基于自适应矩估计优化堆栈自编码器的过热汽温预测模型
2022-11-07马良玉梁书源
马良玉,梁书源
(华北电力大学 控制与计算机工程学院,河北 保定 071003)
0 引言
随着新能源发电所占比例的增加,大容量火电机组在自动发电控制下深度调峰运行已成为常态[1]。过热汽温作为锅炉运行过程中的一项重要指标,其控制效果直接关系着电厂的安全、经济、稳定运行[2]。锅炉过热汽温存在较大的时延、惯性和较强的时变性[3]。当机组大范围变负荷时,常规的过热汽温控制方法控制效果较差[4]。因此,提高过热汽温控制质量一直是电厂优化运行的重要课题。
随着人工智能技术的成熟,先进智能预测控制方法在电厂运行优化和控制系统中逐渐得到应用[5]。实现过热汽温的高精度预测,是提高智能预测控制效果的前提。文献[6]建立了基于改进烟花算法优化的过热汽温预测模型。该模型的泛化能力较强,预测误差较小。文献[7]建立了基于极端梯度提升(extreme gradient boosting,XGBoost)算法的过热汽温预测模型,并通过随机搜索(randomized search,RS)优化算法对模型的初始参数进行调优,使得最终的预测模型拟合程度高、泛化能力强。文献[8]构建了基于粒子群优化算法优化的支持向量机过热汽温预测模型,并将其应用于快速甩负荷工况下的过热汽温预测;该模型精度较高,但是样本数据较少。
本文以某600 MW超临界火电机组为研究对象,基于机组变负荷运行历史数据,利用 SAE(stacked autoencoder)对锅炉过热汽温系统特性进行建模;为了加快模型训练速度,引入 Adam算法对模型进行梯度下降优化,最终构建较高精度的SAE过热汽温预测模型。
