针对目标检测器的假阳性对抗样本
2022-11-11袁小鑫黄永洪
袁小鑫 胡 军 黄永洪
1(计算智能重庆市重点实验室(重庆邮电大学) 重庆 400065) 2(重庆邮电大学计算机科学与技术学院 重庆 400065) 3(重庆邮电大学网络空间安全与信息法学院 重庆 400065)
近年来,随着深度学习的相关理论技术和计算能力的发展,深度神经网络(deep neural networks, DNNs)模型在计算机视觉领域的各项任务中表现出色,基于DNNs模型的目标检测器逐渐被应用在人脸识别[1]、行人跟踪[2]以及无人驾驶[3]等领域.然而,近年来的研究表明DNNs模型易受攻击者精心设计的对抗样本的攻击,从而输出不正确的预测结果,所以DNNs架构的目标检测器本身的安全性也越来越受到研究者的关注.YOLOv3[4]是实时检测任务中一种主流的目标检测器,比如用YOLOv3实时检测交通信号灯[5]以及交通标志[6],现有针对YOLOv3或其他目标检测器的物理对抗攻击的方式大多是先通过特定的目标模型生成较大的对抗性扰动,再将生成的对抗性扰动打印出来并贴在特定类别的物体上构成物理对抗样本.但是在最近的研究中,出现了一种针对目标检测器的新型对抗样本——假阳性对抗样本(false positive adversarial example, FPAE)[7],此类对抗样本是通过目标模型直接生成得到的,人无法识别该对抗样本图像中的内容,但目标检测器却以高置信度将该对抗样本误识别为攻击者指定的目标类.研究FPAE的生成有助于发现YOLOv3及其他目标检测器存在的弱点.现有以YOLOv3为目标模型生成FPAE的方法仅有Zhao等人[8]提出的AA(appearing attack)方法,该方法在生成过程中为提升对抗样本的鲁棒性,使用了典型的EOT(expectation over transformation)图像变换方法[9]来模拟各种物理条件,但是并未包含运动模糊变换,然而在实际的拍摄过程中,如果摄像头与对抗样本之间发生较快的相对运动,对抗样本在拍摄出来的照片上就会出现运动模糊进而影响到对抗样本的攻击效果.此外,该方法生成的FPAE在除目标模型外的其他模型上进行黑盒攻击的成功率并不高.
为生成性能更好的FPAE,以揭示现有目标检测器存在的弱点和测试现有目标检测器的安全性,本文以YOLOv3为目标模型,提出了鲁棒且可迁移的假阳性(robust and transferable false positive, RTFP)对抗攻击方法,该方法在迭代优化过程中,除了加入典型的图像变换外,还新加入了运动模糊变换,在设计损失函数时,借鉴了C&W攻击[10]中损失函数的设计思想,并考虑了目标模型预测出的每个边界框与FPAE所在的真实边界框之间的重合度(intersection over union, IOU),将目标模型在FPAE的中心所在的网格预测出的边界框与FPAE所在的真实边界框之间的IOU作为预测的边界框的类别损失的权重项.在现实世界中的多角度、多距离拍摄测试以及实际道路上的驾车拍摄测试中,RTFP方法生成的FPAE均能保持较强的鲁棒性且迁移性强于现有方法生成的FPAE.
本文的主要贡献有2个方面:
1) 提出了一种新的生成FPAE的RTFP方法,该方法在生成FPAE的过程中,通过新加入的运动模糊变换和借鉴C&W攻击思想设计出的全新的损失函数克服了由于运动模糊造成的FPAE鲁棒性不足以及FPAE在其他目标检测器上的迁移性差的问题;
2) 设计了现实世界中的多角度、多距离拍摄测试以及驾车拍摄测试,在实际场景下对RTFP方法生成的对抗样本的攻击效果进行了全面的评估.
1 相关工作
根据对抗样本所适用的场景,可以将现有的针对目标检测器的对抗样本分为数字对抗样本和物理对抗攻样本,本节主要回顾现有研究中针对目标检测器的数字对抗样本和物理对抗样本.
1.1 针对目标检测器的数字对抗样本
在计算机视觉领域,自Szegedy等人[11]指出DNNs分类器易受对抗样本影响的特性之后,相继有研究者陆续提出针对DNNs分类器的对抗攻击方法,比如生成数字图像对抗样本的FGSM[12]、C&W方法和生成物理对抗样本的BPA-PSO[13]、RP2方法[14].在针对图像分类器的对抗攻击研究取得一定成果后,研究者开始研究针对目标检测器的对抗攻击.2017年,Xie等人[15]提出了针对目标检测器的DAG对抗攻击方法,该算法首先获得图像中每个物体的正确类别,然后给每个物体分别设定一个不正确的类别,通过最大化不正确类别的置信度,同时最小化正确类别的置信度,达到生成对抗样本的目的.Lu等人[16]以Faster R-CNN[17]目标检测器为目标模型,从拍摄视频中抽取出包含STOP交通标志的帧作为训练样本,通过最小化目标检测器对STOP交通标志的平均预测分数,设计出对抗性STOP交通标志图像.Li等人[18]提出RAP对抗攻击算法,该算法主要攻击目标检测器中的区域建议网络RPN,并且在设计损失函数时,设计了针对RPN网络的分类损失和回归损失.Liu等人[19]分别在有目标对抗攻击和无目标对抗攻击的情况下设计出不同的对抗性扰动,当向原始图像添加相应的对抗性扰动之后可以使Faster R-CNN目标检测器对图像中的物体错误识别.Wei等人[20]提出UEA对抗攻击算法,该算法通过构造生成对抗网络来快速地生成图像和视频对抗样本,为了提高对抗样本的迁移性,在训练生成对抗网络中的生成器时,结合了目标检测器的类别损失和特征损失.Li等人[21]研究了目标检测器中SSM模块的脆弱性,指出SSM模块易受背景图像中的对抗性扰动的影响,并利用SSM这一弱点,设计出添加在背景图像区域的对抗性扰动.
1.2 针对目标检测器的物理对抗样本
部署在现实世界中的目标检测器大多是以摄像头拍摄到的画面作为输入,现实中的各种环境因素都会影响对抗样本的攻击效果,为进一步提升对抗样本的鲁棒性,使之能在物理世界也能欺骗目标检测器,研究者进一步提出针对目标检测器的物理对抗样本.Eykholt等人[22]将针对分类器的RP2对抗攻击算法进行拓展,将其应用于YOLOv2目标检测器[23],将生成的对抗性扰动打印出来并贴到正常的STOP交通标志上的相应位置后,YOLOv2目标检测器便不能检测到STOP交通标志.Chen等人[24]在设计针对Faster R-CNN目标检测器的对抗性STOP交通标志图像时,提出了ShapeShifter方法,该方法在生成对抗性扰动的过程中使用了EOT变换,并将添加的扰动限制在STOP交通标志图像中除文字之外的其余区域.Huang等人[25]以Faster R-CNN为目标模型将对抗性扰动设计成广告牌的形式,发现将扰动打印出来并贴在STOP交通标志牌的下方时同样具有攻击效果.上述针对目标检测器的物理对抗样本的构造方式,均是将生成的对抗性扰动添加在目标类别的物体表面或者周围构造出来的,但是最近有研究者发现通过直接生成对抗样本的方式也可以欺骗目标检测器,Kotuliak等人[7]以Faster R-CNN目标检测器为目标模型,生成人无法识别却能使目标检测器产生误判的假阳性对抗样本(FPAE),但是该方法生成的对抗样本只在很短的距离内有攻击效果.Zhao等人[8]以YOLOv3为目标模型提出AA方法,并在生成对抗样本的过程中采用了EOT变换,提升了对抗样本的鲁棒性,但是并未考虑拍摄时出现的运动模糊因素对FPAE攻击效果的影响,导致在发生运动模糊的情况下攻击效果变差,同时在对其他目标检测器进行黑盒攻击时攻击成功率也不高.
2 目标检测器介绍
2.1 现有的主流目标检测器的分类
给定输入图像,目标检测器需要预测出图像中包含的多个物体的类别、类别置信度和包围物体的最小边界框的坐标.目前主流的目标检测器可分为2种类型:一种是单阶段目标检测器,比如YOLOv2,YOLOv3和SSD[26];另外一种是2阶段目标检测器,比如Fast R-CNN[27]和Faster R-CNN.其中,单阶段目标检测器使用单个DNNs网络同时预测图像中的物体类别和所在的位置,2阶段目标检测器先通过CNN神经网络提取图像特征得到特征图并产生可能包含物体的候选区域,再对候选区域包含的物体进行进一步的分类以及调整物体的位置坐标.一般单阶段目标检测器的推理时间会比2阶段目标检测器的推理时间更短,而2阶段目标检测器的准确度比单阶段目标检测器的准确度更高.
2.2 YOLOv3目标检测器
对于给定的输入图像,YOLOv3首先将其缩放为统一的尺寸,然后送入到特征提取网络中进行处理,最终得到相对输入图像32倍下采样、16倍下采样和8倍下采样的3个不同尺度的输出特征图.对于每个尺度的输出特征图,YOLOv3会对输入图像中每个划分出的网格预测出3个边界框,每个边界框的预测向量中包含边界框的位置信息(tx,ty,tw,th)、盒置信度分数(scoreobj)以及边界框中的物体分别属于训练集中每个类的类别置信度分数(score1,score2,…,scoren),所以每个边界框对应的预测向量的形式为
(tx,ty,tw,th,scoreobj,score1,score2,…,scoren).
(1)
其中,tx表示边界框在当前图像中的左上角顶点的横坐标,ty表示边界框在当前图像中的左上角顶点的纵坐标,tw表示边界框的宽度,th表示边界框的高度,n代表训练集中的类别数,而每个尺度的输出特征图上的单位点都与原图中对应位置上划分出的网格相对应,将网格中预测出的3个边界框的预测向量拼接起来就得到单位点所在位置的预测向量.
3 RTFP方法
为提升FPAE的鲁棒性和迁移性以进一步揭示现有目标检测器的弱点,本文提出RTFP方法,本节主要介绍RTFP方法的具体内容.
3.1 威胁模型
本文以YOLOv3为目标模型,采用白盒有目标攻击生成对抗样本,即假定攻击者可以获取到目标模型的结构和参数信息,同时设定目标类,也就是攻击者期望攻击成功后目标模型将对抗样本识别为指定的类别.在实验中,除对目标模型进行白盒攻击外,为评估对抗样本的迁移性,本文还将白盒攻击方式生成的对抗样本对除目标模型之外的其他目标检测器进行黑盒攻击,即假定攻击者不知道这些目标检测器的结构和参数信息,其目标类与白盒攻击的目标类相同,如果这些目标检测器将对抗样本识别为设定的目标类则认为攻击成功.此外,本文假定攻击者只能通过在现实世界中部署物理对抗样本来达到攻击目标检测器的目的,而不能对输入到目标检测器中的数字图像添加对抗性扰动.
3.2 RTFP方法总体流程

