利用对话模型引导的对话生成推荐
2022-11-08齐孝龙韩东红乔百友
齐孝龙, 韩东红, 高 翟, 乔百友
(东北大学 计算机科学与工程学院, 辽宁 沈阳 110169)
推荐系统可以解决海量数据导致的信息过载问题,旨在通过分析用户行为、兴趣、个性化需求等预测用户感兴趣的信息,诸如商品、新闻、感兴趣的话题等[1].
传统的推荐系统不能与用户进行很好地交互,从而影响了用户体验.有研究表明,对话式推荐能够更好地解决推荐系统中的冷启动问题[2],而且在可解释性方面优于基于深度学习的推荐系统[3].基于此,对话式推荐技术开始进入学术界和工业界的视野[4-10].
已有的对话推荐研究多以目标或话题为导向[7,9],即通常采用Pipeline方式,首先利用分类模型预测对话目标、话题或推荐实体,再根据预测得到的对话目标等指导生成合适的推荐对话.由于分类标签的空间过大(大约1 000个)[9],导致预测的准确率不高.针对上述问题,本文提出了一种利用对话模型引导的对话生成推荐(dialogue guided recommendation of dialogue generation,DGRDG)模型,通过对话模型生成对话目标,因对话目标的生成是逐步的,DGRDG模型在每一时间步的目标生成模块均融入上下文信息,生成的对话目标质量优于分类模型;本文提出一种目标重规划策略(goal replan policy,GRP),即在生成对话目标后,利用对话目标之间的关系和对话目标与对话目标候选集中元素之间的语义相似度,调整生成的对话目标,使得对话目标的准确率比未引入该策略前提高了3.93%;最后通过在DuRecDial数据集上进行实验,结果验证了所提出的模型的有效性.
1 相关工作
推荐对话数据集样例如图1所示.对话推荐任务由推荐系统和对话系统构成,本文将分别介绍对话系统、对话目标预测和对话推荐系统的相关工作.对话系统包括面向任务和非面向任务两类:面向任务的对话系统大多将整个对话流程使用管道(Pipeline)的方式连接起来;而非面向任务的对话系统则多使用端到端生成或检索的方式[11].现有的一些研究关注对话推荐系统的对话能力,尝试基于端到端的方式构建模型.这些模型旨在学习人类会话语料库中的模式,并且通常是不透明的且难以解释.端到端方法在推荐和响应方面的人工评估效果不佳,因此设计一个明确的对话策略是非常必要的[12].面向推荐的对话系统其本质也是一种任务型的对话系统,所以适合使用Pipeline方式.
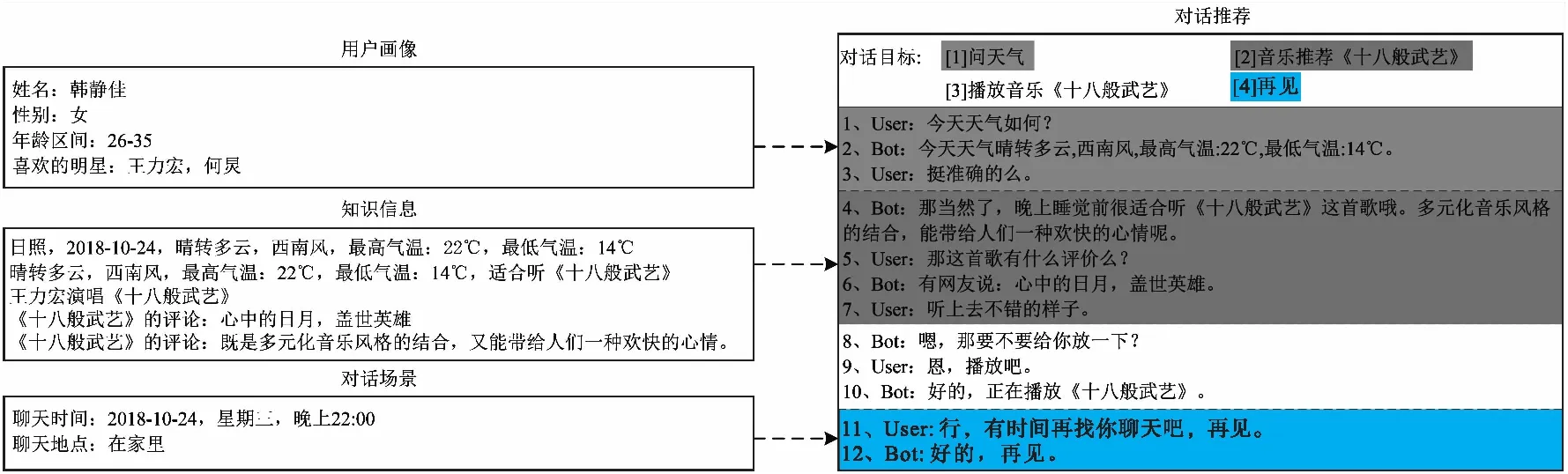
图1 对话推荐数据集样例