1 算法原理
1.1 SAE算法
自编码器(autoencoder,AE)是一种人工神经网络,其通过最小化重构误差,以无监督训练来提取原始数据的降维特征[9]。如图1所示,AE由编码器f(x)和解码器g(h)构成。
AE编码器和解码器的权重与偏置是依据最小化误差函数而进行优化的[10],即:
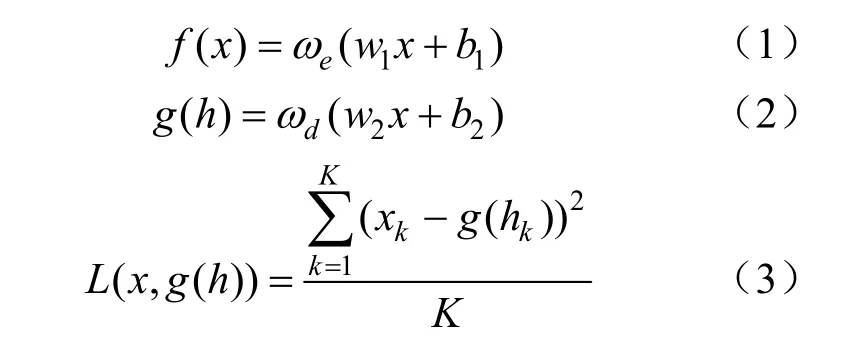
式中:L ( x, g( h))为重构误差;ωe为编码器的激活函数;w1为编码器权重;b1为编码器偏置;dω、w2、b2分别为解码器的激活函数、权重、偏置;K为数据的样本个数。
SAE是由多个AE堆叠而成的深层网络[11]。SAE网络的训练是通过逐层贪婪算法实现的[12]。SAE训练过程如下:假设训练一个有n层隐藏层的SAE。首先,训练第一层的隐藏层。在训练完毕、网络参数基本确定后,将其输出作为第二层的输入。在此基础上,训练第二层,得到第二层的权重与偏置。依次训练,直到第n层隐藏层训练结束。然后,通过最小化误差函数及反向传播对SAE模型的权值对偏置进行微调。最终,完成整个SAE网络结构的训练。
为了加快 SAE模型的训练速度,首先利用Mini-batch将训练数据分为128组,然后对每一个batch利用Adam算法进行优化。
1.2 Adam算法
Adam算法广泛应用于深度学习的优化过程中,适用于较大规模数据集参数优化的情况[13]。Adam算法的优势在于对每个模型参数都有相应的学习速率和动量,从而可以加快模型的收敛速度、减小波动,且按照其默认的初始配置参数就可以达到较好的效果。