Fig. 1 The workflow of RTFP method图1 RTFP方法的工作流程
RTFP方法的主要原理是在优化过程中对FPAE使用一系列的图像变换并将其覆盖在随机的背景图像上,再计算出目标检测器对背景图像中FPAE的预测损失,通过不断优化损失函数得到最终生成的FPAE.该方法工作流程如图1所示,先将FPAE用U(0,1)随机初始化为待优化的方形图像p,为模拟现实世界中各种不同的物理条件,需要对图像p施加一系列图像变换,变换后得到的图像记为ptf.同时,为模拟现实世界中各种不同的场景,在每次迭代优化过程中都会从MS-COCO数据集[28]中随机选取不同的图像作为背景图像xbg,并将所选的背景图像xbg缩放至YOLOv3要求的输入图像的尺寸,再将ptf覆盖在背景图像xbg上得到xbp,将xbp送入YOLOv3目标检测器后得到模型对xbp中的ptf的预测结果,再使用Adam优化器结合模型的预测结果以及p的图像平滑度损失Losstv对图像p不断优化,最终得到FPAE,在优化过程中始终保证目标检测器的权重固定,每次只更新图像p.
3.3 RTFP方法中使用的图像变换
由于现实世界中的目标检测器是对摄像头拍摄到的图像进行检测,摄像头在拍摄过程中,物体与摄像头之间的距离、角度以及物体周围的光照条件都在不断变化,这些环境因素都会影响FPAE的攻击效果.因此,为了使生成的FPAE更加鲁棒,需要在每次迭代优化过程中对当前生成的图像p使用一系列图像变换模拟不同的物理条件.典型的图形变换方法是Athalye等人[9]提出的EOT变换,其中包含有常见的亮度和对比度变换、缩放变换、旋转变换和加性高斯白噪声变换.在实际应用场景中,摄像头在拍摄过程中如果与放置在现实世界中的FPAE之间发生较快的相对运动,那么FPAE在拍摄到的图像上就会出现运动模糊进而影响到FPAE的攻击效果.为避免FPAE在发生运动模糊的情况下的攻击效果受到较大的影响,RTFP方法在已有的图像变换的基础上新加入了运动模糊变换.在RTFP方法的优化过程中,待优化的图像p经过一系列图像变换后得到图像ptf,即ptf=t(p),t是图像变换函数,包括5种可微的图像变换方法.
1) 亮度和对比度变换.在拍摄过程中,由于对抗样本周围的光照强度会不断变化,所以,在每次迭代优化过程中,通过随机调整图像p的亮度和对比度模拟对抗样本在不同光照条件下的状态.
2) 缩放变换.当摄像头从远处向对抗样本靠近时,对抗样本在拍摄到的图像中的大小就会不断变化,并且原始图像在经YOLOv3网络处理之前,会先将原始图像等比例缩放至YOLOv3要求的输入图像的尺寸,现实中的摄像头拍摄出的原始图像的长宽比一般不相等,典型的长宽比是4∶3和16∶9,这就导致对原始图像进行等比例缩放之后,其中的对抗样本的长宽比就不再相等,为了使不同尺寸和长宽比的对抗样本都能欺骗目标检测器,RTFP方法在优化过程中将对抗样本图像的尺寸进行随机调整,同时将长宽比的变化范围设定在典型4∶3和16∶9 之间,以此来模拟对抗样本在不同的距离被拍摄时尺寸的变化情况.
3) 旋转变换.在实际拍摄过程中,对抗样本会在拍摄到的图像上旋转一定的角度,因此,每次通过随机旋转图像p的角度可以模拟对抗样本在拍摄到的图像上出现旋转时的状态.
4) 加性高斯噪声变换.在拍摄对抗样本时会因为摄像设备的问题导致拍摄的图像上出现多余的噪声,通过对图像p添加随机的高斯噪声,可模拟拍摄到的对抗样本在受到此类噪声影响时的状态.
5) 运动模糊变换.考虑到摄像头与物体之间发生较快的相对运动时,对抗样本会在拍摄到的图像中出现运动模糊的情况,因此,RTFP方法在每次优化过程中均对图像p施加随机的运动模糊变换,以此来模拟对抗样本在拍摄到的图像上出现运动模糊时的状态.
3.4 RTFP方法中损失函数的设计
在3.2节中所描述的迭代优化过程中,在将覆盖有ptf的背景图像xbp送入YOLOv3目标检测器后会得到3个不同尺度的输出特征图,分别对应将输入图像xbp中划分出3种不同数量的网格时的预测结果.对于某个尺度为s(s的取值为1,2,3,分别对应3个不同的尺度)的输出特征图,先计算出输入图像xbp中图像ptf的中心所在的网格位置cellpt,进而得到输出特征图中与cellpt对应的单位点的位置Is,在Is处的单位点包含的向量就是YOLOv3在cellpt处的网格中预测出的边界框的预测向量,攻击者最终目的是让YOLOv3检测到图像ptf并将其分类为指定的目标类别y,因此,就需要增加cellpt位置的边界框的预测向量中盒置信度分数scoreobj与目标类别y的类别置信度分数scorey.已有的研究表明C&W攻击生成的对抗样本具有较好的攻击效果[29-30],因此,RTFP方法在优化YOLOv3预测出的类别置信度时,借鉴了C&W攻击中损失函数的设计思想,同时为尽量优化与FPAE最相关的预测边界框,RTFP方法中根据模型在cellpt位置预测出的各个边界框与ptf在输出特征图上对应的真实边界框之间的IOU为每个预测边界框的损失值设置了相应的权重,因此在尺度s下对应的优化问题为
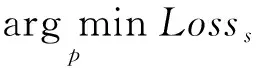
(2)

