全域优化孪生向量机的钢板表面缺陷图像分类
2022-11-07侯政通乔磊明
胡 鹰,侯政通,安 宇,乔磊明
(太原科技大学 计算机科学与技术学院, 太原 030024)
0 引言
钢材是当今世界上最重要的工业材料之一,近年来随着新技术新工艺的不断应用,各种新产品不断涌现,如我国最新研发的手撕钢,其厚度只有0.02 mm,其生产工艺对钢材产品表面质量要求极为严格,我国目前在该领域处于世界领军水平。然而,当这些钢材在制造加工运输等环节中均会受到多种因素的影响,使其在外表面形成各种复杂类型的缺陷。这些缺陷附着或嵌入在钢板表面除了直接影响产品的美观之外,还间接影响了产品的结构质量和使用寿命,从而降低了企业的经济效益。为了能得到优质的成品钢板,需要建立起一套完备的缺陷识别流程体系,供一线生产检测识别。
钢板表面缺陷图像的识别首先需要从生产线上获取不同缺陷的图像,传统缺陷识别主要依靠一线工人目测,随着机器视觉技术的兴起,基于机器视觉的金属表面缺陷检测[1]已经成为当今各国钢铁企业的主流技术,大多采用高速线阵CCD摄像机拍摄钢板表面[2-6],通过融合提取特征[7],再输入到分类器中训练,最后完成对缺陷图像分类。
在传统机器学习分类方法中,Ünsalan等[8]对钢表面锈蚀等级做划分,将最近邻分类器用于带钢表面缺陷类型的识别。Tang等[9]通过提取到的特征,采用BP神经网络方法对冷轧带钢表面缺陷图像进行分类。Jeon等[10]采用支持向量机对划痕缺陷进行检测。但传统的K最近邻法(k-nearest neighbor,KNN)分类器在大数据中难以处理高维数据,并在不同类别之间重叠度高的部分容易判错;另外,BP神经网络训练针对大样本,而且需要通过反向传播不断修正误差,所以学习速度慢,易产生过拟合。而支持向量机(support vector machine,SVM)[11]的优点是考虑结构风险最小化原则,适用于小样本、高维度的二分类问题,能有效避免过拟合,具有良好的泛化性能。
虽然SVM在数据的分类和回归预测上展示了优异的性能,但随着研究的深入,SVM在处理高维数据,尤其在对图像复杂的特征分类时,无法用最大边际求解到一个合适的超平面,经常会产生较差的效果。实际上,传统的SVM算法旨在解决一个大规模的二次规划(QPP)问题,这直接导致SVM在一些应用上效率底、分类速度慢的问题,所以如果对SVM原始的模型做改进或增加正则项势必会增大开销,导致速度更慢。
自2007年孪生支持向量机(twin support vector machine,TWSVM)[12]被提出后,相对于SVM不仅有效削减了计算成本,还保持了优异的分类性能,同时也提出很多的改进和应用,如Kumar 等[13]引入了LSTWSVM,将不等式约束改为线性约束,提高模型训练速度;Jayadeva等[14]引入模糊隶属度函数提供给数据点,使其给模型提供不同的贡献度;Chu等[15]在LSTWSVM基础上通过对数据进行修剪提出ELS-TWSVM,有效地限制了噪声样本所带来的影响并成功运用到带钢表面缺陷的分类上。但是,上述的方法都存在一个问题,就是这些算法只是将异类分开,只关注样本的可分离性,而没有充分挖掘到样本间底层信息的关联性,忽略了底层数据信息的结构分布特征。
在常见的缺陷种类中,同种类的缺陷样本之间会产生极为相似的特征,特征的分布存在很高的关联程度,利用这些数据在全局和局部的结构信息,可以最小化同类样本间离散度并且最大化异类样本间的离散度,从而更好地进行分类。所以针对以上方法存在的问题,本文利用TWSVM的速度优势替换SVM算法,将全局、局部信息加入TWSVM的正则项中当作约束条件,提出全域优化孪生支持向量机(global optimized twin support vector machine,GTWSVM)算法,更好地对钢板表面缺陷分类。
1 图像预处理以及特征提取
1.1 图像预处理
为了使计算机更好地识别缺陷图像,采用灰度变换,从空间域上调整图像对比度来改善视觉效果,在突出感兴趣信息的同时,也能抑制部分无关的信息,以达到图像增强的目的。由于工厂获取的图片受到现场高温的影响,也会出现不同程度的噪点,这些噪点会影响后期的分类效果,所以采用了基于纹理分割的Gabor滤波器[16]对增强后的图像进行降噪平滑处理。
1.2 特征提取
为了后期达到更好的分类效果,这里对预处理后的图像采用灰度共生矩阵(gray-level co-occurrence matrix,GLCM)[17-18]和方向梯度直方图(histogram of oriented gradient,HOG)[19-20]提取高维特征。
1.2.1灰度共生矩阵
在实际的缺陷图像中,往往缺陷区域的灰度值和周围区域的灰度值有着明显的差异,为了更好地统计不同方向上灰度变换的频率,采用GLCM提取缺陷图像的纹理特征。首先将预处理后的图像灰度级压缩为16个灰度级,以此来减少矩阵计算量,然后以当前像素点为坐标中心,设置基准窗口尺寸为3×3,步长距离为1,移动方向为0°、45°、90°、135°。滑动窗口以基准窗口作为参考窗口,通过设定的移动方向和步长距离进行移动,尺寸与基准窗口相同。在依次遍历每幅缺陷图像上的全部像素点后,最终每幅图像都会得到一个关于缺陷纹理信息的特征矩阵。
1.2.2方向梯度直方图
缺陷图像中,局部缺陷区域和非缺陷区域的亮度不同,这可以通过计算边缘梯度来获取图像明暗区域的变化信息,而HOG特征向量是由图像局部区域的梯度方向生成的统计直方图来构成,优点是对几何形变和光照形变有着良好的不变性,因此可以对实时变化的图像数据环境保持良好的鲁棒性。
首先利用[-1,0,1]T和[1,0,-1]T梯度算子分别对预处理后的图像做卷积运算,计算出每个像素的水平方向和垂直方向的梯度,同时计算每个像素位置的梯度大小和方向,然后将图像划分成若干小的细胞单元,以45°等分将梯度方向映射到180°的范围中,统计细胞单元的梯度方向直方图,最后将细胞单元组成更大的描述子,称为“块”,本文的块尺寸设置为3×3。为了降低局部光照变化带来的影响和更好地融合其他特征,需要块内进行归一化处理。
最终将提取好的GLCM和HOG特征进行拼接,得到337维特征长度,由于维数拼接过高容易造成过拟合,这里采用PCA降维,同时将特征归一化和去中心化,使坐标平移到数据中心,更好分类。
2 相关原理
2.1 TWSVM原理
与传统的SVM不同,TWSVM是Jayadeva等[12]在2007年提出的一个二分类算法,它将解决2个小规模的二次规划问题,而不是求解单个大规模二次规划问题,它实际由2个非平行超平面xTω1+b1=0和xTω2+b2=0构成。图1为TWSVM示意图,目的是为了使2个超平面接近2个类的一个,而尽可能远离另一个类。

