一种适用于分布式存储集群的纠删码数据更新方法
2022-11-11章紫琳谭玉娟罗龙攀王纬略
章紫琳 刘 铎 谭玉娟 吴 宇 罗龙攀 王纬略 乔 磊
1(重庆大学计算机学院 重庆 400044) 2(北京控制工程研究所 北京 100080)
分布式存储集群(如Azure[1],HDFS(Hadoop distributed storage system),Dynamo[2]等)多数采用大量的跨地域节点存储海量数据并提供数据访问服务.这些服务节点的失效率很高[3-4],为了提供容错能力,传统的存储集群普遍采用存储开销成倍增长的多副本技术。而纠删码在保证同等的容错性能时,能尽可能减少存储开销[5-6],因此目前大多数存储集群结合纠删码来保证数据的可靠性及可用性[7-10].
然而数据更新时,结合纠删码的分布式存储集群的磁盘I/O开销至少是采用多副本技术的存储集群的2倍.原因在于纠删码是将原始数据分块得到数据块,再对数据块进行线性计算得到校验块.当数据块更新时,校验块也需要重新编码计算,这会导致额外的磁盘I/O开销[11],特别是更新数据块的一小部分时,磁盘I/O开销更高.而在真实工作负载下如MSR Cambridge traces[12],所有更新请求的大小都小于512 KB,其中大部分轨迹(trace)超过60%的更新请求小于4 KB;在Harvard NFS traces[13]中,平均更新大小为10.58 KB,并且在所有写请求中,超过91%的请求都是更新请求(除去第1次写请求)[14].由此可见存储集群的更新操作是频繁的且小写请求占大部分,因此降低纠删码数据更新的磁盘I/O开销对分布式存储集群写性能的提升至关重要.
存储集群中纠删码数据更新方式主要分为2种:即时更新和基于日志更新[15].前者指每次更新都会立即将新的数据写入块中,在更新密集的存储集群中这种频繁地写磁盘会严重影响系统的性能;后者是将新的数据写入日志中,当有需要或者系统空闲时进行日志重播.经典的分布式文件系统如GFS(Google file system)[16]就是采用基于日志的更新方式.这2种更新方式也可以结合,如在PL(parity logging)[17-18]更新方法中,数据块是即时更新,校验块是基于日志更新.这样既保证了数据块实时更新的需求,又降低了频繁写校验块的磁盘I/O开销.
然而,现有的基于日志的数据更新方法都没有同时克服2个缺陷:1)每次更新时需要对数据块执行读后写操作,例如PLR(parity logging with reserved space)[14]及FO(full overwrite)[19]策略,每次计算校验增量时需要先读取原始数据块再写入新的数据.经过在7 200 r/min的硬盘驱动器(hard disk drive, HDD)上的测试,这种读后写操作大约需要8.3 ms,是高于纯写的延时(由于更多的磁盘寻道)[20],这导致PLR的随机写和顺序写的性能有时仍然低于传统的PL策略.2)读写日志时需要额外的磁盘寻道开销[21],例如PARIX(speculative partial write)[20]策略,其在预测失败的情况下,由于需要向日志写入原始数据块,额外的磁盘寻道开销使得随机I/O延时略高于传统的PL策略.以上两者是影响分布式存储集群写性能的重要因素,大多数基于日志的更新策略没有同时兼顾这两者的优化,导致其更新吞吐率远不如副本.
因此,本文针对这个问题提出了PARD(parity logging with reserved space and data delta)数据更新方法,从减少读后写操作和磁盘寻道开销2个方面来极大化纠删码存储集群的数据更新性能.首先根据数据块和校验块的访问频率不一样,采用数据块即时更新、校验块日志重播更新的方式;其次利用计算校验块的算术特性构建基于数据增量的日志,使得在多次更新中只有第1次更新需要读取原始数据块,后续的更新直接向数据节点写入新的数据,避免每次更新都要读取原始数据块再写入新的数据所带来的读后写开销;最后,在校验数据末尾为日志预留空间,以此减少读写日志的磁盘寻道开销.本文的贡献有2个方面:
1) 提出PARD数据更新方法,采用基于数据增量的日志和预留空间的方式减少分布式存储集群中纠删码数据更新时的磁盘I/O开销.
2) 设计PARD实验原型,用真实工作负载下的轨迹对PARD进行性能评估,并与多种最新的数据更新策略如PLR,PARIX,FO进行比较.
1 背景与相关工作
1.1 纠删码基本原理
纠删码首先将原始数据划分成k个同等大小的数据块,然后在有限域GF(2w)(一般w=8)内对数据块进行编码运算得到m个校验块.如图1所示,以经典的RS(Reed-Solomon)(k+m,k)[22-23]纠删码为例描述纠删码编码的基本原理.RS(6,4)将原始数据划分成4个数据块Dj,j=1,2,3,4,编码得到的校验块为Pi,i=1,2,eij为Pi在生成矩阵中对应Dj的编码系数,为1个常量.由此可见,每个校验块都是数据块线性运算的结果,且涉及的运算一般是有限域的加法和乘法[24].

Fig. 1 Basic principle of erasure coding encoding图1 纠删码编码基本原理

(1)
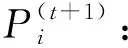
(2)
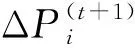
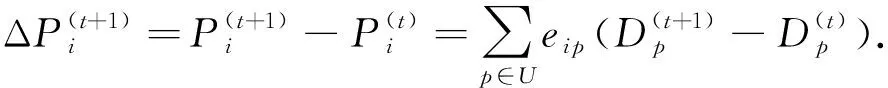
(3)
基本的FO[19]策略即采用式(2)实现数据更新,更新流程示例如图2所示.假设每个节点均保存4个块,编码块间的运算为ai+bi=c1i,ai-bi=c2i,其中i=1,2,3,4.第t+1次更新数据块b3的一部分时,首先需要读取原始数据块来计算校验增量,再写入新的数据块;每更新1个校验块,校验节点需要先读取原始校验块,将其和接收的校验增量执行异或运算获得新的校验块,再写入指定偏移处.整个过程总共4次磁盘访问.
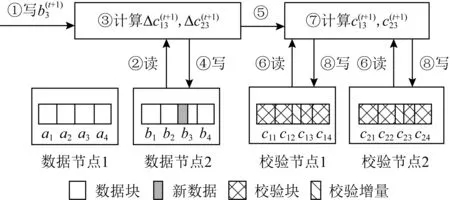
Fig. 2 Data update process in erasure coding with RS(4,2)图2 以RS(4,2)为例的纠删码数据更新流程
为了减少磁盘访问,目前的数据更新策略都会利用纠删码线性运算的特性.如传统的PL策略利用式(2)构建基于校验增量的日志进行数据更新,将对校验块的随机写转换为对日志的顺序写[17-18].即每次更新都会将此次更新的校验增量追加写入日志中,日志满时再将原始校验块和日志中的增量进行线性运算得到最新的校验块,避免频繁地读写校验块.本文也会围绕这个特性来进一步优化数据更新性能.