(3)
3.5 RTFP方法生成FPAE的过程
算法1.calcLoss(x,p,y)./*对于当前所选的背景图像数据集,计算YOLOv3对所有背景图像中的FPAE的预测值的损失之和loss*/
输入:背景图像集x、当前生成的FPAE图像p、目标类别y;
输出:损失值loss.
①loss=0;
② forxiinxdo
③ptf←t(p);/*t是图像变换函数*/
④xpat←(ptf⊕xi);/*将ptf随机覆盖在xi上,⊕表示覆盖操作*/
⑤loss←loss+J(xpat,y);/*J是RTFP方法的损失函数*/
⑥ end for
⑦ returnloss.
算法2.getBatchData(xbg,j,k)./*获取输入的背景图像数据集中某个批次的背景图像数据*/
输入:背景图像数据集xbg、当前欲获取的批次j、总的批次数k;
输出:获取到的数据batchData和下一个批次jnext.
①batchData=0;
② ifj>k
③batchData←xbg中第1个批次的图像;
④jnext=2;
⑤ else
⑥batchData←xbg中第j个批次的图像;
⑦jnext=j+1;
⑧ returnbatchData,jnext.
算法3.RTFP方法生成FPAE的过程.
输入:最大迭代次数e、设定的目标类别y、阈值threshold、训练集Btrain和验证集Bval(Btrain和Bval均来自背景图像数据集B),Btrain对应的总批次数为k;
输出:最终生成的FPAE图像bestP.
① 使用U(0,1)随机初始化一张图像p;
② 将minLoss设置为无穷大;
③bestP=p;
④j=1;
⑤ fori=1,2,…,edo
⑥totalLoss=calcLoss(Bval,p,y);
⑦ iftotalLoss≤threshold
⑧bestP=p;
⑨ break;
⑩ else
/*Btrain,j,k分别对应getBatchData中的xbg,j,k*/
/*Btrainj,p,y分别对应calcLoss中的x,p,y*/
4 实验设计与实验结果
为测试RTFP方法生成的FPAE的鲁棒性和迁移性,本文在现实场景中分别进行了多角度、多距离拍摄测试以及真实道路上的驾车拍摄测试,本节主要介绍实验设置以及实验结果.
4.1 实验设置
考虑到YOLOv3可被应用在无人车的实时处理系统中对摄像头拍摄到的图像进行实时检测,无人车周围的交通标志对无人车的行驶安全非常重要,因此,实验将目标类设定为MS-COCO数据集中的STOP交通标志,目标模型是在MS-COCO数据集上预训练好的YOLOv3目标检测器,其骨干网是Darknet-53,输入到YOLOv3模型中的图像被统一缩放成608×608的尺寸,模型的类别置信度阈值设置为0.5,即当FPAE被目标检测器错误地检测并分类为STOP标志的置信度高于0.5时,才认为FPAE成功欺骗了目标检测器.
在对其他目标检测器进行黑盒攻击测试时,所选的目标检测器包括Faster R-CNN ResNet-101,Faster R-CNN Inception v2,Mask R-CNN Inception v2[31],SSD Inception-v2,SSD MobileNet v2. 这些目标检测器均是TensorFlow官方模型库[32]中提供的在MS-COCO数据集上预训练好的目标检测器,并且在现有研究中也被作为典型的测试模型,这些模型的类别置信度阈值同样设置为0.5,模型的其他参数均按照模型默认的参数进行设置.在现有的使用YOLOv3作为目标模型生成FPAE的研究中,与本文所做的工作最接近的仅有Zhao等人[8]提出的AA方法,因此本文选择AA方法与RTFP方法进行对比,实验中所使用的拍摄设备为OPPO A92s,图2是这2种方法生成的FPAE图像.

Fig. 2 FPAE generated by two methods图2 2种方法生成的FPAE
4.2 多角度、多距离拍摄测试
为在现实世界中测试RTFP方法生成的FPAE在多个不同的距离和角度下的攻击效果,本实验将RTFP方法生成的FPAE打印出来,进行多角度、多距离的拍摄测试.我们将RTFP方法生成的FPAE打印成50 cm×50 cm的大小,然后将距离对抗样本1~25 m的直线距离范围分成5个距离段,每个距离段的范围分别设置为1~5 m,5~10 m,10~15 m,15~20 m,20~25 m.在每个距离段内,以对抗样本正对拍摄者为0°,在对抗样本分别向左和向右偏转0°,15°,30°,45°,60°(向左偏的角度记为负,向右偏的角度记为正)的情况下,在沿着当前直线距离段匀速前进的过程中拍摄对抗样本,最后将拍摄得到的视频送入各目标检测器测试FPAE的攻击效果.首先对目标模型YOLOv3进行白盒攻击测试,然后对其他目标检测器进行黑盒攻击测试,最后计算在每个距离段范围内每个偏转角度下拍摄的视频帧的攻击成功率(attacking success rate,ASR).ASR计算为
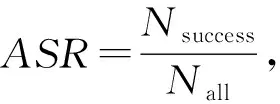
(4)
其中,Nsuccess表示当前拍摄到的视频中成功欺骗目标检测器的帧数,Nall表示拍摄到的视频中的总帧数.同时,本实验将AA方法生成的对抗样本也打印成相同的尺寸,并采用同样的拍摄设备和拍摄方法进行拍摄,最后计算2种方法在白盒攻击和黑盒攻击中的ASR.
表1是RTFP方法生成的FPAE对目标模型YOLOv3进行白盒攻击的ASR.可以看到,偏转角度一定,FPAE与摄像机之间的距离不断变化时,总体变化趋势是距离越远,ASR越低,因为随着拍摄距离的增大,FPAE的特征就更不容易被目标检测器捕获,也就更不容易欺骗目标检测器.从表1中的数据可以得到在1~15 m范围内,ASR相对较高,而在大于15 m的范围内,ASR相对较低,其中1~10 m范围内的ASR均达到了100%,在10~15 m范围内,ASR开始下降,总体范围在45%~100%之间,在15~20 m范围内的ASR在0%~45%之间,在20~25 m范围内的ASR均为0%.当FPAE与摄像机之间的距离段一定,FPAE的偏转角度不断变化时可以看到,在1~10 m的距离范围内,随着FPAE的偏转角度不断变化,FPAE在每个偏转角度下的ASR均是100%;而在10~20 m的距离范围内,总体变化趋势是ASR随着偏转角度的增大而减小,这是因为随着距离的变远和FPAE的偏转角度的增大,FPAE在拍摄到的图像上的尺寸变小加之有部分特征并未被拍摄到,进而导致FPAE的特征更加难以欺骗目标检测器,所以ASR降低.此外,由于RTFP方法生成的FPAE并非是左右对称的图像,因此,FPAE在向左偏转和向右偏转时,目标检测器捕获到的特征不同,所以,在10~20 m距离范围内的ASR并非是关于0°对称的.