图1 孪生支持向量机示意图
为了构造这2个非平行决策平面,首先定义一组d维数据T={(xi,yi)|xi∈Rd,i=1,2,…,m},xi是输入样本,考虑是二分类问题,所以yi={+1,-1}为样本标签。然后将训练集T划分成大小为m1×n的矩阵A和大小为m2×n的矩阵B,其中m1+m2=m,从而建立了一对原始优化问题:
(1)
(2)
式中:ω1、ω2为超平面法向量;b1、b2为超平面偏移量;c1、c2为惩罚参数;q1、q2为松弛变量;e1、e2为适当维数的1向量。
通过引入拉格朗日乘子向量,并利用K.K.T条件[21],如下可以分别得到式(3)和式(4)的对偶问题:
(3)
(4)
式中,α=[α1,α2,…,αm2]T,γ=[γ1,γ2,…,γm1]T为拉格朗日乘子向量H=[Ae1],G=[Be2],P=[Ae1],Q=[Be2]。
令μ=[ω1,b1]T,v=[ω2,b2]T,由K.K.T条件知:μ=-(HTH)-1GTα,v=(QTQ)-1PTγ,当求得μ和v后,即可求出2个超平面。
通过下式,TWSVM很容易标记一个新样本x:
f(x)=argmin{|xTωl+bl=0|},l=1,2
(5)
2.2 线性判别分析
线性鉴别分析(linear discriminant analysis,LDA)[22]是一种降维方式。针对全局结构,每类样本点与本类的样本均值点的总方差体现了散列程度,能体现数据总体分布情况,也反映了样本点之间的密度,所以在投影后使同类样本点与均值点的距离平方和变小,即从总体上来看每个类中的样本与所属类之间的离散度。相反,对于异类的样本之间,从全局的角度上,通过求取每个类的中心点或均值点,使其投影后两类的均值点间的距离能够尽可能的大,从而在整体空间上彼此互相远离。如图2所示,其思想是希望找到一个最佳的投影方向,希望样本之间在投影到低维空间后使异类样本间的距离足够远,也希望同类样本间的距离变得更紧凑,从而LDA可以刻画出样本与样本之间的结构关系。

