基于优化的YOLOv5模型的车辆检测与分类研究
2022-11-07李佳昊陆锦泉
李佳昊,陆锦泉
(广东省城乡规划设计研究院有限责任公司,广东 广州 510290)
0 引言
卷积神经网络的目标检测算法已经在道路交通监控领域得到广泛应用,YOLO系列算法是基于回归的一阶段法,不用产生候选区域,而是通过应用算法来直接对图像进行定位与分类。为解决检测实时性问题,Fukai Zhang等[1]对YOLOv3进行了改进,将不同大小的卷积特征图和残差网络中对应尺度的特征图进行融合,提高车辆检测的精度及速度。2020年3月以来,YOLOv4及YOLOv5相继被提出,对于这种具有更加优秀检测性能的网络模型来说,在车辆检测领域将是一个跨越式发展。
1 优化方法
1.1 先验框机制的自适应调整
先验框Anchor是一组预先设置好的目标检测候选框,实际的候选框是通过在其之上的调整而得出。Anchor设置的合理与否,极大地影响着最终模型检测性能的好坏。
该文使用K-Means算法对数据集中标注好的目标检测框的宽高进行重新聚类,从而获得适用于检测小尺度目标图像的Anchor尺寸。其中聚类方法中距离公式见下式:
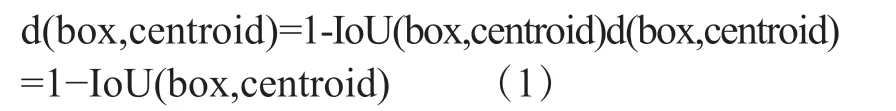
式中,centroid——簇的中心;box——标注的边框坐标;IoU——交并比。选取合适的先验框k值可以使得在尽可能高IoU的情况下,模型复杂度也较低,取得一个较好的平衡。最终获得了九组适用于本数据集的Anchor,大小分别为:[32,28],[70,59],[127,119],[252,227],[585,275],[596,392],[454,577],[587,477],[573,580]。
1.2 注意力机制的引入及卷积的替换
计算机视觉中的注意力机制的基本思想就是能使系统专注于某件事,能够忽略无关信息而将注意力放在重点关注信息上。在车辆检测过程中,为了进一步提升检测的专注力,引入SE模块可以将检测视野集中于所需检测的目标车辆上,这样可以大大减少背景建筑物的干扰[1]。
在真实道路交通视频检测中,存在路段车辆较少的情况,此时,单张图片的所检测的车辆目标个数少且所检测的目标尺寸偏小。因此,在网络的Head部分中,在张量拼接操作及BCSP模块之间加入了SE注意力模块,让网络更加专注于所检测的车辆[2]。
此外,为了减小原始YOLOv5的计算量,以提升检测的速度,该文对结构中的卷积层进行了改进。该文将Head里卷积层的部分普通卷积替换成了深度可分离卷积[3],从而减少模型的参数量,使得检测的速度有进一步的提升。图1为各部分修改完成之后与原模型对比示意图。
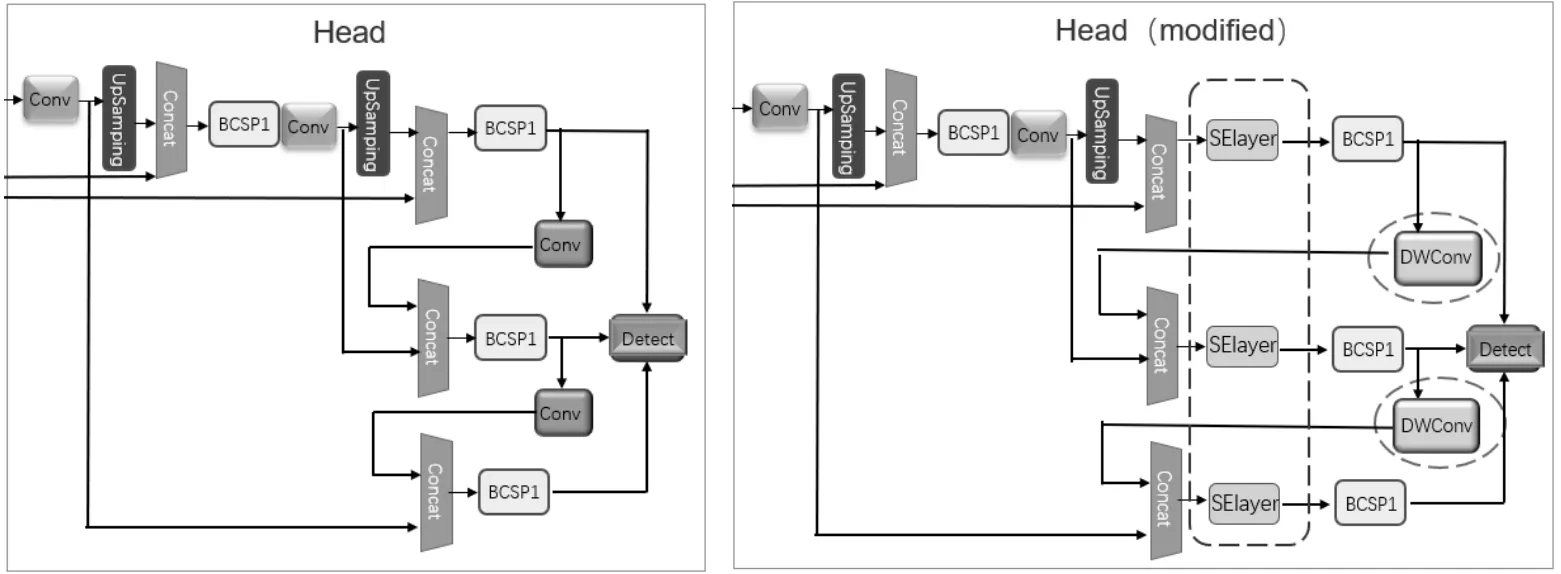
图1 优化前后的Head部分示意图
1.3 非极大值抑制的调整
