井下矿工多目标检测与跟踪联合算法
2022-11-09周孟然李学松朱梓伟黄凯文
周孟然,李学松,朱梓伟,黄凯文
(安徽理工大学 电气与信息工程学院,安徽 淮南 232001)
0 引言
目前,大多煤矿对井下矿工的安全管理仍存在一定盲区。充分利用图像信息对多个运动目标进行检测与跟踪,对可能出现的危险进行预警,对于保障井下矿工的人身安全具有重要意义[1]。
多目标跟踪技术是计算机视觉领域的研究热点,在自动驾驶、军事等领域都有广泛应用[2-3]。针对井下矿工的多目标检测与跟踪,学者们已进行了不少研究。Jiang Daihong 等[4]提出了结合主成分分析和尺度不变特征变换的运动目标跟踪模型,通过均值漂移实现移动目标跟踪,但由于井下矿工服装颜色与背景颜色高度相似,特征提取精确度低。孔丽丽等[5]采用射频识别技术实现对井下矿工的高精度定位,但需要设置大量传感器节点,成本高,且存在通信信号弱等缺点。郭曦等[6]提出使用双目相机获取跟踪目标,并通过相关滤波算法有效解决跟踪问题,但该方法检测速度慢,难以实现实时跟踪。
随着计算机硬件的迅速发展,深度学习领域迎来了新的突破,基于检测的跟踪(Detection Based Tracking,DBT)框架被广泛使用。DBT 框架主要包括目标检测和匹配跟踪2 个部分,目标检测的质量直接影响匹配跟踪的效果。①目标检测。目标检测模型主要分为2 类,一类是以Faster RCNN[7]等为代表的两阶段检测模型,一类是以SSD,YOLO[8-11]为代表的一阶段检测模型。两阶段检测模型虽然精度较高,但检测速度慢,不适用于实时监控场景。一阶段检测模型中,YOLO 模型检测速度快、准确率高,YOLOv5s 是YOLOv5 系列中最小的网络模型,相对来说结构更加简单、速度更快。因此,本文在YOLOv5s 的基础上进行改进,得到YOLOv5s-GAD目标检测模型。② 匹配跟踪。A.Bewley 等[12]提出了简单在线实时跟踪(Simple Online and Realtime Tracking,SORT)算法,通过Faster RCNN 获取图像特征,再通过卡尔曼滤波和匈牙利算法进行模型关联,但SORT 算法主要关注的是逐帧跟踪,出现人员遮挡问题时身份转换频率非常高。N.Wojke 等[13]提出了引入深度关联度量的SORT(Deep SORT)算法,在SORT 算法基础上加入浅层残差网络进行行人重识别,减少了人员身份转换次数,但浅层残差网络提取的是局部特征。为了进一步减少人员身份转换次数,本文在Deep SORT 算法基础上进行改进,采用全尺度网络(Omni-Scale Network,OSNet)[14]进行全方位特征学习,以更好地实现行人重识别,提高目标跟踪的准确性和实时性。