图2 最小化同类间距离和最大化异类间距离示意图
LDA目的是通过最大化以下函数式J(ω)的比值,找到最优的判别向量ω*,函数式定义如下:
(6)
式中:Sb为类内离散度矩阵;Sw为类间离散度矩阵,分别反应类内和类间的数据样本差异。
2.3 全局局部信息
在采集到的钢板表面各类缺陷图像中,往往同种缺陷的图像有非常相似的纹理、梯度等特征,所以在分类中充分挖掘样本信息之间的关联性,使同类样本之间能够尽量聚到一起,同时异类样本之间尽可能远离,从而更好的分类。受LDA思想的启发,在二分类的情况下,通过样本与样本之间的方差来体现样本之间的关联性,会使模型更加关注数据样本的先验知识。在TWSVM中加入LDA全局类内最小化思想,那么图1中两类样本虚线所围面积会有所减小,使计算出的分类超平面将更准确地区分两类样本。
根据LDA算法,可以定义全局类内协方差矩阵Sw:
(7)

因为全局信息体现的数据样本整体的结构关系,没有体现样本局部范围内的信息结构,但在钢板表面缺陷图像中不同类型的缺陷往往存在较大差别,但同种类型的缺陷却高度相关,所以我们也希望利用样本的局部关系,通过欧氏距离找到样本附近与之特征相似的样本点,同时也挖掘出与样本相差很大的部分样本点,使投影后样本在新的子空间有最小的类内距离和最大的类间距离。由于LDA是针对全局结构[23],所以本文将采用KNN算法来提取样本的局部结构,挖掘局部样本之间的关系。
这里考虑正类样本,若xi为正样本中任意一点,则定义它的K个同类近邻样本为N+(xi),同时定义它的K个异类近邻样本为N-(xi)。
N+(xi)=xik,k∈1,2,…,K,
N-(xi)=xjk,k∈1,2,…,K
(8)
(9)

(10)

3 全域优化孪生支持向量机GTWSVM
3.1 线性GTWSVM
在TWSVM算法的基础上,将样本全局类内离散度矩阵、局部类内离散度矩阵和类间离散度矩阵作为正则项加入到TWSVM中构成新模型,相比原模型,新模型在添加全局信息后对于数据的分布有更好地掌控,可以最大程度使同类样本尽可能附着在超平面上;同时,添加局部信息后,不仅可以更加关注内部结构,也能使边缘样本点远离异类超平面,从而达到更好的分类效果。
线性GTWSVM构成如下2个QPPs问题:
(11)
(12)
式中:ω1、ω2为超平面法向量;b1、b2为超平面偏移量;c1至c4,v1至v6为惩罚参数;q1、q2为松弛变量;e1、e2为适当维数的1向量。2个公式的第一项是每个类的点到超平面之间距离的平方和。因此,最小化会使超平面接近2个类中的其中一个类(如正类)。第二项是最小化误差变量的求和。第三项相当于最大化关于超平面的一侧边距。第四项是最小化局部一类样本中的散点。第五项是最大化局部异类样本间散点。第六项是最小化全局类内散点。最终,使得优化后的模型更加关注全局、局部结构信息。
对式(11)建立拉格朗日函数为:

αT(Bω1+e2b1+e2-q2)-βTq2
(13)
其中,α=[α1,…,αm2]T和β=[β1,…,βm2]T是朗格朗日乘子向量。根据K.K.T充分必要条件得:

(14)
(15)
(16)
-(Bω1+e2b1)+q2≥e2,q2≥0
(17)
αT[-(Bω1+e2b1)+q2-e2]=0,βTq2=0
(18)
α≥0,β≥0
(19)
从式(19)中知α≥0,β≥0,所以由式(16)可以得:
0≤α≤c1e2
(20)
将式(14)和式(15)合并表示为:
(21)
其中,I为适当维数的单位矩阵。
定义:
H=P=[Ae1]
G=Q=[Be2]
(22)
令μ=[ω1,b1]T,可以重写式(21)为:
HTHμ+τμ+GTα=0
(23)
则:
μ=-(HTH+τ)-1GTα
(24)
将式(24)代入式(13)中,可以求得式(11)的对偶QPPs问题:
(25)
同理可以获得式(12)的对偶问题:
(26)
其中,
ν=[ω2,b2]T=(QTQ+φ)-1PTγ
(27)
(28)
最终,通过式(24)和式(27),可以得到2个超平面:
xTω1+b1=0,xTω2+b2=0
(29)
由式(5),一个新样本x可以通过计算到2个超平面距离的远近来确定所从属的类别。
3.2 非线性GTWSVM
由于钢板表面缺陷图像属于多维特征,线性分类存在维度制约,不能很好地对其进行分类,所以需要对应非线性情况。GTWSVM通过核函数,从低维空间到高维Hilbert空间中[24]构造2个超平面K(xT,CT)u1+b1=0,K(xT,CT)u2+b2=0,其中,CT=[ATBT],u1,u2∈Rd为法向量,K是一个适合的核函数,K(xT,CT)=φ(xT)·φ(CT)。
此时ω1、ω2被映射为:
(30)
与线性情况相似,非线性GTWSVM的2个QPPs问题分别描述如下:
s.t. -(K(B,CT)u1+e2b1)+q2≥e2,
q2≥0
(31)
s.t. (K(A,CT)u2+e1b2)+q1≥e1,q1≥0
(32)
式中:

(33)

(34)

(35)
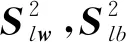
类似于线性情形,式(31)(32) 的解表示为:
(36)
(37)
其中,
Hφ=Pφ=[K(A,CT)e1]
Gφ=Qφ=[K(B,CT)e2]
(38)
同理,可以获得式(31)(32)的对偶QPPs问题:
(39)
(40)
则新样本的类别可以通过如下函数进行判别:
(41)
4 实验准备
在一线生产过程中,由于钢坯在轧制前没有得到彻底地清理,导致轧制过程中有块状等杂质压入钢坯表面,冷却后掉落,最终在表面形成诸如小凹坑状的麻点;热轧中,时间过长也会导致其表面形成点状金属氧化物[25];同时,受到矫直机、运输机等设备的影响,也容易在表面形成条状划痕[26]。
钢板表面缺陷的形成因素极为复杂,所以导致大量的缺陷种类。为了验证算法的可行性和泛化性能,实验选用2个典型的钢板表面缺陷数据集进行验证,首先选用东北大学热轧钢表面缺陷均衡数据集NEU-DET[27],验证算法在平衡数据集上的表现。其次,在工业生产过程中采集到的图像数据往往是不充分的,每种缺陷的数量层次不齐,所以为了验证算法在不平衡数据集上的泛化性,又采用了东北大学的热轧带钢表面缺陷不平衡数据X-SDD[28]进行实验验证。
4.1 NEU数据集
NEU数据集收集了热轧带钢表面的6种典型缺陷图像,即裂纹(Cr) 、夹杂物(In) 、斑块(Pa) 、麻点(PS)、压入氧化皮(RS)、刮痕(Sc)6类缺陷。该数据收集有1 800张钢板表面缺陷的灰度图像,每张图像的原始分辨率为200×200像素,每种类型表面缺陷有300个样本。按8∶2比例随机选取每类缺陷的80%,剩下的20%作为测试集,样本部分图像以及经过预处理后的图像如图3,图中第1行为每种类型缺陷样图,第2行为图像增强后的图像,第3行是经过Gabor滤波的去噪图像。
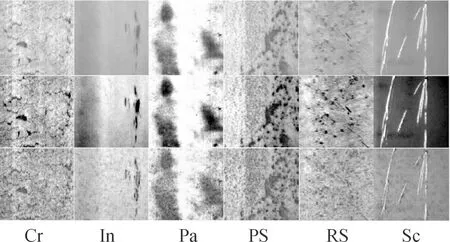
图3 NEU部分原图像以及预处理结果图像
4.2 X-SDD数据集
S-SDD数据集包含7种热轧带钢表面缺陷,即精轧辊印(FRP)、铁皮灰(ISA)、夹杂物(In)、板道系氧化皮(PSOS)、红铁皮(RIS)、划痕(Sc)、温度系氧化皮(TSOS),共计1 360张缺陷图像,每个缺陷图像分辨率为128×128像素。每类缺陷样本数量不同,其中精轧辊印203幅,铁皮灰122幅,夹杂物238幅,板道系氧化皮63幅,红铁皮397幅,划痕134幅,温度系氧化皮203幅,属于不平衡数据集。同样,实验设置80%作为训练集,剩下20%作为测试集。部分图像以及经过预处理后的图像如图4所示,图中第1行为每种类型缺陷样图,第2行为图像增强后的图像,第3行是经过Gabor滤波的去噪图像。

