基于ATR-FTIR光谱的γ-PGA发酵批次分类研究
2022-11-08刘隆兴
单 鹏,吴 缀,何 年,刘隆兴
(东北大学秦皇岛分校 控制工程学院,河北 秦皇岛 066004)
聚谷氨酸(γ-polyglatamic-acid,γ-PGA)由于其水溶性、吸附性好等特点,它及其衍生物被广泛应用于食品工业、化妆品行业,以及医疗保健行业[1].γ-PGA作为一种批次发酵的产物,其发酵过程复杂,易受到各种因素的影响,无法严格保证每个批次发酵条件完全相同,使得不同批次生产的γ-PGA产品质量有所差异.通过对γ-PGA发酵批次的鉴别,可以为鉴别γ-PGA产品质量提供关键的信息.传统的CTAB法[2]、HPLC法[3]、GPC法[4]等化学检测方法对γ-PGA发酵过程提供信息十分有限,而且上述分析方法大多相对复杂、耗时长且需要专业技能.此外,通常需要对样品进行预处理,这样不仅进一步增加检测的复杂性和成本,还可能改变γ-PGA发酵有机分子官能团特征.相比之下,衰减全反射傅里叶变换红外光谱(ATR-FTIR)是一种相对简单、快速、廉价且非侵入性的技术[5],无需任何复杂的样品预处理;此外其光谱范围在4 000到400 cm-1之间,能够准确地提供γ-PGA发酵过程中大部分有机分子化学键和官能团信息,非常适用于γ-PGA发酵过程的监测.
由于发酵条件无法保证完全相同,不同批次γ-PGA发酵液光谱存在差异.根据这些光谱差异,可以对γ-PGA产品批次进行鉴别.γ-PGA光谱信息量大,而且变量之间存在多元相关性.传统的判别分析方法,如线性判别分析(linear discriminant analysis, LDA)[6]、二次判别分析(quadratic discriminant analysis,QDA)[7]、K近邻(K-nearest neighbor,KNN)[8]无法处理多元共线性,分类效果很不理想,所以本文采用了适合处理多元共线性问题的偏最小二次判别分析(partial least squares discriminant analysis, PLSDA)[9]方法.PLSDA方法包括了主成分分析、多元线性回归分析、典型相关性分析,对于本文处理γ-PGA发酵光谱的高维度、噪声大、变量间存在相关性的数据十分适用[10-15].
本文采集了5个批次的γ-PGA发酵液ATR-FTIR数据.先利用波数选择的方法挑选出了重要变量,再利用PLSDA建立分类模型,对样品的批次进行定性分析,测试样品的准确率可以达到87%以上.实验表明,波数选择结合PLSDA可以对ATR-FTIR采集的γ-PGA发酵液光谱实现快速鉴别分类.
1 实验部分
1.1 对菌种进行发酵培养
γ-PGA发酵实验选用中国工业微生物菌种保藏管理中心(China Center of Industrial Culture Collection, CICC)枯草芽孢杆菌亚种为菌种(编号20643).菌种是以冻干粉形式储存的,将菌种溶于无菌水恢复活性后,用接种环将菌群接种于固体培养基,再将其置于电热恒温箱培养24~48 h.随后挑选一株长势良好的菌体,接种在种子培养基中,然后在37 ℃和180 r/min的恒温振荡培养箱中(THZ-92A,跃进医疗器械有限公司,中国 上海)培养10~16 h.接着将种子培养基中种子液按2%接种量接种至发酵培养基中,并将3 L的发酵培养基置于5 L的发酵罐(GRJB-5D,绿色生物工程有限公司,中国 镇江)中,在37 ℃恒温和300 r/min搅拌速度的条件下进行发酵.上述三种培养基配置如下,固体培养基:蛋白胨(10 g/L),牛肉膏(5 g/L),氯化钠(5 g/L)以及2%琼脂粉;种子培养基:葡萄糖(10 g/L),牛肉膏(5 g/L),蛋白胨(10 g/L),氯化钠(5 g/L);发酵培养基:葡萄糖(35 g/L),酵母膏(5 g/L),谷氨酸钠(30 g/L),氯化铵(2 g/L),磷酸氢二钾(5 g/L)和硫酸镁(0.5 g/L).三种培养基均需在121 ℃下灭菌20 min.