设模型训练第 t轮时,模型权值和阈值的更新规则为[14]:

式中:1α、2α为超参数,初始值一般为0.9、0.999;vdw、sdw分别为权重的累计梯度和累计平方梯度;vdb、sdb分别为偏置的累计梯度和累计平方梯度;dw、db 分别为权重梯度和偏置梯度;vd′w、sd′w分别为权重的累计梯度和累计平方梯度的偏差修正;vd′b、sd′b分别为偏置的累计梯度和累计平方梯度的偏差修正;wt、bt为更新的权重和偏置;η为学习率;ξ为一个超参数,初始值一般设为10-8。
2 过热汽温SAE预测模型
2.1 模型训练数据获取与预处理
本文研究对象为某 600 MW 超临界火电机组,型号为DG1900/25.4-Ⅱ1。建模与实验数据取自该机组的全工况仿真机系统。
将机组负荷从600 MW降低到420 MW,再升至600 MW,共获取28 000组秒级数据。将20 000组数据用来训练SAE预测模型,其余8 000组数据作为测试集。
考虑模型训练时的预测精度和收敛加速,在将训练样本和测试样本输入到SAE预测模型前,先进行[0,1]归一化处理[15]。
在 Pycharm仿真软件上,选择编程语言Python进行编程,构建SAE过热汽温预测模型。
2.2 模型输入输出变量的选取
过热器喷水减温系统采用二级喷水减温控制结构,目的在于更精确地控制屏过出口汽温与末过出口汽温。
喷水减温器布置图如图2所示:一、二级喷水减温器都有 A、B侧。每级喷水由两侧喷入,可各自控制减温水量,以有效地减小屏过出口汽温与末过出口汽温偏差。