另外,由于煤矿井下环境特殊,光线较暗,现有的公开数据集如PASCAL VOC 和MS COCO 等无法完全满足井下低照度特殊场景应用需求[15],本文通过训练自定义的井下矿工数据集,对比常见的几种目标检测算法,验证YOLOv5s-GAD 模型的有效性。
1 井下矿工多目标检测与跟踪联合算法原理
多目标跟踪主要解决的问题是在视频序列的当前帧中找到过去帧出现的多个特征目标。井下矿工多目标检测与跟踪联合算法流程如图1 所示。获取井下矿工数据集并进行预处理,通过YOLOv5s-GAD模型进行特征提取,得到检测框信息,最后通过改进Deep SORT 多目标跟踪算法实现级联匹配,从而实现多目标检测与跟踪。
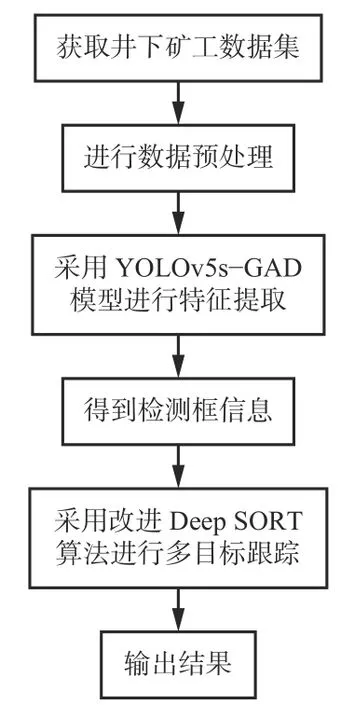
图1 井下矿工多目标检测与跟踪联合算法流程Fig.1 Flow of joint algorithm of multi-target detection and tracking for underground miners
2 目标检测
2.1 YOLOv5s 模型结构
YOLOv5s 模型中,backbone 部分使用一系列CBL(Conv+BN+Leaky_ReLU)模块和BottleneckCSP模块的组合叠加,实现对输入图像的特征提取;在最后一层输出接上一个空间金字塔池化层(Spatial Pyramid Pooling,SPP)[16],相比于普通的池化操作,这种方式更能增加感受野;在neck 部分使用路径聚合网络(Path Aggregation Network,PANet)[17],融合自底向上和自顶向下2 种方式来加强骨干网络的特征提取能力;输出部分应用了多尺度融合,对于3 个输出尺度,得到3 种不同大小的单元格,分别用于检测对应大小的特征图像。
2.2 YOLOv5s-GAD 模型
YOLOv5s-GAD 模型主要包括输入、backbone、neck、输出等部分,如图2 所示,其中ConCat 表示连接,dw Conv 表示深度卷积,pw Conv 表示逐点卷积。
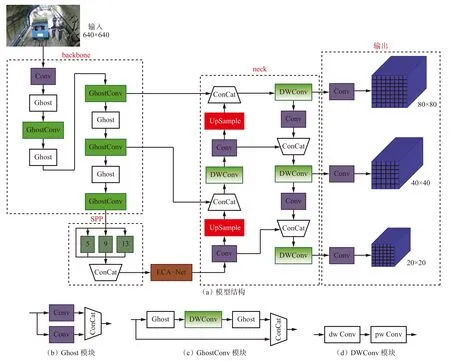
图2 YOLOv5s-GAD 模型Fig.2 YOLOv5s-GAD model
YOLOv5s-GAD 模型在YOLOv5s 模型的基础上进行了以下改进:
(1)在backbone 部分,为了减少特征图冗余运算,降低计算成本,提高特征提取速度,引入幻象(Ghost)模块和幻象瓶颈卷积(GhostConv)模块对网络进行轻量化设计[18],替换原YOLOv5s 模型中的卷积模块和BottleneckCSP 模块,实现对输入图像的特征提取。
(2)针对井下光线暗、图像噪点多等特点,在SPP 输出的最小特征图中引入高效通道注意力神经网络(Efficient Channel Attention Neural Networks,ECA-Net)模块,使模型更多地关注感兴趣特征,提高模型整体精度。
(3)在neck 部分同样进行轻量化设计[19],将原来的BottleneckCSP 模块替换为深度可分离卷积(Depthwise Separable Convolution,DWConv)模块,以加快特征提取速度,提高实时性。
2.2.1 GhostConv 模块
Ghost 模块通过一半普通卷积叠加一半逐通道卷积操作实现特征提取,GhostConv 模块由Ghost 模块与DWConv 模块前后相连并与捷径分支组合得到。普通卷积和Ghost 的加速比为
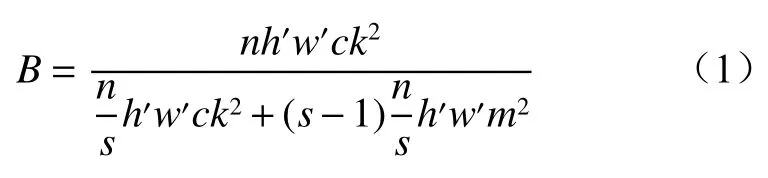
式中:n为卷积核个数;h′和w′分别为特征图的高和宽;c为通道数;k和m为卷积核大小,k≈m;s为幻象特征图个数,s<<c。
化简式(1)可得
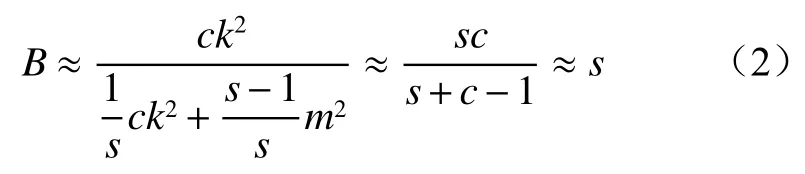
2.2.2 DWConv 模块
DWConv 模块是用于算力较小的移动设备或嵌入式设备的轻量化模块。由于YOLOv5s 在路径聚合部分使用了参数量很大的BottleneckCSP 模块,在特征提取过程中需耗费大量时间,使得井下矿工目标跟踪的实时性得不到保障,所以用DWConv 模块替换路径聚合部分的BottleneckCSP。
标准卷积过程如图3 所示。对于输入尺寸为DF×DF的特征图,通过N个大小为DK×DK、深度为M的卷积核进行特征提取,输出图像尺寸为。标准卷积的参数量为

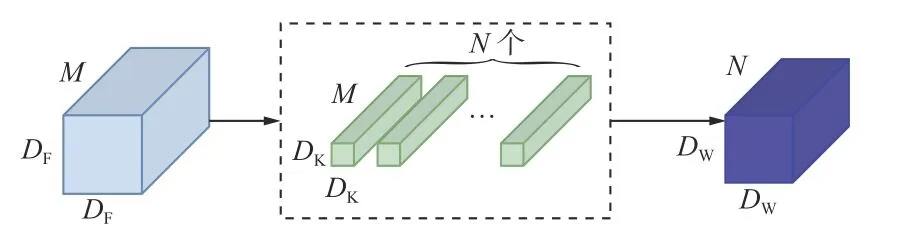
图3 标准卷积过程Fig.3 Standard convolution process
DWConv 过程如图4 所示。将普通卷积的1 步操作拆分成2 步执行。先通过M个大小为DK×DK、深度为1 的卷积核进行深度卷积,再通过N个大小为1×1、深度为M的卷积核进行逐点卷积。深度卷积负责滤波,逐点卷积负责转换通道。DWConv 的参数量为