1.2 对发酵液进行光谱采集


图1 γ-PGA 5个发酵批次的光谱图
1.3 模型建立
1.3.1 PLSDA原理简介
PLSDA是一种有监督的判别分析统计方法[16],该方法被用来建立γ-PGA发酵液样品光谱与发酵批次之间的关系模型,来实现对样品批次的预测.PLSDA是基于LDA基础上的偏最小二乘(partial least squares,PLS),它同时对样本光谱矩阵X∈Rm×n(m和n分别为样本数和光谱变量数)和类别标签向量y∈Rm×1进行分解,突显类别信息在光谱分解时的作用,以提取出与样本类别最相关的光谱信息,即最大化提取不同类别光谱之间的差异.
PLSDA建立X与y之间的数学模型:
y=XB+E.
(1)
其中:B∈Rn×1为回归系数向量;E为残差向量.
在建立模型(1)之前,先通过PLS对X和y进行双线性分解:
X=TPT+EX,
(2)
y=UQT+Ey.
(3)
式中:T=[t1,…,tc]∈Rm×c和U=[u1,…,uc]∈Rm×c为关于X和y的得分矩阵;P∈Rq×c和Q∈Rq×c是X和y的载荷矩阵;EX和Ey是X和y的残差矩阵.
T和U中的得分向量为原始变量的线性组合:
ti=Xwi,
(4)
ui=yvi.
(5)
式中:wi和vi是投影向量,用非线性迭代偏最小二乘(nonlinear iterative partial least squares,NIPLS)方法提取c组得分,提取c组得分关键在于求解wi和vi,只有求解出wi和vi才能得到ti和ui.提取每组得分需要满足目标函数:
(6)
(7)
1.3.2 波数选择方法
经典的光谱波数选择方法包括了子窗口置换分析(subwindow permutation analysis, SPA)、竞争自适应重加权采样(competitive adaptive reweighted sampling, CARS)、随机青蛙(random frog, RF)等.其中SPA算法能够考虑到多变量的协同效应,以及能够识别信息“峰”,来进行变量重要性评估[17].CARS算法以简单的“适者生存”原则[18],结合偏最小二乘回归来选择全光谱中的最佳波段.RF是一种基于模型整体分析的变量挑选方法,借鉴了可逆跳跃马尔可夫链蒙特卡罗(reversible jump Markov chain-Monte Carlo, RJMCMC)[19]的思想,生成了一系列可以在整个模型空间中随机跳跃的模型,根据每个变量的选择概率作为变量重要性的度量[20].其中RF,SPA和CARS算法挑选的波数见图2.通过观察挑选波数的分布情况,发现SPA算法中挑选的波数位于波峰波谷处的多;RF算法挑选波数呈现出分散状态,正好对应了其随机跳跃的特点.CARS对于变量重要程度判断标准较为严格,是三种方法中挑选出波数最少的.
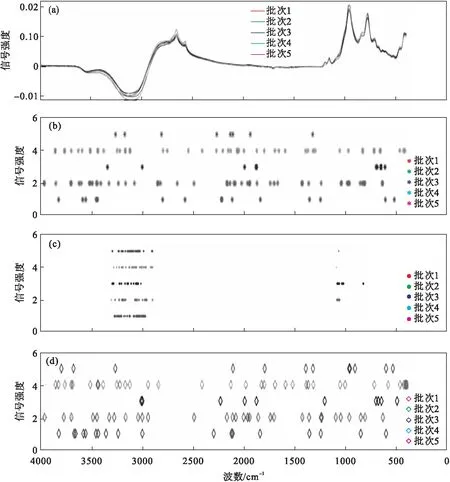
图2 5个批次的平均光谱及不同选择方法挑选的波数
1.3.3 建立模型
本文主要关注每个批次与其他批次的分类效果,因此采用二分类分类器,将每个批次作为一个小类,将其余4个批次作为一个大类.为了保证样本划分均衡,对大类和小类同时进行KS(kennard-stone)划分.用KS算法将γ-PGA发酵液光谱数据按照3∶1比例划分,其中3份作为训练集,建立模型;一份作为测试集,用来验证模型.用波数选择方法,挑选出重要性高的波数.采用5折交叉验证,对挑选出的变量交叉验证分析,从1~20 中选出最佳潜在变量个数.最后利用PLSDA算法对训练集建立模型,用测试集来验证模型精度.所有模型建立之前,光谱数据均进行中心化预处理.