1.2 相关工作
1.2.1 磁盘阵列系统中的数据更新策略
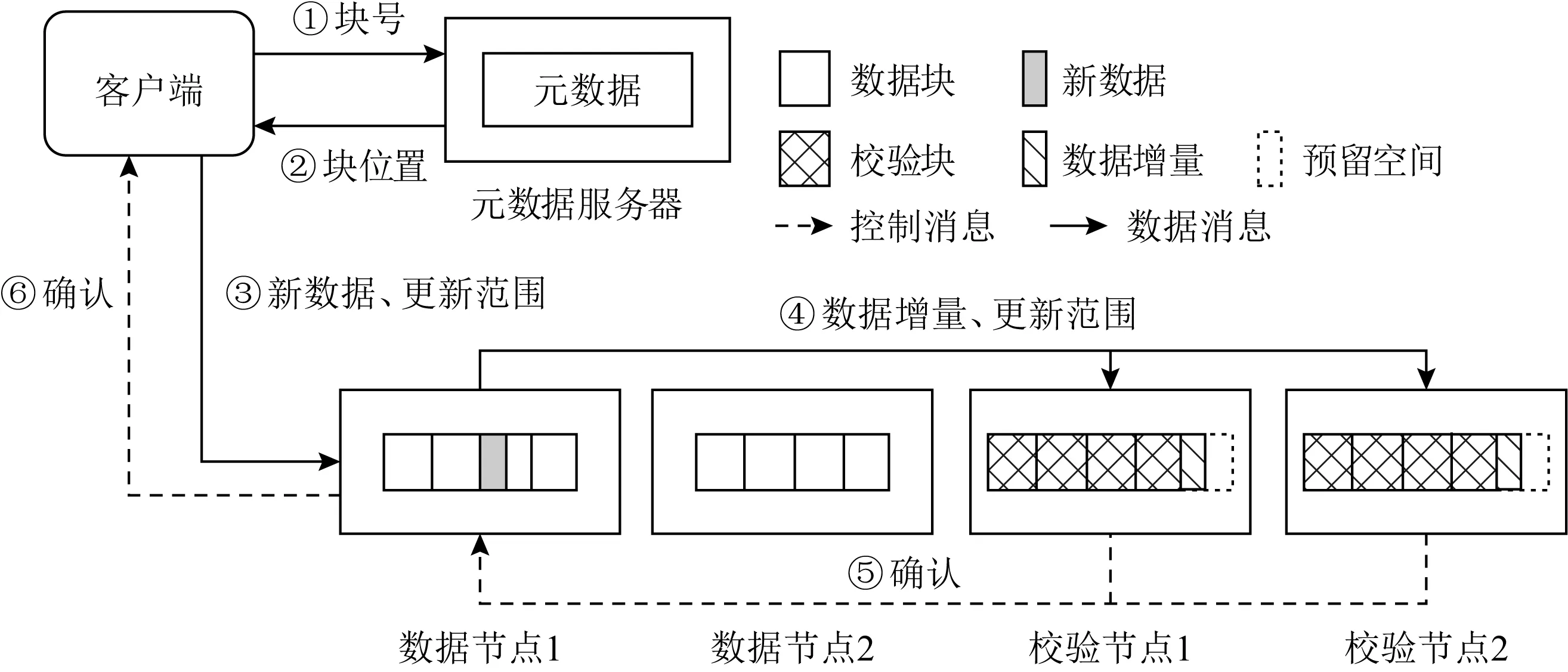
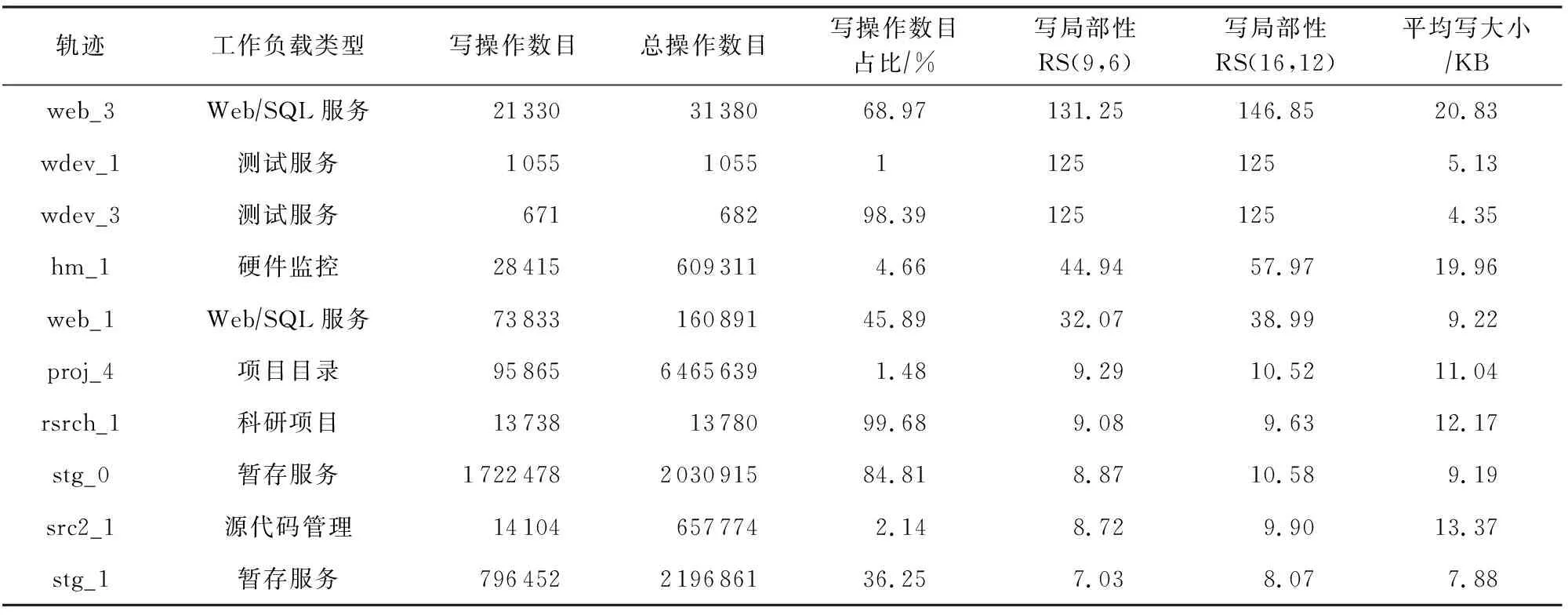
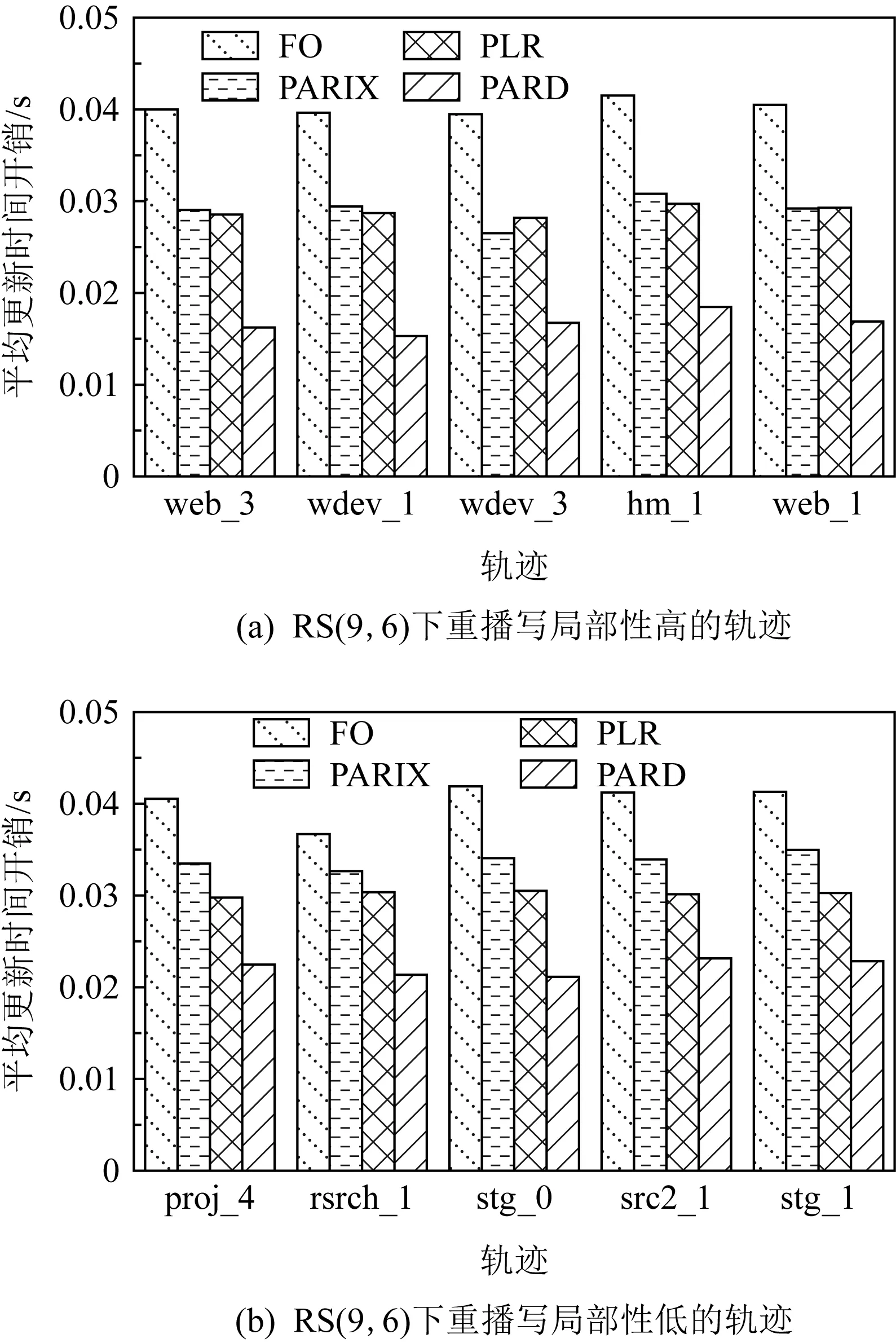
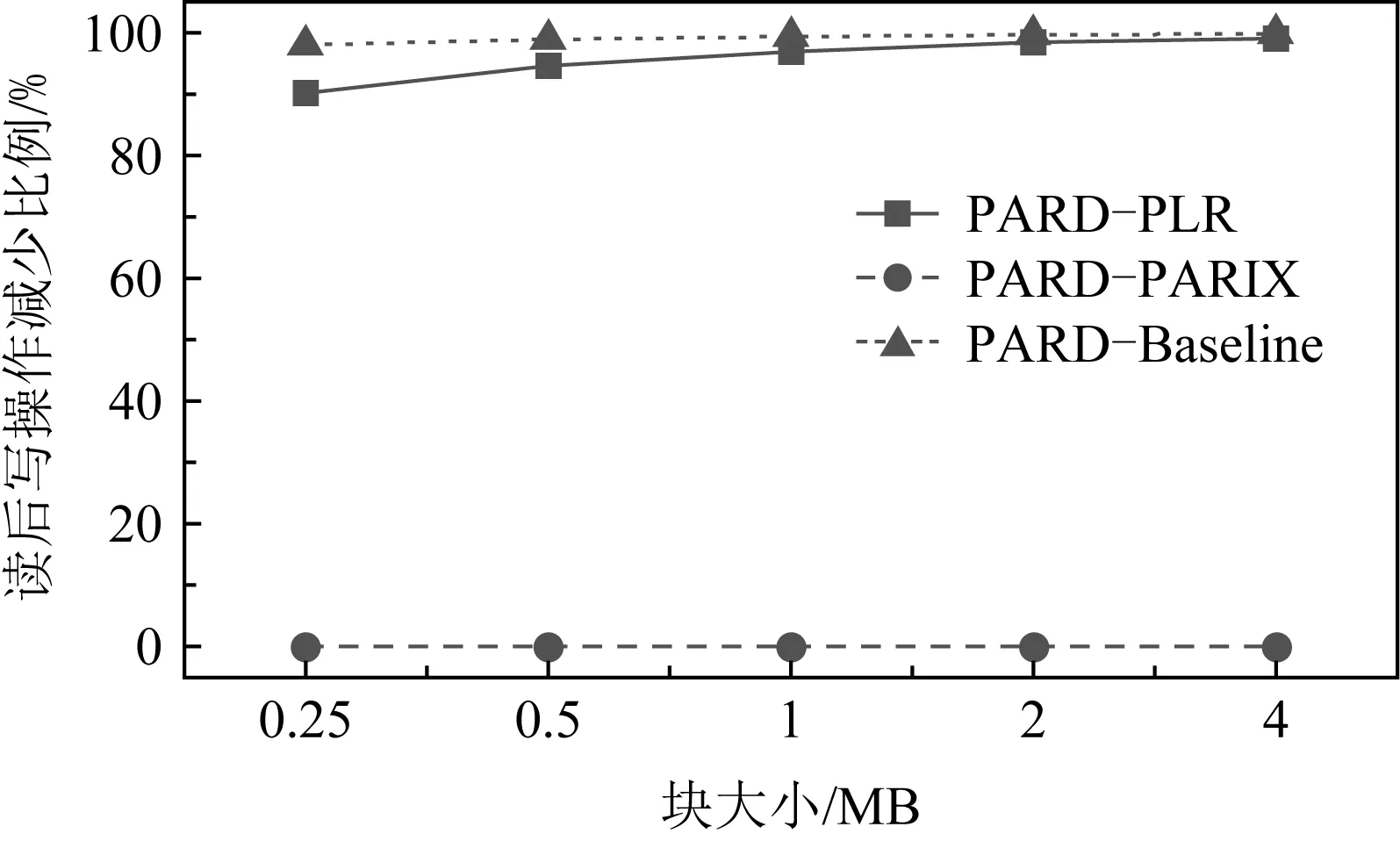
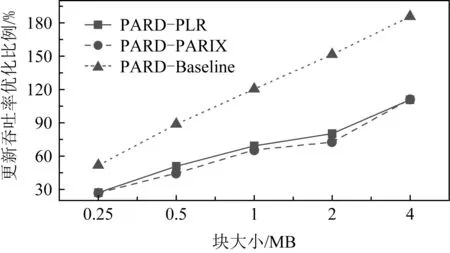
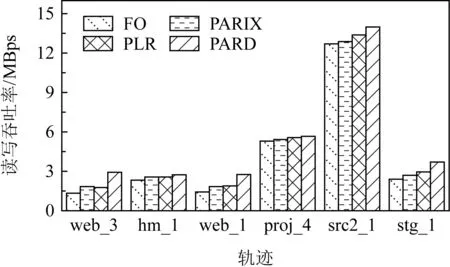
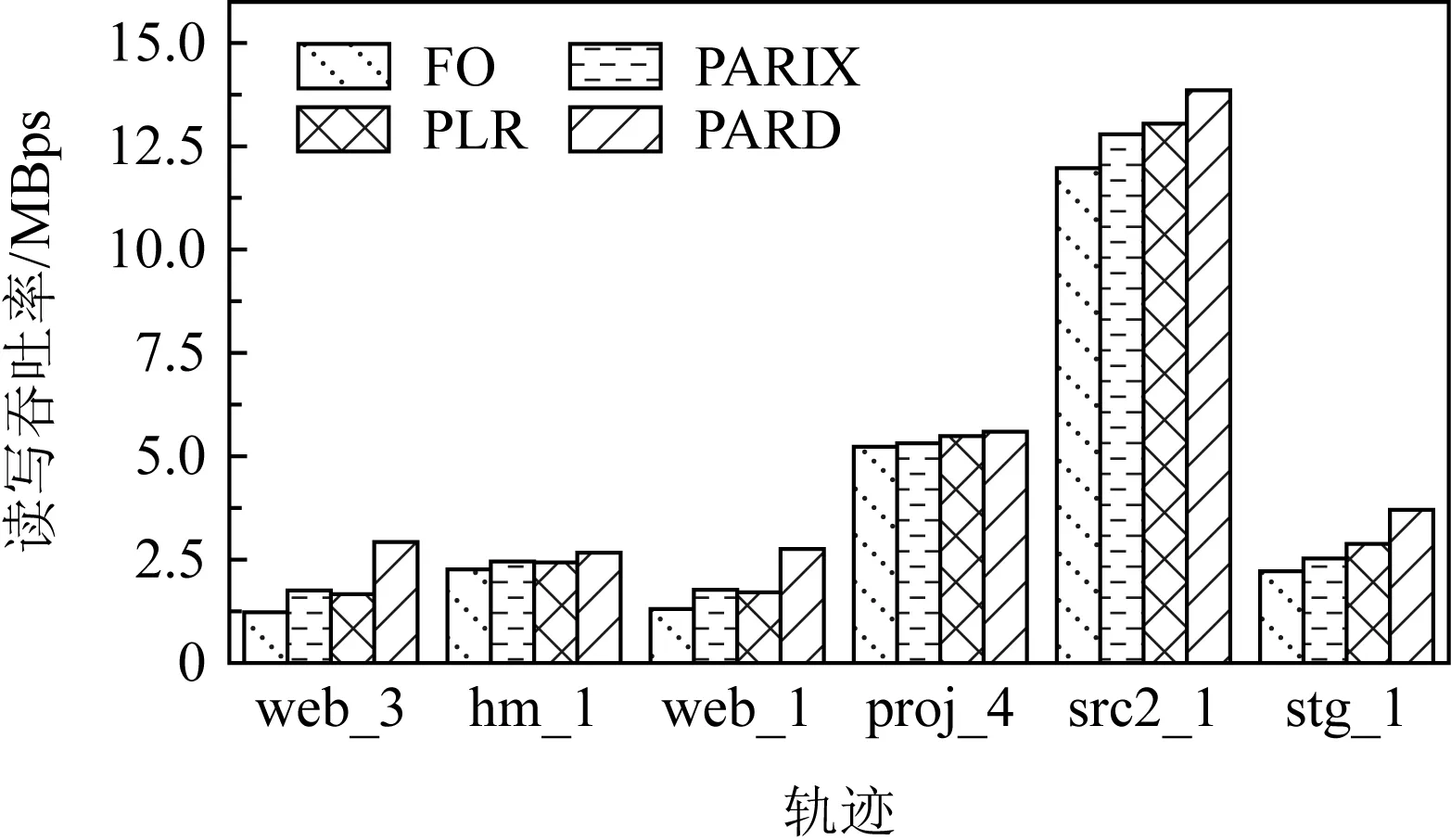
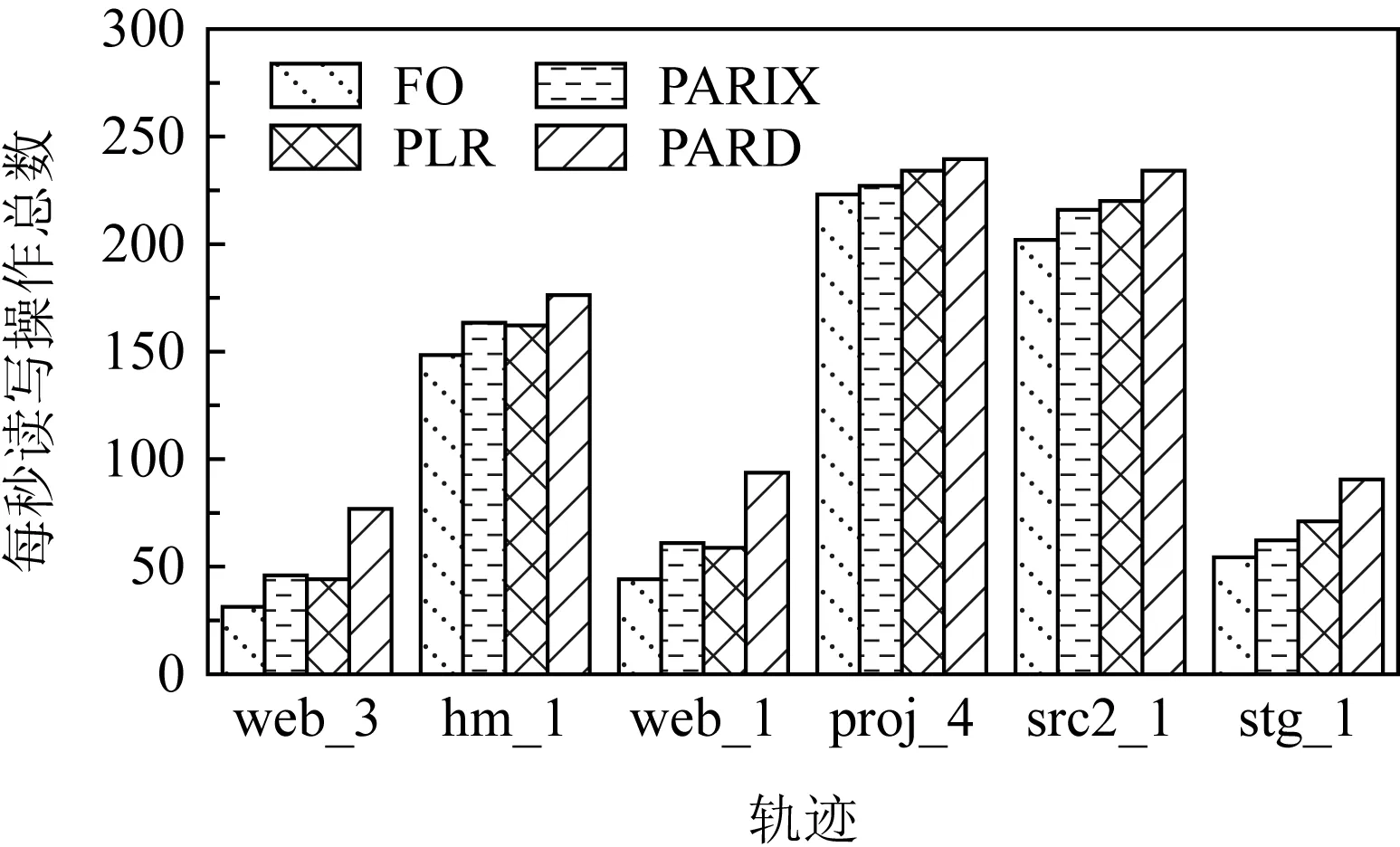
磁盘阵列系统的数据更新策略主要分为满条带写(full-stripes writes)、重构写(reconstruct writes, RCW)、读修改写(read-modify writes, RMW).假设1个条带分为k个数据块和m个校验块,满条带写[25]指的是对整条条带进行更新,适用于更新所有数据块的情况.满条带写将新的数据块编码得到新的校验块,不需要额外地读写数据块或者校验块,性能达到最优.RCW[26]适用于更新i(0 为了降低小写惩罚,LSA(log-structured arrays)采取的策略是将多个小更新缓存到DAC cache中[28],最后聚合到一起进行满条带更新.Fu等人[29]构造出Short Code编码方式,通过在磁盘阵列中添加对角校验元素来减少更新时的磁盘I/O.与Fu等人不同的是,Wu等人[30]提出一种基于异或运算的混合码(hybrid code, H-Code),将反对角校验元素分布在磁盘阵列中,实现了更加均衡的I/O分布,并保证任意2个连续的数据元素能够和同一个校验元素相关联.Shen等人[31]将共享校验元素的思想延伸到采用任意一种异或纠删码的磁盘阵列中,通过PDP(parity-switched data placement)数据布局算法来保证任意2个连续的数据元素在同一个校验链中.Du等人[32]则根据小写I/O的分布特征来调整数据块的存储位置,通过校验共享来最小化写校验块数目,并在这个阶段将待迁移的数据块和即将到来的写请求进行聚合.文献[28-32]都是将同一个校验链的多个小写请求聚合成1个大写请求,从而减少写校验块的磁盘I/O.而DCD(disk cache disk)[33]结合智能缓存的思想达到写聚合,降低了磁盘读写I/O,提升小写性能.对于基于固态硬盘的磁盘阵列,Wu等人[34]将小写请求缓存在作为镜像缓存区的日志磁盘中,再将他们合并成对固态硬盘的大写请求. 文献[28-34]的更新策略均是采用写聚合的思想来降低小写惩罚.针对于内存存储,Huang等人[35]则根据分组的思想提出GU(grouped-updating)更新机制,思想是在内存中将更新请求分组,1个组中的多个小更新可以并发执行,从而降低更新延时. 然而运用在磁盘阵列系统上的数据更新策略都有一定的局限性,如日志文件系统(log-structured file system, LFS)[15]中的满条带写将每个磁盘看作可追加的日志,每次更新都将新的数据附在末尾,使得检索更新时需要额外的磁盘寻道开销[21].而RMW和RCW是针对单机设计的更新策略,在数据块和校验块分布在跨地域机器的分布式环境下,RMW和RCW的性能显著降低[36].其他的策略也是针对磁盘阵列所设计的,不能很好地适应分布式环境. 1.2.2 分布式环境中的数据更新策略 为了适应存储集群的分布式环境,目前有许多基于校验增量的数据更新方法,如FO,FL(full logging),PL等,这些更新方法都利用了纠删码线性运算的特性.每次更新时,数据节点会读取被修改范围的原始数据并将原始数据和新的数据进行线性运算得出校验增量;然后数据节点再在指定偏移处写入新的数据并将校验增量发送给校验节点;校验节点接收到数据节点传输的校验增量后,根据具体的更新策略进行即时更新或将其写入日志中. FO[19]是最简单易实现的基于校验增量的数据更新策略,数据块和校验块均采用即时更新.任意时刻,数据块和校验块的版本都是最新的,保证了数据的一致性.然而频繁地读写磁盘导致更新性能低下,类似于磁盘阵列系统中的RMW策略[26],存在小写惩罚的问题. 而FL[1,16]通过日志的方式将大量对数据块的随机小写操作转换为对日志的顺序写操作,避免了频繁的磁盘寻道,从而降低了写时的磁盘I/O开销.但是在真实情况下,数据块是热数据,访问频率很高.每次读数据块FL都需要重播日志得到最新的数据,即将随机分布在日志中的所有更新数据读出来和数据块进行合并[37],这仍然需要频繁的读写操作,会严重滞后读取性能. 鉴于FO中的小写惩罚问题及FL只适用于读写冷数据的问题,Stodolsky等人[18]提出只包含校验增量日志的PL更新策略.PL结合了FO和FL的思想,采用数据块即时更新、校验块基于日志更新的方式.既减少了写操作时读写校验块的磁盘I/O开销,又提升了后续读数据块的性能,但是合并日志中的校验增量时仍然需要额外的磁盘寻道开销.