无人机空中基站的路径规划研究
2022-11-07周永涛
周永涛,刘 唐,彭 舰
(1.四川大学 计算机学院, 成都 610065; 2.四川师范大学 计算机科学学院, 成都 610101)
0 引言
得益于无人机(unmanned aerial vehicle,UAV)的一些优点,例如很高的机动性、可按需部署、成本较低等,可以将其作为空中基站[1](base station,BS)与地面用户建立无线连接以提供通信服务,增强网络的覆盖范围以及数据传输性能。空中基站被部署在一定高度的空中,相较于传统地面基站能够有更大的机会与地面用户建立视距链路连接(line-of-sight,LoS)。空战基站有很多实际应用场景,例如在地面基站受损的灾害环境中提供稳定可靠的无线通信服务,以及在传统地面网络出现拥塞时作为辅助通信基站。
近年来,无人机作为空中基站提供无线通信服务受到了较为广泛的关注[2-9]。在关于基站无人机的研究中,有较多工作致力于寻找基站无人机的部署位置[4-6]。Zhang等[4]以最大化用户体验质量(quality of experience,QoE)为目标寻找无人机的最佳部署位置;Zhang等[5]通过设计基站无人机的三维部署位置来增强目标信号强度和减少信道干扰;Valiulahi等[6]在存在同频道干扰的情况下,以最大化所有地面用户可实现的最小系统吞吐量为目标计算基站无人机最佳的三维部署位置。这类研究将无人机作为静态空中基站,忽视了无人机的高机动和可控制特性。另外,有部分研究关注于计算无人机的飞行路径[7-9],通过规划无人机的飞行路径最大化下行通信中所有地面用户的最小吞吐量[7]、最大化无人机飞行期间的整体平均总传输速率[8]、实现对目标区域较高的通信覆盖率[9]。这类研究在设计无人机飞行路径时没有考虑地面用户位置可能发生变化。
上述对于基站无人机部署问题和飞行路径规划问题的研究很少考虑到地面用户的移动。然而在现实应用场景中,地面用户的活动往往呈现动态性和随机性[10-11]。地面用户持续移动且基站无人机的通信范围有限,可能降低地面移动用户与基站无人机间的无线通信速率,从而造成网络性能的损失[12]。故在部署基站无人机的无线通信网络中考虑地面用户的移动是必要的。
得益于无人机的机动性和可控制特性,可以通过动态调整无人机的飞行距离和飞行方向角(即规划无人机的飞行路径)实时追踪地面移动用户,提高用户与基站无人机间的无线通信速率,增强无人机网络性能。在考虑地面用户移动的无人机网络中,规划基站无人机飞行路径的挑战主要有两点:一是无人机的飞行距离和飞行方向角都是连续变量[13],在连续空间内寻找最优的飞行动作比较困难;二是在实时追踪持续移动的地面用户时,很难保持优化算法的较高性能[14]。