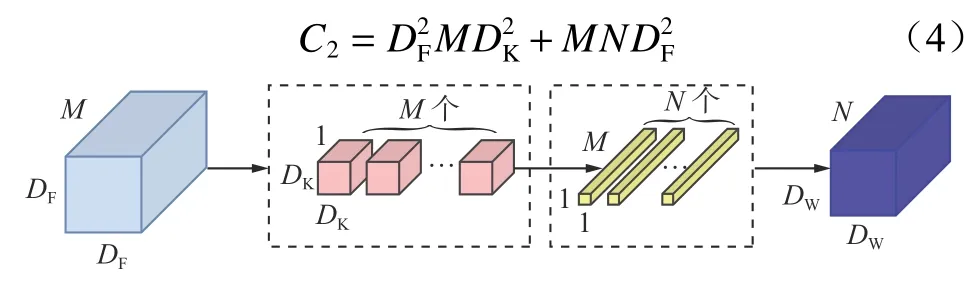
图4 DWConv 过程Fig.4 Depthwise separable convolution process
DWConv 与标准卷积的参数量之比为
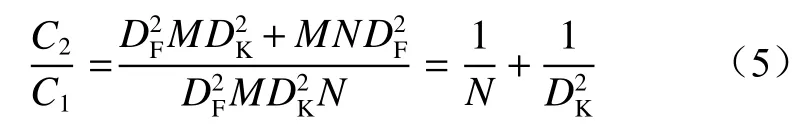
因为N和DK的值都很大,所以C2与C1的比值远小于1,说明DWConv 模块可明显减少网络模型的参数量,加快模型的训练速度。
2.2.3 ECA-Net 模块
注意力机制能够改善卷积神经网络的性能[20-22],但目前大部分研究都是用更复杂的结构来提升性能,Wang Qilong 等[23]提出了一种基于一维卷积的局部跨通道交互策略,兼顾了网络性能及复杂度。在不降低维度的条件下输入特征图,由通道注意力机制获得通道权重 ω的通用计算公式:
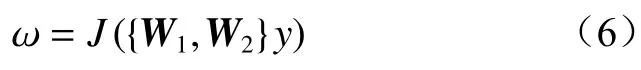
式中:J(·)为ReLU 激活函数;W1,W2为带状矩阵;y为通道全局平均池化。
由式(6)可知,通道与其权重之间的对应关系是间接的,ECA-Net 使用第K个带状矩阵WK来学习通道注意力,对于第a个通道的全局平均池化ya,只考虑其与K个相邻通道的信息交互,忽视其他干扰信息。第a个通道的权重为
式中:σ(·)为激活函数;Wab,yab分别为第a个通道的第b个相邻通道的带状矩阵和全局平均池化。
最后使用卷积核大小为S的一维卷积VS来获取最终权重:

3 Deep SORT 多目标跟踪算法改进
匹配关联模型是DBT 框架的核心,其目的是将目标检测获得的检测框与卡尔曼滤波器获得的预测框关联起来,并通过对各目标标记ID 来确定身份。Deep SORT 算法的级联匹配融合了2 种度量方式:一种是通过目标的运动信息计算检测框与预测框之间的马氏距离,实现状态匹配;另一种是通过引入检测目标的外观信息,对浅层残差网络提取的128 维特征向量进行关联,计算特征向量与检测框的最小余弦距离,实现状态匹配。
第i个预测框与第j个检测框的马氏距离为
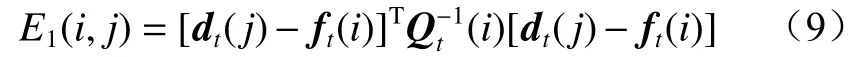
式中:dt(j) 为第t条轨迹的第j个检测框;ft(i)为第t条轨迹的第i个预测框;Qt(i)为检测状态和估计状态的平均协方差矩阵。
第i个预测框与第j个检测框的最小余弦距离为
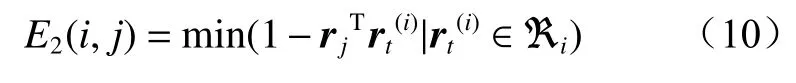
式中:rj为利用第j个检测框在行人重识别中提取的128 维特征向量;为第t条轨迹的第i个特征向量;ℜi为最近100 帧内特征向量的集合。