运行过程中,水煤比会影响中间点温度,从而影响后续各级汽温;因此,模型输入变量中考虑了总煤量、进水冷壁的给水流量。
变负荷过程中,一、二级喷水量直接影响屏式过热器出口汽温和末级过热汽温。喷水量与各级喷水阀开度、给水压力、主汽压力有关。给水温度、总风量变化也会对汽温产生影响[16]。所以,最终确定一级过热汽温预测模型的输入变量为总煤量、总风量、高压加热器出口给水压力、高压加热器出口给水温度、主汽压力、进水冷壁给水流量、一级喷水阀开度、低过出口汽温;输出变量为屏过出口汽温。二级过热汽温预测模型的输入变量为总煤量、总风量、高压加热器出口给水压力、高压加热器出口给水温度、主汽压力、进水冷壁给水流量、二级喷水阀开度、屏过出口汽温;输出变量为末过出口汽温(以一、二级左侧减温器为例)。
2.3 模型结构
考虑过热蒸汽温度具有惯性、迟延特性,因此选择输入、输出带有时延的SAE模型结构。
保持其他条件一致,仅改变输入输出变量延迟阶次,进行相关实验。
以均方误差(MSE),平均绝对误差(MAE)来作为判定指标。
在不同的输入输出延迟阶数条件下,预测模型对应测试集预测结果如表1所示。
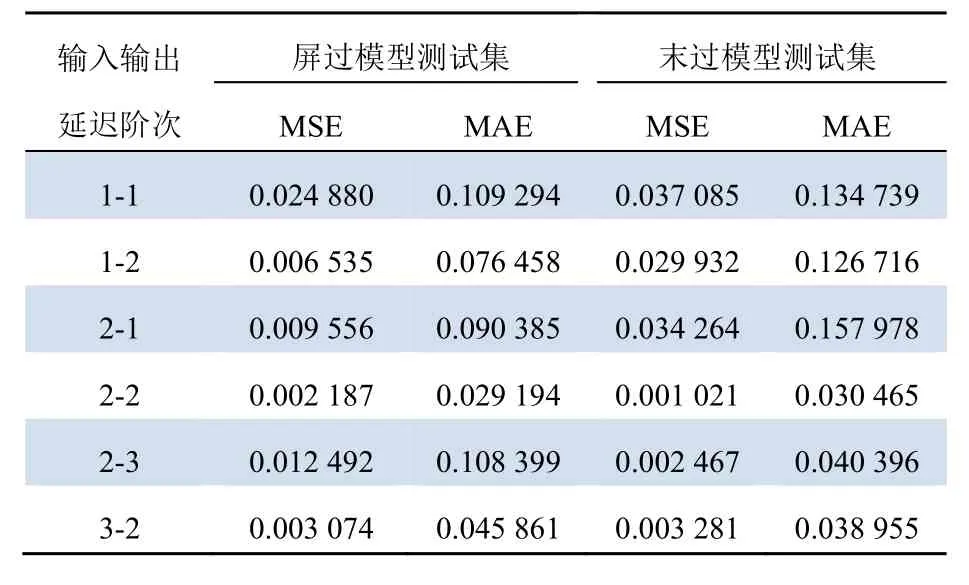
表1 两级过热汽温预测模型输入输出阶次实验结果Tab. 1 The experimental results of inputs and outputs order of the two-stage SST prediction model
由表1可知,在两级过热器出口汽温预测模型中输入输出延迟阶次都为2时,对应模型精度最高;因此,选择输入输出延迟阶数都为2的模型结构。