作为Pipeline模型中的重要组成部分,对话目标预测很大程度上影响着最终生成回复的质量.对话目标预测任务是自然语言理解(natural language understanding, NLU)的一个子方向,与对话行为识别、对话状态跟踪以及意图识别相似,目前研究主要通过以下两种方式来实现:①分类模型,Pavuri等[13]使用基于RNN和LSTM的模型实现NLU,并发现在输入完整信息后再进行意图分类的效果更好;Guo等[14]通过使用一个两阶段模型来解决对话状态跟踪中标签重复的问题,从而提高了模型的预测效率.②将原问题转化为序列到序列任务;Colombo等[15]使用Seq2Seq模型在编码阶段使用层次化编码器获取不同粒度下的编码信息,在解码阶段的每一时间步预测单个话语的对话行为,并在实验中验证了所提出模型的有效性.经过上述通过分类模型或者序列到序列的标签预测模型处理NLU问题的基础上,对话系统再通过下游的自然语言生成(natural language generation, NLG)模块生成最终的回复.
现有对话推荐任务的解决方案多采用Pipeline方式.Zhou等[6]提出了结合面向单词和实体的知识图谱以增强对话推荐中的数据表示,并采用互信息最大化来对齐单词级和实体级的语义空间,从而可以在响应文本中生成信息丰富的关键字或实体.Zhou等[7]提出了一种话题引导会话推荐模型,并在实验中证明了该方法在主题预测、项目推荐和响应生成三个子任务上的有效性.
以上对话推荐相关模型多采用分类模型预测出对话目标、话题或推荐实体,再对推荐对话的生成进行指导[7],但当标签数量很大时分类效果并不理想;或者使用端到端的方式将对话管理模块隐式地融合在整个对话推荐系统中[6].鉴于Pipeline模型在任务型对话中获得的良好效果,本文尝试利用Pipeline模型来解决对话推荐任务,在上游使用对话模型来生成对话目标,期望对话模型能够充分学习输入信息之间的语义信息,进而生成更合适的对话目标来对下游推荐对话的生成进行指导.
2 模 型
2.1 问题定义
对话推荐任务的定义如下:
定义1用户画像P={p1,p2,…,pnp},其中pi为第i个用户画像键值对,np为用户画像键值对个数.
定义2知识信息K={k1,k2,…,knk},其中ki为第i条知识.
定义3对话历史H={h1,h2,…,ht-1},其中hi={wi,1,wi.2,…,wi,nw}为第i条对话历史,t为当前对话轮次,wi,j为第i条对话历史的第j个字.
定义4对话目标G={g1,g2,…,gng},其中gi为第i个对话目标,gi包含两部分,Goal_type和Goal_topic,如“美食推荐(Goal_type)水煮鱼(Goal_topic)”,ng为对话目标的个数.