Table 1 ASR of FPAE Generated by RTFP Method on YOLOv3表1 RTFP方法生成的FPAE在YOLOv3上的ASR %
表2~6是RTFP方法生成的FPAE对其他模型进行黑盒攻击的ASR.可以看到FPAE在Faster R-CNN ResNet-101,Faster R-CNN Inception v2,Mask R-CNN Inception v2这3个模型上都能保持较高的攻击成功率,反映出RTFP方法生成的FPAE的具有较强的迁移性;同时,在距离较远的情况下,FPAE同样可以欺骗这些目标检测器,这是由于这些目标检测器在设计时,相比于推理时间,更注重识别物体的精度,因此,这些目标检测器善于捕捉图像中小尺寸物体的特征,对交通标志本身的特征也更敏感,所以即使在距离较远时,FPAE上的对抗性特征也能被这些目标检测器捕获,从而可以进一步欺骗这些目标检测器;但是SSD Inception v2和SSD MobileNet v2并不善于检测图像中的小尺寸物体,所以,在距离相对比较远时,这2种目标检测器便难以捕获到FPAE的特征,也就无法被FPAE欺骗.
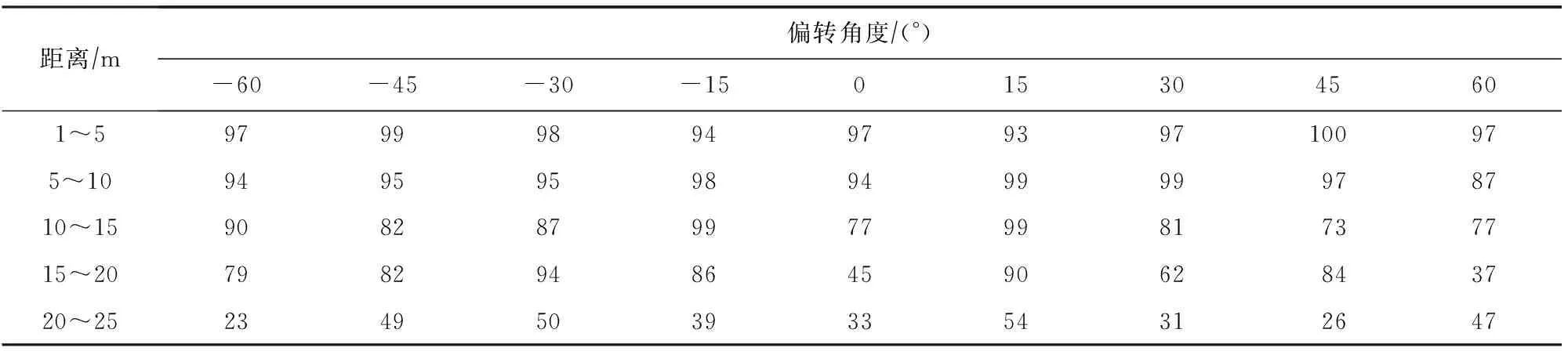
Table 2 ASR of FPAE Generated by RTFP Method on Faster R-CNN ResNet-101表2 RTFP方法生成的FPAE在Faster R-CNN ResNet-101上的ASR %
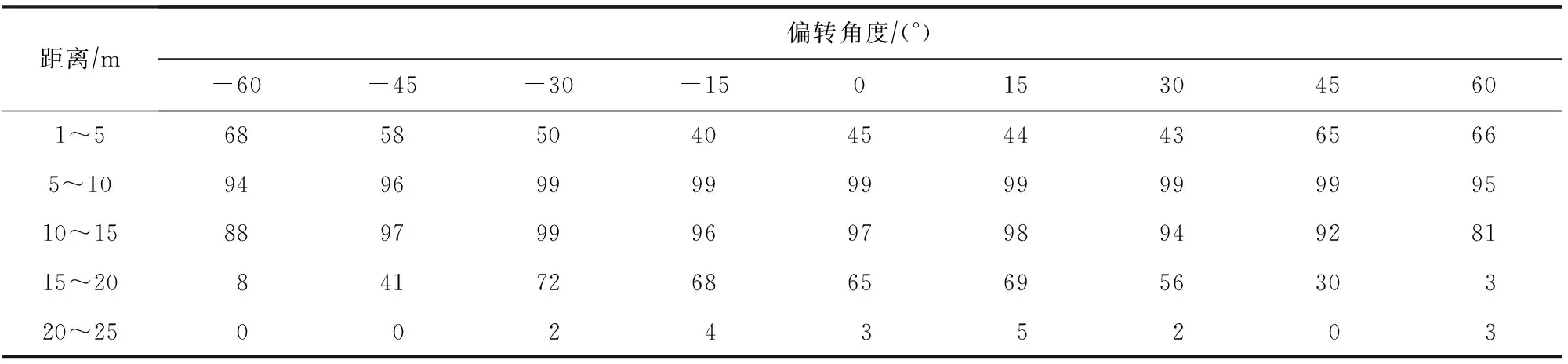
Table 3 ASR of FPAE Generated by RTFP Method on Faster R-CNN Inception v2表3 RTFP方法生成的FPAE在Faster R-CNN Inception v2上的ASR %
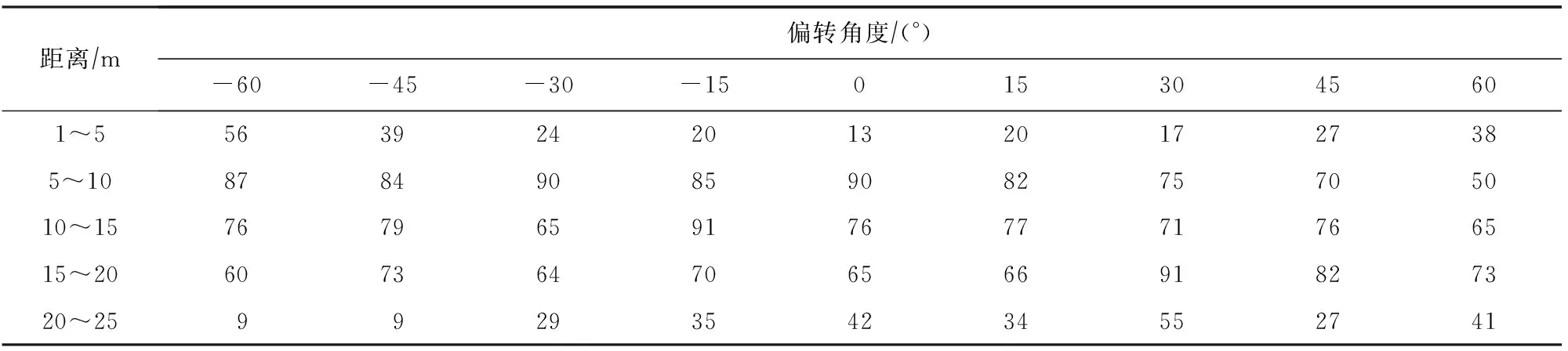
Table 4 ASR of FPAE Generated by RTFP Method on Mask R-CNN Inception v2表4 RTFP方法生成的FPAE在Mask R-CNN Inception v2上的ASR %

Table 5 ASR of FPAE Generated by RTFP Method on SSD Inception v2表5 RTFP方法生成的FPAE在SSD Inception v2上的ASR %

Table 6 ASR of FPAE Generated by RTFP Method on SSD MobileNet v2表6 RTFP方法生成的FPAE在SSD MobileNet v2上的ASR %

Fig. 3 AASR of FPAE on YOLOv3 at different distance ranges图3 在不同距离范围内FPAE在YOLOv3上 的AASR
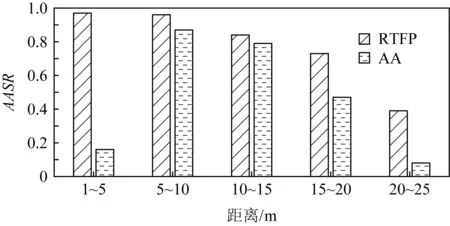
Fig. 4 AASR of FPAE on Faster R-CNN ResNet-101 at different distance ranges图4 在不同距离范围内FPAE在Faster R-CNN ResNet-101上的AASR