设当前时刻为t。将预测模型输入变量的t、(t-1)(t-2)这3个时刻的值和输出变量的(t-1)(t-2)这2个时刻的值,一起作为模型的输入;输出为输出变量 t时刻的值[17]——以此来构建SAE模型,进一步提高模型的精度。SAE模型一般结构如图3所示。

图3 SAE模型一般结构图Fig. 3 SAE model general structure diagram
对于屏式过热器、末级过热器出口汽温SAE预测模型,图3中的m为8,n为1。由此可确定:屏式过热器、末级过热器出口汽温SAE预测模型均有26个输入,1个输出。
2.4 模型激活函数确定
比较隐藏层采用relu、swish、leaky_relu、elu这4种不同激活函数对模型预测精度的影响,结果如图4所示。
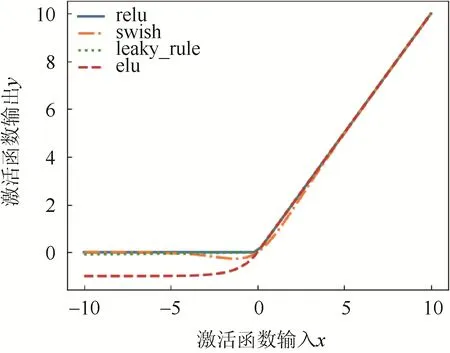
图4 不同激活函数对预测精度影响结果对比Fig. 4 Comparison of effects of different activation functions on prediction accuracy
为消除隐藏层层数及各隐藏层节点数对实验结果的影响,初始确定SAE预测模型的隐藏层层数为2层,第一层节点为30个,第二层节点为27个;模型其他训练参数均一致。采用不同激活函数的模型训练结果和测试结果如表2所示。
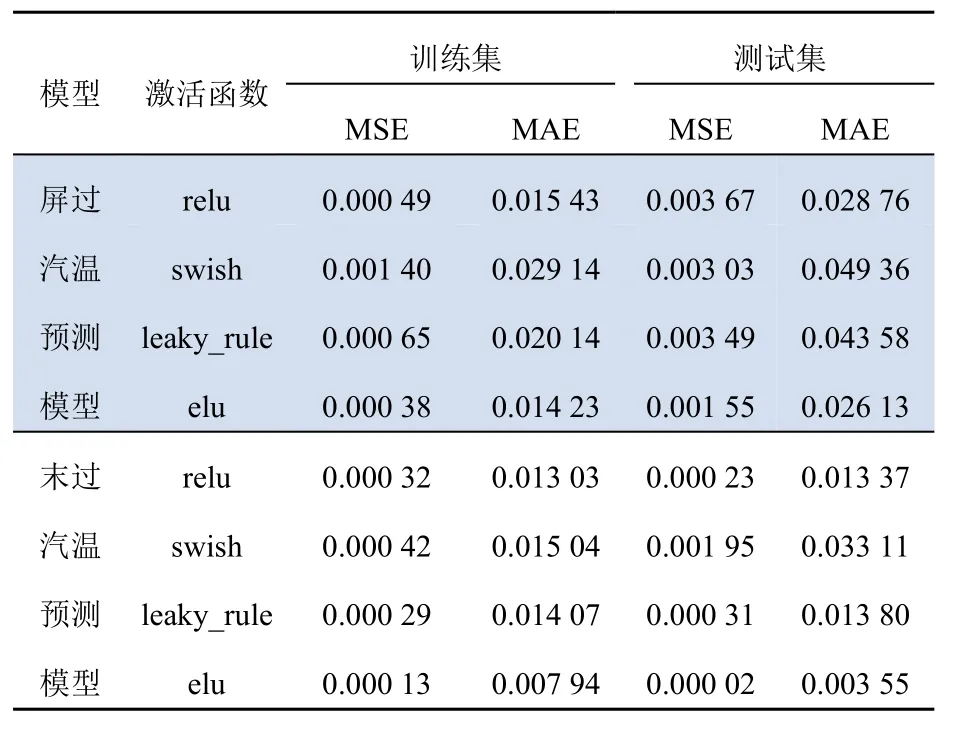
表2 不同激活函数测试结果Tab. 2 Different activation function test results