为了解决这一问题,PLR[14]在每个校验块末尾预留空间(默认为块大小)作为日志用途,使得校验块和日志中的校验增量可以被顺序检索. FO,FL,PL和PLR的数据更新策略均是基于校验增量.每次更新时,为了得到校验增量,数据节点均需要读取原始数据再写入新的数据,频繁的读后写操作严重滞后了存储集群的更新性能.为了减少读后写操作,近几年提出的PARIX[20]采用基于数据增量的更新方式.在连续多次更新中,数据节点只在第1次更新时有读后写操作,后续只写入新的数据.在日志重播时,校验节点利用日志中的数据增量即可获得最新的校验块. FO,FL,PL,PLR和PARIX策略均是对磁盘I/O的优化,而针对跨机架环境,小写操作的网络传输开销也是影响更新性能的重要因素.针对这一问题,Zhang等人[38]提出PUM-P和PDN-P更新策略.PUM-P是将计算增量的任务交给管理节点,管理节点再将校验增量传输给每个校验节点,减少了读取原始校验块的网络传输开销;PDN-P是将计算增量的任务交给数据节点,数据节点再向校验节点发送计算结果,减少了读取原始数据块的网络传输开销.然而PUM-P和PDN-P更新策略采用的是星型数据传输结构,没有充分利用各节点间的带宽,发送校验增量的节点甚至会成为网络瓶颈,导致网络拥塞情况的出现.T-Update[39]和TA-Update[40]利用自顶向下的树型传输结构,充分利用各节点间的带宽资源来传输增量,消除了星型结构的网络瓶颈问题. 然而PUM-P,PDN-P,T-Update,TA-Update策略只适用于单节点更新,而对于多节点小写更新,CASO(correlation-aware stripe organization)[41]根据更新数据的相关性来组织条带,将关联的数据放在1个条带内,减少小写更新时数据节点和校验节点间的网络传输.CAU(cross-rack-aware updates)[42]则借鉴PARIX的思想来降低数据节点和校验节点间的网络传输,在多次更新中,数据节点根据原始数据和最新的数据计算出增量,并向每个校验节点传输1次数据增量. Fig. 3 Update throughput when using four update strategies to replay traces图3 在4种更新策略下重播轨迹的更新吞吐率 为了探索影响分布式存储集群的纠删码数据更新性能的主要因素,本文在6台机器上对FO,PL,PLR和PARIX策略进行了更新性能对比实验(在多数情况下,数据块的访问频率很高,目前普遍采用PL策略而不是FL策略,所以此处不与FL策略比较).图3是在RS(4,2)的配置下,采用不同更新策略重播4个轨迹wdev_1,wdev_3,rsrch_1,src2_1的更新吞吐率.实验结果表明,FO的更新性能是最差的,这也和之前的分析相符;PARIX和PLR实现了最高的更新吞吐率,说明磁盘寻道和读后写操作是影响分布式存储集群更新性能的主要因素. 为了更直观地验证图3的结论,本文利用filefrag-v命令记录了在不同的更新策略下重播每个轨迹后所有数据文件和日志文件的磁盘碎片数(碎片数目高表示磁盘寻道开销大).由于4个轨迹的大致规律相同,本文只展示重播rsrch_1的碎片数目以及读后写操作数目,如表1所示.实验结果表明,和FO相较,PARIX有少量的碎片但是读后写操作数目最少,实现了最优的更新性能;而PLR虽然没有碎片,但是读后写操作数目的减少比例没有PARIX高,更新性能和PARIX近似;此外,PLR在PL的基础上采用预留空间的方式降低磁盘寻道开销从而提升了更新性能.以上结论再次验证了磁盘寻道和读后写操作是影响存储集群更新性能的主要因素. Table 1 Numbers of Fragments and Write-After-Read When Replaying rsrch_1 综上所述,PLR和PARIX是目前最优的更新策略.但是PLR仍然需要额外地读取原始数据块,再写入新的数据,大量的读后写操作降低了更新吞吐率.而PARIX也有少量的碎片,导致合并日志时需要额外的磁盘寻道开销,对更新性能有一定的影响.因此,为了更进一步地提升纠删码存储集群的数据更新性能,本文将这2种策略进行结合,从减少数据更新时的读后写操作和读写日志时的磁盘寻道开销2方面来优化数据更新性能. 本文提出一种新型的适用于大规模分布式存储集群的纠删码数据更新方法,目的在于减少数据更新路径上的读后写操作和进一步更新校验块的磁盘寻道开销.本文的PARD方法主要从2方面来提升更新性能: 1) 构建基于数据增量的日志.利用纠删码计算的线性特性构建基于数据增量的日志,使得每次更新数据块时只需要写数据节点(除了第1次更新需要读取原始数据块并写入新的数据),减少传统的FO,PLR等更新策略中对数据块的读后写操作. 2) 在校验块末尾为日志预留空间(默认为块大小).将数据节点传输的原始数据和新的数据顺序写入预留的日志空间中,使得日志重播时校验块和日志中的数据增量能被顺序检索,从而降低磁盘寻道开销. 正如1.2节所述,基于校验增量的更新策略的日志是存储如式(3)的校验增量,这种策略的弊端在于频繁的读后写操作.