图4 X-SDD部分原图像以及预处理结果图像
4.3 实验环境和对比算法
在本节中,通过相关实验来证明本文GTWSVM算法的性能。所做实验是在1台配有Intel(R) Core(TM) i5-1135G7处理器(2.40 GHz)和16 GB RAM的电脑上并结合MATLAB R2017b编程软件实现的。
实验中对比了5种传统的算法,分别为BP、KNN、SVM、TWSVM、本文算法GTWSVM,每个算法均采用SOR算法来求解带有约束条件的二次规划问题。通过上文特征提取后降维得到37维缺陷样本。这样每个缺陷样本图像将由37维的特征向量和对应的标签构成,进行多分类测试实验,采用“一对多”(one-versus-all,OVA)[29]策略。用于本文评价方法的精确率(P)、召回率(R)、准确率(A)和F1Score值定义如下:
(42)
其中,TP、TN、FP和FN分别为正确预测为正样本数量、正确预测为负样本数量、被错误预测为正样本的负样本数量、被错误预测为负样本的正样本数量。
4.4 核函数选择以及参数寻优
核函数的选择对映射到高维中样本的分类有重要作用,文中采用最广泛应用的径向基函数(radial basis function,RBF),其表达式为:

(43)
为了减少大规模训练时间,使正则化参数c1=c3、c2=c4、v1=v4、v2=v5、v3=v6,通过网格搜索,从{2i|i=-16,-15,…,+5}获取RBF核参数σ、正则化参数和惩罚参数最优值。经过参数预调整,在GTWSVM中最近邻参数K值选取7,一旦选择了这些参数,将调优集返回到训练集,学习最终的决策函数。
5 实验结果与分析
5.1 NEU数据集分类结果与分析
对NEU数据集进行实验对比后,总体表现性能以及6种缺陷在不同算法的分类结果对应的详细指标分别如表1和表2所示。

表1 不同算法在NEU数据集上的评估结果

表2 每种缺陷分类指标结果
由表2实验结果可以看出,除BP神经网络外,其他4种算法对每类缺陷的识别都呈现出比较高的精度,但在同样大小的训练集和测试集下,本文新提出的GTWSVM算法分类精度更高。在实际图像中,麻点(PS)和压入氧化皮(RS)存在类似点状缺陷,尤其在第4类缺陷PS中混杂噪点较多并附着少量其他类型的缺陷,导致整体分类精度不高。但本文算法在PS缺陷中相对于其他算法分类效果更加明显,召回率相较于BP提升了38.14%、相较于KNN提升了13.56、相较于SVM提升了3.39%、相较于TWSVM提升了6.78%,另外在其他指标上均有一定程度的提升;同时,在第2类缺陷In和第6类缺陷Sc中,本文算法相对于TWSVM算法有明显提高,F1Score值分别提高1.42%和0.91%,召回率分别提高1.24%和1.67%。说明改进后的算法更加关注样本与样本之间的关联性,所得到的超平面更加利于区分。虽然提出的算法在一些缺陷分类效果上与其他算法相持平,但从表1可以看出分类整体效果上均优于其他4种算法,有更好的表现。
5.2 X-SDD数据集分类结果与分析
为了证明算法的实用性,对X-SDD数据集进行了测试,总体表现和具体每种缺陷指标如表3、表4所示。