由表2可知,elu激活函数具有更优异的表现,模型预测精度更高,所以本文模型的激活函数采用elu函数。
2.5 过热汽温模型训练及验证结果
考虑输入输出变量的维度、网络的复杂程度等因素,经多次实验,确定2个SAE过热汽温预测模型的最优网络结构为:26-30-26-1。
训练完成的屏过出口汽温预测模型、末过出口汽温预测模型针对训练集、测试集的计算和测试结果及误差分别如图5、图6所示。
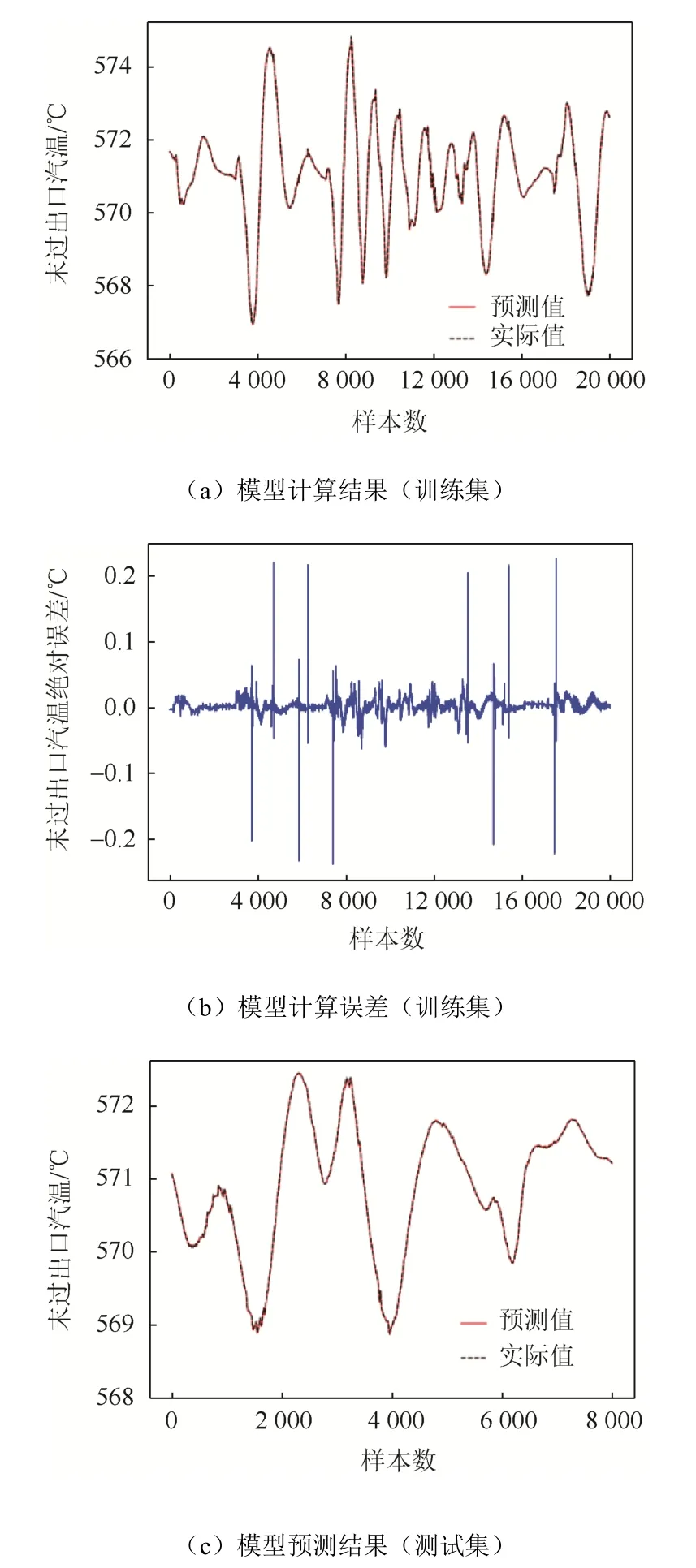
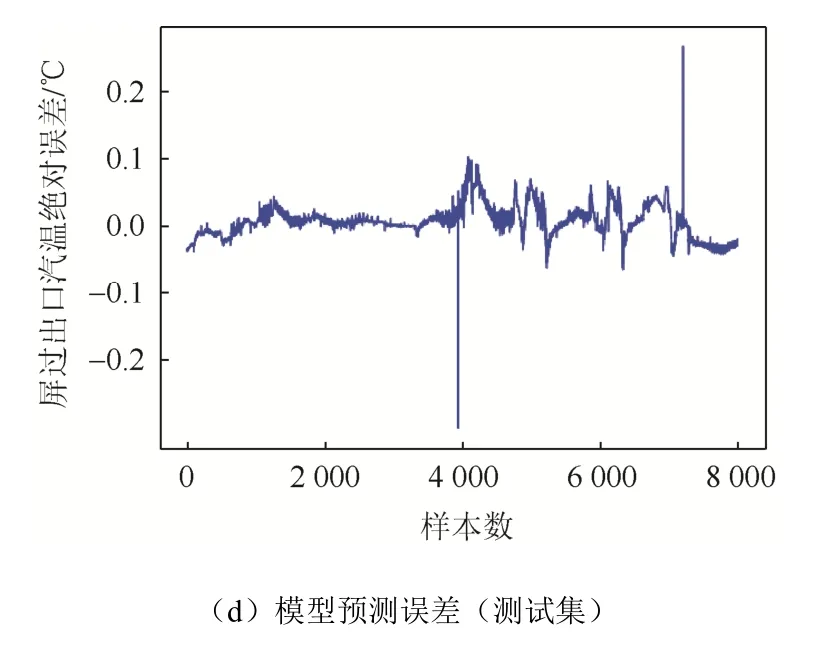
图5 屏过出口汽温预测模型训练和测试结果Fig. 5 Train and test results of the PSH outlet steam temperature prediction model
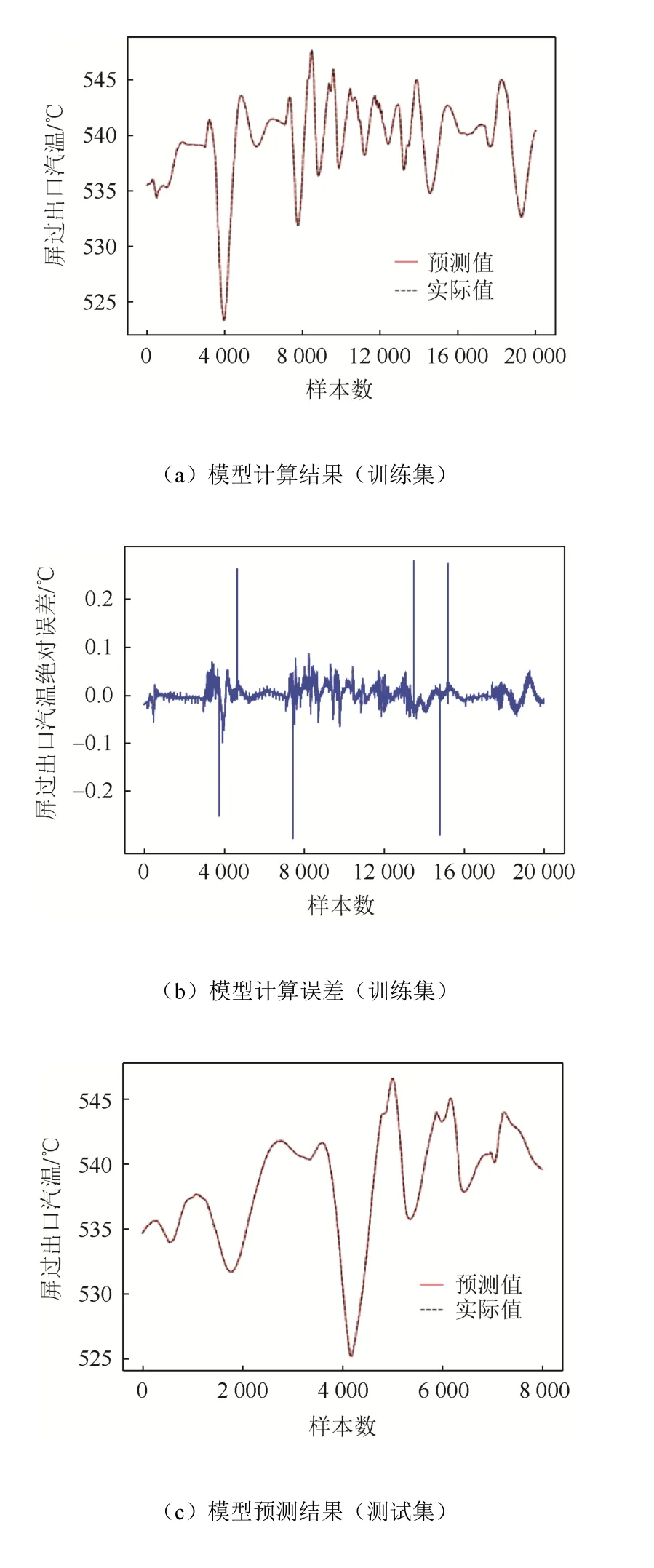

图6 末过出口汽温预测模型训练和测试结果Fig. 6 Train and test results of the FSH outlet steam temperature prediction model
由图 5(a)(c)、图 6(a)(c)可知,Adam优化的SAE过热汽温预测模型不论在训练还是测试过程中,所对应的预测精度都很高;由图5(b)(d)、图6(b)(d)可知,模型在训练或者预测的时,绝对误差都很小,比较稳定。
2.6 不同模型预测效果比较
以均方误差MSE、平均绝对误差MAE以及相关系数R2为判定效果优劣的指标,比较Adam优化的SAE预测模型与机器学习中具有预测高精度优点的XGBoost预测模型的预测结果。