1.3.4 评价指标
所得模型根据正确率、准确率、召回率、特异性、F1得分共5个指标来评价,其中真阳性(true positive,TP)、假阳性(false positive,FP)、假阴性(false negative,FN),真阴性(true negative,TN)评价指标计算公式如下:
正确率表示预测正确样本占总样本数比例:
(8)
准确率表示预测为正类中正确的比例:
(9)
召回率(敏感度)表示预测为正类正确个数占实际正类比例:
(10)
特异性表示预测为负类正确个数占实际负类比例:
(11)
F1得分表示准确率与召回率的调和平均数:
(12)
利用PLSDA和三种经典的波数选择方(SPA-PLSDA,CARS-PLSDA和 RF-PLSDA),对采集的5个批次γ-PGA发酵ATR-FTIR光谱进行判别分析,通过对比波数选择和无波数选择判别分析精度、敏感度、F1得分来找到最适合γ-PGA发酵批次判别的方法.
2 结果与讨论
2.1 PLSDA(无波数选择)结果分析
不进行波数挑选,直接利用PLSDA算法进行5次二分类,5个批次训练集的精度都达到了100%,测试集精度除了批次3为100%,其余4个批次也在92.1%~94.9%之间.具体数据如表1所示.
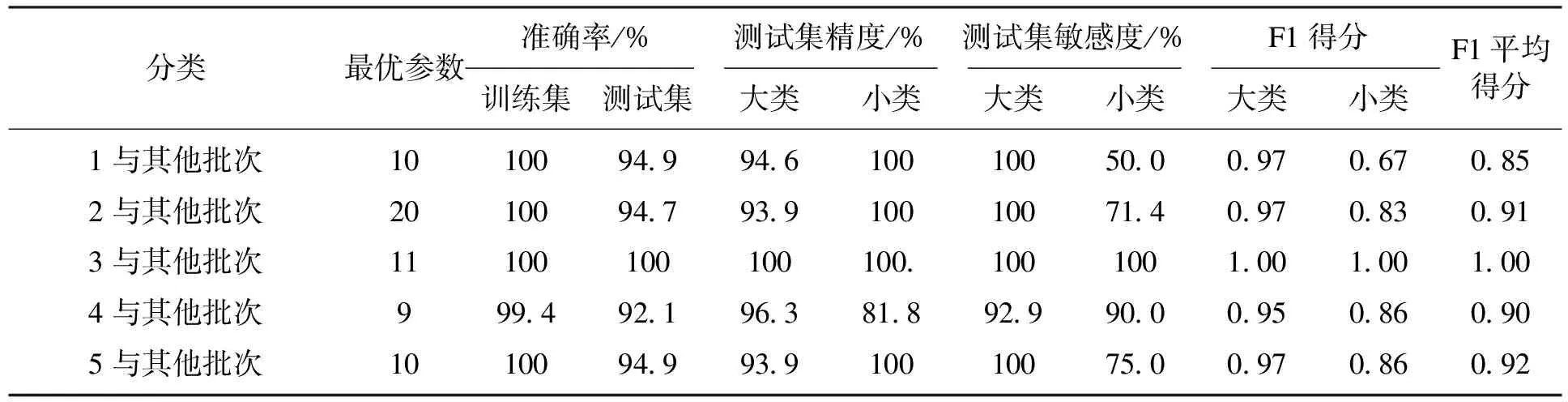
表1 PLSDA方法分类结果
2.2 不同波数选择结合PLSDA的结果分析
2.2.1 SPA-PLSDA结果分析
通过1 000次蒙特卡洛实验,SPA挑选出合理的波数,再结合PLSDA对挑选出的波数进行建模,实验结果见表2.挑选的波数(见图2c)主要集中在波峰与波谷处,挑选出连续的波数,对应了其移动窗口选择波数的特点.相比于不进行波数选择,SPA-PLSDA模型在5个训练集模型精度都接近100%,测试集精度4个批次达到了100%,批次1为97.4%,而且F1得分、测试集敏感度以及测试集精度上都有显著提升.经过波数选择后,大大降低了模型的复杂度,但预测精度仍然能够保持甚至提升.这些结果都表明了SPA-PLSDA十分适用于γ-PGA发酵批次分类.