因为获得校验增量需要先从数据节点读取原始数据块,计算得到校验增量后再写入新的数据.针对这一问题,本文将采用基于数据增量的日志来尽量避免读取原始数据块的操作,实现纯写. (4) 正如图4所示(为了简洁,图4中省略了下标p),根据基于校验增量的日志进行数据更新的策略每次更新都需要从数据节点读取当前的原始数据块,再写入新的数据,最后将校验增量写入校验节点的日志中;而根据基于数据增量的日志进行校验更新的策略只有在第1次更新时需读取原始数据块,后续的更新只需对数据节点执行纯写.最终,日志中存放的数据是D(0),D(1),….触发日志合并的条件可设为更新数据大小或更新条带数达到阈值,校验节点合并完日志获得最新的校验块后会清空日志中的数据.下次更新时,校验节点又向数据节点发送1个请求当前原始数据块D′(0)(此时数据块已发生变化,记为D′)的标志位,并将新的增量写入日志. Fig. 4 Comparison between log based on parity delta and log based on data delta图4 基于校验增量的日志和基于数据增量的日志的区别 综上所述,基于数据增量的日志相较基于校验增量的日志显著减少了读后写操作.唯一的开销是第1次更新或者合并完日志后,数据节点需要向校验节点传输原始数据块.这需要1段额外的网络往返时延(round-trip time,RTT),RTT的取值范围是0.1~0.2 ms[20],在现代的网络环境下这是微不足道的开销,不会影响本文方法的更新性能. 1.2节中的FL,PL,PARIX更新策略的日志文件和存放编码块的数据文件是不同的,即两者在磁盘存放的物理位置不连续.合并日志时,校验节点需要读取随机分布在日志文件中的所有增量并将其和数据文件进行合并,这引入了额外的磁盘寻道开销.针对这一问题,本文采用为日志预留空间的策略,使增量和校验块可以被顺序检索,从而降低磁盘寻道时间. 本文将采用预留空间的PARD方法和最基本的数据更新策略(FO)、最新的数据更新策略(PLR,PARIX)进行了示例对比,如图5所示.以RS(3,2)为例,假设数据节点1和数据节点2均保存2个数据块,且均有1处数据更新,分别在第1个数据块和第2个数据块. FO策略是在指定偏移处即时更新数据块和校验块,保证了数据块和校验块的实时一致性.但是每次更新都需读写原始数据块、原始校验块,磁盘I/O开销是副本的4倍.对于磁盘I/O是性能瓶颈的纠删码存储集群,采用FO数据更新策略会严重影响系统的读写性能. PLR策略和FO的不同之处在于PLR是将大量对校验块的小写操作转换为对日志的顺序写操作.每次更新时PLR会将此次更新的校验增量写入日志,等到日志满时再将其和数据文件进行合并获取最新的校验块.由此对同一校验块的更新可批量处理,降低了数据更新时读写校验块的磁盘I/O开销.此外,PLR采用在校验数据末尾为日志预留空间的方式减少了校验节点合并日志的磁盘寻道开销. Fig. 5 Comparison of update illustrations between PARD and other data update strategies图5 PARD方法和其他数据更新策略的更新示例对比 Fig. 6 Architecture of PARD with RS(4,2)图6 以RS(4,2)为例的PARD体系架构 PARIX策略和FO策略、PLR策略的区别在于每次更新写入日志的是数据增量而不是校验增量,正如2.1节所述,这从根本上减少了对数据块的读后写操作.但是由于没有给日志预留空间,合并日志时仍然需要额外的磁盘寻道开销. 本文的PARD方法采用基于数据增量的日志和在校验数据末尾为日志预留空间的方式,减少了更新路径上的读后写操作以及后续更新校验块时合并日志的磁盘寻道开销,极大限度地提升了存储集群的纠删码数据更新性能. 采用PARD方法进行数据更新的体系架构如图6所示.客户端负责向整个集群发起写请求.元数据服务器根据数据块号计算其对应的条带号,并将其存放的数据节点、相应的校验块存放的校验节点的位置信息及存放的具体偏移保存在元数据信息中.数据节点保存数据块,校验节点保存校验块,并将数据节点传输的增量写入预留的日志空间内.校验节点记录了3类元数据用于合并日志:记录更新条带号和更新条带数目的更新条带元数据;记录增量在预留空间的偏移和长度的增量元数据;记录原始数据块在预留空间的偏移和长度的原始数据块元数据. 1次更新请求的执行流程包括6个步骤. 1) 客户端将对指定数据块的写请求发送给元数据服务器. 2) 元数据服务器根据数据块号返回其所在的位置信息,以及对应的校验块的位置信息. 3) 客户端根据这些元数据向对应的数据节点发起更新请求,并向数据节点转发新的数据及其在数据块中偏移和长度等信息. 4) 数据节点将新的数据写入指定的偏移处,并将数据增量及更新范围等信息转发给对应的校验节点. 5) 校验节点接收到数据增量后,主要执行3个步骤: ① 判断当前是否需要合并日志.本文默认更新数据量达到预留空间的大小即预留空间满时合并日志.