定义5生成回复Y={y1,y2,…,yny}.其中yi为生成的回复中的第i个字.
训练集中所有的对话目标都是已知的,但测试集中只给出第一个以及最后两个对话目标.基于此,模型的任务为:首先预测出本轮对话的对话目标GOAL,并根据预测出的对话目标生成对应的回复Y.
2.2 DGRDG模型总体架构
受到文献[9]的启发,DGRDG模型整体分为3个子模块:IsGoalEnd模块、GoalPlan模块和ResponseGeneration模块.如图2所示,其中GoalPlan模块由NextGoalGeneration子模块与GRP构成.首先使用IsGoalEnd模块判断上一轮次的对话目标是否结束,结束则调用GoalPlan模块生成当前轮次的对话目标,没有结束则依然使用上一轮次的对话目标作为当前轮次的对话目标;得到当前轮次的对话目标后,调用ResponseGeneration模块生成最终的回复Y.

图2 DGRDG模型总体架构
2.3 IsGoalEnd模块
鉴于预训练模型在分类任务上的优异表现,本模块融合BERT-wwm(之后用BERT表示)[16]及BiLSTM构建回归模型.首先将对话历史H与上一轮次的对话目标gt-1拼接(若超过模型最大输入长度,则从后往前截取到标点符号处)后形成一个句子,将其输入至BERT得到整个句子的矩阵,表示为
HI=BERT([h1;h2;…;ht-1;gt-1]).
(1)
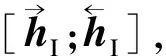
(2)
若PIsGoalEnd>0.5,表示上一轮次的对话目标已经结束,需要生成新的对话目标作为当前轮次的对话目标;若PIsGoalEnd≤0.5,则表示上一轮次的对话目标尚未结束,依然使用上一轮次的对话目标作为当前轮次的对话目标.可将该模块表示为一个函数:IsGoalEnd(H,gt-1).
2.4 GoalPlan模块
2.4.1 NextGoalGeneration子模块
本模块利用对话模型生成新的对话目标GOAL.如图3a所示,Encoder首先获取输入的信息(包括知识信息K、用户画像P、对话历史H)融合上下文的编码表示,如对于知识信息K,首先获取其编码表示KGembedding,再将其输入至BiGRU中:
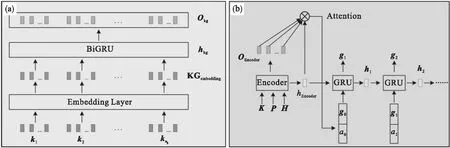
图3 NextGoalGeneration子模块
Okg,hkg=BiGRU(KGembedding).
(3)
其中,KGembedding为知识信息的编码表示,再将句子经过Embedding Layer得到相应的编码表示,Okg与hkg则分别为BiGRU的输出与隐藏层状态.
采用同样的方法,获取用户画像P和对话历史H融合上下文信息的编码表示与隐藏层状态:Oup,hup和Ohis与hhis;再将知识信息、用户画像信息及对话历史信息融合上下文的编码表示,Okg,Oup和Ohis拼接,得到Encoder最终编码表示:
OEncoder=[Okg;Oup;Ohis].
(4)
将知识信息、用户画像信息和对话历史信息的隐藏层状态hkg,hup和hhis进行拼接和线性变换,得到Encoder最终的隐藏层状态,用于初始化Decoder的隐藏层状态:
hEncoder=W[hkg;hup;hhis]+b.
(5)
其中,W,b分别为可学习的参数和偏置.
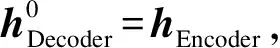
(6)
(7)
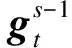
(8)
γs-1=softmax(γs-1′),
(9)
as-1=(γs-1)TOEncoder.
(10)
最终采用交叉熵损失函数对该模块进行优化,解码时采用贪心解码策略.