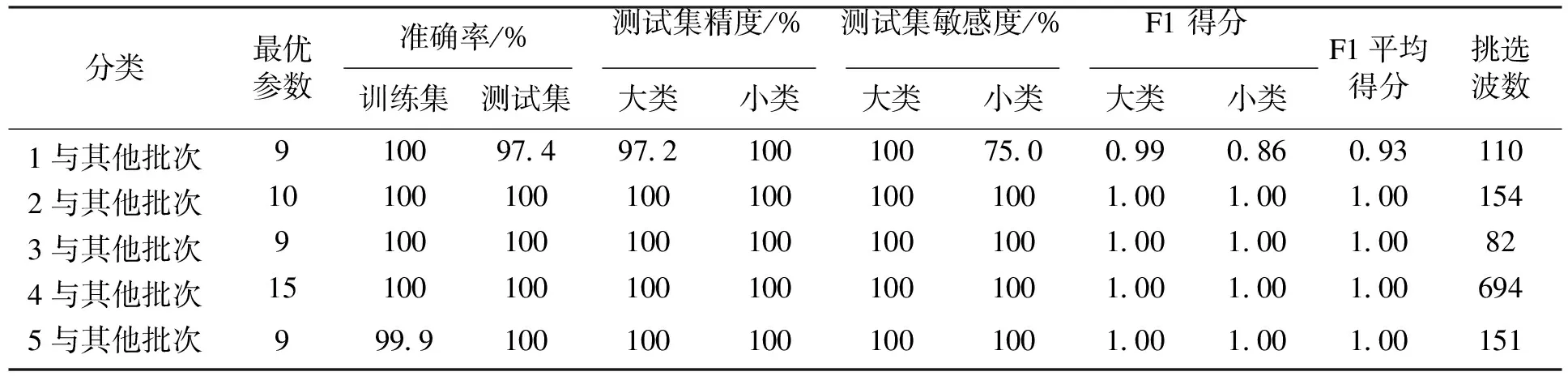
表2 SPA-PLSDA方法分类结果
2.2.2 CARS-PLSDA结果分析
利用CARS算法进行波数选择,首先构建包含所有变量的模型,接着以迭代方式消除最不重要的变量.每次迭代中要消除的变量数量由指数递减函数和自适应加权采样技术所决定.且在每次迭代中,不是对单个变量重要性评估,而是对变量子集进行评估[21].CARS算法对于变量重要程度判断标准较为严格,挑选的波数(见图2d)主要集中在波段的前部和中后部;其中批次3虽然只挑选了10个特征波数的组合(279,282,501,569,602,793,937,943,952和996 cm-1),但预测性能与全波段模型性能相当.相比于表1不进行波数选择情况,尽管训练模型的精度仍然是100%,但测试集精度显著降低,其中批次1,2和4都降低了5%~8%,降低幅度较大,特别是在测试集批次1中,将所有类别都归为了大类,而仅仅在批次5有一点提升,各项指标也不够理想,具体数据如表3所示.
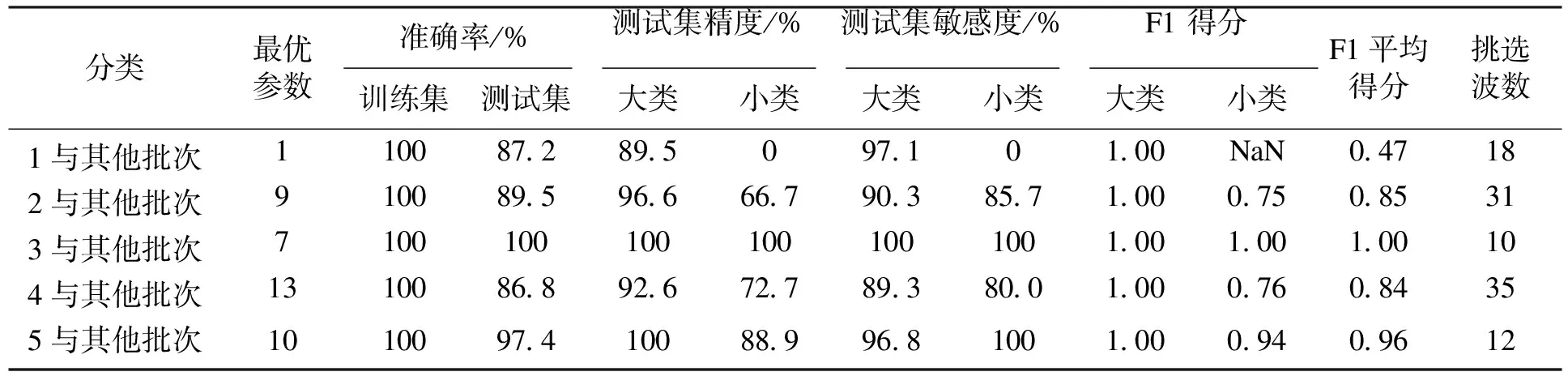
表3 CARS-PLSDA方法分类结果
2.2.3 RF-PLSDA结果分析
RF通过在模型空间中模拟一条服从稳态分布的马尔科夫链,来计算每个变量的被选概率,然后根据所有变量的排名选择变量[22].挑选的波数见图2b,整个波数的选择都比较随机,在整个波段中也比较均匀分散.特别是批次3与5分别挑选出10个(951,963,941,952,603,601,938,185,569和282 cm-1)和8个(207,233,336,536,760,529,491和585 cm-1)特征波数组合,仍然取得了测试集100%和97.4%的准确率.相比直接进行PLSDA分类,经过RF算法挑选波数,训练集准确率仍然为100%,除了测试集3个批次仍然保持100%外,其他几个批次均有2%~8%左右的提升,测试集准确率均在97.4%以上,其余指标如敏感度以及F1得分方面也有明显提升,模型的复杂度经过波数选择后显著降低,具体数据如表4所示.