在目标检测的过程中,通常在同一个物体的位置上会出现众多的候选框,这些候选框两两之间存在相交的情况。当遇到拥堵路段密集车辆的图像时,如果不去除这种冗余的候选框,将会非常影响检测和分类的准确性。因此,针对这种重叠候选框的筛选,通常需要进行非极大值抑制(nms)操作。YOLOv5中采用普通的IoU的计算方式。这种方式在抑制多余的检测框时,因为仅考虑了重叠区域,对于遮挡情况经常产生错误抑制。因此,使用DIoU作为非极大值抑制的标准,在考虑重叠区域面积的同时,还考虑了中心点距离。该文对YOLOv5模型的非极大值抑制进行了调整,采用了DIoU的方法。DIoU在IoU基础上引入了惩罚项R,目的是最小化两个与预测框的中心点距离,因此比IoU速度快。对于包含两个车辆交错重叠的情况,采用DIoU-nms的方式可以将其区分检测出来,检测效果有了进一步改善。
2 实验及结果分析
2.1 数据集描述
为了能够实现对复杂道路情况下车辆的快速检测,采集了实际道路交通视频信息用于提取分类器训练的样本。该文采用数据集如下,选出包含2 100张有清晰样本的图像,并将其分成三部分:1 680张图像作为训练集,210张图像作为验证集,210张图像作为测试集。之后,将图像尺寸统一设置为416*416,并进行图像标注,将车辆分为五个类别标签:Car、Bus、Truck、 Bicycle和Motorcycle。各类型车型识别数据集见表1。
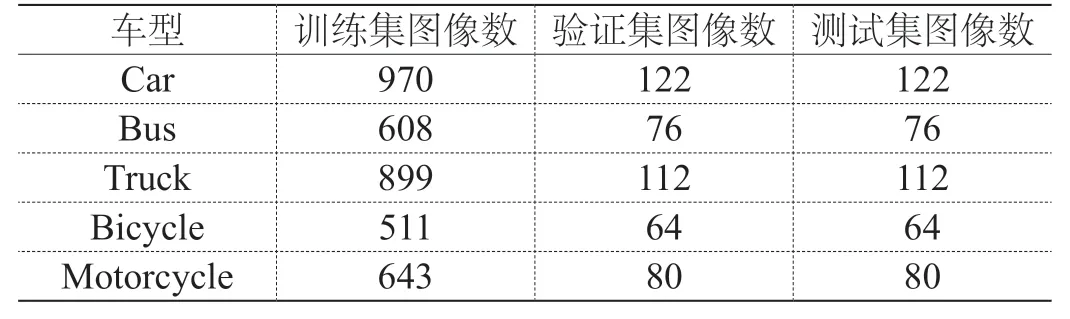
表1 车型识别数据集
2.2 训练过程
根据已搭建好的车辆图像数据集及OP-YOLOv5网络训练方法,执行训练过程:将训练集中的1 680张图片输入到YOLOv5和OP-YOLOv5网络中,经过训练后,学习到了各卷积层、BN层以及检测层[4]的权重参数,最终得到车辆检测模型。
在整个训练的过程中,设置参数批量为32,动量为0.937,权重衰减配置为0.000 5,总迭代次数为200次,初始学习率lr=0.01。
2.3 实验结果及分析
在训练完成之后,将测试集中待检测的图片分别输入以上5种模型中,得到检测结果。
经过试验,模型的三种损失都随着训练次数的增加而逐渐下降,当训练次数达50次左右时,模型的损失变化趋于平缓,基本达到收敛;当训练次数达到200次时,改进前后车辆检测模型的损失均降到0.005以下,两种模型的损失基本不再变化,此时终止训练即可获得稳定的模型权重。
该文通过均值平均精度(mAP)、检测速率、查准率和查全率四项指标对不同模型检测的结果进行评价与分析[5]。表2是改进前后的两种网络结构经过深度学习训练后,所得到的模型的平均精度(IoU≥0.5)和每秒帧数。
从表2中可以看出,基于YOLOv5模型平均检测精度可达93.8%,传输速度为53.1 f/s,而改进后的OPYOLOv5可以获得高达95.7%的mAP,且传输速率也有了提升,可达到60.5 f/s。对于5种分类的车型而言,卡车和自行车的mAP效果提升最明显,分别提高了7.0%和2.5%。其中,由于小轿车的车型样式多样,自行车骑行中行人的干扰,它们两者的平均检测精度相对其他种类来说较低,但也能保持在90%以上的高准确率,具有良好的检测效果。图2可以看出,相对于YOLOv5而言,OP-YOLOv5随着迭代次数的增多,收敛效果更好,且速度也较快。当迭代次数达50次时,就可以获得90%的mAP。该文提出的OP-YOLOv5方法不仅在平均检测精度上较原有模型提高了近2%,检测速度也有了提升,具有良好的检测实时性。

