词手语识别方法进行识别并整合[45]。
(1)基于卷积神经网络的连续手语识别
受益于深度神经网络在视频表示学习中的发展,基于深度学习的视觉特征的连续手语识别逐渐成为主流[46]。Wei等人[46]提出了一种基于循环卷积神经网络框架的多尺度感知策略,用于学习手语视频的高维特征表示。针对连续手语识别研究中的弱监督问题,Koller等人[47]通过在迭代算法中嵌入卷积神经网络,利用其更好的描述能力辅助细化帧级标注进而提升模型训练精度。文献[48]则将卷积神经网络嵌入到隐马尔可夫模型框架中。Li 等人[49]使用一个去除最后的全连通层的ResNet-152 网络来提取任意长度视频的高维视觉特征。Cheng 等人[50]提出了一种用于在线手语识别的全卷积网络用于学习视频序列的时空特征。随着三维卷积神经网络在动作识别任务中的广泛应用[51-54],Zhao等人[55]提出了一种结合光流处理的三维卷积神经网络方法来提升识别精度。Liao等人[56]基于B3D-ResNet执行长期时空特征提取的任务。Yang等人[57]提出了一种结构化特征网络(structured feature network,SF-Net),通过长短时记忆网络与三维卷积神经网络在帧级的组合创建一个有效的时间建模架构。为了更好地对齐视频片段和文本注释,Pu等人[58]引入软动态时间翘曲(soft dynamic time warpping,soft-DTW)算法,提出了一种新的基于3D-ResNet 和编码-解码器的网络结构,在soft-DTW的作用下,3D-ResNet特征提取器和编码器-解码器序列建模网络逐步交替优化。
(2)基于循环卷积神经网络的连续手语识别
循环卷积神经网络被广泛应用于处理序列建模问题,如长短期记忆网络(long short-term memory,LSTM)[59]、双向长短期记忆网络(bi-directional long short-term memory,Bi-LSTM)[60]、门控循环单元网络[61]等。在连续手语识别中,通常结合循环卷积神经网络与隐马尔可夫模型,由于隐马尔可夫模型需要计算先验估计,文献[62-64]尝试用连接主义时态分类(connectionist temporal classification,CTC)方法[64-65]把路径选择的问题归纳为最大后验估计问题,通过引入空白类和映射法则模拟了动态规划的过程,从而缓解输入序列和输出序列的对应难的问题。Wang等人[66]提出了一种由时域卷积模块、双向门控循环单元模块和融合层模块组成的混合深度学习结构进行特征的连接融合。Xiao 等人[67]将长短期记忆网络与注意力网络融合进行连续手语识别。
(3)基于Transformer的连续手语识别
Transformer[68]作为一种领先的深层级网络特征提取模型被广泛应用于自然语言处理、计算机视觉和语音处理等领域。在连续手语识别研究中,Tunga等人[69]利用图卷积网络对手语演示者身体部位的关键点之间的空间关系进行编码,进而挖掘帧间的时间依赖关系。Niu等人[70]使用二维卷积神经网络提取视频序列的空间特征,用Transformer 编码器来提取时序特征。Varol 等人[71]利用预训练的I3D 模型通过滑动窗口提取时空视觉特征。然后训练一个2 层Transformer模型进行手语识别。Zhang等人[72]将Transformer与强化学习相结合进行连续手语识别。Yin等人[73]提出了一种基于编码器-解码器架构的轻量级手语翻译模型SF-Transformer用来识别手语。
(4)基于多线索协同的连续手语识别
手语在传递信息、表达思想时,通常以手势动作配合脸部表情及身体姿势进行综合表达。因此,可以简单地认为,在手语识别研究中,其所表达的含义可以由多种线索共同作用[74]。Zhou 等人[74]结合基于视频的手语理解与多线索学习,提出一种时空多线索网络来解决基于视觉的序列学习问题,其中空间多线索通过姿态估计分支学习不同线索的空间表示,时间多线索则分别从线索内及线索外两个角度对时间相关性进行建模获得线索间的协作关系。