本文提出一种基于DRL的基站无人机路径规划算法(DDPG-TD)来应对地面用户移动的无人机网络,以避免由于用户移动造成的无人机网络性能损失。将基站无人机提供通信服务的任务周期划分为多个时间间隔相同的时隙,算法以最大化任务周期内无人机网络总吞吐量(所有时隙内的网络吞吐量之和)为目标,在连续动作空间中计算出每个时隙内无人机的飞行动作,完成对无人机飞行路径的规划。算法中的DRL模型经过训练后能够针对变化的地面用户位置做出相应的飞行策略调整。为验证本文提出的算法在规划基站无人机飞行路径时的有效性,将DDPG-TD算法与3种较为常用的算法进行比较。仿真结果表明,DDPG-TD算法中的无人机网络吞吐量明显高于3种对比算法。此外,本文还对DRL中的神经网络结构设计和超参设定进行了实验对比,以挑选合适的神经网络结构和超参设定。
1 模型建立
1.1 环境模型
在一个部署基站无人机的无线通信网络中,有多个基站无人机为多个地面用户提供无线通信服务,地面用户的位置可能持续变化,如图1所示。
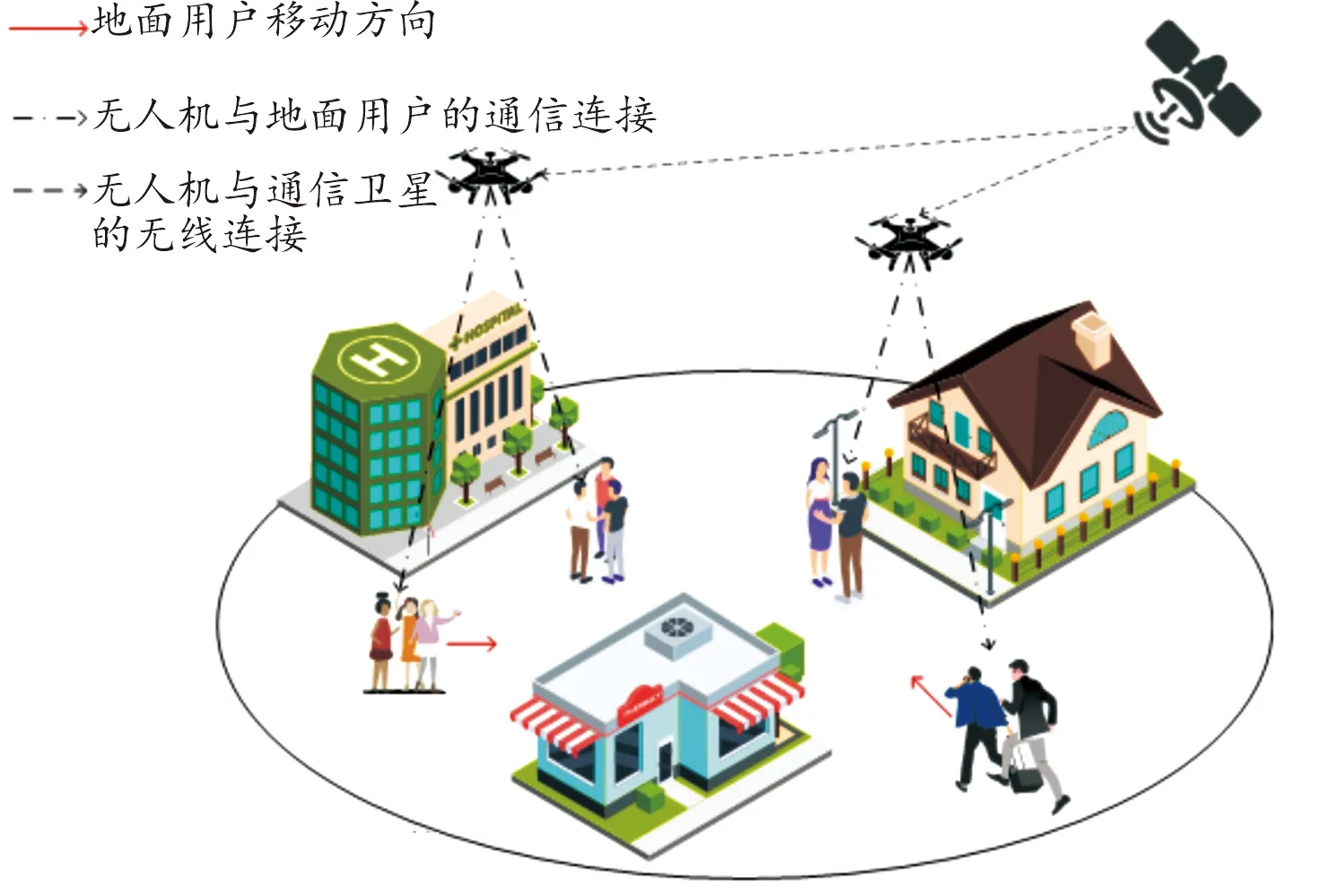
图1 地面用户移动的无人机网络示意图
基站无人机的数量为K,地面用户的数量为N。所有基站无人机可以通过通信卫星与外部网络建立通信连接。由于地面用户的位置随着时间的推移发生改变,可能导致固定位置部署的基站无人机与地面用户间的无线通信速率下降。因此需要规划无人机的飞行路径实时追踪地面移动用户,提高用户与基站无人机间的无线通信速率。假定一个基站无人机为地面用户提供网络通信服务的任务,该任务时长为T个时隙,每个时隙的时间间隔均相同。在任务初始时刻,每个基站无人机在随机位置起飞,并以固定高度H飞行,随后使用本文提出的路径规划算法不断调整自己的飞行轨迹,使T个时隙的任务周期内无人机网络中总吞吐量最大化。每个用户在一个时隙内仅可以与一架基站无人机建立通信连接,无人机在同时服务多个地面用户时使用的是频分多址(frequency division multiple access,FDMA)技术。
1.2 无人机飞行路径表示