为消除初始参数对XGBoost模型的影响,选用随机搜索算法来对此参数模型进行优化[5]。
不同方法训练效果对比结果如表3所示;测试效果对比结果如表4所示。
由表3、表4可知,与随机搜索(randomized search, RS)算法优化的XGBoost预测模型相比,Adam优化的SAE过热汽温模型预测精度更高,泛化能力更强。
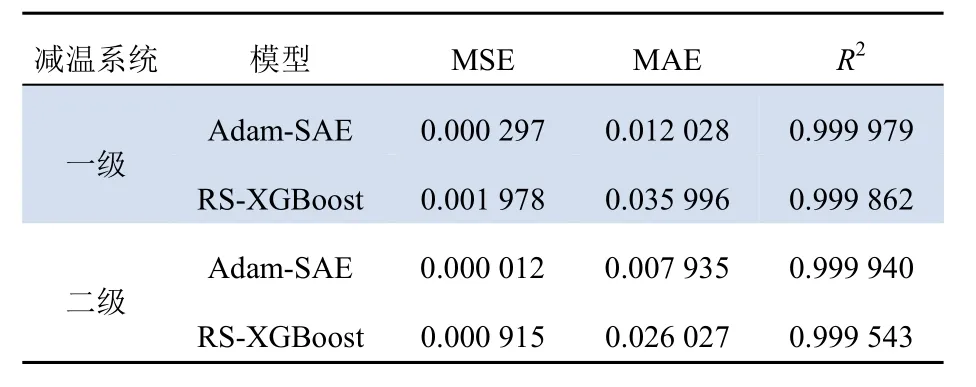
表3 过热汽温系统的训练集预测效果Tab. 3 The prediction result of the training set of the superheated vapor temperature system
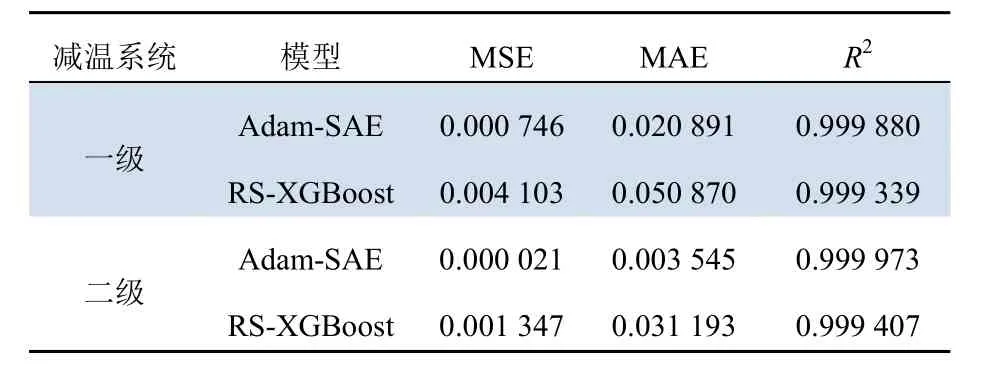
表4 过热汽温系统的测试集预测效果Tab. 4 The prediction result of the test set of the superheated steam temperature system
3 结论
针对600 MW超临界火电机组过热汽温系统一、二级汽温对象,建立了Adam优化的SAE过热汽温预测模型:隐层采用了elu激活函数使得模型精度更高;为加快SAE预测模型的训练速度,采用Adam算法和Mini-batch对模型进行了优化。
将Adam优化的SAE过热汽温预测模型与RS优化的XGBoost过热汽温预测模型的预测效果进行对比,结果表明:Adam优化的SAE过热汽温预测模型有着更高的预测精度。