2.4.2 目标重规划策略GRP
对话目标由两部分构成,分别为Goal_type与Goal_topic,且Goal_type之间存在着如图4所示的关系[9],所以可以根据Goal_type之间的关系对模型预测出的对话目标进行调整,如上一对话目标的Goal_type为“音乐推荐”,则下一对话目标的Goal_type则为“播放音乐”或“关于明星的聊天”;2.4.1节中对话模型所输出的句子与真实值有时存在一些误差,如真实值为“美食推荐水煮鱼”,而模型的输出则可能为“美食推荐鱼”,所以可以计算预测值与候选目标集中的元素的语义相似度来对预测值进行调整.基于以上两方面的因素,提出目标重规划策略GRP,对2.4.1节所预测出的对话目标进行修正.
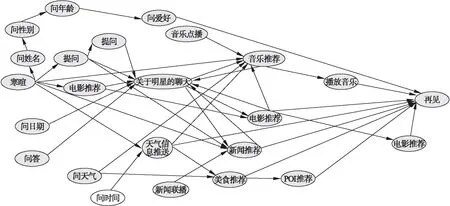
图4 Goal_type之间关系
步骤1 首先根据上一轮次的对话目标与Goal_type之间的关系,筛选出Goal_type候选集,如上一轮次的对话目标为“天气信息推送”,则Goal_type候选集为[“音乐推荐”, “美食推荐”, “再见”].
步骤2 将Goal_type候选集中需要Goal_topic的元素(“美食推荐”和“音乐推荐”)与知识信息中的实体进行排列组合,构成对话目标候选集,如[“音乐推荐一剪梅”, “音乐推荐月亮代表我的心”,…,“美食推荐水煮鱼”,“美食推荐口水鸡”,…, “再见”],其中“再见”为不需要Goal_topic的Goal_type,所以不参与排列组合的过程.
步骤3 将2.3节所输出的对话目标与步骤2构建的对话目标候选集中的每一个元素计算TF-IDF值作为得分,并选择对话目标候选集中得分最大的元素作为最终的对话目标.
可将2.4.1节与2.4.2节结合,共同表示为一个函数:GoalPlan(K,P,H).
2.5 ResponseGeneration模块
在本模块中,将采用与2.4.1节中相似的架构生成最终的回复Y.为了能够获取融入对话目标信息的对话历史表示,需将当前轮次的对话目标GOAL加在对话历史之前.并且在利用式(3)计算出融合上下文的各个输入信息的表示后,使用一种交互注意力机制[17]计算对话历史表示与知识信息以及用户画像的注意力,得到融合对话历史的知识信息表示和融入对话历史的用户画像表示.并按照式(4)将各个输入信息进行拼接,得到Encoder最终的编码表示.再使用与2.4.1节中相同的Decoder架构生成最终的回复Y.与2.4.1节相同,本模块采用交叉熵损失函数对该模块进行优化,解码时采用贪心解码策略.可将该模块表示为一个函数:ResponseGeneration(K,P,H, GOAL).
3 实验与分析
3.1 训练与推理策略
总体模型的三个模块进行分别训练,并在测试时组装在一起.具体处理过程如算法1所示.第1行将第1个对话目标赋值给GOAL,并给H′与j赋初值,H′为循环过程中的对话历史,j表示当前是第j个对话目标.由于对话目标是残缺的,需要对残缺的对话目标进行补充,所以需要对所有的对话历史进行遍历,如第2行所示.第3行将对话历史中第i条话语加入H′中,第4行调用IsGoalEnd模块判断针对当前的对话历史H′,当前的对话目标GOAL是否结束.若需生成下一对话目标.由于已知对话目标的总个数为ng-1,且已知最后两个对话目标,所以第6行判断需生成的对话目标是否为倒数第二个,若是倒数第二个,则第7行直接将已知的倒数第二个对话目标赋值给GOAL;否则,第8行再判断需生成的对话目标是否为倒数第一个,若是倒数第一个则第9行直接将已知的倒数第一个对话目标赋值给GOAL;若不是,则第11行调用GoalPlan模块生成新的对话目标赋值给GOAL.第14行判断对话历史是否已经全部遍历完成,如果尚未遍历完成,则遍历下一条对话历史;若已遍历完成,则在第17行调用ResponseGeneration模块生成最终的回复Y,至此循环结束,并在第20行输出所生成的回复Y.