给定时隙t基站无人机k的飞行方向角和飞行距离,基站无人机k在时隙t内终点位置的三维坐标可以表示为:

(1)

1.3 地面用户移动模型
地面用户的活动具有动态性和随机性,目前有较多研究对地面用户的活动进行预测建模,文献[16]对这些地面用户运动模型做了比较全面的调查。其中一种比较常见的模型是随机游走模型(random walk model,RWM)。RWM中,地面用户的移动方向由均匀分布在[0,2π]之间的角度决定,且用户被分配一个随机速度,这个速度的范围是[0,vmax],vmax表示一个普通行人的最大行走速度。
指定地面用户n的移动方向角和速度为(σn,vn),在时隙t的时间间隔充分小,且地面用户的移动速度v较小的前提下,用户n在时隙t内的二维坐标表示为:

(2)


(3)
1.4 通信覆盖表示及信道速率计算
1.4.1通信覆盖表示


(4)

1.4.2信道速率计算
地面用户与基站无人机之间的通信连接可以看作是空对地通信信道(air-to-ground channels),该信道的路径损失(path loss)被建模为视距链路连接(line-of-sight,LoS)和非视距链路连接(none-line-of-sight,NLoS)2个传播类[17]。用户n与无人机k之间建立LoS连接的概率计算如下:

(5)
式中: 常量参数α和β取决于环境(如城市环境或乡村环境等)。φ=sin-1H/d表示用户n与无人机k之间的仰角,由式(3)可以计算d。平均路径损失可以表示为:

(6)
式中:fc和c分别表示载波频率和光速,常量ηLoS和ηNLoS表示自由空间中信号传播的额外损失。另外,非视距链路概率PNLoS=1-PLoS。
本文中无人机同时服务多个地面用户使用的是FDMA技术。在计算用户传输速率时不考虑用户传播信道之间的干扰。根据香农公式,用户n和无人机k之间的传输速率可以表示为:
Rn,k=Wn,klog2(1+10SNRn,k/10)
(7)
式中:Rn,k的单位是bit/s,Wn,k表示通信信道带宽,SNRn,k是信噪比,计算如下:
SNRn,k=pn,kLn,k/Ngw
(8)
式中:pn,k表示无人机k到用户n的传输功率,Ngw是加性高斯白噪声(additive white gaussian noise),Ln,k可由式(6)计算。
1.5 问题描述
为了提高用户与基站无人机间的无线通信速率,增强无人机网络性能,目标是最大化任务周期内无人机网络的总吞吐量Csum:

(9)
由于无人机的飞行动作空间是连续的,且地面用户活动呈现动态性和随机性,这就导致解决最大化Csum问题是具有挑战性的[18]。基于传统搜索式算法会带来比较高的计算复杂度。为了解决该问题,本文提出DDPG-TD算法来计算基站无人机的飞行路径。
2 DDPG-TD路径规划算法
2.1 深度强化学习
强化学习是和监督学习、非监督学习并列的第3种机器学习方法,其更侧重于以交互目标为导向进行学习,近年来强化学习在一些游戏应用中表现出不错的性能。强化学习中,智能体与系统环境不断进行交互,以实现目标收益最大化为目标,学习环境中不同状态对应的正确动作。结合了深度学习的强化学习解决了传统强化学习中状态空间和动作空间无限带来的“维度灾难”问题,它利用神经网络帮助智能体在与环境的交互中不断学习理想动作,可以应对更复杂的状态空间和时变环境。
在标准的强化学习中,智能体在离散的时间点(Epoch)与系统环境进行交互。如图2所示,在每一个时间点t,智能体观察此时的环境状态st,选择执行动作at后得到相应的奖励rt。强化学习旨在找到每个状态下对应的动作,即策略π(s),该策略能够最大化总的折扣奖励R:

图2 强化学习中的智能体与环境交互示意图
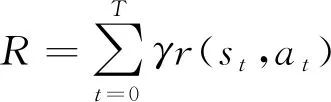
(10)
式中,r(·)是奖励函数(reward function),折扣因子γ∈[0,1]。
标准的强化学习需要记录每个状态下的动作价值分布,当环境状态集合复杂甚至状态空间连续时,很难实现记录每个状态下的所有动作价值。为了处理复杂的状态空间,DRL使用深度神经网络(deep neural networks,DNN)构成一个近似函数Q(·):
Q(st,at)=E[Rt|st,at]
(11)
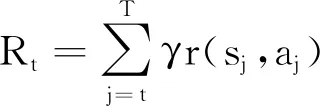
(12)
式中:Q(·)近似估计动作at在状态st下的累积期望折扣奖励。DRL中比较常用的寻找策略π(s)的方法是贪心算法:
π(st)=argmaxatQ(st,at)
(13)
DRL中称该网络为深度Q神经网络(deep Q network,DQN)。最小化均方差损失函数L(θQ)训练DQN:
L(θQ)=E[yt-Q(st,at|θQ)]
(14)
式中:θQ是DQN的权重向量,yt是目标价值,可以通过以下表达式计算:
yt=r(st,at)+γQ′[st+1,π′(st+1|θπ′)|θQ′]
(15)
深度强化学习一般利用经验回放和目标网络技术协助训练神经网络[15]。经验回放池用于保存智能体和环境交互得到的奖励值和状态更新。训练阶段,在经验回放池中按一定规则采样若干数据来更新神经网络。经验回放能够解除用来训练网络的序列数据之间的相关性,能够避免难收敛问题,同时训练过程也更加平滑。DRL使用目标网络估计目标价值yt,双网络方式能够消除DQN过度估计的问题。目标网络和原始DQN网络具有相同的结构,但是目标网络的参数更新要比原始网络慢。
▽θπJ=E[▽atQ(s,a|θQ)|s=st,a=π(s|θπ)·
▽θππ(s|θπ)|s=st]
(16)
2.2 DDPG-TD算法设计
本文提出一种基于DRL的基站无人机路径规划算法。在该算法中,DRL智能体周期性地收集地面环境数据(地面用户的位置),根据地面环境计算出每个时隙最优的飞行动作,并通过指令将动作信息发送给正在提供无线通信服务的基站无人机,无人机收到指令做出相应的调整。基于DRL算法的设计思想,定义的状态、动作和奖励值等如下:
1) 状态st:在任务周期内的每个时隙,定义的状态st包含以下3个方面:

②pgn:当前时隙地面用户n的位置坐标;
③puk:当前时隙基站无人机k的位置坐标。

2) 动作at:定义基站无人机在每个时隙的飞行动作包含2个方面:


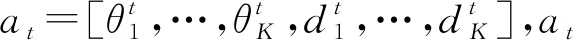
3) 奖励值rt:在时隙t采取了动作at后得到的奖励值定义为:
(17)
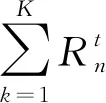
4) 惩罚值penalty:每个时隙无人机执行动作at后,如果存在无人机飞出地面边界或者无人机之间发生碰撞,将会在该时隙获得的奖励值上减去惩罚值,这样能够有效避免无人机飞出地面边界以及无人机之间发生碰撞。
2.3 DDPG-TD算法框架
如图3所示,DDPG-TD算法由一个智能体和无人机网络环境组成,智能体中有4个神经网络和一个经验回放池。算法中的4个神经网络,分别是评论者网络Q(st,at|θQ)和执行者网络π(st|θπ),以及评论者目标网络Q′(st,at|θQ′)和执行者目标网络π′(st|θπ′)。目标网络和原网络具有相同的结构,算法使用目标网络解决网络训练过程中的过度估计问题。网络更新的数据由智能体和无人机网络环境交互产生。在智能体与无人机网络环境交互阶段,执行者网络根据当前时隙环境的状态st计算出对应的动作at,智能体执行该动作并观察得到环境状态的转变st+1以及对应的奖励值rt,并将得到的数据(st,at,rt,st+1)存入经验回放池。经验回放池B的容量大小设置为S,并设置一个累积经验阈值Bth,当B中存放的数据量未达到Bth时,无人机动作at的选择是随机的;当B中累积经验数据达到Bth后,对π(st|θπ)加噪声后得到无人机动作at,本文采用正态分布随机变量噪声。