校验节点根据本地管理的更新条带元数据、增量元数据、原始数据块元数据进行逐条带校验更新,合并完日志后,以上元数据都将恢复成初始状态. ② 将新的数据以追加的方式写入本地预留的日志空间中,并且将数据节点传输的更新条带号、数据块号、更新范围等分别记录在更新条带元数据和增量元数据中. ③ 根据原始数据块元数据判断待更新的数据所在的原始数据块是否已读取.如果没有则向数据节点发送需要原始数据块的标志位.数据节点侦听到标志位后,将整个块读取出来并传输给校验节点.校验节点再将原始数据块写入日志中并更新原始数据块元数据. 6) 校验节点向数据节点上报更新完成的答复信息,数据节点再向客户端发送确认.需要说明的是,为了模拟数据,本文在数据节点采用fallocate命令产生了60 GB的数据文件,在校验节点采用fallocate命令产生总大小为60 GB+预留空间的数据文件.本文的预留空间默认为块大小即4 MB,所以PARD方法的预留空间开销和数据文件相较忽略不计.在校验节点中,数据增量包含2种数据:新的数据和原始数据块.为了区分两者,本文将新的数据存放在数据文件预留的日志空间内,原始数据块存放在另一个预留的日志空间内. 本节实验在18台虚拟机上进行,每台机器运行Ubuntu 20.04.1 LTS,配有2.40 GHz的Xeon Silver 4210R CPU,125 GB内存,7 200r/min的硬盘(1T B).首先,本节基于2.3节的体系架构设计了PARD实验原型,并实现了PARD,PLR,PARIX及基本的FO策略;然后在商业界普遍采用的2种编码配置即RS(9,6)和RS(16,12)下对实验采用的轨迹进行分析,主要研究真实工作负载下写请求的规律;最后分析编码配置、轨迹的更新密集度、块大小对PARD的更新吞吐率、每秒完成的写操作数、读后写操作数的影响,并与基本的FO更新策略及最新的PLR,PARIX更新策略比较. 为了模拟真实负载环境下的数据更新,实验采用Microsoft Research Cambridge发布的块级磁盘I/O轨迹[12]来测试更新策略的性能.该轨迹集记录了1周内,外部对存储集群中36个卷的I/O请求.每个轨迹包含时间戳、主机名、磁盘号、读写类型、写偏移、写大小及响应时间.为了反映不同轨迹的更新密集度,本文定义1个称为写局部性的变量,并且将1个轨迹的写请求划分为n个工作集,每个工作集包含a个连续写请求.假设每个工作集对应的更新条带数为si(1≤i≤n),则写局部性可表示为 (5) ∂越大,代表该轨迹的写局部性越高即更新密集度越高. 默认块大小为4 MB,a=500,本文在RS(9,6)和RS(16,12)两种配置下测量轨迹的写局部性.为了限制后续测试更新性能的实验周期,本文选取了5个写局部性最高的和5个写局部性最低的轨迹,如表2所示.写操作数目指该轨迹中写请求的数目,总操作数目指所有读写请求数目,写操作数目占比指写请求在所有请求中的占比.它们的写操作数目在600~2 000 000之间并且涵盖了多种工作负载类型,表明PARD方法不局限于特定工作负载下的纠删码数据更新.表2中所有轨迹的平均写大小均小于21 KB,说明大部分写请求都是小写.其中web_3的写局部性最高,RS(9,6)配置下每500个写请求平均有3.8(a/∂=3.8)个条带更新.而对于写局部性最低的stg_1,每500个写请求平均覆盖71.1个条带,更新范围最广.此外,RS(16,12)配置下的写局部性比RS(9,6)的大,原因是数据块增多,1个条带的数据范围更广. 本节首先将轨迹的写偏移及写大小按照4 MB划分,为了和轨迹中最大的写偏移对应,实验采用fallocate命令在每个数据节点上产生60 GB的数据文件,由此,客户端顺序重播轨迹中的写请求时,每个写请求都会作为更新请求处理并触发校验更新.每个校验节点也采用fallocate命令产生总大小为60 GB+预留空间(默认为块大小即4 MB)的数据文件,校验更新时根据所采用的更新策略将增量写入相应的文件或即时更新.实验默认当更新数据量达到预留空间的大小时触发合并日志操作,并在合并完成时将日志格式化回到初始状态.在每次重播前,为了保证数据更新性能只受更新策略的影响,每个校验节点上的日志文件也会清空. Table 2 Analysis for 10 Traces表2 对10个轨迹的分析 3.2.1 RS(9,6)下更新密集度实验 图7是在RS(9,6)下,重播不同写局部性的轨迹时,不同更新策略的平均更新时间开销比较,平均更新时间指总更新时间除以更新操作数.图7表明在所有的轨迹中,PARD实现了最低的平均更新时间开销,相较于FO,PARIX,PLR分别平均减少了46.8%,38.3%,34.3%.当重播写局部性高的轨迹时PARD的优化效果更显著.例如当重播wdev_1时,PARD的平均更新时间开销相较于FO,PARIX,PLR分别减少了61.5%,48.1%,46.8%;而对于stg_0,PARD相较于FO,PARIX,PLR分别减少了49.5%,38.0%,30.7%. Fig. 7 Average update time when replaying traces with RS(9,6)图7 RS(9,6)下重播不同轨迹的平均更新时间开销 在图7(a)中,FO的平均更新时间稳定在0.040 s左右;PARIX,PLR的平均更新时间都稳定在0.029 s左右,两者更新时间开销差距不大,这是因为PLR采用预留空间的技术减少了磁盘寻道开销,但是读后写操作数目的减少比例没有PARIX高,平均更新时间开销和PARIX近似;PARD的平均更新时间稳定在0.017 s左右.