将上述结果按权重λ加入代价矩阵中,得到第i个预测框与第j个检测框总的匹配指标为
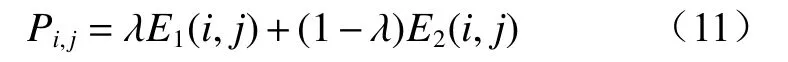
最后用匈牙利算法得到匹配结果。
由于浅层残差网络提取的是局部特征,为了进一步减少人员身份转换次数,本文使用OSNet 替换Deep SORT 算法中行人重识别部分的浅层残差网络。OSNet 结构如图5 所示。通过全局平均池化实现的聚合门(Aggregation Gate,AG)按照特定比例对4 种特征尺度进行动态组合,以减少因遮挡等原因产生的身份转换现象。另外,在普通的3×3 卷积中加入DWConv 模块,以减少模型参数,提高训练速度。
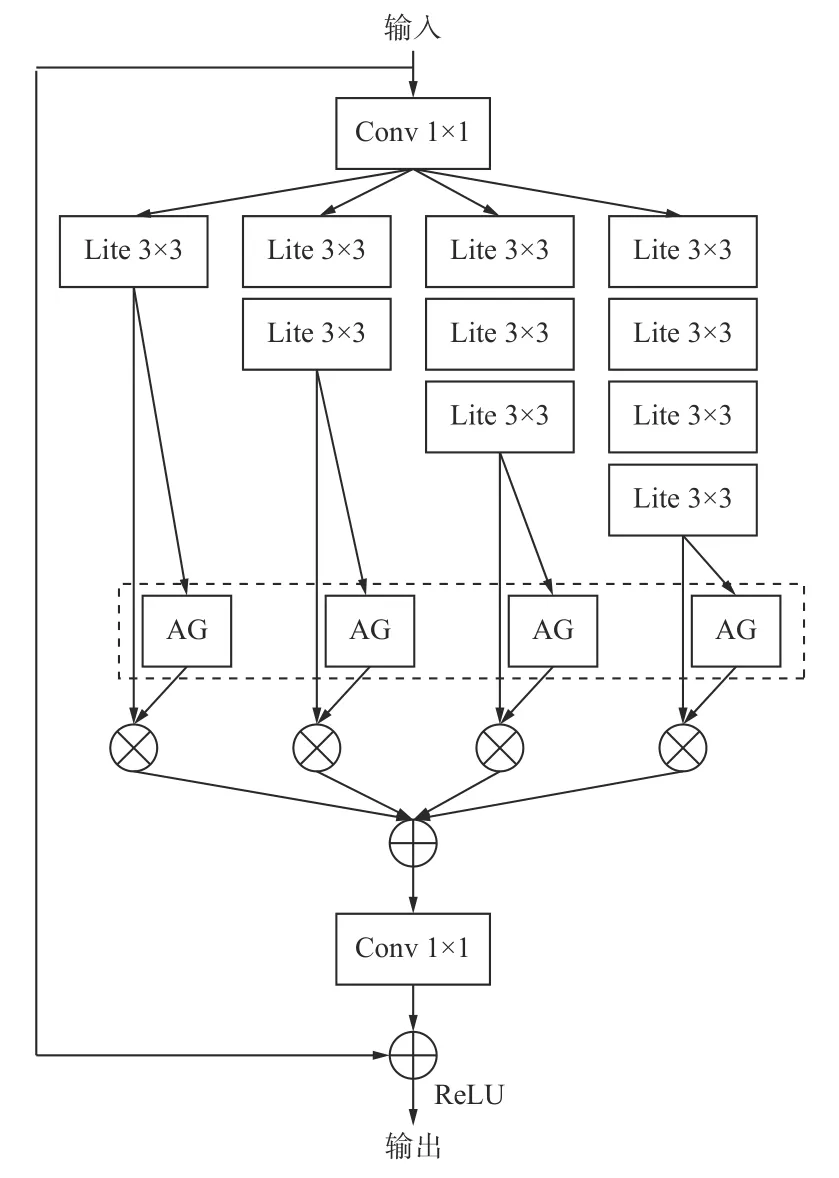
图5 OSNet 结构Fig.5 Omni-scale network structure
4 实验分析
深度学习的硬件平台为计算机,CPU 型号为Intel i5-9400F,GPU 型号为NVIDIA GTX 1070-8G,采用Windows 10 操作系统,结合配套驱动工具CUDA10.1及深度学习加速库cuDNN8.0.4,在Pytorch1.8.1 框架下,使用Pycharm 集成开发环境实现目标检测及跟踪模型的训练与验证。
4.1 数据集的选取与处理
数据集分为目标检测数据集和目标跟踪数据集2 个部分。检测部分的井下矿工数据集来自于2021 年10 月安徽淮南某矿区底抽巷道作业监控视频[24],通过自定义的python 脚本进行视频抽帧,共采集1 636 张图像,图像尺寸为1 920×1 280 像素。由于识别对象是井下矿工,所以忽略了视频中其他所有类别,类别标签仅有1 个,即Person 类。使用开源标注软件LabelImg 对图像进行人工标注,用矩形框确定目标所在区域,如图6 所示。将数据集按照9∶1 的比例划分为训练集与验证集,训练集1 472 张,验证集164 张。通过加载部分预训练权重的迁移学习方法,在自定义数据集Miner21 上进行微调训练。跟踪部分数据集使用公开行人数据集MOT17 中除MOT17-06 以外的视频序列。

图6 数据集图像Fig.6 Dataset image
4.2 YOLOv5s-GAD 模型消融实验
为了验证YOLOv5s-GAD 模型的有效性,在Miner21 数据集上迭代100 轮进行消融实验。采用随机裁剪、拉伸等方法进行数据增强,以增强模型的泛化能力。以YOLOv5s 为基准网络,分别加入GhostConv,ECA-Net 模块及其与DWConv 组合进行实验,并调用YOLOv5 的自适应anchor 脚本,使用迁移学习方法加载部分预训练权重,训练结果见表1,其中AP为交并比为0.5 时的平均精度。