图3 DDPG-TD算法框图
在神经网络更新阶段,先从经验回放池B中随机采样大小为Bs的小批量数据,对这些数据进行归一化处理后,通过最小化式(10)的损失函数L(θQ)来更新评论者网络参数θQ,并通过计算式(12)的梯度▽θπJ来更新执行者网络参数θπ。目标网络和原始网络具有相同的结构,目标网络的更新速度慢于原始网络,更新速度由学习率控制。
3 实验仿真与结果分析
3.1 仿真实验设置
在仿真实验中,设置一个大小为的1 000 m×1 000 m的矩形目标区域,地面用户的数量为20,网络中部署2架基站无人机。相关参数[3,14]见表1。实验使用TensorFlow 2.0和Python 3.7,仿真设备为一台搭载28核2.4 GHz的Intel Xeno E5处理器和一张24 GB显存3090显卡的计算机。网络一共训练1 000幕(Episode),每一幕包含200个时隙(200 s)。执行者网络结构为两层全连接神经网络,第一个隐藏层包含600个神经元,第二个隐藏层包含500个神经元,使用ReLU函数作为激活函数。执行者网络输出层使用Sigmoid函数作为激活函数,防止输出的动作值超过算法设计的边界值。评论者网络也是两层全连接神经网络,第一层第二层分别包含600和500个神经元,使用ReLU函数作为激活函数。执行者和评论者网络中均使用L2权重衰减来防止过拟合。执行者网络和评论者网络结构见图4。通过大量的实验比较,找到神经网络中性能表现良好的超参。设置采样批量为512,折扣因子为0.9,执行者网络学习率为0.000 3。

表1 仿真参数

图4 执行者网络和评论者网络结构示意图
使用以下指标来对DDPG-TD算法做性能评估:
1) 网络吞吐量TPt:表示当前时隙所有地面用户无线传输速率之和,由式(7)计算传输速率。
(18)
将DDPG-TD算法与3种常见算法进行对比:

2) DMC(distributed motion control)[3]:该算法将地面用户区域对无人机的吸引看作为一个虚拟的力,通过对无人机受到的力进行受力分析,结合牛顿第二定律计算出无人机的飞行方向和飞行速度。
3) DDQN[19]:该算法也是强化学习算法。与DDPG-TD算法不同,该算法仅能够在离散的动作空间中选择价值最大的飞行动作。在DDQN算法实验中,将无人机的飞行动作划分成离散的值,例如飞行方向划分为东、南、西、北4个方向,飞行距离划分成小于等于dmax的多个值。
3.2 仿真实验结果及分析
图5展示了在DDPG-TD算法规划的基站无人机飞行路径下,无人机与地面用户的位置分布,图5(a)展示的是任务初始时刻2架无人机和20位地面用户的位置分布,图5(b)展示的是无人机执行任务100 s后,图5(c)展示的是无人机执行任务200 s后。在仿真实验中,20位地面移动用户分为2个簇,每个簇中各10位用户。2架无人机的初始位置分别设置为(450,200)和(550,200)。从1.4.2小节计算无线传输速率的过程可以看出,无人机与地面用户的距离越近则地面用户能够获得的无线传输速率越高。仿真实验中,图5展示无人机会逐渐飞向用户簇,以缩短移动与地面用户的距离,为用户提供较高传输速率的无线通信服务。图5中展示的地面用户是以簇的形式向固定方向移动,这样设定的目的是更清楚地展示无人机实时追踪用户的过程。在本文提出的DDPG-TD算法中,环境状态的设定包含了全部地面用户的位置以及无人机的位置。算法根据环境状态决定无人机飞行动作,故无论用户如何移动,在获得地面用户位置和无人机位置后,算法均能够规划无人机飞行路径。