在手语识别研究中,一般将不同的信息来源定义为不同模态,例如图像特征、文本特征和利用图卷积网络(graph convolutional networks,GCN)提取的骨架特征就是不同种模态。从多模态中学习各个模态的信息,并且实现各个模态的信息的交流和转换。Papastratis等人[75]提出利用文本信息来改进视觉特征进行连续手语的跨模态学习,模型最初使用两个强大的编码网络来生成视频和文本的特征,再将它们映射和对齐到联合潜在特征中,最后使用联合训练的解码器对处理后的视频特征进行分类。Gao等人[76]设计了一种视频序列特征和语言特征多模态融合的手语识别系统。Huang等人[5]基于双流结构从视频中提取时空特征,其中高层流用于提取全局的信息,低层流更关注局部的手势。
1.2 手语翻译研究任务
手语作为一门特殊的语言体系,拥有一套区别于其他语言的语法规则。为了让健听人士能够高效、准确地理解听障人士演示的手语,则需要利用手语翻译研究将手语视频翻译成口语化的句子。
1.2.1 手语视频到文本的手语翻译
手语翻译的目的是从执行连续手语的人的视频中提取等效的口语句子。因此,一种研究方案是直接将手语视频翻译成文本,即S2T[77]。Camgoz等人[77]提出Sign2Text模型,使用基于注意力的编码器-解码器模型来学习如何从空间表征或手语注释中进行翻译。Guo 等人[78]建立了一种面向手语翻译的高级视觉语义嵌入模型。Li 等人[79]提出一种考虑多粒度的时间标识视频片段表示方法,减轻了对精确视频分割的需求。虽然Sign2Text 结构简化了手语翻译模型,但容易出现模型的长期依赖问题。且受制于当前技术及数据的制约,当前手语视频到文本的翻译在没有任何明确的中间监督的情况下很难获得较好的效果。考虑到手语注释的数量远低于其所代表的视频帧的数量,另一些研究者开始引入手语注释作为中间标记,设计了手语到注释到文本的手语翻译(S2G2T)。
1.2.2 手语视频到注释到文本的手语翻译
在基于手语视频到注释到文本的手语翻译范式中,手语翻译过程被分为两个阶段[80]:第一阶段将手语识别视为一个中间标记化组件,该组件从视频中提取手语注释;第二阶段是语言翻译任务,将手语注释映射为口语文本。
在Sign2Gloss2Text 的手语翻译研究中,典型的工作包括:受手语翻译数据集规模限制,Chen等人[80]将手语翻译过程分解为视觉任务和语言任务,提出一种视觉-语言映射器来连接两者,这种解耦使得视觉网络和语言网络在联合训练前能进行独立的预训练。Camgoz 等人[81]通过在手语翻译中利用Transformer 融合手工和非手工特征进行手语翻译。Fang等人[82]将手语翻译模型嵌入可穿戴设备。Yin等人[83]基于文献[74]将预训练的词表达嵌入至解码器用于手语翻译。Zhou等人[84]使用文本到注释翻译模型将大量的口语文本整合到手语翻译训练中。Camgoz等人[10]将手语识别和口语翻译的任务整合成一个统一的网络结构进行联合优化。为了实现实时手语翻译,Yin等人[85]基于Transformer设计了一个端到端的手语同步翻译模型,并且提出一种新的重编码方法来增强编码器的特征表达能力。
基于手语视频到注释到文本的手语翻译是目前使用较多的手语翻译范式。但是,一方面手语注释是语言模态的离散表示,若注释遗漏、误译部分信息,很大程度上会影响翻译结果;另一方面,如何确保两个阶段在翻译过程中的高效配合也是手语翻译的难点之一。
2 数据集与评价指标介绍
2.1 数据集介绍
2.1.1 数据采集方式简介
早期手语数据采集主要使用手部建模设备,如数据手套等,来进行数据收集。利用手语演示者的手型、手部运动的轨迹和手部的三维空间位置信息来描述手势变化的过程。Gao 等人[86]利用数据手套将采集到的手势数据输入到特征提取模块,模块输出的特征向量输入到快速匹配模块生成候选单词列表。
然而,手部建模设备不仅价格昂贵并且不易携带,因此一些研究人员开始简化或消除设备上复杂传感器,并在不同的设备部位使用不同的颜色标记进行数据采集。如Iwai 等人[87]利用颜色手套获取手部实时位置和形状。但是,使用颜色手套进行数据采集时对手语演示者的着装、环境等要求较高,否则容易引起数据偏差。
为了更好地方便手语者演示手语,一些研究者通过采用非接触式传感设备来获取手部的运动轨迹信息。如文献[88]使用RealSense技术将手掌方向和手指关节的数据作为识别模型的输入。但是,手语是一种结合手势变换、脸部表情、身体姿态等多因素综合作用的语言体系,仅只关注手部信息是不够的。因此,研究者们开始转向基于视觉特征的手语识别与翻译研究。