Fig. 5 AASR of FPAE on Faster R-CNN Inception v2 at different distance ranges图5 在不同距离范围内FPAE在Faster R-CNN Inception v2上的AASR

Fig. 6 AASR of FPAE on Mask R-CNN Inception v2 at different distance ranges图6 在不同距离范围内FPAE在Mask R-CNN Inception v2上的AASR

Fig. 7 AASR of FPAE on SSD Inception v2 at different distance ranges图7 在不同距离范围内FPAE在SSD Inception v2 上的AASR
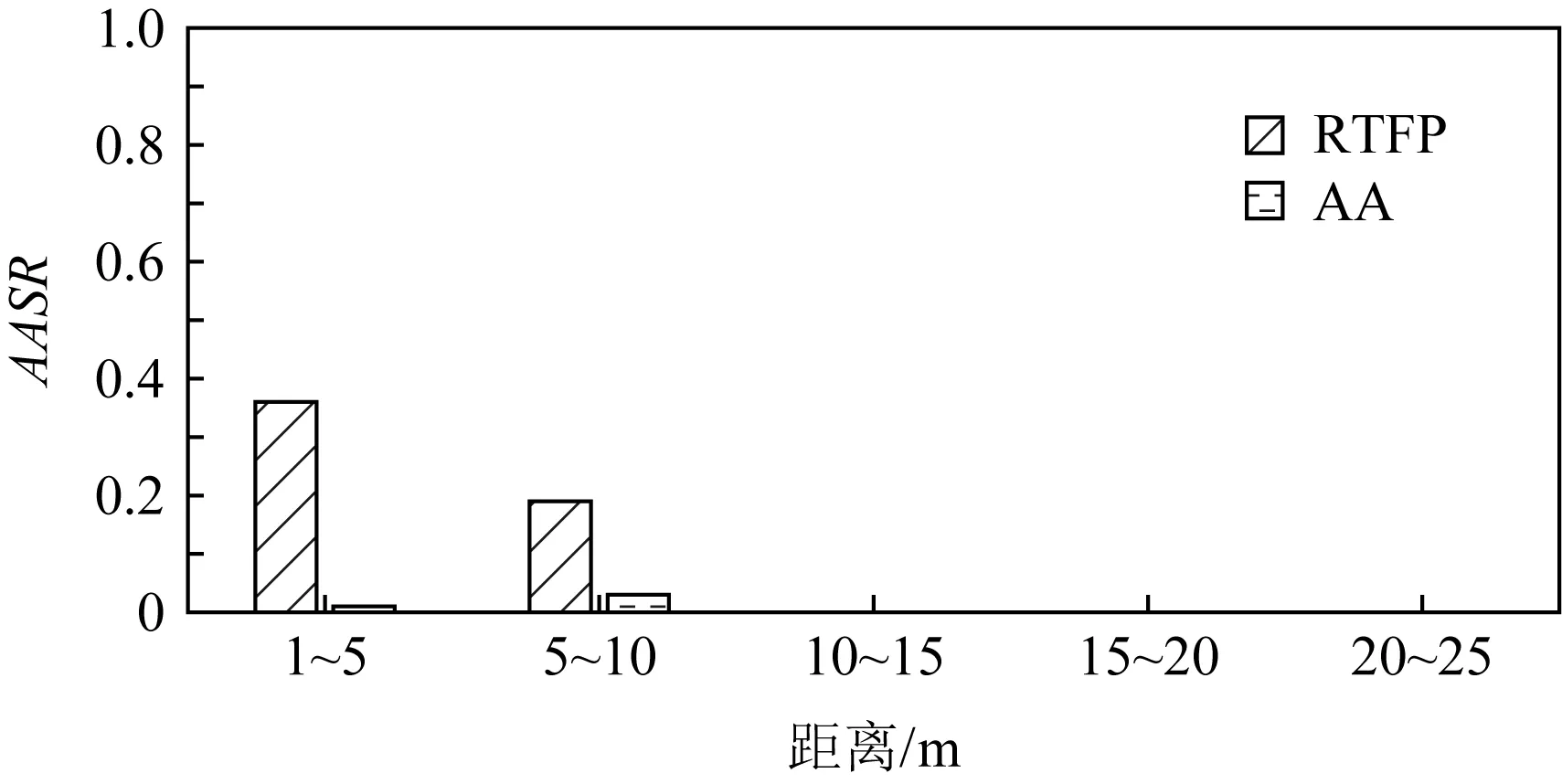
Fig. 8 AASR of FPAE on SSD MobileNet v2 at different distance ranges图8 在不同距离范围内FPAE在SSD MobileNet v2 上的AASR
图3是RTFP方法与AA方法生成的FPAE在各个距离段内在目标模型YOLOv3上的平均攻击成功率(average attacking success rate,AASR)的对比结果,图4~8是RTFP方法与AA方法生成的FPAE在各个距离段内在其他模型上的AASR的对比结果.AASR计算为