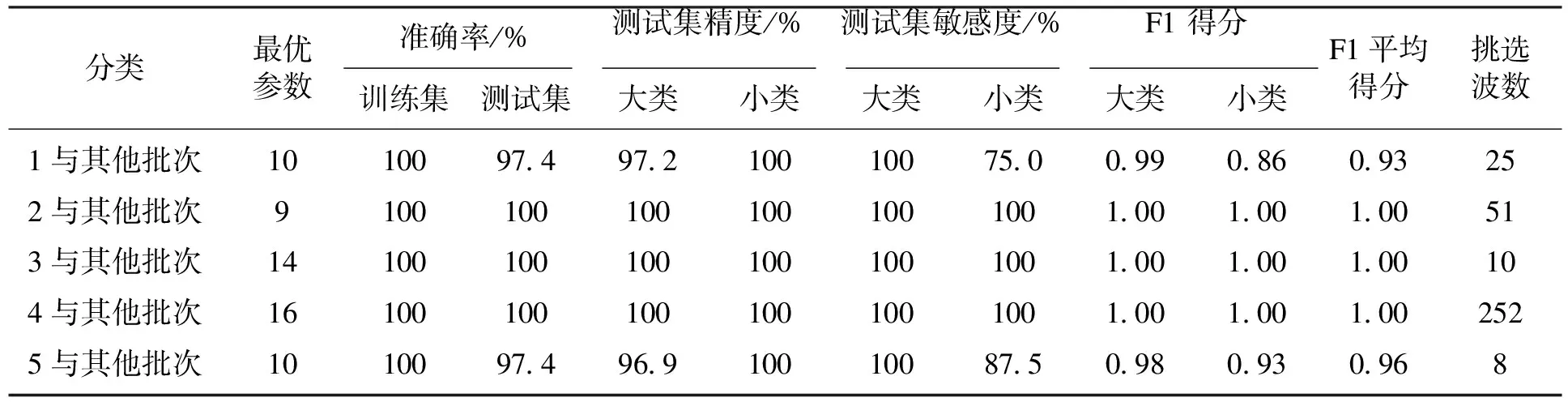
表4 RF-PLSDA方法的分类结果
2.3 三种波数选择方法比较
将SPA-PLSDA,CARS-PLSDA,RF-PLSDA三种方法进行比较.对于训练集来说经过波数选择后对于鉴别γ-PGA批次准确率都非常高,对于测试集来说CARS-PLSDA方法效果较差,主要是因为CARS-PLSDA将批次1分类中全部归为了大类,导致准确率低.而SPA-PLSDA和RF-PLSDA两种波数选择方法取得的效果相差不大,均能很好地对γ-PGA发酵批次进行判别.其中SPA-PLSDA将批次2,4和5的准确率提升到了100%,RF-PLSDA将批次2和4的准确率提升到了100%,将批次5提升了2.5%达到97.4%.具体数据如表5所示.

表5 三种波数选择方法比较
3 结 论
1)利用波数选择的方法对ATR-FTIR光谱仪测量的γ-PGA发酵液的5个批次进行快速鉴别,相比于直接应用PLSDA,波数选择方法显著降低了模型复杂度.
2)在波数选择方法中,CARS算法由于每次迭代中要消除的变量数量由指数递减函数决定,消除变量数太多,尽管大幅降低模型复杂度,但其他指标并不理想.
3)RF和SPA算法都取得了良好的效果,经过SPA和RF波数选择后,批次2,4和5的各项指标都得到了提升.其中SPA-PLSDA方法在批次2~5上的准确率更是达到100%,批次1达到97.4%.因此合适的波数选择的方法结合PLSDA可以成功应用到γ-PGA的批次鉴别上.