算法1 对话模型引导的推荐对话生成DGRDG.
输入:用户画像P、知识信息K,对话历史H={h1,h2,…,ht-1},对话目标G={g1,g2,…,gng},
输出:回复Y.
1 GOAL=g1,H′={},j=1
2 Fori=1,2,…,t-1 Do
3 将hi加入H′中
4 If IsGoalEnd(H′,GOAL)> 0.5
5j++
6 Ifj==ng-1
7 GOAL=gng-1
8 Else Ifj≥ng-1
9 GOAL=gng
10 Else
11 GOAL=GoalPlan(K,P,H′)
12 End If
13 End If
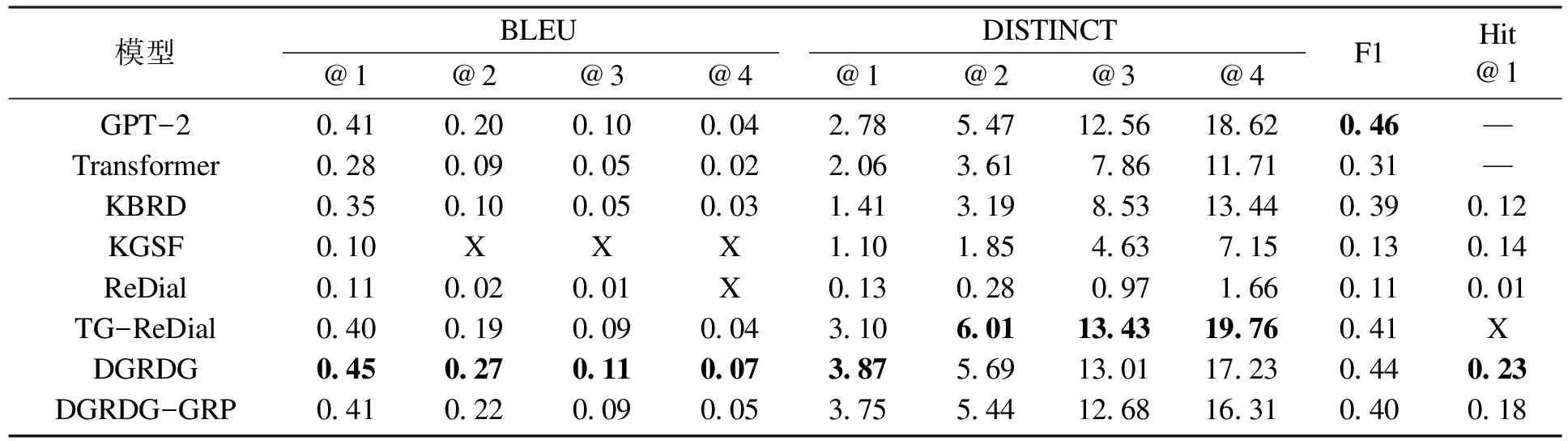
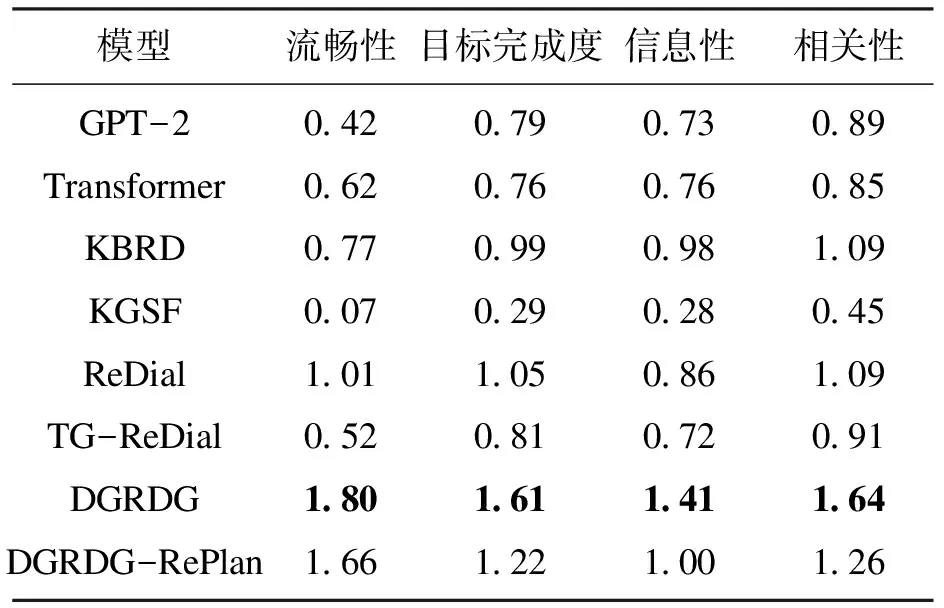
14 Ifi 15i++ 16 Else 17Y=ResponseGeneration(K,P,H′, GOAL) 18 End If 19 End For 20 ReturnY 本文使用DuRecDial数据集[9],由于其中测试集的标注值没有发布,所以将原DuRecDial数据集中的验证集作为测试集,原DuRecDial数据集中的训练集随机选择10%作为验证集,原DuRecDial数据集中的训练集剩下的90%作为训练集进行实验. 对于整体模型,采用F1衡量字粒度的重合程度,BLEU@n衡量n-gram的重合程度,同时采用DISTINCT@n衡量n-gram对话内容多样性.由于GoalPlan模块只可生成一个对话目标,该对话目标也只含有一个推荐实体,所以在推荐方面将采用推荐系统中的Hit@1作为评价指标.并且,将采用准确率(即生成的对话目标与标注值完全相同的概率)作为评价指标评价GoalPlan模块的性能. 3.4.1 与DGRDG模型对比的方法 GPT-2[18]:一种使用大规模语料训练的生成式预训练模型. Transformer[19]:一种基于注意力机制的Encoder-Decoder架构. KBRD[5]:一种基于知识图谱的对话推荐系统. KGSF[6]:一种结合了面向单词和面向实体的知识图谱的对话推荐系统. ReDial[4]:一种融合了基于用户的协同过滤和情感分析的对话推荐系统. TG-ReDial[7]:一种基于话题引导对话推荐的模型. 针对以上模型,使用Zhou等[20]开源的CRSLab库进行实现. 