(5)
其中,Nas是当前距离段内各个角度下拍摄到的视频中成功欺骗目标检测器的帧数之和,Ndis是当前距离段内各个角度下拍摄到的视频的总帧数.
图3的结果表明,对于目标模型YOLOv3,2种方法生成的FPAE在各个距离段内的AASR大致相同,表明2种FPAE在目标模型上的鲁棒性相当.但是从图4~8的对比结果可以看出,RTFP方法生成的FPAE在其他模型上的每个距离段内的AASR均高于AA方法生成的FPAE的AASR,表明RTFP方法生成的FPAE的迁移性强于AA方法生成的FPAE的迁移性.此外,对于除目标模型YOLOv3之外的其他模型,在距离相对较近时,特别是在1~5 m距离范围内,AA方法生成的FPAE在各个模型上的AASR普遍较低,而RTFP方法生成的FPAE依然可以保持相对较高的AASR.这是由于AA方法的损失函数中并没有设计图像平滑度损失,从而导致生成的FPAE上出现较多的噪声像素点,这些噪声像素点是以YOLOv3为目标模型生成的,所以不会显著影响FPAE对YOLOv3的攻击效果,但是这些噪声像素特征会影响FPAE对其他目标检测器进行黑盒攻击的效果,尤其是在距离较近时,这些像素点在拍摄到的图像上非常明显,因此FPAE会对其他模型进行黑盒攻击的效果有较大影响,而RTFP方法在优化损失函数时加入了图像平滑度损失,所以生成的对抗样本更加平滑,降低了噪声像素点的影响,从而在距离较近时,RTFP方法生成的FPAE依然可以保持相对较高的AASR.
4.3 真实道路上的驾车拍摄测试
为在实际的道路上测试RTFP方法生成的FPAE的攻击效果,本文将生成好的FPAE竖立在真实道路的右侧,然后在距离FPAE较远处驾车匀速(速度的误差在1 km/h内)驶向FPAE,在保持匀速行驶后,在距FPAE所在位置20 m处开始拍摄,直至驶过FPAE,最后,将拍摄的视频中所有包含FPAE的帧送入YOLOv3进行白盒攻击测试,再送入其他目标检测器进行黑盒攻击测试,并计算在各个目标检测器上的攻击成功率ASR. 图9是RTFP方法生成的FPAE在15 km/h,20 km/h,25 km/h,30 km/h的速度下,在目标模型YOLOv3和其他目标检测器上的ASR.可以看出,在不同速度下拍摄的FPAE在各个目标检测器上均能攻击成功,并且对于每个模型,FPAE在不同速度下的ASR大致相同,表明FPAE在不同的速度下仍可以保持较好的鲁棒性和迁移性.图10是RTFP方法与AA方法生成的FPAE在15 km/h,20 km/h,25 km/h,30 km/h的行驶速度下对YOLOv3进行白盒攻击的ASR.