在图7(b)中,FO的平均更新时间仍然稳定在0.040 s左右;PARIX,PLR的平均更新时间都稳定在0.032 s左右;PARD的平均更新时间稳定在0.022 s左右.对于PARIX,PLR,PARD,图7(a)中的平均更新时间开销的稳定值低于图7(b)的平均更新时间开销的稳定值,这是因为重播写局部性高的轨迹时,更多的写请求可以被批量处理,读取原始数据块或校验块的磁盘I/O数降低,导致更新时间降低. 图8是在RS(9,6)下,重播不同写局部性的轨迹时,不同更新策略的更新吞吐率比较.图8表明在所有轨迹中,PARD达到了最高的更新吞吐率,相较于FO,PARIX,PLR分别平均提升了112%,63.3%,54.8%.当重播写局部性高的轨迹时PARD的优化效果更显著.例如当重播wdev_1时,PARD相较于FO,PARIX,PLR分别提升了160%,92.6%,87.9%;而对于stg_0,PARD相较于FO,PARIX,PLR分别提升了97.9%,61.2%,44.3%.这是因为当客户端对同一条带发起连续多个更新请求时,每个数据节点只需要向校验节点发送1次原始数据块;而对于写局部性低的轨迹,客户端每次都向不同的条带发起更新请求.数据节点向校验节点传输原始数据次数增加,导致性能优化比例降低,但是PARD仍然显著提升了更新性能. Fig. 8 Update throughput when replaying traces with RS(9,6)图8 RS(9,6)下重播不同轨迹的更新吞吐率 图9是重播不同写局部性的轨迹时,不同更新策略每秒完成的写操作数的比较.从总体来看,重播不同轨迹时FO和PLR的每秒写操作总数波动较小.而图9(a)中PARIX和PARD的每秒写操作总数略高于图9(b),提升比例分别为17.0%和33.0%.原因在于重播写局部性高的轨迹时,对同一条带的连续多个写请求可被批量处理,使得日志重播时只需要读取1次原始数据块和校验块;而写局部性低的轨迹的写请求对应多个不同的条带,校验更新时需要读取多次数据块和校验块,I/O开销增大.重播写局部性高的轨迹时,PARD相较于其他策略平均提升了73.1%~141%;而重播写局部性低的轨迹时,PARD平均提升了36.4%~82.0%. Fig. 9 Aggregate numbers of write completed per second when replaying traces with RS(9,6)图9 RS(9,6)下重播不同轨迹的每秒写操作总数 3.2.2 RS(16,12)下更新密集度实验 图10是在RS(16,12)下,重播不同写局部性的轨迹时,不同更新策略的平均更新时间开销的比较.和RS(9,6)相较,RS(16,12)下PARD的优化效果更显著.在所有轨迹中,PARD的更新时间开销相较于FO,PARIX,PLR分别平均减少了47.9%,41.2%,36.3%.这是由于RS(16,12)的数据块增多,几乎所有轨迹的写局部性都得到提升(如表2所示),更多的写请求可以被批量处理导致RS(16,12)下PARD的优化效果更显著. 和RS(9,6)相较,重播相同的轨迹时,RS(16,12)下每种策略的平均更新时间开销增加.例如,在图10(a)中,FO的平均更新时间稳定在0.044 s左右;PARIX,PLR的平均更新时间都稳定在0.032 s左右;PARD的平均更新时间稳定在0.018 s左右.而在图7(a)中,FO的平均更新时间稳定在0.040 s左右;PARIX,PLR的平均更新时间都稳定在0.029 s左右;PARD的平均更新时间稳定在0.017 s左右.这是因为RS(16,12)下需更新的校验块增多,磁盘I/O开销增加,导致平均更新时间增加. 其他的大致规律和RS(9,6)下的相同,如重播写局部性高的轨迹时PARD相较于其他策略的减少比例更高.例如当重播wdev_1时,PARD的平均更新时间开销相较于FO,PARIX,PLR分别减少了65.0%,52.7%,52.5%;而对于stg_0,PARD相较于FO,PARIX,PLR分别减少了49.5%,40.4%,31.8%. 此外,对于PARIX,PLR,PARD,图10(a)中的平均更新时间开销低于图10(b),而FO的大致相同. 图11是在RS(16,12)下,4种更新策略重播不同轨迹的更新吞吐率的比较.和RS(9,6)相较,RS(16,12)下PARD的优化效果更显著,其更新吞吐率相较于FO,PARIX,PLR分别平均提升了118%,72.8%,60.6%.这也是由于RS(16,12)的配置下,所有轨迹的写局部性都得到提升(如表2所示),更多的写请求可以被批量处理导致RS(16,12)下PARD的优化效果更显著.当重播写局部性高的轨迹时,PARD相较于其他策略的提升比例更高.