3.4.2 与GoalPlan模块对比的方法 对于GoalPlan模块,为验证本文所提出的对话模型生成对话目标的有效性,以及GRP策略的有效性,将与以下模型进行对比: BERT[16]:一种经过微调就可以在下游的分类任务中达到很好的分类效果的预训练模型. BERT+LSTM:在BERT后附加LSTM来对上下文信息进行增强. MTTDSC[21]:一种基于GRU的应用于多任务分类的深度学习模型. Seq2SeqDU[22]:一种将对话状态跟踪转换为序列到序列标签预测任务的模型. 使用Pytorch框架复现了前两种模型,对于MTTDSC和Seq2SeqDU模型则使用了文献[22]中所开源的代码. 3.5.1 自动评价 各模型在F1,BLEU@n,DISTINCT@n以及Hit@1等自动评价指标上的表现见表1.本文所提出的DGRDG模型在BLEU@n指标上均优于所对比的模型,说明DGRDG模型能产生与标注值更相似的回答.但DISTINCT@n指标中只有DISTINCT@1最优,在DISTINCT@2~4上的表现均弱于TG-ReDial模型,原因是由于TG-ReDial模型在推荐实体的选择上多样性较高,导致模型所输出的回复在内容多样性上占据了优势.DGRDG模型在推荐的准确性上是最优的,在Hit@1指标上相比于次好的KGSF模型高出0.09,而在DISTINCT@n上占优的TG-ReDial模型在Hit@1指标上的表现反而是最差的,原因在于TG-ReDial模型在推荐实体的选择上较多而导致推荐准确度不高.在与标注值字粒度的重合程度上,GPT-2由于其强大的文本生成能力,在F1指标上表现最优.DGRDG模型在该指标上的表现相比于其他模型依然是最好的,而且相比于GPT-2,在F1评价指标上仅相差0.02. 表1 各模型自动评价指标得分 为了验证所提出的目标重规划策略GRP的有效性,进行消融实验,即将目标重规划策略从整体模型中移除,直接使用NextGoalGeneration子模块所生成的目标进行回复的生成,最后的实验结果在各个评价指标中都造成了不同程度的下降,尤其在Hit@1指标上,相比于原模型减少了0.05. 在对话目标预测方面,由于本文所使用的GoalPlan模块是由两个阶段所构成,所以为了实验的公平性和衡量GRP策略的性能,将GRP策略与其他对比模型相结合,具体实验结果见图5.本文所提出的GoalPlan模块在准确率上均优于所对比的模型,消融实验表明,GRP策略为模型在预测准确率上带来了3.93%的提升.