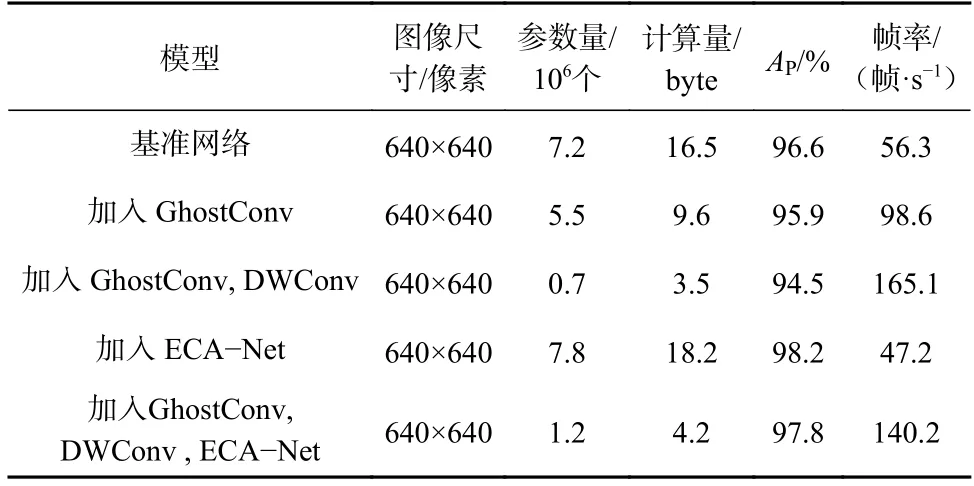
表1 不同模型消融实验结果Table 1 Ablation experiment results of different models
由表1 可知,在基准网络中加入GhostConv 后,虽然精度降低了0.7%,但是参数量减少了近200 万个;同时加入GhostConv 和DWConv 后,参数量减少至原来的1/10,帧率提升至原来的3 倍左右,大大提升了模型的训练速度;加入ECANet 后,虽然参数量略增加,但检测精度提升了1.6%;同时加入上述3 个模块后,检测精度提升了1.2%,帧率提高了83.9 帧/s。各模型训练过程如图7 所示。训练至第45 轮时模型渐渐收敛并趋于稳定。
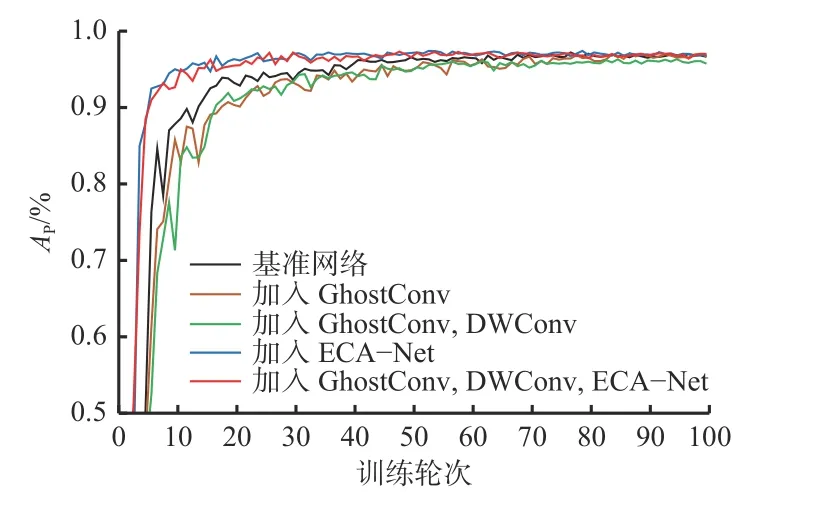
图7 各模型训练过程Fig.7 Training process of each model
4.3 目标检测实验
为了验证YOLOv5s-GAD 模型的检测效果,采用常用的Faster RCNN,YOLOv3 及YOLOv5s 进行对比实验。同样在Miner21 数据集上进行100 轮迭代训练,结果如图8 所示。可看出YOLOv3 模型出现了漏检情况,且精度较低,YOLOv5s-GAD 模型的精度最高,说明在自定义的验证集上,引入注意力机制后的模型更适合井下低照度的特殊需求,目标检测效果更好。

图8 各种目标检测模型效果对比Fig.8 Comparison of effects of various target detection models
各种目标检测模型对比实验结果见表2。可看出YOLOv5s-GAD 模型虽然检测精度低于Faster RCNN,但是速度提升了近16 倍;与YOLOv3 模型相比,YOLOv5s-GAD 模型平均精度提升了24.9%,帧率提升了119.8 帧/s;与原始的YOLOv5s 模型相比,YOLOv5s-GAD 模型平均精度提升了1.2%,帧率提升了83.9 帧/s,模型的训练速度及精度都得到了明显提升。
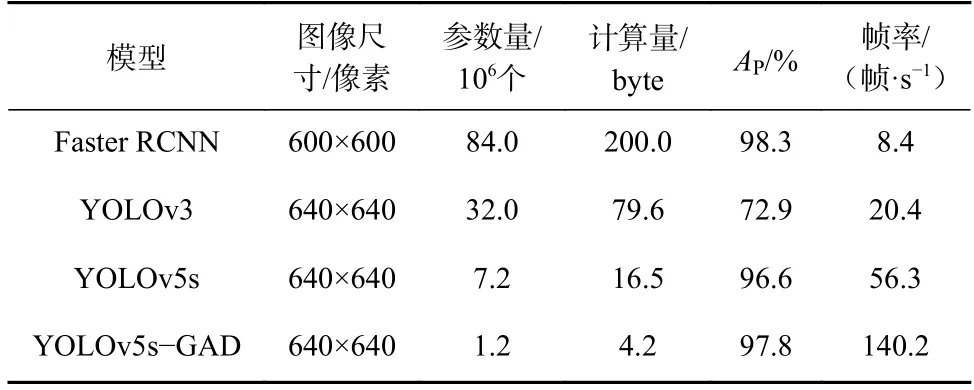
表2 目标检测模型实验结果Table 2 Experimental results of target detection models