例如当重播wdev_1时,PARD相较于FO,PARIX,PLR分别提升了186%,111%,111%;而对于stg_0,PARD相较于FO,PARIX,PLR分别提升了98.1%,67.7%,46.7%. Fig. 11 Update throughput when replaying traces with RS(16,12)图11 RS(16,12)下重播不同轨迹的更新吞吐率 图12是在RS(16,12)下,重播不同写局部性的轨迹时,不同更新策略每秒完成的写操作数的比较.大致规律和RS(9,6)下相似,唯一不同在于RS(16,12)下PARD的每秒写操作总数相较于其他策略提升比例增加.重播写局部性高的轨迹时,PARD相较于其他策略平均提升了81.3%~148%;而重播写局部性低的轨迹时,PARD相较于其他策略平均提升了40.0%~87.7%. Fig. 12 Aggregate numbers of write completed per second when replaying traces with RS(16,12)图12 RS(16,12)下重播不同轨迹的每秒写操作总数 3.2.3 块大小对读后写操作的影响 本文在3.2.1节和3.2.2节的实验均是在4 MB块大小下进行测试的.为了研究块大小对PARD优化效果的影响,本节测试了0.25~4 MB块大小下PARD相较于PLR,PARIX,Baseline(FO)的读后写操作数减少比例.为了对比不同更新密集度的轨迹对块大小的敏感度,本文选取了更新密集度高的wdev_1和更新密集度低的rsrch_1进行测试,编码配置为RS(16,12). 图13和图14为PARD相较于其他策略的读后写操作减少比例.首先,PARD相较PLR和Baseline的减少比例随着块大小的增加而增大.对于wdev_1,其减少比例最高分别为99.0%和99.8%;而对于rsrch_1,其减少比例最高分别为87.0%和97.4%.由于PARIX也是采用基于数据增量的日志进行校验更新,故读后写操作和PARD一样,对应的优化比例为0.但是PARD采用了预留空间的技术,故更新吞吐率比PARIX高,具体如图15和图16所示.由于PARD对块进行第1次更新时需要1次读后写操作,所以当重播写请求较为分散的rsrch_1时,PARD的读后写操作相较于重播wdev_1时增加.因此,在相同的块大小下,图14中PARD相较PLR和Baseline的读后写操作减少比例低于图11.此外,rsrch_1对块大小更敏感,减少比例的增长速度高于wdev_1. Fig. 13 Reduction proportion of write-after-read when replaying wdev_1 with different chunk sizes图13 不同块大小下重播wdev_1的读后写操作减少比例 Fig. 14 Reduction proportion of write-after-read when replaying rsrch_1 with different chunk sizes图14 不同块大小下重播rsrch_1的读后写操作减少比例 3.2.4 块大小对更新吞吐率的影响 PARD相较于其他策略的更新吞吐率优化比例如图15和图16所示.总体来看,对于2种更新密集度的轨迹,PARD相较于其他策略的更新吞吐率优化比例均随着块大小的增加而增大.图15中,PARD相较于PLR,PARIX,Baseline的优化比例最高分别达110%,110%,186%.图16中,PARD相较于PLR,PARIX,Baseline的优化比例最高分别达41.1%,64.2%,87.1%.和3.2.2节的实验一样,在相同的块大小下,图15的更新吞吐率优化比例高于图16.两者对块大小的敏感度趋势大致相似,唯一明显的不同在于块大小为1~4 MB时,图16中PARD-Baseline的增长速度低于图15的.此外,重播wdev_1时PARD相较PLR的优化比例略高于相较PARIX的优化比例,而重播rsrch_1时相反.这是由于重播更新密集度高的轨迹时,对1个块的连续写请求PARD只需要1次读后写操作,而PLR每次更新均需要1次读后写操作.对于写请求分布在不同条带上的rsrch_1,PARD相较于PLR的读后写操作减少比例降低,且数据节点和校验节点间传输原始数据块的次数增加,导致PARD相较于PLR的更新吞吐率优化效果降低. Fig. 15 Optimization proportion of update throughputwhen replaying wdev_1 with different chunk sizes图15 不同块大小下重播wdev_1的更新吞吐率优化比例 Fig. 16 Optimization proportion of update throughputwhen replaying rsrch_1 with different chunk sizes图16 不同块大小下重播rsrch_1的更新吞吐率优化比例 3.2.5 RS(9,6)下的整体性能 本节在3.2.1节和3.2.4节的实验已经验证PARD在更新性能方面优于其他对比策略,为测试PARD在整体性能上的优化效果,本节从表2中选取6个写操作数目占比最低的轨迹进行实验,其中web_3,hm_1,web_1的写局部性高于proj_4,src2_1,stg_1.