图5 无人机与地面用户位置分布示意图
图6展示了本文提出的DDPG-TD算法与3种常见算法在每个时隙网络吞吐量上的对比结果。DDPG-TD、DDQN以及DMC 3种算法的网络吞吐量都有一个明显上升并趋于稳定的过程,而Random算法的网络吞吐量仅在一定区间内波动。这是因为前3种算法实现了无人机对地面移动用户的动态追踪,而Random算法中无人机每个时刻的飞行动作都是随机确定的。在无人机速度快于地面用户移动速度的前提下,DDPG-TD、DDQN以及DMC 3种算法通过规划无人机飞行路径不断缩小无人机与地面移动用户的距离,以提高无人机与地面用户之间的无线传输速率。在第10个时隙,DDPG-TD算法实现了每个时隙网络吞吐量最大化;在第13个时隙,DDQN算法也实现了网络吞吐量最大化;在第21个时隙,DMC算法基本实现了网络吞吐量最大化。在DDPG-TD、DDQN以及DMC 3种算法的网络吞吐量趋于稳定后,前2种强化学习算法相较于DMC算法更加稳定,DDQN在短暂波动后网络吞吐量基本稳定。这是因为2种强化学习算法根据所有地面用户的实时位置以及无人机的位置,以最大化吞吐量为目标规划无人机的飞行路径,在一段时间后算法寻找到了无人机与地面用户间最佳相对位置,故能够保持网络吞吐量稳定。而DMC算法将地面用户区域对无人机的吸引看作为一个虚拟的力。文献[3]给出该力的计算与无人机和用户间的距离有关,这种计算方法不能精确反应无人机与用户的位置对网络吞吐量的影响,故DMC算法的网络吞吐量在趋于稳定后存在波动的情况。可以看出,2种强化学习算法相较于DMC算法有更好的效果呈现。强化学习智能体与环境交互并学习最大化收益的策略,能够更好地应对地面用户移动的时变网络环境。得益于能够在连续空间中计算无人机的飞行动作,DDPG-TD算法相较于DDQN算法能够更快实现最大化网络吞吐量的目标(DDPG-TD算法在连续空间中计算飞行动作,无人机的飞行路径更加平滑)。在实际实验中,DDQN算法中的飞行动作离散值越多,神经网络输出维度会越大,网络的结构也会更复杂。

图6 每时隙网络吞吐量曲线
图7是4种算法分别在前5个时隙间隔、前10个时隙间隔以及前15个时隙间隔内的平均网络吞吐量,是对图6展示的吞吐量变化的补充。可以看出从前5个时隙到前10个时隙,再到前15个时隙,DDPG-TD、DDQN以及DMC 3种算法的平均吞吐量有明显的上升趋势,即3种算法在规划无人机逐渐飞往用户簇,缩小与用户之间的距离,提高无线网络传输速率。DDPG-TD算法可以在连续空间计算无人机的飞行动作,所以能够更快靠近用户簇,故能够保持平均吞吐量一直领先于对比的3种算法。

图7 平均网络吞吐量直方图
图8展示了超参对神经网络训练结果的影响。结构一(Struct1)是两层全连接神经网络,每层网络分别包含500和400个神经元;结构二(Struct2)是两层全连接神经网络,每层网络分别包含600和500个神经元。在3个学习率0.000 2、0.000 3、0.000 4对比下,找到了相对较好的超参设置,即执行者和评论者网络结构采用结构二,网络学习率设置为0.000 3。

图8 不同超参对训练结果的影响直方图
图9展示了深度强化学习模型在训练过程中奖励值的变化情况。随着训练轮次增加,奖励值逐渐增大并收敛在非常小的范围内[20]。奖励值的变化趋势代表每训练轮次(Episode)网络总吞吐量的变化趋势。

图9 训练过程中的奖励值曲线
4 结论
提出了一种基于深度强化学习的基站无人机路径规划算法,该算法在地面用户移动的无人机网络中规划多架基站无人机的飞行路径。仿真结果表明,通过所提算法规划基站无人机飞行路径,无人机网络的吞吐量始终维持在较高水平。提出的算法是一种集中式算法,无人机的飞行动作指令由后端服务设备计算给出,这对后端服务设备和无人机之间的往返通信连接有较高的带宽要求,在某些特殊情况如灾害环境下后端服务设备带宽可能无法支持与大量无人机进行通信连接。分布式算法较好地解决了上述集中式算法存在的问题。