4.4 多目标检测与跟踪联合算法性能验证
为了验证多目标检测与跟踪联合算法的有效性,采用常见的多目标跟踪算法进行对比,包括IOU17[25],MOTDT17[26],Deep SORT,FairMOT[27]。采用MOT17 中除MOT17-06 以外的视频序列进行实验,并选取文献[28]提出的部分常用评价指标进行评估,结果见表3。其中A为多目标跟踪准确率,R为正确识别的检测数与真实检测数的比值,I为跟踪目标身份切换次数,T为成功跟踪目标百分比,L为丢失目标百分比。可看出IOU17 算法虽然速度最快,但是准确率低于本文算法;MOTDT,Deep SORT,FairMOT 虽然准确率高,但帧率远低于本文算法,实时性得不到保障。权衡速度与准确率,在MOT17 测试序列上,采用YOLOv5s-GAD 模型和改进Deep SORT 算法时人员身份转换次数最少,行人重识别效果最好。
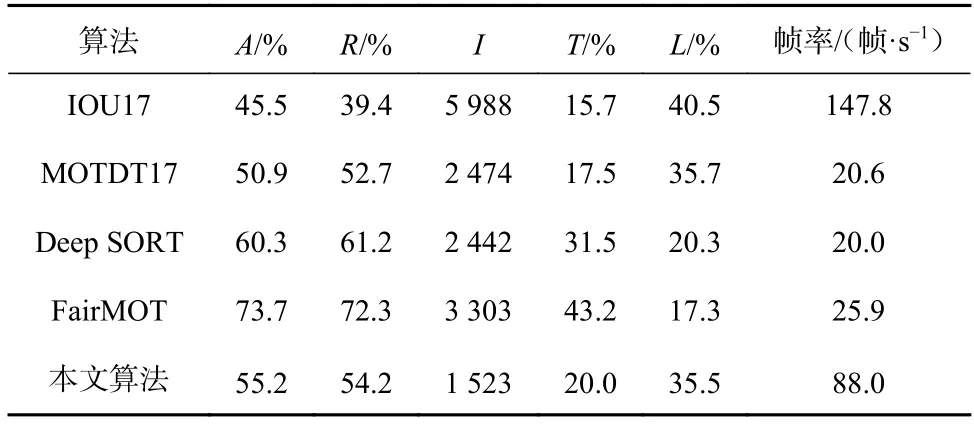
表3 多目标检测与跟踪联合算法实验结果Table 3 Experimental results of joint algorithms of multi-target detection and tracking
联合YOLOv5s-GAD 模型和改进Deep SORT 算法进行多目标检测与跟踪,结果如图9 所示。可看出在连续序列帧中,即使出现行人交错重叠,跟踪的ID 号也没有发生改变,对新出现的井下矿工也能及时跟踪并匹配ID,跟踪效果良好。

图9 井下矿工多目标检测与跟踪结果Fig.9 Multi-target detection and tracking results of underground miners
5 结论
(1)通过引入GhostConv 模块和DWConv 模块,替换YOLOv5s 模型骨干网路和路径聚合网络中的BottleneckCSP 模块,提高矿工目标的特征提取速度。通过引入ECA-Net 模块,提高矿工多目标检测精度。
(2)使用全尺度网络替换Deep SORT 中的浅层残差网络,可进一步减少人员身份转换次数,更好地实现行人重识别,提高目标跟踪的准确性。
(3)实验结果表明:在自定义数据集Miner21上,YOLOv5s-GAD 模型的平均精度达97.8%,帧率达140.2 帧/s;在公开行人数据集MOT17 上,多目标检测与跟踪联合算法的速度与准确率等综合性能优于IOU17,Deep SORT 等常用多目标跟踪算法,能够满足井下矿工多目标跟踪的实时性和准确性需求。