从图10中可以看出,RTFP方法生成的FPAE的ASR相对较高,表明RTFP方法生成的FPAE在不同速度下的鲁棒性强于AA方法生成的FPAE.图11~14是RTFP与AA方法生成的FPAE分别在15 km/h,20 km/h,25 km/h,30 km/h的速度下对除YOLOv3之外的其他目标检测器进行黑盒攻击的ASR.从这4组对比结果可以看出,RTFP方法生成的FPAE在各个速度下对各个模型进行黑盒攻击的ASR相对较高,表明RTFP方法生成的FPAE在各个速度下的迁移性强于AA方法生成的FPAE.道路上的驾车拍摄测试近似反映了RTFP方法和AA方法生成的FPAE在实际的驾驶场景中的攻击效果,测试结果表明RTFP方法生成的FPAE在不同的行驶速度下可以保持较强的鲁棒性和迁移性且强于AA方法生成的FPAE.
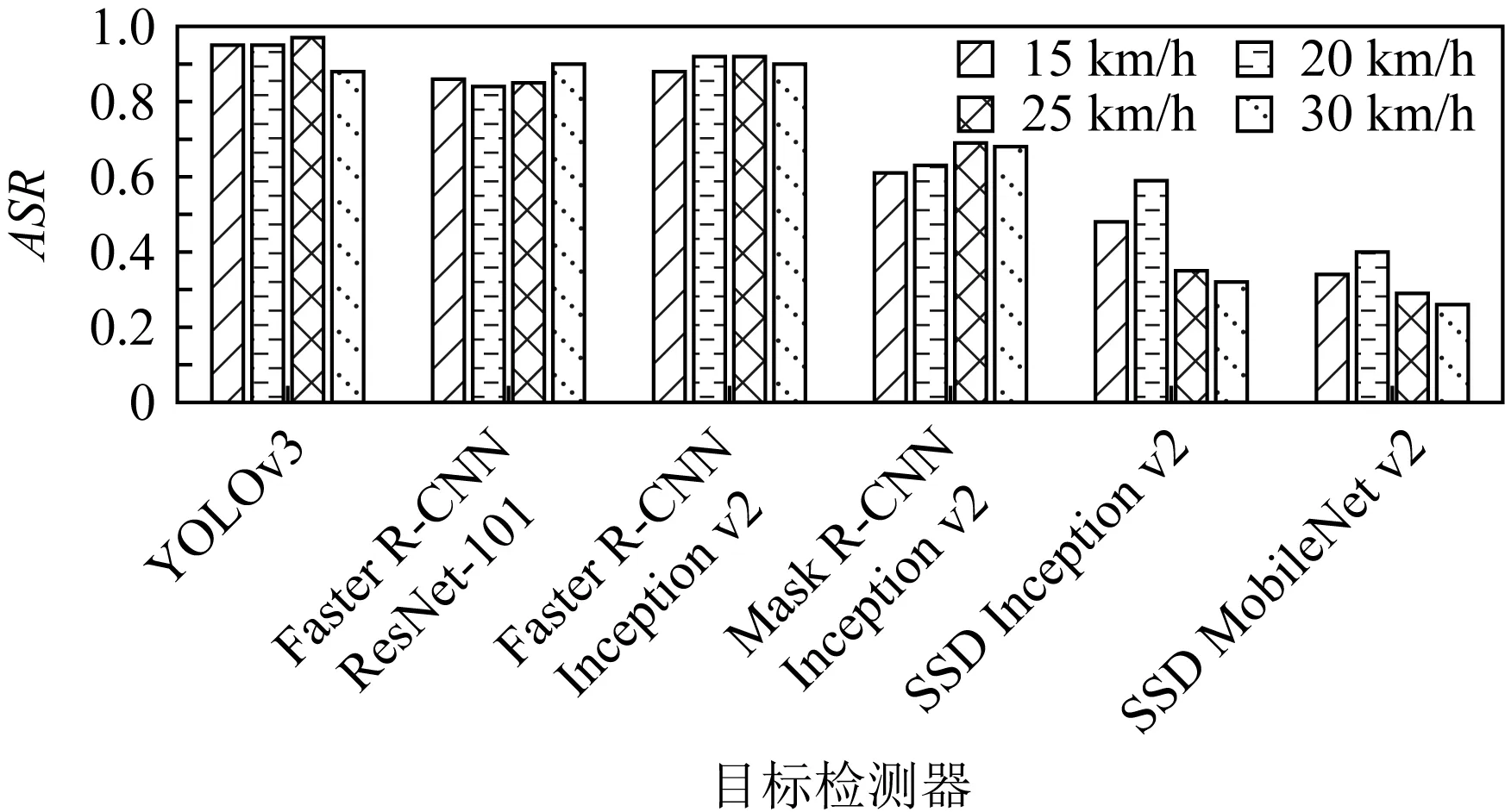
Fig. 9 ASR of FPAE on YOLOv3 and other object detectors at different speeds图9 在不同速度下FPAE在YOLOv3和其他目标 检测器上的ASR
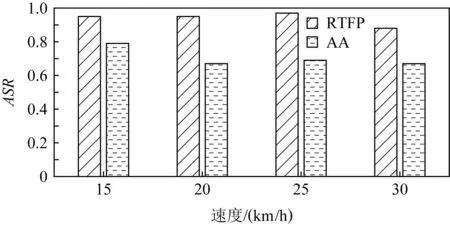
Fig. 10 ASR of FPAE on YOLOv3 at 4 different speeds图10 在4种不同速度下FPAE在YOLOv3上的 ASR
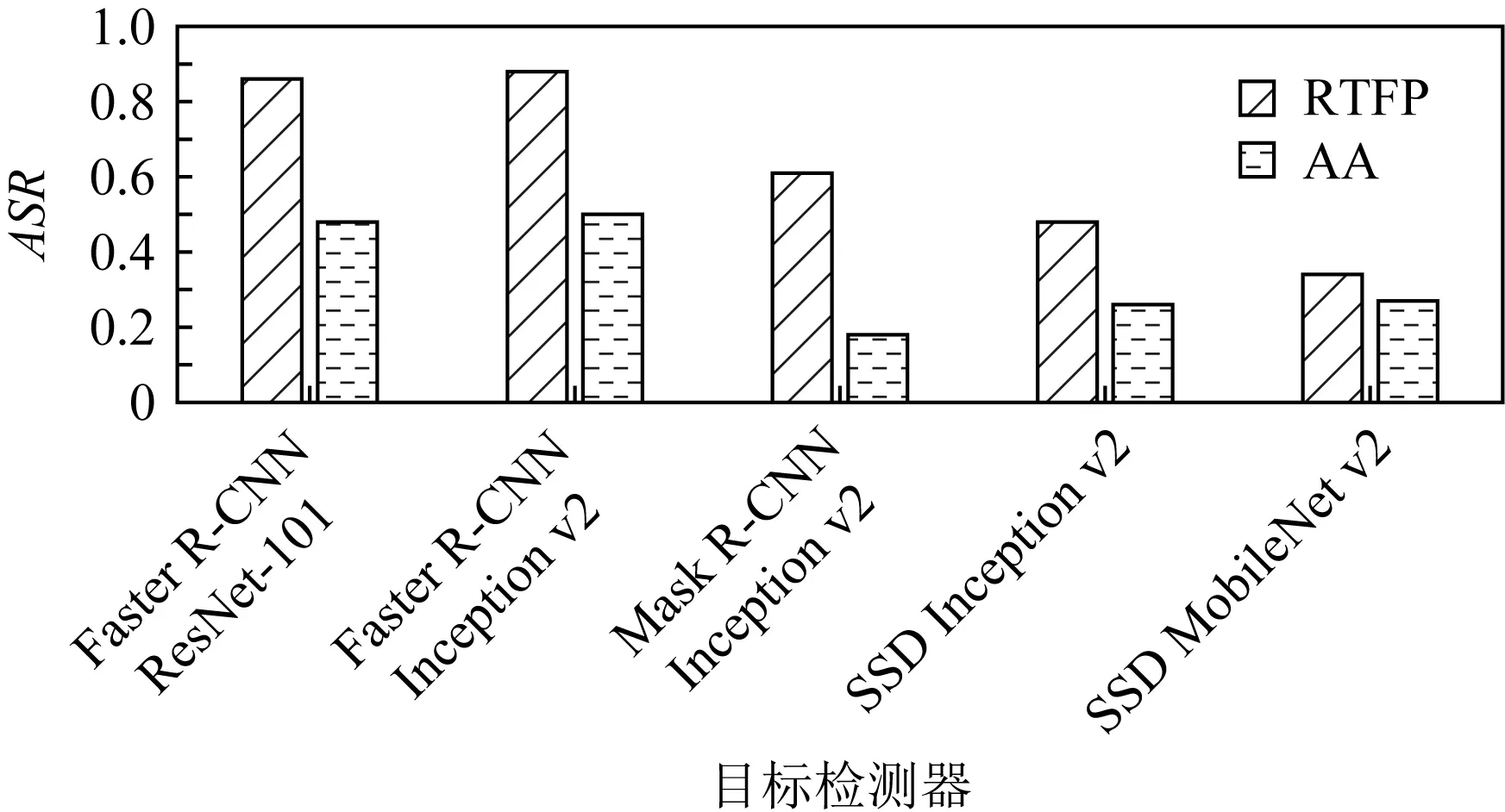
Fig. 11 ASR of FPAE in the black-box attack test at speed of 15 km/h图11 速度为15 km/h时FPAE在黑盒攻击测试 中的ASR
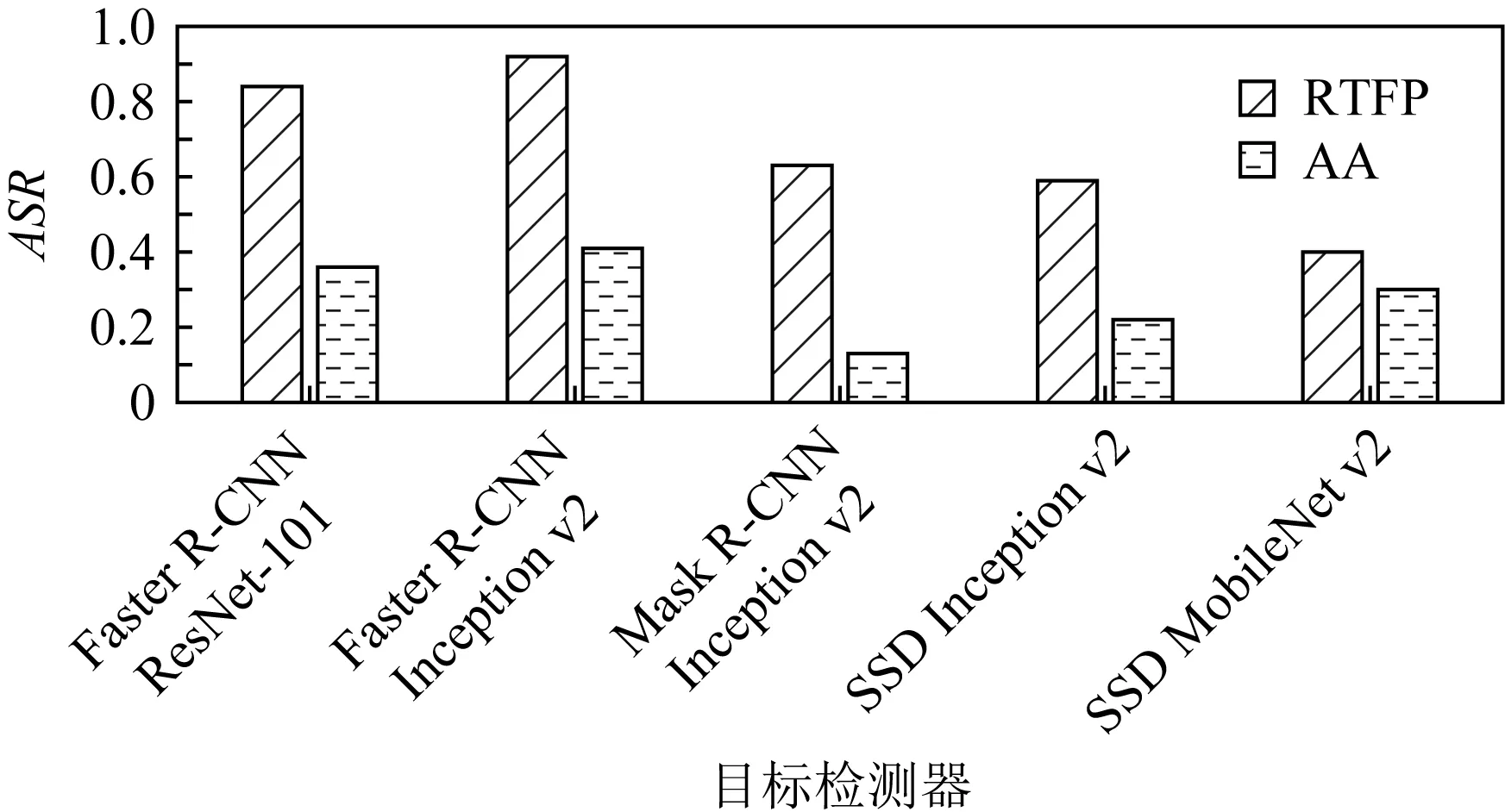
Fig. 12 ASR of FPAE in the black-box attack test at speed of 20 km/h图12 速度为20 km/h时FPAE在黑盒攻击测试 中的ASR
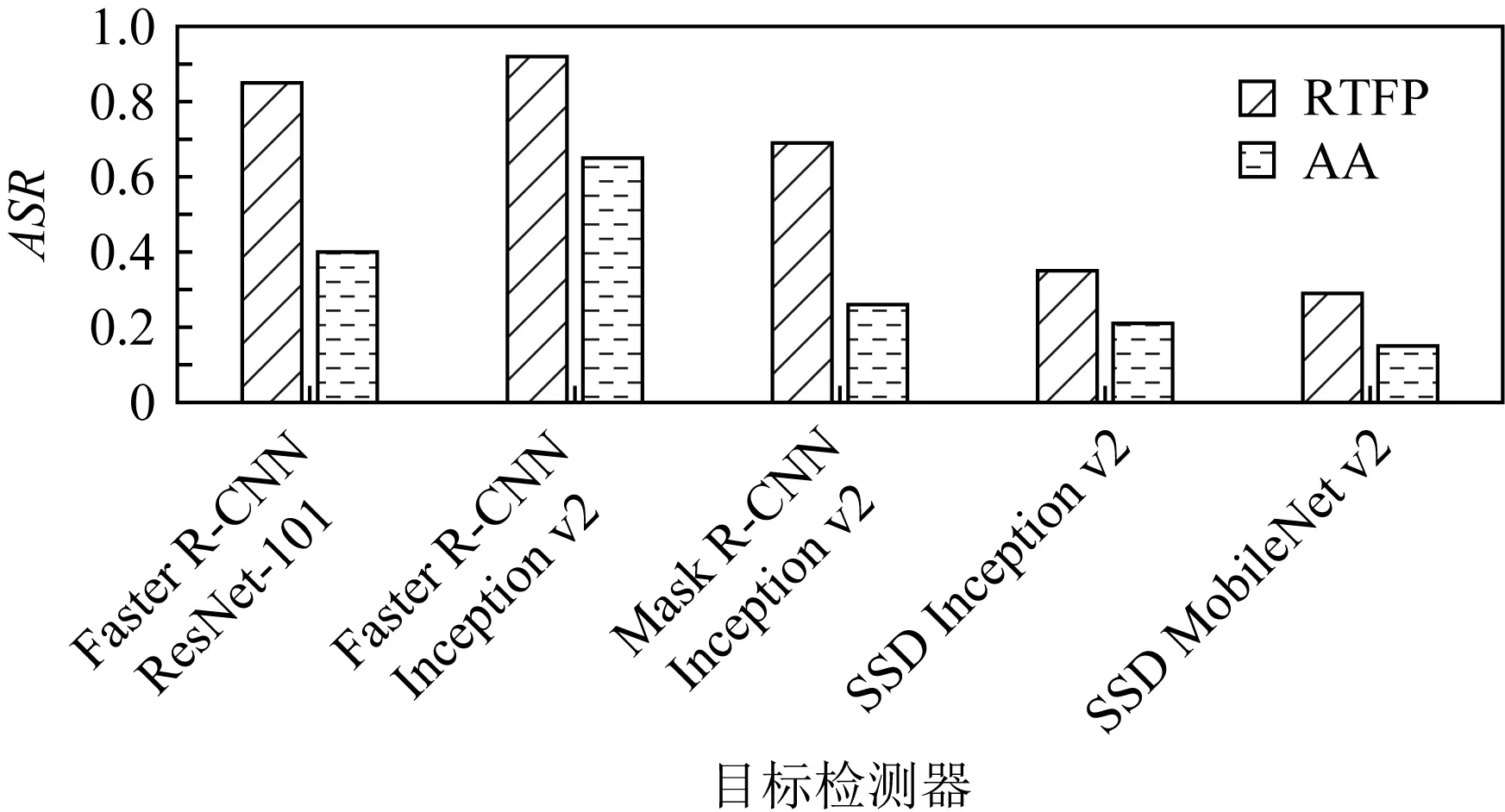
Fig. 13 ASR of FPAE in the black-box attack test at speed of 25 km/h图13 速度为25 km/h时FPAE在黑盒攻击测试 中的ASR