表2 不同方法实验对比结果
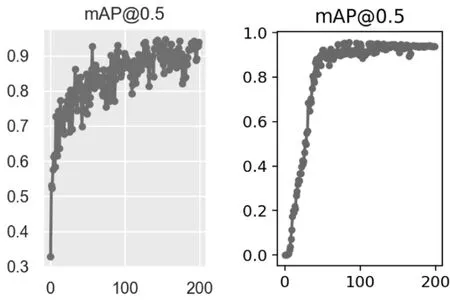
图2 优化前后模型平均精度曲线对比图
在此选取查准率、查全率作为车辆分类模型的评价指标来对5种类别车辆的分类检测结果进行进一步分析,统计结果见表3。
由表3可以看出,改进前后方法检测公交车得到的查全率和查准率在所有车型中是最高的,优化后的方法检测所得查全率和查准率高达99%,具有很好的识别效果。而对于卡车和轿车来说,查全率和查准率略有下降,自行车的查全率和查准率最低,但总的查准率和查全率可分别达到92%、94%。相比之下,OP-YOLOv5比YOLOv5对不同车型的识别效果有了进一步提升。

表3 查准率与查全率统计表
YOLOv5和OP-YOLOv5车辆检测模型的查准率和查全率绘制出P-R曲线图,如图3所示。模型检测的准确性会随着查全率的升高而降低,当查全率约为90%时,查准率约为90%,此时模型在具有较高的查全率的同时,又保证了较高的检测精度。当查准率相等时,相对于YOLOv5来说,OP-YOLOv5方法能够取得更高的查全率,即可以将测试集中更多的车辆检测出来。

图3 P-R对比图曲线
此外,从测试样本集中选出小目标车辆及重叠遮挡的车辆图片进行检测试验,对比改进YOLOv5模型前后的识别分类效果,如图4所示,左侧为原模型检测效果图,右侧为改进后模型检测效果图。在图4(a)(b)中,测试样本通过YOLOv5模型处理后,最终未能检测出较远的小尺度车辆目标,相比之下,OP-YOLOv5模型可以将视野中这个较远处的车辆检测出来。图4(c)(d)为车辆侧面检测效果,可以看出OP-YOLOv5不仅提高了检测精度值,而且将原图中错检的摩托车,进行了更正,降低了错检率。在图4(e)(f)中,YOLOv5模型仅识别出了前方的2个摩托车,而OP-YOLOv5模型对于后方被重叠遮挡的摩托车,也可以清晰地辨别出来。因此,OP-YOLOv5模型具有更高的查全率和查准率,可以获得更好的检测效果。

图4 车辆检测分类效果对比图
3 结束语
在计算机视觉技术迅速发展的今天,利用深度学习算法检测车辆类型,可以为交通量的分类统计提供帮助,还可为交通事故和识别查证提供一定的有效信息。该文在YOLOv5的基础上进行了优化,利用K-means聚类算法自适应产生合适的锚框尺寸,更改部分卷积网络,并在输出端利用DIoU的方法进行非极大值抑制,使得特征图的表征能力进一步提高,同时也提高了车辆识别的准确性。OP-YOLOv5可以精准地输出每个车辆的预测框并判断车辆的类型,如Car、Bus、Bicycle等。在后续工作中,笔者将对不同环境条件下(包括天气、光线因素)的车辆检测进行研究,改进检测模型对不同环境的适应能力,使其更好地为交通管理服务。