表3 不同算法在X-SDD数据集上的评估结果
从表4可以看出,在第4类缺陷样本PSOS中,由于训练数据较少,导致模型拟合效果没有达到良好的表现,但本文所提的GTWSVM算法在该类缺陷上,召回率取得了60%的成绩,相对于其他算法有显著提升。虽然在第1类缺陷FRP中,GTWSVM的召回率低于TWSVM,但在第2类缺陷ISA、第3类缺陷In以及第5类缺陷RIS中均有不同程度的提升,其中在第3类缺陷In中,召回率相较于改进前的TWSVM算法召回率提升了16.26%,F1Score达到了90.72%,远高于其他对比算法。同时,从表3可以获知,本文所提GTWSVM算法在整体性能上优于TWSVM、SVM等算法,总体准确率达到了89.19%,同样在其他指标上也有一定提升。
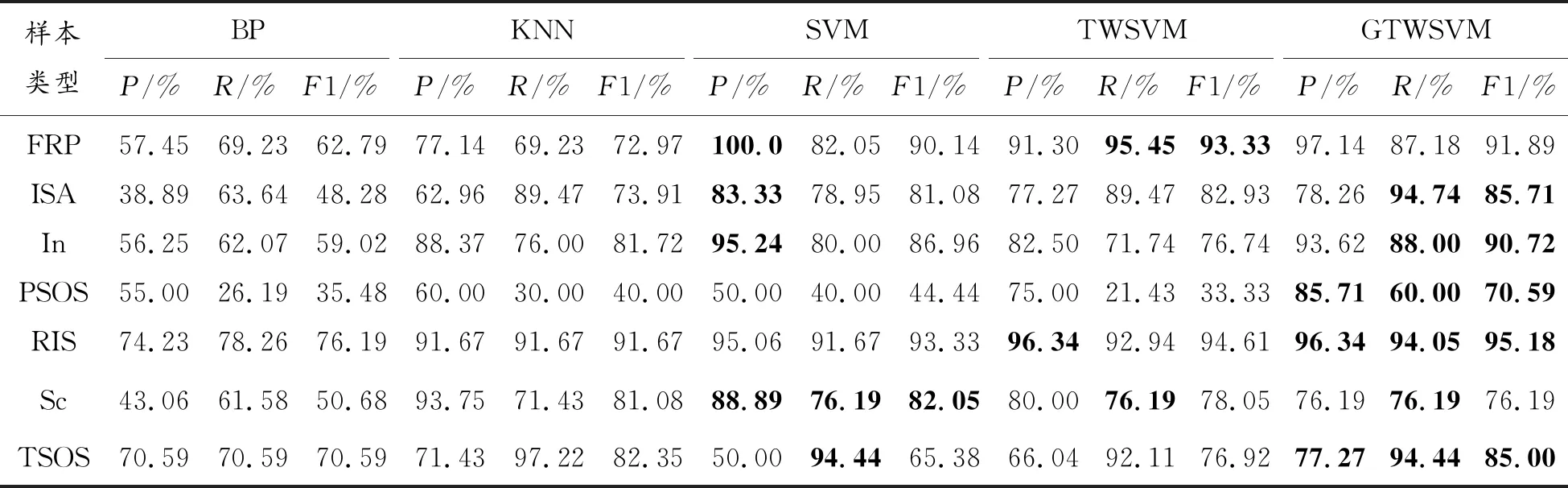
表4 每种缺陷分类指标详细结果
通过2组实验,说明在原TWSVM模型中,添加全局信息后,使得投影后的每一类样本到本类样本均值点的距离平方和减小;同时,添加局部信息后,每类样本点在选择局部同类近邻样本和异类近邻样本后,同样可以使局部范围对同类样本之间的距离变得紧凑,并且远离局部异类样本点,利用样本局部数据信息来扩大同类与异类样本间的边界,通过平衡模型参数的权重,找到最佳投影方向,进而提高TWSVM算法的性能。因此,最终得到的分类超平面会比优化前的超平面更加关注全域范围内样本间的内部结构,分类更加准确。
5.3 GTWSVM的鲁棒性
考虑到GTWSVM算法引入了局部近邻,K值的选取会对模型的性能产生影响。为了验证算法的稳定性,通过选取不同K值来进行实验,同时为了验证算法的普适性,将测试集数量增加为总数据量的30%,结果如图5所示。
图5 GTWSVM不同K值在NEU和X-SDD上的性能图像
经过多次实验,在NEU数据集和X-SDD数据集上,GTWSVM算法在不同K值选取下所对应的识别准确率基本趋于稳定。可以看出,当K取7时,识别准确率最高,当K取其他值时,模型依然能够维持在一个相对稳定的范围中。并且随着测试数量的增加,K值并没有对模型造成很大的波动,说明模型对K值的选取不敏感,有很好的鲁棒性。
6 结论
1) 利用LDA的全局思想并结合KNN算法,将每个样本的局部同类近邻样本尽可能聚集在一起,将异类样本尽可能分开,并作为正则项嵌入到TWSVM中。在对缺陷样本图像降噪处理后,利用GLCM和 HOG分别进行特征提取,并融合2种特征。通过PCA降维后输入到本文算法中训练。
2) 通过实验对比,本文算法在考虑了样本之间的关联性后,整体性能得到进一步提高,更加适应现代化工业生产,可提高钢板质量,增大企业经济效益。