Fig. 14 ASR of FPAE in the black-box attack test at speed of 30 km/h图14 速度为30 km/h时FPAE在黑盒攻击测试 中的ASR

Fig. 15 ASR of FPAE at 4 different speeds图15 FPAE在4种不同速度下的ASR
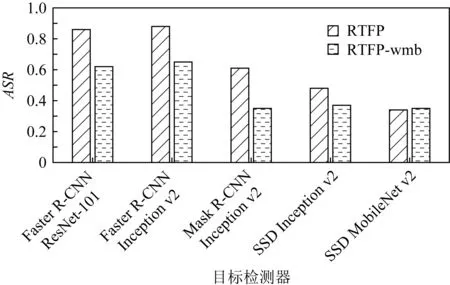
Fig. 16 ASR of FPAE in the black-box attack test at speed of 15 km/h图16 速度为15 km/h时FPAE在黑盒攻击测试 中的ASR
此外,在驾车拍摄的过程中,摄像头和FPAE之间会发生较快的相对运动,在这种情况下,FPAE在拍摄出来的图像上极易发生运动模糊,因此,为验证RTFP方法中加入的运动模糊变换的有效性,本测试还进行了消融实验.也就是将完整的RTFP方法生成的FPAE与将RTFP方法中的运动模糊变换去除之后(将该方法记为RTFP-wmb方法)生成的FPAE使用同样的拍摄方法进行拍摄,然后测试这2种FPAE在各目标检测器上的ASR.图15是RTFP方法与RTFP-wmb方法生成的FPAE分别在15 km/h,20 km/h,25 km/h,30 km/h的行驶速度下对YOLOv3进行白盒攻击的ASR.从实验结果可以看出,完整的RTFP方法在目标模型上的ASR更高,说明完整的RTFP方法生成的FPAE的鲁棒性强于RTFP-wmb方法生成的FPAE.图16~19是RTFP方法与RTFP-wmb方法生成的FPAE分别在15 km/h,20 km/h,25 km/h,30 km/h的速度下对其他目标检测器进行黑盒攻击的ASR.从这4组对比结果可以看出,在不同的行驶速度下,RTFP方法生成的FPAE的ASR在Faster R-CNN ResNet-101,Faster R-CNN Inception v2,Mask R-CNN Inception v2这3个模型上的ASR较高,而在SSD Inception v2和SSD MobileNet v2这2个模型上的ASR与RTFP-wmb方法生成的FPAE的ASR大致相同,表明RTFP方法生成的FPAE只在部分模型上的迁移性强于RTFP-wmb生成的FPAE,这是因为RTFP方法中加入的运动模糊变换的主要作用是提高FPAE抵抗运动模糊的能力,也就是侧重于提高FPAE的鲁棒性,但是并不能显著提升FPAE的迁移性.图20是RTFP方法生成的FPAE成功欺骗YOLOv3目标检测器的样例帧.

Fig. 17 ASR of FPAE in the black-box attack test at speed of 20 km/h图17 速度为20 km/h时FPAE在黑盒攻击测试 中的ASR

Fig. 18 ASR of FPAE in the black-box attack test at speed of 25 km/h图18 速度为25 km/h时FPAE在黑盒攻击测试 中的ASR
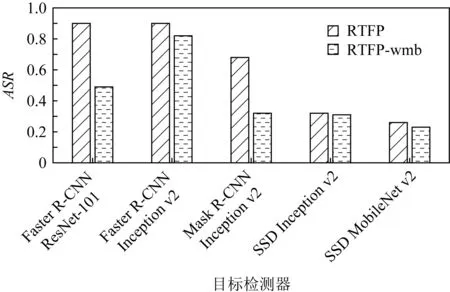
Fig. 19 ASR of FPAE in the black-box attack test at speed of 30 km/h图19 速度为30 km/h时FPAE在黑盒攻击测试 中的ASR

Fig. 20 Sample frames of FPAE successfully fool YOLOv3图20 FPAE成功欺骗YOLOv3目标检测器的 样例帧
5 结 论
本文提出一种可生成具有较强的鲁棒性和迁移性的假阳性对抗样本(FPAE)的RTFP方法,该方法在迭代优化过程中考虑了运动模糊对FPAE的攻击效果的影响,除了加入典型的图像变换方法之外,还新加入了运动模糊变换.此外,在设计损失函数时,借鉴了C&W攻击中损失函数的设计思想,将目标检测器在对抗样本所在位置预测出的多个边界框的类别损失设计为适用于生成FPAE的损失函数,并且为防止生成的FPAE出现过多的噪声像素点,在整个损失函数中加入了图像平滑度损失.本文在现实场景中对RTFP方法生成的FPAE进行了多角度、多距离的拍摄测试以及实际道路上的驾车拍摄测试,用每次拍摄得到的视频对目标模型YOLOv3和其他目标检测器分别进行了白盒攻击测试和黑盒攻击测试,并且与现有的AA方法生成的FPAE的攻击成功率进行了对比.在多角度、多距离的拍摄测试中,RTFP方法生成的FPAE在相对较远的距离和较大的偏转角度下依然可以欺骗YOLOv3以及其他目标检测器.实际道路上的驾车拍摄测试表明在4种不同的行驶速度下,RTFP方法生成的FPAE依然能够对YOLOv3和其他目标检测器进行欺骗,且攻击成功率高于现有的AA方法生成的FPAE的攻击成功率,并且,驾车拍摄测试中的消融实验表明RTFP方法生成的FPAE的鲁棒性强于不加入运动模糊变换的RTFP-wmb方法生成的FPAE的鲁棒性,说明了RTFP方法中所加入的运动模糊变换的有效性.综合的实验结果表明RTFP方法生成的FPAE具有较强的鲁棒性和迁移性.
作者贡献声明:袁小鑫进行文献调研,提出论文的创新点,负责实验的实施与分析以及论文的撰写;胡军提供选题来源,设计研究思路,指导实验的设计与论文的撰写;黄永洪提供选题来源,指导实验设计,参加论文研讨.