选取写操作数目占比低的轨迹进行实验的原因在于占比越高,整体性能的优化效果越接近更新性能的优化效果,为了降低更新性能对整体性能的影响,本节选取写操作数目占比最低的6个轨迹进行实验. 图17是在RS(9,6)下,重播不同写局部性的轨迹时,不同更新策略的读写吞吐率比较.从总体来看,PARD的读写吞吐率相较于FO,PARIX,PLR分别平均提升了50.5%,26.3%,24.8%.重播写操作数目占比高的轨迹时,PARD的优化效果更显著.例如当重播web_3时,其相较于FO,PARIX,PLR分别提升了120%,59.0%,63.8%;而对于写操作数目占比最低的proj_4,其相较于FO,PARIX,PLR分别提升了7.1%,4.6%,1.9%.原因主要在于PARD降低更新操作的时间开销,不同策略间读操作的时间开销大致相同,当写操作数目占比低时,PARD对整体性能的优化效果降低,但是尽管是写操作数目占比只有1.48%的proj_4,PARD仍然达到了最高的读写吞吐率. Fig. 17 Read-write throughput when replaying traces with RS(9,6)图17 RS(9,6)下重播不同轨迹的读写吞吐率 图18是在RS(9,6)下,重播不同写局部性的轨迹时,不同更新策略每秒完成的读写操作数比较.从总体来看,由于读操作的时间开销远低于写操作的时间开销,当读请求占多数时,整体的IOPS会增加.即重播写操作数目占比低的轨迹时,每秒读写操作数更高.当重播写操作数目为占比最低的proj_4时,FO,PARIX,PLR,PARD的每秒读写操作数最高,分别为226,231,237,242个.重播写操作数目占比高的轨迹时,PARD的每秒读写操作数相较于其他策略的提升比例增加,提升比例和图17一样,主要是因为PARD降低更新操作的时间开销,当写操作数目占比高时,PARD对整体性能的优化效果增加. Fig. 18 Aggregate numbers of read and write completed per second when replaying traces with RS(9,6)图18 RS(9,6)下重播不同轨迹的每秒读写操作总数 3.2.6 RS(16,12)下的整体性能 图19是在RS(16,12)下,4种更新策略重播不同轨迹的读写吞吐率比较.和RS(9,6)相较,RS(16,12)下PARD的优化效果更显著,其读写吞吐率相较于FO,PARIX,PLR分别平均提升了59.2%,29.7%,29.9%.这是由于RS(16,12)下轨迹的写局部性提高,更多的写请求可以被批量处理导致RS(16,12)下PARD的优化效果更显著.重播写操作数目占比高的轨迹时,PARD的优化效果更显著.例如当重播web_3时,其相较于FO,PARIX,PLR分别提升了140%,66.3%,74.7%;而对于写操作数目占比最低的proj_4,其相较于FO,PARIX,PLR分别提升了7.4%,5.6%,2.1%. Fig. 19 Read-write throughput when replaying traces with RS(16,12)图19 RS(16,12)下重播不同轨迹的读写吞吐率 图20是在RS(16,12)下,重播不同写局部性的轨迹时,不同更新策略每秒完成的读写操作数比较.大致规律和RS(9,6)下相似,唯一不同在于RS(16,12)下PARD的每秒完成的读写操作数相较于其他策略提升比例增加.RS(9,6)下PARD相较于FO,PARIX,PLR分别平均提升了50.5%,26.3%,24.8%;RS(16,12)下PARD相较于FO,PARIX,PLR分别平均提升了59.2%,29.7%,29.9%. Fig. 20 Aggregate numbers of read and write completedper second when replaying traces with RS(16,12)图20 RS(16,12)下重播不同轨迹的每秒读写操作总数 相较于传统的基于校验增量和基于数据增量的纠删码数据更新方法,本文提出的PARD更新方法极大限度地从减少更新路径上的读后写操作及后续更新校验块的磁盘寻道开销2个方面来提升分布式存储集群的数据更新性能.此外,本文设计的PARD原型实现了多种最新的数据更新策略,并用真实工作负载下的轨迹对不同更新策略的写性能进行测试.实验结果表明,PARD策略显著提升了纠删码存储集群数据更新性能.在未来本工作计划探索如何在PARD的基础上,进一步减少跨机架环境下数据更新时的网络传输开销,并测试PARD的单节点和多节点的修复效率. 作者贡献声明:章紫琳提出数据更新方法思路,负责完成实验并撰写论文;刘铎提出实验方案,修改并审核论文;谭玉娟提出指导意见;吴宇参与论文校对;罗龙攀参与图表修正;王纬略负责调研文献;乔磊参与实验数据审查.
1.3 问题描述与研究动机

2 PARD介绍
2.1 基于数据增量的日志



2.2 预留空间

2.3 体系架构
3 实验与分析
3.1 轨迹分析
3.2 性能评估







4 结 论