所对比的模型表现差的原因,是分类模型或序列标注模型在解决对话目标预测的问题时,由于标签的数量太大,模型不能很好地学习到输入数据与标签的关系.对于所对比的模型而言,加入GRP策略后,带来的提升并不明显(最多只带来0.54%的提升).究其原因,是因为本文提出的GRP策略是在字粒度上对预测出的对话目标进行修正,与本文所用的NextGoalGeneration适配程度较高,但对于其他所对比模型,由于其是分类模型或序列标注模型,所输出的结果都是标签级别的,GRP策略所能带来的提升并不显著. 说明:NextGoalGeneration为本文所提出的NextGoalGeneration模块;+GRP表示添加GRP策略后模型的表现. 3.5.2 人工评价 为了能够更好地对模型的输出结果进行评估,引入人工评价,评价的指标为:①流畅性,用于评估模型的输出结果是否符合人类的说话习惯;②目标完成度,用于评价模型生成的回复是否完成了对话目标;③信息性,用于评价模型在生成回复时是否准确地使用了所输入的知识信息;④相关性,用于评价模型生成的回复是否与对话的语境相关. 所有的指标都分为3个等级:“0”表示差;“1”表示一般;“2”表示好.邀请一家专业的数据标注公司进行人工评价,标注人员一共有三位,每个人都需对全部的数据进行评价,且为保证公平,模型对评价人员是匿名的,最后得分取三位标注人员所给出得分的平均值,结果如表2所示.可以看出,所提出的模型在各指标上的表现都显著地超过了所对比的模型,并且消融实验中,模型在没有GRP策略的情况下,相比于所对比的模型依然占据着优势.在目标完成度、信息性和相关性的指标上相比于完整的模型下降幅度较大,都在0.4左右,但在流畅性方面只下降了0.14.这样的结果说明了所提出的DGRDG模型的有效性,而且由于模型主要依靠准确的目标作为指导,所以这样的实验结果同时也证明了所提出的GRP策略的有效性. 表2 各模型人工评价得分 本文提出了一种利用对话模型引导的推荐对话生成模型DGRDG,并在对话目标生成模块生成当前的对话目标后,为了修正该模块的输出结果,引入目标重规划策略 GRP来提高对话目标预测的准确率.经过在DuRecDial数据集上进行实验,结果表明所提出的模型在生成的回复质量和推荐质量都拥有较好的效果,消融实验也证明了所提出的目标重规划策略GRP的有效性.3.2 数据集
3.3 评价指标
3.4 模型说明
3.5 实验结果与分析

4 结 语