在采用视觉特征的手语识别与翻译研究方法中,由摄像机得到手语演示者的彩色图像并做相应的图像处理,将其用作手语识别模拟的输入数据。不仅如此,一些其他模态的手语信息也受到关注[89],例如体感摄像机,以便同时获取视觉图像信息、深度信息、骨架信息等。总的来说,相较于基于非视觉的采集方式而言,基于视觉的采集方式,具备成本低、采集方便、设备依赖度低等优势,同时在特征处理、算法模型上更具挑战性。
2.1.2 公共数据集简要分析
手语数据集可以大致分为孤立词手语数据集和连续手语数据集。孤立词手语数据集主要用于孤立词手语识别研究,由较短的手语单词视频构成。而连续手语数据集主要用于连续手语识别与手语翻译研究任务,由较长的手语句子视频组成。表1列举了部分手语数据集。

表1 手语数据集总结Table 1 Summary of sign language datasets
其中,目前使用较多的公共手语数据主要包括:RWTH-PHOENIX-WEATHER-2014[12]数据集、RWTHPHOENIX-WEATHER-2014-T[76]数据集、USTC-CCSL[5]数据集和CSL-Daily[83]数据集。
RWTH-PHOENIX-WEATHER-2014[12]是用于连续手语识别的德国手语数据集,其素材来源于9位手语主持人播报的天气预报视频。数据集的训练集、验证集和测试集分别包含5 672、540和629个数据样本。
RWTH-PHOENIX-WEATHER-2014-T 数据集[76]可以同时用于手语翻译任务和识别任务,该数据集同样来自于德国手语的天气播报。数据集的训练集、验证集和测试集分别包含7 096、519 和642 个样本。与RWTH-PHOENIX-WEATHER-2014数据集类似,同样拥有9个手语演示者。
USTC-CCSL数据集[5]是目前使用最广的中国手语[113]数据集,该数据集包含约25 000 段已标记的手语视频,由50 名手语演示者进行手语演示。数据集的训练集、验证集和测试集分别包含约17 000、2 000及6 000 个样本。特别的,该数据集采用Kinect 摄像机[114]采集数据,可提供RGB视觉信息、深度信息及骨架信息。
CSL-Daily数据集[83]可用于连续手语识别及翻译任务,相较于USTC-CCSL,CSL-Daily 更侧重于日常生活场景,包括家庭生活、医疗保健和学校生活等多个主题。CSL-Daily的训练、验证和测试集分别包含18 401、1 077和1 176段视频样本。
在连续手语语句数据集中,一部分数据集有注释与正常口语语序的文本对照,可用作手语翻译,主要包括Boston-104[106]、RWTH-PHOENIX-WEATHER-2014-T[77]、KETI[109]、GSL[110]、MEDIAPI-SKEL corpus[111]和CSL-Daily[83]数据集。
2.2 评价指标介绍
对于孤立词手语识别,常采用准确率和召回率进行评价[115]。准确率(Acc)又叫查准率,表示在所有的样本数中得到正确分类的样本数所占据的比例。通常采用Top-1准确率和Top-5准确率进行评价。前者用于预测结果中取最大的概率向量,若正确则分类结果正确,反之则错误;后者预测结果中取最大的前五个概率向量评判正确性,若五个全部预测错误时则预测分类结果错误,反之则正确。召回率(Recall)又叫查全率,表示的是样本中的正例有多少被预测正确。
对于连续手语识别,常采用误字率和准确率。误字率(word error rate,WER)[116]作为手语识别研究中衡量两句之间相似度的指标。其是指将已识别句子转换为相应参考句子所进行的替换、插入和删除操作的最小总和。

其中,S、I和D表示将假设句转换为标注序列所需的替换、插入和删除操作的最小数量。N是标注序列的单词数。一些文章中使用准确率表示手语识别的性能,具体公式为:

对于手语翻译,评价体系参考自然语言翻译研究,包括评价指标:BLEU(bilingual evaluation understudy)[117]、CIDEr(consensus-based image description evaluation)[118]、ROUGE(recall-oriented understanding for gisting evaluation)[119]和METEOR[120]。BLEU 得分是手语翻译常用的评估指标。假设一个文本由机器和人工各翻译一次,BLEU的值为n个连续的单词序列(n-gram)同时出现在机器翻译和人工翻译中的比例。根据n-gram可以划分成多种评价指标,如BLEU-1、BLEU-2、BLEU-3、BLEU-4。CIDEr 是BLEU 和向量空间模型的结合。通过计算其TF-IDF向量[121]的余弦夹角,得到各个n-gram 的权重来度量得到候选句子和参考句子的相似度。ROUGE 是通过统计系统生成的机器翻译与人工生成的标准翻译之间重叠的基本单元(n元语法、词序列和词对)的数目,来评价翻译的质量。与BLEU 得分不同,METEOR 考虑到了语言的变化性。METEOR不仅双向比较了机器翻译和人工翻译,而且还考虑到了语言语法等因素。例如在英语中,ride 或riding 在BLEU 方法中算作不同的词,在METEOR中由于词根相同,两者算作同一个单词。
3 手语识别与翻译研究面临的挑战
3.1 手语视频帧有效信息获取
首先,手语视频冗余性会导致关键帧提取困难。手语视频普遍较长,并且有的视频会有大量空白帧,有的任务背景过于复杂,系统在识别提取关键手势时会遭遇困难。其次,针对连续手语识别,其本质上是一种弱监督的学习任务[122]。连续手语视频中语义边界是未知的,由于手语词汇丰富,许多术语都有非常相似的手势和动作。而且,因为不同的人有不同的动作速度,同样的手语注释可能有不同的长度。如何精确分割每个手势是困难所在。如果对视频进行时间分割时出现错误,会不可避免地将错误传播到后续步骤中,从而影响结果的准确度。这些因素都会给手语视频帧处理及特征提取带来挑战。表2 列举了一些近年来代表性的在手语视频特征处理上的研究工作。

表2 特征提取代表性工作Table 2 Representative work of feature extraction
3.2 多线索权重分配
为了有效地进行手语识别与翻译,需要从不同线索进行融合共同指导模型预测,因此如何综合利用这些线索进行多角度的手语特征表达也是难点之一。首先,简单的特征融合组合不一定比单个特征更好。其次,对于多线索而言,自适应地为不同线索设置模型参数并非易事,每个模型中所涉及到的关键动作的变化都可能会对参数造成影响。针对多线索融合问题,需要关注的重点是选择哪些线索以及如何融合这些线索。一种可行的方案是通过大量的对比实验,找出最优的特征融合方式,例如设置线索优先级、动态分配各个线索权重、设置多步融合模块等。
3.3 手语语法和自然语言语法的对应
根据手语语言学研究,通常一些国家的手语可分为自然手语和规约手语(或称手势手语)。以中国手语举例,中国手语可以分为自然手语和手势汉语。自然手语主要由听障人士使用,具备一套体系化的语法规则,而手势汉语是一种在口语语法的基础上直接进行手势演练操作的人工语言,其和汉字具有一一对应的关系,因此又称书面手语。如何将自然手语和规约手语进行映射是手语翻译研究的挑战之一。现有手语翻译研究大多是在连续手语识别的基础上,结合语言模型得到符合口语化描述的自然语言翻译。未来可以考虑构建大型的文本对数据集,即自然手语注释集及对应的规约手语注释集,将语言模型在文本对数据集上先进行预训练,然后迁移至手语翻译的语言模型中。
3.4 数据集资源
相对于手语识别及翻译研究模型所需的数据规模而言,目前的手语数据集还远不能满足模型需求,而基于数据驱动的识别及翻译方案,很容易导致神经网络过拟合。且大部分数据是在实验室环境下拍摄收集,而在现实场景中,存在背景多变、阴影、遮挡等众多干扰,这更容易导致模型无法较好地捕捉到手部、脸部及肢体等部位的变化,从而影响识别和翻译结果。未来研究者们可以考虑构建规模更大、场景更复杂的通用手语数据集。
4 结束语
手语识别与翻译是一个典型的多领域交叉研究方向,具备重要的研究及社会意义。由于手语的复杂性及当前客观的技术及数据方面的制约,手语识别与翻译研究充满挑战性,尤其是数据量不够造成的模型过拟合问题以及模型过于复杂导致的实时性不够的问题。文章对近年来手语识别与翻译相关研究进行综述,简单介绍了主流方法情况及特点,同时介绍了手语识别与翻译研究所涉及的数据集及评价方式,为研究者快速全面地了解手语识别与翻译研究提供了有效的途径。
